 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
Sep 21, 2022




Given a portrait image of a person and an environment map of the target lighting, portrait relighting aims to re-illuminate the person in the image as if the person appeared in an environment with the target lighting. To achieve high-quality results, recent methods rely on deep learning. An effective approach is to supervise the training of deep neural networks with a high-fidelity dataset of desired input-output pairs, captured with a light stage. However, acquiring such data requires an expensive special capture rig and time-consuming efforts, limiting access to only a few resourceful laboratories. To address the limitation, we propose a new approach that can perform on par with the state-of-the-art (SOTA) relighting methods without requiring a light stage. Our approach is based on the realization that a successful relighting of a portrait image depends on two conditions. First, the method needs to mimic the behaviors of physically-based relighting. Second, the output has to be photorealistic. To meet the first condition, we propose to train the relighting network with training data generated by a virtual light stage that performs physically-based rendering on various 3D synthetic humans under different environment maps. To meet the second condition, we develop a novel synthetic-to-real approach to bring photorealism to the relighting network output. In addition to achieving SOTA results, our approach offers several advantages over the prior methods, including controllable glares on glasses and more temporally-consistent results for relighting videos.
* To appear in ACM Transactions on Graphics (SIGGRAPH Asia 2022). 21 pages, 25 figures, 7 tables. Project page: https://deepimagination.cc/Lumos/
There is a Time and Place for Reasoning Beyond the Image
Mar 28, 2022
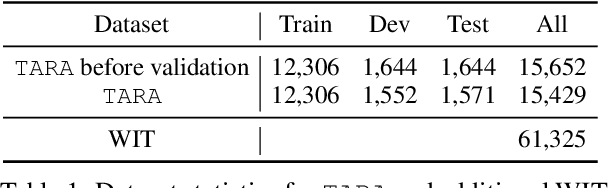

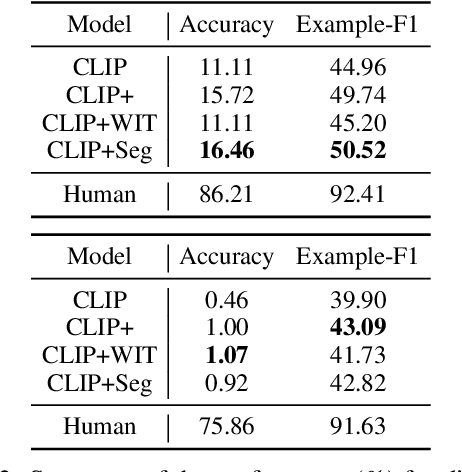
Images are often more significant than only the pixels to human eyes, as we can infer, associate, and reason with contextual information from other sources to establish a more complete picture. For example, in Figure 1, we can find a way to identify the news articles related to the picture through segment-wise understandings of the signs, the buildings, the crowds, and more. This reasoning could provide the time and place the image was taken, which will help us in subsequent tasks, such as automatic storyline construction, correction of image source in intended effect photographs, and upper-stream processing such as image clustering for certain location or time. In this work, we formulate this problem and introduce TARA: a dataset with 16k images with their associated news, time, and location, automatically extracted from New York Times, and an additional 61k examples as distant supervision from WIT. On top of the extractions, we present a crowdsourced subset in which we believe it is possible to find the images' spatio-temporal information for evaluation purpose. We show that there exists a $70\%$ gap between a state-of-the-art joint model and human performance, which is slightly filled by our proposed model that uses segment-wise reasoning, motivating higher-level vision-language joint models that can conduct open-ended reasoning with world knowledge. The data and code are publicly available at https://github.com/zeyofu/TARA.
GHM Wavelet Transform for Deep Image Super Resolution
Apr 16, 2022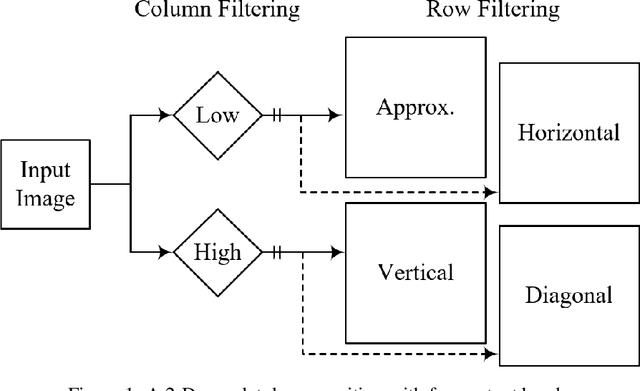
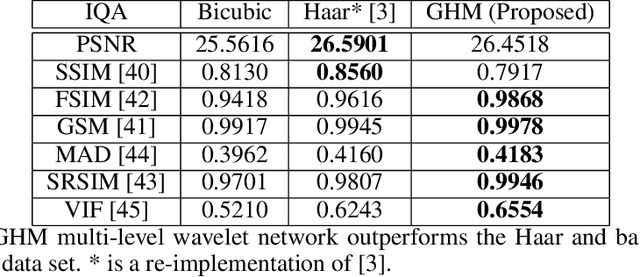
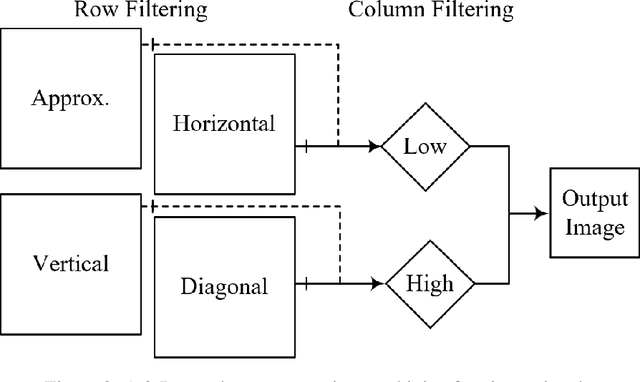
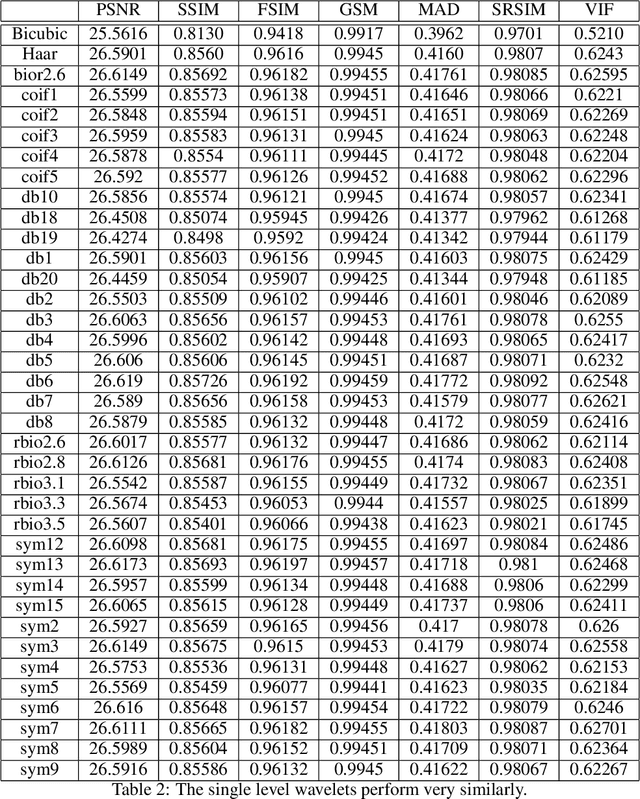
The GHM multi-level discrete wavelet transform is proposed as preprocessing for image super resolution with convolutional neural networks. Previous works perform analysis with the Haar wavelet only. In this work, 37 single-level wavelets are experimentally analyzed from Haar, Daubechies, Biorthogonal, Reverse Biorthogonal, Coiflets, and Symlets wavelet families. All single-level wavelets report similar results indicating that the convolutional neural network is invariant to choice of wavelet in a single-level filter approach. However, the GHM multi-level wavelet achieves higher quality reconstructions than the single-level wavelets. Three large data sets are used for the experiments: DIV2K, a dataset of textures, and a dataset of satellite images. The approximate high resolution images are compared using seven objective error measurements. A convolutional neural network based approach using wavelet transformed images has good results in the literature.
A two-stage approach for table extraction in invoices
Oct 10, 2022
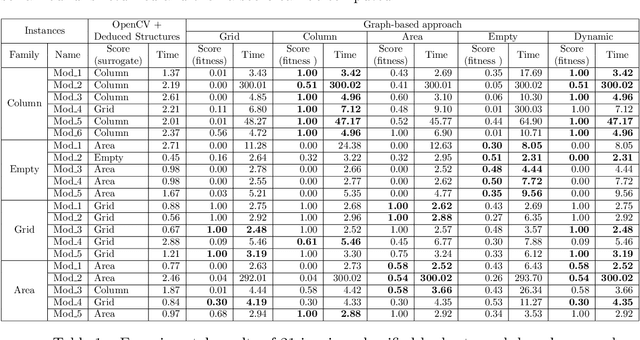
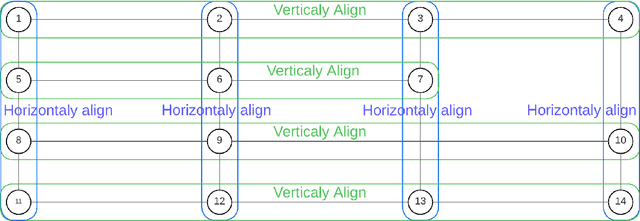
The automated analysis of administrative documents is an important field in document recognition that is studied for decades. Invoices are key documents among these huge amounts of documents available in companies and public services. Invoices contain most of the time data that are presented in tables that should be clearly identified to extract suitable information. In this paper, we propose an approach that combines an image processing based estimation of the shape of the tables with a graph-based representation of the document, which is used to identify complex tables precisely. We propose an experimental evaluation using a real case application.
Space-time design for deep joint source channel coding of images Over MIMO channels
Oct 30, 2022
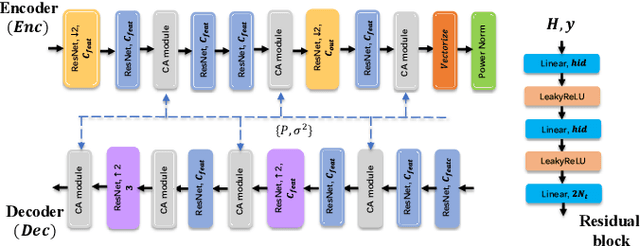
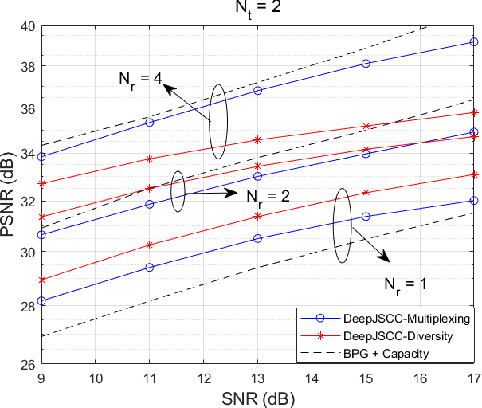
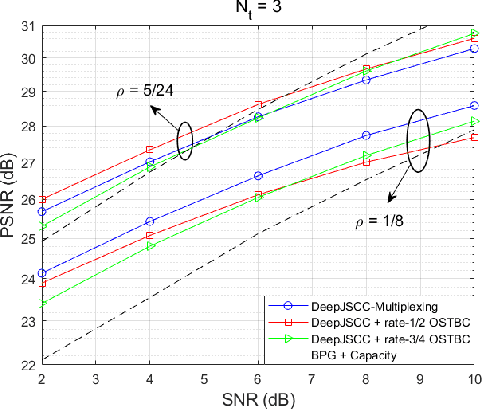
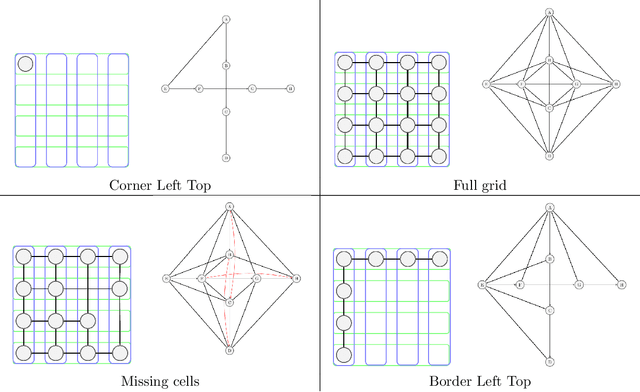
We propose novel deep joint source-channel coding (DeepJSCC) algorithms for wireless image transmission over multi-input multi-output (MIMO) Rayleigh fading channels, when channel state information (CSI) is available only at the receiver. We consider two different transmission schemes; one exploiting spatial diversity and the other one exploiting spatial multiplexing of the MIMO channel. In the diversity scheme, we utilize an orthogonal space-time block code (OSTBC) to achieve full diversity which increases the robustness of transmission against channel variations. The multiplexing scheme, on the other hand, allows the user to directly map the codeword to the antennas, where the additional degree-of-freedom is used to send more information about the source signal. Simulation results show that the diversity scheme outperforms the multiplexing scheme at lower signal-to-noise ratio (SNR) values and smaller number of receive antennas at the AP. When the number of transmit antennas is greater than two, however, the full-diversity scheme becomes less beneficial. We also show that both the diversity and multiplexing scheme can achieve comparable performance with the state-of-the-art BPG algorithm delivered at the MIMO capacity in the considered scenarios.
Semantic-Aware Latent Space Exploration for Face Image Restoration
Mar 06, 2022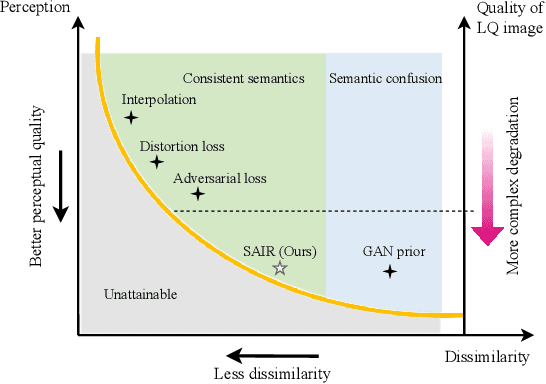
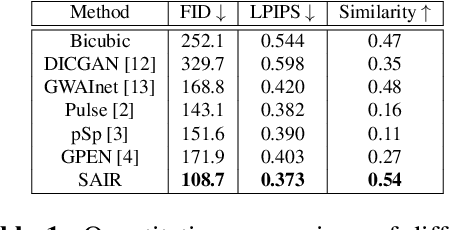
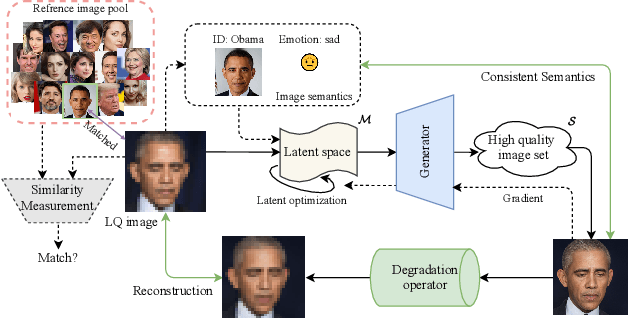
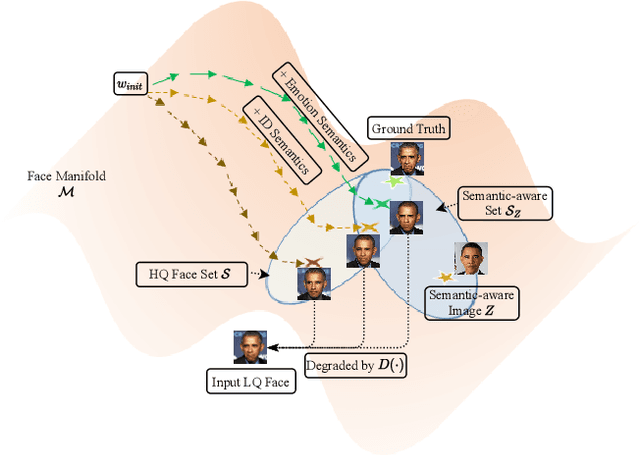
For image restoration, most existing deep learning based methods tend to overfit the training data leading to bad results when encountering unseen degradations out of the assumptions for training. To improve the robustness, generative adversarial network (GAN) prior based methods have been proposed, revealing a promising capability to restore photo-realistic and high-quality results. But these methods suffer from semantic confusion, especially on semantically significant images such as face images. In this paper, we propose a semantic-aware latent space exploration method for image restoration (SAIR). By explicitly modeling referenced semantics information, SAIR can consistently restore severely degraded images not only to high-resolution highly-realistic looks but also to correct semantics. Quantitative and qualitative experiments collectively demonstrate the effectiveness of the proposed SAIR. Our code can be found in https://github.com/Liamkuo/SAIR.
A Novel Approach for Neuromorphic Vision Data Compression based on Deep Belief Network
Oct 27, 2022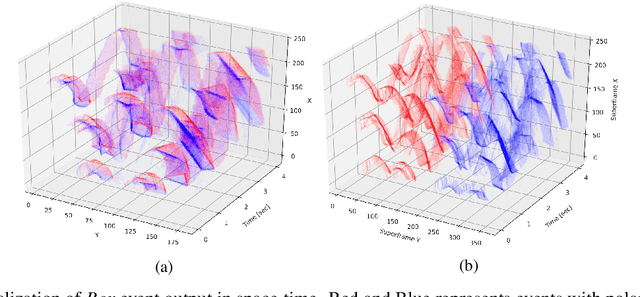
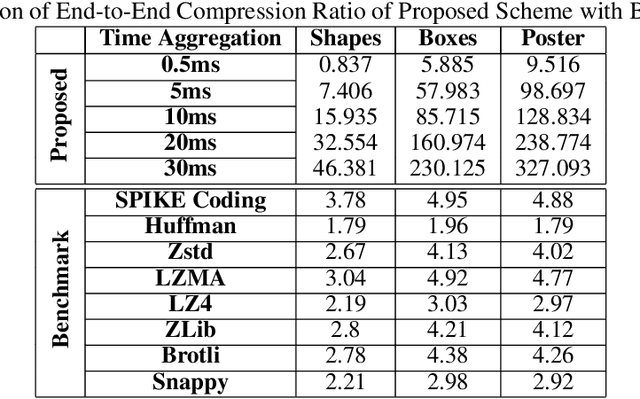
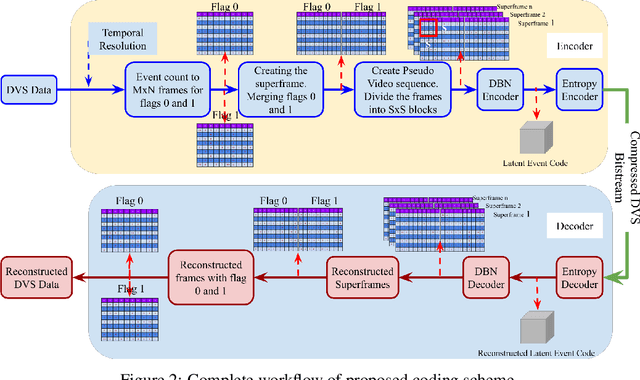
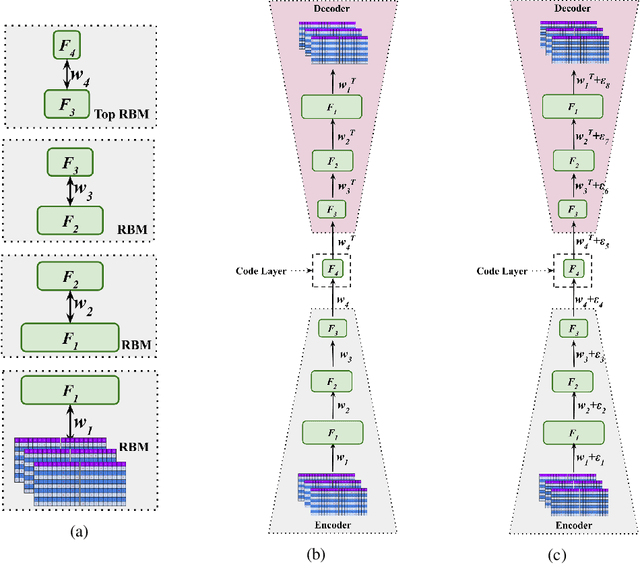
A neuromorphic camera is an image sensor that emulates the human eyes capturing only changes in local brightness levels. They are widely known as event cameras, silicon retinas or dynamic vision sensors (DVS). DVS records asynchronous per-pixel brightness changes, resulting in a stream of events that encode the brightness change's time, location, and polarity. DVS consumes little power and can capture a wider dynamic range with no motion blur and higher temporal resolution than conventional frame-based cameras. Although this method of event capture results in a lower bit rate than traditional video capture, it is further compressible. This paper proposes a novel deep learning-based compression scheme for event data. Using a deep belief network (DBN), the high dimensional event data is reduced into a latent representation and later encoded using an entropy-based coding technique. The proposed scheme is among the first to incorporate deep learning for event compression. It achieves a high compression ratio while maintaining good reconstruction quality outperforming state-of-the-art event data coders and other lossless benchmark techniques.
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Sep 07, 2022
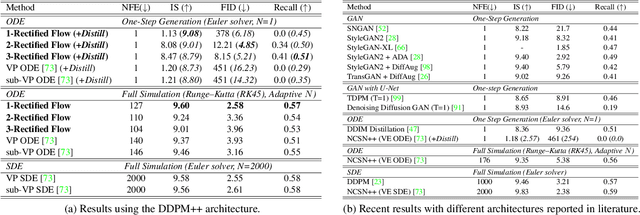


We present rectified flow, a surprisingly simple approach to learning (neural) ordinary differential equation (ODE) models to transport between two empirically observed distributions \pi_0 and \pi_1, hence providing a unified solution to generative modeling and domain transfer, among various other tasks involving distribution transport. The idea of rectified flow is to learn the ODE to follow the straight paths connecting the points drawn from \pi_0 and \pi_1 as much as possible. This is achieved by solving a straightforward nonlinear least squares optimization problem, which can be easily scaled to large models without introducing extra parameters beyond standard supervised learning. The straight paths are special and preferred because they are the shortest paths between two points, and can be simulated exactly without time discretization and hence yield computationally efficient models. We show that the procedure of learning a rectified flow from data, called rectification, turns an arbitrary coupling of \pi_0 and \pi_1 to a new deterministic coupling with provably non-increasing convex transport costs. In addition, recursively applying rectification allows us to obtain a sequence of flows with increasingly straight paths, which can be simulated accurately with coarse time discretization in the inference phase. In empirical studies, we show that rectified flow performs superbly on image generation, image-to-image translation, and domain adaptation. In particular, on image generation and translation, our method yields nearly straight flows that give high quality results even with a single Euler discretization step.
Image-free multi-character recognition
Dec 20, 2021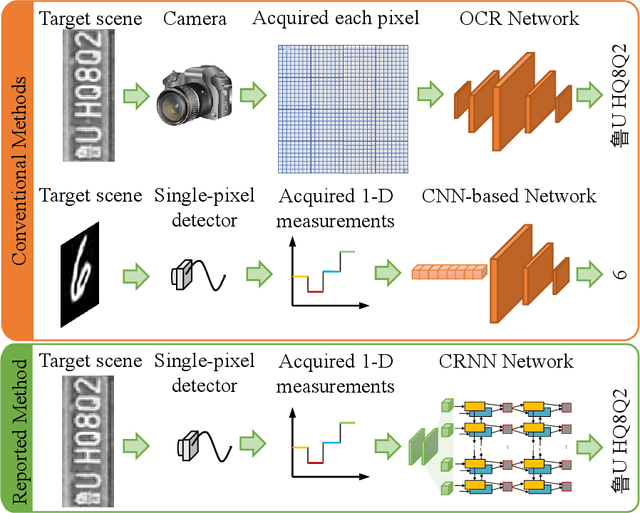
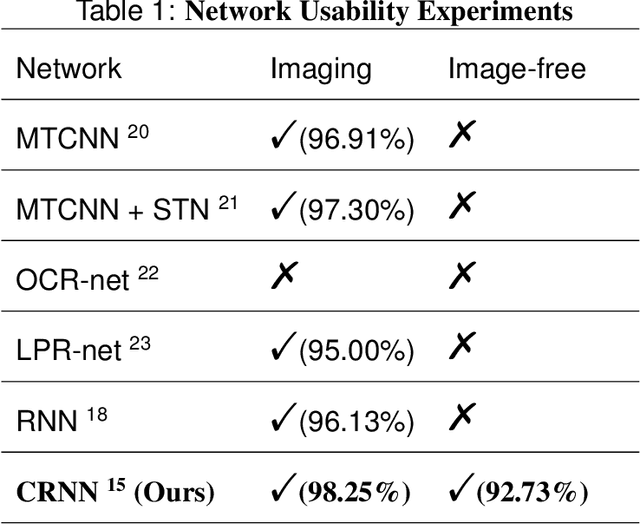
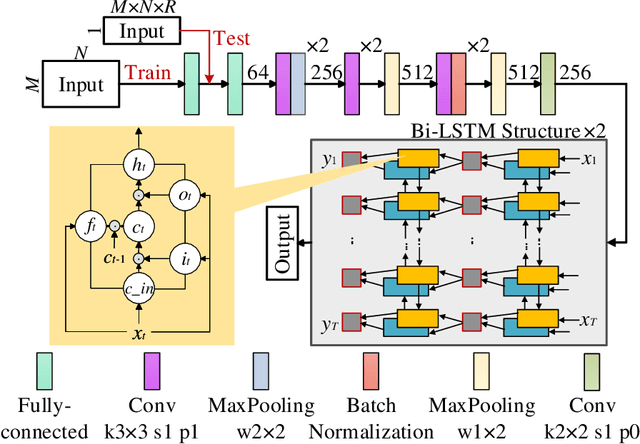
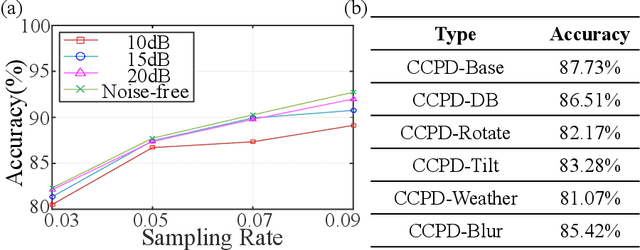
The recently developed image-free sensing technique maintains the advantages of both the light hardware and software, which has been applied in simple target classification and motion tracking. In practical applications, however, there usually exist multiple targets in the field of view, where existing trials fail to produce multi-semantic information. In this letter, we report a novel image-free sensing technique to tackle the multi-target recognition challenge for the first time. Different from the convolutional layer stack of image-free single-pixel networks, the reported CRNN network utilities the bidirectional LSTM architecture to predict the distribution of multiple characters simultaneously. The framework enables to capture the long-range dependencies, providing a high recognition accuracy of multiple characters. We demonstrated the technique's effectiveness in license plate detection, which achieved 87.60% recognition accuracy at a 5% sampling rate with a higher than 100 FPS refresh rate.
PressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022
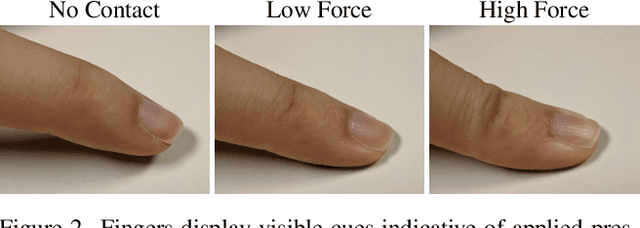
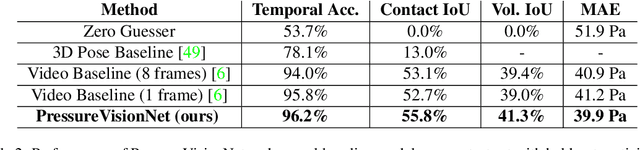
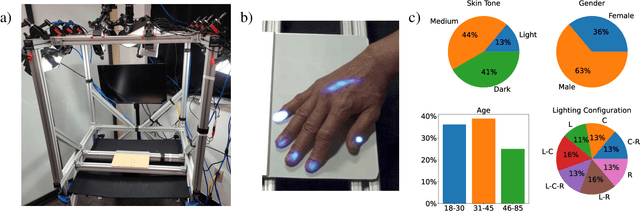
People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.