 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diabetic foot ulcers monitoring by employing super resolution and noise reduction deep learning techniques
Sep 20, 2022

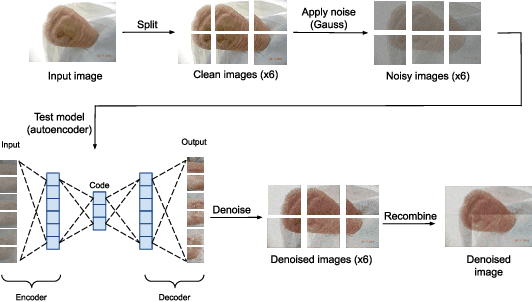

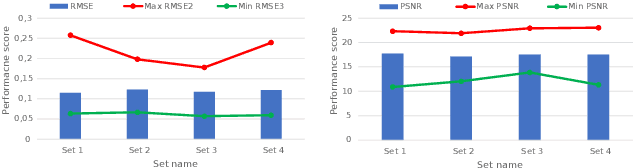
Diabetic foot ulcers (DFUs) constitute a serious complication for people with diabetes. The care of DFU patients can be substantially improved through self-management, in order to achieve early-diagnosis, ulcer prevention, and complications management in existing ulcers. In this paper, we investigate two categories of image-to-image translation techniques (ItITT), which will support decision making and monitoring of diabetic foot ulcers: noise reduction and super-resolution. In the former case, we investigated the capabilities on noise removal, for convolutional neural network stacked-autoencoders (CNN-SAE). CNN-SAE was tested on RGB images, induced with Gaussian noise. The latter scenario involves the deployment of four deep learning super-resolution models. The performance of all models, for both scenarios, was evaluated in terms of execution time and perceived quality. Results indicate that applied techniques consist a viable and easy to implement alternative that should be used by any system designed for DFU monitoring.
Three-Stream Joint Network for Zero-Shot Sketch-Based Image Retrieval
Apr 12, 2022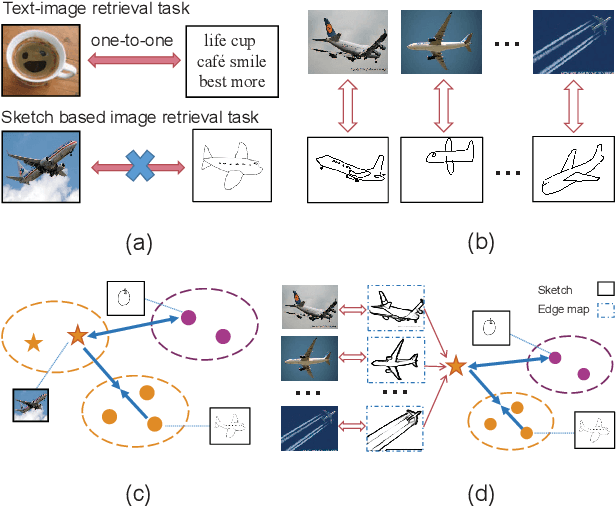
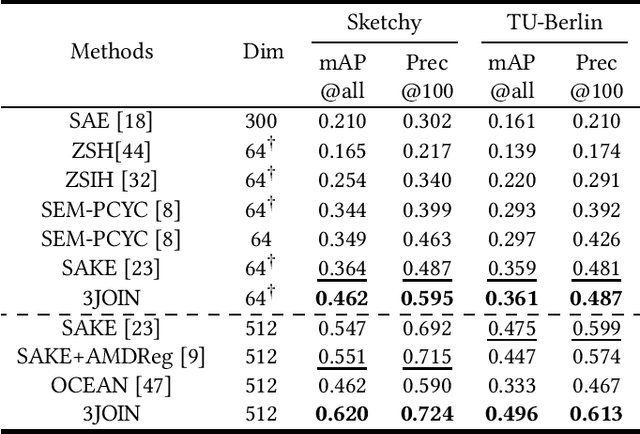
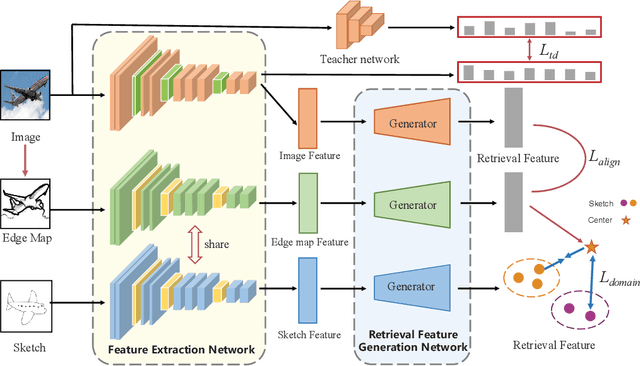
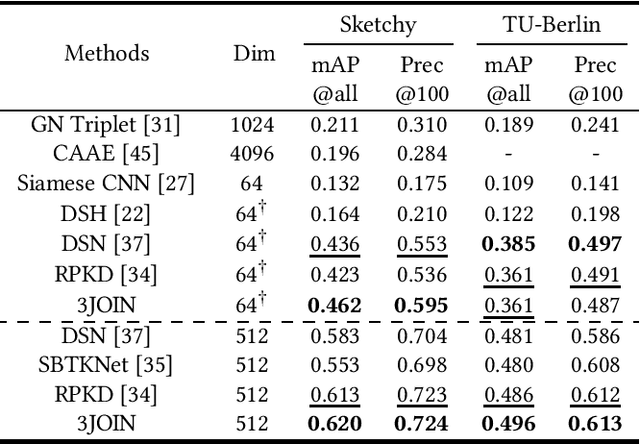
The Zero-Shot Sketch-based Image Retrieval (ZS-SBIR) is a challenging task because of the large domain gap between sketches and natural images as well as the semantic inconsistency between seen and unseen categories. Previous literature bridges seen and unseen categories by semantic embedding, which requires prior knowledge of the exact class names and additional extraction efforts. And most works reduce domain gap by mapping sketches and natural images into a common high-level space using constructed sketch-image pairs, which ignore the unpaired information between images and sketches. To address these issues, in this paper, we propose a novel Three-Stream Joint Training Network (3JOIN) for the ZS-SBIR task. To narrow the domain differences between sketches and images, we extract edge maps for natural images and treat them as a bridge between images and sketches, which have similar content to images and similar style to sketches. For exploiting a sufficient combination of sketches, natural images, and edge maps, a novel three-stream joint training network is proposed. In addition, we use a teacher network to extract the implicit semantics of the samples without the aid of other semantics and transfer the learned knowledge to unseen classes. Extensive experiments conducted on two real-world datasets demonstrate the superiority of our proposed method.
ACORT: A Compact Object Relation Transformer for Parameter Efficient Image Captioning
Feb 11, 2022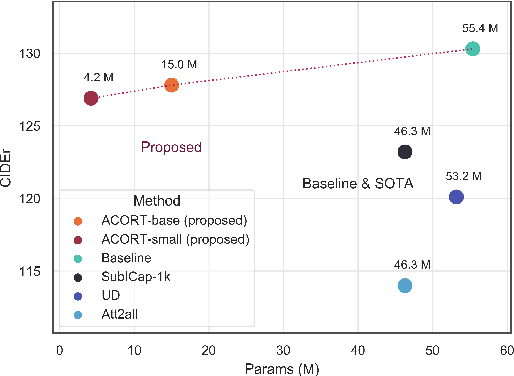
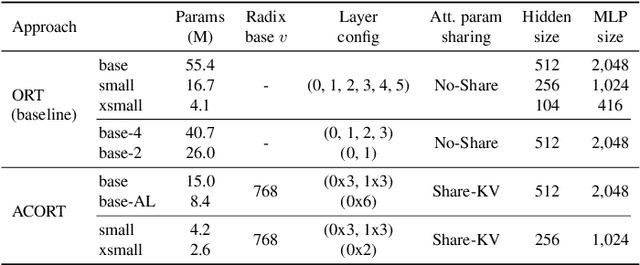
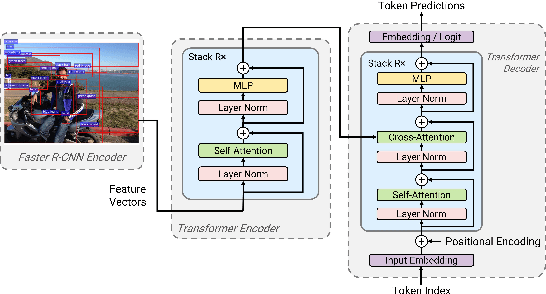
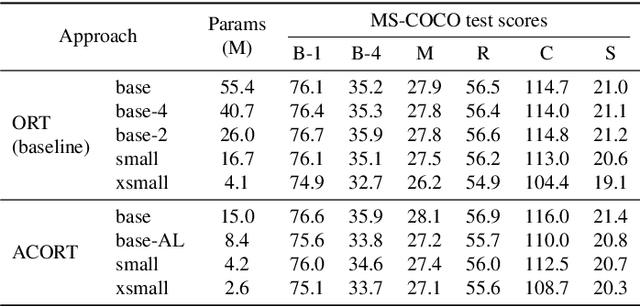
Recent research that applies Transformer-based architectures to image captioning has resulted in state-of-the-art image captioning performance, capitalising on the success of Transformers on natural language tasks. Unfortunately, though these models work well, one major flaw is their large model sizes. To this end, we present three parameter reduction methods for image captioning Transformers: Radix Encoding, cross-layer parameter sharing, and attention parameter sharing. By combining these methods, our proposed ACORT models have 3.7x to 21.6x fewer parameters than the baseline model without compromising test performance. Results on the MS-COCO dataset demonstrate that our ACORT models are competitive against baselines and SOTA approaches, with CIDEr score >=126. Finally, we present qualitative results and ablation studies to demonstrate the efficacy of the proposed changes further. Code and pre-trained models are publicly available at https://github.com/jiahuei/sparse-image-captioning.
Moving from 2D to 3D: volumetric medical image classification for rectal cancer staging
Sep 13, 2022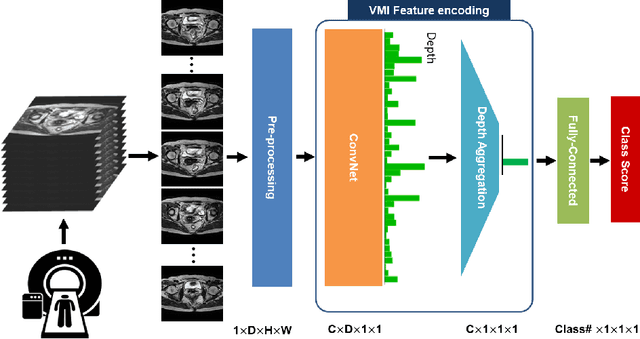
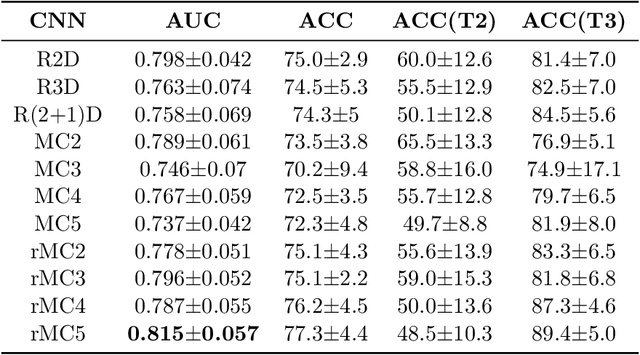
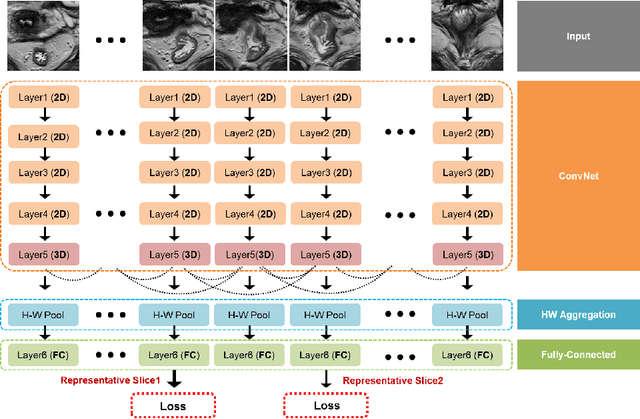

Volumetric images from Magnetic Resonance Imaging (MRI) provide invaluable information in preoperative staging of rectal cancer. Above all, accurate preoperative discrimination between T2 and T3 stages is arguably both the most challenging and clinically significant task for rectal cancer treatment, as chemo-radiotherapy is usually recommended to patients with T3 (or greater) stage cancer. In this study, we present a volumetric convolutional neural network to accurately discriminate T2 from T3 stage rectal cancer with rectal MR volumes. Specifically, we propose 1) a custom ResNet-based volume encoder that models the inter-slice relationship with late fusion (i.e., 3D convolution at the last layer), 2) a bilinear computation that aggregates the resulting features from the encoder to create a volume-wise feature, and 3) a joint minimization of triplet loss and focal loss. With MR volumes of pathologically confirmed T2/T3 rectal cancer, we perform extensive experiments to compare various designs within the framework of residual learning. As a result, our network achieves an AUC of 0.831, which is higher than the reported accuracy of the professional radiologist groups. We believe this method can be extended to other volume analysis tasks
Boost CTR Prediction for New Advertisements via Modeling Visual Content
Sep 23, 2022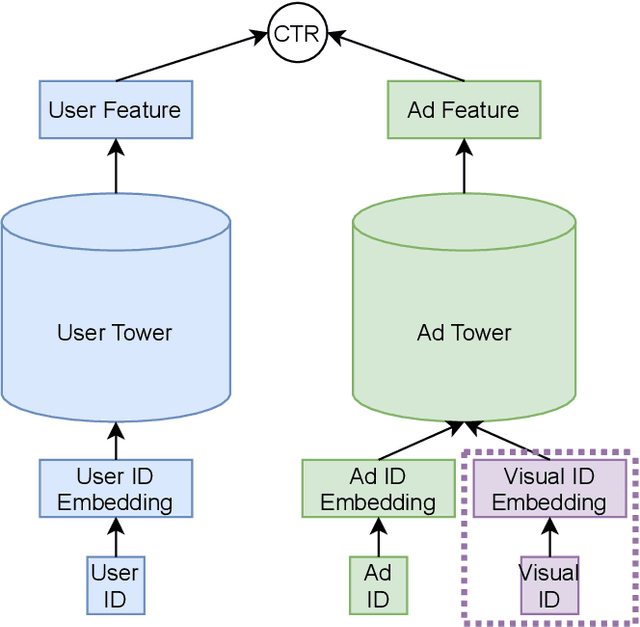
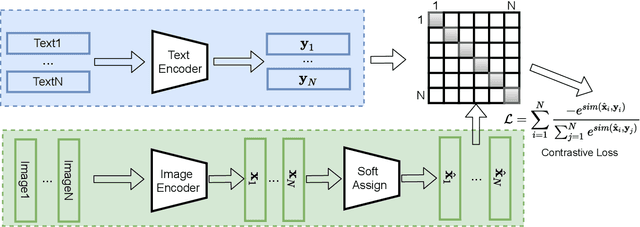
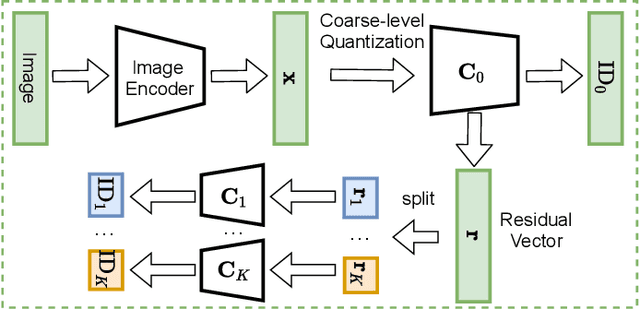
Existing advertisements click-through rate (CTR) prediction models are mainly dependent on behavior ID features, which are learned based on the historical user-ad interactions. Nevertheless, behavior ID features relying on historical user behaviors are not feasible to describe new ads without previous interactions with users. To overcome the limitations of behavior ID features in modeling new ads, we exploit the visual content in ads to boost the performance of CTR prediction models. Specifically, we map each ad into a set of visual IDs based on its visual content. These visual IDs are further used for generating the visual embedding for enhancing CTR prediction models. We formulate the learning of visual IDs into a supervised quantization problem. Due to a lack of class labels for commercial images in advertisements, we exploit image textual descriptions as the supervision to optimize the image extractor for generating effective visual IDs. Meanwhile, since the hard quantization is non-differentiable, we soften the quantization operation to make it support the end-to-end network training. After mapping each image into visual IDs, we learn the embedding for each visual ID based on the historical user-ad interactions accumulated in the past. Since the visual ID embedding depends only on the visual content, it generalizes well to new ads. Meanwhile, the visual ID embedding complements the ad behavior ID embedding. Thus, it can considerably boost the performance of the CTR prediction models previously relying on behavior ID features for both new ads and ads that have accumulated rich user behaviors. After incorporating the visual ID embedding in the CTR prediction model of Baidu online advertising, the average CTR of ads improves by 1.46%, and the total charge increases by 1.10%.
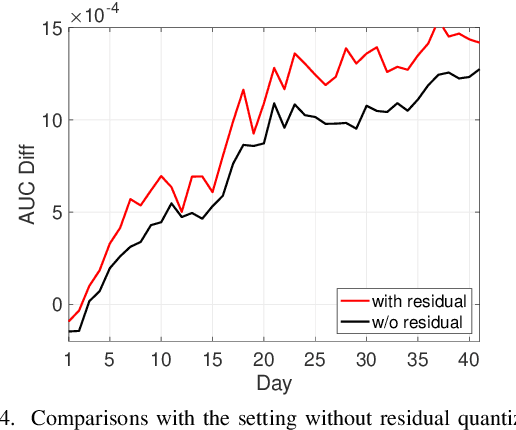
LBF:Learnable Bilateral Filter For Point Cloud Denoising
Oct 28, 2022
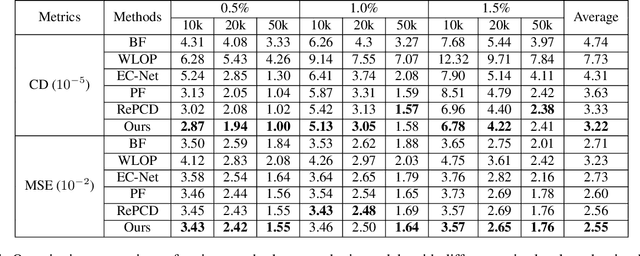
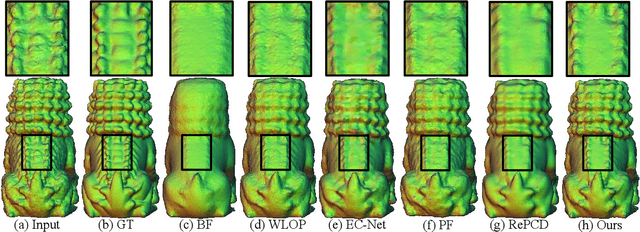
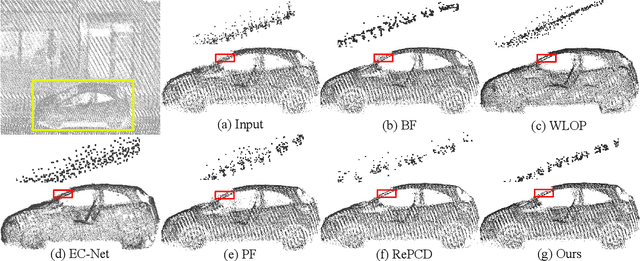
Bilateral filter (BF) is a fast, lightweight and effective tool for image denoising and well extended to point cloud denoising. However, it often involves continual yet manual parameter adjustment; this inconvenience discounts the efficiency and user experience to obtain satisfied denoising results. We propose LBF, an end-to-end learnable bilateral filtering network for point cloud denoising; to our knowledge, this is the first time. Unlike the conventional BF and its variants that receive the same parameters for a whole point cloud, LBF learns adaptive parameters for each point according its geometric characteristic (e.g., corner, edge, plane), avoiding remnant noise, wrongly-removed geometric details, and distorted shapes. Besides the learnable paradigm of BF, we have two cores to facilitate LBF. First, different from the local BF, LBF possesses a global-scale feature perception ability by exploiting multi-scale patches of each point. Second, LBF formulates a geometry-aware bi-directional projection loss, leading the denoising results to being faithful to their underlying surfaces. Users can apply our LBF without any laborious parameter tuning to achieve the optimal denoising results. Experiments show clear improvements of LBF over its competitors on both synthetic and real-scanned datasets.
Combined Data and Deep Learning Model Uncertainties: An Application to the Measurement of Solid Fuel Regression Rate
Oct 25, 2022


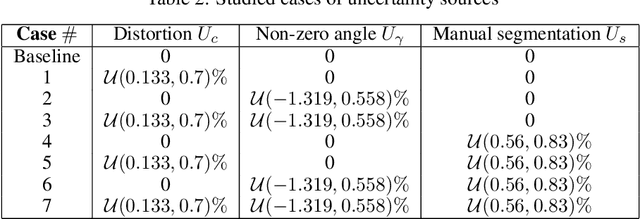
In complex physical process characterization, such as the measurement of the regression rate for solid hybrid rocket fuels, where both the observation data and the model used have uncertainties originating from multiple sources, combining these in a systematic way for quantities of interest(QoI) remains a challenge. In this paper, we present a forward propagation uncertainty quantification (UQ) process to produce a probabilistic distribution for the observed regression rate $\dot{r}$. We characterized two input data uncertainty sources from the experiment (the distortion from the camera $U_c$ and the non-zero angle fuel placement $U_\gamma$), the prediction and model form uncertainty from the deep neural network ($U_m$), as well as the variability from the manually segmented images used for training it ($U_s$). We conducted seven case studies on combinations of these uncertainty sources with the model form uncertainty. The main contribution of this paper is the investigation and inclusion of the experimental image data uncertainties involved, and how to include them in a workflow when the QoI is the result of multiple sequential processes.
Removing Radio Frequency Interference from Auroral Kilometric Radiation with Stacked Autoencoders
Oct 25, 2022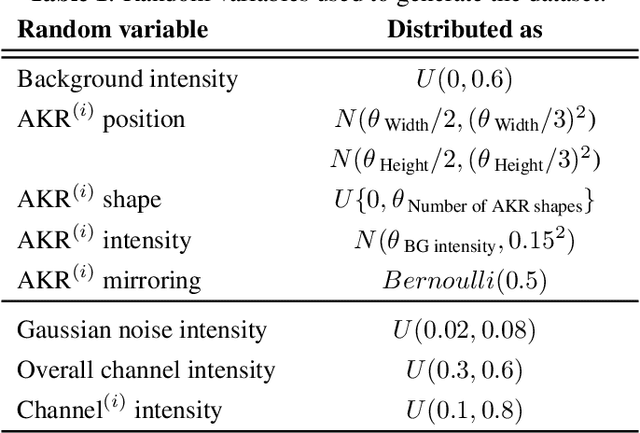
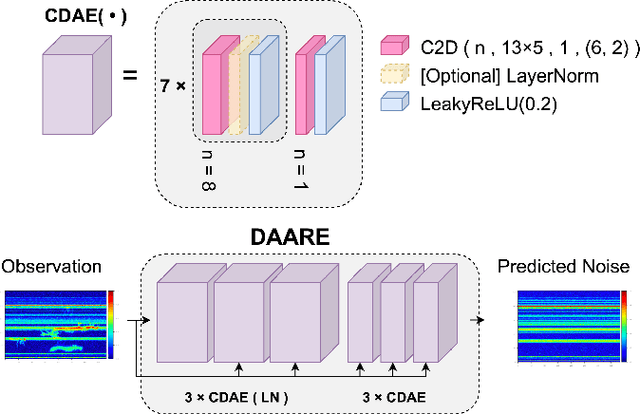


Radio frequency data in astronomy enable scientists to analyze astrophysical phenomena. However, these data can be corrupted by a host of radio frequency interference (RFI) sources that limit the ability to observe underlying natural processes. In this study, we extended recent work in image processing to remove RFI from time-frequency spectrograms containing auroral kilometric radiation (AKR), a coherent radio emission originating from the Earth's auroral zones that is used to study astrophysical plasmas. We present a Denoising Autoencoder for Auroral Radio Emissions (DAARE) trained with synthetic spectrograms to denoise AKR spectrograms collected at the South Pole Station. DAARE achieved 42.2 peak-signal-to-noise ratio (PSNR) and 0.981 structural similarity (SSIM) on synthesized AKR observations, improving PSNR by 3.9 and SSIM by 0.064 compared to state-of-the-art filtering and denoising networks. Qualitative comparisons demonstrate DAARE's denoising capability to effectively remove RFI from real AKR observations, despite being trained completely on a dataset of simulated AKR. The framework for simulating AKR, training DAARE, and employing DAARE can be accessed at https://github.com/Cylumn/daare.
Image Reconstruction from Events. Why learn it?
Dec 12, 2021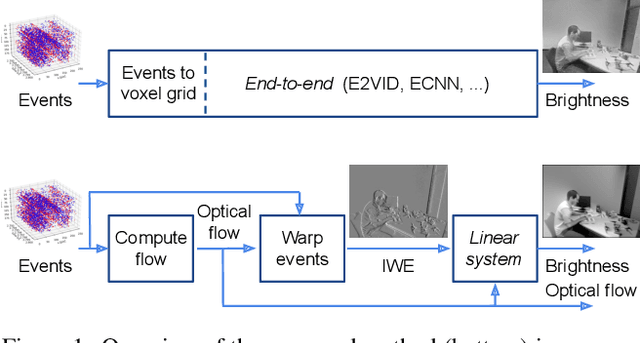
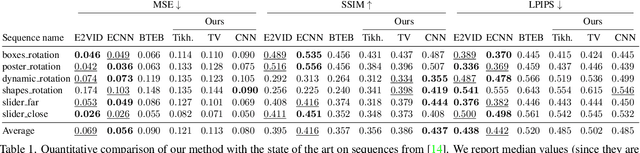

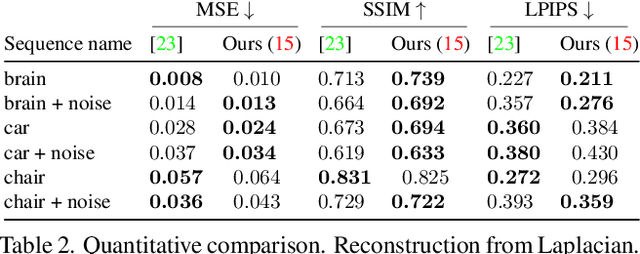
Traditional cameras measure image intensity. Event cameras, by contrast, measure per-pixel temporal intensity changes asynchronously. Recovering intensity from events is a popular research topic since the reconstructed images inherit the high dynamic range (HDR) and high-speed properties of events; hence they can be used in many robotic vision applications and to generate slow-motion HDR videos. However, state-of-the-art methods tackle this problem by training an event-to-image recurrent neural network (RNN), which lacks explainability and is difficult to tune. In this work we show, for the first time, how tackling the joint problem of motion and intensity estimation leads us to model event-based image reconstruction as a linear inverse problem that can be solved without training an image reconstruction RNN. Instead, classical and learning-based image priors can be used to solve the problem and remove artifacts from the reconstructed images. The experiments show that the proposed approach generates images with visual quality on par with state-of-the-art methods despite only using data from a short time interval (i.e., without recurrent connections). Our method can also be used to improve the quality of images reconstructed by approaches that first estimate the image Laplacian; here our method can be interpreted as Poisson reconstruction guided by image priors.
Trap and Replace: Defending Backdoor Attacks by Trapping Them into an Easy-to-Replace Subnetwork
Oct 12, 2022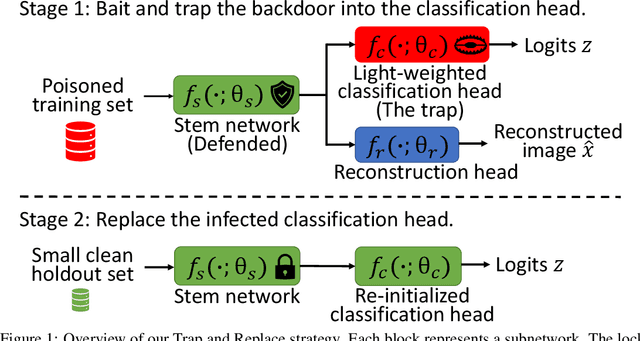
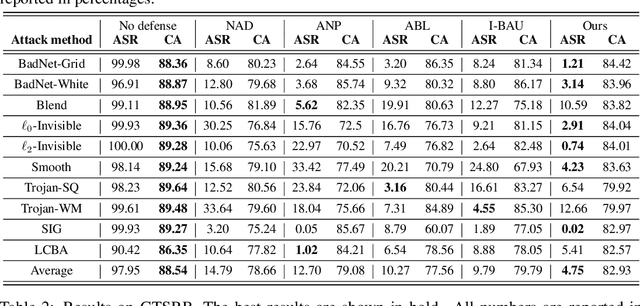
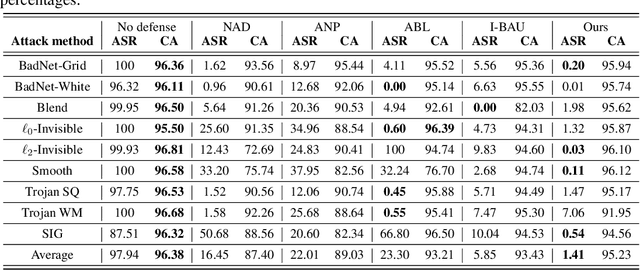
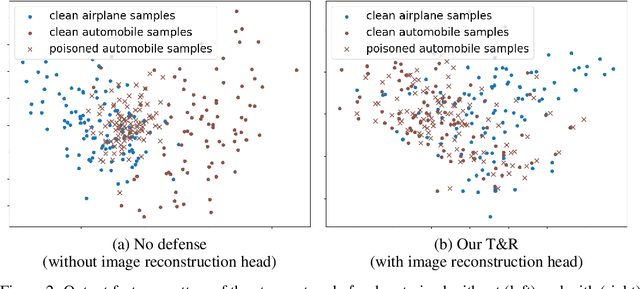
Deep neural networks (DNNs) are vulnerable to backdoor attacks. Previous works have shown it extremely challenging to unlearn the undesired backdoor behavior from the network, since the entire network can be affected by the backdoor samples. In this paper, we propose a brand-new backdoor defense strategy, which makes it much easier to remove the harmful influence of backdoor samples from the model. Our defense strategy, \emph{Trap and Replace}, consists of two stages. In the first stage, we bait and trap the backdoors in a small and easy-to-replace subnetwork. Specifically, we add an auxiliary image reconstruction head on top of the stem network shared with a light-weighted classification head. The intuition is that the auxiliary image reconstruction task encourages the stem network to keep sufficient low-level visual features that are hard to learn but semantically correct, instead of overfitting to the easy-to-learn but semantically incorrect backdoor correlations. As a result, when trained on backdoored datasets, the backdoors are easily baited towards the unprotected classification head, since it is much more vulnerable than the shared stem, leaving the stem network hardly poisoned. In the second stage, we replace the poisoned light-weighted classification head with an untainted one, by re-training it from scratch only on a small holdout dataset with clean samples, while fixing the stem network. As a result, both the stem and the classification head in the final network are hardly affected by backdoor training samples. We evaluate our method against ten different backdoor attacks. Our method outperforms previous state-of-the-art methods by up to $20.57\%$, $9.80\%$, and $13.72\%$ attack success rate and on-average $3.14\%$, $1.80\%$, and $1.21\%$ clean classification accuracy on CIFAR10, GTSRB, and ImageNet-12, respectively. Code is available online.