 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MonoDVPS: A Self-Supervised Monocular Depth Estimation Approach to Depth-aware Video Panoptic Segmentation
Oct 14, 2022



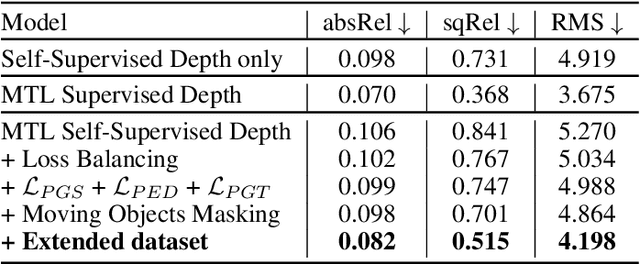
Depth-aware video panoptic segmentation tackles the inverse projection problem of restoring panoptic 3D point clouds from video sequences, where the 3D points are augmented with semantic classes and temporally consistent instance identifiers. We propose a novel solution with a multi-task network that performs monocular depth estimation and video panoptic segmentation. Since acquiring ground truth labels for both depth and image segmentation has a relatively large cost, we leverage the power of unlabeled video sequences with self-supervised monocular depth estimation and semi-supervised learning from pseudo-labels for video panoptic segmentation. To further improve the depth prediction, we introduce panoptic-guided depth losses and a novel panoptic masking scheme for moving objects to avoid corrupting the training signal. Extensive experiments on the Cityscapes-DVPS and SemKITTI-DVPS datasets demonstrate that our model with the proposed improvements achieves competitive results and fast inference speed.
TokenMixup: Efficient Attention-guided Token-level Data Augmentation for Transformers
Oct 14, 2022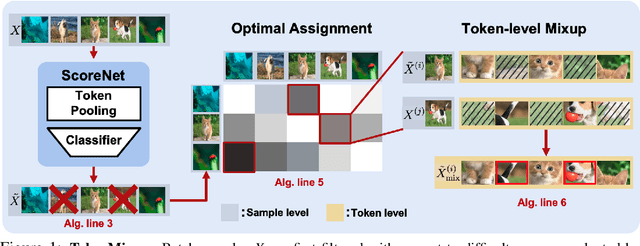
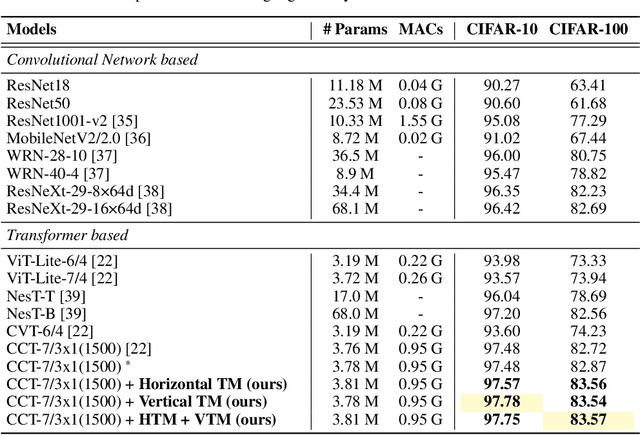
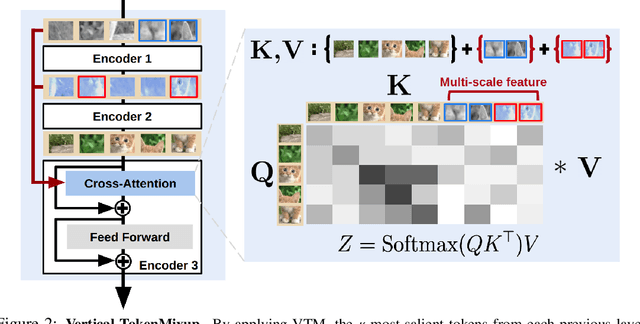
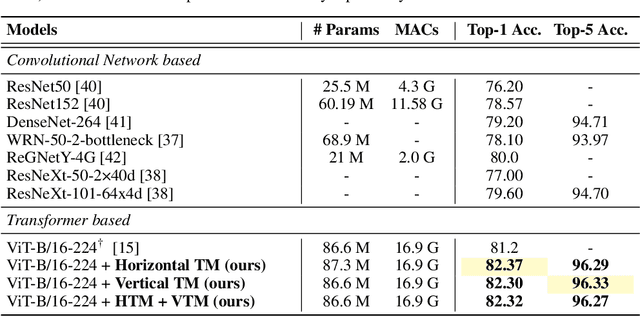
Mixup is a commonly adopted data augmentation technique for image classification. Recent advances in mixup methods primarily focus on mixing based on saliency. However, many saliency detectors require intense computation and are especially burdensome for parameter-heavy transformer models. To this end, we propose TokenMixup, an efficient attention-guided token-level data augmentation method that aims to maximize the saliency of a mixed set of tokens. TokenMixup provides x15 faster saliency-aware data augmentation compared to gradient-based methods. Moreover, we introduce a variant of TokenMixup which mixes tokens within a single instance, thereby enabling multi-scale feature augmentation. Experiments show that our methods significantly improve the baseline models' performance on CIFAR and ImageNet-1K, while being more efficient than previous methods. We also reach state-of-the-art performance on CIFAR-100 among from-scratch transformer models. Code is available at https://github.com/mlvlab/TokenMixup.
Efficient and Effective Augmentation Strategy for Adversarial Training
Oct 27, 2022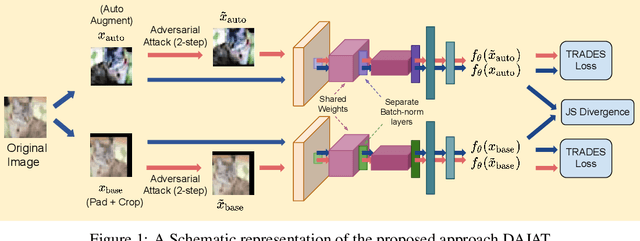

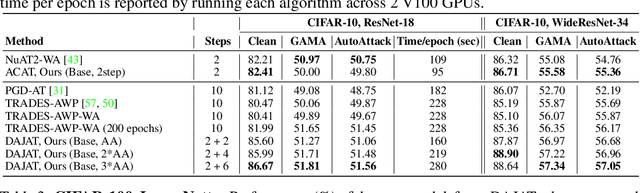
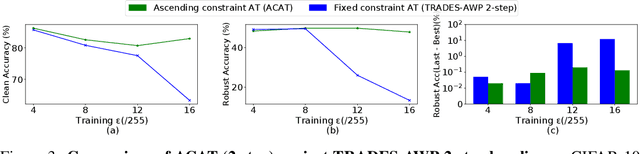
Adversarial training of Deep Neural Networks is known to be significantly more data-hungry when compared to standard training. Furthermore, complex data augmentations such as AutoAugment, which have led to substantial gains in standard training of image classifiers, have not been successful with Adversarial Training. We first explain this contrasting behavior by viewing augmentation during training as a problem of domain generalization, and further propose Diverse Augmentation-based Joint Adversarial Training (DAJAT) to use data augmentations effectively in adversarial training. We aim to handle the conflicting goals of enhancing the diversity of the training dataset and training with data that is close to the test distribution by using a combination of simple and complex augmentations with separate batch normalization layers during training. We further utilize the popular Jensen-Shannon divergence loss to encourage the joint learning of the diverse augmentations, thereby allowing simple augmentations to guide the learning of complex ones. Lastly, to improve the computational efficiency of the proposed method, we propose and utilize a two-step defense, Ascending Constraint Adversarial Training (ACAT), that uses an increasing epsilon schedule and weight-space smoothing to prevent gradient masking. The proposed method DAJAT achieves substantially better robustness-accuracy trade-off when compared to existing methods on the RobustBench Leaderboard on ResNet-18 and WideResNet-34-10. The code for implementing DAJAT is available here: https://github.com/val-iisc/DAJAT.
ProbNeRF: Uncertainty-Aware Inference of 3D Shapes from 2D Images
Oct 27, 2022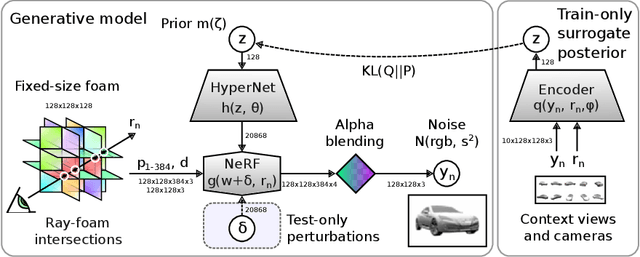

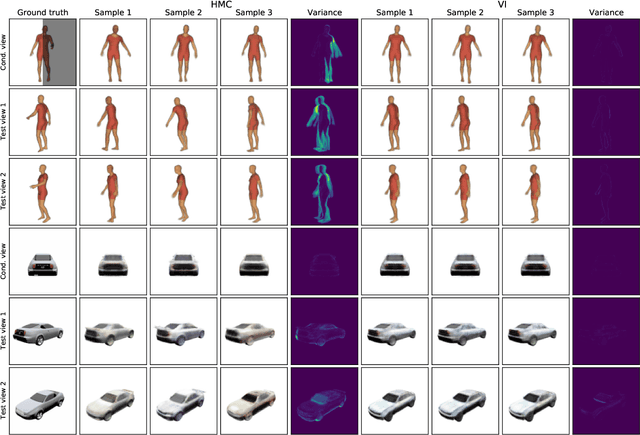
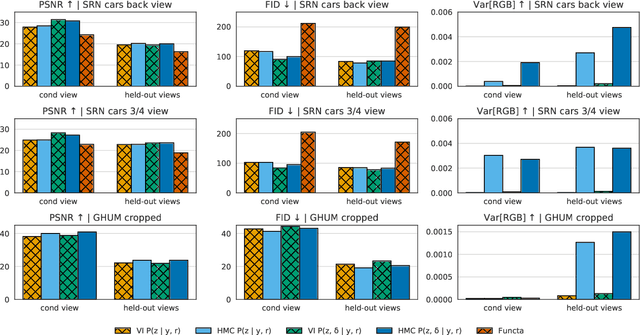
The problem of inferring object shape from a single 2D image is underconstrained. Prior knowledge about what objects are plausible can help, but even given such prior knowledge there may still be uncertainty about the shapes of occluded parts of objects. Recently, conditional neural radiance field (NeRF) models have been developed that can learn to infer good point estimates of 3D models from single 2D images. The problem of inferring uncertainty estimates for these models has received less attention. In this work, we propose probabilistic NeRF (ProbNeRF), a model and inference strategy for learning probabilistic generative models of 3D objects' shapes and appearances, and for doing posterior inference to recover those properties from 2D images. ProbNeRF is trained as a variational autoencoder, but at test time we use Hamiltonian Monte Carlo (HMC) for inference. Given one or a few 2D images of an object (which may be partially occluded), ProbNeRF is able not only to accurately model the parts it sees, but also to propose realistic and diverse hypotheses about the parts it does not see. We show that key to the success of ProbNeRF are (i) a deterministic rendering scheme, (ii) an annealed-HMC strategy, (iii) a hypernetwork-based decoder architecture, and (iv) doing inference over a full set of NeRF weights, rather than just a low-dimensional code.
Image-based Stroke Assessment for Multi-site Preclinical Evaluation of Cerebroprotectants
Mar 11, 2022

Ischemic stroke is a leading cause of death worldwide, but there has been little success translating putative cerebroprotectants from preclinical trials to patients. We investigated computational image-based assessment tools for practical improvement of the quality, scalability, and outlook for large scale preclinical screening for potential therapeutic interventions. We developed, evaluated, and deployed a pipeline for image-based stroke outcome quantification for the Stroke Prelinical Assessment Network (SPAN), which is a multi-site, multi-arm, multi-stage study evaluating a suite of cerebroprotectant interventions. Our fully automated pipeline combines state-of-the-art algorithmic and data analytic approaches to assess stroke outcomes from multi-parameter MRI data collected longitudinally from a rodent model of middle cerebral artery occlusion (MCAO), including measures of infarct volume, brain atrophy, midline shift, and data quality. We tested our approach with 1,368 scans and report population level results of lesion extent and longitudinal changes from injury. We validated our system by comparison with manual annotations of coronal MRI slices and tissue sections from the same brain, using crowdsourcing from blinded stroke experts from the network. Our results demonstrate the efficacy and robustness of our image-based stroke assessments. The pipeline may provide a promising resource for ongoing preclinical studies conducted by SPAN and other networks in the future.
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 07, 2022



Image-Test matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
UPST-NeRF: Universal Photorealistic Style Transfer of Neural Radiance Fields for 3D Scene
Aug 15, 2022
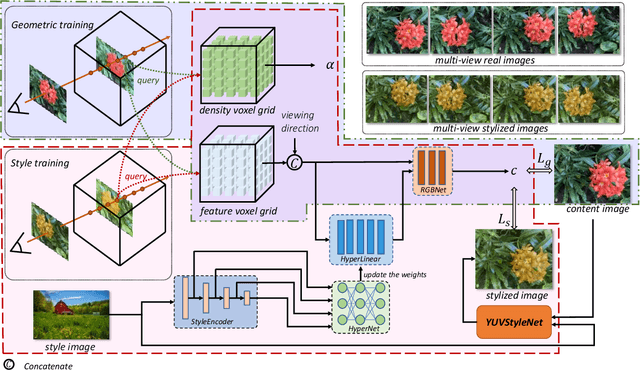
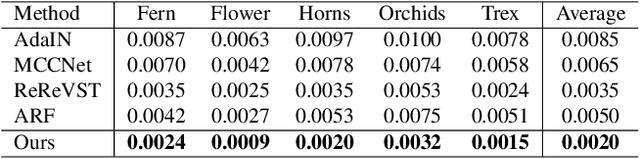
3D scenes photorealistic stylization aims to generate photorealistic images from arbitrary novel views according to a given style image while ensuring consistency when rendering from different viewpoints. Some existing stylization methods with neural radiance fields can effectively predict stylized scenes by combining the features of the style image with multi-view images to train 3D scenes. However, these methods generate novel view images that contain objectionable artifacts. Besides, they cannot achieve universal photorealistic stylization for a 3D scene. Therefore, a styling image must retrain a 3D scene representation network based on a neural radiation field. We propose a novel 3D scene photorealistic style transfer framework to address these issues. It can realize photorealistic 3D scene style transfer with a 2D style image. We first pre-trained a 2D photorealistic style transfer network, which can meet the photorealistic style transfer between any given content image and style image. Then, we use voxel features to optimize a 3D scene and get the geometric representation of the scene. Finally, we jointly optimize a hyper network to realize the scene photorealistic style transfer of arbitrary style images. In the transfer stage, we use a pre-trained 2D photorealistic network to constrain the photorealistic style of different views and different style images in the 3D scene. The experimental results show that our method not only realizes the 3D photorealistic style transfer of arbitrary style images but also outperforms the existing methods in terms of visual quality and consistency. Project page:https://semchan.github.io/UPST_NeRF.
Deep Constrained Least Squares for Blind Image Super-Resolution
Feb 15, 2022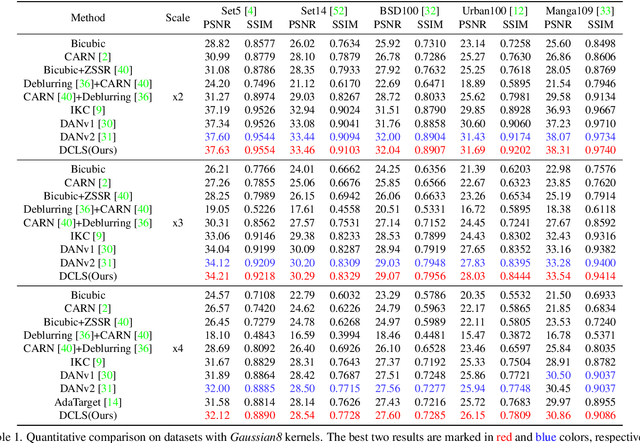

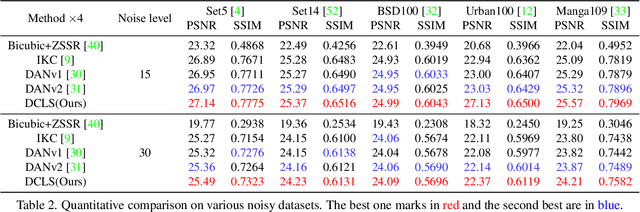
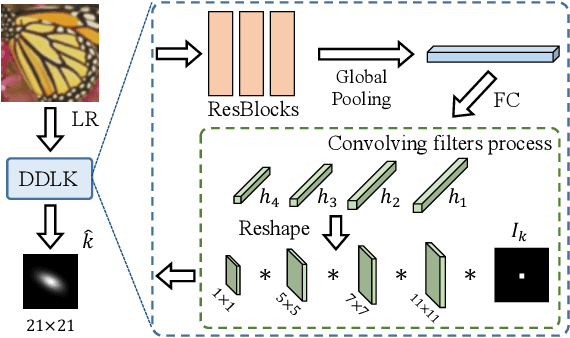
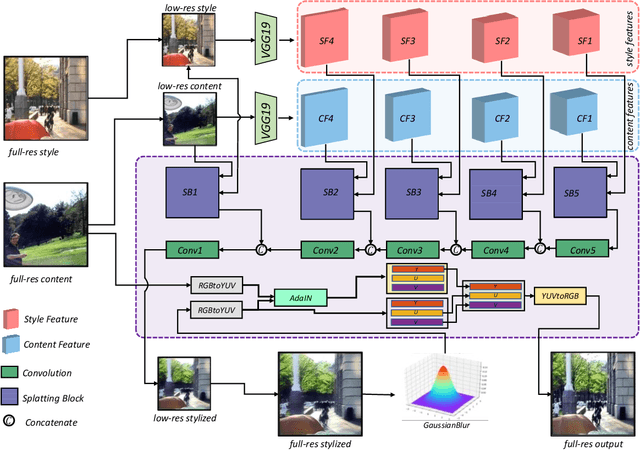
In this paper, we tackle the problem of blind image super-resolution(SR) with a reformulated degradation model and two novel modules. Following the common practices of blind SR, our method proposes to improve both the kernel estimation as well as the kernel based high resolution image restoration. To be more specific, we first reformulate the degradation model such that the deblurring kernel estimation can be transferred into the low resolution space. On top of this, we introduce a dynamic deep linear filter module. Instead of learning a fixed kernel for all images, it can adaptively generate deblurring kernel weights conditional on the input and yields more robust kernel estimation. Subsequently, a deep constrained least square filtering module is applied to generate clean features based on the reformulation and estimated kernel. The deblurred feature and the low input image feature are then fed into a dual-path structured SR network and restore the final high resolution result. To evaluate our method, we further conduct evaluations on several benchmarks, including Gaussian8 and DIV2KRK. Our experiments demonstrate that the proposed method achieves better accuracy and visual improvements against state-of-the-art methods.
A Generalist Framework for Panoptic Segmentation of Images and Videos
Oct 12, 2022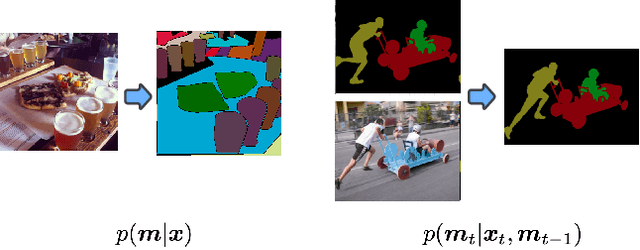
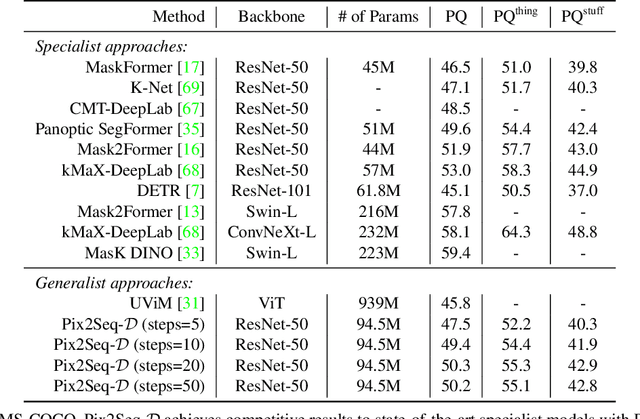
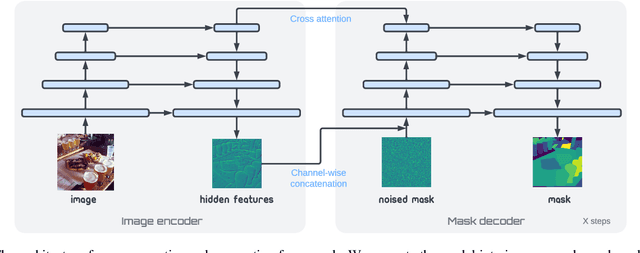
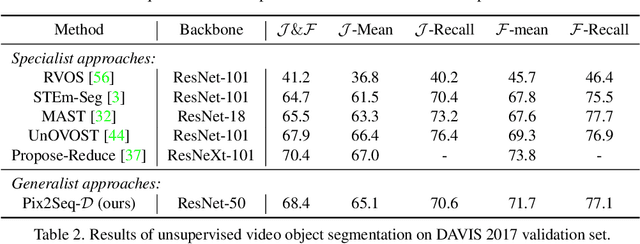
Panoptic segmentation assigns semantic and instance ID labels to every pixel of an image. As permutations of instance IDs are also valid solutions, the task requires learning of high-dimensional one-to-many mapping. As a result, state-of-the-art approaches use customized architectures and task-specific loss functions. We formulate panoptic segmentation as a discrete data generation problem, without relying on inductive bias of the task. A diffusion model based on analog bits is used to model panoptic masks, with a simple, generic architecture and loss function. By simply adding past predictions as a conditioning signal, our method is capable of modeling video (in a streaming setting) and thereby learns to track object instances automatically. With extensive experiments, we demonstrate that our generalist approach can perform competitively to state-of-the-art specialist methods in similar settings.
A Unified Framework with Meta-dropout for Few-shot Learning
Oct 12, 2022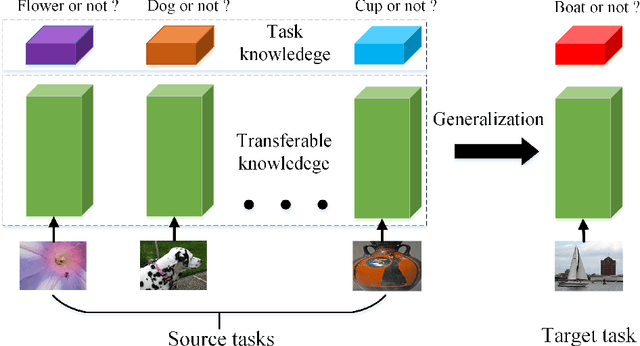

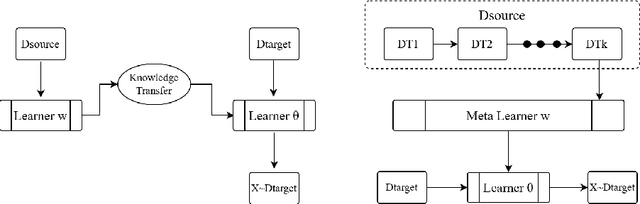
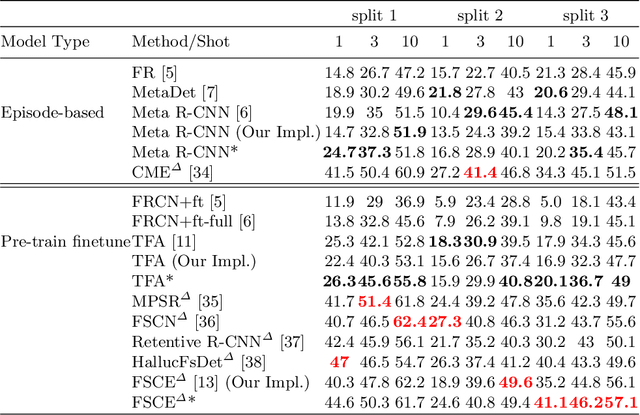
Conventional training of deep neural networks usually requires a substantial amount of data with expensive human annotations. In this paper, we utilize the idea of meta-learning to explain two very different streams of few-shot learning, i.e., the episodic meta-learning-based and pre-train finetune-based few-shot learning, and form a unified meta-learning framework. In order to improve the generalization power of our framework, we propose a simple yet effective strategy named meta-dropout, which is applied to the transferable knowledge generalized from base categories to novel categories. The proposed strategy can effectively prevent neural units from co-adapting excessively in the meta-training stage. Extensive experiments on the few-shot object detection and few-shot image classification datasets, i.e., Pascal VOC, MS COCO, CUB, and mini-ImageNet, validate the effectiveness of our method.