 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Are Classification Robustness and Explanation Robustness Really Strongly Correlated? An Analysis Through Input Loss Landscape
Mar 09, 2024
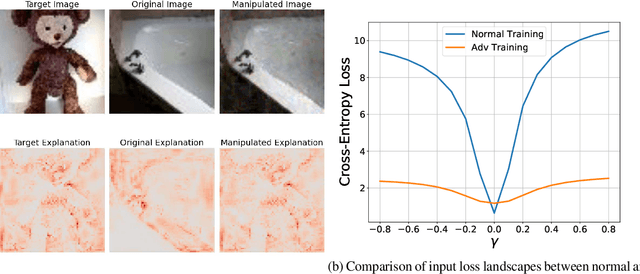
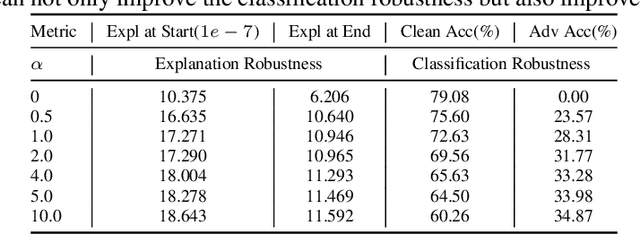
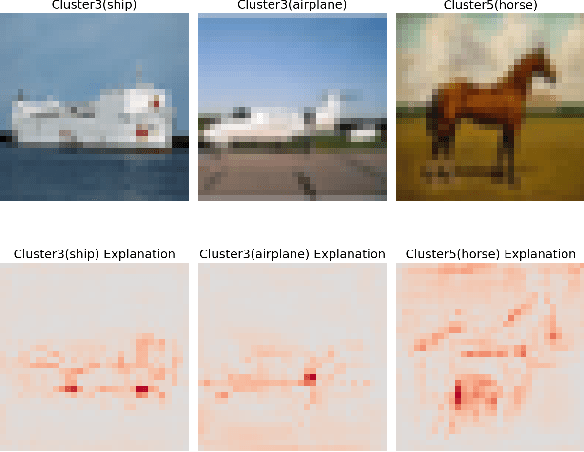
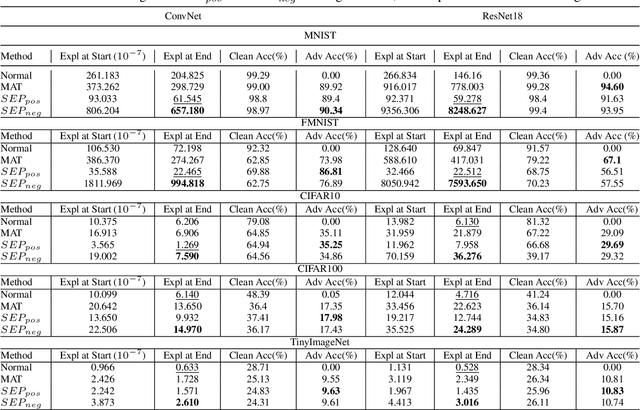
This paper delves into the critical area of deep learning robustness, challenging the conventional belief that classification robustness and explanation robustness in image classification systems are inherently correlated. Through a novel evaluation approach leveraging clustering for efficient assessment of explanation robustness, we demonstrate that enhancing explanation robustness does not necessarily flatten the input loss landscape with respect to explanation loss - contrary to flattened loss landscapes indicating better classification robustness. To deeply investigate this contradiction, a groundbreaking training method designed to adjust the loss landscape with respect to explanation loss is proposed. Through the new training method, we uncover that although such adjustments can impact the robustness of explanations, they do not have an influence on the robustness of classification. These findings not only challenge the prevailing assumption of a strong correlation between the two forms of robustness but also pave new pathways for understanding relationship between loss landscape and explanation loss.
Style Blind Domain Generalized Semantic Segmentation via Covariance Alignment and Semantic Consistence Contrastive Learning
Mar 10, 2024
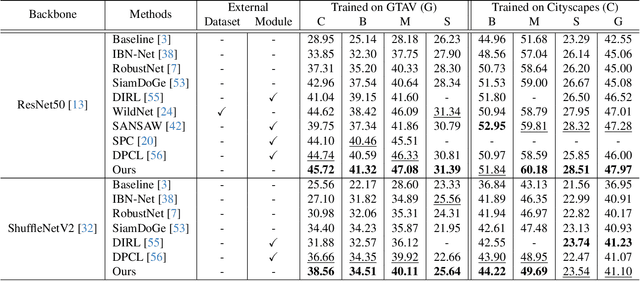
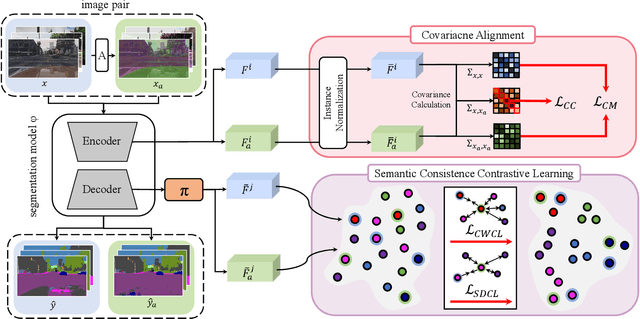
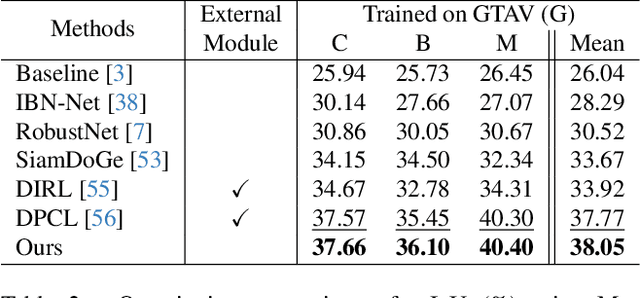
Deep learning models for semantic segmentation often experience performance degradation when deployed to unseen target domains unidentified during the training phase. This is mainly due to variations in image texture (\ie style) from different data sources. To tackle this challenge, existing domain generalized semantic segmentation (DGSS) methods attempt to remove style variations from the feature. However, these approaches struggle with the entanglement of style and content, which may lead to the unintentional removal of crucial content information, causing performance degradation. This study addresses this limitation by proposing BlindNet, a novel DGSS approach that blinds the style without external modules or datasets. The main idea behind our proposed approach is to alleviate the effect of style in the encoder whilst facilitating robust segmentation in the decoder. To achieve this, BlindNet comprises two key components: covariance alignment and semantic consistency contrastive learning. Specifically, the covariance alignment trains the encoder to uniformly recognize various styles and preserve the content information of the feature, rather than removing the style-sensitive factor. Meanwhile, semantic consistency contrastive learning enables the decoder to construct discriminative class embedding space and disentangles features that are vulnerable to misclassification. Through extensive experiments, our approach outperforms existing DGSS methods, exhibiting robustness and superior performance for semantic segmentation on unseen target domains.
A unified framework of non-local parametric methods for image denoising
Feb 21, 2024We propose a unified view of non-local methods for single-image denoising, for which BM3D is the most popular representative, that operate by gathering noisy patches together according to their similarities in order to process them collaboratively. Our general estimation framework is based on the minimization of the quadratic risk, which is approximated in two steps, and adapts to photon and electronic noises. Relying on unbiased risk estimation (URE) for the first step and on ``internal adaptation'', a concept borrowed from deep learning theory, for the second, we show that our approach enables to reinterpret and reconcile previous state-of-the-art non-local methods. Within this framework, we propose a novel denoiser called NL-Ridge that exploits linear combinations of patches. While conceptually simpler, we show that NL-Ridge can outperform well-established state-of-the-art single-image denoisers.
BAGS: Blur Agnostic Gaussian Splatting through Multi-Scale Kernel Modeling
Mar 07, 2024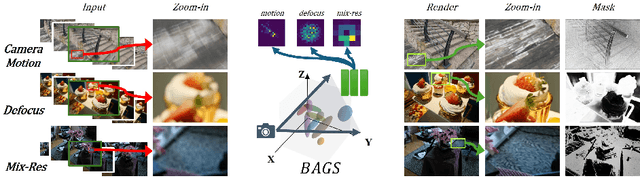
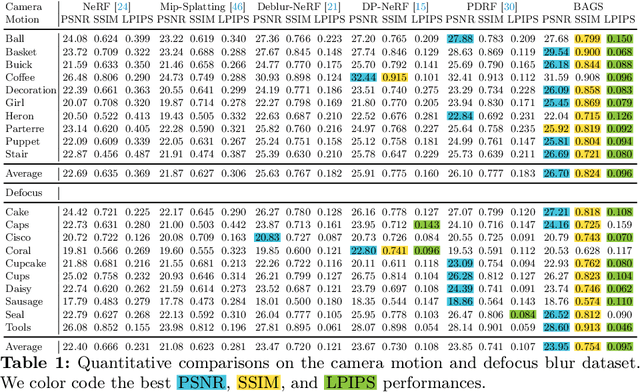
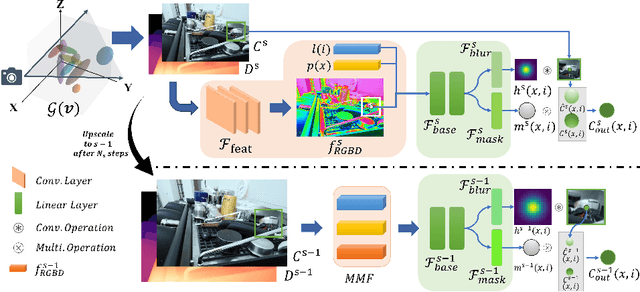

Recent efforts in using 3D Gaussians for scene reconstruction and novel view synthesis can achieve impressive results on curated benchmarks; however, images captured in real life are often blurry. In this work, we analyze the robustness of Gaussian-Splatting-based methods against various image blur, such as motion blur, defocus blur, downscaling blur, \etc. Under these degradations, Gaussian-Splatting-based methods tend to overfit and produce worse results than Neural-Radiance-Field-based methods. To address this issue, we propose Blur Agnostic Gaussian Splatting (BAGS). BAGS introduces additional 2D modeling capacities such that a 3D-consistent and high quality scene can be reconstructed despite image-wise blur. Specifically, we model blur by estimating per-pixel convolution kernels from a Blur Proposal Network (BPN). BPN is designed to consider spatial, color, and depth variations of the scene to maximize modeling capacity. Additionally, BPN also proposes a quality-assessing mask, which indicates regions where blur occur. Finally, we introduce a coarse-to-fine kernel optimization scheme; this optimization scheme is fast and avoids sub-optimal solutions due to a sparse point cloud initialization, which often occurs when we apply Structure-from-Motion on blurry images. We demonstrate that BAGS achieves photorealistic renderings under various challenging blur conditions and imaging geometry, while significantly improving upon existing approaches.
CLIP the Bias: How Useful is Balancing Data in Multimodal Learning?
Mar 07, 2024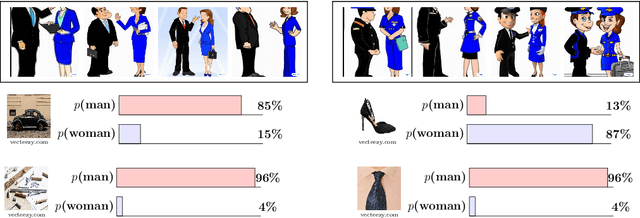
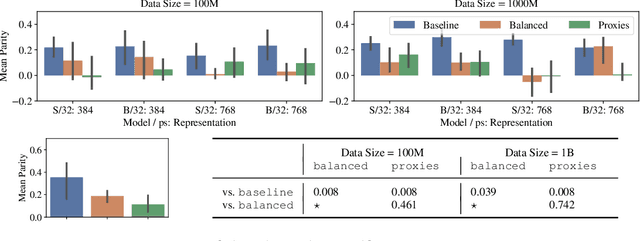

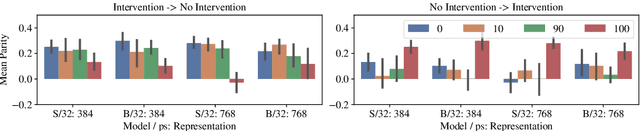
We study the effectiveness of data-balancing for mitigating biases in contrastive language-image pretraining (CLIP), identifying areas of strength and limitation. First, we reaffirm prior conclusions that CLIP models can inadvertently absorb societal stereotypes. To counter this, we present a novel algorithm, called Multi-Modal Moment Matching (M4), designed to reduce both representation and association biases (i.e. in first- and second-order statistics) in multimodal data. We use M4 to conduct an in-depth analysis taking into account various factors, such as the model, representation, and data size. Our study also explores the dynamic nature of how CLIP learns and unlearns biases. In particular, we find that fine-tuning is effective in countering representation biases, though its impact diminishes for association biases. Also, data balancing has a mixed impact on quality: it tends to improve classification but can hurt retrieval. Interestingly, data and architectural improvements seem to mitigate the negative impact of data balancing on performance; e.g. applying M4 to SigLIP-B/16 with data quality filters improves COCO image-to-text retrieval @5 from 86% (without data balancing) to 87% and ImageNet 0-shot classification from 77% to 77.5%! Finally, we conclude with recommendations for improving the efficacy of data balancing in multimodal systems.
* 32 pages, 20 figures, 7 tables
T-TAME: Trainable Attention Mechanism for Explaining Convolutional Networks and Vision Transformers
Mar 07, 2024The development and adoption of Vision Transformers and other deep-learning architectures for image classification tasks has been rapid. However, the "black box" nature of neural networks is a barrier to adoption in applications where explainability is essential. While some techniques for generating explanations have been proposed, primarily for Convolutional Neural Networks, adapting such techniques to the new paradigm of Vision Transformers is non-trivial. This paper presents T-TAME, Transformer-compatible Trainable Attention Mechanism for Explanations, a general methodology for explaining deep neural networks used in image classification tasks. The proposed architecture and training technique can be easily applied to any convolutional or Vision Transformer-like neural network, using a streamlined training approach. After training, explanation maps can be computed in a single forward pass; these explanation maps are comparable to or outperform the outputs of computationally expensive perturbation-based explainability techniques, achieving SOTA performance. We apply T-TAME to three popular deep learning classifier architectures, VGG-16, ResNet-50, and ViT-B-16, trained on the ImageNet dataset, and we demonstrate improvements over existing state-of-the-art explainability methods. A detailed analysis of the results and an ablation study provide insights into how the T-TAME design choices affect the quality of the generated explanation maps.
Beyond Finite Data: Towards Data-free Out-of-distribution Generalization via Extrapolation
Mar 11, 2024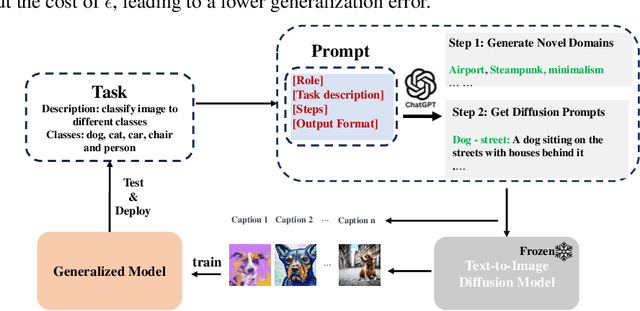
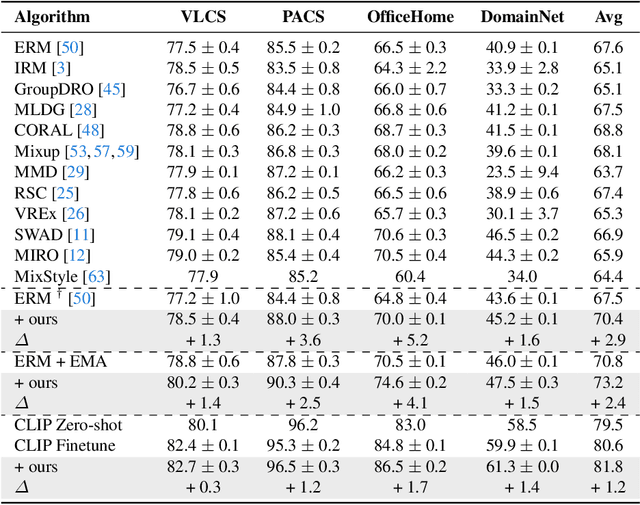
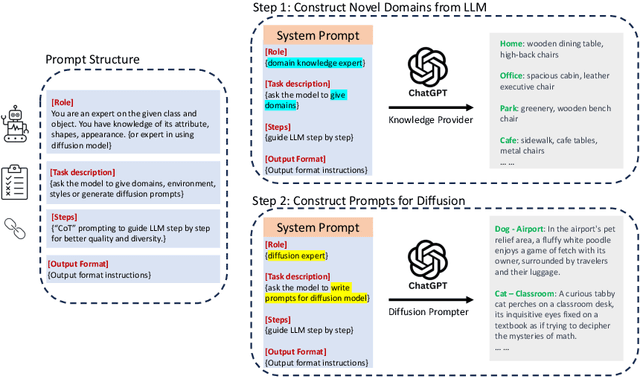
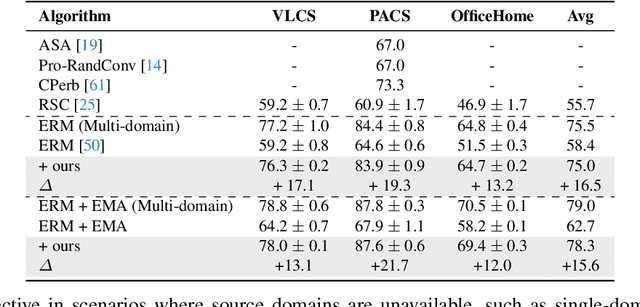
Out-of-distribution (OOD) generalization is a favorable yet challenging property for deep neural networks. The core challenges lie in the limited availability of source domains that help models learn an invariant representation from the spurious features. Various domain augmentation have been proposed but largely rely on interpolating existing domains and frequently face difficulties in creating truly "novel" domains. Humans, on the other hand, can easily extrapolate novel domains, thus, an intriguing question arises: How can neural networks extrapolate like humans and achieve OOD generalization? We introduce a novel approach to domain extrapolation that leverages reasoning ability and the extensive knowledge encapsulated within large language models (LLMs) to synthesize entirely new domains. Starting with the class of interest, we query the LLMs to extract relevant knowledge for these novel domains. We then bridge the gap between the text-centric knowledge derived from LLMs and the pixel input space of the model using text-to-image generation techniques. By augmenting the training set of domain generalization datasets with high-fidelity, photo-realistic images of these new domains, we achieve significant improvements over all existing methods, as demonstrated in both single and multi-domain generalization across various benchmarks. With the ability to extrapolate any domains for any class, our method has the potential to learn a generalized model for any task without any data. To illustrate, we put forth a much more difficult setting termed, data-free domain generalization, that aims to learn a generalized model in the absence of any collected data. Our empirical findings support the above argument and our methods exhibit commendable performance in this setting, even surpassing the supervised setting by approximately 1-2\% on datasets such as VLCS.
VoCo: A Simple-yet-Effective Volume Contrastive Learning Framework for 3D Medical Image Analysis
Feb 27, 2024Self-Supervised Learning (SSL) has demonstrated promising results in 3D medical image analysis. However, the lack of high-level semantics in pre-training still heavily hinders the performance of downstream tasks. We observe that 3D medical images contain relatively consistent contextual position information, i.e., consistent geometric relations between different organs, which leads to a potential way for us to learn consistent semantic representations in pre-training. In this paper, we propose a simple-yet-effective Volume Contrast (VoCo) framework to leverage the contextual position priors for pre-training. Specifically, we first generate a group of base crops from different regions while enforcing feature discrepancy among them, where we employ them as class assignments of different regions. Then, we randomly crop sub-volumes and predict them belonging to which class (located at which region) by contrasting their similarity to different base crops, which can be seen as predicting contextual positions of different sub-volumes. Through this pretext task, VoCo implicitly encodes the contextual position priors into model representations without the guidance of annotations, enabling us to effectively improve the performance of downstream tasks that require high-level semantics. Extensive experimental results on six downstream tasks demonstrate the superior effectiveness of VoCo. Code will be available at https://github.com/Luffy03/VoCo.
FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View
Mar 05, 2024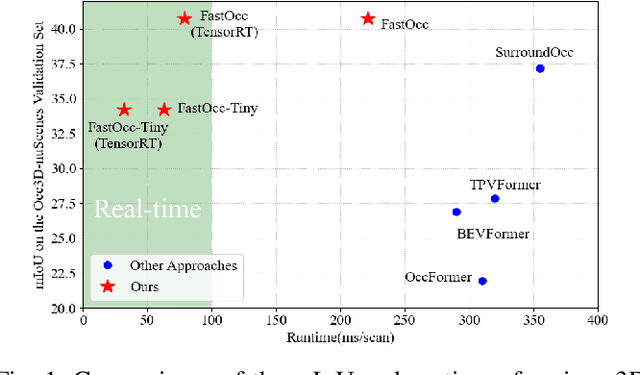
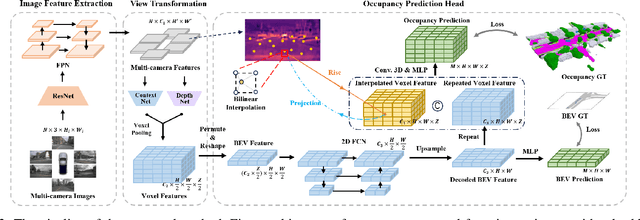
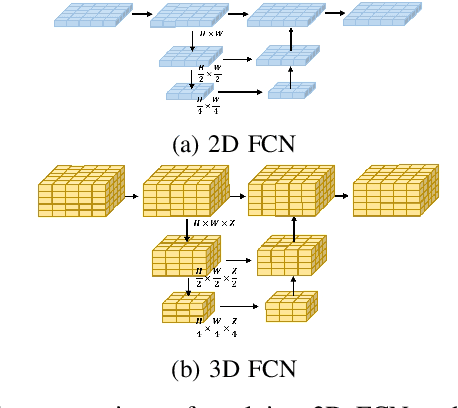
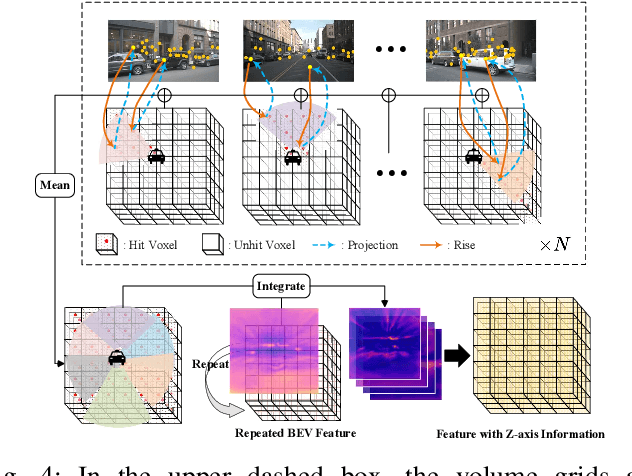
In autonomous driving, 3D occupancy prediction outputs voxel-wise status and semantic labels for more comprehensive understandings of 3D scenes compared with traditional perception tasks, such as 3D object detection and bird's-eye view (BEV) semantic segmentation. Recent researchers have extensively explored various aspects of this task, including view transformation techniques, ground-truth label generation, and elaborate network design, aiming to achieve superior performance. However, the inference speed, crucial for running on an autonomous vehicle, is neglected. To this end, a new method, dubbed FastOcc, is proposed. By carefully analyzing the network effect and latency from four parts, including the input image resolution, image backbone, view transformation, and occupancy prediction head, it is found that the occupancy prediction head holds considerable potential for accelerating the model while keeping its accuracy. Targeted at improving this component, the time-consuming 3D convolution network is replaced with a novel residual-like architecture, where features are mainly digested by a lightweight 2D BEV convolution network and compensated by integrating the 3D voxel features interpolated from the original image features. Experiments on the Occ3D-nuScenes benchmark demonstrate that our FastOcc achieves state-of-the-art results with a fast inference speed.
Robust Surgical Tool Tracking with Pixel-based Probabilities for Projected Geometric Primitives
Mar 08, 2024
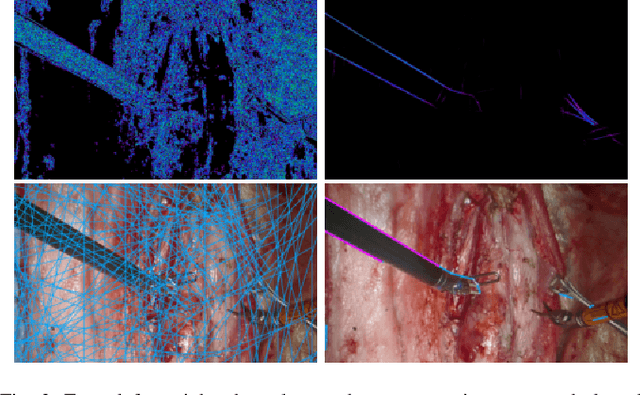

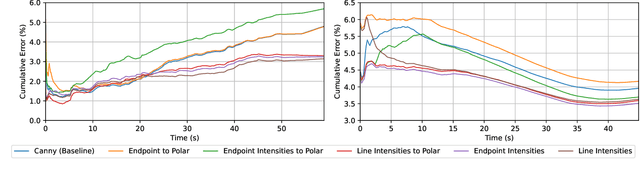
Controlling robotic manipulators via visual feedback requires a known coordinate frame transformation between the robot and the camera. Uncertainties in mechanical systems as well as camera calibration create errors in this coordinate frame transformation. These errors result in poor localization of robotic manipulators and create a significant challenge for applications that rely on precise interactions between manipulators and the environment. In this work, we estimate the camera-to-base transform and joint angle measurement errors for surgical robotic tools using an image based insertion-shaft detection algorithm and probabilistic models. We apply our proposed approach in both a structured environment as well as an unstructured environment and measure to demonstrate the efficacy of our methods.