 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering
Mar 10, 2024
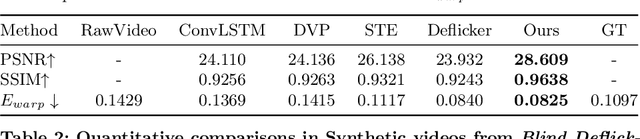

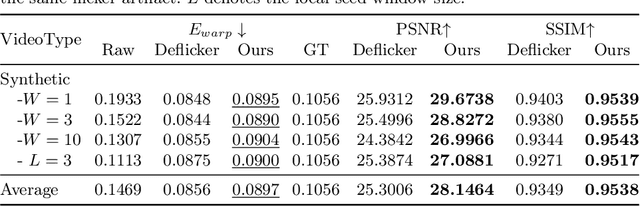
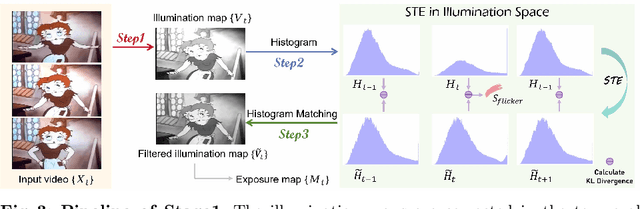
Developing blind video deflickering (BVD) algorithms to enhance video temporal consistency, is gaining importance amid the flourish of image processing and video generation. However, the intricate nature of video data complicates the training of deep learning methods, leading to high resource consumption and instability, notably under severe lighting flicker. This underscores the critical need for a compact representation beyond pixel values to advance BVD research and applications. Inspired by the classic scale-time equalization (STE), our work introduces the histogram-assisted solution, called BlazeBVD, for high-fidelity and rapid BVD. Compared with STE, which directly corrects pixel values by temporally smoothing color histograms, BlazeBVD leverages smoothed illumination histograms within STE filtering to ease the challenge of learning temporal data using neural networks. In technique, BlazeBVD begins by condensing pixel values into illumination histograms that precisely capture flickering and local exposure variations. These histograms are then smoothed to produce singular frames set, filtered illumination maps, and exposure maps. Resorting to these deflickering priors, BlazeBVD utilizes a 2D network to restore faithful and consistent texture impacted by lighting changes or localized exposure issues. BlazeBVD also incorporates a lightweight 3D network to amend slight temporal inconsistencies, avoiding the resource consumption issue. Comprehensive experiments on synthetic, real-world and generated videos, showcase the superior qualitative and quantitative results of BlazeBVD, achieving inference speeds up to 10x faster than state-of-the-arts.
Low-Frequency Black-Box Backdoor Attack via Evolutionary Algorithm
Mar 06, 2024While convolutional neural networks (CNNs) have achieved success in computer vision tasks, it is vulnerable to backdoor attacks. Such attacks could mislead the victim model to make attacker-chosen prediction with a specific trigger pattern. Until now, the trigger injection of existing attacks is mainly limited to spatial domain. Recent works take advantage of perceptual properties of planting specific patterns in the frequency domain, which only reflect indistinguishable pixel-wise perturbations in pixel domain. However, in the black-box setup, the inaccessibility of training process often renders more complex trigger designs. Existing frequency attacks simply handcraft the magnitude of spectrum, introducing anomaly frequency disparities between clean and poisoned data and taking risks of being removed by image processing operations (such as lossy compression and filtering). In this paper, we propose a robust low-frequency black-box backdoor attack (LFBA), which minimally perturbs low-frequency components of frequency spectrum and maintains the perceptual similarity in spatial space simultaneously. The key insight of our attack restrict the search for the optimal trigger to low-frequency region that can achieve high attack effectiveness, robustness against image transformation defenses and stealthiness in dual space. We utilize simulated annealing (SA), a form of evolutionary algorithm, to optimize the properties of frequency trigger including the number of manipulated frequency bands and the perturbation of each frequency component, without relying on the knowledge from the victim classifier. Extensive experiments on real-world datasets verify the effectiveness and robustness of LFBA against image processing operations and the state-of-the-art backdoor defenses, as well as its inherent stealthiness in both spatial and frequency space, making it resilient against frequency inspection.
ACC-ViT : Atrous Convolution's Comeback in Vision Transformers
Mar 07, 2024
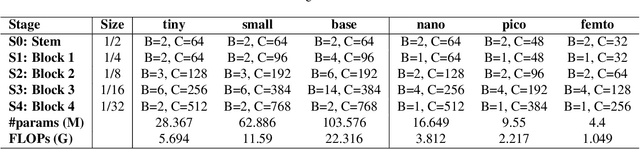
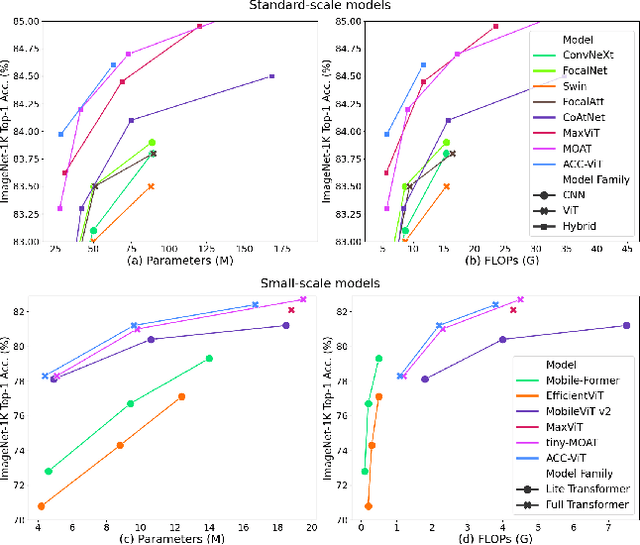
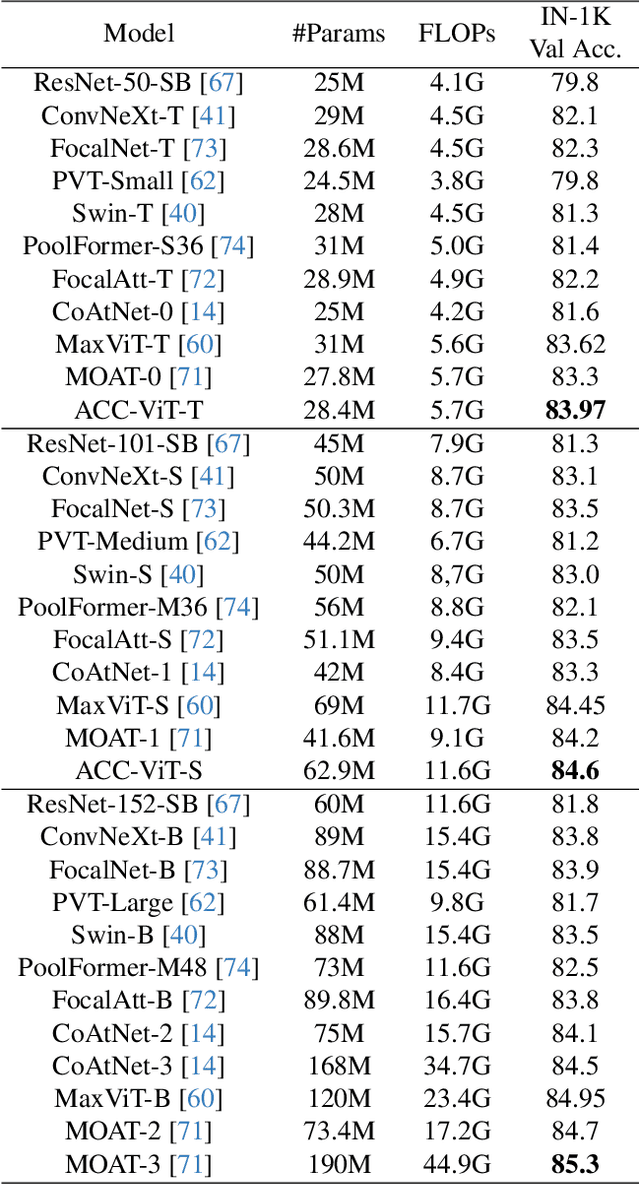
Transformers have elevated to the state-of-the-art vision architectures through innovations in attention mechanism inspired from visual perception. At present two classes of attentions prevail in vision transformers, regional and sparse attention. The former bounds the pixel interactions within a region; the latter spreads them across sparse grids. The opposing natures of them have resulted in a dilemma between either preserving hierarchical relation or attaining a global context. In this work, taking inspiration from atrous convolution, we introduce Atrous Attention, a fusion of regional and sparse attention, which can adaptively consolidate both local and global information, while maintaining hierarchical relations. As a further tribute to atrous convolution, we redesign the ubiquitous inverted residual convolution blocks with atrous convolution. Finally, we propose a generalized, hybrid vision transformer backbone, named ACC-ViT, following conventional practices for standard vision tasks. Our tiny version model achieves $\sim 84 \%$ accuracy on ImageNet-1K, with less than $28.5$ million parameters, which is $0.42\%$ improvement over state-of-the-art MaxViT while having $8.4\%$ less parameters. In addition, we have investigated the efficacy of ACC-ViT backbone under different evaluation settings, such as finetuning, linear probing, and zero-shot learning on tasks involving medical image analysis, object detection, and language-image contrastive learning. ACC-ViT is therefore a strong vision backbone, which is also competitive in mobile-scale versions, ideal for niche applications with small datasets.
Object-level Geometric Structure Preserving for Natural Image Stitching
Feb 20, 2024The topic of stitching images with globally natural structures holds paramount significance. Current methodologies exhibit the ability to preserve local geometric structures, yet fall short in maintaining relationships between these geometric structures. In this paper, we endeavor to safeguard the overall, OBJect-level structures within images based on Global Similarity Prior, while concurrently mitigating distortion and ghosting artifacts with OBJ-GSP. Our approach leverages the Segment Anything Model to extract geometric structures with semantic information, enhancing the algorithm's ability to preserve objects in a manner that aligns more intuitively with human perception. We seek to identify spatial constraints that govern the relationships between various geometric boundaries. Recognizing that multiple geometric boundaries collectively define complete objects, we employ triangular meshes to safeguard not only individual geometric structures but also the overall shapes of objects within the images. Empirical evaluations across multiple image stitching datasets demonstrate that our method establishes a new state-of-the-art benchmark in image stitching. Our implementation and dataset is publicly available at https://github.com/RussRobin/OBJ-GSP .
D4C glove-train: solving the RPM and Bongard-logo problem by distributing and Circumscribing concepts
Mar 09, 2024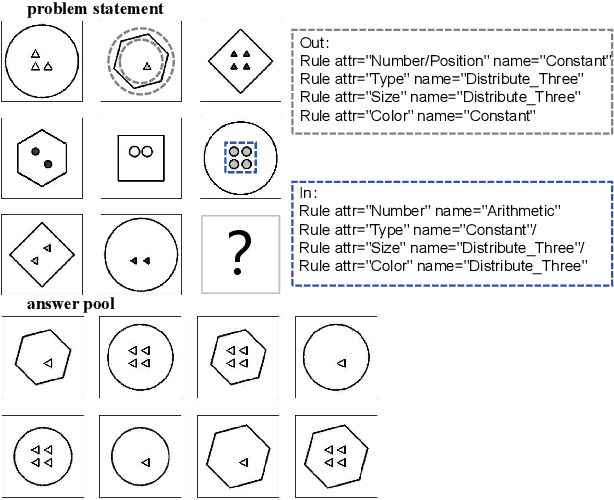
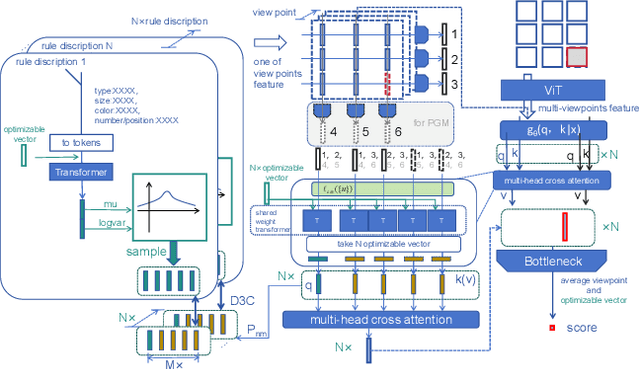
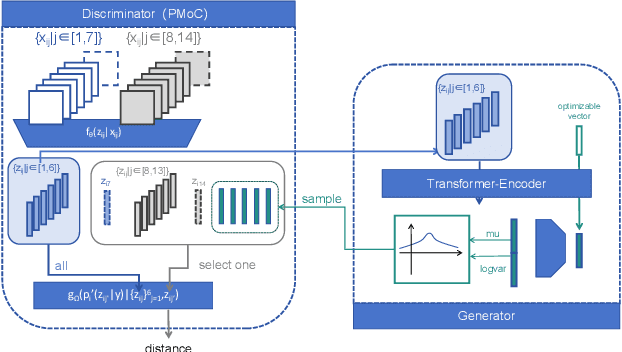
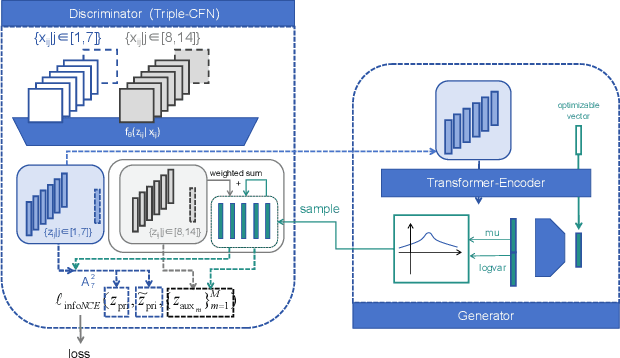
This paper achieves significant progress in the field of abstract reasoning, particularly in addressing Raven's Progressive Matrices (RPM) and Bongard-Logo problems. We propose the D2C approach, which redefines conceptual boundaries in these domains and bridges the gap between high-level concepts and their low-dimensional representations. Based on this, we further introduce the D3C method that handles Bongard-Logo problems and significantly improves reasoning accuracy by estimating the distribution of image representations and measuring their Sinkhorn distance. To enhance computational efficiency, we introduce the D3C-cos variant, which provides an efficient and accurate solution for RPM problems by constraining distribution distances. Additionally, we present Lico-Net, a network that combines D3C and D3C-cos to achieve state-of-the-art performance in both problem-solving and interpretability. Finally, we extend our approach to D4C, employing adversarial strategies to further refine conceptual boundaries and demonstrate notable improvements for both RPM and Bongard-Logo problems. Overall, our contributions offer a new perspective and practical solutions to the field of abstract reasoning.
Multi-Grained Cross-modal Alignment for Learning Open-vocabulary Semantic Segmentation from Text Supervision
Mar 06, 2024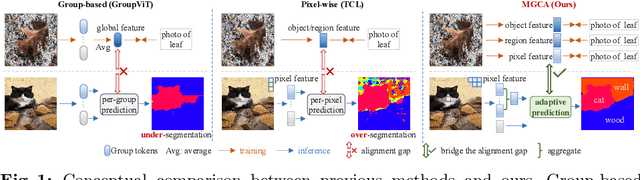
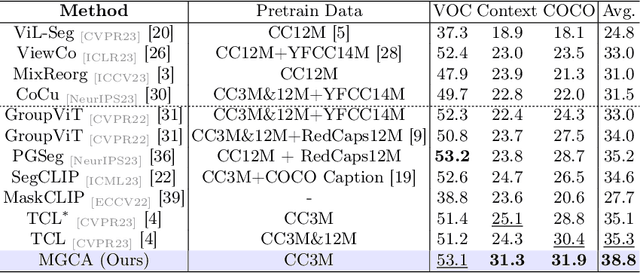
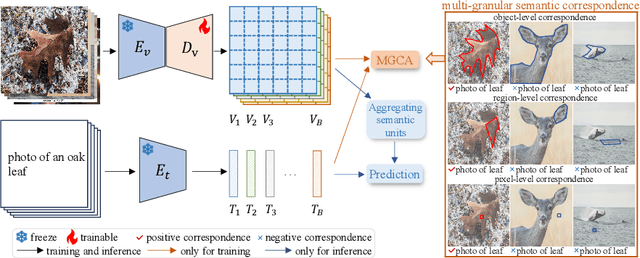
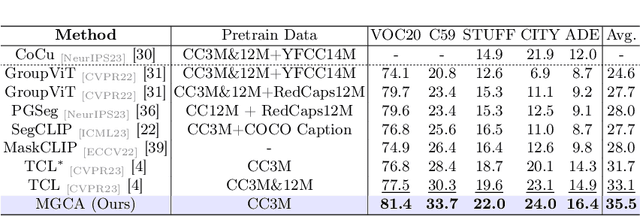
Recently, learning open-vocabulary semantic segmentation from text supervision has achieved promising downstream performance. Nevertheless, current approaches encounter an alignment granularity gap owing to the absence of dense annotations, wherein they learn coarse image/region-text alignment during training yet perform group/pixel-level predictions at inference. Such discrepancy leads to suboptimal learning efficiency and inferior zero-shot segmentation results. In this paper, we introduce a Multi-Grained Cross-modal Alignment (MGCA) framework, which explicitly learns pixel-level alignment along with object- and region-level alignment to bridge the granularity gap without any dense annotations. Specifically, MGCA ingeniously constructs pseudo multi-granular semantic correspondences upon image-text pairs and collaborates with hard sampling strategies to facilitate fine-grained cross-modal contrastive learning. Further, we point out the defects of existing group and pixel prediction units in downstream segmentation and develop an adaptive semantic unit which effectively mitigates their dilemmas including under- and over-segmentation. Training solely on CC3M, our method achieves significant advancements over state-of-the-art methods, demonstrating its effectiveness and efficiency.
Decoupled Contrastive Learning for Long-Tailed Recognition
Mar 10, 2024
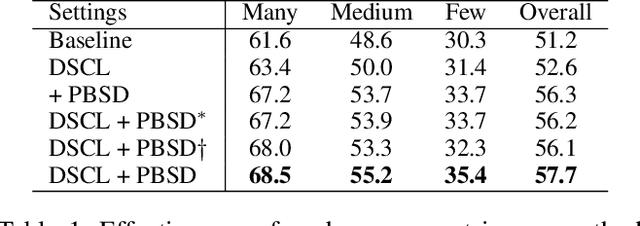
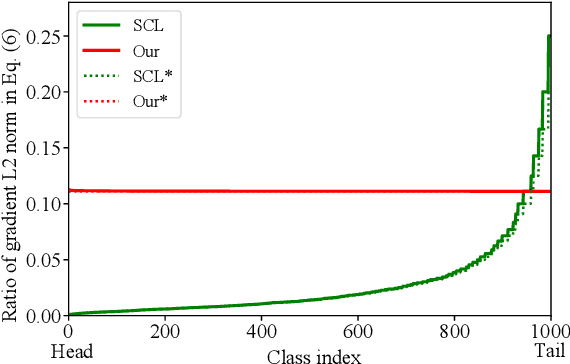
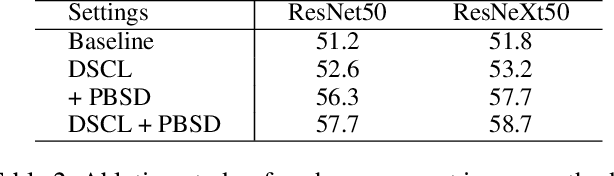
Supervised Contrastive Loss (SCL) is popular in visual representation learning. Given an anchor image, SCL pulls two types of positive samples, i.e., its augmentation and other images from the same class together, while pushes negative images apart to optimize the learned embedding. In the scenario of long-tailed recognition, where the number of samples in each class is imbalanced, treating two types of positive samples equally leads to the biased optimization for intra-category distance. In addition, similarity relationship among negative samples, that are ignored by SCL, also presents meaningful semantic cues. To improve the performance on long-tailed recognition, this paper addresses those two issues of SCL by decoupling the training objective. Specifically, it decouples two types of positives in SCL and optimizes their relations toward different objectives to alleviate the influence of the imbalanced dataset. We further propose a patch-based self distillation to transfer knowledge from head to tail classes to relieve the under-representation of tail classes. It uses patch-based features to mine shared visual patterns among different instances and leverages a self distillation procedure to transfer such knowledge. Experiments on different long-tailed classification benchmarks demonstrate the superiority of our method. For instance, it achieves the 57.7% top-1 accuracy on the ImageNet-LT dataset. Combined with the ensemble-based method, the performance can be further boosted to 59.7%, which substantially outperforms many recent works. The code is available at https://github.com/SY-Xuan/DSCL.
On depth prediction for autonomous driving using self-supervised learning
Mar 10, 2024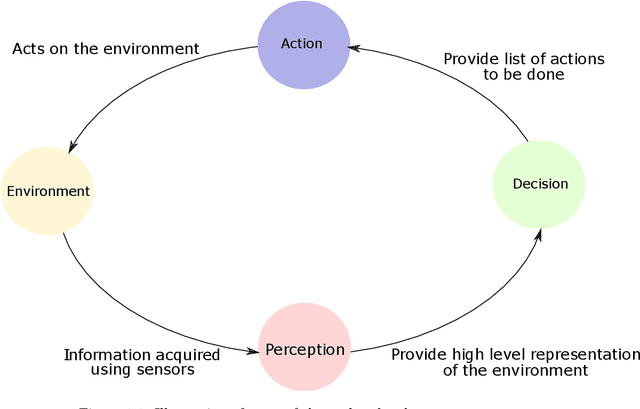
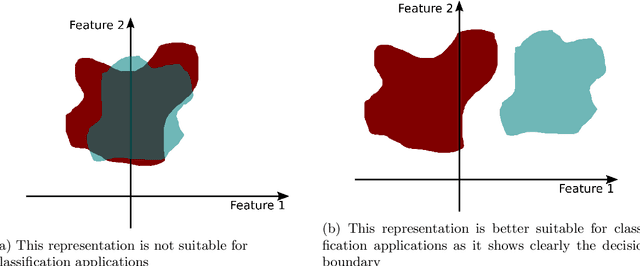

Perception of the environment is a critical component for enabling autonomous driving. It provides the vehicle with the ability to comprehend its surroundings and make informed decisions. Depth prediction plays a pivotal role in this process, as it helps the understanding of the geometry and motion of the environment. This thesis focuses on the challenge of depth prediction using monocular self-supervised learning techniques. The problem is approached from a broader perspective first, exploring conditional generative adversarial networks (cGANs) as a potential technique to achieve better generalization was performed. In doing so, a fundamental contribution to the conditional GANs, the acontrario cGAN was proposed. The second contribution entails a single image-to-depth self-supervised method, proposing a solution for the rigid-scene assumption using a novel transformer-based method that outputs a pose for each dynamic object. The third significant aspect involves the introduction of a video-to-depth map forecasting approach. This method serves as an extension of self-supervised techniques to predict future depths. This involves the creation of a novel transformer model capable of predicting the future depth of a given scene. Moreover, the various limitations of the aforementioned methods were addressed and a video-to-video depth maps model was proposed. This model leverages the spatio-temporal consistency of the input and output sequence to predict a more accurate depth sequence output. These methods have significant applications in autonomous driving (AD) and advanced driver assistance systems (ADAS).
VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
Mar 10, 2024

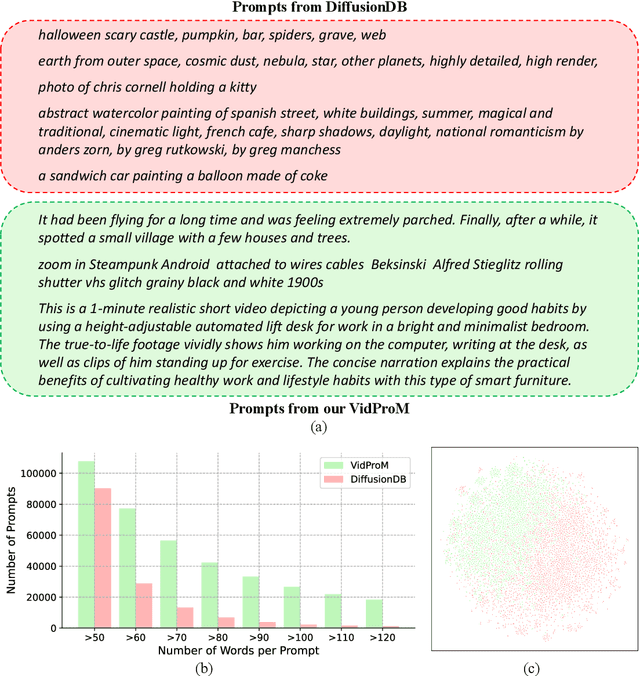
The arrival of Sora marks a new era for text-to-video diffusion models, bringing significant advancements in video generation and potential applications. However, Sora, as well as other text-to-video diffusion models, highly relies on the prompts, and there is no publicly available dataset featuring a study of text-to-video prompts. In this paper, we introduce VidProM, the first large-scale dataset comprising 1.67 million unique text-to-video prompts from real users. Additionally, the dataset includes 6.69 million videos generated by four state-of-the-art diffusion models and some related data. We initially demonstrate the curation of this large-scale dataset, which is a time-consuming and costly process. Subsequently, we show how the proposed VidProM differs from DiffusionDB, a large-scale prompt-gallery dataset for image generation. Based on the analysis of these prompts, we identify the necessity for a new prompt dataset specifically designed for text-to-video generation and gain insights into the preferences of real users when creating videos. Our large-scale and diverse dataset also inspires many exciting new research areas. For instance, to develop better, more efficient, and safer text-to-video diffusion models, we suggest exploring text-to-video prompt engineering, efficient video generation, and video copy detection for diffusion models. We make the collected dataset VidProM publicly available at GitHub and Hugging Face under the CC-BY- NC 4.0 License.
Fourier-basis Functions to Bridge Augmentation Gap: Rethinking Frequency Augmentation in Image Classification
Mar 05, 2024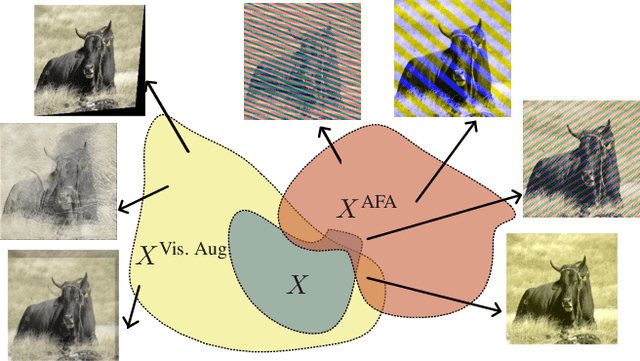


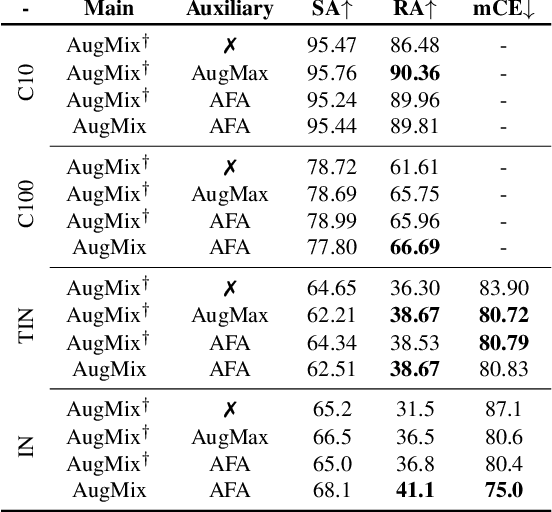
Computer vision models normally witness degraded performance when deployed in real-world scenarios, due to unexpected changes in inputs that were not accounted for during training. Data augmentation is commonly used to address this issue, as it aims to increase data variety and reduce the distribution gap between training and test data. However, common visual augmentations might not guarantee extensive robustness of computer vision models. In this paper, we propose Auxiliary Fourier-basis Augmentation (AFA), a complementary technique targeting augmentation in the frequency domain and filling the augmentation gap left by visual augmentations. We demonstrate the utility of augmentation via Fourier-basis additive noise in a straightforward and efficient adversarial setting. Our results show that AFA benefits the robustness of models against common corruptions, OOD generalization, and consistency of performance of models against increasing perturbations, with negligible deficit to the standard performance of models. It can be seamlessly integrated with other augmentation techniques to further boost performance. Code and models can be found at: https://github.com/nis-research/afa-augment