 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OhMG: Zero-shot Open-vocabulary Human Motion Generation
Oct 28, 2022
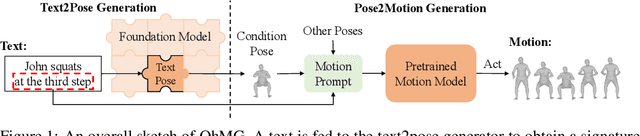

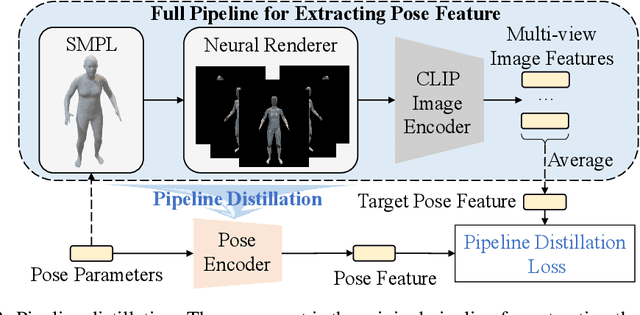
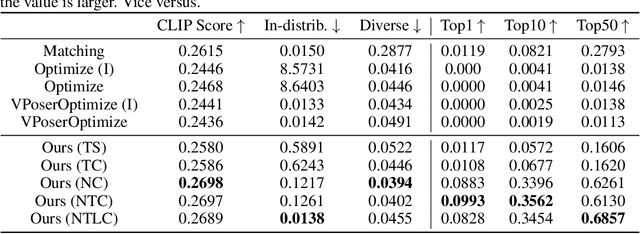
Generating motion in line with text has attracted increasing attention nowadays. However, open-vocabulary human motion generation still remains touchless and undergoes the lack of diverse labeled data. The good news is that, recent studies of large multi-model foundation models (e.g., CLIP) have demonstrated superior performance on few/zero-shot image-text alignment, largely reducing the need for manually labeled data. In this paper, we take advantage of CLIP for open-vocabulary 3D human motion generation in a zero-shot manner. Specifically, our model is composed of two stages, i.e., text2pose and pose2motion. For text2pose, to address the difficulty of optimization with direct supervision from CLIP, we propose to carve the versatile CLIP model into a slimmer but more specific model for aligning 3D poses and texts, via a novel pipeline distillation strategy. Optimizing with the distilled 3D pose-text model, we manage to concretize the text-pose knowledge of CLIP into a text2pose generator effectively and efficiently. As for pose2motion, drawing inspiration from the advanced language model, we pretrain a transformer-based motion model, which makes up for the lack of motion dynamics of CLIP. After that, by formulating the generated poses from the text2pose stage as prompts, the motion generator can generate motions referring to the poses in a controllable and flexible manner. Our method is validated against advanced baselines and obtains sharp improvements. The code will be released here.
Multispectral image fusion by super pixel statistics
Dec 21, 2021
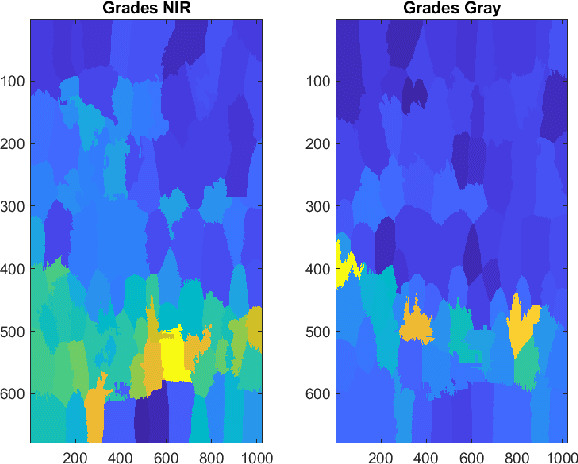
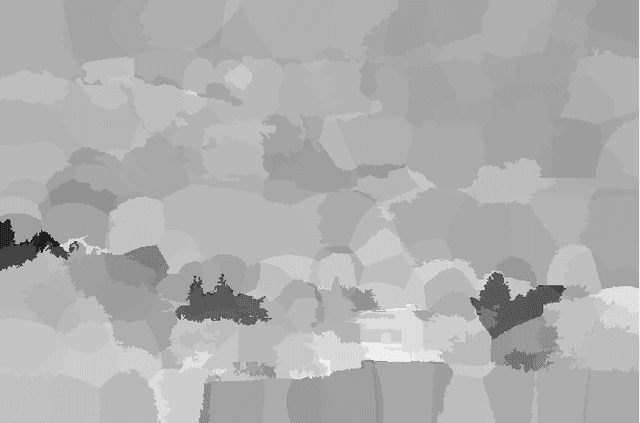

Multispectral image fusion is a fundamental problem of remote sensing and image processing. This problem is addressed by both classic and deep learning approaches. This paper is focused on the classic solutions and introduces a new novel approach to this family. The proposed method carries out multispectral image fusion based on the content of the fused images. It relies on analysis based on the level of information on segmented superpixels in the fused inputs. Specifically, I address the task of visible color RGB to Near-Infrared (NIR) fusion. The RGB image captures the color of the scene while the NIR captures details and sees beyond haze and clouds. Since each channel senses different information of the scene, their fusion is challenging and interesting. The proposed method is designed to produce a fusion that contains both advantages of each spectra. This manuscript experiments show that the proposed method is visually informative with respect to other classic fusion methods which can be run fastly on embedded devices with no need for heavy computation resources.
Evaluation of 3D GANs for Lung Tissue Modelling in Pulmonary CT
Aug 17, 2022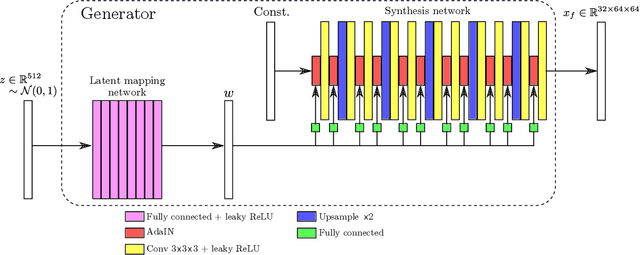
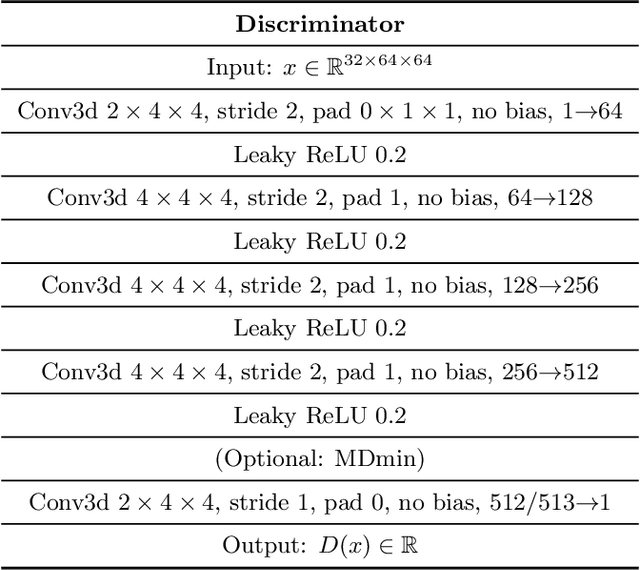
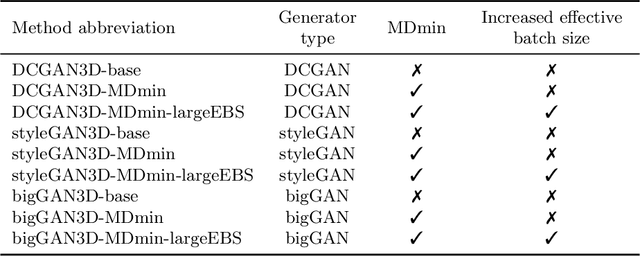

GANs are able to model accurately the distribution of complex, high-dimensional datasets, e.g. images. This makes high-quality GANs useful for unsupervised anomaly detection in medical imaging. However, differences in training datasets such as output image dimensionality and appearance of semantically meaningful features mean that GAN models from the natural image domain may not work `out-of-the-box' for medical imaging, necessitating re-implementation and re-evaluation. In this work we adapt and evaluate three GAN models to the task of modelling 3D healthy image patches for pulmonary CT. To the best of our knowledge, this is the first time that such an evaluation has been performed. The DCGAN, styleGAN and the bigGAN architectures were investigated due to their ubiquity and high performance in natural image processing. We train different variants of these methods and assess their performance using the FID score. In addition, the quality of the generated images was evaluated by a human observer study, the ability of the networks to model 3D domain-specific features was investigated, and the structure of the GAN latent spaces was analysed. Results show that the 3D styleGAN produces realistic-looking images with meaningful 3D structure, but suffer from mode collapse which must be addressed during training to obtain samples diversity. Conversely, the 3D DCGAN models show a greater capacity for image variability, but at the cost of poor-quality images. The 3D bigGAN models provide an intermediate level of image quality, but most accurately model the distribution of selected semantically meaningful features. The results suggest that future development is required to realise a 3D GAN with sufficient capacity for patch-based lung CT anomaly detection and we offer recommendations for future areas of research, such as experimenting with other architectures and incorporation of position-encoding.
DRT: A Lightweight Single Image Deraining Recursive Transformer
Apr 25, 2022
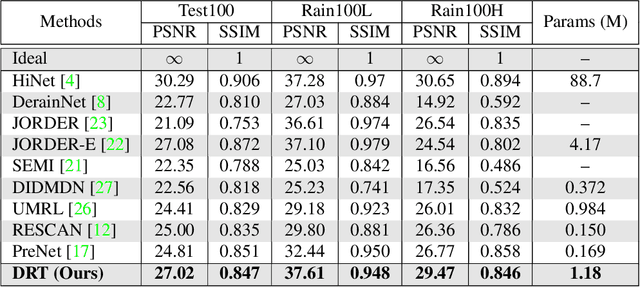
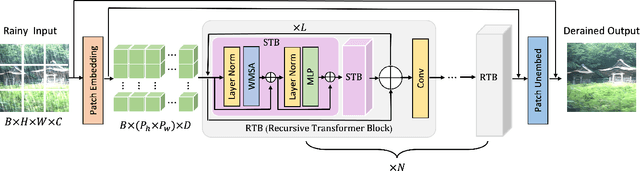
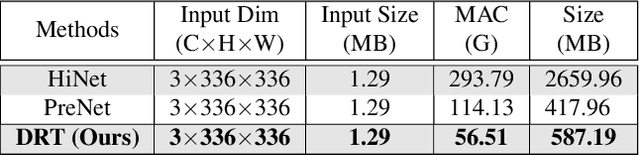
Over parameterization is a common technique in deep learning to help models learn and generalize sufficiently to the given task; nonetheless, this often leads to enormous network structures and consumes considerable computing resources during training. Recent powerful transformer-based deep learning models on vision tasks usually have heavy parameters and bear training difficulty. However, many dense-prediction low-level computer vision tasks, such as rain streak removing, often need to be executed on devices with limited computing power and memory in practice. Hence, we introduce a recursive local window-based self-attention structure with residual connections and propose deraining a recursive transformer (DRT), which enjoys the superiority of the transformer but requires a small amount of computing resources. In particular, through recursive architecture, our proposed model uses only 1.3% of the number of parameters of the current best performing model in deraining while exceeding the state-of-the-art methods on the Rain100L benchmark by at least 0.33 dB. Ablation studies also investigate the impact of recursions on derain outcomes. Moreover, since the model contains no deliberate design for deraining, it can also be applied to other image restoration tasks. Our experiment shows that it can achieve competitive results on desnowing. The source code and pretrained model can be found at https://github.com/YC-Liang/DRT.
Anomaly Detection using Generative Models and Sum-Product Networks in Mammography Scans
Oct 12, 2022Unsupervised anomaly detection models which are trained solely by healthy data, have gained importance in the recent years, as the annotation of medical data is a tedious task. Autoencoders and generative adversarial networks are the standard anomaly detection methods that are utilized to learn the data distribution. However, they fall short when it comes to inference and evaluation of the likelihood of test samples. We propose a novel combination of generative models and a probabilistic graphical model. After encoding image samples by autoencoders, the distribution of data is modeled by Random and Tensorized Sum-Product Networks ensuring exact and efficient inference at test time. We evaluate different autoencoder architectures in combination with Random and Tensorized Sum-Product Networks on mammography images using patch-wise processing and observe superior performance over utilizing the models standalone and state-of-the-art in anomaly detection for medical data.
* Submitted to DGM4MICCAI 2022 Workshop. This preprint has not undergone peer review (when applicable) or any post-submission improvements or corrections. The Version of Record of this contribution is published in LNCS 13609, and is available online at https://doi.org/10.1007/978-3-031-18576-2_8
Face recognition via compact second order image gradient orientations
Jan 29, 2022
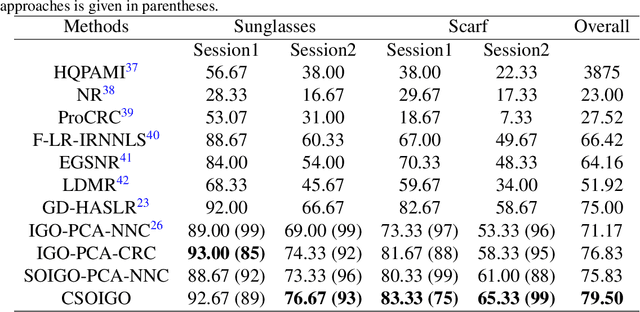

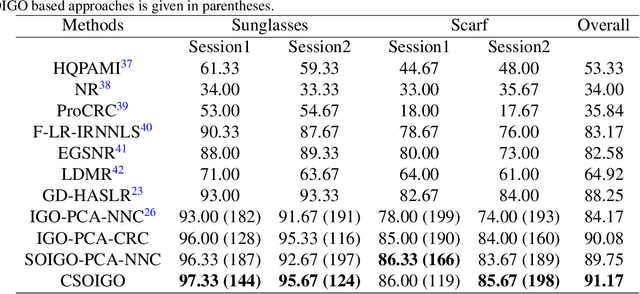
Conventional subspace learning approaches based on image gradient orientations only employ the first-order gradient information. However, recent researches on human vision system (HVS) uncover that the neural image is a landscape or a surface whose geometric properties can be captured through the second order gradient information. The second order image gradient orientations (SOIGO) can mitigate the adverse effect of noises in face images. To reduce the redundancy of SOIGO, we propose compact SOIGO (CSOIGO) by applying linear complex principal component analysis (PCA) in SOIGO. Combined with collaborative representation based classification (CRC) algorithm, the classification performance of CSOIGO is further enhanced. CSOIGO is evaluated under real-world disguise, synthesized occlusion and mixed variations. Experimental results indicate that the proposed method is superior to its competing approaches with few training samples, and even outperforms some prevailing deep neural network based approaches. The source code of CSOIGO is available at https://github.com/yinhefeng/SOIGO.
Plug-and-Play VQA: Zero-shot VQA by Conjoining Large Pretrained Models with Zero Training
Oct 17, 2022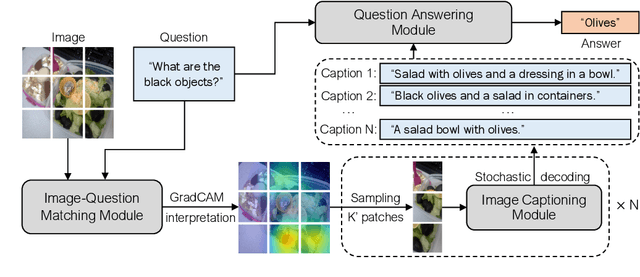
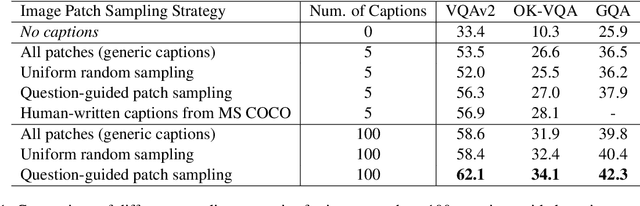

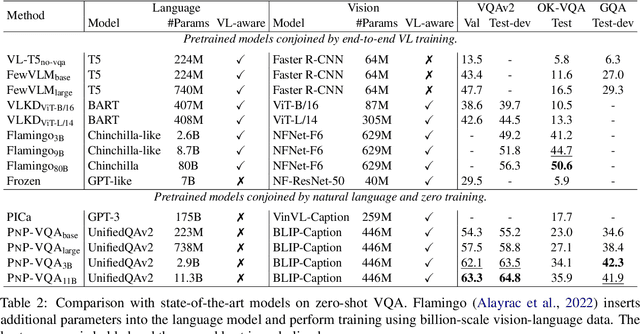
Visual question answering (VQA) is a hallmark of vision and language reasoning and a challenging task under the zero-shot setting. We propose Plug-and-Play VQA (PNP-VQA), a modular framework for zero-shot VQA. In contrast to most existing works, which require substantial adaptation of pretrained language models (PLMs) for the vision modality, PNP-VQA requires no additional training of the PLMs. Instead, we propose to use natural language and network interpretation as an intermediate representation that glues pretrained models together. We first generate question-guided informative image captions, and pass the captions to a PLM as context for question answering. Surpassing end-to-end trained baselines, PNP-VQA achieves state-of-the-art results on zero-shot VQAv2 and GQA. With 11B parameters, it outperforms the 80B-parameter Flamingo model by 8.5% on VQAv2. With 738M PLM parameters, PNP-VQA achieves an improvement of 9.1% on GQA over FewVLM with 740M PLM parameters. Code is released at https://github.com/salesforce/LAVIS/tree/main/projects/pnp-vqa
A Transfer Learning Based Approach for Classification of COVID-19 and Pneumonia in CT Scan Imaging
Oct 17, 2022
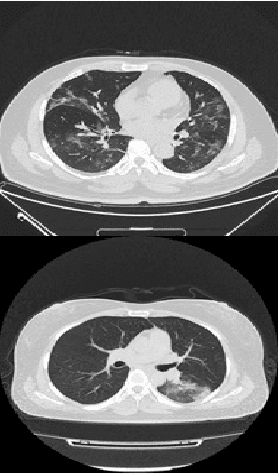
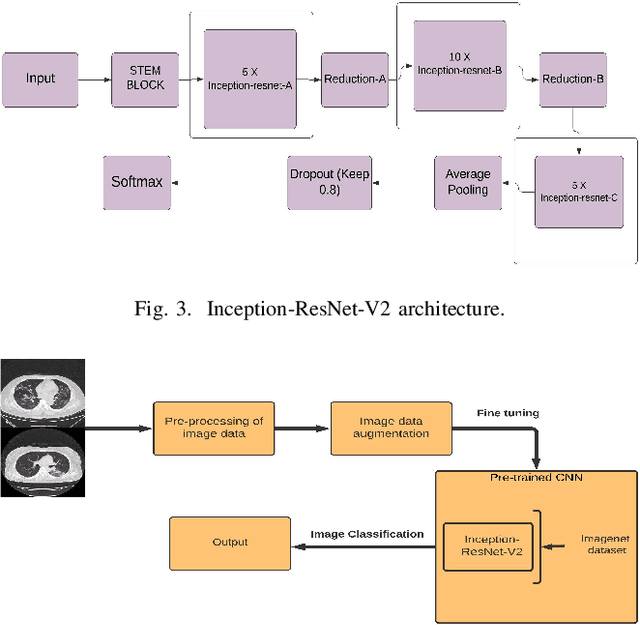
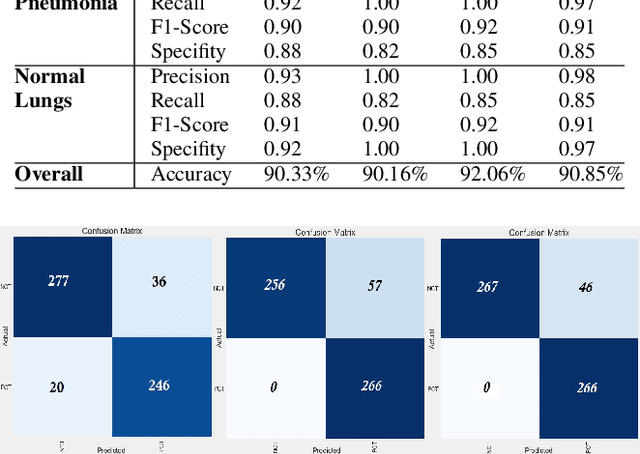
The world is still overwhelmed by the spread of the COVID-19 virus. With over 250 Million infected cases as of November 2021 and affecting 219 countries and territories, the world remains in the pandemic period. Detecting COVID-19 using the deep learning method on CT scan images can play a vital role in assisting medical professionals and decision authorities in controlling the spread of the disease and providing essential support for patients. The convolution neural network is widely used in the field of large-scale image recognition. The current method of RT-PCR to diagnose COVID-19 is time-consuming and universally limited. This research aims to propose a deep learning-based approach to classify COVID-19 pneumonia patients, bacterial pneumonia, viral pneumonia, and healthy (normal cases). This paper used deep transfer learning to classify the data via Inception-ResNet-V2 neural network architecture. The proposed model has been intentionally simplified to reduce the implementation cost so that it can be easily implemented and used in different geographical areas, especially rural and developing regions.
DEArt: Dataset of European Art
Nov 03, 2022

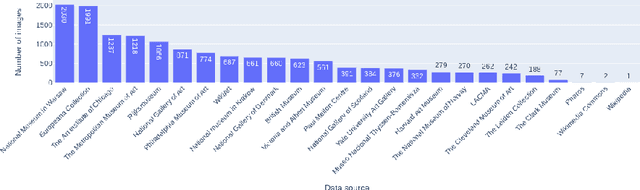

Large datasets that were made publicly available to the research community over the last 20 years have been a key enabling factor for the advances in deep learning algorithms for NLP or computer vision. These datasets are generally pairs of aligned image / manually annotated metadata, where images are photographs of everyday life. Scholarly and historical content, on the other hand, treat subjects that are not necessarily popular to a general audience, they may not always contain a large number of data points, and new data may be difficult or impossible to collect. Some exceptions do exist, for instance, scientific or health data, but this is not the case for cultural heritage (CH). The poor performance of the best models in computer vision - when tested over artworks - coupled with the lack of extensively annotated datasets for CH, and the fact that artwork images depict objects and actions not captured by photographs, indicate that a CH-specific dataset would be highly valuable for this community. We propose DEArt, at this point primarily an object detection and pose classification dataset meant to be a reference for paintings between the XIIth and the XVIIIth centuries. It contains more than 15000 images, about 80% non-iconic, aligned with manual annotations for the bounding boxes identifying all instances of 69 classes as well as 12 possible poses for boxes identifying human-like objects. Of these, more than 50 classes are CH-specific and thus do not appear in other datasets; these reflect imaginary beings, symbolic entities and other categories related to art. Additionally, existing datasets do not include pose annotations. Our results show that object detectors for the cultural heritage domain can achieve a level of precision comparable to state-of-art models for generic images via transfer learning.
TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition
Oct 20, 2022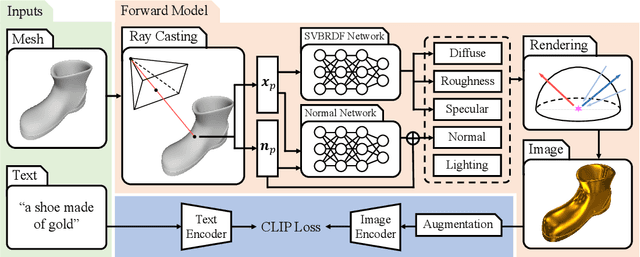



Creation of 3D content by stylization is a promising yet challenging problem in computer vision and graphics research. In this work, we focus on stylizing photorealistic appearance renderings of a given surface mesh of arbitrary topology. Motivated by the recent surge of cross-modal supervision of the Contrastive Language-Image Pre-training (CLIP) model, we propose TANGO, which transfers the appearance style of a given 3D shape according to a text prompt in a photorealistic manner. Technically, we propose to disentangle the appearance style as the spatially varying bidirectional reflectance distribution function, the local geometric variation, and the lighting condition, which are jointly optimized, via supervision of the CLIP loss, by a spherical Gaussians based differentiable renderer. As such, TANGO enables photorealistic 3D style transfer by automatically predicting reflectance effects even for bare, low-quality meshes, without training on a task-specific dataset. Extensive experiments show that TANGO outperforms existing methods of text-driven 3D style transfer in terms of photorealistic quality, consistency of 3D geometry, and robustness when stylizing low-quality meshes. Our codes and results are available at our project webpage https://cyw-3d.github.io/tango/.