 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ACORT: A Compact Object Relation Transformer for Parameter Efficient Image Captioning
Feb 11, 2022
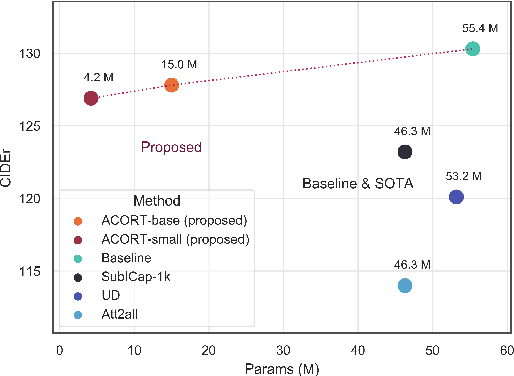
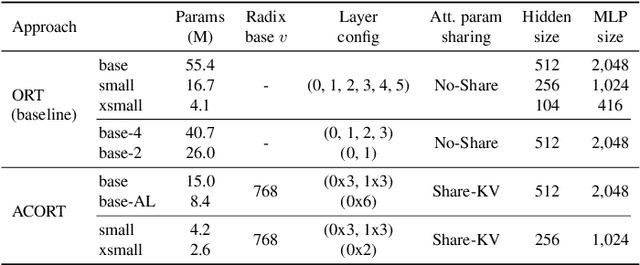
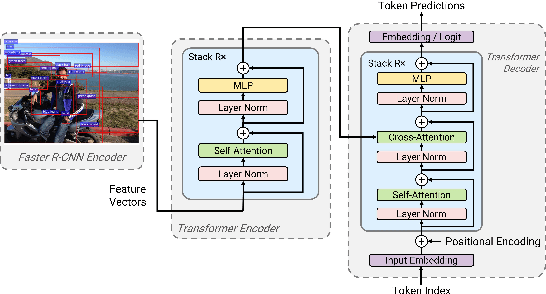
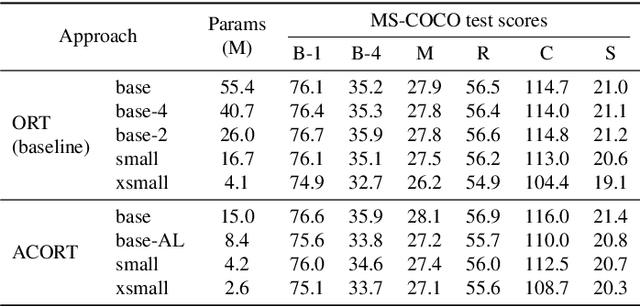
Recent research that applies Transformer-based architectures to image captioning has resulted in state-of-the-art image captioning performance, capitalising on the success of Transformers on natural language tasks. Unfortunately, though these models work well, one major flaw is their large model sizes. To this end, we present three parameter reduction methods for image captioning Transformers: Radix Encoding, cross-layer parameter sharing, and attention parameter sharing. By combining these methods, our proposed ACORT models have 3.7x to 21.6x fewer parameters than the baseline model without compromising test performance. Results on the MS-COCO dataset demonstrate that our ACORT models are competitive against baselines and SOTA approaches, with CIDEr score >=126. Finally, we present qualitative results and ablation studies to demonstrate the efficacy of the proposed changes further. Code and pre-trained models are publicly available at https://github.com/jiahuei/sparse-image-captioning.
Multi-NeuS: 3D Head Portraits from Single Image with Neural Implicit Functions
Sep 07, 2022
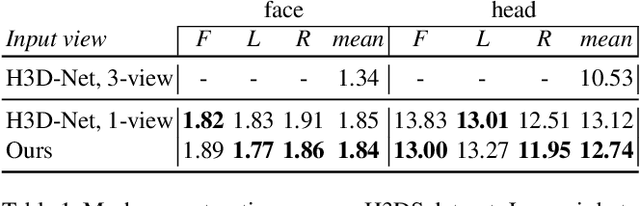
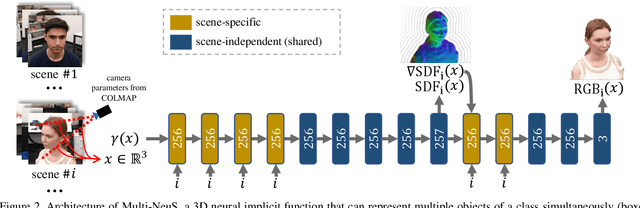

We present an approach for the reconstruction of textured 3D meshes of human heads from one or few views. Since such few-shot reconstruction is underconstrained, it requires prior knowledge which is hard to impose on traditional 3D reconstruction algorithms. In this work, we rely on the recently introduced 3D representation $\unicode{x2013}$ neural implicit functions $\unicode{x2013}$ which, being based on neural networks, allows to naturally learn priors about human heads from data, and is directly convertible to textured mesh. Namely, we extend NeuS, a state-of-the-art neural implicit function formulation, to represent multiple objects of a class (human heads in our case) simultaneously. The underlying neural net architecture is designed to learn the commonalities among these objects and to generalize to unseen ones. Our model is trained on just a hundred smartphone videos and does not require any scanned 3D data. Afterwards, the model can fit novel heads in the few-shot or one-shot modes with good results.
On Image Segmentation With Noisy Labels: Characterization and Volume Properties of the Optimal Solutions to Accuracy and Dice
Jun 13, 2022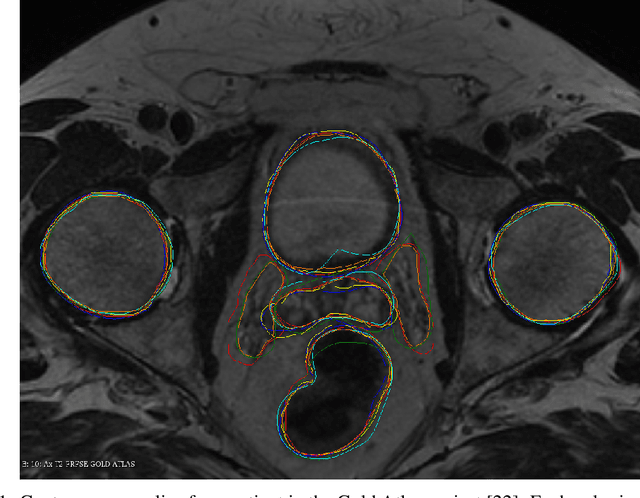
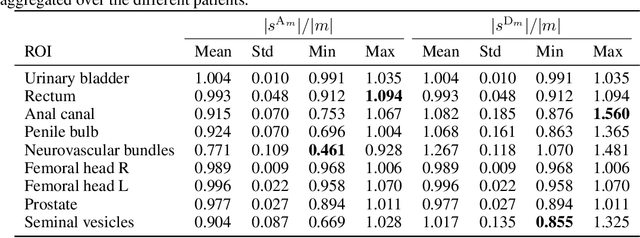
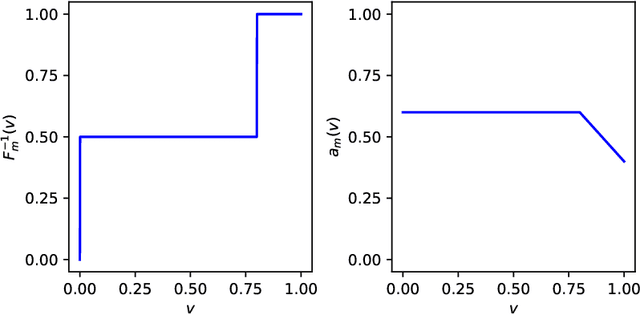
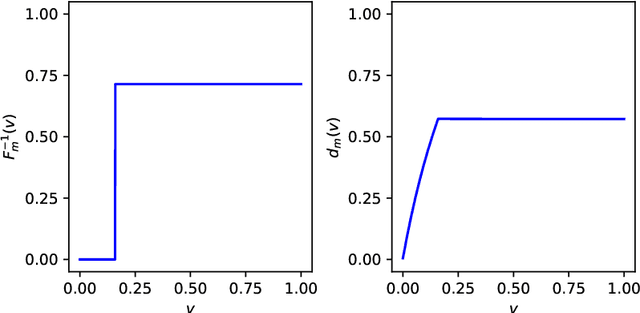
We study two of the most popular performance metrics in medical image segmentation, Accuracy and Dice, when the target labels are noisy. For both metrics, several statements related to characterization and volume properties of the set of optimal segmentations are proved, and associated experiments are provided. Our main insights are: (i) the volume of the solutions to both metrics may deviate significantly from the expected volume of the target, (ii) the volume of a solution to Accuracy is always less than or equal to the volume of a solution to Dice and (iii) the optimal solutions to both of these metrics coincide when the set of feasible segmentations is constrained to the set of segmentations with the volume equal to the expected volume of the target.
SUMD: Super U-shaped Matrix Decomposition Convolutional neural network for Image denoising
Apr 11, 2022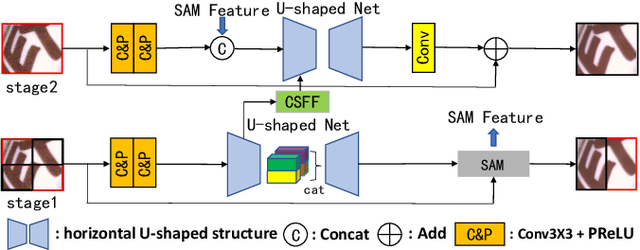
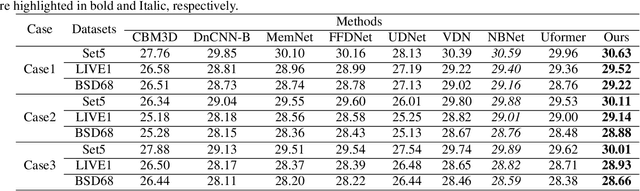
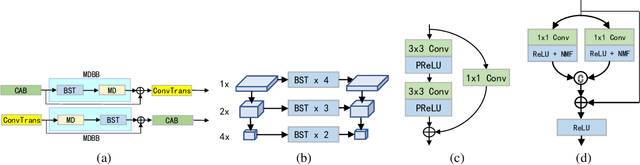
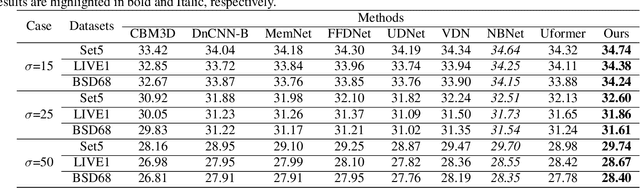
In this paper, we propose a novel and efficient CNN-based framework that leverages local and global context information for image denoising. Due to the limitations of convolution itself, the CNN-based method is generally unable to construct an effective and structured global feature representation, usually called the long-distance dependencies in the Transformer-based method. To tackle this problem, we introduce the matrix decomposition module(MD) in the network to establish the global context feature, comparable to the Transformer based method performance. Inspired by the design of multi-stage progressive restoration of U-shaped architecture, we further integrate the MD module into the multi-branches to acquire the relative global feature representation of the patch range at the current stage. Then, the stage input gradually rises to the overall scope and continuously improves the final feature. Experimental results on various image denoising datasets: SIDD, DND, and synthetic Gaussian noise datasets show that our model(SUMD) can produce comparable visual quality and accuracy results with Transformer-based methods.
Towards Dynamic Fault Tolerance for Hardware-Implemented Artificial Neural Networks: A Deep Learning Approach
Oct 16, 2022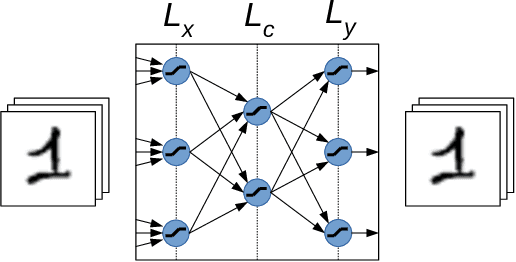
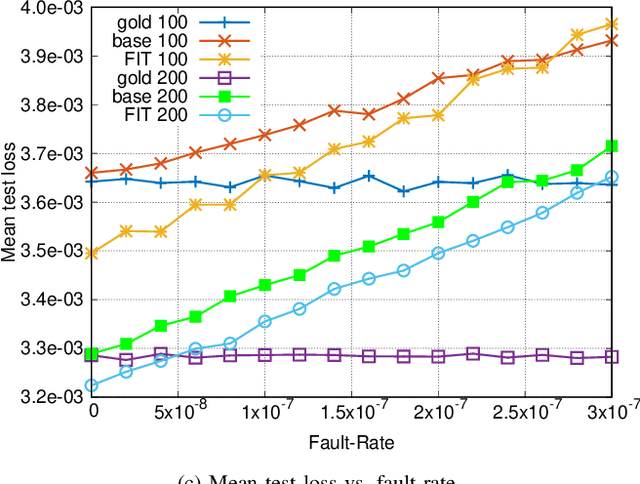
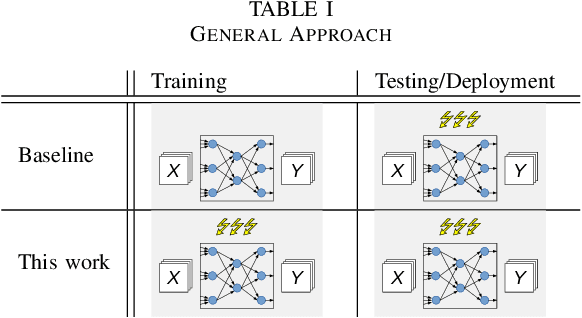
The functionality of electronic circuits can be seriously impaired by the occurrence of dynamic hardware faults. Particularly, for digital ultra low-power systems, a reduced safety margin can increase the probability of dynamic failures. This work investigates a deep learning approach to mitigate dynamic fault impact for artificial neural networks. As a theoretic use case, image compression by means of a deep autoencoder is considered. The evaluation shows a linear dependency of the test loss to the fault injection rate during testing. If the number of training epochs is sufficiently large, our approach shows more than 2% reduction of the test loss compared to a baseline network without the need of additional hardware. At the absence of faults during testing, our approach also decreases the test loss compared to reference networks.
Image Reconstruction from Events. Why learn it?
Dec 12, 2021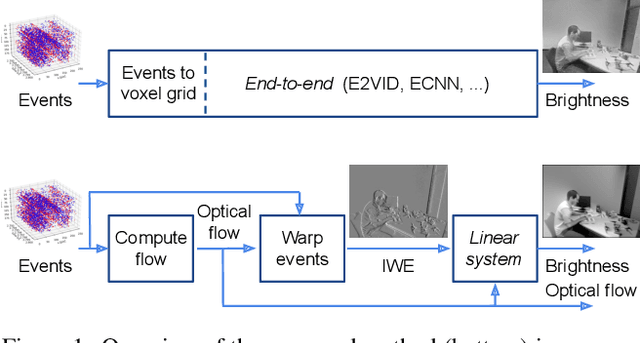
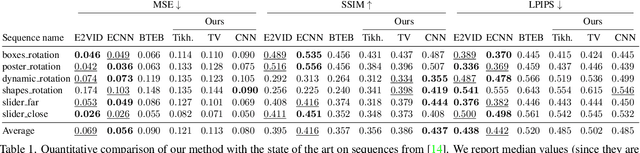

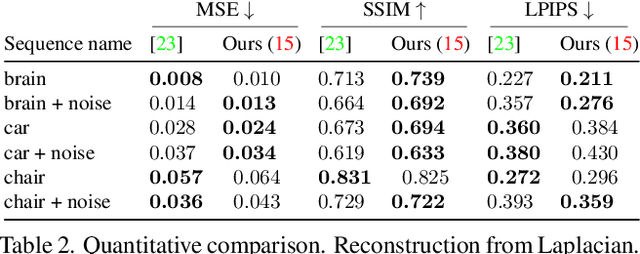
Traditional cameras measure image intensity. Event cameras, by contrast, measure per-pixel temporal intensity changes asynchronously. Recovering intensity from events is a popular research topic since the reconstructed images inherit the high dynamic range (HDR) and high-speed properties of events; hence they can be used in many robotic vision applications and to generate slow-motion HDR videos. However, state-of-the-art methods tackle this problem by training an event-to-image recurrent neural network (RNN), which lacks explainability and is difficult to tune. In this work we show, for the first time, how tackling the joint problem of motion and intensity estimation leads us to model event-based image reconstruction as a linear inverse problem that can be solved without training an image reconstruction RNN. Instead, classical and learning-based image priors can be used to solve the problem and remove artifacts from the reconstructed images. The experiments show that the proposed approach generates images with visual quality on par with state-of-the-art methods despite only using data from a short time interval (i.e., without recurrent connections). Our method can also be used to improve the quality of images reconstructed by approaches that first estimate the image Laplacian; here our method can be interpreted as Poisson reconstruction guided by image priors.
Parameter-Free Average Attention Improves Convolutional Neural Network Performance (Almost) Free of Charge
Oct 14, 2022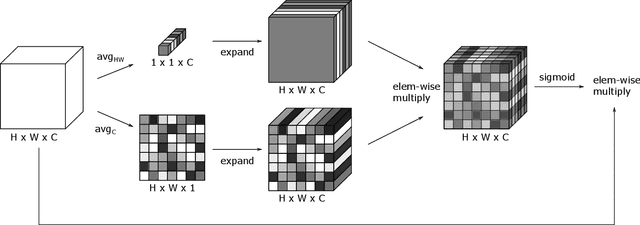

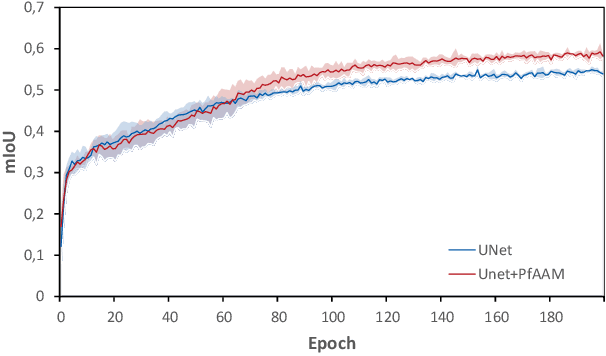
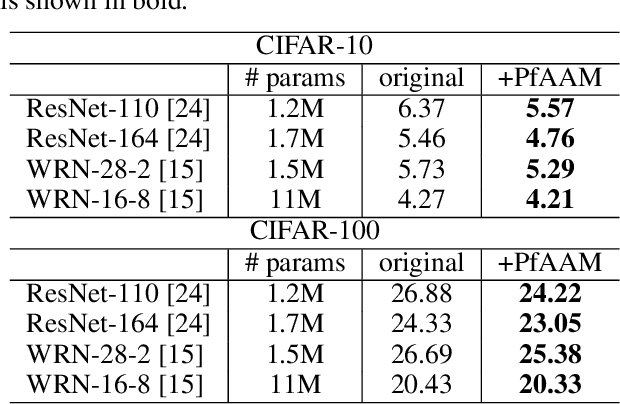
Visual perception is driven by the focus on relevant aspects in the surrounding world. To transfer this observation to the digital information processing of computers, attention mechanisms have been introduced to highlight salient image regions. Here, we introduce a parameter-free attention mechanism called PfAAM, that is a simple yet effective module. It can be plugged into various convolutional neural network architectures with a little computational overhead and without affecting model size. PfAAM was tested on multiple architectures for classification and segmentic segmentation leading to improved model performance for all tested cases. This demonstrates its wide applicability as a general easy-to-use module for computer vision tasks. The implementation of PfAAM can be found on https://github.com/nkoerb/pfaam.
Transfer Learning Application of Self-supervised Learning in ARPES
Aug 23, 2022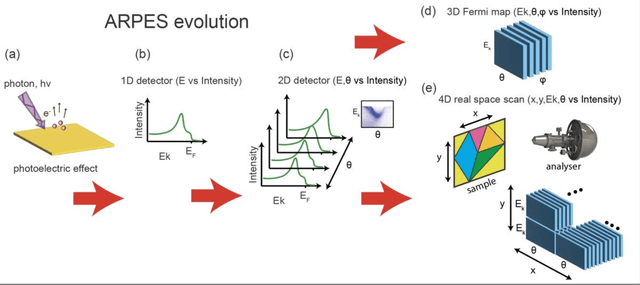
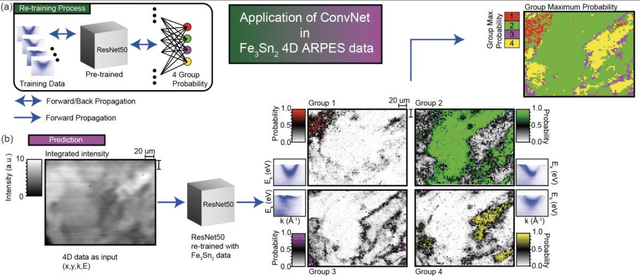
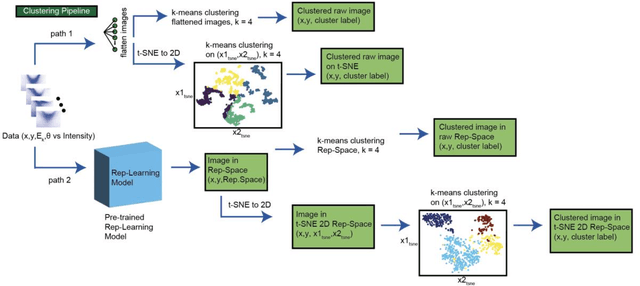
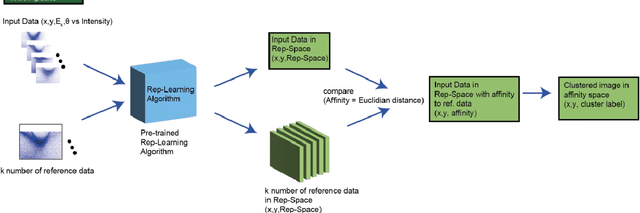
Recent development in angle-resolved photoemission spectroscopy (ARPES) technique involves spatially resolving samples while maintaining the high-resolution feature of momentum space. This development easily expands the data size and its complexity for data analysis, where one of it is to label similar dispersion cuts and map them spatially. In this work, we demonstrate that the recent development in representational learning (self-supervised learning) model combined with k-means clustering can help automate that part of data analysis and save precious time, albeit with low performance. Finally, we introduce a few-shot learning (k-nearest neighbour or kNN) in representational space where we selectively choose one (k=1) image reference for each known label and subsequently label the rest of the data with respect to the nearest reference image. This last approach demonstrates the strength of the self-supervised learning to automate the image analysis in ARPES in particular and can be generalized into any science data analysis that heavily involves image data.
Observations on K-image Expansion of Image-Mixing Augmentation for Classification
Oct 08, 2021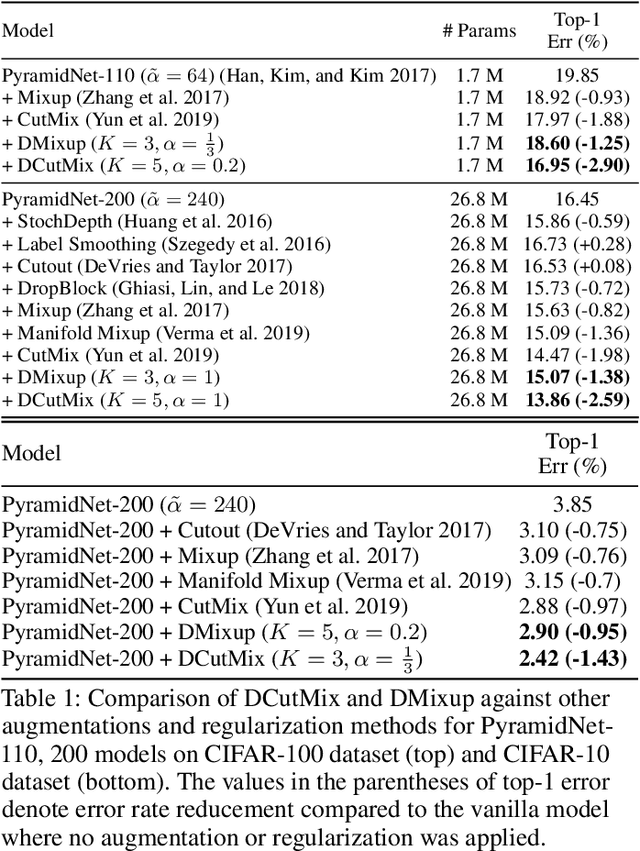
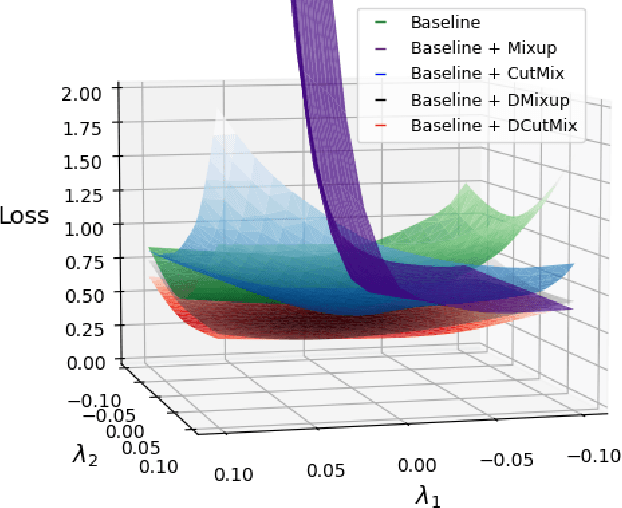

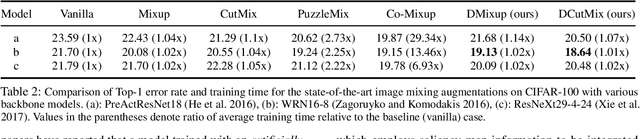
Image-mixing augmentations (e.g., Mixup or CutMix), which typically mix two images, have become de-facto training tricks for image classification. Despite their huge success on image classification, the number of images to mix has not been profoundly investigated by the previous works, only showing the naive K-image expansion leads to poor performance degradation. This paper derives a new K-image mixing augmentation based on the stick-breaking process under Dirichlet prior. We show that our method can train more robust and generalized classifiers through extensive experiments and analysis on classification accuracy, a shape of a loss landscape and adversarial robustness, than the usual two-image methods. Furthermore, we show that our probabilistic model can measure the sample-wise uncertainty and can boost the efficiency for Network Architecture Search (NAS) with 7x reduced search time.
Scalable Self-Supervised Representation Learning from Spatiotemporal Motion Trajectories for Multimodal Computer Vision
Oct 07, 2022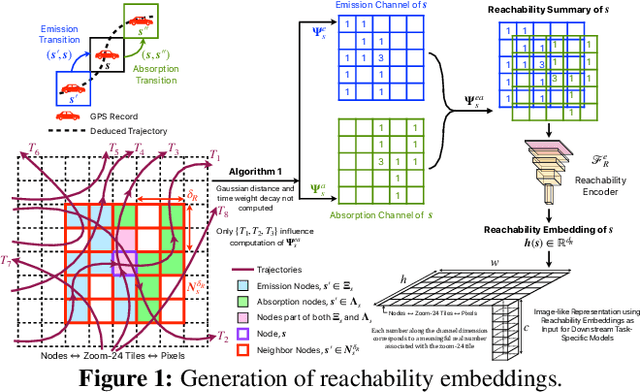

Self-supervised representation learning techniques utilize large datasets without semantic annotations to learn meaningful, universal features that can be conveniently transferred to solve a wide variety of downstream supervised tasks. In this work, we propose a self-supervised method for learning representations of geographic locations from unlabeled GPS trajectories to solve downstream geospatial computer vision tasks. Tiles resulting from a raster representation of the earth's surface are modeled as nodes on a graph or pixels of an image. GPS trajectories are modeled as allowed Markovian paths on these nodes. A scalable and distributed algorithm is presented to compute image-like representations, called reachability summaries, of the spatial connectivity patterns between tiles and their neighbors implied by the observed Markovian paths. A convolutional, contractive autoencoder is trained to learn compressed representations, called reachability embeddings, of reachability summaries for every tile. Reachability embeddings serve as task-agnostic, feature representations of geographic locations. Using reachability embeddings as pixel representations for five different downstream geospatial tasks, cast as supervised semantic segmentation problems, we quantitatively demonstrate that reachability embeddings are semantically meaningful representations and result in 4-23% gain in performance, as measured using area under the precision-recall curve (AUPRC) metric, when compared to baseline models that use pixel representations that do not account for the spatial connectivity between tiles. Reachability embeddings transform sequential, spatiotemporal mobility data into semantically meaningful tensor representations that can be combined with other sources of imagery and are designed to facilitate multimodal learning in geospatial computer vision.