 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comparative Attention Framework for Better Few-Shot Object Detection on Aerial Images
Oct 25, 2022
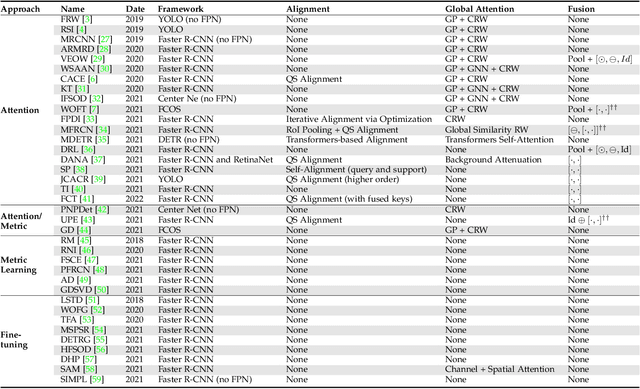
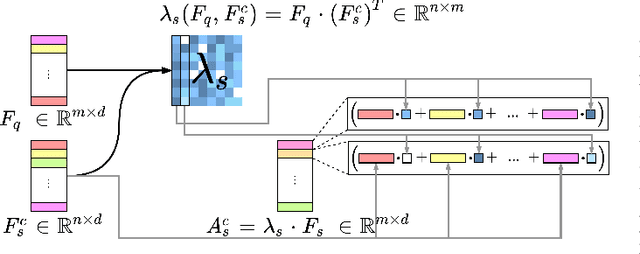
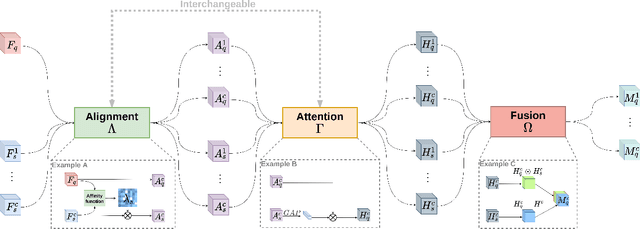

Few-Shot Object Detection (FSOD) methods are mainly designed and evaluated on natural image datasets such as Pascal VOC and MS COCO. However, it is not clear whether the best methods for natural images are also the best for aerial images. Furthermore, direct comparison of performance between FSOD methods is difficult due to the wide variety of detection frameworks and training strategies. Therefore, we propose a benchmarking framework that provides a flexible environment to implement and compare attention-based FSOD methods. The proposed framework focuses on attention mechanisms and is divided into three modules: spatial alignment, global attention, and fusion layer. To remain competitive with existing methods, which often leverage complex training, we propose new augmentation techniques designed for object detection. Using this framework, several FSOD methods are reimplemented and compared. This comparison highlights two distinct performance regimes on aerial and natural images: FSOD performs worse on aerial images. Our experiments suggest that small objects, which are harder to detect in the few-shot setting, account for the poor performance. Finally, we develop a novel multiscale alignment method, Cross-Scales Query-Support Alignment (XQSA) for FSOD, to improve the detection of small objects. XQSA outperforms the state-of-the-art significantly on DOTA and DIOR.
SIMBAR: Single Image-Based Scene Relighting For Effective Data Augmentation For Automated Driving Vision Tasks
Apr 01, 2022
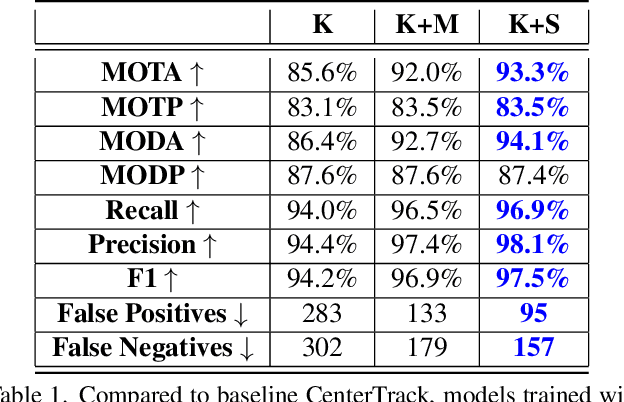
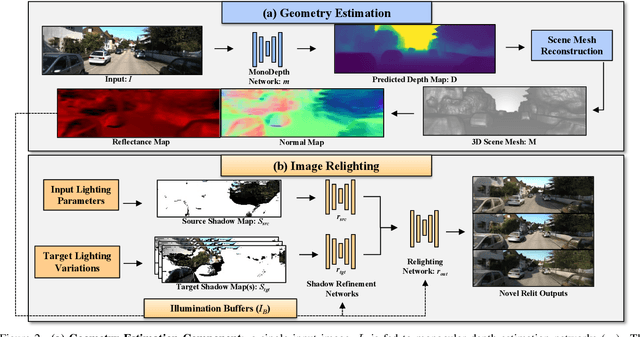
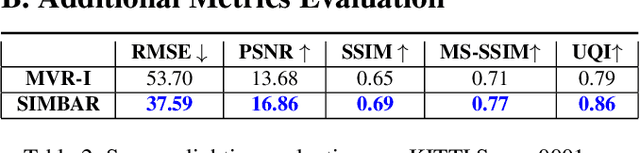
Real-world autonomous driving datasets comprise of images aggregated from different drives on the road. The ability to relight captured scenes to unseen lighting conditions, in a controllable manner, presents an opportunity to augment datasets with a richer variety of lighting conditions, similar to what would be encountered in the real-world. This paper presents a novel image-based relighting pipeline, SIMBAR, that can work with a single image as input. To the best of our knowledge, there is no prior work on scene relighting leveraging explicit geometric representations from a single image. We present qualitative comparisons with prior multi-view scene relighting baselines. To further validate and effectively quantify the benefit of leveraging SIMBAR for data augmentation for automated driving vision tasks, object detection and tracking experiments are conducted with a state-of-the-art method, a Multiple Object Tracking Accuracy (MOTA) of 93.3% is achieved with CenterTrack on SIMBAR-augmented KITTI - an impressive 9.0% relative improvement over the baseline MOTA of 85.6% with CenterTrack on original KITTI, both models trained from scratch and tested on Virtual KITTI. For more details and SIMBAR relit datasets, please visit our project website (https://simbarv1.github.io/).
S2MS: Self-Supervised Learning Driven Multi-Spectral CT Image Enhancement
Jan 25, 2022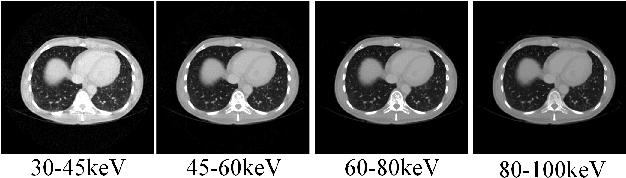
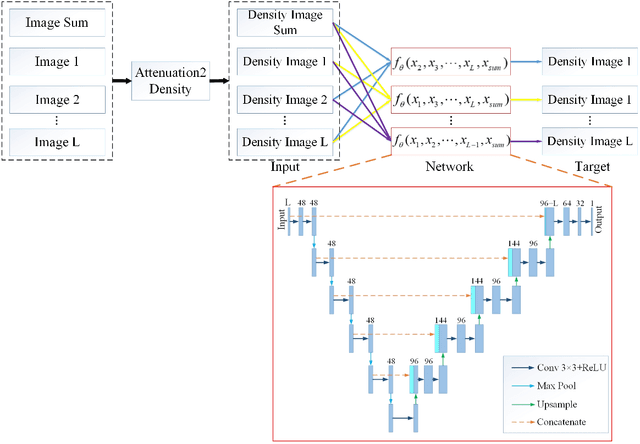
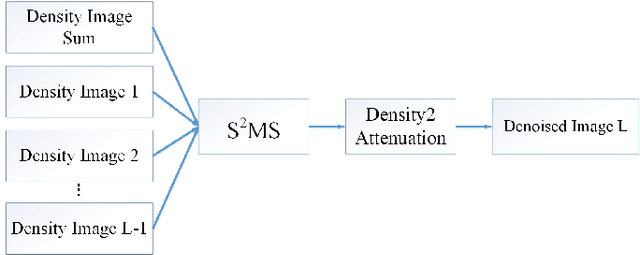
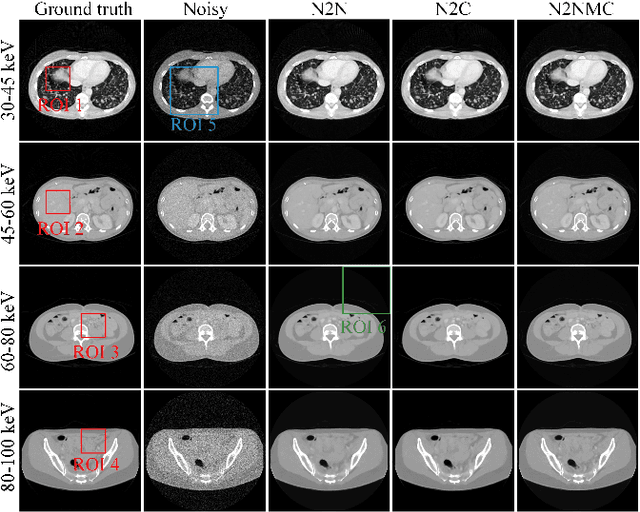
Photon counting spectral CT (PCCT) can produce reconstructed attenuation maps in different energy channels, reflecting energy properties of the scanned object. Due to the limited photon numbers and the non-ideal detector response of each energy channel, the reconstructed images usually contain much noise. With the development of Deep Learning (DL) technique, different kinds of DL-based models have been proposed for noise reduction. However, most of the models require clean data set as the training labels, which are not always available in medical imaging field. Inspiring by the similarities of each channel's reconstructed image, we proposed a self-supervised learning based PCCT image enhancement framework via multi-spectral channels (S2MS). In S2MS framework, both the input and output labels are noisy images. Specifically, one single channel image was used as output while images of other single channels and channel-sum image were used as input to train the network, which can fully use the spectral data information without extra cost. The simulation results based on the AAPM Low-dose CT Challenge database showed that the proposed S2MS model can suppress the noise and preserve details more effectively in comparison with the traditional DL models, which has potential to improve the image quality of PCCT in clinical applications.
Automatic Image Content Extraction: Operationalizing Machine Learning in Humanistic Photographic Studies of Large Visual Archives
Apr 05, 2022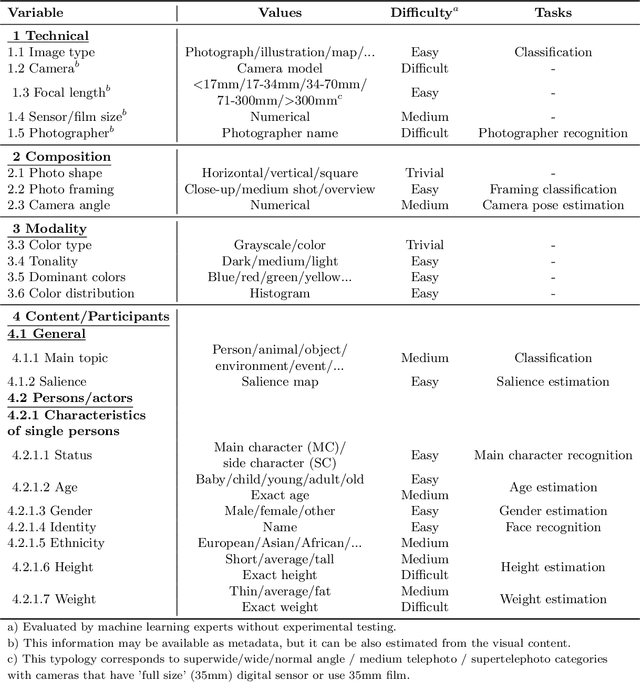
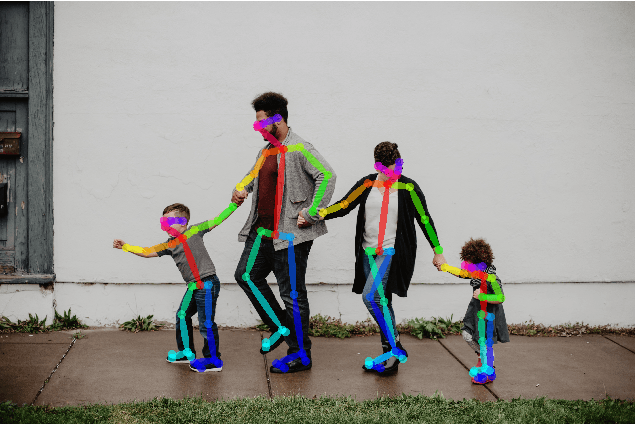
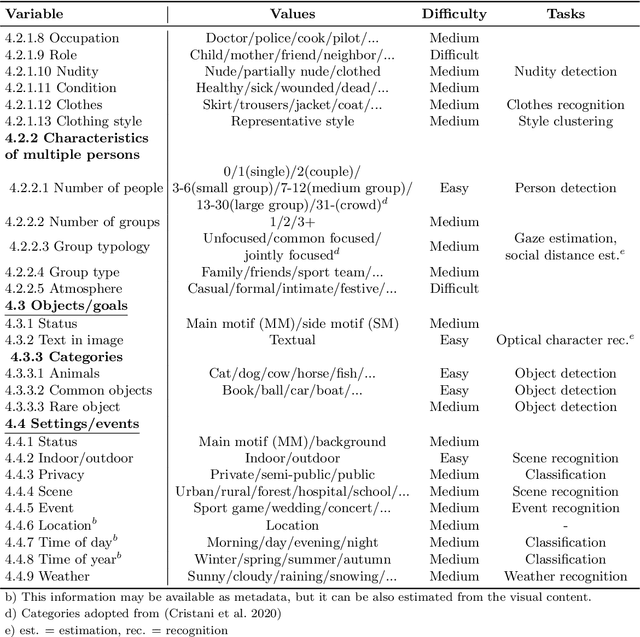

Applying machine learning tools to digitized image archives has a potential to revolutionize quantitative research of visual studies in humanities and social sciences. The ability to process a hundredfold greater number of photos than has been traditionally possible and to analyze them with an extensive set of variables will contribute to deeper insight into the material. Overall, these changes will help to shift the workflow from simple manual tasks to more demanding stages. In this paper, we introduce Automatic Image Content Extraction (AICE) framework for machine learning-based search and analysis of large image archives. We developed the framework in a multidisciplinary research project as framework for future photographic studies by reformulating and expanding the traditional visual content analysis methodologies to be compatible with the current and emerging state-of-the-art machine learning tools and to cover the novel machine learning opportunities for automatic content analysis. The proposed framework can be applied in several domains in humanities and social sciences, and it can be adjusted and scaled into various research settings. We also provide information on the current state of different machine learning techniques and show that there are already various publicly available methods that are suitable to a wide-scale of visual content analysis tasks.
ACT: Semi-supervised Domain-adaptive Medical Image Segmentation with Asymmetric Co-training
Jun 09, 2022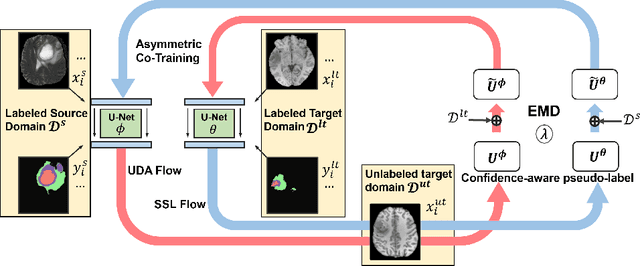
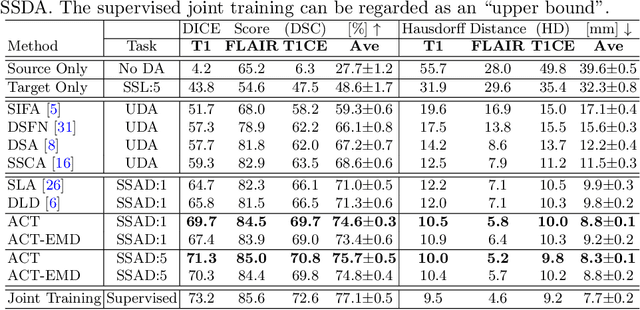
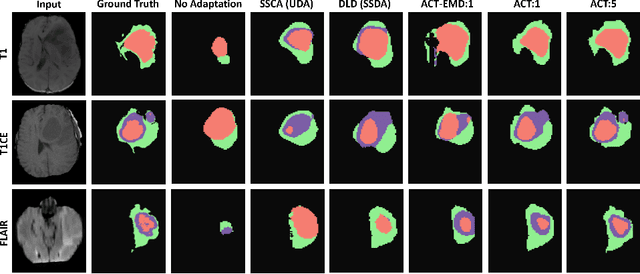
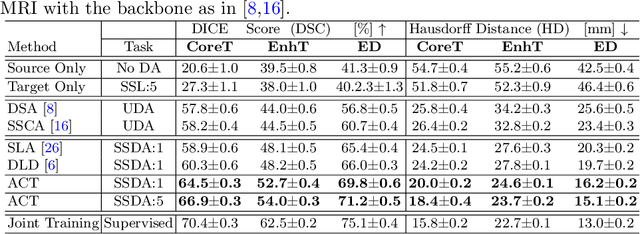
Unsupervised domain adaptation (UDA) has been vastly explored to alleviate domain shifts between source and target domains, by applying a well-performed model in an unlabeled target domain via supervision of a labeled source domain. Recent literature, however, has indicated that the performance is still far from satisfactory in the presence of significant domain shifts. Nonetheless, delineating a few target samples is usually manageable and particularly worthwhile, due to the substantial performance gain. Inspired by this, we aim to develop semi-supervised domain adaptation (SSDA) for medical image segmentation, which is largely underexplored. We, thus, propose to exploit both labeled source and target domain data, in addition to unlabeled target data in a unified manner. Specifically, we present a novel asymmetric co-training (ACT) framework to integrate these subsets and avoid the domination of the source domain data. Following a divide-and-conquer strategy, we explicitly decouple the label supervisions in SSDA into two asymmetric sub-tasks, including semi-supervised learning (SSL) and UDA, and leverage different knowledge from two segmentors to take into account the distinction between the source and target label supervisions. The knowledge learned in the two modules is then adaptively integrated with ACT, by iteratively teaching each other, based on the confidence-aware pseudo-label. In addition, pseudo label noise is well-controlled with an exponential MixUp decay scheme for smooth propagation. Experiments on cross-modality brain tumor MRI segmentation tasks using the BraTS18 database showed, even with limited labeled target samples, ACT yielded marked improvements over UDA and state-of-the-art SSDA methods and approached an "upper bound" of supervised joint training.
MonoDVPS: A Self-Supervised Monocular Depth Estimation Approach to Depth-aware Video Panoptic Segmentation
Oct 14, 2022


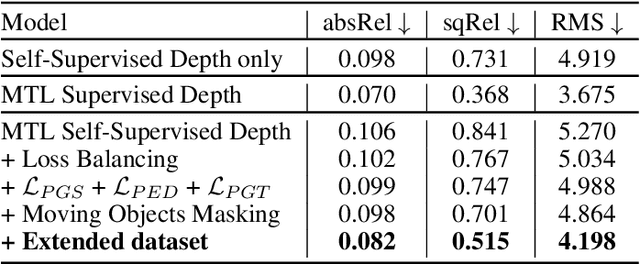
Depth-aware video panoptic segmentation tackles the inverse projection problem of restoring panoptic 3D point clouds from video sequences, where the 3D points are augmented with semantic classes and temporally consistent instance identifiers. We propose a novel solution with a multi-task network that performs monocular depth estimation and video panoptic segmentation. Since acquiring ground truth labels for both depth and image segmentation has a relatively large cost, we leverage the power of unlabeled video sequences with self-supervised monocular depth estimation and semi-supervised learning from pseudo-labels for video panoptic segmentation. To further improve the depth prediction, we introduce panoptic-guided depth losses and a novel panoptic masking scheme for moving objects to avoid corrupting the training signal. Extensive experiments on the Cityscapes-DVPS and SemKITTI-DVPS datasets demonstrate that our model with the proposed improvements achieves competitive results and fast inference speed.
TokenMixup: Efficient Attention-guided Token-level Data Augmentation for Transformers
Oct 14, 2022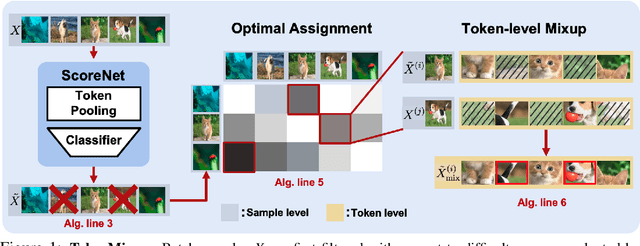
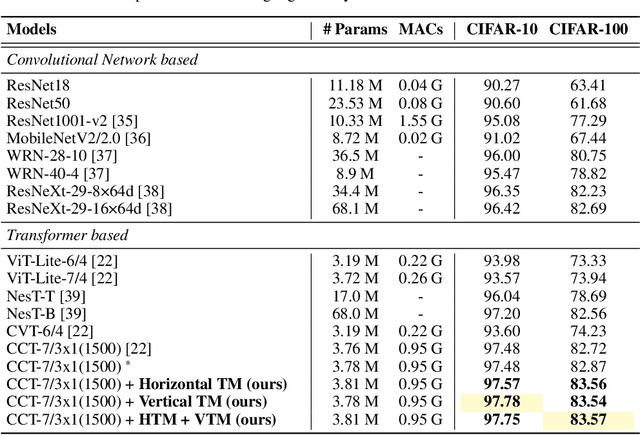
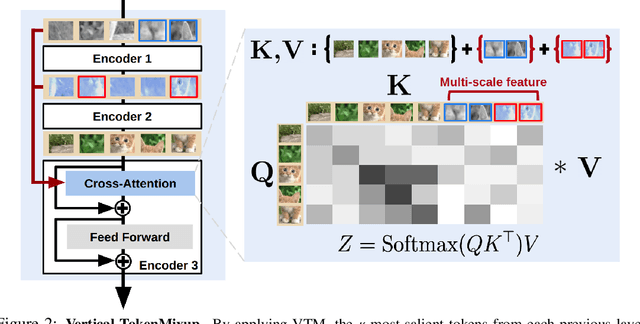
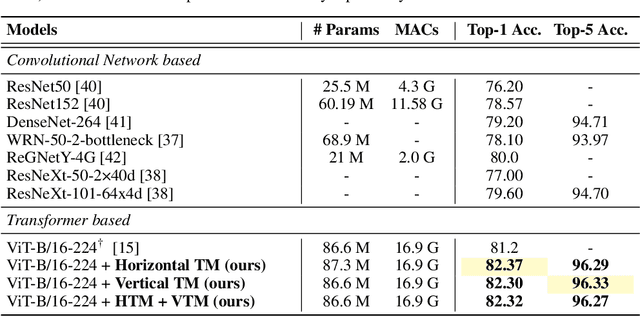
Mixup is a commonly adopted data augmentation technique for image classification. Recent advances in mixup methods primarily focus on mixing based on saliency. However, many saliency detectors require intense computation and are especially burdensome for parameter-heavy transformer models. To this end, we propose TokenMixup, an efficient attention-guided token-level data augmentation method that aims to maximize the saliency of a mixed set of tokens. TokenMixup provides x15 faster saliency-aware data augmentation compared to gradient-based methods. Moreover, we introduce a variant of TokenMixup which mixes tokens within a single instance, thereby enabling multi-scale feature augmentation. Experiments show that our methods significantly improve the baseline models' performance on CIFAR and ImageNet-1K, while being more efficient than previous methods. We also reach state-of-the-art performance on CIFAR-100 among from-scratch transformer models. Code is available at https://github.com/mlvlab/TokenMixup.
How to scale hyperparameters for quickshift image segmentation
Jan 23, 2022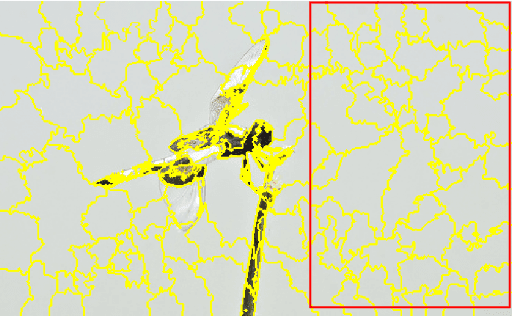

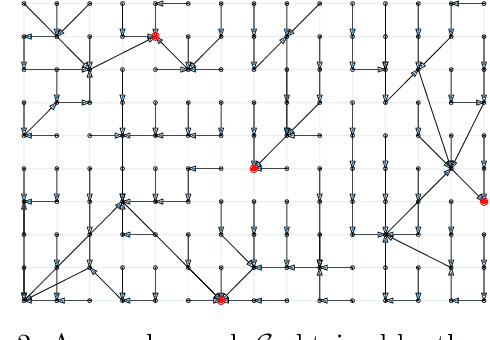
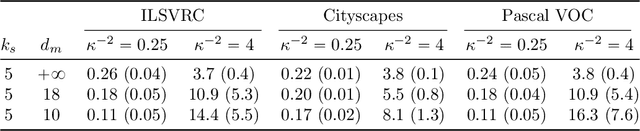
Quickshift is a popular algorithm for image segmentation, used as a preprocessing step in many applications. Unfortunately, it is quite challenging to understand the hyperparameters' influence on the number and shape of superpixels produced by the method. In this paper, we study theoretically a slightly modified version of the quickshift algorithm, with a particular emphasis on homogeneous image patches with i.i.d. pixel noise and sharp boundaries between such patches. Leveraging this analysis, we derive a simple heuristic to scale quickshift hyperparameters when dealing with real images, which we check empirically.
From Play to Policy: Conditional Behavior Generation from Uncurated Robot Data
Oct 19, 2022

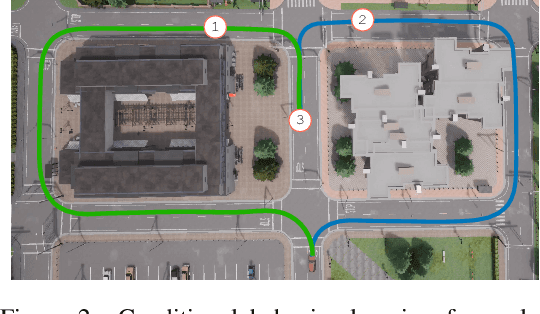

While large-scale sequence modeling from offline data has led to impressive performance gains in natural language and image generation, directly translating such ideas to robotics has been challenging. One critical reason for this is that uncurated robot demonstration data, i.e. play data, collected from non-expert human demonstrators are often noisy, diverse, and distributionally multi-modal. This makes extracting useful, task-centric behaviors from such data a difficult generative modeling problem. In this work, we present Conditional Behavior Transformers (C-BeT), a method that combines the multi-modal generation ability of Behavior Transformer with future-conditioned goal specification. On a suite of simulated benchmark tasks, we find that C-BeT improves upon prior state-of-the-art work in learning from play data by an average of 45.7%. Further, we demonstrate for the first time that useful task-centric behaviors can be learned on a real-world robot purely from play data without any task labels or reward information. Robot videos are best viewed on our project website: https://play-to-policy.github.io
Efficient, probabilistic analysis of combinatorial neural codes
Oct 19, 2022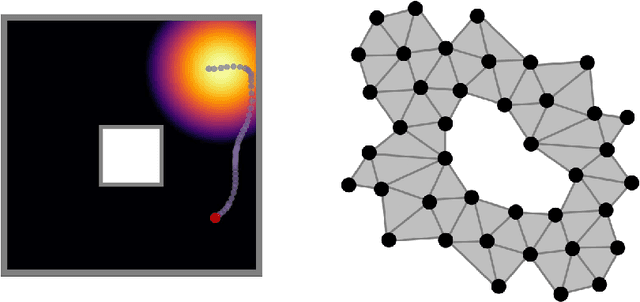
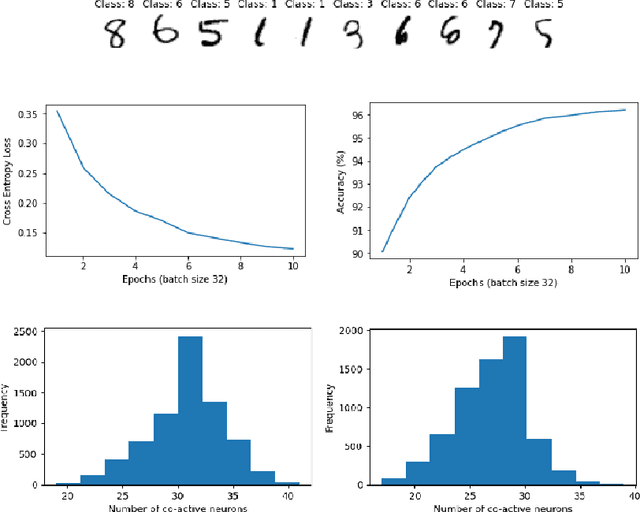

Artificial and biological neural networks (ANNs and BNNs) can encode inputs in the form of combinations of individual neurons' activities. These combinatorial neural codes present a computational challenge for direct and efficient analysis due to their high dimensionality and often large volumes of data. Here we improve the computational complexity -- from factorial to quadratic time -- of direct algebraic methods previously applied to small examples and apply them to large neural codes generated by experiments. These methods provide a novel and efficient way of probing algebraic, geometric, and topological characteristics of combinatorial neural codes and provide insights into how such characteristics are related to learning and experience in neural networks. We introduce a procedure to perform hypothesis testing on the intrinsic features of neural codes using information geometry. We then apply these methods to neural activities from an ANN for image classification and a BNN for 2D navigation to, without observing any inputs or outputs, estimate the structure and dimensionality of the stimulus or task space. Additionally, we demonstrate how an ANN varies its internal representations across network depth and during learning.