 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Classification using Graph Neural Network and Multiscale Wavelet Superpixels
Jan 29, 2022
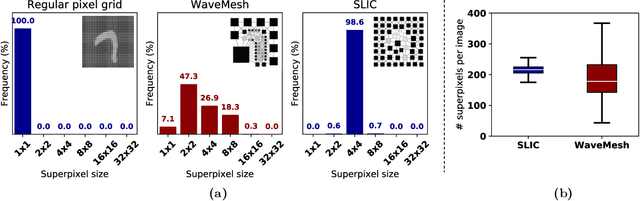
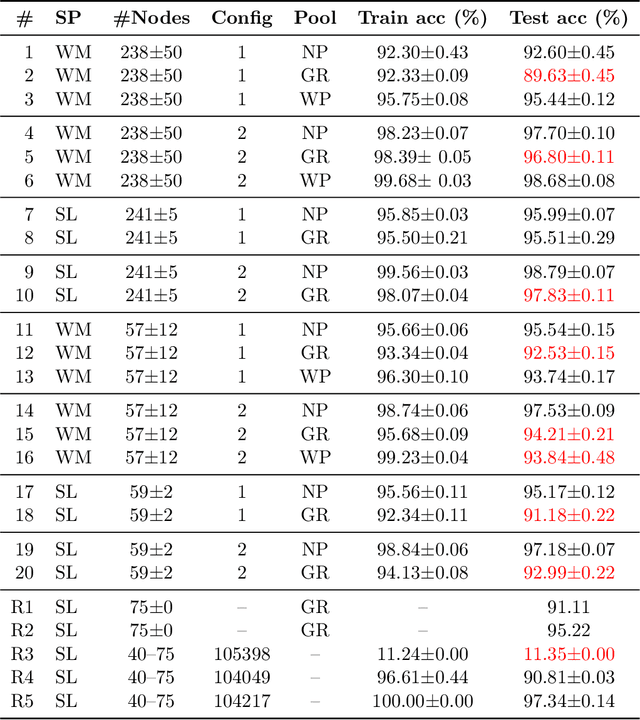

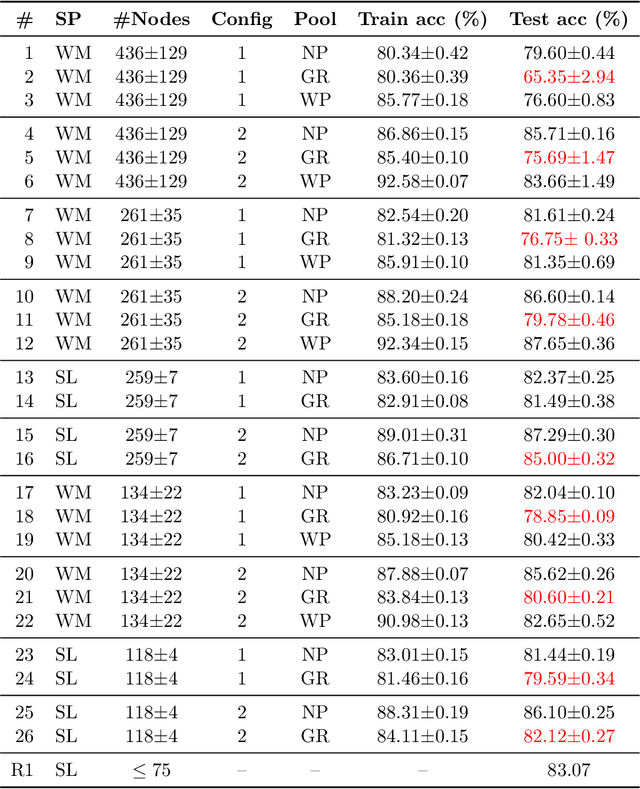
Prior studies using graph neural networks (GNNs) for image classification have focused on graphs generated from a regular grid of pixels or similar-sized superpixels. In the latter, a single target number of superpixels is defined for an entire dataset irrespective of differences across images and their intrinsic multiscale structure. On the contrary, this study investigates image classification using graphs generated from an image-specific number of multiscale superpixels. We propose WaveMesh, a new wavelet-based superpixeling algorithm, where the number and sizes of superpixels in an image are systematically computed based on its content. WaveMesh superpixel graphs are structurally different from similar-sized superpixel graphs. We use SplineCNN, a state-of-the-art network for image graph classification, to compare WaveMesh and similar-sized superpixels. Using SplineCNN, we perform extensive experiments on three benchmark datasets under three local-pooling settings: 1) no pooling, 2) GraclusPool, and 3) WavePool, a novel spatially heterogeneous pooling scheme tailored to WaveMesh superpixels. Our experiments demonstrate that SplineCNN learns from multiscale WaveMesh superpixels on-par with similar-sized superpixels. In all WaveMesh experiments, GraclusPool performs poorer than no pooling / WavePool, indicating that poor choice of pooling can result in inferior performance while learning from multiscale superpixels.
Sparse Video Representation Using Steered Mixture-of-Experts With Global Motion Compensation
Sep 13, 2022


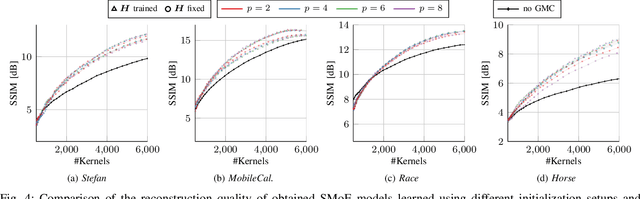
Steered-Mixtures-of Experts (SMoE) present a unified framework for sparse representation and compression of image data with arbitrary dimensionality. Recent work has shown great improvements in the performance of such models for image and light-field representation. However, for the case of videos the straight-forward application yields limited success as the SMoE framework leads to a piece-wise linear representation of the underlying imagery which is disrupted by nonlinear motion. We incorporate a global motion model into the SMoE framework which allows for higher temporal steering of the kernels. This drastically increases its capabilities to exploit correlations between adjacent frames by only adding 2 to 8 motion parameters per frame to the model but decreasing the required amount of kernels on average by 54.25%, respectively, while maintaining the same reconstruction quality yielding higher compression gains.
Unsupervised segmentation of biomedical hyperspectral image data: tackling high dimensionality with convolutional autoencoders
Sep 09, 2022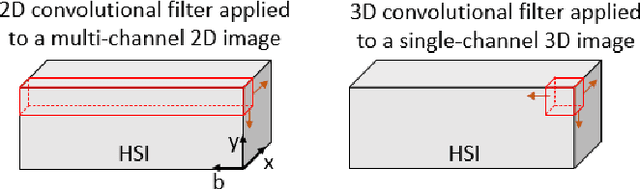
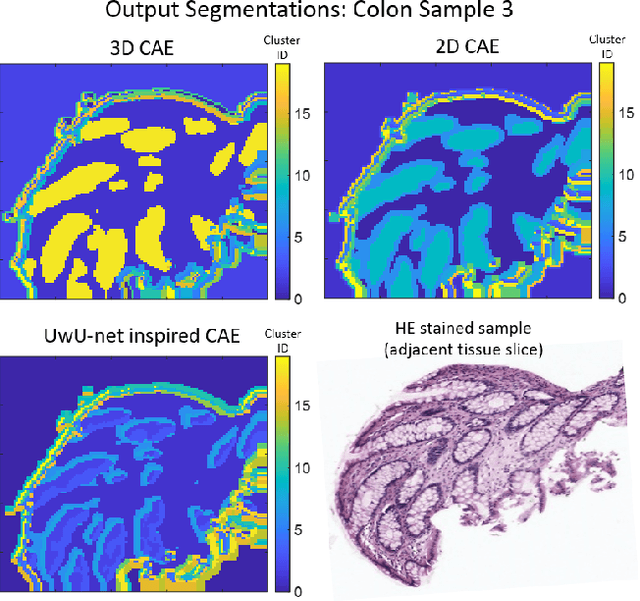
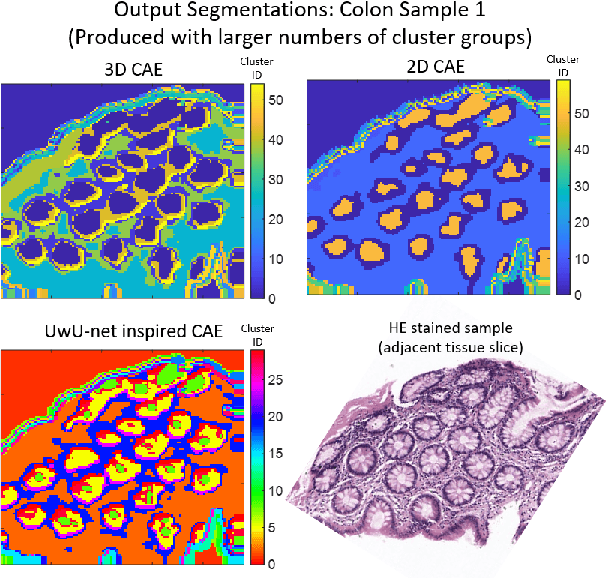
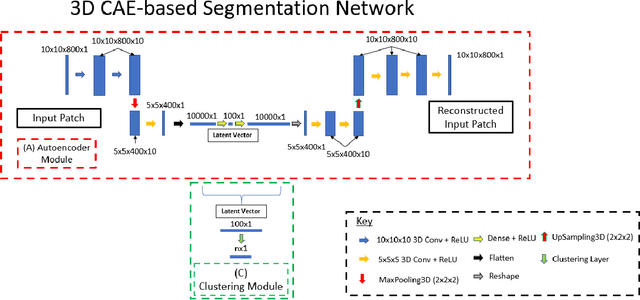
Information about the structure and composition of biopsy specimens can assist in disease monitoring and diagnosis. In principle, this can be acquired from Raman and infrared (IR) hyperspectral images (HSIs) that encode information about how a sample's constituent molecules are arranged in space. Each tissue section/component is defined by a unique combination of spatial and spectral features, but given the high dimensionality of HSI datasets, extracting and utilising them to segment images is non-trivial. Here, we show how networks based on deep convolutional autoencoders (CAEs) can perform this task in an end-to-end fashion by first detecting and compressing relevant features from patches of the HSI into low-dimensional latent vectors, and then performing a clustering step that groups patches containing similar spatio-spectral features together. We showcase the advantages of using this end-to-end spatio-spectral segmentation approach compared to i) the same spatio-spectral technique not trained in an end-to-end manner, and ii) a method that only utilises spectral features (spectral k-means) using simulated HSIs of porcine tissue as test examples. Secondly, we describe the potential advantages/limitations of using three different CAE architectures: a generic 2D CAE, a generic 3D CAE, and a 2D CNN architecture inspired by the recently proposed UwU-net that is specialised for extracting features from HSI data. We assess their performance on IR HSIs of real colon samples. We find that all architectures are capable of producing segmentations that show good correspondence with HE stained adjacent tissue slices used as approximate ground truths, indicating the robustness of the CAE-driven approach for segmenting biomedical HSI data. Additionally, we stress the need for more accurate ground truth information to rigorously compare the advantages offered by each architecture.
MoRSE: Deep Learning-based Arm Gesture Recognition for Search and Rescue Operations
Oct 15, 2022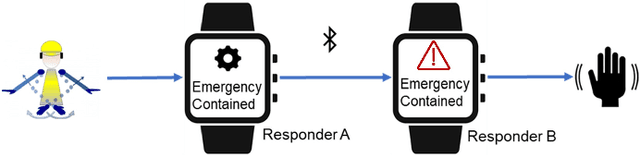
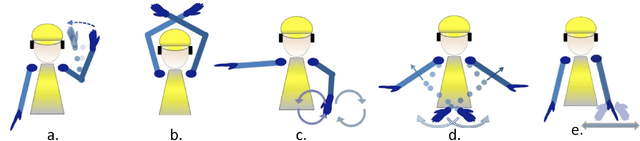
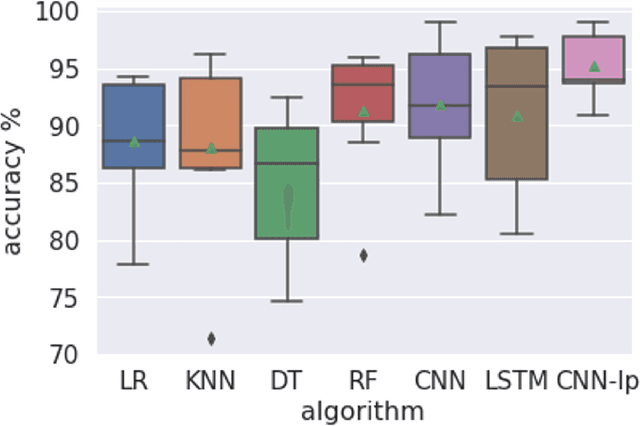
Efficient and quick remote communication in search and rescue operations can be life-saving for the first responders. However, while operating on the field means of communication based on text, image and audio are not suitable for several disaster scenarios. In this paper, we present a smartwatch-based application, which utilizes a Deep Learning (DL) model, to recognize a set of predefined arm gestures, maps them into Morse code via vibrations enabling remote communication amongst first responders. The model performance was evaluated by training it using 4,200 gestures performed by 7 subjects (cross-validation) wearing a smartwatch on their dominant arm. Our DL model relies on convolutional pooling and surpasses the performance of existing DL approaches and common machine learning classifiers, obtaining gesture recognition accuracy above 95%. We conclude by discussing the results and providing future directions.
Holistic Attention-Fusion Adversarial Network for Single Image Defogging
Feb 19, 2022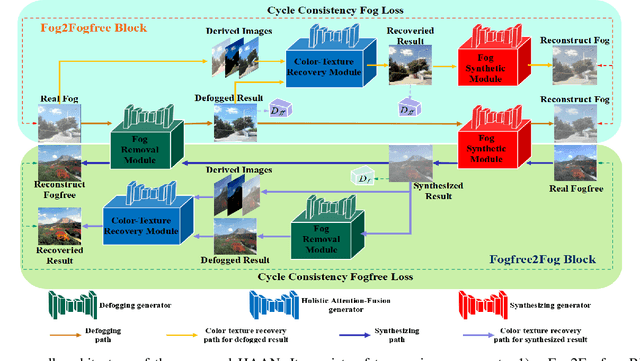



Adversarial learning-based image defogging methods have been extensively studied in computer vision due to their remarkable performance. However, most existing methods have limited defogging capabilities for real cases because they are trained on the paired clear and synthesized foggy images of the same scenes. In addition, they have limitations in preserving vivid color and rich textual details in defogging. To address these issues, we develop a novel generative adversarial network, called holistic attention-fusion adversarial network (HAAN), for single image defogging. HAAN consists of a Fog2Fogfree block and a Fogfree2Fog block. In each block, there are three learning-based modules, namely, fog removal, color-texture recovery, and fog synthetic, that are constrained each other to generate high quality images. HAAN is designed to exploit the self-similarity of texture and structure information by learning the holistic channel-spatial feature correlations between the foggy image with its several derived images. Moreover, in the fog synthetic module, we utilize the atmospheric scattering model to guide it to improve the generative quality by focusing on an atmospheric light optimization with a novel sky segmentation network. Extensive experiments on both synthetic and real-world datasets show that HAAN outperforms state-of-the-art defogging methods in terms of quantitative accuracy and subjective visual quality.
Saliency Constrained Arbitrary Image Style Transfer using SIFT and DCNN
Jan 14, 2022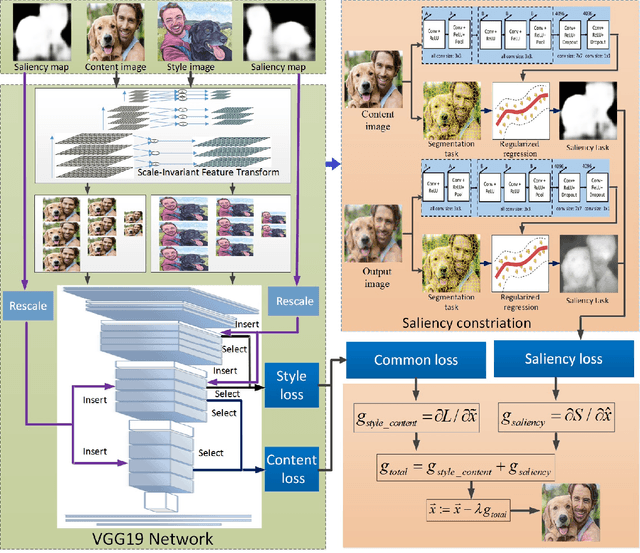
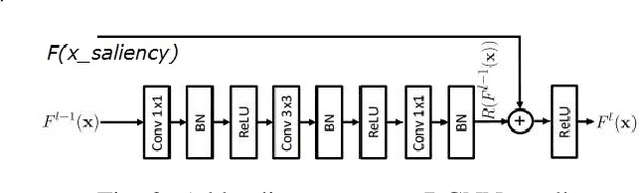

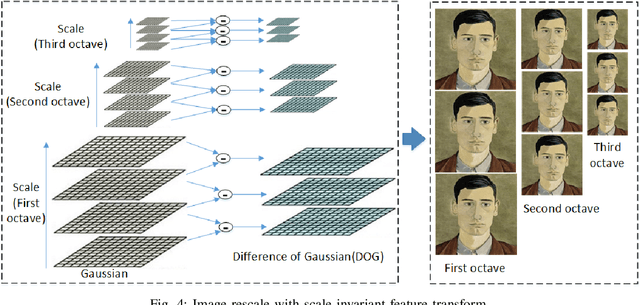
This paper develops a new image synthesis approach to transfer an example image (style image) to other images (content images) by using Deep Convolutional Neural Networks (DCNN) model. When common neural style transfer methods are used, the textures and colors in the style image are usually transferred imperfectly to the content image, or some visible errors are generated. This paper proposes a novel saliency constrained method to reduce or avoid such effects. It first evaluates some existing saliency detection methods to select the most suitable one for use in our method. The selected saliency detection method is used to detect the object in the style image, corresponding to the object of the content image with the same saliency. In addition, aim to solve the problem that the size or resolution is different in the style image and content, the scale-invariant feature transform is used to generate a series of style images and content images which can be used to generate more feature maps for patches matching. It then proposes a new loss function combining the saliency loss, style loss and content loss, adding gradient of saliency constraint into style transfer in iterations. Finally the source images and saliency detection results are utilized as multichannel input to an improved deep CNN framework for style transfer. The experiments show that the saliency maps of source images can help find the correct matching and avoid artifacts. Experimental results on different kind of images demonstrate that our method outperforms nine representative methods from recent publications and has good robustness.
TransFuse: A Unified Transformer-based Image Fusion Framework using Self-supervised Learning
Jan 19, 2022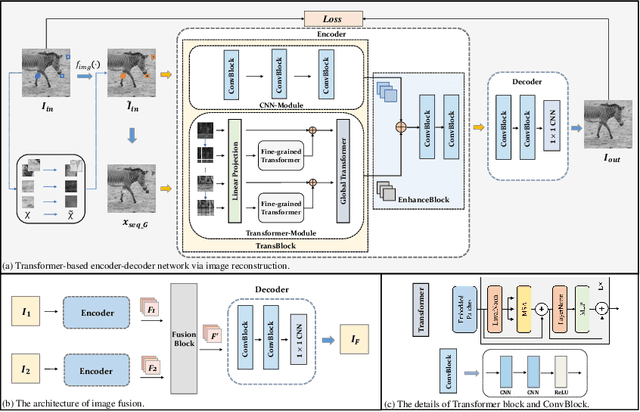
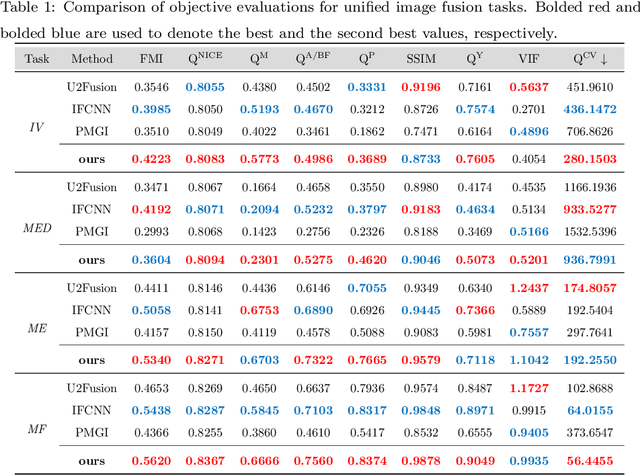
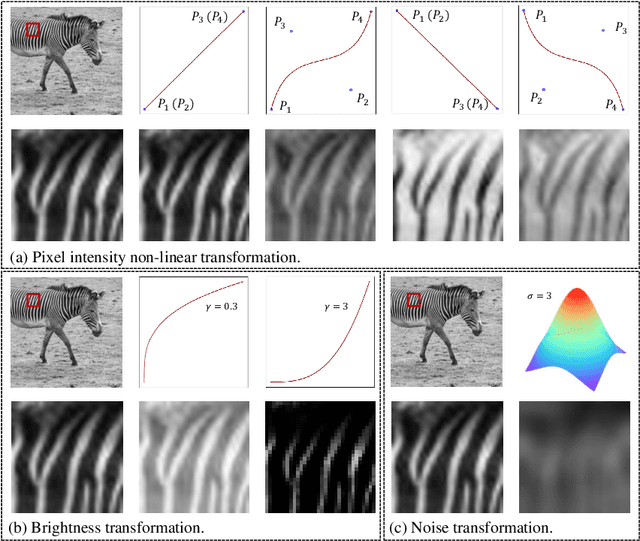
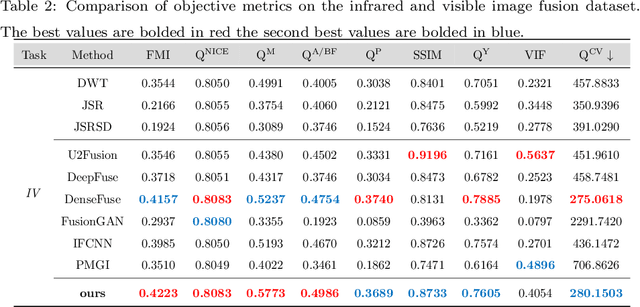
Image fusion is a technique to integrate information from multiple source images with complementary information to improve the richness of a single image. Due to insufficient task-specific training data and corresponding ground truth, most existing end-to-end image fusion methods easily fall into overfitting or tedious parameter optimization processes. Two-stage methods avoid the need of large amount of task-specific training data by training encoder-decoder network on large natural image datasets and utilizing the extracted features for fusion, but the domain gap between natural images and different fusion tasks results in limited performance. In this study, we design a novel encoder-decoder based image fusion framework and propose a destruction-reconstruction based self-supervised training scheme to encourage the network to learn task-specific features. Specifically, we propose three destruction-reconstruction self-supervised auxiliary tasks for multi-modal image fusion, multi-exposure image fusion and multi-focus image fusion based on pixel intensity non-linear transformation, brightness transformation and noise transformation, respectively. In order to encourage different fusion tasks to promote each other and increase the generalizability of the trained network, we integrate the three self-supervised auxiliary tasks by randomly choosing one of them to destroy a natural image in model training. In addition, we design a new encoder that combines CNN and Transformer for feature extraction, so that the trained model can exploit both local and global information. Extensive experiments on multi-modal image fusion, multi-exposure image fusion and multi-focus image fusion tasks demonstrate that our proposed method achieves the state-of-the-art performance in both subjective and objective evaluations. The code will be publicly available soon.
medigan: A Python Library of Pretrained Generative Models for Enriched Data Access in Medical Imaging
Sep 28, 2022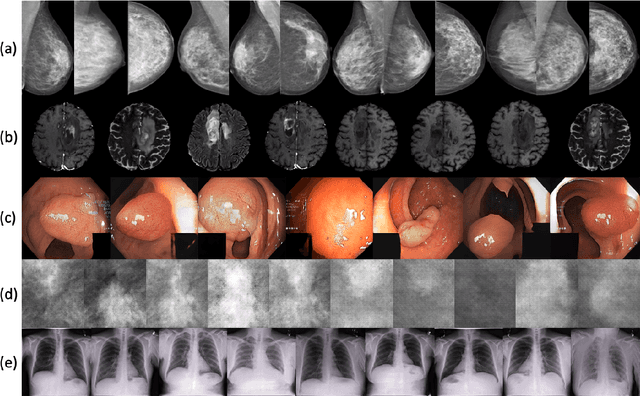
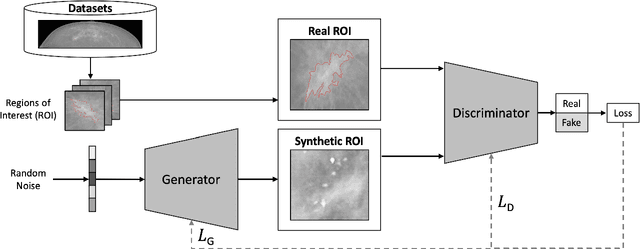
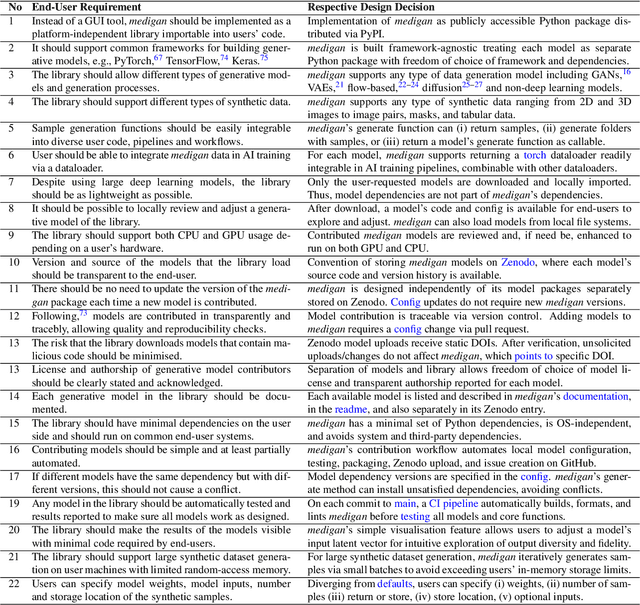
Synthetic data generated by generative models can enhance the performance and capabilities of data-hungry deep learning models in medical imaging. However, there is (1) limited availability of (synthetic) datasets and (2) generative models are complex to train, which hinders their adoption in research and clinical applications. To reduce this entry barrier, we propose medigan, a one-stop shop for pretrained generative models implemented as an open-source framework-agnostic Python library. medigan allows researchers and developers to create, increase, and domain-adapt their training data in just a few lines of code. Guided by design decisions based on gathered end-user requirements, we implement medigan based on modular components for generative model (i) execution, (ii) visualisation, (iii) search & ranking, and (iv) contribution. The library's scalability and design is demonstrated by its growing number of integrated and readily-usable pretrained generative models consisting of 21 models utilising 9 different Generative Adversarial Network architectures trained on 11 datasets from 4 domains, namely, mammography, endoscopy, x-ray, and MRI. Furthermore, 3 applications of medigan are analysed in this work, which include (a) enabling community-wide sharing of restricted data, (b) investigating generative model evaluation metrics, and (c) improving clinical downstream tasks. In (b), extending on common medical image synthesis assessment and reporting standards, we show Fr\'echet Inception Distance variability based on image normalisation and radiology-specific feature extraction.
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 07, 2022



Image-Test matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
Self-Supervised Pyramid Representation Learning for Multi-Label Visual Analysis and Beyond
Aug 30, 2022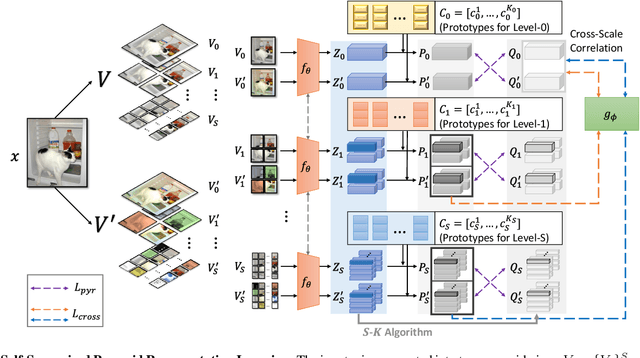
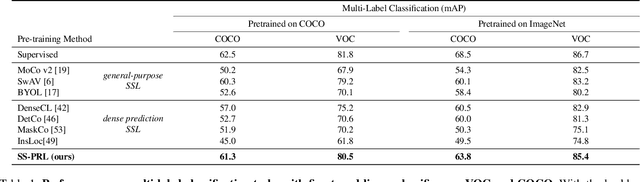
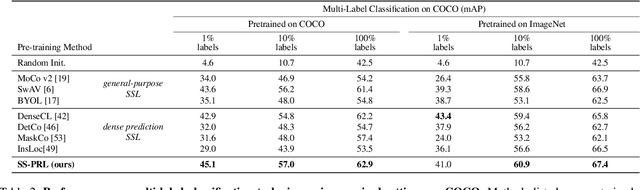
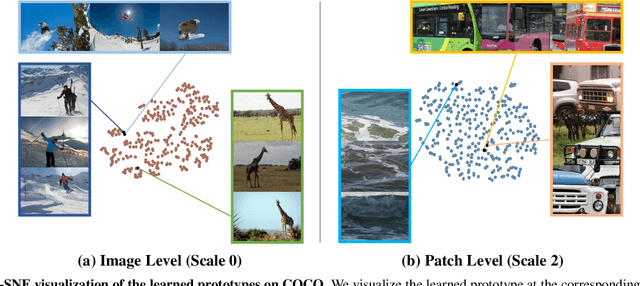
While self-supervised learning has been shown to benefit a number of vision tasks, existing techniques mainly focus on image-level manipulation, which may not generalize well to downstream tasks at patch or pixel levels. Moreover, existing SSL methods might not sufficiently describe and associate the above representations within and across image scales. In this paper, we propose a Self-Supervised Pyramid Representation Learning (SS-PRL) framework. The proposed SS-PRL is designed to derive pyramid representations at patch levels via learning proper prototypes, with additional learners to observe and relate inherent semantic information within an image. In particular, we present a cross-scale patch-level correlation learning in SS-PRL, which allows the model to aggregate and associate information learned across patch scales. We show that, with our proposed SS-PRL for model pre-training, one can easily adapt and fine-tune the models for a variety of applications including multi-label classification, object detection, and instance segmentation.