 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hybrid Model-based / Data-driven Graph Transform for Image Coding
Mar 02, 2022
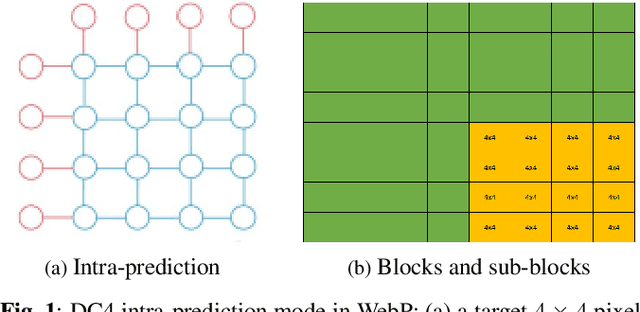
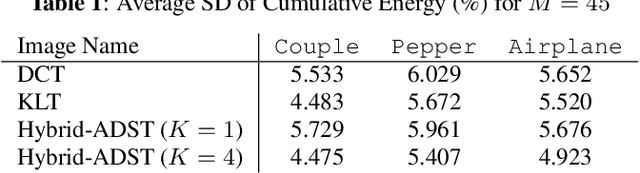
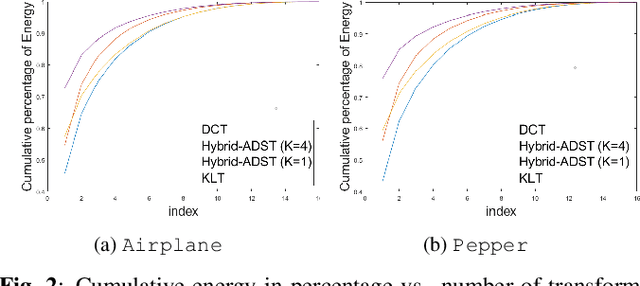

Transform coding to sparsify signal representations remains crucial in an image compression pipeline. While the Karhunen-Lo\`{e}ve transform (KLT) computed from an empirical covariance matrix $\bar{C}$ is theoretically optimal for a stationary process, in practice, collecting sufficient statistics from a non-stationary image to reliably estimate $\bar{C}$ can be difficult. In this paper, to encode an intra-prediction residual block, we pursue a hybrid model-based / data-driven approach: the first $K$ eigenvectors of a transform matrix are derived from a statistical model, e.g., the asymmetric discrete sine transform (ADST), for stability, while the remaining $N-K$ are computed from $\bar{C}$ for performance. The transform computation is posed as a graph learning problem, where we seek a graph Laplacian matrix minimizing a graphical lasso objective inside a convex cone sharing the first $K$ eigenvectors in a Hilbert space of real symmetric matrices. We efficiently solve the problem via augmented Lagrangian relaxation and proximal gradient (PG). Using WebP as a baseline image codec, experimental results show that our hybrid graph transform achieved better energy compaction than default discrete cosine transform (DCT) and better stability than KLT.
STEM image analysis based on deep learning: identification of vacancy defects and polymorphs of ${MoS_2}$
Jun 09, 2022
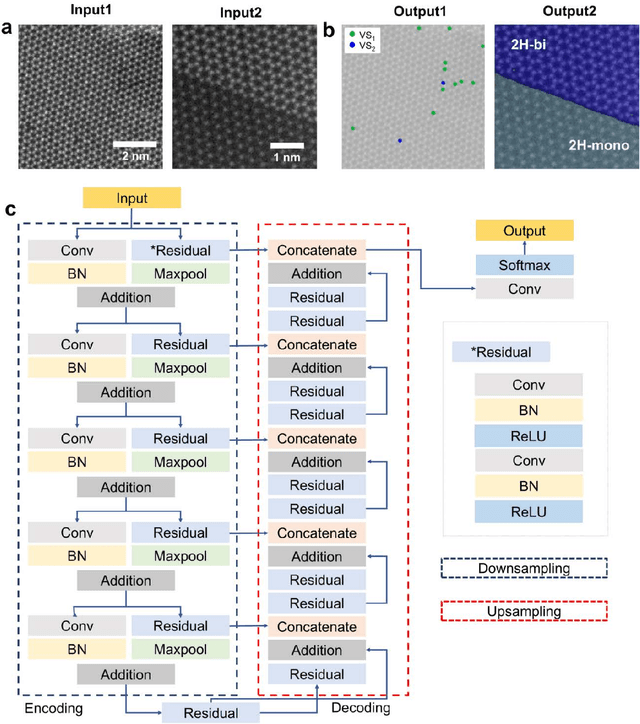
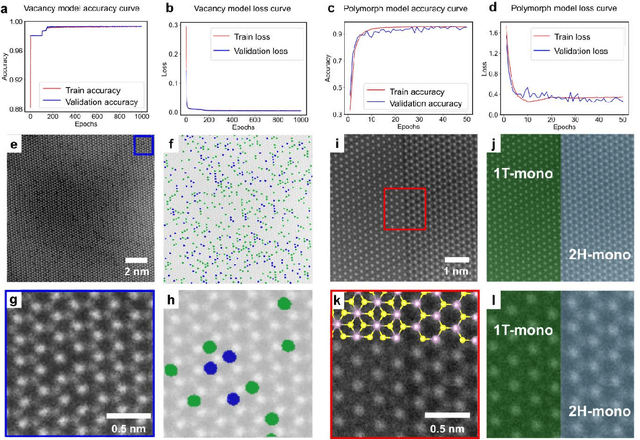
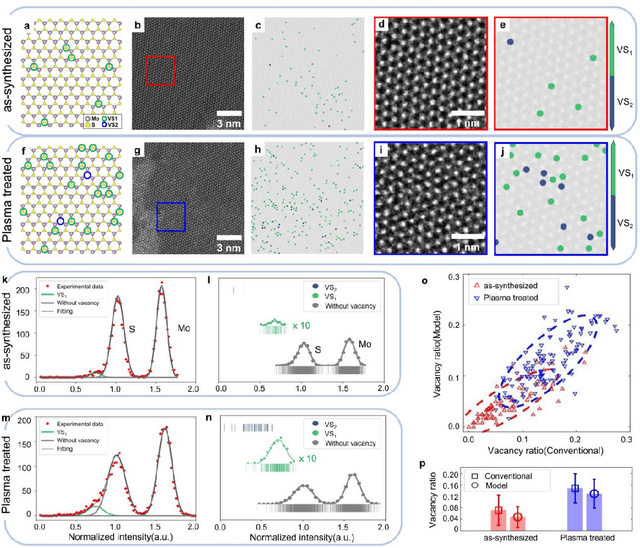
Scanning transmission electron microscopy (STEM) is an indispensable tool for atomic-resolution structural analysis for a wide range of materials. The conventional analysis of STEM images is an extensive hands-on process, which limits efficient handling of high-throughput data. Here we apply a fully convolutional network (FCN) for identification of important structural features of two-dimensional crystals. ResUNet, a type of FCN, is utilized in identifying sulfur vacancies and polymorph types of ${MoS_2}$ from atomic resolution STEM images. Efficient models are achieved based on training with simulated images in the presence of different levels of noise, aberrations, and carbon contamination. The accuracy of the FCN models toward extensive experimental STEM images is comparable to that of careful hands-on analysis. Our work provides a guideline on best practices to train a deep learning model for STEM image analysis and demonstrates FCN's application for efficient processing of a large volume of STEM data.
* 24 pages, 5 figures
Scalable Self-Supervised Representation Learning from Spatiotemporal Motion Trajectories for Multimodal Computer Vision
Oct 07, 2022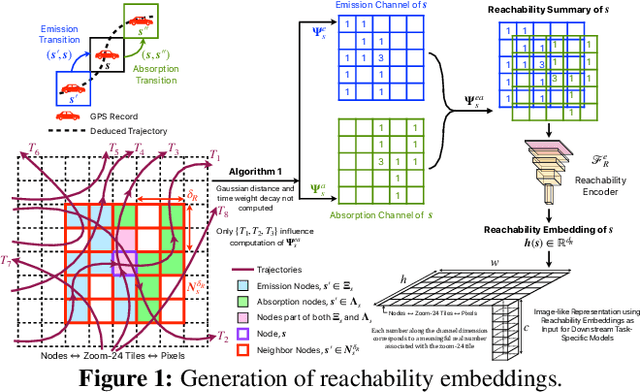

Self-supervised representation learning techniques utilize large datasets without semantic annotations to learn meaningful, universal features that can be conveniently transferred to solve a wide variety of downstream supervised tasks. In this work, we propose a self-supervised method for learning representations of geographic locations from unlabeled GPS trajectories to solve downstream geospatial computer vision tasks. Tiles resulting from a raster representation of the earth's surface are modeled as nodes on a graph or pixels of an image. GPS trajectories are modeled as allowed Markovian paths on these nodes. A scalable and distributed algorithm is presented to compute image-like representations, called reachability summaries, of the spatial connectivity patterns between tiles and their neighbors implied by the observed Markovian paths. A convolutional, contractive autoencoder is trained to learn compressed representations, called reachability embeddings, of reachability summaries for every tile. Reachability embeddings serve as task-agnostic, feature representations of geographic locations. Using reachability embeddings as pixel representations for five different downstream geospatial tasks, cast as supervised semantic segmentation problems, we quantitatively demonstrate that reachability embeddings are semantically meaningful representations and result in 4-23% gain in performance, as measured using area under the precision-recall curve (AUPRC) metric, when compared to baseline models that use pixel representations that do not account for the spatial connectivity between tiles. Reachability embeddings transform sequential, spatiotemporal mobility data into semantically meaningful tensor representations that can be combined with other sources of imagery and are designed to facilitate multimodal learning in geospatial computer vision.
EMDS-6: Environmental Microorganism Image Dataset Sixth Version for Image Denoising, Segmentation, Feature Extraction, Classification and Detection Methods Evaluation
Dec 14, 2021
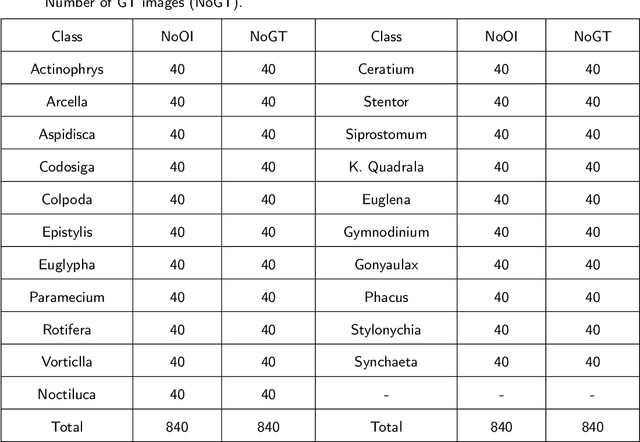
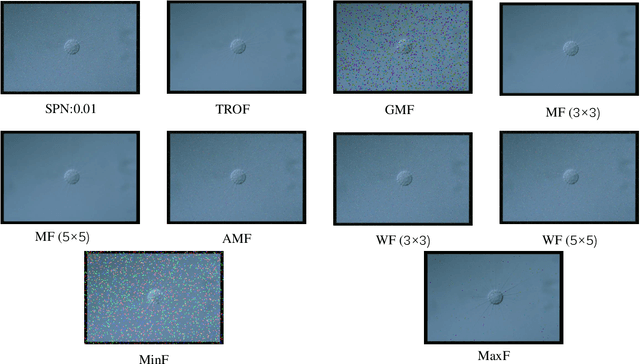
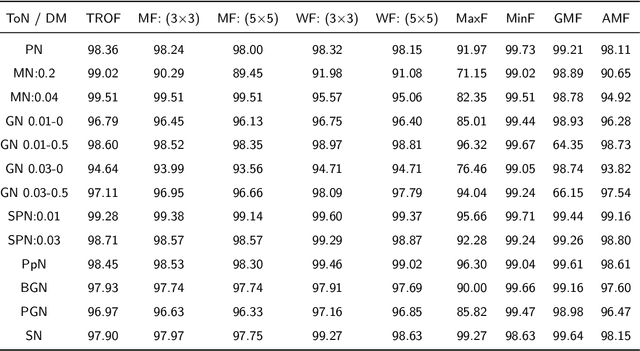
Environmental microorganisms (EMs) are ubiquitous around us and have an important impact on the survival and development of human society. However, the high standards and strict requirements for the preparation of environmental microorganism (EM) data have led to the insufficient of existing related databases, not to mention the databases with GT images. This problem seriously affects the progress of related experiments. Therefore, This study develops the Environmental Microorganism Dataset Sixth Version (EMDS-6), which contains 21 types of EMs. Each type of EM contains 40 original and 40 GT images, in total 1680 EM images. In this study, in order to test the effectiveness of EMDS-6. We choose the classic algorithms of image processing methods such as image denoising, image segmentation and target detection. The experimental result shows that EMDS-6 can be used to evaluate the performance of image denoising, image segmentation, image feature extraction, image classification, and object detection methods.
Dataset Distillation via Factorization
Oct 30, 2022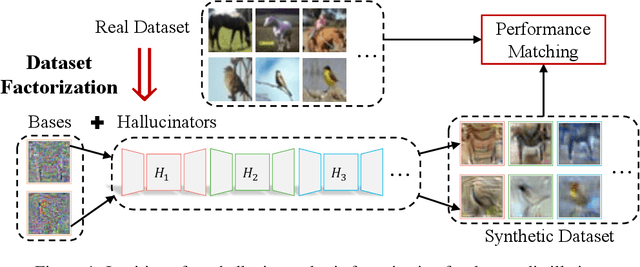
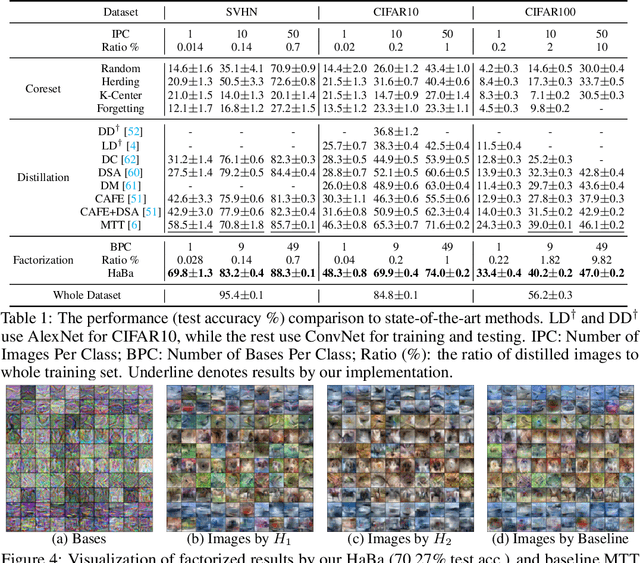
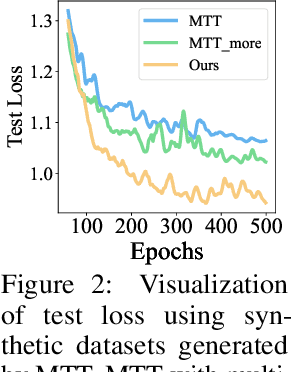
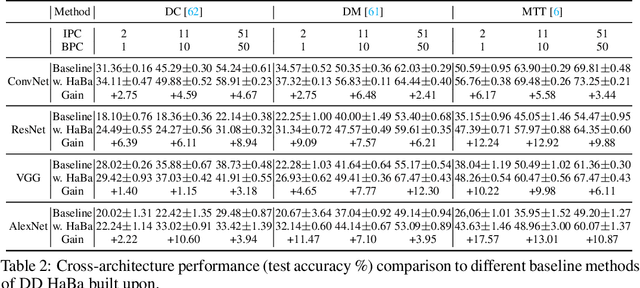
In this paper, we study \xw{dataset distillation (DD)}, from a novel perspective and introduce a \emph{dataset factorization} approach, termed \emph{HaBa}, which is a plug-and-play strategy portable to any existing DD baseline. Unlike conventional DD approaches that aim to produce distilled and representative samples, \emph{HaBa} explores decomposing a dataset into two components: data \emph{Ha}llucination networks and \emph{Ba}ses, where the latter is fed into the former to reconstruct image samples. The flexible combinations between bases and hallucination networks, therefore, equip the distilled data with exponential informativeness gain, which largely increase the representation capability of distilled datasets. To furthermore increase the data efficiency of compression results, we further introduce a pair of adversarial contrastive constraints on the resultant hallucination networks and bases, which increase the diversity of generated images and inject more discriminant information into the factorization. Extensive comparisons and experiments demonstrate that our method can yield significant improvement on downstream classification tasks compared with previous state of the arts, while reducing the total number of compressed parameters by up to 65\%. Moreover, distilled datasets by our approach also achieve \textasciitilde10\% higher accuracy than baseline methods in cross-architecture generalization. Our code is available \href{https://github.com/Huage001/DatasetFactorization}{here}.
Towards Versatile Embodied Navigation
Oct 30, 2022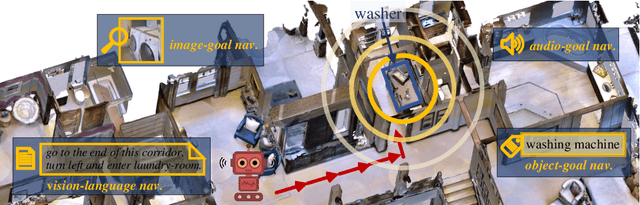

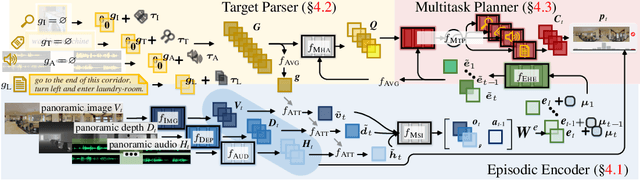

With the emergence of varied visual navigation tasks (e.g, image-/object-/audio-goal and vision-language navigation) that specify the target in different ways, the community has made appealing advances in training specialized agents capable of handling individual navigation tasks well. Given plenty of embodied navigation tasks and task-specific solutions, we address a more fundamental question: can we learn a single powerful agent that masters not one but multiple navigation tasks concurrently? First, we propose VXN, a large-scale 3D dataset that instantiates four classic navigation tasks in standardized, continuous, and audiovisual-rich environments. Second, we propose Vienna, a versatile embodied navigation agent that simultaneously learns to perform the four navigation tasks with one model. Building upon a full-attentive architecture, Vienna formulates various navigation tasks as a unified, parse-and-query procedure: the target description, augmented with four task embeddings, is comprehensively interpreted into a set of diversified goal vectors, which are refined as the navigation progresses, and used as queries to retrieve supportive context from episodic history for decision making. This enables the reuse of knowledge across navigation tasks with varying input domains/modalities. We empirically demonstrate that, compared with learning each visual navigation task individually, our multitask agent achieves comparable or even better performance with reduced complexity.
Attention Swin U-Net: Cross-Contextual Attention Mechanism for Skin Lesion Segmentation
Oct 30, 2022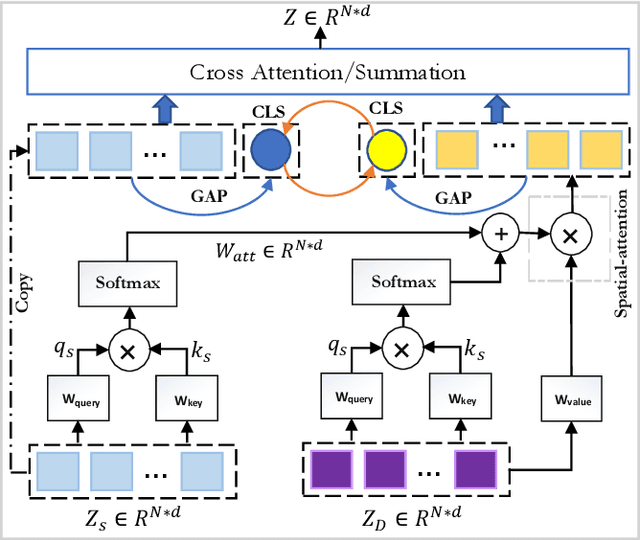
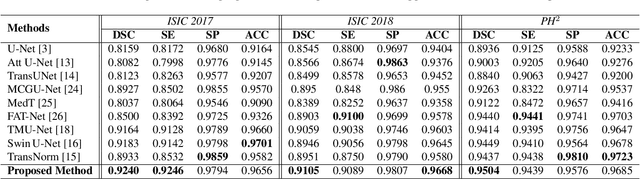

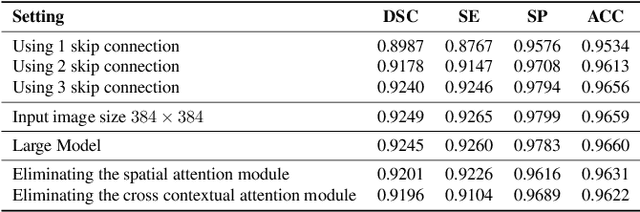
Melanoma is caused by the abnormal growth of melanocytes in human skin. Like other cancers, this life-threatening skin cancer can be treated with early diagnosis. To support a diagnosis by automatic skin lesion segmentation, several Fully Convolutional Network (FCN) approaches, specifically the U-Net architecture, have been proposed. The U-Net model with a symmetrical architecture has exhibited superior performance in the segmentation task. However, the locality restriction of the convolutional operation incorporated in the U-Net architecture limits its performance in capturing long-range dependency, which is crucial for the segmentation task in medical images. To address this limitation, recently a Transformer based U-Net architecture that replaces the CNN blocks with the Swin Transformer module has been proposed to capture both local and global representation. In this paper, we propose Att-SwinU-Net, an attention-based Swin U-Net extension, for medical image segmentation. In our design, we seek to enhance the feature re-usability of the network by carefully designing the skip connection path. We argue that the classical concatenation operation utilized in the skip connection path can be further improved by incorporating an attention mechanism. By performing a comprehensive ablation study on several skin lesion segmentation datasets, we demonstrate the effectiveness of our proposed attention mechanism.
Alleviating the Sample Selection Bias in Few-shot Learning by Removing Projection to the Centroid
Oct 30, 2022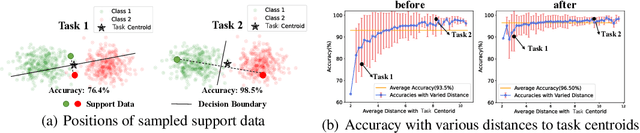
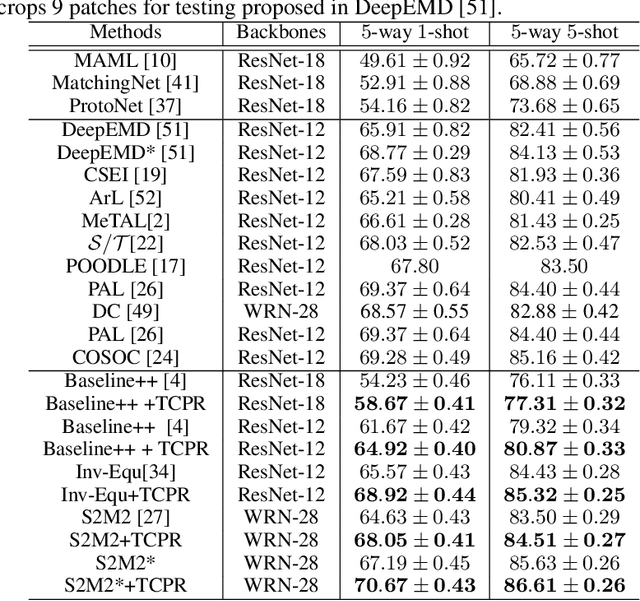
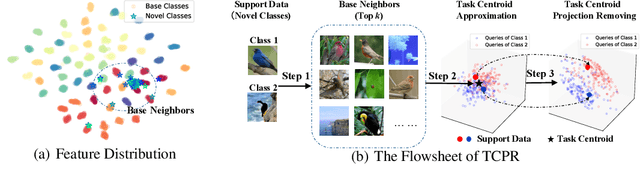
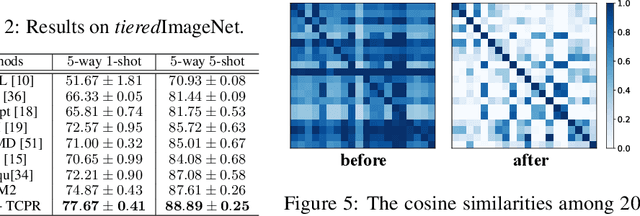
Few-shot learning (FSL) targets at generalization of vision models towards unseen tasks without sufficient annotations. Despite the emergence of a number of few-shot learning methods, the sample selection bias problem, i.e., the sensitivity to the limited amount of support data, has not been well understood. In this paper, we find that this problem usually occurs when the positions of support samples are in the vicinity of task centroid -- the mean of all class centroids in the task. This motivates us to propose an extremely simple feature transformation to alleviate this problem, dubbed Task Centroid Projection Removing (TCPR). TCPR is applied directly to all image features in a given task, aiming at removing the dimension of features along the direction of the task centroid. While the exact task centroid cannot be accurately obtained from limited data, we estimate it using base features that are each similar to one of the support features. Our method effectively prevents features from being too close to the task centroid. Extensive experiments over ten datasets from different domains show that TCPR can reliably improve classification accuracy across various feature extractors, training algorithms and datasets. The code has been made available at https://github.com/KikimorMay/FSL-TCBR.
Conversion Between CT and MRI Images Using Diffusion and Score-Matching Models
Sep 29, 2022


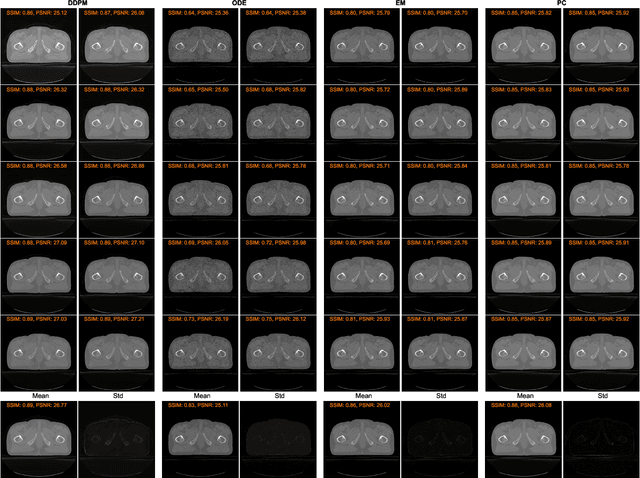
MRI and CT are most widely used medical imaging modalities. It is often necessary to acquire multi-modality images for diagnosis and treatment such as radiotherapy planning. However, multi-modality imaging is not only costly but also introduces misalignment between MRI and CT images. To address this challenge, computational conversion is a viable approach between MRI and CT images, especially from MRI to CT images. In this paper, we propose to use an emerging deep learning framework called diffusion and score-matching models in this context. Specifically, we adapt denoising diffusion probabilistic and score-matching models, use four different sampling strategies, and compare their performance metrics with that using a convolutional neural network and a generative adversarial network model. Our results show that the diffusion and score-matching models generate better synthetic CT images than the CNN and GAN models. Furthermore, we investigate the uncertainties associated with the diffusion and score-matching networks using the Monte-Carlo method, and improve the results by averaging their Monte-Carlo outputs. Our study suggests that diffusion and score-matching models are powerful to generate high quality images conditioned on an image obtained using a complementary imaging modality, analytically rigorous with clear explainability, and highly competitive with CNNs and GANs for image synthesis.
Graph Attention Network for Camera Relocalization on Dynamic Scenes
Sep 29, 2022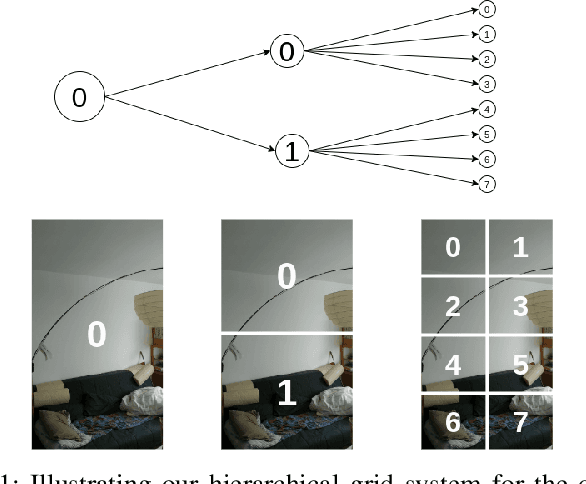
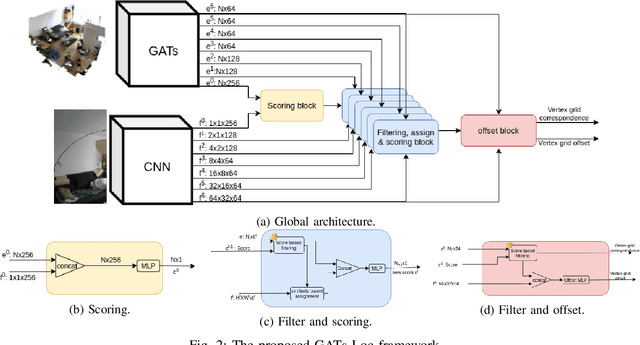
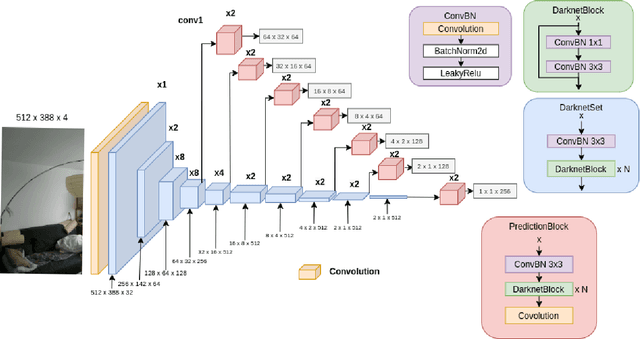
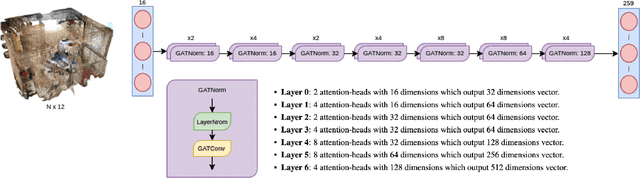
We devise a graph attention network-based approach for learning a scene triangle mesh representation in order to estimate an image camera position in a dynamic environment. Previous approaches built a scene-dependent model that explicitly or implicitly embeds the structure of the scene. They use convolution neural networks or decision trees to establish 2D/3D-3D correspondences. Such a mapping overfits the target scene and does not generalize well to dynamic changes in the environment. Our work introduces a novel approach to solve the camera relocalization problem by using the available triangle mesh. Our 3D-3D matching framework consists of three blocks: (1) a graph neural network to compute the embedding of mesh vertices, (2) a convolution neural network to compute the embedding of grid cells defined on the RGB-D image, and (3) a neural network model to establish the correspondence between the two embeddings. These three components are trained end-to-end. To predict the final pose, we run the RANSAC algorithm to generate camera pose hypotheses, and we refine the prediction using the point-cloud representation. Our approach significantly improves the camera pose accuracy of the state-of-the-art method from $0.358$ to $0.506$ on the RIO10 benchmark for dynamic indoor camera relocalization.