 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Deep Optimal Embeddings with Sinkhorn Divergences
Sep 14, 2022
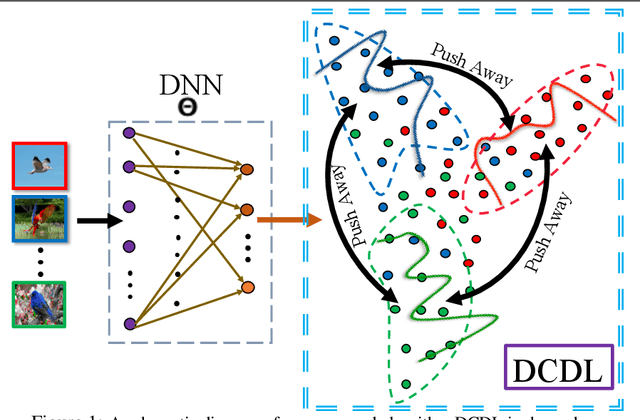
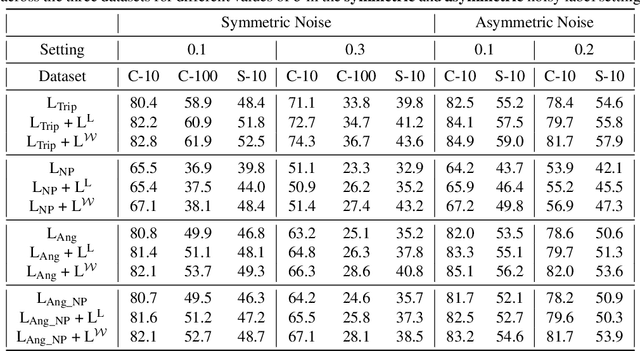
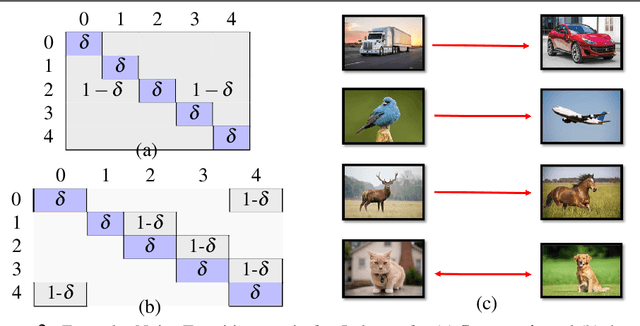
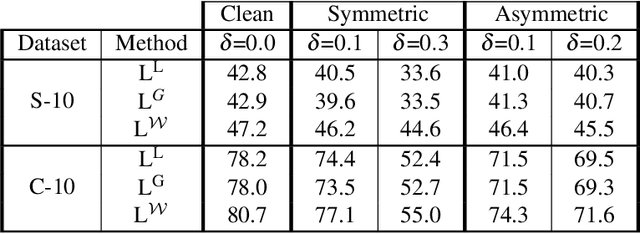
Deep Metric Learning algorithms aim to learn an efficient embedding space to preserve the similarity relationships among the input data. Whilst these algorithms have achieved significant performance gains across a wide plethora of tasks, they have also failed to consider and increase comprehensive similarity constraints; thus learning a sub-optimal metric in the embedding space. Moreover, up until now; there have been few studies with respect to their performance in the presence of noisy labels. Here, we address the concern of learning a discriminative deep embedding space by designing a novel, yet effective Deep Class-wise Discrepancy Loss (DCDL) function that segregates the underlying similarity distributions (thus introducing class-wise discrepancy) of the embedding points between each and every class. Our empirical results across three standard image classification datasets and two fine-grained image recognition datasets in the presence and absence of noise clearly demonstrate the need for incorporating such class-wise similarity relationships along with traditional algorithms while learning a discriminative embedding space.
Image Classification using Graph Neural Network and Multiscale Wavelet Superpixels
Jan 29, 2022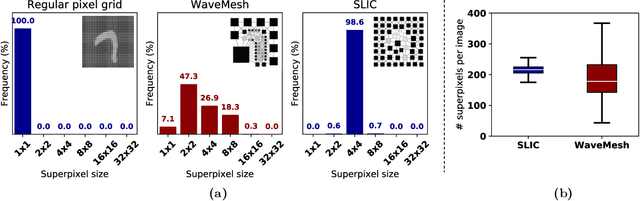
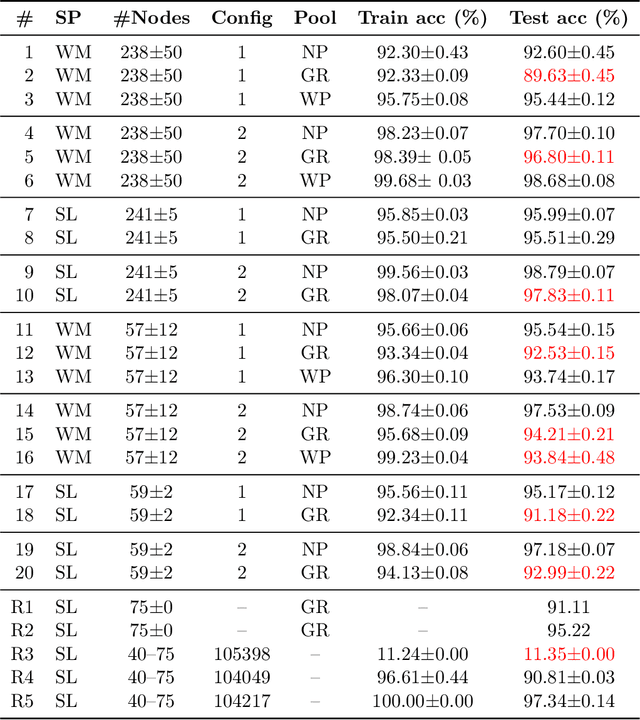

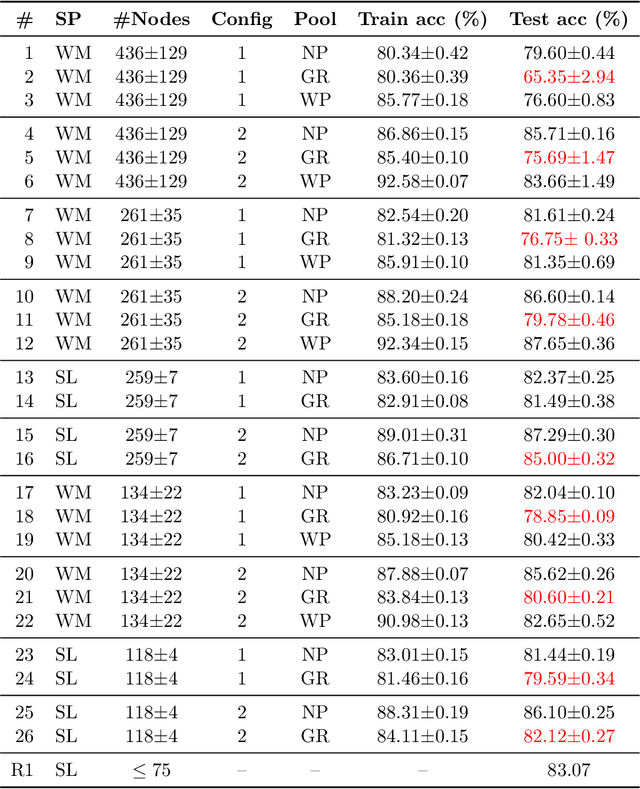
Prior studies using graph neural networks (GNNs) for image classification have focused on graphs generated from a regular grid of pixels or similar-sized superpixels. In the latter, a single target number of superpixels is defined for an entire dataset irrespective of differences across images and their intrinsic multiscale structure. On the contrary, this study investigates image classification using graphs generated from an image-specific number of multiscale superpixels. We propose WaveMesh, a new wavelet-based superpixeling algorithm, where the number and sizes of superpixels in an image are systematically computed based on its content. WaveMesh superpixel graphs are structurally different from similar-sized superpixel graphs. We use SplineCNN, a state-of-the-art network for image graph classification, to compare WaveMesh and similar-sized superpixels. Using SplineCNN, we perform extensive experiments on three benchmark datasets under three local-pooling settings: 1) no pooling, 2) GraclusPool, and 3) WavePool, a novel spatially heterogeneous pooling scheme tailored to WaveMesh superpixels. Our experiments demonstrate that SplineCNN learns from multiscale WaveMesh superpixels on-par with similar-sized superpixels. In all WaveMesh experiments, GraclusPool performs poorer than no pooling / WavePool, indicating that poor choice of pooling can result in inferior performance while learning from multiscale superpixels.
AI Illustrator: Translating Raw Descriptions into Images by Prompt-based Cross-Modal Generation
Sep 08, 2022
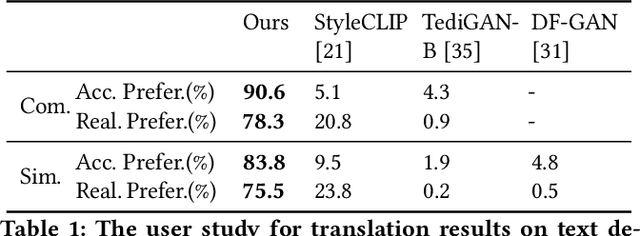
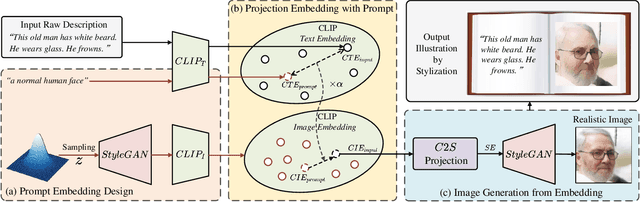
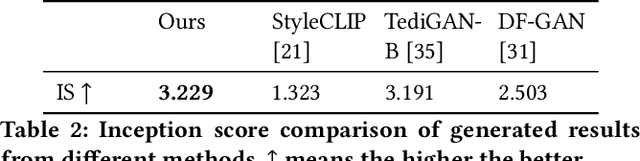
AI illustrator aims to automatically design visually appealing images for books to provoke rich thoughts and emotions. To achieve this goal, we propose a framework for translating raw descriptions with complex semantics into semantically corresponding images. The main challenge lies in the complexity of the semantics of raw descriptions, which may be hard to be visualized (e.g., "gloomy" or "Asian"). It usually poses challenges for existing methods to handle such descriptions. To address this issue, we propose a Prompt-based Cross-Modal Generation Framework (PCM-Frame) to leverage two powerful pre-trained models, including CLIP and StyleGAN. Our framework consists of two components: a projection module from Text Embeddings to Image Embeddings based on prompts, and an adapted image generation module built on StyleGAN which takes Image Embeddings as inputs and is trained by combined semantic consistency losses. To bridge the gap between realistic images and illustration designs, we further adopt a stylization model as post-processing in our framework for better visual effects. Benefiting from the pre-trained models, our method can handle complex descriptions and does not require external paired data for training. Furthermore, we have built a benchmark that consists of 200 raw descriptions. We conduct a user study to demonstrate our superiority over the competing methods with complicated texts. We release our code at https://github.com/researchmm/AI_Illustrator.
UDepth: Fast Monocular Depth Estimation for Visually-guided Underwater Robots
Sep 26, 2022
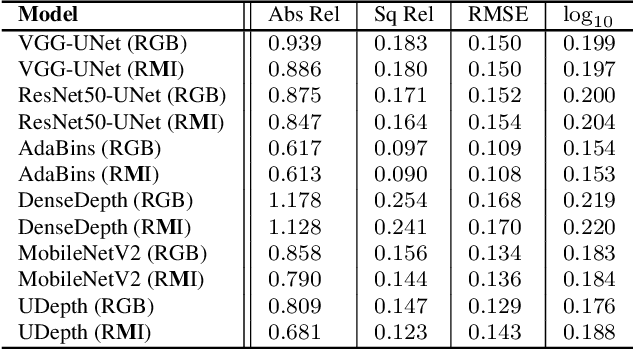
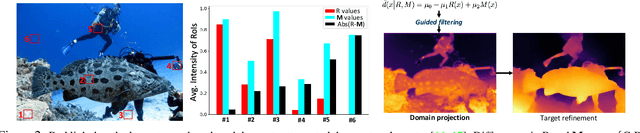
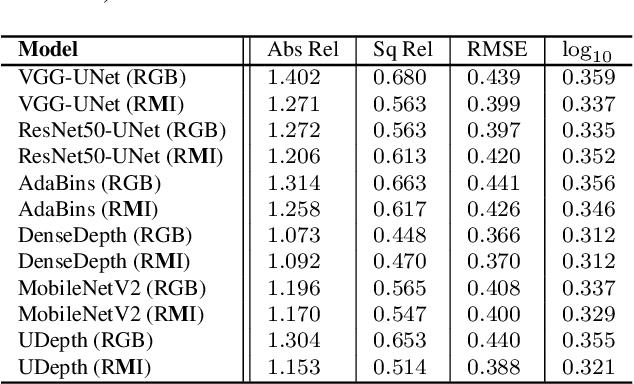
In this paper, we present a fast monocular depth estimation method for enabling 3D perception capabilities of low-cost underwater robots. We formulate a novel end-to-end deep visual learning pipeline named UDepth, which incorporates domain knowledge of image formation characteristics of natural underwater scenes. First, we adapt a new input space from raw RGB image space by exploiting underwater light attenuation prior, and then devise a least-squared formulation for coarse pixel-wise depth prediction. Subsequently, we extend this into a domain projection loss that guides the end-to-end learning of UDepth on over 9K RGB-D training samples. UDepth is designed with a computationally light MobileNetV2 backbone and a Transformer-based optimizer for ensuring fast inference rates on embedded systems. By domain-aware design choices and through comprehensive experimental analyses, we demonstrate that it is possible to achieve state-of-the-art depth estimation performance while ensuring a small computational footprint. Specifically, with 70%-80% less network parameters than existing benchmarks, UDepth achieves comparable and often better depth estimation performance. While the full model offers over 66 FPS (13 FPS) inference rates on a single GPU (CPU core), our domain projection for coarse depth prediction runs at 51.5 FPS rates on single-board NVIDIA Jetson TX2s. The inference pipelines are available at https://github.com/uf-robopi/UDepth.
Large-scale Bilingual Language-Image Contrastive Learning
Apr 15, 2022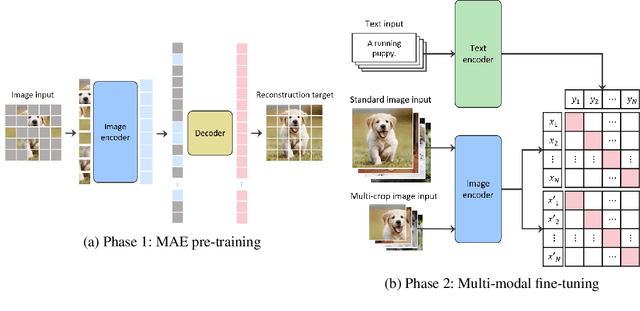
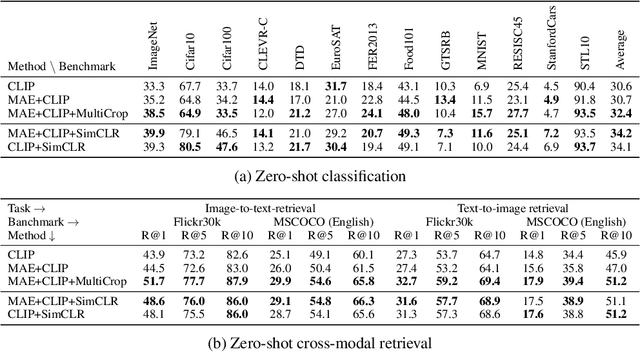
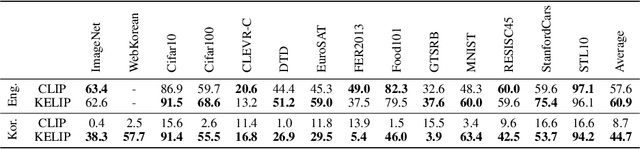
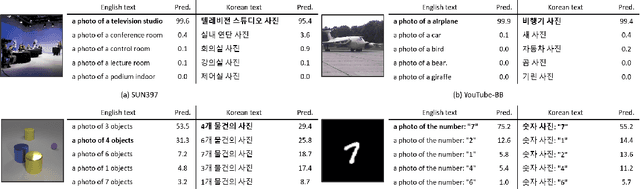
This paper is a technical report to share our experience and findings building a Korean and English bilingual multimodal model. While many of the multimodal datasets focus on English and multilingual multimodal research uses machine-translated texts, employing such machine-translated texts is limited to describing unique expressions, cultural information, and proper noun in languages other than English. In this work, we collect 1.1 billion image-text pairs (708 million Korean and 476 million English) and train a bilingual multimodal model named KELIP. We introduce simple yet effective training schemes, including MAE pre-training and multi-crop augmentation. Extensive experiments demonstrate that a model trained with such training schemes shows competitive performance in both languages. Moreover, we discuss multimodal-related research questions: 1) strong augmentation-based methods can distract the model from learning proper multimodal relations; 2) training multimodal model without cross-lingual relation can learn the relation via visual semantics; 3) our bilingual KELIP can capture cultural differences of visual semantics for the same meaning of words; 4) a large-scale multimodal model can be used for multimodal feature analogy. We hope that this work will provide helpful experience and findings for future research. We provide an open-source pre-trained KELIP.
Automated segmentation of microvessels in intravascular OCT images using deep learning
Oct 01, 2022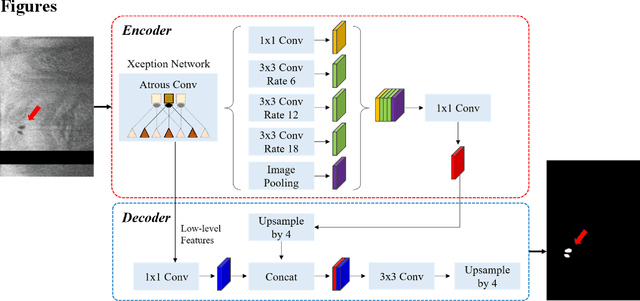
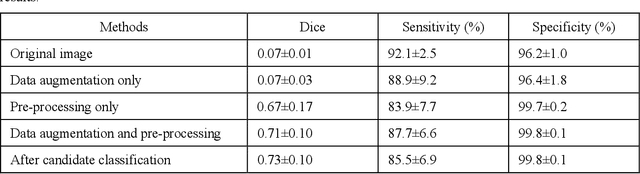


To analyze this characteristic of vulnerability, we developed an automated deep learning method for detecting microvessels in intravascular optical coherence tomography (IVOCT) images. A total of 8,403 IVOCT image frames from 85 lesions and 37 normal segments were analyzed. Manual annotation was done using a dedicated software (OCTOPUS) previously developed by our group. Data augmentation in the polar (r,{\theta}) domain was applied to raw IVOCT images to ensure that microvessels appear at all possible angles. Pre-processing methods included guidewire/shadow detection, lumen segmentation, pixel shifting, and noise reduction. DeepLab v3+ was used to segment microvessel candidates. A bounding box on each candidate was classified as either microvessel or non-microvessel using a shallow convolutional neural network. For better classification, we used data augmentation (i.e., angle rotation) on bounding boxes with a microvessel during network training. Data augmentation and pre-processing steps improved microvessel segmentation performance significantly, yielding a method with Dice of 0.71+/-0.10 and pixel-wise sensitivity/specificity of 87.7+/-6.6%/99.8+/-0.1%. The network for classifying microvessels from candidates performed exceptionally well, with sensitivity of 99.5+/-0.3%, specificity of 98.8+/-1.0%, and accuracy of 99.1+/-0.5%. The classification step eliminated the majority of residual false positives, and the Dice coefficient increased from 0.71 to 0.73. In addition, our method produced 698 image frames with microvessels present, compared to 730 from manual analysis, representing a 4.4% difference. When compared to the manual method, the automated method improved microvessel continuity, implying improved segmentation performance. The method will be useful for research purposes as well as potential future treatment planning.
CoV-TI-Net: Transferred Initialization with Modified End Layer for COVID-19 Diagnosis
Sep 20, 2022
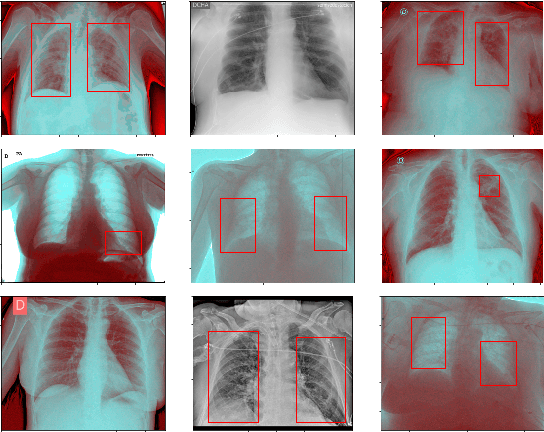
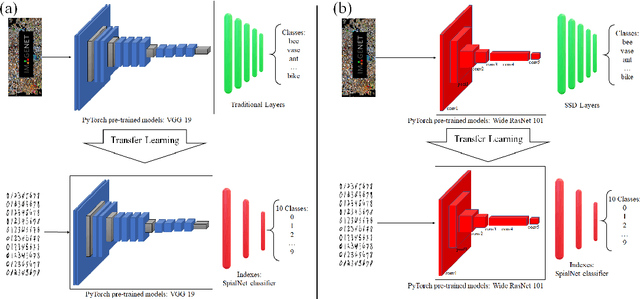
This paper proposes transferred initialization with modified fully connected layers for COVID-19 diagnosis. Convolutional neural networks (CNN) achieved a remarkable result in image classification. However, training a high-performing model is a very complicated and time-consuming process because of the complexity of image recognition applications. On the other hand, transfer learning is a relatively new learning method that has been employed in many sectors to achieve good performance with fewer computations. In this research, the PyTorch pre-trained models (VGG19\_bn and WideResNet -101) are applied in the MNIST dataset for the first time as initialization and with modified fully connected layers. The employed PyTorch pre-trained models were previously trained in ImageNet. The proposed model is developed and verified in the Kaggle notebook, and it reached the outstanding accuracy of 99.77% without taking a huge computational time during the training process of the network. We also applied the same methodology to the SIIM-FISABIO-RSNA COVID-19 Detection dataset and achieved 80.01% accuracy. In contrast, the previous methods need a huge compactional time during the training process to reach a high-performing model. Codes are available at the following link: github.com/dipuk0506/SpinalNet
ISA-Net: Improved spatial attention network for PET-CT tumor segmentation
Nov 04, 2022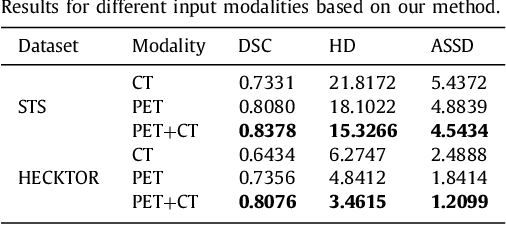
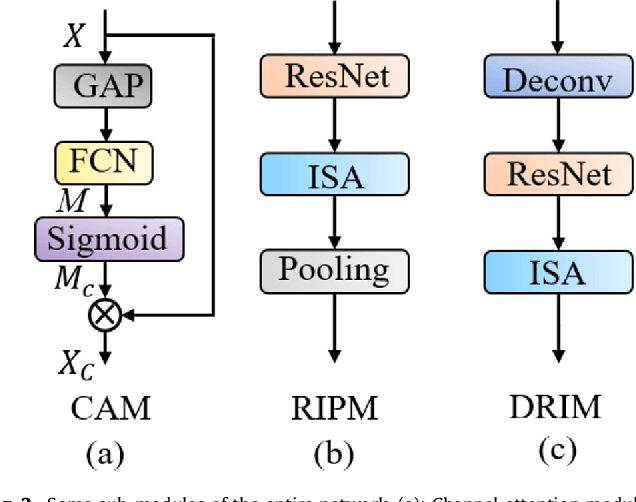
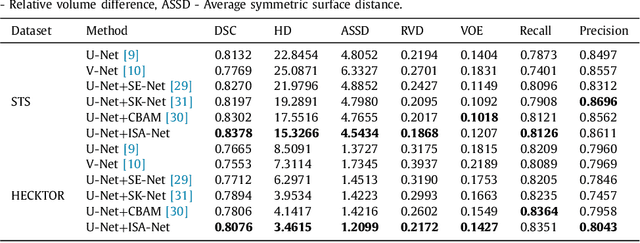
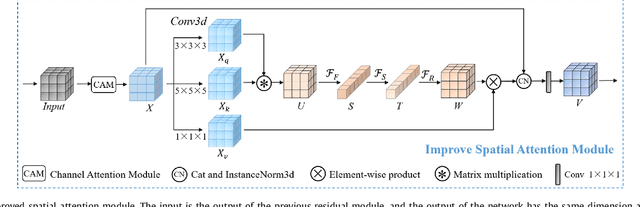
Achieving accurate and automated tumor segmentation plays an important role in both clinical practice and radiomics research. Segmentation in medicine is now often performed manually by experts, which is a laborious, expensive and error-prone task. Manual annotation relies heavily on the experience and knowledge of these experts. In addition, there is much intra- and interobserver variation. Therefore, it is of great significance to develop a method that can automatically segment tumor target regions. In this paper, we propose a deep learning segmentation method based on multimodal positron emission tomography-computed tomography (PET-CT), which combines the high sensitivity of PET and the precise anatomical information of CT. We design an improved spatial attention network(ISA-Net) to increase the accuracy of PET or CT in detecting tumors, which uses multi-scale convolution operation to extract feature information and can highlight the tumor region location information and suppress the non-tumor region location information. In addition, our network uses dual-channel inputs in the coding stage and fuses them in the decoding stage, which can take advantage of the differences and complementarities between PET and CT. We validated the proposed ISA-Net method on two clinical datasets, a soft tissue sarcoma(STS) and a head and neck tumor(HECKTOR) dataset, and compared with other attention methods for tumor segmentation. The DSC score of 0.8378 on STS dataset and 0.8076 on HECKTOR dataset show that ISA-Net method achieves better segmentation performance and has better generalization. Conclusions: The method proposed in this paper is based on multi-modal medical image tumor segmentation, which can effectively utilize the difference and complementarity of different modes. The method can also be applied to other multi-modal data or single-modal data by proper adjustment.
Data Models for Dataset Drift Controls in Machine Learning With Images
Nov 04, 2022


Camera images are ubiquitous in machine learning research. They also play a central role in the delivery of important services spanning medicine and environmental surveying. However, the application of machine learning models in these domains has been limited because of robustness concerns. A primary failure mode are performance drops due to differences between the training and deployment data. While there are methods to prospectively validate the robustness of machine learning models to such dataset drifts, existing approaches do not account for explicit models of the primary object of interest: the data. This makes it difficult to create physically faithful drift test cases or to provide specifications of data models that should be avoided when deploying a machine learning model. In this study, we demonstrate how these shortcomings can be overcome by pairing machine learning robustness validation with physical optics. We examine the role raw sensor data and differentiable data models can play in controlling performance risks related to image dataset drift. The findings are distilled into three applications. First, drift synthesis enables the controlled generation of physically faithful drift test cases. The experiments presented here show that the average decrease in model performance is ten to four times less severe than under post-hoc augmentation testing. Second, the gradient connection between task and data models allows for drift forensics that can be used to specify performance-sensitive data models which should be avoided during deployment of a machine learning model. Third, drift adjustment opens up the possibility for processing adjustments in the face of drift. This can lead to speed up and stabilization of classifier training at a margin of up to 20% in validation accuracy. A guide to access the open code and datasets is available at https://github.com/aiaudit-org/raw2logit.
Instruction-Following Agents with Jointly Pre-Trained Vision-Language Models
Oct 24, 2022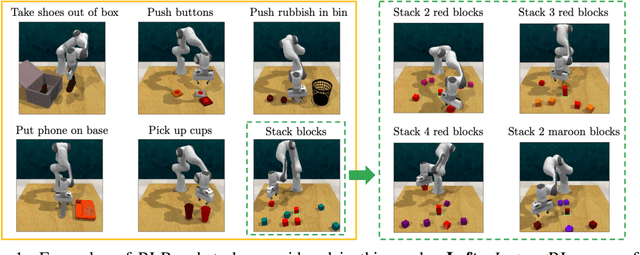
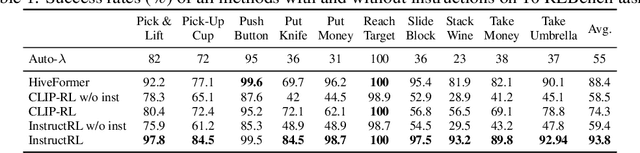
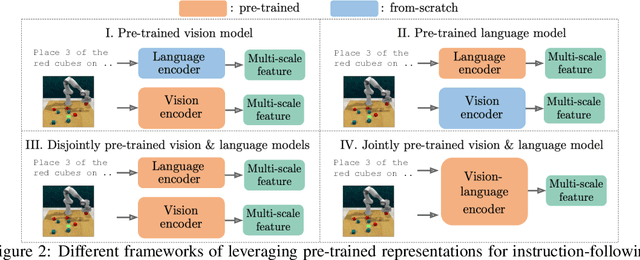

Humans are excellent at understanding language and vision to accomplish a wide range of tasks. In contrast, creating general instruction-following embodied agents remains a difficult challenge. Prior work that uses pure language-only models lack visual grounding, making it difficult to connect language instructions with visual observations. On the other hand, methods that use pre-trained vision-language models typically come with divided language and visual representations, requiring designing specialized network architecture to fuse them together. We propose a simple yet effective model for robots to solve instruction-following tasks in vision-based environments. Our \ours method consists of a multimodal transformer that encodes visual observations and language instructions, and a policy transformer that predicts actions based on encoded representations. The multimodal transformer is pre-trained on millions of image-text pairs and natural language text, thereby producing generic cross-modal representations of observations and instructions. The policy transformer keeps track of the full history of observations and actions, and predicts actions autoregressively. We show that this unified transformer model outperforms all state-of-the-art pre-trained or trained-from-scratch methods in both single-task and multi-task settings. Our model also shows better model scalability and generalization ability than prior work.