 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Imaging with Equivariant Deep Learning
Sep 05, 2022
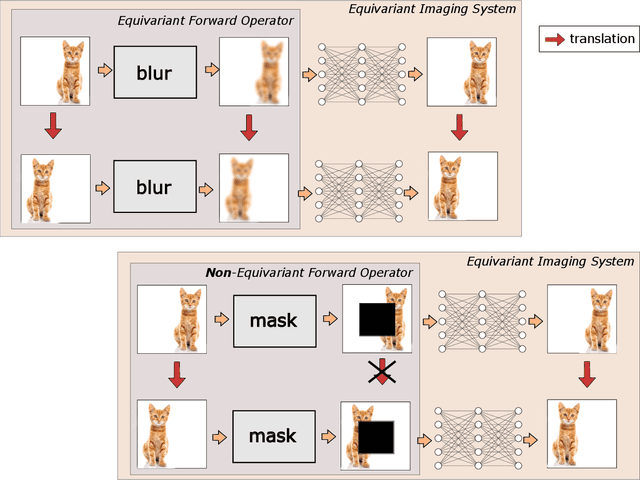


From early image processing to modern computational imaging, successful models and algorithms have relied on a fundamental property of natural signals: symmetry. Here symmetry refers to the invariance property of signal sets to transformations such as translation, rotation or scaling. Symmetry can also be incorporated into deep neural networks in the form of equivariance, allowing for more data-efficient learning. While there has been important advances in the design of end-to-end equivariant networks for image classification in recent years, computational imaging introduces unique challenges for equivariant network solutions since we typically only observe the image through some noisy ill-conditioned forward operator that itself may not be equivariant. We review the emerging field of equivariant imaging and show how it can provide improved generalization and new imaging opportunities. Along the way we show the interplay between the acquisition physics and group actions and links to iterative reconstruction, blind compressed sensing and self-supervised learning.
Combining Image Space and q-Space PDEs for Lossless Compression of Diffusion MR Images
Jun 14, 2022
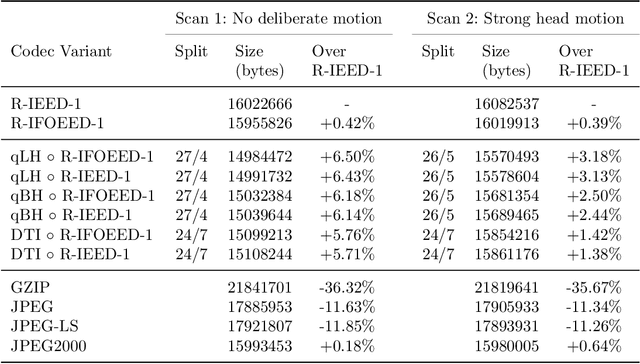
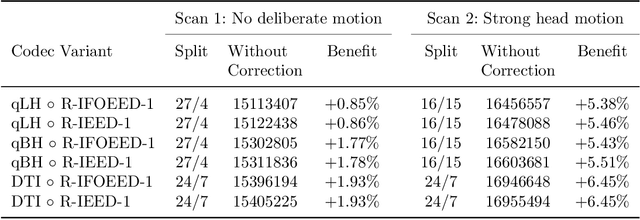
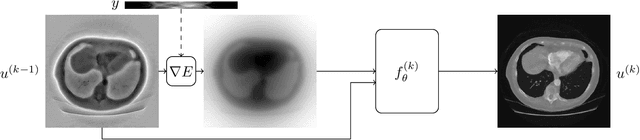
Diffusion MRI is a modern neuroimaging modality with a unique ability to acquire microstructural information by measuring water self-diffusion at the voxel level. However, it generates huge amounts of data, resulting from a large number of repeated 3D scans. Each volume samples a location in q-space, indicating the direction and strength of a diffusion sensitizing gradient during the measurement. This captures detailed information about the self-diffusion, and the tissue microstructure that restricts it. Lossless compression with GZIP is widely used to reduce the memory requirements. We introduce a novel lossless codec for diffusion MRI data. It reduces file sizes by more than 30% compared to GZIP, and also beats lossless codecs from the JPEG family. Our codec builds on recent work on lossless PDE-based compression of 3D medical images, but additionally exploits smoothness in q-space. We demonstrate that, compared to using only image space PDEs, q-space PDEs further improve compression rates. Moreover, implementing them with Finite Element Methods and a custom acceleration significantly reduces computational expense. Finally, we show that our codec clearly benefits from integrating subject motion correction, and slightly from optimizing the order in which the 3D volumes are coded.
NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations
May 09, 2022

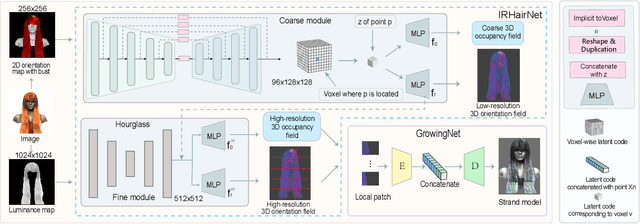

Undoubtedly, high-fidelity 3D hair plays an indispensable role in digital humans. However, existing monocular hair modeling methods are either tricky to deploy in digital systems (e.g., due to their dependence on complex user interactions or large databases) or can produce only a coarse geometry. In this paper, we introduce NeuralHDHair, a flexible, fully automatic system for modeling high-fidelity hair from a single image. The key enablers of our system are two carefully designed neural networks: an IRHairNet (Implicit representation for hair using neural network) for inferring high-fidelity 3D hair geometric features (3D orientation field and 3D occupancy field) hierarchically and a GrowingNet(Growing hair strands using neural network) to efficiently generate 3D hair strands in parallel. Specifically, we perform a coarse-to-fine manner and propose a novel voxel-aligned implicit function (VIFu) to represent the global hair feature, which is further enhanced by the local details extracted from a hair luminance map. To improve the efficiency of a traditional hair growth algorithm, we adopt a local neural implicit function to grow strands based on the estimated 3D hair geometric features. Extensive experiments show that our method is capable of constructing a high-fidelity 3D hair model from a single image, both efficiently and effectively, and achieves the-state-of-the-art performance.
Noise-reducing attention cross fusion learning transformer for histological image classification of osteosarcoma
Apr 29, 2022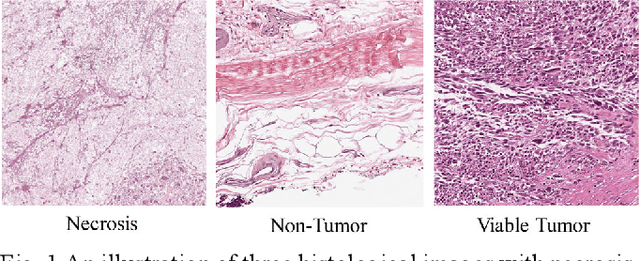
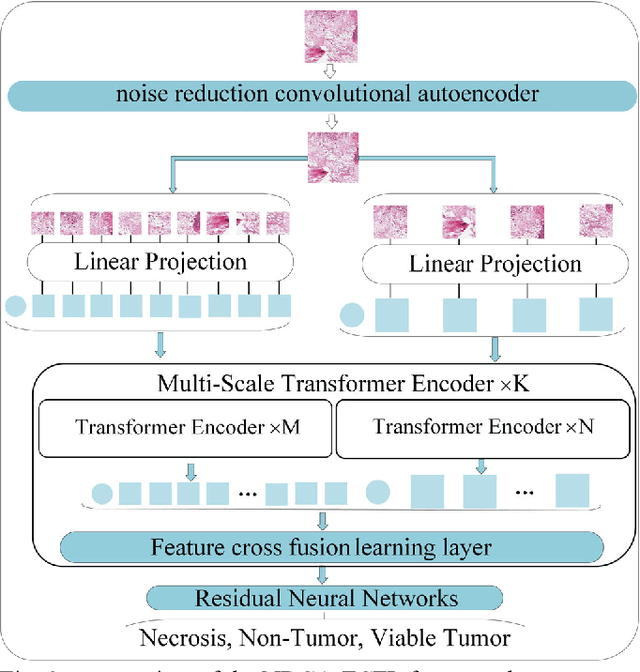
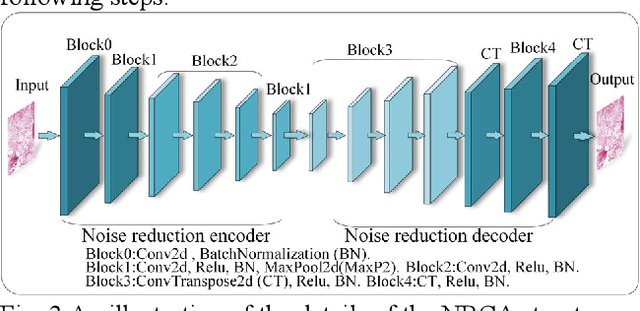
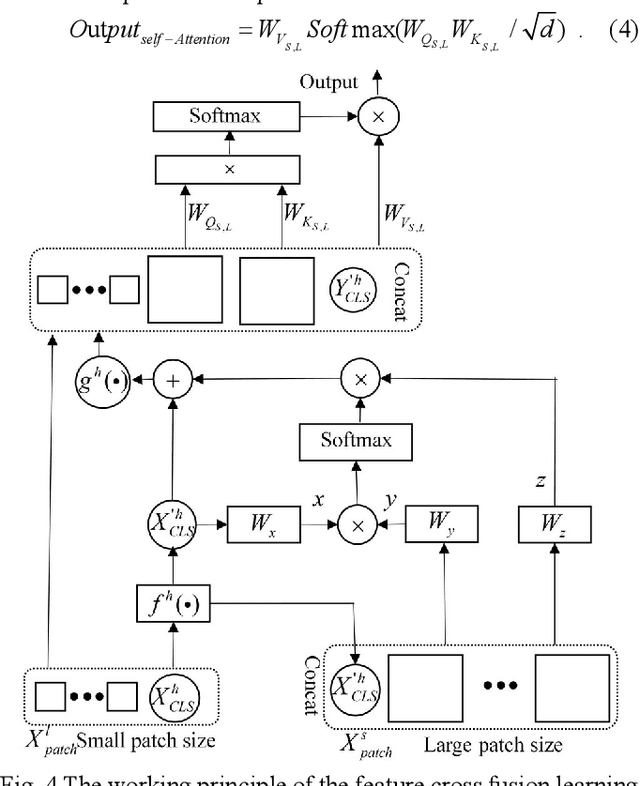
The degree of malignancy of osteosarcoma and its tendency to metastasize/spread mainly depend on the pathological grade (determined by observing the morphology of the tumor under a microscope). The purpose of this study is to use artificial intelligence to classify osteosarcoma histological images and to assess tumor survival and necrosis, which will help doctors reduce their workload, improve the accuracy of osteosarcoma cancer detection, and make a better prognosis for patients. The study proposes a typical transformer image classification framework by integrating noise reduction convolutional autoencoder and feature cross fusion learning (NRCA-FCFL) to classify osteosarcoma histological images. Noise reduction convolutional autoencoder could well denoise histological images of osteosarcoma, resulting in more pure images for osteosarcoma classification. Moreover, we introduce feature cross fusion learning, which integrates two scale image patches, to sufficiently explore their interactions by using additional classification tokens. As a result, a refined fusion feature is generated, which is fed to the residual neural network for label predictions. We conduct extensive experiments to evaluate the performance of the proposed approach. The experimental results demonstrate that our method outperforms the traditional and deep learning approaches on various evaluation metrics, with an accuracy of 99.17% to support osteosarcoma diagnosis.
Supervised GAN Watermarking for Intellectual Property Protection
Sep 07, 2022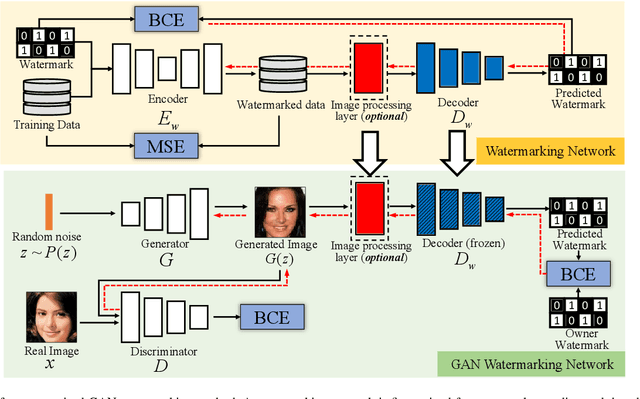

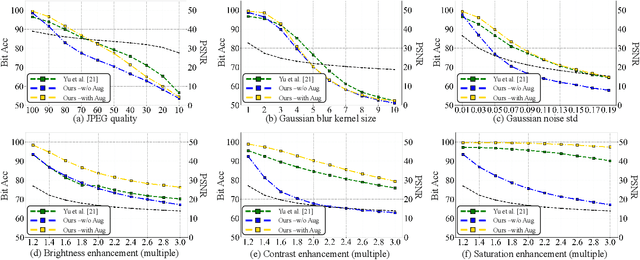

We propose a watermarking method for protecting the Intellectual Property (IP) of Generative Adversarial Networks (GANs). The aim is to watermark the GAN model so that any image generated by the GAN contains an invisible watermark (signature), whose presence inside the image can be checked at a later stage for ownership verification. To achieve this goal, a pre-trained CNN watermarking decoding block is inserted at the output of the generator. The generator loss is then modified by including a watermark loss term, to ensure that the prescribed watermark can be extracted from the generated images. The watermark is embedded via fine-tuning, with reduced time complexity. Results show that our method can effectively embed an invisible watermark inside the generated images. Moreover, our method is a general one and can work with different GAN architectures, different tasks, and different resolutions of the output image. We also demonstrate the good robustness performance of the embedded watermark against several post-processing, among them, JPEG compression, noise addition, blurring, and color transformations.
Local and Global GANs with Semantic-Aware Upsampling for Image Generation
Feb 28, 2022
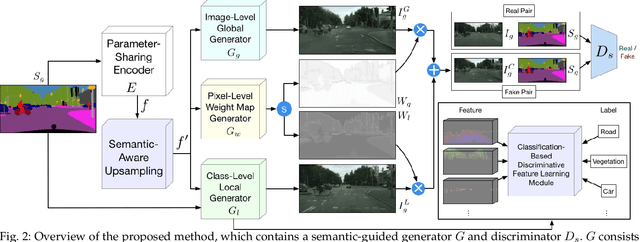
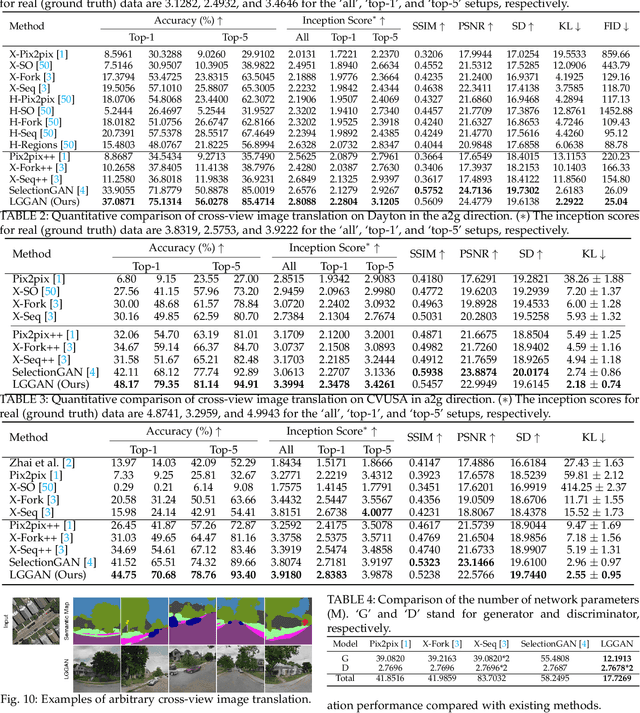
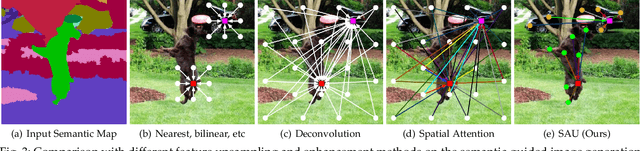
In this paper, we address the task of semantic-guided image generation. One challenge common to most existing image-level generation methods is the difficulty in generating small objects and detailed local textures. To address this, in this work we consider generating images using local context. As such, we design a local class-specific generative network using semantic maps as guidance, which separately constructs and learns subgenerators for different classes, enabling it to capture finer details. To learn more discriminative class-specific feature representations for the local generation, we also propose a novel classification module. To combine the advantages of both global image-level and local class-specific generation, a joint generation network is designed with an attention fusion module and a dual-discriminator structure embedded. Lastly, we propose a novel semantic-aware upsampling method, which has a larger receptive field and can take far-away pixels that are semantically related for feature upsampling, enabling it to better preserve semantic consistency for instances with the same semantic labels. Extensive experiments on two image generation tasks show the superior performance of the proposed method. State-of-the-art results are established by large margins on both tasks and on nine challenging public benchmarks. The source code and trained models are available at https://github.com/Ha0Tang/LGGAN.
Learning Hierarchical Graph Representation for Image Manipulation Detection
Jan 15, 2022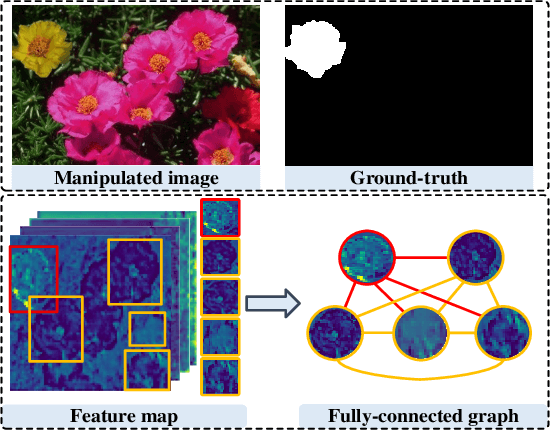
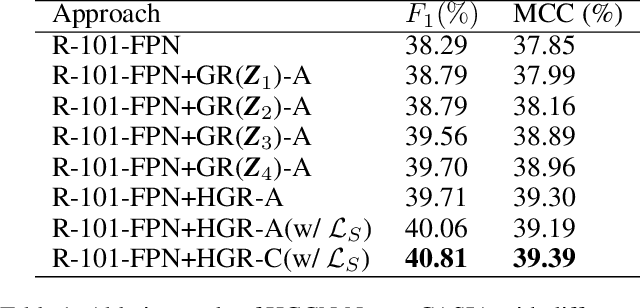
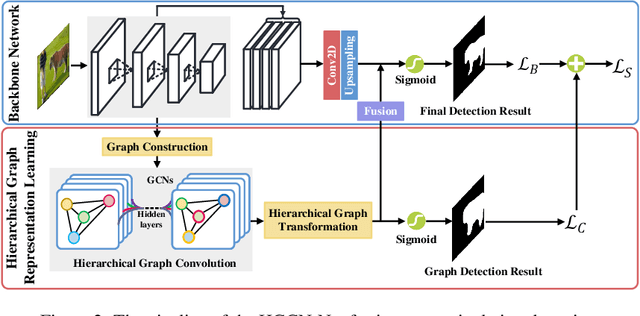
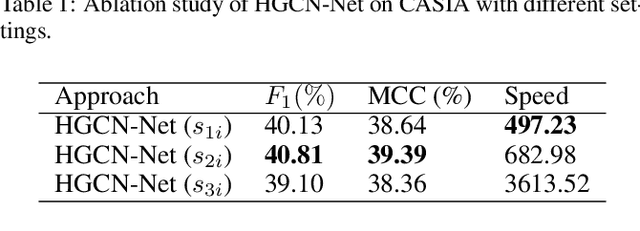
The objective of image manipulation detection is to identify and locate the manipulated regions in the images. Recent approaches mostly adopt the sophisticated Convolutional Neural Networks (CNNs) to capture the tampering artifacts left in the images to locate the manipulated regions. However, these approaches ignore the feature correlations, i.e., feature inconsistencies, between manipulated regions and non-manipulated regions, leading to inferior detection performance. To address this issue, we propose a hierarchical Graph Convolutional Network (HGCN-Net), which consists of two parallel branches: the backbone network branch and the hierarchical graph representation learning (HGRL) branch for image manipulation detection. Specifically, the feature maps of a given image are extracted by the backbone network branch, and then the feature correlations within the feature maps are modeled as a set of fully-connected graphs for learning the hierarchical graph representation by the HGRL branch. The learned hierarchical graph representation can sufficiently capture the feature correlations across different scales, and thus it provides high discriminability for distinguishing manipulated and non-manipulated regions. Extensive experiments on four public datasets demonstrate that the proposed HGCN-Net not only provides promising detection accuracy, but also achieves strong robustness under a variety of common image attacks in the task of image manipulation detection, compared to the state-of-the-arts.
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 14, 2022



Image-Text matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
Improving trajectory calculations using deep learning inspired single image superresolution
Jun 07, 2022

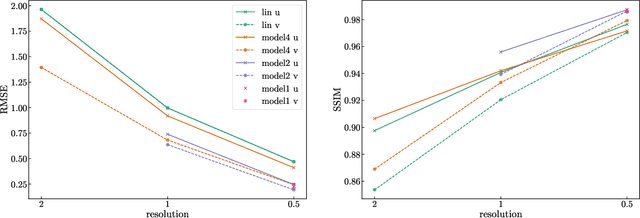

Lagrangian trajectory or particle dispersion models as well as semi-Lagrangian advection schemes require meteorological data such as wind, temperature and geopotential at the exact spatio-temporal locations of the particles that move independently from a regular grid. Traditionally, this high-resolution data has been obtained by interpolating the meteorological parameters from the gridded data of a meteorological model or reanalysis, e.g. using linear interpolation in space and time. However, interpolation errors are a large source of error for these models. Reducing them requires meteorological input fields with high space and time resolution, which may not always be available and can cause severe data storage and transfer problems. Here, we interpret this problem as a single image superresolution task. We interpret meteorological fields available at their native resolution as low-resolution images and train deep neural networks to up-scale them to higher resolution, thereby providing more accurate data for Lagrangian models. We train various versions of the state-of-the-art Enhanced Deep Residual Networks for Superresolution on low-resolution ERA5 reanalysis data with the goal to up-scale these data to arbitrary spatial resolution. We show that the resulting up-scaled wind fields have root-mean-squared errors half the size of the winds obtained with linear spatial interpolation at acceptable computational inference costs. In a test setup using the Lagrangian particle dispersion model FLEXPART and reduced-resolution wind fields, we demonstrate that absolute horizontal transport deviations of calculated trajectories from "ground-truth" trajectories calculated with undegraded 0.5{\deg} winds are reduced by at least 49.5% (21.8%) after 48 hours relative to trajectories using linear interpolation of the wind data when training on 2{\deg} to 1{\deg} (4{\deg} to 2{\deg}) resolution data.
A training-free recursive multiresolution framework for diffeomorphic deformable image registration
Feb 01, 2022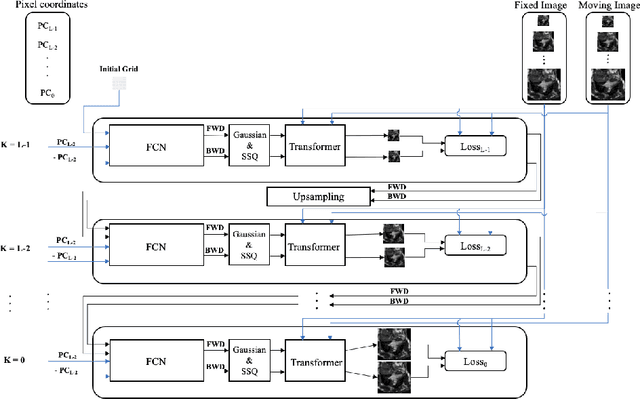
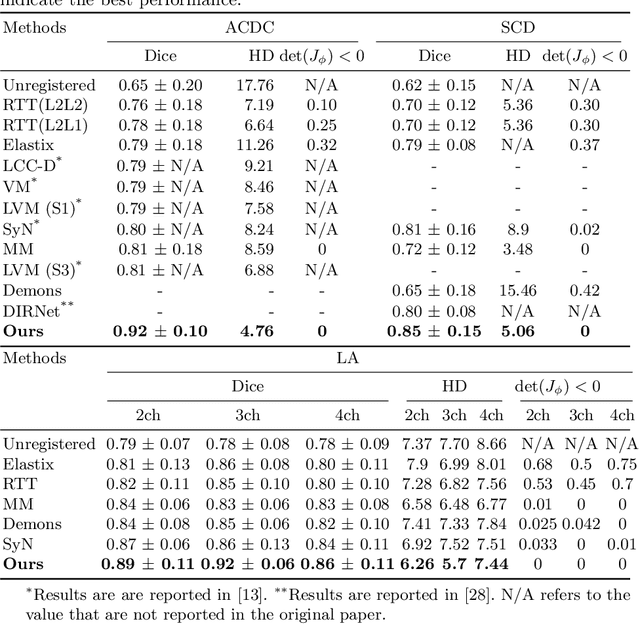
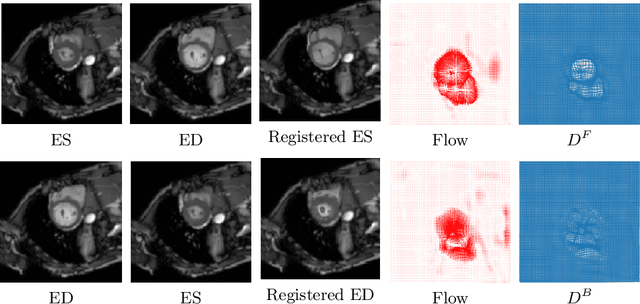
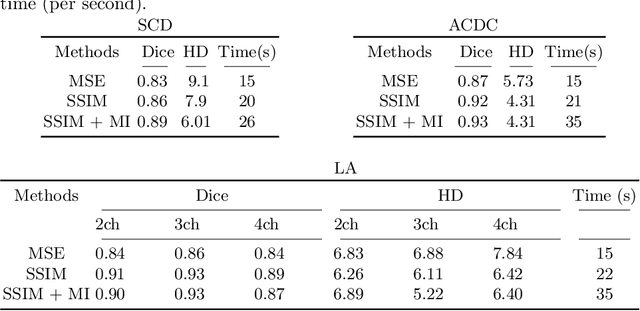
Diffeomorphic deformable image registration is one of the crucial tasks in medical image analysis, which aims to find a unique transformation while preserving the topology and invertibility of the transformation. Deep convolutional neural networks (CNNs) have yielded well-suited approaches for image registration by learning the transformation priors from a large dataset. The improvement in the performance of these methods is related to their ability to learn information from several sample medical images that are difficult to obtain and bias the framework to the specific domain of data. In this paper, we propose a novel diffeomorphic training-free approach; this is built upon the principle of an ordinary differential equation. Our formulation yields an Euler integration type recursive scheme to estimate the changes of spatial transformations between the fixed and the moving image pyramids at different resolutions. The proposed architecture is simple in design. The moving image is warped successively at each resolution and finally aligned to the fixed image; this procedure is recursive in a way that at each resolution, a fully convolutional network (FCN) models a progressive change of deformation for the current warped image. The entire system is end-to-end and optimized for each pair of images from scratch. In comparison to learning-based methods, the proposed method neither requires a dedicated training set nor suffers from any training bias. We evaluate our method on three cardiac image datasets. The evaluation results demonstrate that the proposed method achieves state-of-the-art registration accuracy while maintaining desirable diffeomorphic properties.