 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Beyond Finite Data: Towards Data-free Out-of-distribution Generalization via Extrapolation
Mar 11, 2024
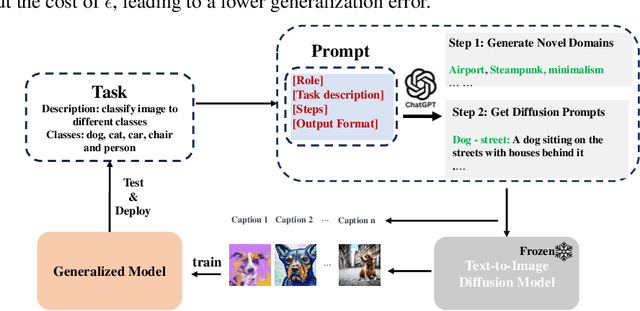
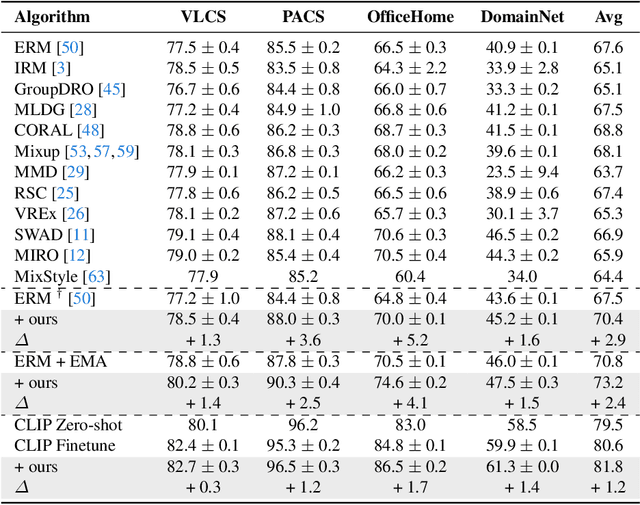
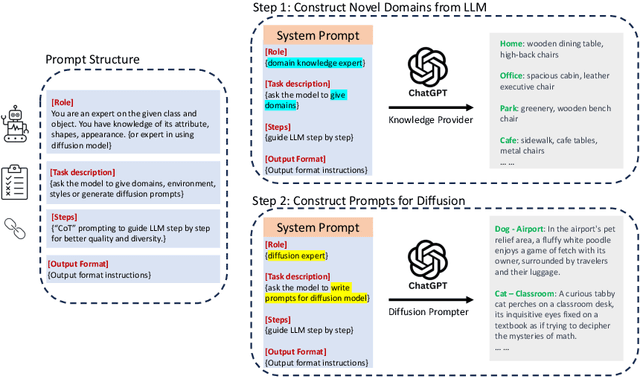
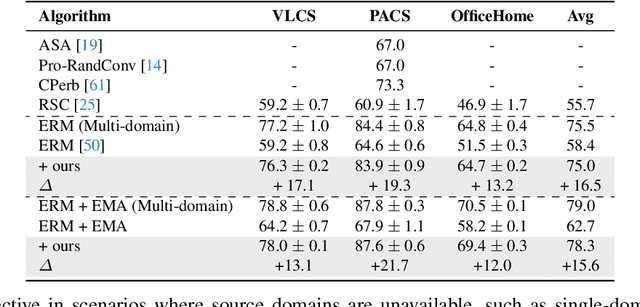
Out-of-distribution (OOD) generalization is a favorable yet challenging property for deep neural networks. The core challenges lie in the limited availability of source domains that help models learn an invariant representation from the spurious features. Various domain augmentation have been proposed but largely rely on interpolating existing domains and frequently face difficulties in creating truly "novel" domains. Humans, on the other hand, can easily extrapolate novel domains, thus, an intriguing question arises: How can neural networks extrapolate like humans and achieve OOD generalization? We introduce a novel approach to domain extrapolation that leverages reasoning ability and the extensive knowledge encapsulated within large language models (LLMs) to synthesize entirely new domains. Starting with the class of interest, we query the LLMs to extract relevant knowledge for these novel domains. We then bridge the gap between the text-centric knowledge derived from LLMs and the pixel input space of the model using text-to-image generation techniques. By augmenting the training set of domain generalization datasets with high-fidelity, photo-realistic images of these new domains, we achieve significant improvements over all existing methods, as demonstrated in both single and multi-domain generalization across various benchmarks. With the ability to extrapolate any domains for any class, our method has the potential to learn a generalized model for any task without any data. To illustrate, we put forth a much more difficult setting termed, data-free domain generalization, that aims to learn a generalized model in the absence of any collected data. Our empirical findings support the above argument and our methods exhibit commendable performance in this setting, even surpassing the supervised setting by approximately 1-2\% on datasets such as VLCS.
Simplicity in Complexity
Mar 05, 2024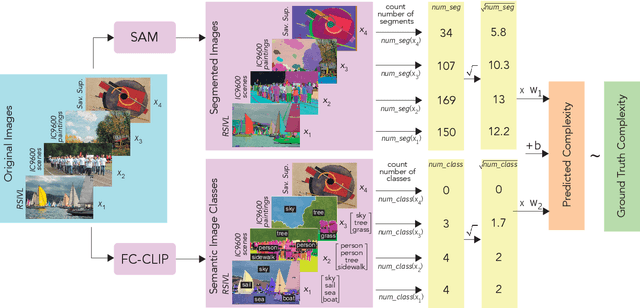
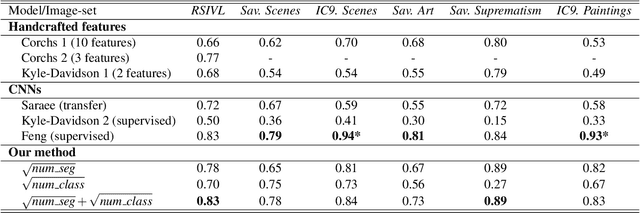
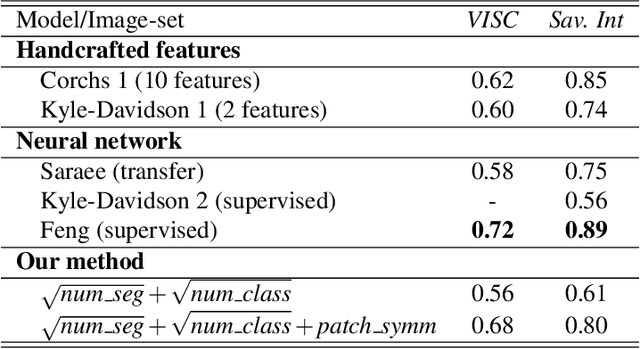

The complexity of visual stimuli plays an important role in many cognitive phenomena, including attention, engagement, memorability, time perception and aesthetic evaluation. Despite its importance, complexity is poorly understood and ironically, previous models of image complexity have been quite \textit{complex}. There have been many attempts to find handcrafted features that explain complexity, but these features are usually dataset specific, and hence fail to generalise. On the other hand, more recent work has employed deep neural networks to predict complexity, but these models remain difficult to interpret, and do not guide a theoretical understanding of the problem. Here we propose to model complexity using segment-based representations of images. We use state-of-the-art segmentation models, SAM and FC-CLIP, to quantify the number of segments at multiple granularities, and the number of classes in an image respectively. We find that complexity is well-explained by a simple linear model with these two features across six diverse image-sets of naturalistic scene and art images. This suggests that the complexity of images can be surprisingly simple.
BAGS: Blur Agnostic Gaussian Splatting through Multi-Scale Kernel Modeling
Mar 07, 2024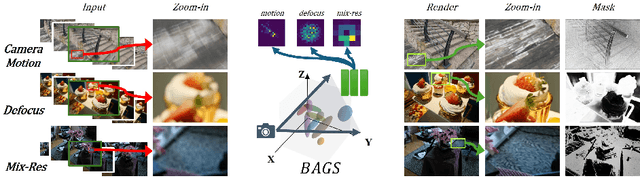
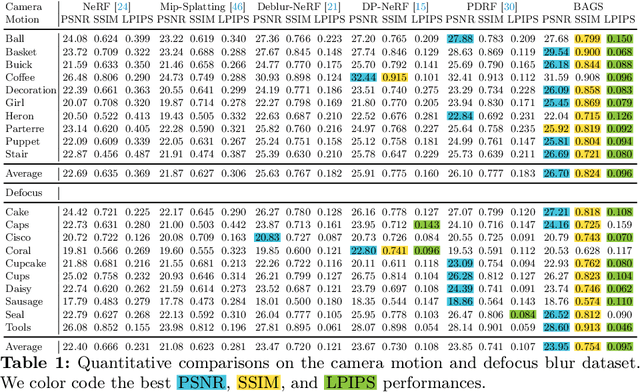
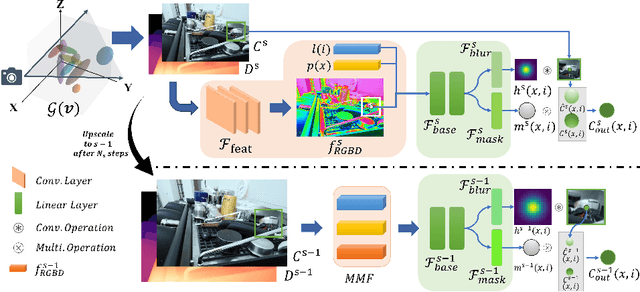

Recent efforts in using 3D Gaussians for scene reconstruction and novel view synthesis can achieve impressive results on curated benchmarks; however, images captured in real life are often blurry. In this work, we analyze the robustness of Gaussian-Splatting-based methods against various image blur, such as motion blur, defocus blur, downscaling blur, \etc. Under these degradations, Gaussian-Splatting-based methods tend to overfit and produce worse results than Neural-Radiance-Field-based methods. To address this issue, we propose Blur Agnostic Gaussian Splatting (BAGS). BAGS introduces additional 2D modeling capacities such that a 3D-consistent and high quality scene can be reconstructed despite image-wise blur. Specifically, we model blur by estimating per-pixel convolution kernels from a Blur Proposal Network (BPN). BPN is designed to consider spatial, color, and depth variations of the scene to maximize modeling capacity. Additionally, BPN also proposes a quality-assessing mask, which indicates regions where blur occur. Finally, we introduce a coarse-to-fine kernel optimization scheme; this optimization scheme is fast and avoids sub-optimal solutions due to a sparse point cloud initialization, which often occurs when we apply Structure-from-Motion on blurry images. We demonstrate that BAGS achieves photorealistic renderings under various challenging blur conditions and imaging geometry, while significantly improving upon existing approaches.
CLIP the Bias: How Useful is Balancing Data in Multimodal Learning?
Mar 07, 2024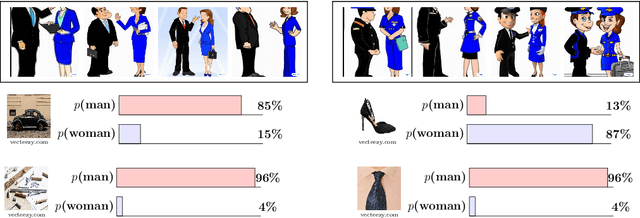
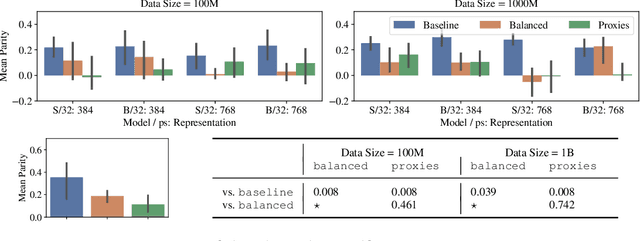

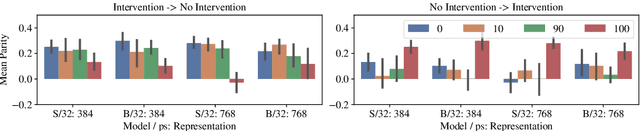
We study the effectiveness of data-balancing for mitigating biases in contrastive language-image pretraining (CLIP), identifying areas of strength and limitation. First, we reaffirm prior conclusions that CLIP models can inadvertently absorb societal stereotypes. To counter this, we present a novel algorithm, called Multi-Modal Moment Matching (M4), designed to reduce both representation and association biases (i.e. in first- and second-order statistics) in multimodal data. We use M4 to conduct an in-depth analysis taking into account various factors, such as the model, representation, and data size. Our study also explores the dynamic nature of how CLIP learns and unlearns biases. In particular, we find that fine-tuning is effective in countering representation biases, though its impact diminishes for association biases. Also, data balancing has a mixed impact on quality: it tends to improve classification but can hurt retrieval. Interestingly, data and architectural improvements seem to mitigate the negative impact of data balancing on performance; e.g. applying M4 to SigLIP-B/16 with data quality filters improves COCO image-to-text retrieval @5 from 86% (without data balancing) to 87% and ImageNet 0-shot classification from 77% to 77.5%! Finally, we conclude with recommendations for improving the efficacy of data balancing in multimodal systems.
* 32 pages, 20 figures, 7 tables
T-TAME: Trainable Attention Mechanism for Explaining Convolutional Networks and Vision Transformers
Mar 07, 2024The development and adoption of Vision Transformers and other deep-learning architectures for image classification tasks has been rapid. However, the "black box" nature of neural networks is a barrier to adoption in applications where explainability is essential. While some techniques for generating explanations have been proposed, primarily for Convolutional Neural Networks, adapting such techniques to the new paradigm of Vision Transformers is non-trivial. This paper presents T-TAME, Transformer-compatible Trainable Attention Mechanism for Explanations, a general methodology for explaining deep neural networks used in image classification tasks. The proposed architecture and training technique can be easily applied to any convolutional or Vision Transformer-like neural network, using a streamlined training approach. After training, explanation maps can be computed in a single forward pass; these explanation maps are comparable to or outperform the outputs of computationally expensive perturbation-based explainability techniques, achieving SOTA performance. We apply T-TAME to three popular deep learning classifier architectures, VGG-16, ResNet-50, and ViT-B-16, trained on the ImageNet dataset, and we demonstrate improvements over existing state-of-the-art explainability methods. A detailed analysis of the results and an ablation study provide insights into how the T-TAME design choices affect the quality of the generated explanation maps.
LoLiSRFlow: Joint Single Image Low-light Enhancement and Super-resolution via Cross-scale Transformer-based Conditional Flow
Feb 29, 2024The visibility of real-world images is often limited by both low-light and low-resolution, however, these issues are only addressed in the literature through Low-Light Enhancement (LLE) and Super- Resolution (SR) methods. Admittedly, a simple cascade of these approaches cannot work harmoniously to cope well with the highly ill-posed problem for simultaneously enhancing visibility and resolution. In this paper, we propose a normalizing flow network, dubbed LoLiSRFLow, specifically designed to consider the degradation mechanism inherent in joint LLE and SR. To break the bonds of the one-to-many mapping for low-light low-resolution images to normal-light high-resolution images, LoLiSRFLow directly learns the conditional probability distribution over a variety of feasible solutions for high-resolution well-exposed images. Specifically, a multi-resolution parallel transformer acts as a conditional encoder that extracts the Retinex-induced resolution-and-illumination invariant map as the previous one. And the invertible network maps the distribution of usually exposed high-resolution images to a latent distribution. The backward inference is equivalent to introducing an additional constrained loss for the normal training route, thus enabling the manifold of the natural exposure of the high-resolution image to be immaculately depicted. We also propose a synthetic dataset modeling the realistic low-light low-resolution degradation, named DFSR-LLE, containing 7100 low-resolution dark-light/high-resolution normal sharp pairs. Quantitative and qualitative experimental results demonstrate the effectiveness of our method on both the proposed synthetic and real datasets.
Deep, convergent, unrolled half-quadratic splitting for image deconvolution
Feb 25, 2024In recent years, algorithm unrolling has emerged as a powerful technique for designing interpretable neural networks based on iterative algorithms. Imaging inverse problems have particularly benefited from unrolling-based deep network design since many traditional model-based approaches rely on iterative optimization. Despite exciting progress, typical unrolling approaches heuristically design layer-specific convolution weights to improve performance. Crucially, convergence properties of the underlying iterative algorithm are lost once layer-specific parameters are learned from training data. We propose an unrolling technique that breaks the trade-off between retaining algorithm properties while simultaneously enhancing performance. We focus on image deblurring and unrolling the widely-applied Half-Quadratic Splitting (HQS) algorithm. We develop a new parametrization scheme which enforces layer-specific parameters to asymptotically approach certain fixed points. Through extensive experimental studies, we verify that our approach achieves competitive performance with state-of-the-art unrolled layer-specific learning and significantly improves over the traditional HQS algorithm. We further establish convergence of the proposed unrolled network as the number of layers approaches infinity, and characterize its convergence rate. Our experimental verification involves simulations that validate the analytical results as well as comparison with state-of-the-art non-blind deblurring techniques on benchmark datasets. The merits of the proposed convergent unrolled network are established over competing alternatives, especially in the regime of limited training.
BlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering
Mar 10, 2024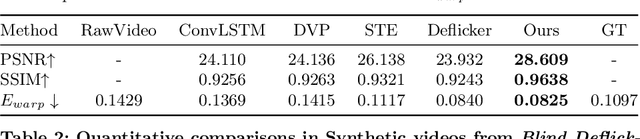

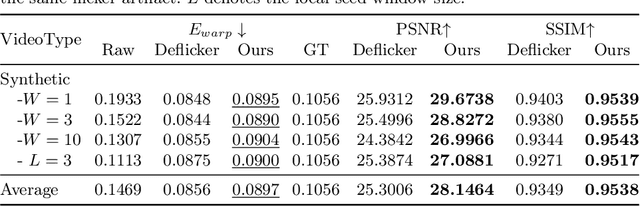
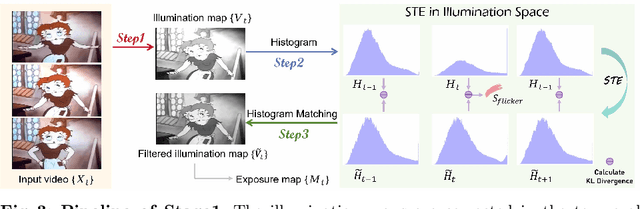
Developing blind video deflickering (BVD) algorithms to enhance video temporal consistency, is gaining importance amid the flourish of image processing and video generation. However, the intricate nature of video data complicates the training of deep learning methods, leading to high resource consumption and instability, notably under severe lighting flicker. This underscores the critical need for a compact representation beyond pixel values to advance BVD research and applications. Inspired by the classic scale-time equalization (STE), our work introduces the histogram-assisted solution, called BlazeBVD, for high-fidelity and rapid BVD. Compared with STE, which directly corrects pixel values by temporally smoothing color histograms, BlazeBVD leverages smoothed illumination histograms within STE filtering to ease the challenge of learning temporal data using neural networks. In technique, BlazeBVD begins by condensing pixel values into illumination histograms that precisely capture flickering and local exposure variations. These histograms are then smoothed to produce singular frames set, filtered illumination maps, and exposure maps. Resorting to these deflickering priors, BlazeBVD utilizes a 2D network to restore faithful and consistent texture impacted by lighting changes or localized exposure issues. BlazeBVD also incorporates a lightweight 3D network to amend slight temporal inconsistencies, avoiding the resource consumption issue. Comprehensive experiments on synthetic, real-world and generated videos, showcase the superior qualitative and quantitative results of BlazeBVD, achieving inference speeds up to 10x faster than state-of-the-arts.
Distinctive Image Captioning: Leveraging Ground Truth Captions in CLIP Guided Reinforcement Learning
Feb 21, 2024Training image captioning models using teacher forcing results in very generic samples, whereas more distinctive captions can be very useful in retrieval applications or to produce alternative texts describing images for accessibility. Reinforcement Learning (RL) allows to use cross-modal retrieval similarity score between the generated caption and the input image as reward to guide the training, leading to more distinctive captions. Recent studies show that pre-trained cross-modal retrieval models can be used to provide this reward, completely eliminating the need for reference captions. However, we argue in this paper that Ground Truth (GT) captions can still be useful in this RL framework. We propose a new image captioning model training strategy that makes use of GT captions in different ways. Firstly, they can be used to train a simple MLP discriminator that serves as a regularization to prevent reward hacking and ensures the fluency of generated captions, resulting in a textual GAN setup extended for multimodal inputs. Secondly, they can serve as additional trajectories in the RL strategy, resulting in a teacher forcing loss weighted by the similarity of the GT to the image. This objective acts as an additional learning signal grounded to the distribution of the GT captions. Thirdly, they can serve as strong baselines when added to the pool of captions used to compute the proposed contrastive reward to reduce the variance of gradient estimate. Experiments on MS-COCO demonstrate the interest of the proposed training strategy to produce highly distinctive captions while maintaining high writing quality.
Multi-Objective Learning for Deformable Image Registration
Feb 23, 2024Deformable image registration (DIR) involves optimization of multiple conflicting objectives, however, not many existing DIR algorithms are multi-objective (MO). Further, while there has been progress in the design of deep learning algorithms for DIR, there is no work in the direction of MO DIR using deep learning. In this paper, we fill this gap by combining a recently proposed approach for MO training of neural networks with a well-known deep neural network for DIR and create a deep learning based MO DIR approach. We evaluate the proposed approach for DIR of pelvic magnetic resonance imaging (MRI) scans. We experimentally demonstrate that the proposed MO DIR approach -- providing multiple registration outputs for each patient that each correspond to a different trade-off between the objectives -- has additional desirable properties from a clinical use point-of-view as compared to providing a single DIR output. The experiments also show that the proposed MO DIR approach provides a better spread of DIR outputs across the entire trade-off front than simply training multiple neural networks with weights for each objective sampled from a grid of possible values.