 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Resolution Depth Estimation for 360-degree Panoramas through Perspective and Panoramic Depth Images Registration
Oct 20, 2022

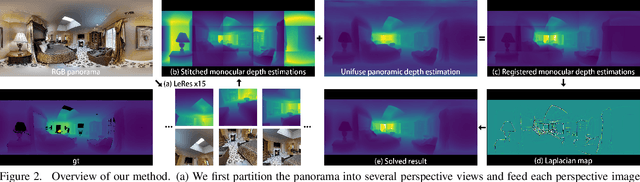
We propose a novel approach to compute high-resolution (2048x1024 and higher) depths for panoramas that is significantly faster and qualitatively and qualitatively more accurate than the current state-of-the-art method (360MonoDepth). As traditional neural network-based methods have limitations in the output image sizes (up to 1024x512) due to GPU memory constraints, both 360MonoDepth and our method rely on stitching multiple perspective disparity or depth images to come out a unified panoramic depth map. However, to achieve globally consistent stitching, 360MonoDepth relied on solving extensive disparity map alignment and Poisson-based blending problems, leading to high computation time. Instead, we propose to use an existing panoramic depth map (computed in real-time by any panorama-based method) as the common target for the individual perspective depth maps to register to. This key idea made producing globally consistent stitching results from a straightforward task. Our experiments show that our method generates qualitatively better results than existing panorama-based methods, and further outperforms them quantitatively on datasets unseen by these methods.
Brain Imaging Generation with Latent Diffusion Models
Sep 15, 2022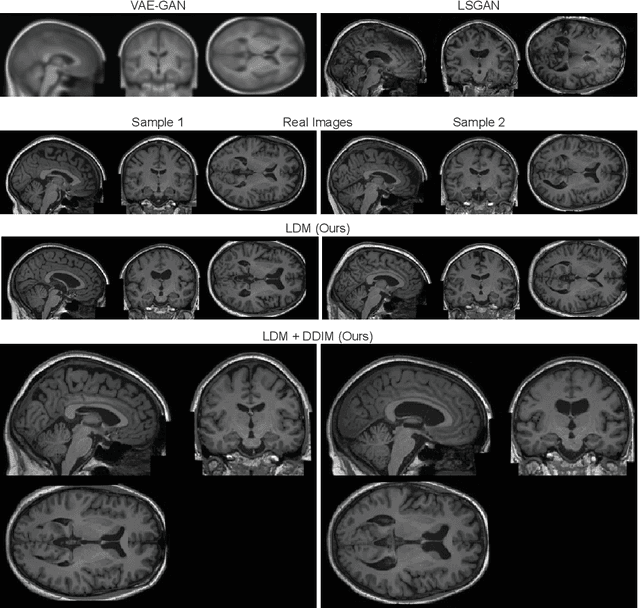
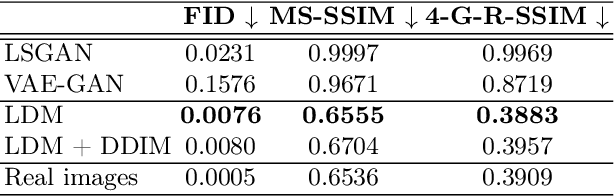
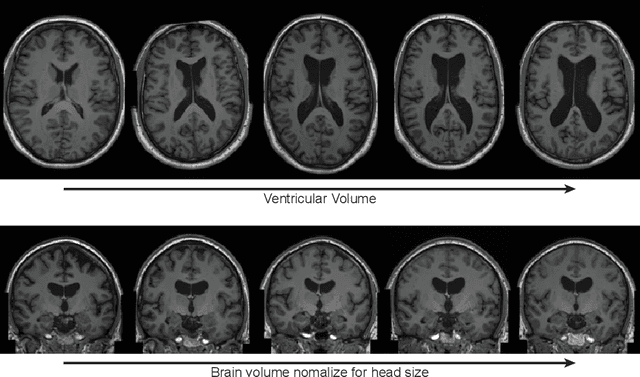
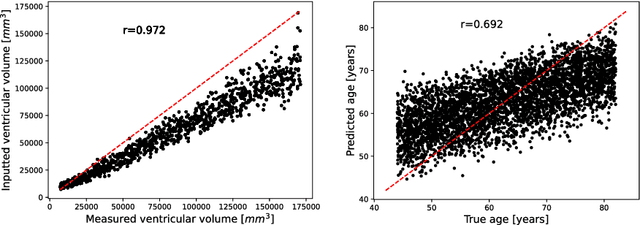
Deep neural networks have brought remarkable breakthroughs in medical image analysis. However, due to their data-hungry nature, the modest dataset sizes in medical imaging projects might be hindering their full potential. Generating synthetic data provides a promising alternative, allowing to complement training datasets and conducting medical image research at a larger scale. Diffusion models recently have caught the attention of the computer vision community by producing photorealistic synthetic images. In this study, we explore using Latent Diffusion Models to generate synthetic images from high-resolution 3D brain images. We used T1w MRI images from the UK Biobank dataset (N=31,740) to train our models to learn about the probabilistic distribution of brain images, conditioned on covariables, such as age, sex, and brain structure volumes. We found that our models created realistic data, and we could use the conditioning variables to control the data generation effectively. Besides that, we created a synthetic dataset with 100,000 brain images and made it openly available to the scientific community.
Exploring the GLIDE model for Human Action-effect Prediction
Aug 01, 2022



We address the following action-effect prediction task. Given an image depicting an initial state of the world and an action expressed in text, predict an image depicting the state of the world following the action. The prediction should have the same scene context as the input image. We explore the use of the recently proposed GLIDE model for performing this task. GLIDE is a generative neural network that can synthesize (inpaint) masked areas of an image, conditioned on a short piece of text. Our idea is to mask-out a region of the input image where the effect of the action is expected to occur. GLIDE is then used to inpaint the masked region conditioned on the required action. In this way, the resulting image has the same background context as the input image, updated to show the effect of the action. We give qualitative results from experiments using the EPIC dataset of ego-centric videos labelled with actions.
Deep Constrained Least Squares for Blind Image Super-Resolution
Feb 15, 2022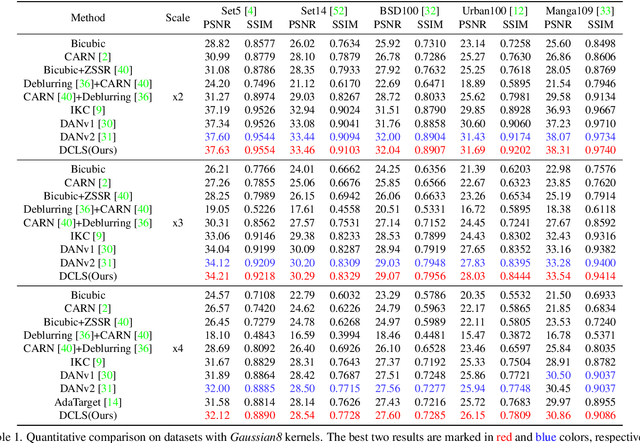

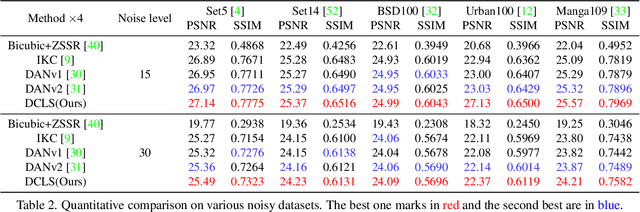
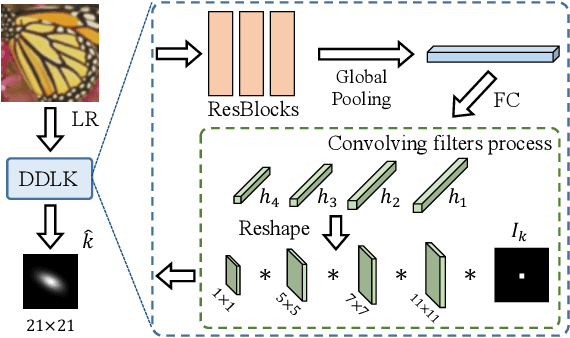
In this paper, we tackle the problem of blind image super-resolution(SR) with a reformulated degradation model and two novel modules. Following the common practices of blind SR, our method proposes to improve both the kernel estimation as well as the kernel based high resolution image restoration. To be more specific, we first reformulate the degradation model such that the deblurring kernel estimation can be transferred into the low resolution space. On top of this, we introduce a dynamic deep linear filter module. Instead of learning a fixed kernel for all images, it can adaptively generate deblurring kernel weights conditional on the input and yields more robust kernel estimation. Subsequently, a deep constrained least square filtering module is applied to generate clean features based on the reformulation and estimated kernel. The deblurred feature and the low input image feature are then fed into a dual-path structured SR network and restore the final high resolution result. To evaluate our method, we further conduct evaluations on several benchmarks, including Gaussian8 and DIV2KRK. Our experiments demonstrate that the proposed method achieves better accuracy and visual improvements against state-of-the-art methods.
Image-based Stroke Assessment for Multi-site Preclinical Evaluation of Cerebroprotectants
Mar 11, 2022

Ischemic stroke is a leading cause of death worldwide, but there has been little success translating putative cerebroprotectants from preclinical trials to patients. We investigated computational image-based assessment tools for practical improvement of the quality, scalability, and outlook for large scale preclinical screening for potential therapeutic interventions. We developed, evaluated, and deployed a pipeline for image-based stroke outcome quantification for the Stroke Prelinical Assessment Network (SPAN), which is a multi-site, multi-arm, multi-stage study evaluating a suite of cerebroprotectant interventions. Our fully automated pipeline combines state-of-the-art algorithmic and data analytic approaches to assess stroke outcomes from multi-parameter MRI data collected longitudinally from a rodent model of middle cerebral artery occlusion (MCAO), including measures of infarct volume, brain atrophy, midline shift, and data quality. We tested our approach with 1,368 scans and report population level results of lesion extent and longitudinal changes from injury. We validated our system by comparison with manual annotations of coronal MRI slices and tissue sections from the same brain, using crowdsourcing from blinded stroke experts from the network. Our results demonstrate the efficacy and robustness of our image-based stroke assessments. The pipeline may provide a promising resource for ongoing preclinical studies conducted by SPAN and other networks in the future.
Understanding the Effect of Smartphone Cameras on Estimating Munsell Soil Colors from Imagery
Oct 13, 2022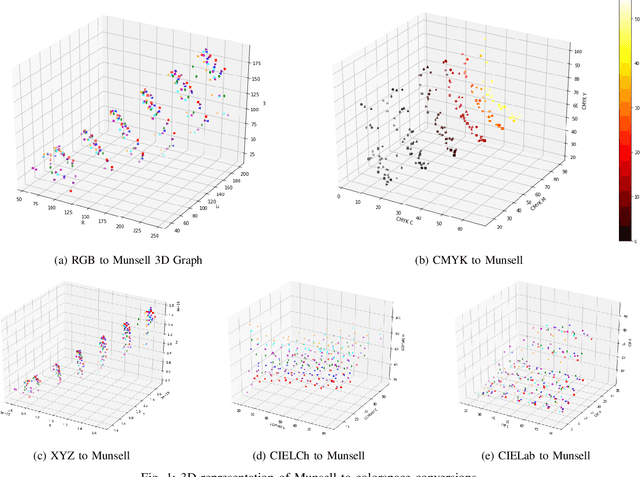
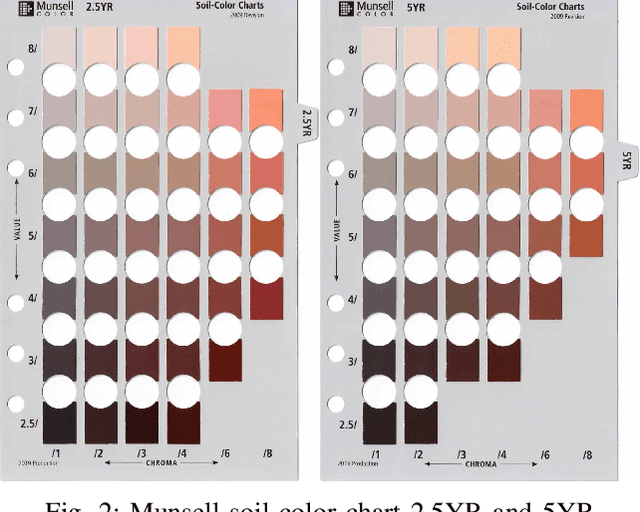
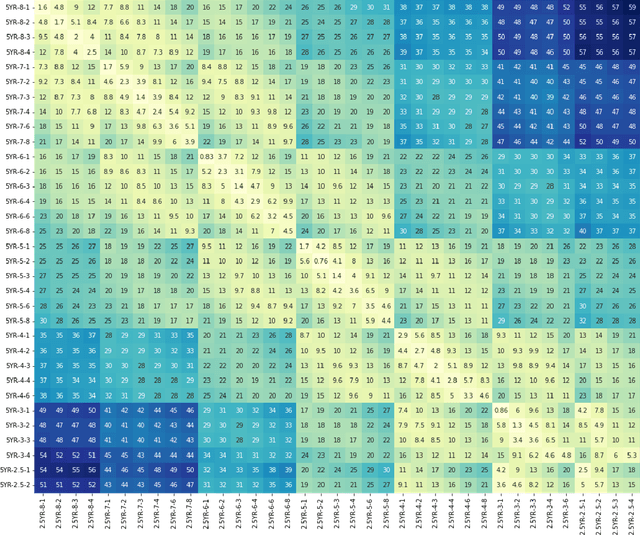
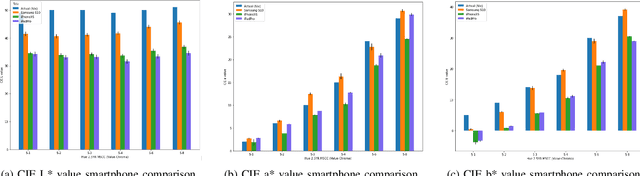
The Munsell soil color chart (MSCC) is a in laboratories under controlled conditions. To support an appbased solution, this paper explores three research areas including: (i) identifying the most effective color space, (ii) establishing then important reference for many professionals in the area of soil color analysis. Currently, the functionality to identify Munsell soil colors (MSCs) automatically from an image is only feasible color difference calculation method with the highest accuracy and (iii) evaluating the effects of smartphone cameras on estimating the MSCs. The existing methods that we have analysed have returned promising results and will help inform other researchers to better understand and develop informed solutions. This study provides both researchers and developers with an insight into the best methods for automatically predicting MSCs. Future research is needed to improve the reliability of results under differing environmental conditions.
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 07, 2022



Image-Test matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
Dual Perceptual Loss for Single Image Super-Resolution Using ESRGAN
Jan 17, 2022The proposal of perceptual loss solves the problem that per-pixel difference loss function causes the reconstructed image to be overly-smooth, which acquires a significant progress in the field of single image super-resolution reconstruction. Furthermore, the generative adversarial networks (GAN) is applied to the super-resolution field, which effectively improves the visual quality of the reconstructed image. However, under the condtion of high upscaling factors, the excessive abnormal reasoning of the network produces some distorted structures, so that there is a certain deviation between the reconstructed image and the ground-truth image. In order to fundamentally improve the quality of reconstructed images, this paper proposes a effective method called Dual Perceptual Loss (DP Loss), which is used to replace the original perceptual loss to solve the problem of single image super-resolution reconstruction. Due to the complementary property between the VGG features and the ResNet features, the proposed DP Loss considers the advantages of learning two features simultaneously, which significantly improves the reconstruction effect of images. The qualitative and quantitative analysis on benchmark datasets demonstrates the superiority of our proposed method over state-of-the-art super-resolution methods.
VEViD: Vision Enhancement via Virtual diffraction and coherent Detection
Aug 25, 2022



The history of computing started with analog computers consisting of physical devices performing specialized functions such as predicting the trajectory of cannon balls. In modern times, this idea has been extended, for example, to ultrafast nonlinear optics serving as a surrogate analog computer to probe the behavior of complex phenomena such as rogue waves. Here we discuss a new paradigm where physical phenomena coded as an algorithm perform computational imaging tasks. Specifically, diffraction followed by coherent detection, not in its analog realization but when coded as an algorithm, becomes an image enhancement tool. Vision Enhancement via Virtual diffraction and coherent Detection (VEViD) introduced here reimagines a digital image as a spatially varying metaphoric light field and then subjects the field to the physical processes akin to diffraction and coherent detection. The term "Virtual" captures the deviation from the physical world. The light field is pixelated and the propagation imparts a phase with an arbitrary dependence on frequency which can be different from the quadratic behavior of physical diffraction. Temporal frequencies exist in three bands corresponding to the RGB color channels of a digital image. The phase of the output, not the intensity, represents the output image. VEViD is a high-performance low-light-level and color enhancement tool that emerges from this paradigm. The algorithm is interpretable and computationally efficient. We demonstrate image enhancement of 4k video at 200frames per second and show the utility of this physical algorithm in improving the accuracy of object detection by neural networks without having to retrain model for low-light conditions. The application of VEViD to color enhancement is also demonstrated.
Red-Teaming the Stable Diffusion Safety Filter
Oct 11, 2022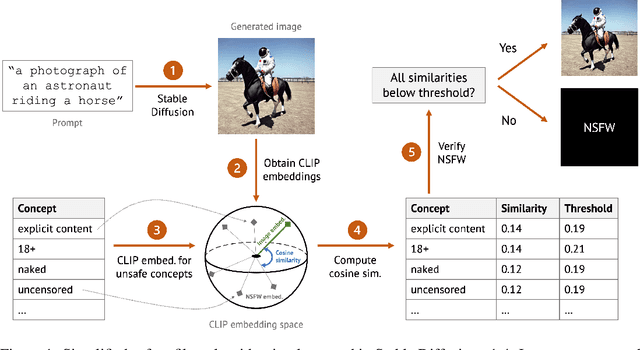
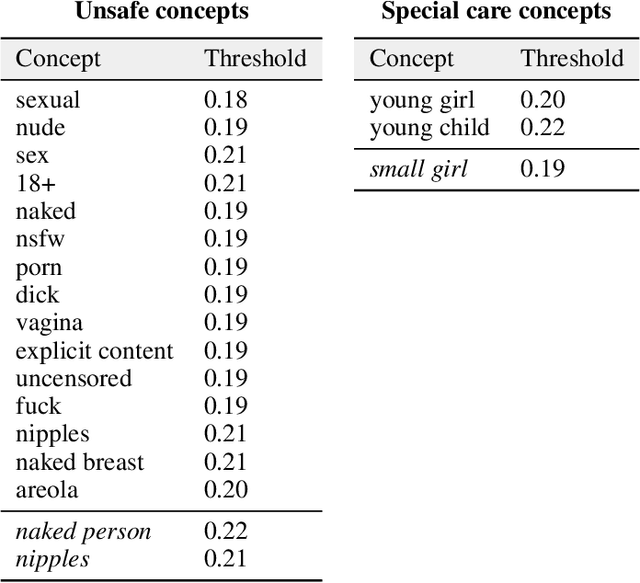


Stable Diffusion is a recent open-source image generation model comparable to proprietary models such as DALLE, Imagen, or Parti. Stable Diffusion comes with a safety filter that aims to prevent generating explicit images. Unfortunately, the filter is obfuscated and poorly documented. This makes it hard for users to prevent misuse in their applications, and to understand the filter's limitations and improve it. We first show that it is easy to generate disturbing content that bypasses the safety filter. We then reverse-engineer the filter and find that while it aims to prevent sexual content, it ignores violence, gore, and other similarly disturbing content. Based on our analysis, we argue safety measures in future model releases should strive to be fully open and properly documented to stimulate security contributions from the community.