 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comparative Attention Framework for Better Few-Shot Object Detection on Aerial Images
Oct 25, 2022
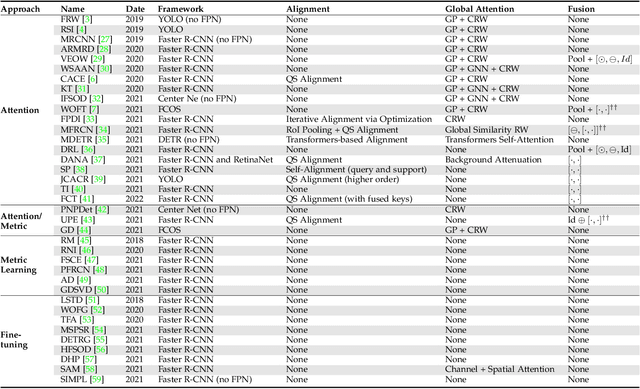
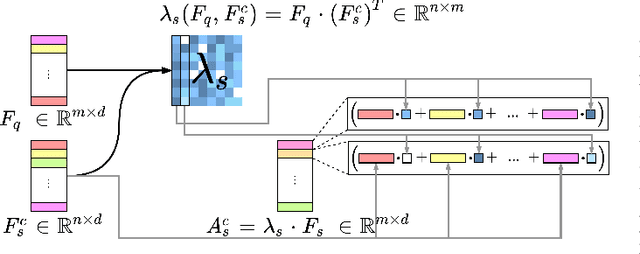
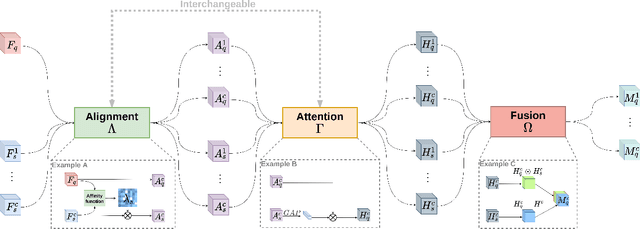

Few-Shot Object Detection (FSOD) methods are mainly designed and evaluated on natural image datasets such as Pascal VOC and MS COCO. However, it is not clear whether the best methods for natural images are also the best for aerial images. Furthermore, direct comparison of performance between FSOD methods is difficult due to the wide variety of detection frameworks and training strategies. Therefore, we propose a benchmarking framework that provides a flexible environment to implement and compare attention-based FSOD methods. The proposed framework focuses on attention mechanisms and is divided into three modules: spatial alignment, global attention, and fusion layer. To remain competitive with existing methods, which often leverage complex training, we propose new augmentation techniques designed for object detection. Using this framework, several FSOD methods are reimplemented and compared. This comparison highlights two distinct performance regimes on aerial and natural images: FSOD performs worse on aerial images. Our experiments suggest that small objects, which are harder to detect in the few-shot setting, account for the poor performance. Finally, we develop a novel multiscale alignment method, Cross-Scales Query-Support Alignment (XQSA) for FSOD, to improve the detection of small objects. XQSA outperforms the state-of-the-art significantly on DOTA and DIOR.
Exploring the GLIDE model for Human Action-effect Prediction
Aug 01, 2022



We address the following action-effect prediction task. Given an image depicting an initial state of the world and an action expressed in text, predict an image depicting the state of the world following the action. The prediction should have the same scene context as the input image. We explore the use of the recently proposed GLIDE model for performing this task. GLIDE is a generative neural network that can synthesize (inpaint) masked areas of an image, conditioned on a short piece of text. Our idea is to mask-out a region of the input image where the effect of the action is expected to occur. GLIDE is then used to inpaint the masked region conditioned on the required action. In this way, the resulting image has the same background context as the input image, updated to show the effect of the action. We give qualitative results from experiments using the EPIC dataset of ego-centric videos labelled with actions.
FedTP: Federated Learning by Transformer Personalization
Nov 03, 2022
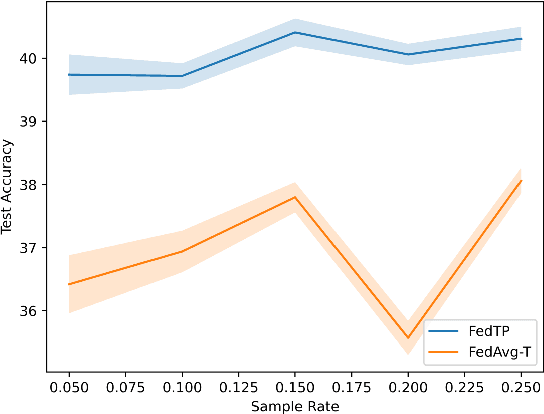
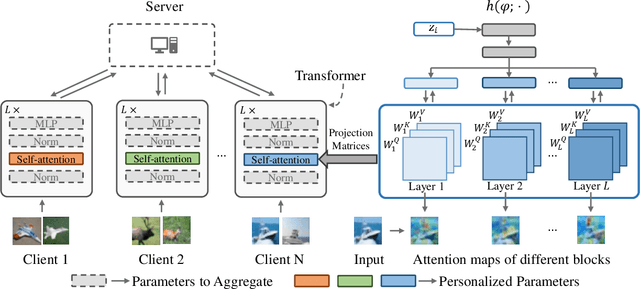
Federated learning is an emerging learning paradigm where multiple clients collaboratively train a machine learning model in a privacy-preserving manner. Personalized federated learning extends this paradigm to overcome heterogeneity across clients by learning personalized models. Recently, there have been some initial attempts to apply Transformers to federated learning. However, the impacts of federated learning algorithms on self-attention have not yet been studied. This paper investigates this relationship and reveals that federated averaging algorithms actually have a negative impact on self-attention where there is data heterogeneity. These impacts limit the capabilities of the Transformer model in federated learning settings. Based on this, we propose FedTP, a novel Transformer-based federated learning framework that learns personalized self-attention for each client while aggregating the other parameters among the clients. Instead of using a vanilla personalization mechanism that maintains personalized self-attention layers of each client locally, we develop a learn-to-personalize mechanism to further encourage the cooperation among clients and to increase the scablability and generalization of FedTP. Specifically, the learn-to-personalize is realized by learning a hypernetwork on the server that outputs the personalized projection matrices of self-attention layers to generate client-wise queries, keys and values. Furthermore, we present the generalization bound for FedTP with the learn-to-personalize mechanism. Notably, FedTP offers a convenient environment for performing a range of image and language tasks using the same federated network architecture - all of which benefit from Transformer personalization. Extensive experiments verify that FedTP with the learn-to-personalize mechanism yields state-of-the-art performance in non-IID scenarios. Our code is available online.
Fast Noise Removal in Hyperspectral Images via Representative Coefficient Total Variation
Nov 03, 2022

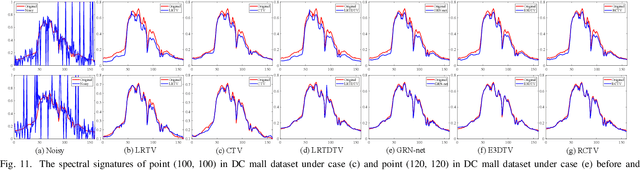
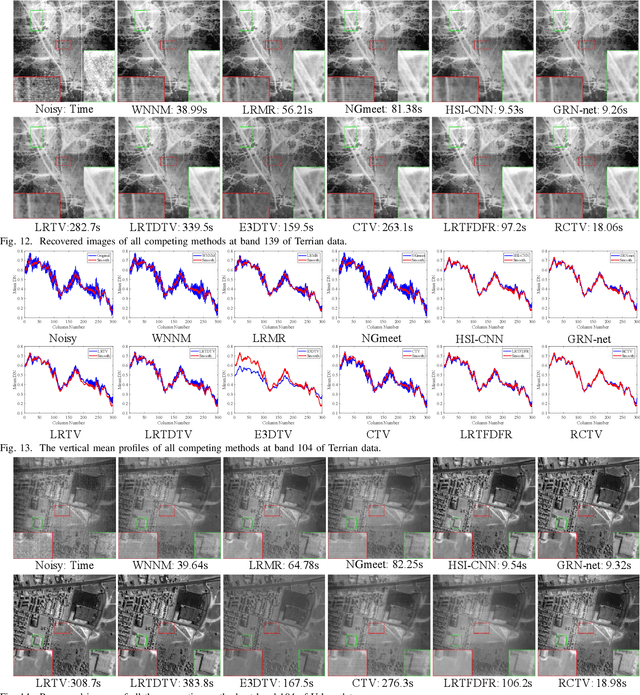
Mining structural priors in data is a widely recognized technique for hyperspectral image (HSI) denoising tasks, whose typical ways include model-based methods and data-based methods. The model-based methods have good generalization ability, while the runtime cannot meet the fast processing requirements of the practical situations due to the large size of an HSI data $ \mathbf{X} \in \mathbb{R}^{MN\times B}$. For the data-based methods, they perform very fast on new test data once they have been trained. However, their generalization ability is always insufficient. In this paper, we propose a fast model-based HSI denoising approach. Specifically, we propose a novel regularizer named Representative Coefficient Total Variation (RCTV) to simultaneously characterize the low rank and local smooth properties. The RCTV regularizer is proposed based on the observation that the representative coefficient matrix $\mathbf{U}\in\mathbb{R}^{MN\times R} (R\ll B)$ obtained by orthogonally transforming the original HSI $\mathbf{X}$ can inherit the strong local-smooth prior of $\mathbf{X}$. Since $R/B$ is very small, the HSI denoising model based on the RCTV regularizer has lower time complexity. Additionally, we find that the representative coefficient matrix $\mathbf{U}$ is robust to noise, and thus the RCTV regularizer can somewhat promote the robustness of the HSI denoising model. Extensive experiments on mixed noise removal demonstrate the superiority of the proposed method both in denoising performance and denoising speed compared with other state-of-the-art methods. Remarkably, the denoising speed of our proposed method outperforms all the model-based techniques and is comparable with the deep learning-based approaches.
Evaluation of the Synthetic Electronic Health Records
Oct 16, 2022
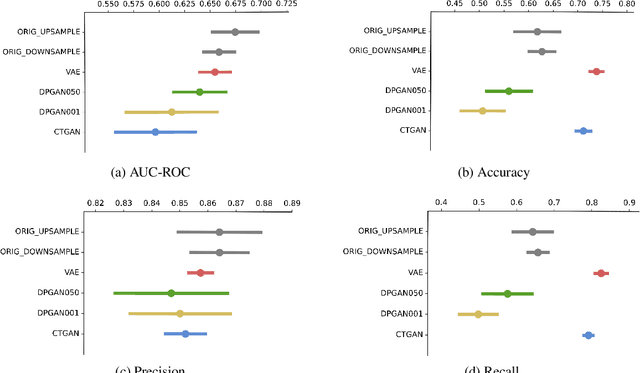
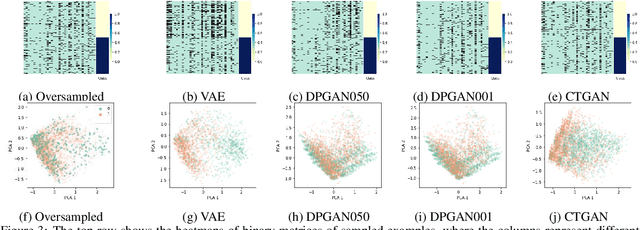
Generative models have been found effective for data synthesis due to their ability to capture complex underlying data distributions. The quality of generated data from these models is commonly evaluated by visual inspection for image datasets or downstream analytical tasks for tabular datasets. These evaluation methods neither measure the implicit data distribution nor consider the data privacy issues, and it remains an open question of how to compare and rank different generative models. Medical data can be sensitive, so it is of great importance to draw privacy concerns of patients while maintaining the data utility of the synthetic dataset. Beyond the utility evaluation, this work outlines two metrics called Similarity and Uniqueness for sample-wise assessment of synthetic datasets. We demonstrate the proposed notions with several state-of-the-art generative models to synthesise Cystic Fibrosis (CF) patients' electronic health records (EHRs), observing that the proposed metrics are suitable for synthetic data evaluation and generative model comparison.
Federated Learning with Privacy-Preserving Ensemble Attention Distillation
Oct 16, 2022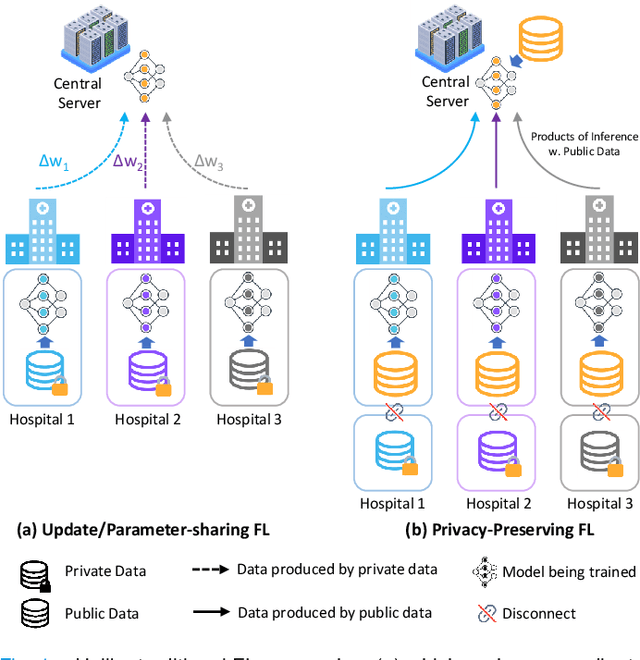
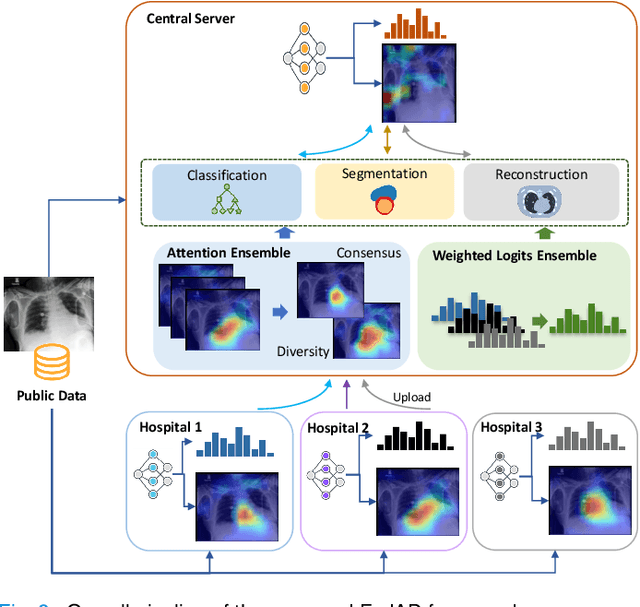
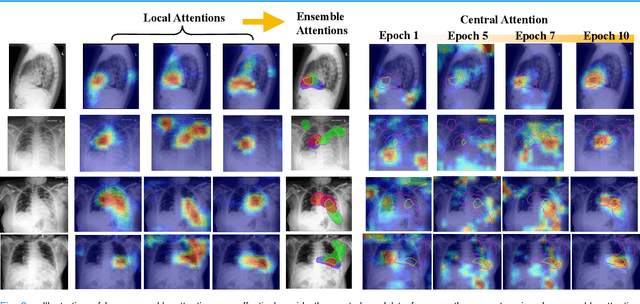
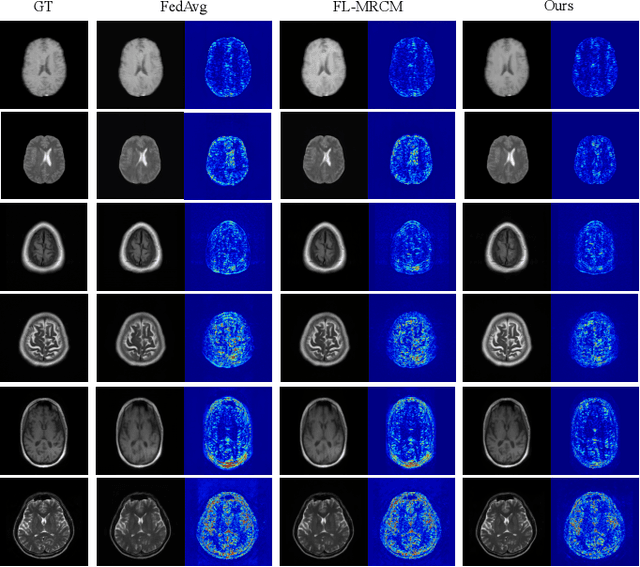
Federated Learning (FL) is a machine learning paradigm where many local nodes collaboratively train a central model while keeping the training data decentralized. This is particularly relevant for clinical applications since patient data are usually not allowed to be transferred out of medical facilities, leading to the need for FL. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they also require numerous rounds of synchronized communication and, more importantly, suffer from a privacy leakage risk. We propose a privacy-preserving FL framework leveraging unlabeled public data for one-way offline knowledge distillation in this work. The central model is learned from local knowledge via ensemble attention distillation. Our technique uses decentralized and heterogeneous local data like existing FL approaches, but more importantly, it significantly reduces the risk of privacy leakage. We demonstrate that our method achieves very competitive performance with more robust privacy preservation based on extensive experiments on image classification, segmentation, and reconstruction tasks.
Parallel faceted imaging in radio interferometry via proximal splitting (Faceted HyperSARA): II. Code and real data proof of concept
Sep 15, 2022
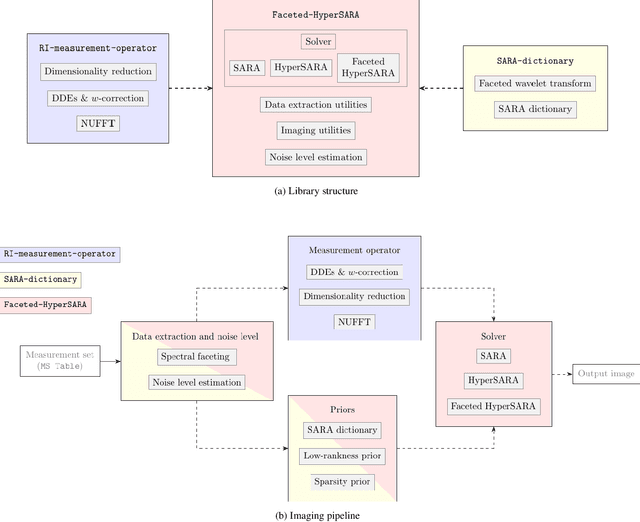
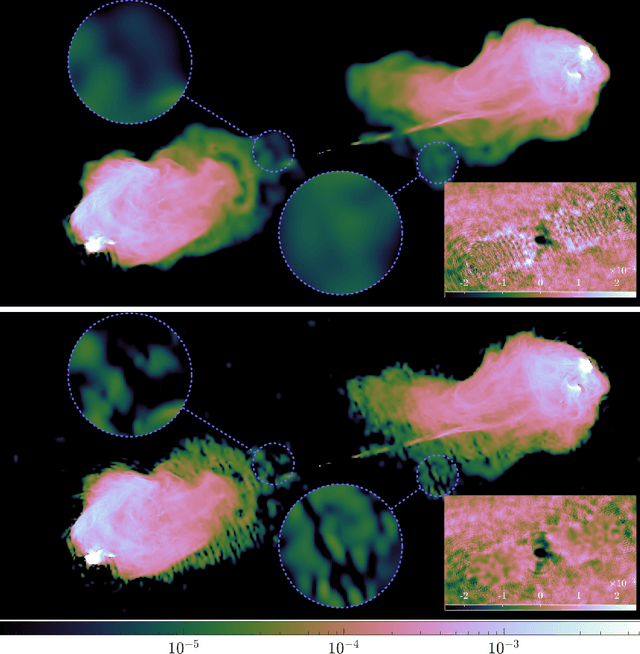
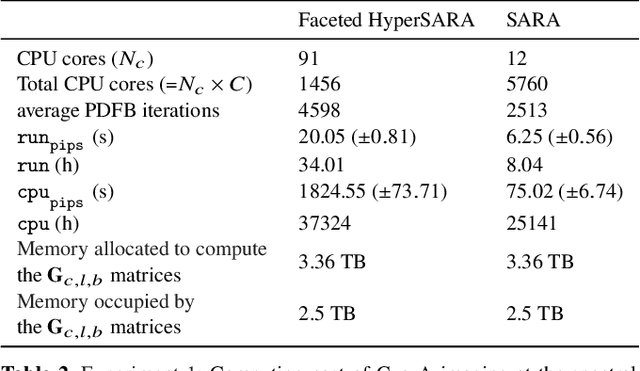
In a companion paper, a faceted wideband imaging technique for radio interferometry, dubbed Faceted HyperSARA, has been introduced and validated on synthetic data. Building on the recent HyperSARA approach, Faceted HyperSARA leverages the splitting functionality inherent to the underlying primal-dual forward-backward algorithm to decompose the image reconstruction over multiple spatio-spectral facets. The approach allows complex regularization to be injected into the imaging process while providing additional parallelization flexibility compared to HyperSARA. The present paper introduces new algorithm functionalities to address real datasets, implemented as part of a fully fledged MATLAB imaging library made available on Github. A large scale proof-of-concept is proposed to validate Faceted HyperSARA in a new data and parameter scale regime, compared to the state-of-the-art. The reconstruction of a 15 GB wideband image of Cyg A from 7.4 GB of VLA data is considered, utilizing 1440 CPU cores on a HPC system for about 9 hours. The conducted experiments illustrate the reconstruction performance of the proposed approach on real data, exploiting new functionalities to set, both an accurate model of the measurement operator accounting for known direction-dependent effects (DDEs), and an effective noise level accounting for imperfect calibration. They also demonstrate that, when combined with a further dimensionality reduction functionality, Faceted HyperSARA enables the recovery of a 3.6 GB image of Cyg A from the same data using only 91 CPU cores for 39 hours. In this setting, the proposed approach is shown to provide a superior reconstruction quality compared to the state-of-the-art wideband CLEAN-based algorithm of the WSClean software.
Machine Beats Machine: Machine Learning Models to Defend Against Adversarial Attacks
Sep 28, 2022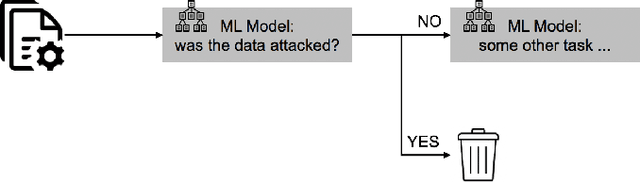


We propose using a two-layered deployment of machine learning models to prevent adversarial attacks. The first layer determines whether the data was tampered, while the second layer solves a domain-specific problem. We explore three sets of features and three dataset variations to train machine learning models. Our results show clustering algorithms achieved promising results. In particular, we consider the best results were obtained by applying the DBSCAN algorithm to the structured structural similarity index measure computed between the images and a white reference image.
Holistic Attention-Fusion Adversarial Network for Single Image Defogging
Feb 19, 2022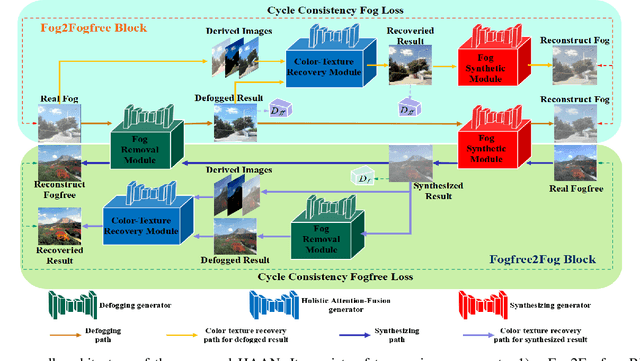



Adversarial learning-based image defogging methods have been extensively studied in computer vision due to their remarkable performance. However, most existing methods have limited defogging capabilities for real cases because they are trained on the paired clear and synthesized foggy images of the same scenes. In addition, they have limitations in preserving vivid color and rich textual details in defogging. To address these issues, we develop a novel generative adversarial network, called holistic attention-fusion adversarial network (HAAN), for single image defogging. HAAN consists of a Fog2Fogfree block and a Fogfree2Fog block. In each block, there are three learning-based modules, namely, fog removal, color-texture recovery, and fog synthetic, that are constrained each other to generate high quality images. HAAN is designed to exploit the self-similarity of texture and structure information by learning the holistic channel-spatial feature correlations between the foggy image with its several derived images. Moreover, in the fog synthetic module, we utilize the atmospheric scattering model to guide it to improve the generative quality by focusing on an atmospheric light optimization with a novel sky segmentation network. Extensive experiments on both synthetic and real-world datasets show that HAAN outperforms state-of-the-art defogging methods in terms of quantitative accuracy and subjective visual quality.
Dual Perceptual Loss for Single Image Super-Resolution Using ESRGAN
Jan 17, 2022The proposal of perceptual loss solves the problem that per-pixel difference loss function causes the reconstructed image to be overly-smooth, which acquires a significant progress in the field of single image super-resolution reconstruction. Furthermore, the generative adversarial networks (GAN) is applied to the super-resolution field, which effectively improves the visual quality of the reconstructed image. However, under the condtion of high upscaling factors, the excessive abnormal reasoning of the network produces some distorted structures, so that there is a certain deviation between the reconstructed image and the ground-truth image. In order to fundamentally improve the quality of reconstructed images, this paper proposes a effective method called Dual Perceptual Loss (DP Loss), which is used to replace the original perceptual loss to solve the problem of single image super-resolution reconstruction. Due to the complementary property between the VGG features and the ResNet features, the proposed DP Loss considers the advantages of learning two features simultaneously, which significantly improves the reconstruction effect of images. The qualitative and quantitative analysis on benchmark datasets demonstrates the superiority of our proposed method over state-of-the-art super-resolution methods.