 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantification of Pollen Viability in Lantana camara By Digital Holographic Microscopy
Oct 10, 2022
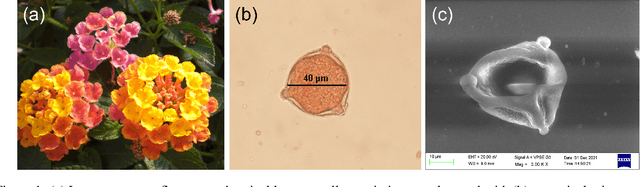

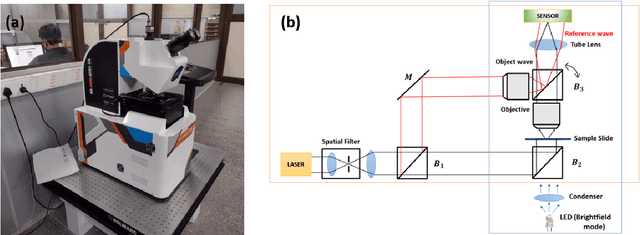
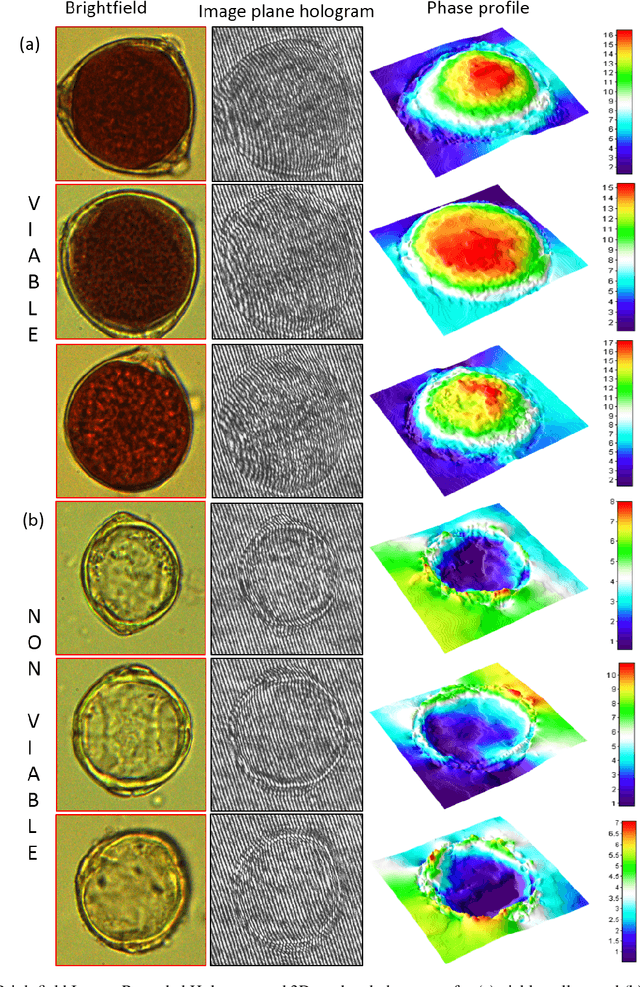
Pollen grains represent the male gametes of seed plants and their viability is critical for efficient sexual reproduction in the plant life cycle. Pollen analysis is used in diverse research thematics to address a range of botanical, ecological and geological questions. More recently it has been recognized that pollen may also be a vector for transgene escape from genetically modified crops, and the importance of pollen viability in invasion biology has also been emphasized. In this work, we analyse and report an efficient visual method for assessing the viability of pollen using digital holographic microscopy (DHM). We test this method on pollen grains of the invasive Lantana camara, a well known plant invader known to most of the tropical world. We image pollen grains and show that the quantitative phase information provided by the DHM technique can be readily related to the chromatin content of the individual cells and thereby to pollen viability. Our results offer a new technique for pollen viability assessment that does not require staining, and can be applied to a number of emerging areas in plant science.
Utilizing supervised models to infer consensus labels and their quality from data with multiple annotators
Oct 13, 2022
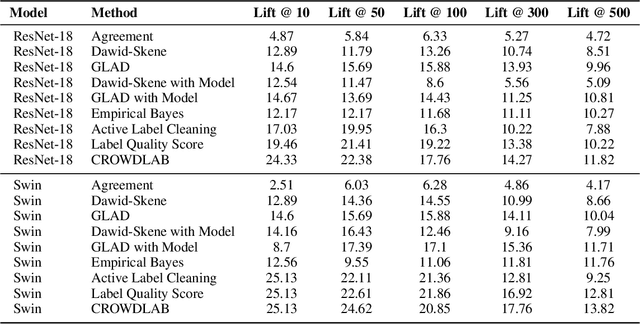
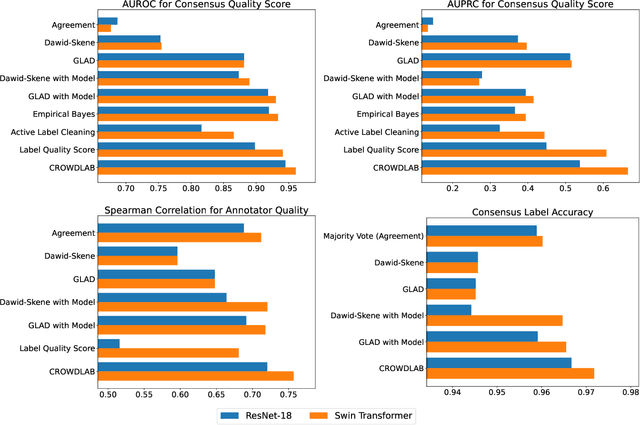
Real-world data for classification is often labeled by multiple annotators. For analyzing such data, we introduce CROWDLAB, a straightforward approach to estimate: (1) A consensus label for each example that aggregates the individual annotations (more accurately than aggregation via majority-vote or other algorithms used in crowdsourcing); (2) A confidence score for how likely each consensus label is correct (via well-calibrated estimates that account for the number of annotations for each example and their agreement, prediction-confidence from a trained classifier, and trustworthiness of each annotator vs. the classifier); (3) A rating for each annotator quantifying the overall correctness of their labels. While many algorithms have been proposed to estimate related quantities in crowdsourcing, these often rely on sophisticated generative models with iterative inference schemes, whereas CROWDLAB is based on simple weighted ensembling. Many algorithms also rely solely on annotator statistics, ignoring the features of the examples from which the annotations derive. CROWDLAB in contrast utilizes any classifier model trained on these features, which can generalize between examples with similar features. In evaluations on real-world multi-annotator image data, our proposed method provides superior estimates for (1)-(3) than many alternative algorithms.
Multiple Convex Objects Image Segmentation via Proximal Alternating Direction Method of Multipliers
Mar 22, 2022
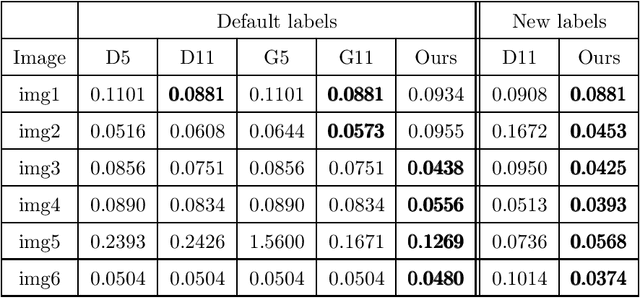

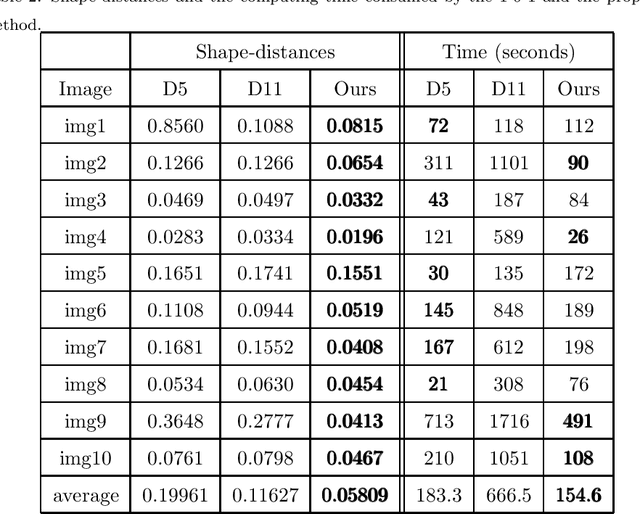
This paper focuses on the issue of image segmentation with convex shape prior. Firstly, we use binary function to represent convex object(s). The convex shape prior turns out to be a simple quadratic inequality constraint on the binary indicator function associated with each object. An image segmentation model incorporating convex shape prior into a probability-based method is proposed. Secondly, a new algorithm is designed to solve involved optimization problem, which is a challenging task because of the quadratic inequality constraint. To tackle this difficulty, we relax and linearize the quadratic inequality constraint to reduce it to solve a sequence of convex minimization problems. For each convex problem, an efficient proximal alternating direction method of multipliers is developed to solve it. The convergence of the algorithm follows some existing results in the optimization literature. Moreover, an interactive procedure is introduced to improve the accuracy of segmentation gradually. Numerical experiments on natural and medical images demonstrate that the proposed method is superior to some existing methods in terms of segmentation accuracy and computational time.
Partitioning Image Representation in Contrastive Learning
Mar 20, 2022
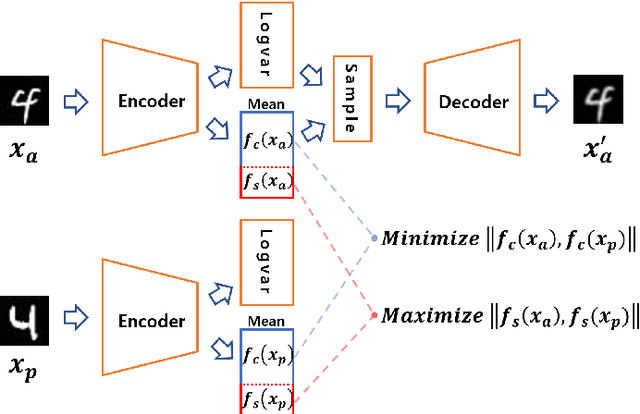
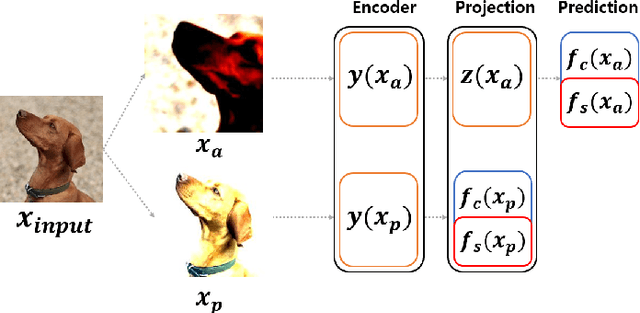
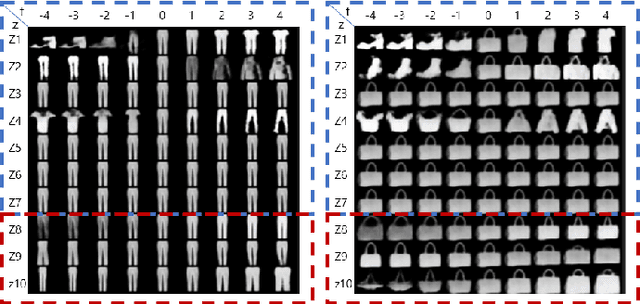
In contrastive learning in the image domain, the anchor and positive samples are forced to have as close representations as possible. However, forcing the two samples to have the same representation could be misleading because the data augmentation techniques make the two samples different. In this paper, we introduce a new representation, partitioned representation, which can learn both common and unique features of the anchor and positive samples in contrastive learning. The partitioned representation consists of two parts: the content part and the style part. The content part represents common features of the class, and the style part represents the own features of each sample, which can lead to the representation of the data augmentation method. We can achieve the partitioned representation simply by decomposing a loss function of contrastive learning into two terms on the two separate representations, respectively. To evaluate our representation with two parts, we take two framework models: Variational AutoEncoder (VAE) and BootstrapYour Own Latent(BYOL) to show the separability of content and style, and to confirm the generalization ability in classification, respectively. Based on the experiments, we show that our approach can separate two types of information in the VAE framework and outperforms the conventional BYOL in linear separability and a few-shot learning task as downstream tasks.
Feature Embedding by Template Matching as a ResNet Block
Oct 03, 2022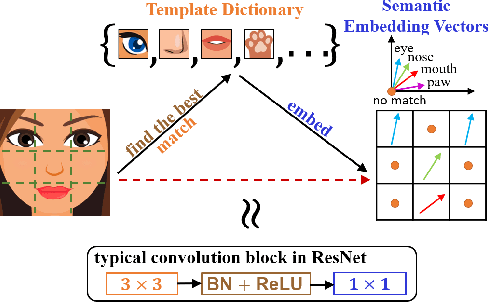
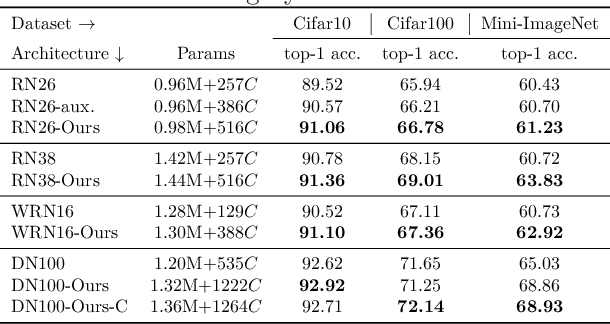
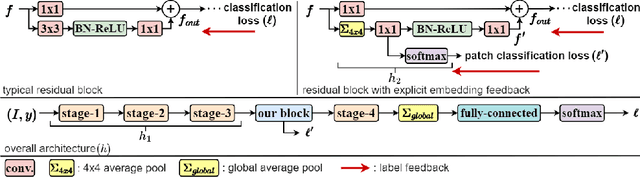
Convolution blocks serve as local feature extractors and are the key to success of the neural networks. To make local semantic feature embedding rather explicit, we reformulate convolution blocks as feature selection according to the best matching kernel. In this manner, we show that typical ResNet blocks indeed perform local feature embedding via template matching once batch normalization (BN) followed by a rectified linear unit (ReLU) is interpreted as arg-max optimizer. Following this perspective, we tailor a residual block that explicitly forces semantically meaningful local feature embedding through using label information. Specifically, we assign a feature vector to each local region according to the classes that the corresponding region matches. We evaluate our method on three popular benchmark datasets with several architectures for image classification and consistently show that our approach substantially improves the performance of the baseline architectures.
Text-to-Audio Grounding Based Novel Metric for Evaluating Audio Caption Similarity
Oct 03, 2022
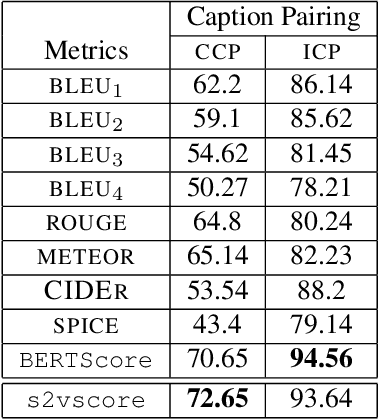
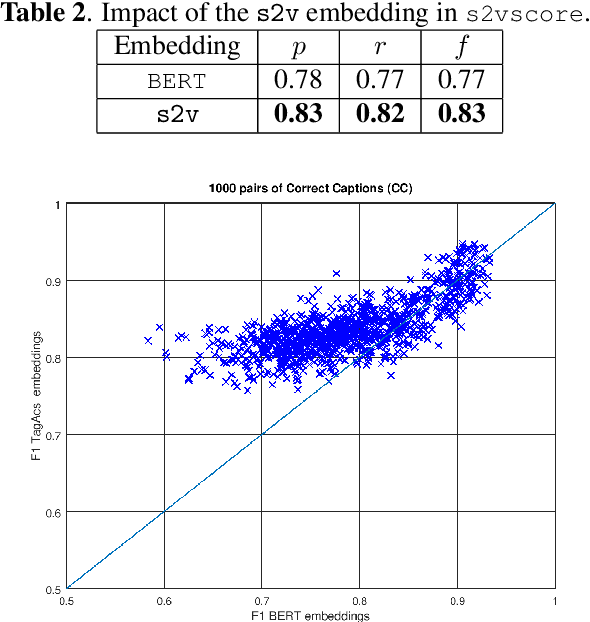
Automatic Audio Captioning (AAC) refers to the task of translating an audio sample into a natural language (NL) text that describes the audio events, source of the events and their relationships. Unlike NL text generation tasks, which rely on metrics like BLEU, ROUGE, METEOR based on lexical semantics for evaluation, the AAC evaluation metric requires an ability to map NL text (phrases) that correspond to similar sounds in addition lexical semantics. Current metrics used for evaluation of AAC tasks lack an understanding of the perceived properties of sound represented by text. In this paper, wepropose a novel metric based on Text-to-Audio Grounding (TAG), which is, useful for evaluating cross modal tasks like AAC. Experiments on publicly available AAC data-set shows our evaluation metric to perform better compared to existing metrics used in NL text and image captioning literature.
Style Transfer of Black and White Silhouette Images using CycleGAN and a Randomly Generated Dataset
Aug 03, 2022



CycleGAN can be used to transfer an artistic style to an image. It does not require pairs of source and stylized images to train a model. Taking this advantage, we propose using randomly generated data to train a machine learning model that can transfer traditional art style to a black and white silhouette image. The result is noticeably better than the previous neural style transfer methods. However, there are some areas for improvement, such as removing artifacts and spikes from the transformed image.
Two-Stream UNET Networks for Semantic Segmentation in Medical Images
Jul 27, 2022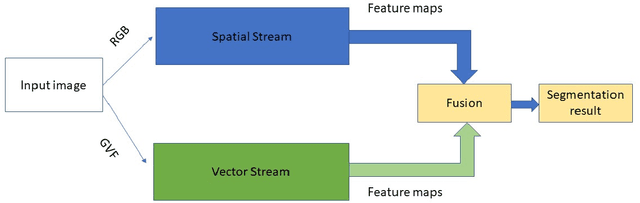

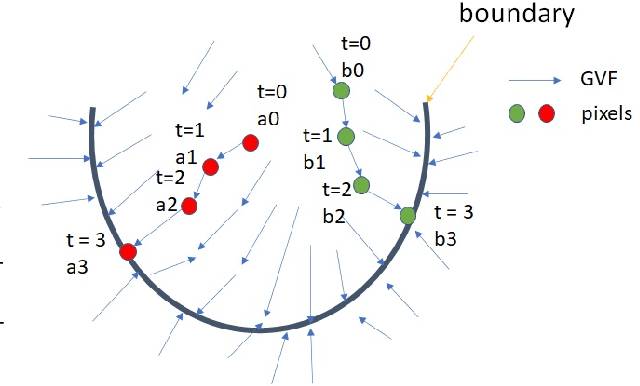
Recent advances of semantic image segmentation greatly benefit from deeper and larger Convolutional Neural Network (CNN) models. Compared to image segmentation in the wild, properties of both medical images themselves and of existing medical datasets hinder training deeper and larger models because of overfitting. To this end, we propose a novel two-stream UNET architecture for automatic end-to-end medical image segmentation, in which intensity value and gradient vector flow (GVF) are two inputs for each stream, respectively. We demonstrate that two-stream CNNs with more low-level features greatly benefit semantic segmentation for imperfect medical image datasets. Our proposed two-stream networks are trained and evaluated on the popular medical image segmentation benchmarks, and the results are competitive with the state of the art. The code will be released soon.
SketchEdit: Mask-Free Local Image Manipulation with Partial Sketches
Nov 30, 2021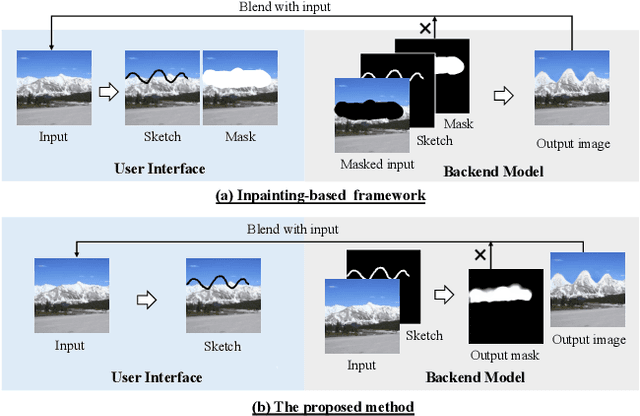
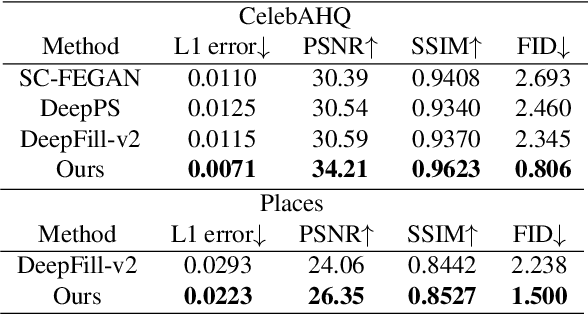
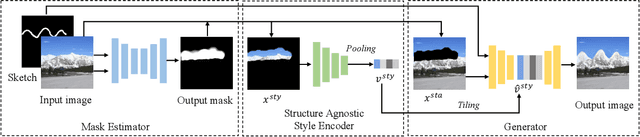
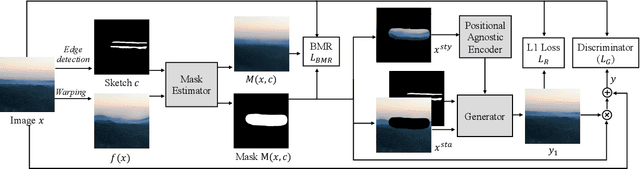
Sketch-based image manipulation is an interactive image editing task to modify an image based on input sketches from users. Existing methods typically formulate this task as a conditional inpainting problem, which requires users to draw an extra mask indicating the region to modify in addition to sketches. The masked regions are regarded as holes and filled by an inpainting model conditioned on the sketch. With this formulation, paired training data can be easily obtained by randomly creating masks and extracting edges or contours. Although this setup simplifies data preparation and model design, it complicates user interaction and discards useful information in masked regions. To this end, we investigate a new paradigm of sketch-based image manipulation: mask-free local image manipulation, which only requires sketch inputs from users and utilizes the entire original image. Given an image and sketch, our model automatically predicts the target modification region and encodes it into a structure agnostic style vector. A generator then synthesizes the new image content based on the style vector and sketch. The manipulated image is finally produced by blending the generator output into the modification region of the original image. Our model can be trained in a self-supervised fashion by learning the reconstruction of an image region from the style vector and sketch. The proposed method offers simpler and more intuitive user workflows for sketch-based image manipulation and provides better results than previous approaches. More results, code and interactive demo will be available at \url{https://zengxianyu.github.io/sketchedit}.
AT-DDPM: Restoring Faces degraded by Atmospheric Turbulence using Denoising Diffusion Probabilistic Models
Aug 24, 2022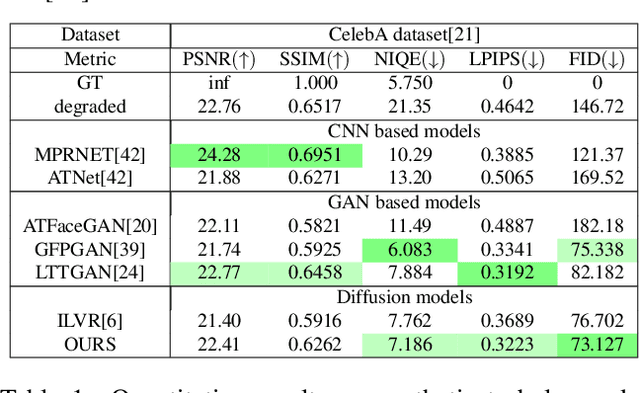
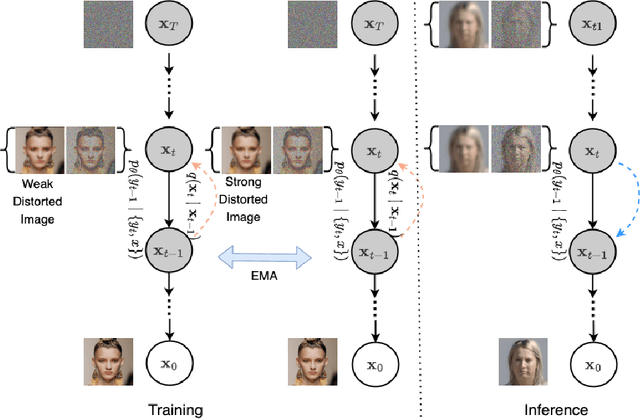
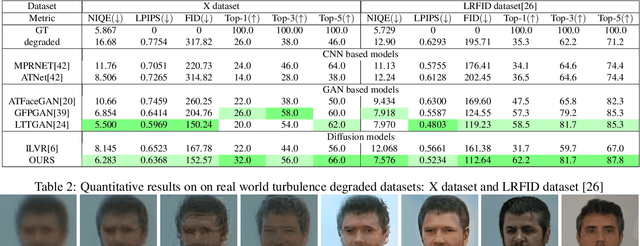

Although many long-range imaging systems are designed to support extended vision applications, a natural obstacle to their operation is degradation due to atmospheric turbulence. Atmospheric turbulence causes significant degradation to image quality by introducing blur and geometric distortion. In recent years, various deep learning-based single image atmospheric turbulence mitigation methods, including CNN-based and GAN inversion-based, have been proposed in the literature which attempt to remove the distortion in the image. However, some of these methods are difficult to train and often fail to reconstruct facial features and produce unrealistic results especially in the case of high turbulence. Denoising Diffusion Probabilistic Models (DDPMs) have recently gained some traction because of their stable training process and their ability to generate high quality images. In this paper, we propose the first DDPM-based solution for the problem of atmospheric turbulence mitigation. We also propose a fast sampling technique for reducing the inference times for conditional DDPMs. Extensive experiments are conducted on synthetic and real-world data to show the significance of our model. To facilitate further research, all codes and pretrained models will be made public after the review process.