 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Max Pooling with Vision Transformers reconciles class and shape in weakly supervised semantic segmentation
Oct 31, 2022
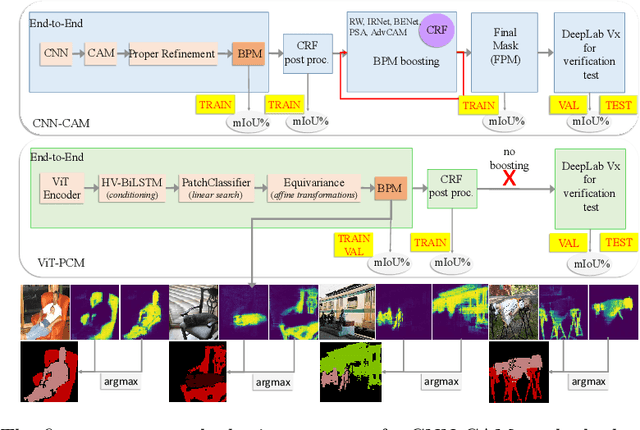
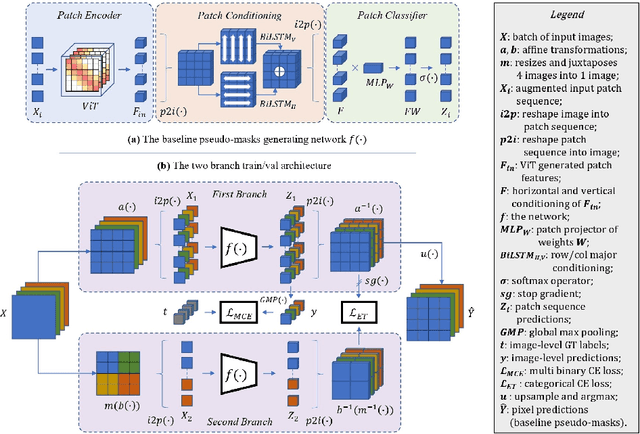
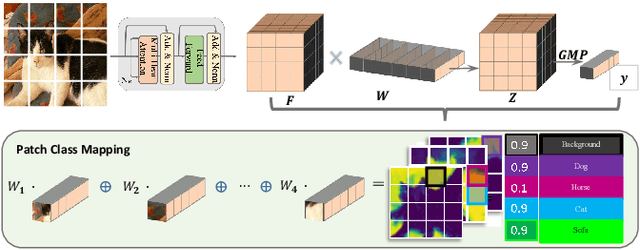
Weakly Supervised Semantic Segmentation (WSSS) research has explored many directions to improve the typical pipeline CNN plus class activation maps (CAM) plus refinements, given the image-class label as the only supervision. Though the gap with the fully supervised methods is reduced, further abating the spread seems unlikely within this framework. On the other hand, WSSS methods based on Vision Transformers (ViT) have not yet explored valid alternatives to CAM. ViT features have been shown to retain a scene layout, and object boundaries in self-supervised learning. To confirm these findings, we prove that the advantages of transformers in self-supervised methods are further strengthened by Global Max Pooling (GMP), which can leverage patch features to negotiate pixel-label probability with class probability. This work proposes a new WSSS method dubbed ViT-PCM (ViT Patch-Class Mapping), not based on CAM. The end-to-end presented network learns with a single optimization process, refined shape and proper localization for segmentation masks. Our model outperforms the state-of-the-art on baseline pseudo-masks (BPM), where we achieve $69.3\%$ mIoU on PascalVOC 2012 $val$ set. We show that our approach has the least set of parameters, though obtaining higher accuracy than all other approaches. In a sentence, quantitative and qualitative results of our method reveal that ViT-PCM is an excellent alternative to CNN-CAM based architectures.
Evaluating a GAN for enhancing camera simulation for robotics
Sep 14, 2022
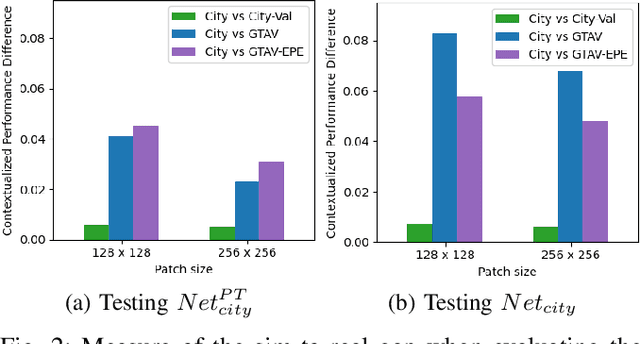
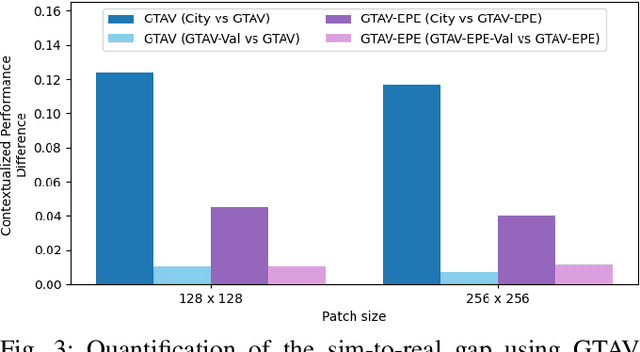

Given the versatility of generative adversarial networks (GANs), we seek to understand the benefits gained from using an existing GAN to enhance simulated images and reduce the sim-to-real gap. We conduct an analysis in the context of simulating robot performance and image-based perception. Specifically, we quantify the GAN's ability to reduce the sim-to-real difference in image perception in robotics. Using semantic segmentation, we analyze the sim-to-real difference in training and testing, using nominal and enhanced simulation of a city environment. As a secondary application, we consider use of the GAN in enhancing an indoor environment. For this application, object detection is used to analyze the enhancement in training and testing. The results presented quantify the reduction in the sim-to-real gap when using the GAN, and illustrate the benefits of its use.
Convolutional Neural Networks: Basic Concepts and Applications in Manufacturing
Oct 14, 2022

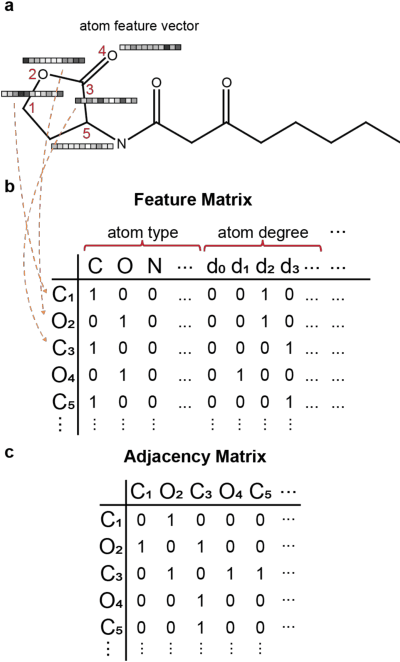
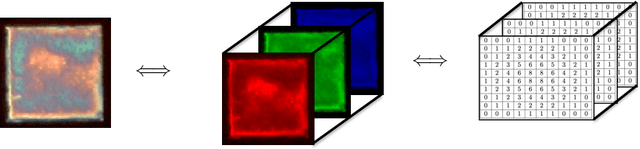
We discuss basic concepts of convolutional neural networks (CNNs) and outline uses in manufacturing. We begin by discussing how different types of data objects commonly encountered in manufacturing (e.g., time series, images, micrographs, videos, spectra, molecular structures) can be represented in a flexible manner using tensors and graphs. We then discuss how CNNs use convolution operations to extract informative features (e.g., geometric patterns and textures) from the such representations to predict emergent properties and phenomena and/or to identify anomalies. We also discuss how CNNs can exploit color as a key source of information, which enables the use of modern computer vision hardware (e.g., infrared, thermal, and hyperspectral cameras). We illustrate the concepts using diverse case studies arising in spectral analysis, molecule design, sensor design, image-based control, and multivariate process monitoring.
On the Relationship Between Variational Inference and Auto-Associative Memory
Oct 14, 2022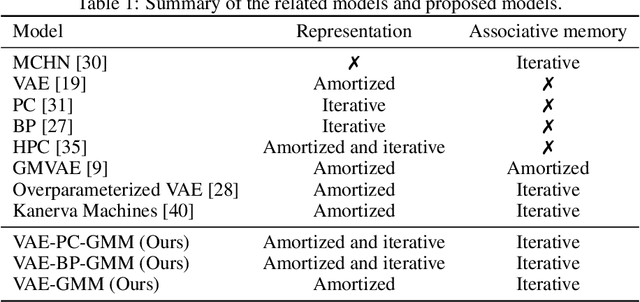
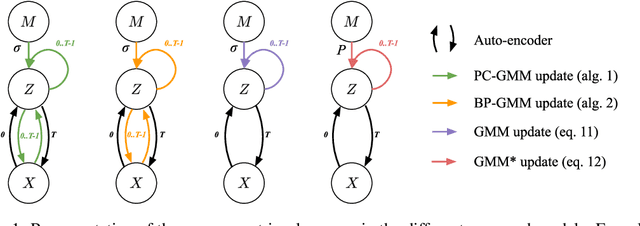

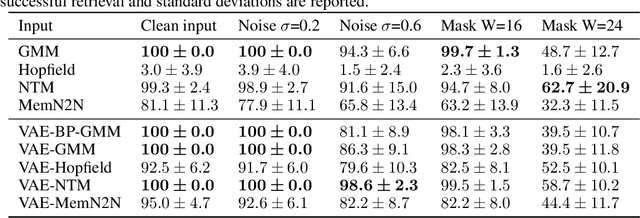
In this article, we propose a variational inference formulation of auto-associative memories, allowing us to combine perceptual inference and memory retrieval into the same mathematical framework. In this formulation, the prior probability distribution onto latent representations is made memory dependent, thus pulling the inference process towards previously stored representations. We then study how different neural network approaches to variational inference can be applied in this framework. We compare methods relying on amortized inference such as Variational Auto Encoders and methods relying on iterative inference such as Predictive Coding and suggest combining both approaches to design new auto-associative memory models. We evaluate the obtained algorithms on the CIFAR10 and CLEVR image datasets and compare them with other associative memory models such as Hopfield Networks, End-to-End Memory Networks and Neural Turing Machines.
LatentGaze: Cross-Domain Gaze Estimation through Gaze-Aware Analytic Latent Code Manipulation
Sep 21, 2022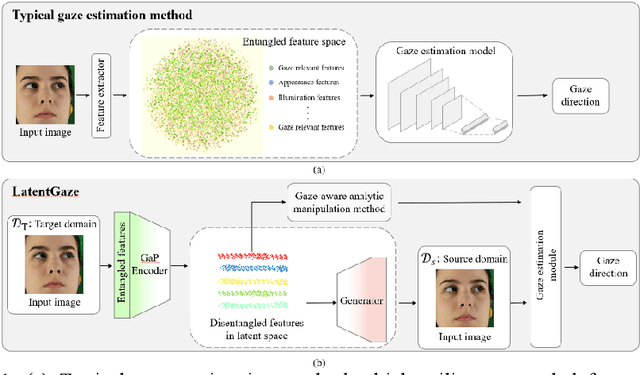
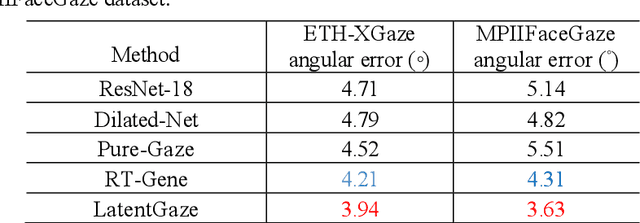
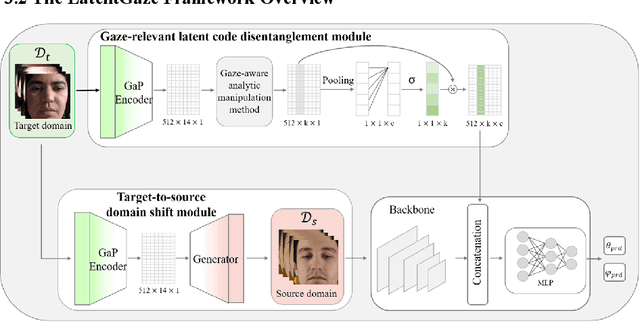
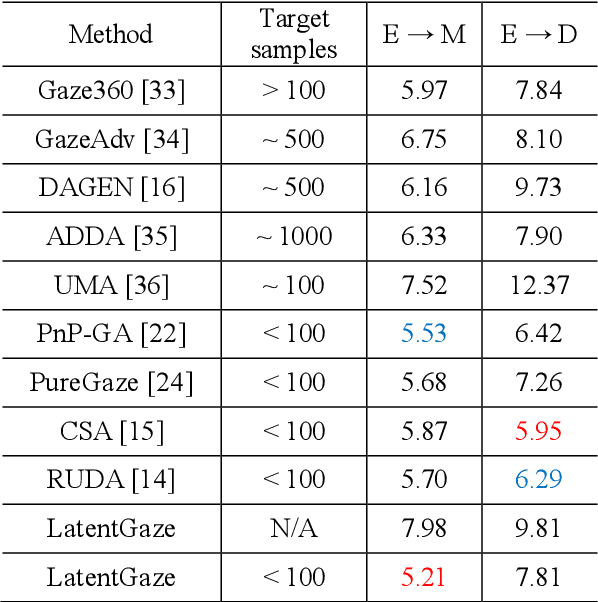
Although recent gaze estimation methods lay great emphasis on attentively extracting gaze-relevant features from facial or eye images, how to define features that include gaze-relevant components has been ambiguous. This obscurity makes the model learn not only gaze-relevant features but also irrelevant ones. In particular, it is fatal for the cross-dataset performance. To overcome this challenging issue, we propose a gaze-aware analytic manipulation method, based on a data-driven approach with generative adversarial network inversion's disentanglement characteristics, to selectively utilize gaze-relevant features in a latent code. Furthermore, by utilizing GAN-based encoder-generator process, we shift the input image from the target domain to the source domain image, which a gaze estimator is sufficiently aware. In addition, we propose gaze distortion loss in the encoder that prevents the distortion of gaze information. The experimental results demonstrate that our method achieves state-of-the-art gaze estimation accuracy in a cross-domain gaze estimation tasks. This code is available at https://github.com/leeisack/LatentGaze/.
MIPI 2022 Challenge on RGBW Sensor Fusion: Dataset and Report
Sep 27, 2022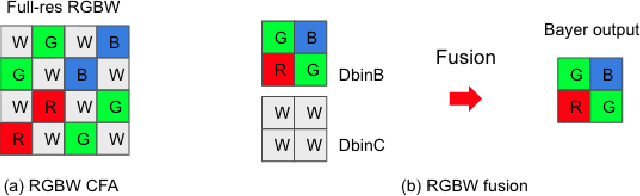
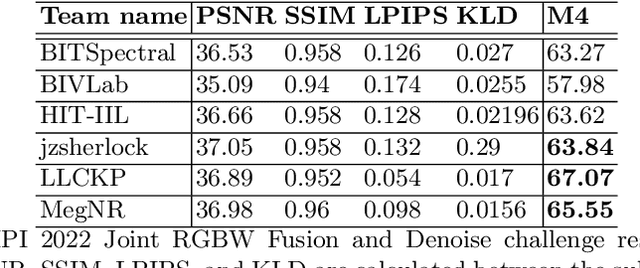


Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge, including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Fusion and Denoise, one of the five tracks, working on the fusion of binning-mode RGBW to Bayer, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 24dB and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics, including PSNR, SSIM}, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
TartanCalib: Iterative Wide-Angle Lens Calibration using Adaptive SubPixel Refinement of AprilTags
Oct 05, 2022
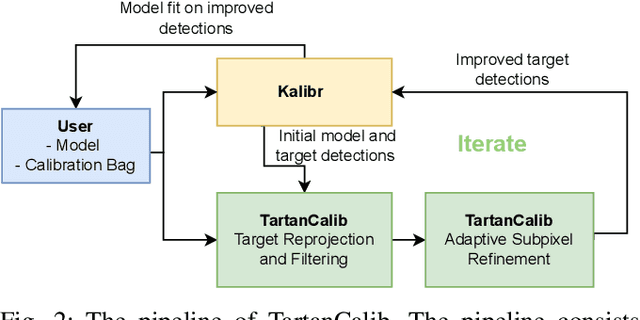

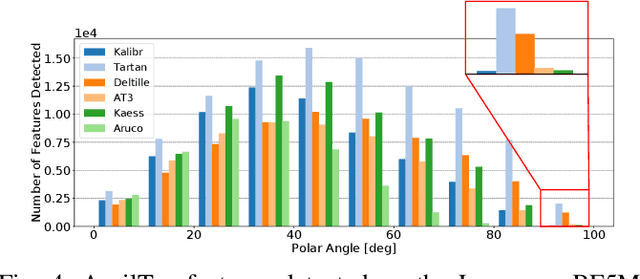
Wide-angle cameras are uniquely positioned for mobile robots, by virtue of the rich information they provide in a small, light, and cost-effective form factor. An accurate calibration of the intrinsics and extrinsics is a critical pre-requisite for using the edge of a wide-angle lens for depth perception and odometry. Calibrating wide-angle lenses with current state-of-the-art techniques yields poor results due to extreme distortion at the edge, as most algorithms assume a lens with low to medium distortion closer to a pinhole projection. In this work we present our methodology for accurate wide-angle calibration. Our pipeline generates an intermediate model, and leverages it to iteratively improve feature detection and eventually the camera parameters. We test three key methods to utilize intermediate camera models: (1) undistorting the image into virtual pinhole cameras, (2) reprojecting the target into the image frame, and (3) adaptive subpixel refinement. Combining adaptive subpixel refinement and feature reprojection significantly improves reprojection errors by up to 26.59 %, helps us detect up to 42.01 % more features, and improves performance in the downstream task of dense depth mapping. Finally, TartanCalib is open-source and implemented into an easy-to-use calibration toolbox. We also provide a translation layer with other state-of-the-art works, which allows for regressing generic models with thousands of parameters or using a more robust solver. To this end, TartanCalib is the tool of choice for wide-angle calibration. Project website and code: http://tartancalib.com.
Affection: Learning Affective Explanations for Real-World Visual Data
Oct 04, 2022
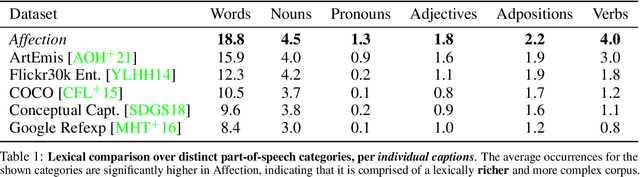
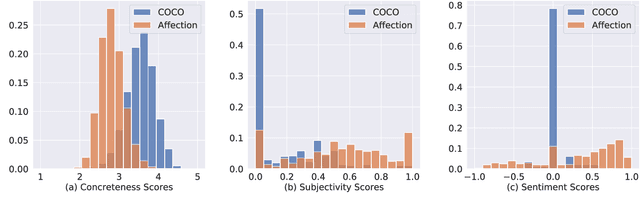
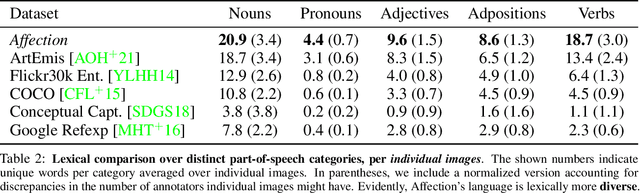
In this work, we explore the emotional reactions that real-world images tend to induce by using natural language as the medium to express the rationale behind an affective response to a given visual stimulus. To embark on this journey, we introduce and share with the research community a large-scale dataset that contains emotional reactions and free-form textual explanations for 85,007 publicly available images, analyzed by 6,283 annotators who were asked to indicate and explain how and why they felt in a particular way when observing a specific image, producing a total of 526,749 responses. Even though emotional reactions are subjective and sensitive to context (personal mood, social status, past experiences) - we show that there is significant common ground to capture potentially plausible emotional responses with a large support in the subject population. In light of this crucial observation, we ask the following questions: i) Can we develop multi-modal neural networks that provide reasonable affective responses to real-world visual data, explained with language? ii) Can we steer such methods towards producing explanations with varying degrees of pragmatic language or justifying different emotional reactions while adapting to the underlying visual stimulus? Finally, iii) How can we evaluate the performance of such methods for this novel task? With this work, we take the first steps in addressing all of these questions, thus paving the way for richer, more human-centric, and emotionally-aware image analysis systems. Our introduced dataset and all developed methods are available on https://affective-explanations.org
Vec2Face-v2: Unveil Human Faces from their Blackbox Features via Attention-based Network in Face Recognition
Sep 11, 2022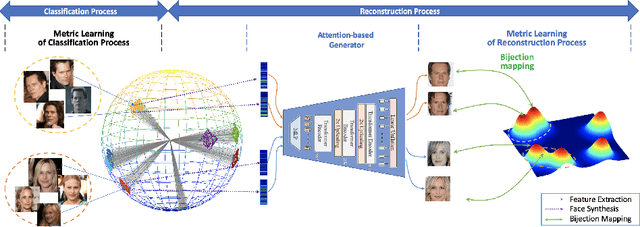

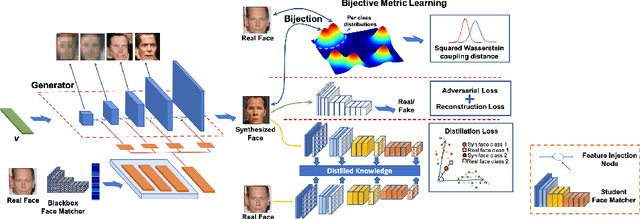
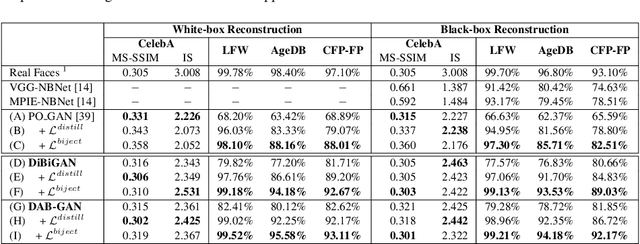
In this work, we investigate the problem of face reconstruction given a facial feature representation extracted from a blackbox face recognition engine. Indeed, it is very challenging problem in practice due to the limitations of abstracted information from the engine. We therefore introduce a new method named Attention-based Bijective Generative Adversarial Networks in a Distillation framework (DAB-GAN) to synthesize faces of a subject given his/her extracted face recognition features. Given any unconstrained unseen facial features of a subject, the DAB-GAN can reconstruct his/her faces in high definition. The DAB-GAN method includes a novel attention-based generative structure with the new defined Bijective Metrics Learning approach. The framework starts by introducing a bijective metric so that the distance measurement and metric learning process can be directly adopted in image domain for an image reconstruction task. The information from the blackbox face recognition engine will be optimally exploited using the global distillation process. Then an attention-based generator is presented for a highly robust generator to synthesize realistic faces with ID preservation. We have evaluated our method on the challenging face recognition databases, i.e. CelebA, LFW, AgeDB, CFP-FP, and consistently achieved the state-of-the-art results. The advancement of DAB-GAN is also proven on both image realism and ID preservation properties.
Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
Mar 21, 2022
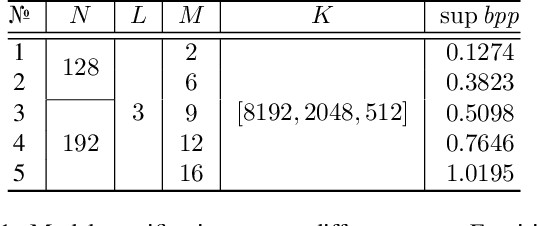
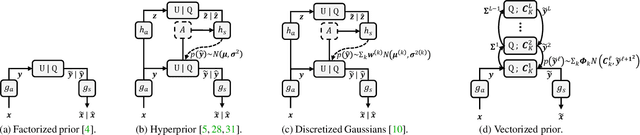
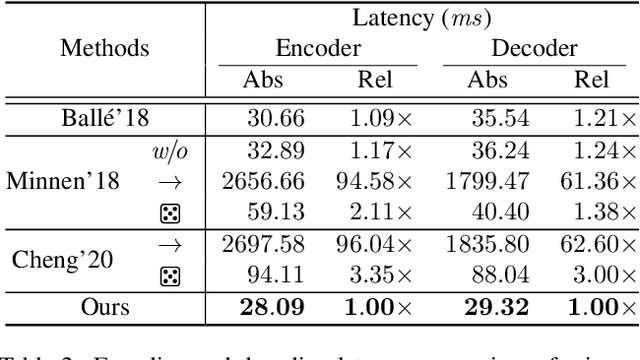
Modeling latent variables with priors and hyperpriors is an essential problem in variational image compression. Formally, trade-off between rate and distortion is handled well if priors and hyperpriors precisely describe latent variables. Current practices only adopt univariate priors and process each variable individually. However, we find inter-correlations and intra-correlations exist when observing latent variables in a vectorized perspective. These findings reveal visual redundancies to improve rate-distortion performance and parallel processing ability to speed up compression. This encourages us to propose a novel vectorized prior. Specifically, a multivariate Gaussian mixture is proposed with means and covariances to be estimated. Then, a novel probabilistic vector quantization is utilized to effectively approximate means, and remaining covariances are further induced to a unified mixture and solved by cascaded estimation without context models involved. Furthermore, codebooks involved in quantization are extended to multi-codebooks for complexity reduction, which formulates an efficient compression procedure. Extensive experiments on benchmark datasets against state-of-the-art indicate our model has better rate-distortion performance and an impressive $3.18\times$ compression speed up, giving us the ability to perform real-time, high-quality variational image compression in practice. Our source code is publicly available at \url{https://github.com/xiaosu-zhu/McQuic}.
* Accepted to CVPR 2022