 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Dec 20, 2021
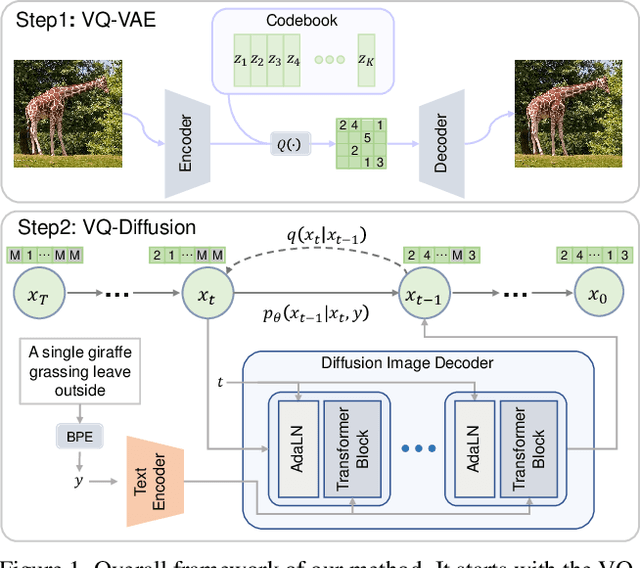
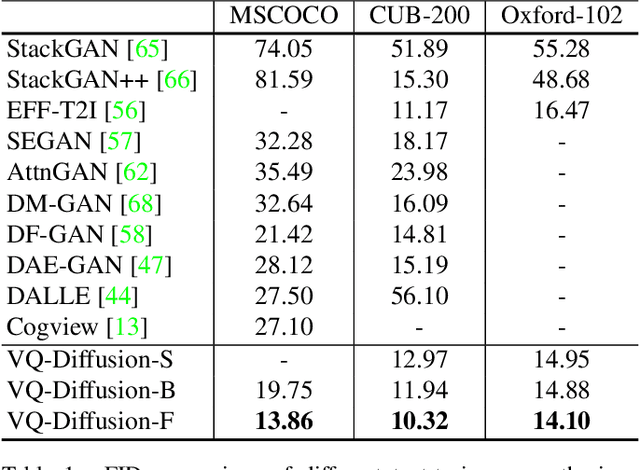

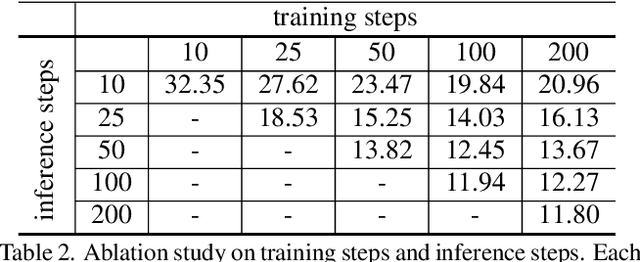
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
Deep Metric Learning with Chance Constraints
Sep 19, 2022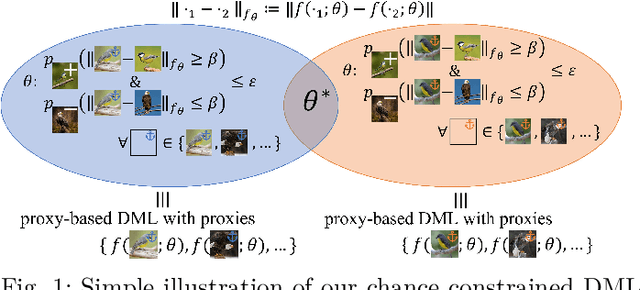
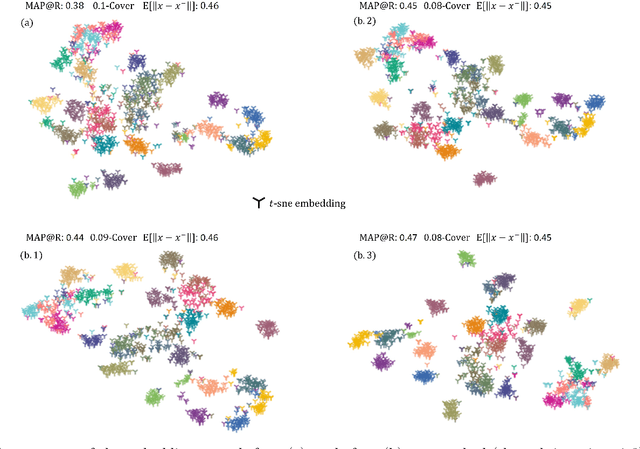
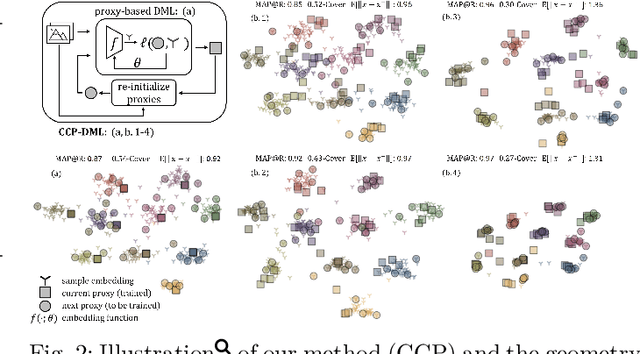

Deep metric learning (DML) aims to minimize empirical expected loss of the pairwise intra-/inter- class proximity violations in the embedding image. We relate DML to feasibility problem of finite chance constraints. We show that minimizer of proxy-based DML satisfies certain chance constraints, and that the worst case generalization performance of the proxy-based methods can be characterized by the radius of the smallest ball around a class proxy to cover the entire domain of the corresponding class samples, suggesting multiple proxies per class helps performance. To provide a scalable algorithm as well as exploiting more proxies, we consider the chance constraints implied by the minimizers of proxy-based DML instances and reformulate DML as finding a feasible point in intersection of such constraints, resulting in a problem to be approximately solved by iterative projections. Simply put, we repeatedly train a regularized proxy-based loss and re-initialize the proxies with the embeddings of the deliberately selected new samples. We apply our method with the well-accepted losses and evaluate on four popular benchmark datasets for image retrieval. Outperforming state-of-the-art, our method consistently improves the performance of the applied losses. Code is available at: https://github.com/yetigurbuz/ccp-dml
Edge-Aware Extended Star-Tetrix Transforms for CFA-Sampled Raw Camera Image Compression
Sep 02, 2022
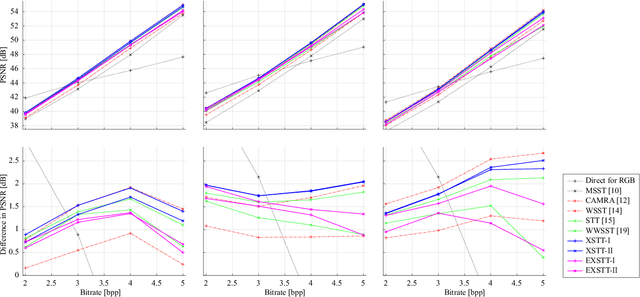

Codecs using spectral-spatial transforms efficiently compress raw camera images captured with a color filter array (CFA-sampled raw images) by changing their RGB color space into a decorrelated color space. This study describes two types of spectral-spatial transform, called extended Star-Tetrix transforms (XSTTs), and their edge-aware versions, called edge-aware XSTTs (EXSTTs), with no extra bits (side information) and little extra complexity. They are obtained by (i) extending the Star-Tetrix transform (STT), which is one of the latest spectral-spatial transforms, to a new version of our previously proposed wavelet-based spectral-spatial transform and a simpler version, (ii) considering that each 2-D predict step of the wavelet transform is a combination of two 1-D diagonal or horizontal-vertical transforms, and (iii) weighting the transforms along the edge directions in the images. Compared with XSTTs, the EXSTTs can decorrelate CFA-sampled raw images well: they reduce the difference in energy between the two green components by about $3.38$--$30.08$ \% for high-quality camera images and $8.97$--$14.47$ \% for mobile phone images. The experiments on JPEG 2000-based lossless and lossy compression of CFA-sampled raw images show better performance than conventional methods. For high-quality camera images, the XSTTs/EXSTTs produce results equal to or better than the conventional methods: especially for images with many edges, the type-I EXSTT improves them by about $0.03$--$0.19$ bpp in average lossless bitrate and the XSTTs improve them by about $0.16$--$0.96$ dB in average Bj\o ntegaard delta peak signal-to-noise ratio. For mobile phone images, our previous work perform the best, whereas the XSTTs/EXSTTs show similar trends to the case of high-quality camera images.
Meta Ordinal Regression Forest for Medical Image Classification with Ordinal Labels
Mar 15, 2022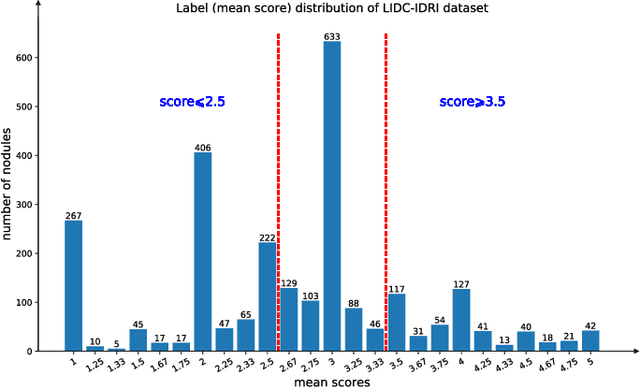
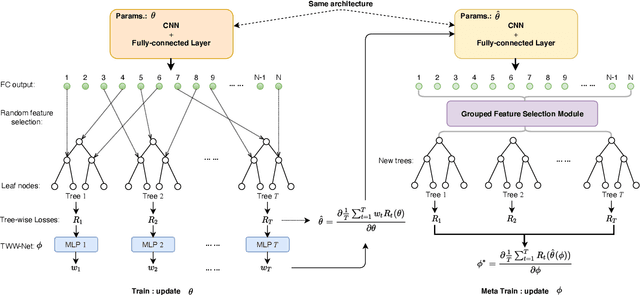
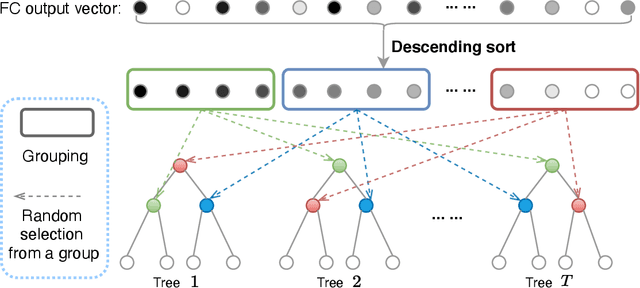
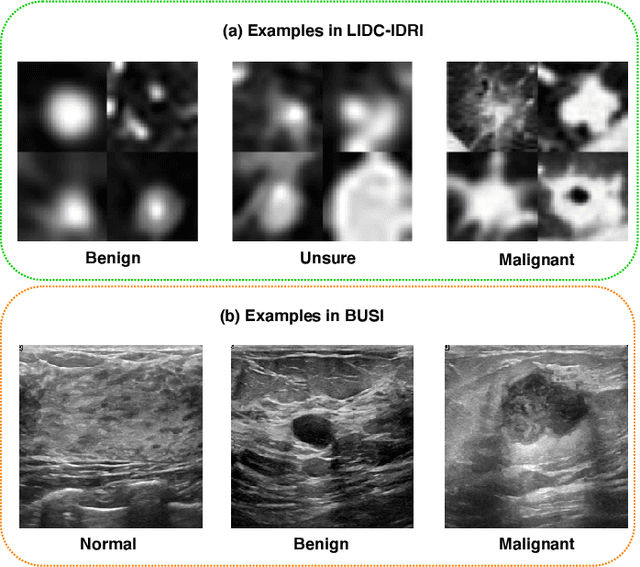
The performance of medical image classification has been enhanced by deep convolutional neural networks (CNNs), which are typically trained with cross-entropy (CE) loss. However, when the label presents an intrinsic ordinal property in nature, e.g., the development from benign to malignant tumor, CE loss cannot take into account such ordinal information to allow for better generalization. To improve model generalization with ordinal information, we propose a novel meta ordinal regression forest (MORF) method for medical image classification with ordinal labels, which learns the ordinal relationship through the combination of convolutional neural network and differential forest in a meta-learning framework. The merits of the proposed MORF come from the following two components: a tree-wise weighting net (TWW-Net) and a grouped feature selection (GFS) module. First, the TWW-Net assigns each tree in the forest with a specific weight that is mapped from the classification loss of the corresponding tree. Hence, all the trees possess varying weights, which is helpful for alleviating the tree-wise prediction variance. Second, the GFS module enables a dynamic forest rather than a fixed one that was previously used, allowing for random feature perturbation. During training, we alternatively optimize the parameters of the CNN backbone and TWW-Net in the meta-learning framework through calculating the Hessian matrix. Experimental results on two medical image classification datasets with ordinal labels, i.e., LIDC-IDRI and Breast Ultrasound Dataset, demonstrate the superior performances of our MORF method over existing state-of-the-art methods.
Skin Lesion Recognition with Class-Hierarchy Regularized Hyperbolic Embeddings
Sep 13, 2022In practice, many medical datasets have an underlying taxonomy defined over the disease label space. However, existing classification algorithms for medical diagnoses often assume semantically independent labels. In this study, we aim to leverage class hierarchy with deep learning algorithms for more accurate and reliable skin lesion recognition. We propose a hyperbolic network to learn image embeddings and class prototypes jointly. The hyperbola provably provides a space for modeling hierarchical relations better than Euclidean geometry. Meanwhile, we restrict the distribution of hyperbolic prototypes with a distance matrix that is encoded from the class hierarchy. Accordingly, the learned prototypes preserve the semantic class relations in the embedding space and we can predict the label of an image by assigning its feature to the nearest hyperbolic class prototype. We use an in-house skin lesion dataset which consists of around 230k dermoscopic images on 65 skin diseases to verify our method. Extensive experiments provide evidence that our model can achieve higher accuracy with less severe classification errors than models without considering class relations.
FocalUNETR: A Focal Transformer for Boundary-aware Segmentation of CT Images
Oct 06, 2022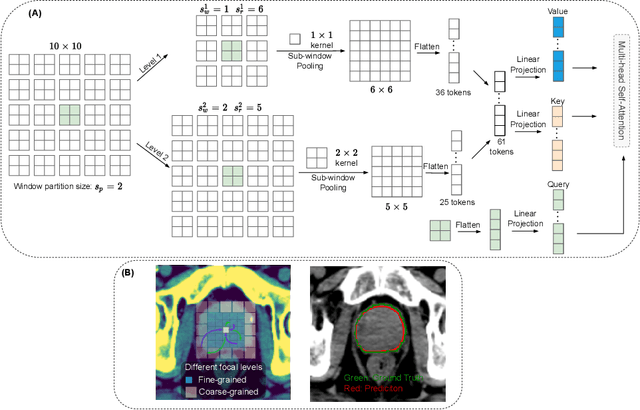
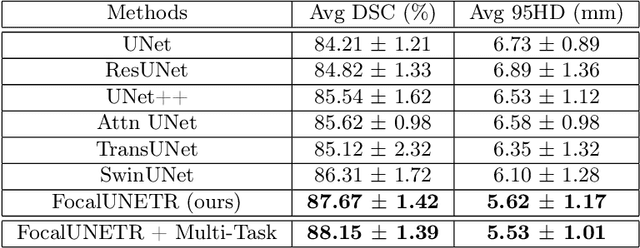
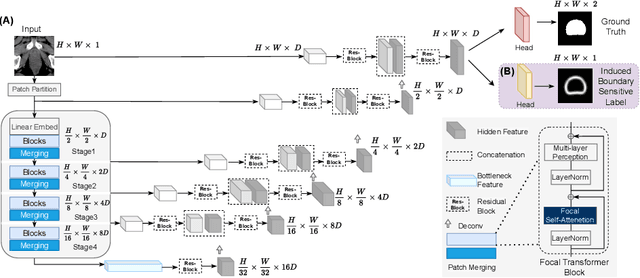

Computed Tomography (CT) based precise prostate segmentation for treatment planning is challenging due to (1) the unclear boundary of prostate derived from CTs poor soft tissue contrast, and (2) the limitation of convolutional neural network based models in capturing long-range global context. Here we propose a focal transformer based image segmentation architecture to effectively and efficiently extract local visual features and global context from CT images. Furthermore, we design a main segmentation task and an auxiliary boundary-induced label regression task as regularization to simultaneously optimize segmentation results and mitigate the unclear boundary effect, particularly in unseen data set. Extensive experiments on a large data set of 400 prostate CT scans demonstrate the superior performance of our focal transformer to the competing methods on the prostate segmentation task.
CLAD: A Contrastive Learning based Approach for Background Debiasing
Oct 06, 2022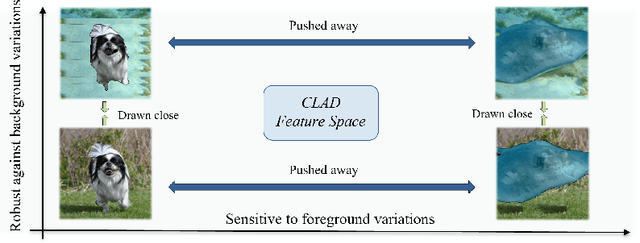


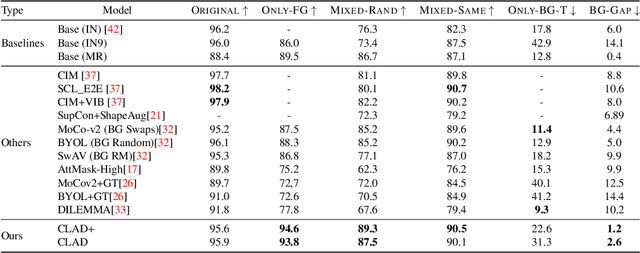
Convolutional neural networks (CNNs) have achieved superhuman performance in multiple vision tasks, especially image classification. However, unlike humans, CNNs leverage spurious features, such as background information to make decisions. This tendency creates different problems in terms of robustness or weak generalization performance. Through our work, we introduce a contrastive learning-based approach (CLAD) to mitigate the background bias in CNNs. CLAD encourages semantic focus on object foregrounds and penalizes learning features from irrelavant backgrounds. Our method also introduces an efficient way of sampling negative samples. We achieve state-of-the-art results on the Background Challenge dataset, outperforming the previous benchmark with a margin of 4.1\%. Our paper shows how CLAD serves as a proof of concept for debiasing of spurious features, such as background and texture (in supplementary material).
The Dynamics of Sharpness-Aware Minimization: Bouncing Across Ravines and Drifting Towards Wide Minima
Oct 04, 2022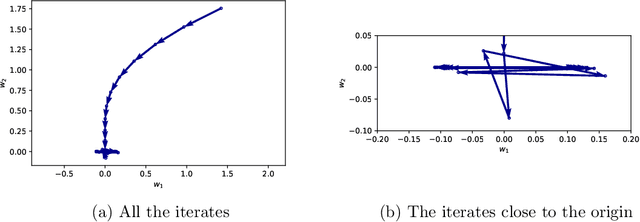
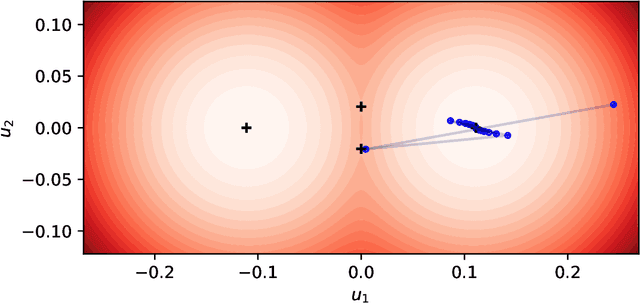
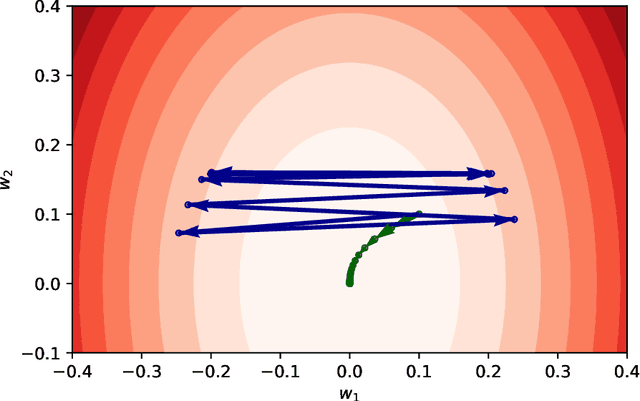
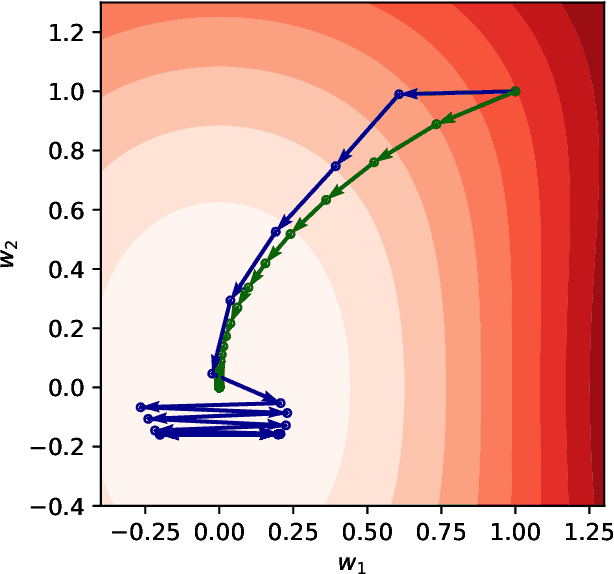
We consider Sharpness-Aware Minimization (SAM), a gradient-based optimization method for deep networks that has exhibited performance improvements on image and language prediction problems. We show that when SAM is applied with a convex quadratic objective, for most random initializations it converges to a cycle that oscillates between either side of the minimum in the direction with the largest curvature, and we provide bounds on the rate of convergence. In the non-quadratic case, we show that such oscillations effectively perform gradient descent, with a smaller step-size, on the spectral norm of the Hessian. In such cases, SAM's update may be regarded as a third derivative -- the derivative of the Hessian in the leading eigenvector direction -- that encourages drift toward wider minima.
Deep Joint Source-Channel and Encryption Coding: Secure Semantic Communications
Aug 31, 2022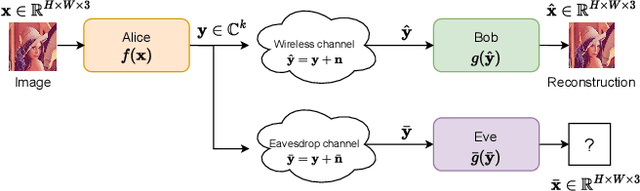
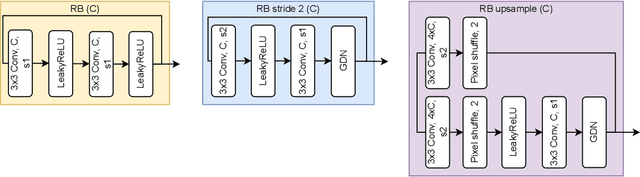
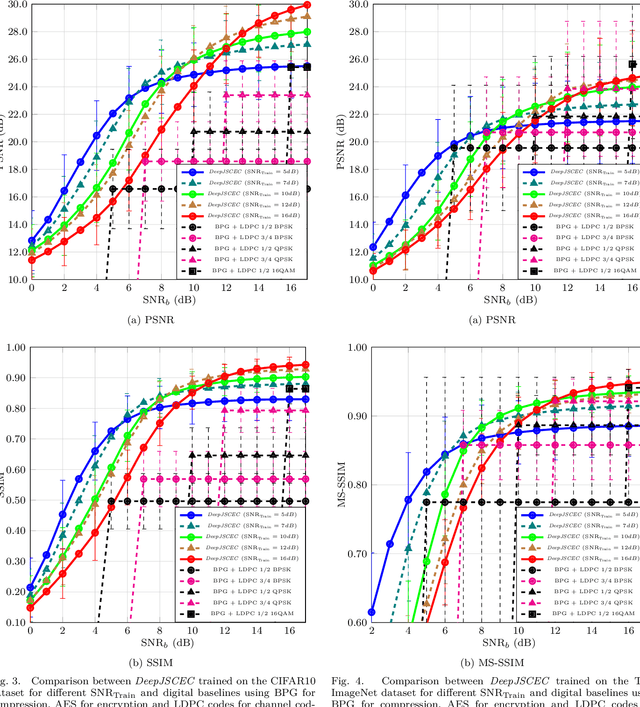
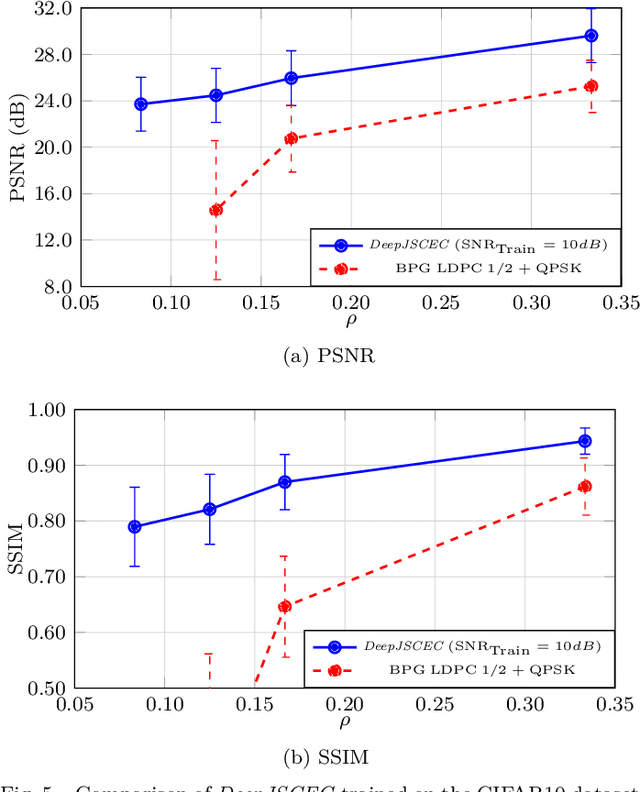
Deep learning driven joint source-channel coding (JSCC) for wireless image or video transmission, also called DeepJSCC, has been a topic of interest recently with very promising results. The idea is to map similar source samples to nearby points in the channel input space such that, despite the noise introduced by the channel, the input can be recovered with minimal distortion. In DeepJSCC, this is achieved by an autoencoder architecture with a non-trainable channel layer between the encoder and decoder. DeepJSCC has many favorable properties, such as better end-to-end distortion performance than its separate source and channel coding counterpart as well as graceful degradation with respect to channel quality. However, due to the inherent correlation between the source sample and channel input, DeepJSCC is vulnerable to eavesdropping attacks. In this paper, we propose the first DeepJSCC scheme for wireless image transmission that is secure against eavesdroppers, called DeepJSCEC. DeepJSCEC not only preserves the favorable properties of DeepJSCC, it also provides security against chosen-plaintext attacks from the eavesdropper, without the need to make assumptions about the eavesdropper's channel condition, or its intended use of the intercepted signal. Numerical results show that DeepJSCEC achieves similar or better image quality than separate source coding using BPG compression, AES encryption, and LDPC codes for channel coding, while preserving the graceful degradation of image quality with respect to channel quality. We also show that the proposed encryption method is problem agnostic, meaning it can be applied to other end-to-end JSCC problems, such as remote classification, without modification. Given the importance of security in modern wireless communication systems, we believe this work brings DeepJSCC schemes much closer to adoption in practice.
Denoising MCMC for Accelerating Diffusion-Based Generative Models
Sep 29, 2022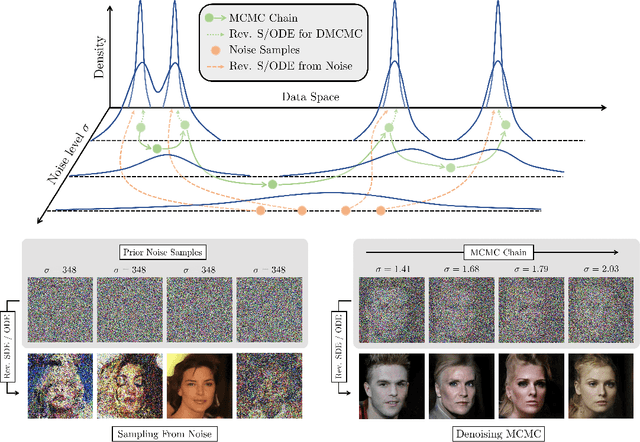
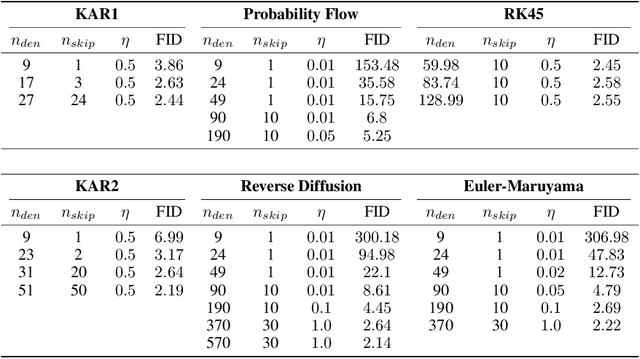
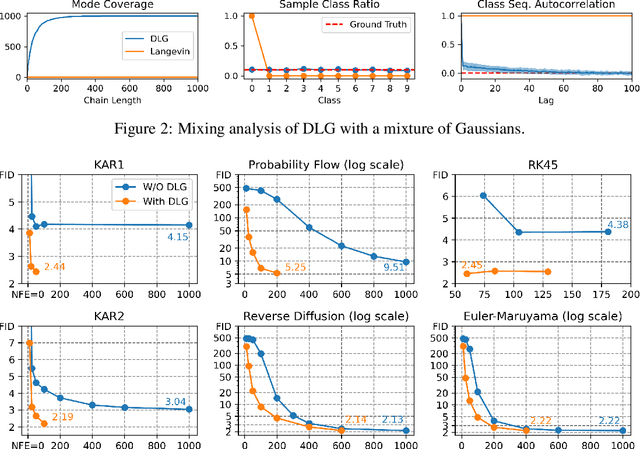
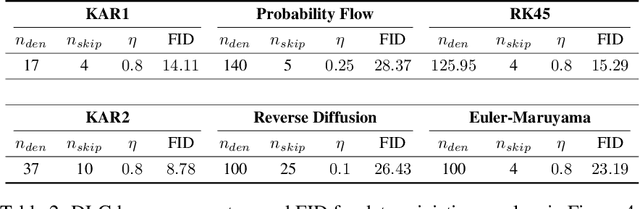
Diffusion models are powerful generative models that simulate the reverse of diffusion processes using score functions to synthesize data from noise. The sampling process of diffusion models can be interpreted as solving the reverse stochastic differential equation (SDE) or the ordinary differential equation (ODE) of the diffusion process, which often requires up to thousands of discretization steps to generate a single image. This has sparked a great interest in developing efficient integration techniques for reverse-S/ODEs. Here, we propose an orthogonal approach to accelerating score-based sampling: Denoising MCMC (DMCMC). DMCMC first uses MCMC to produce samples in the product space of data and variance (or diffusion time). Then, a reverse-S/ODE integrator is used to denoise the MCMC samples. Since MCMC traverses close to the data manifold, the computation cost of producing a clean sample for DMCMC is much less than that of producing a clean sample from noise. To verify the proposed concept, we show that Denoising Langevin Gibbs (DLG), an instance of DMCMC, successfully accelerates all six reverse-S/ODE integrators considered in this work on the tasks of CIFAR10 and CelebA-HQ-256 image generation. Notably, combined with integrators of Karras et al. (2022) and pre-trained score models of Song et al. (2021b), DLG achieves SOTA results. In the limited number of score function evaluation (NFE) settings on CIFAR10, we have $3.86$ FID with $\approx 10$ NFE and $2.63$ FID with $\approx 20$ NFE. On CelebA-HQ-256, we have $6.99$ FID with $\approx 160$ NFE, which beats the current best record of Kim et al. (2022) among score-based models, $7.16$ FID with $4000$ NFE. Code: https://github.com/1202kbs/DMCMC