 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-time Virtual-Try-On from a Single Example Image through Deep Inverse Graphics and Learned Differentiable Renderers
May 12, 2022


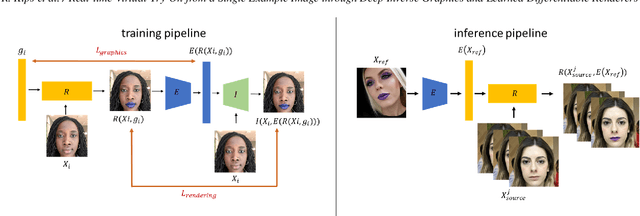

Augmented reality applications have rapidly spread across online platforms, allowing consumers to virtually try-on a variety of products, such as makeup, hair dying, or shoes. However, parametrizing a renderer to synthesize realistic images of a given product remains a challenging task that requires expert knowledge. While recent work has introduced neural rendering methods for virtual try-on from example images, current approaches are based on large generative models that cannot be used in real-time on mobile devices. This calls for a hybrid method that combines the advantages of computer graphics and neural rendering approaches. In this paper we propose a novel framework based on deep learning to build a real-time inverse graphics encoder that learns to map a single example image into the parameter space of a given augmented reality rendering engine. Our method leverages self-supervised learning and does not require labeled training data which makes it extendable to many virtual try-on applications. Furthermore, most augmented reality renderers are not differentiable in practice due to algorithmic choices or implementation constraints to reach real-time on portable devices. To relax the need for a graphics-based differentiable renderer in inverse graphics problems, we introduce a trainable imitator module. Our imitator is a generative network that learns to accurately reproduce the behavior of a given non-differentiable renderer. We propose a novel rendering sensitivity loss to train the imitator, which ensures that the network learns an accurate and continuous representation for each rendering parameter. Our framework enables novel applications where consumers can virtually try-on a novel unknown product from an inspirational reference image on social media. It can also be used by graphics artists to automatically create realistic rendering from a reference product image.
A Smoothing and Thresholding Image Segmentation Framework with Weighted Anisotropic-Isotropic Total Variation
Mar 20, 2022
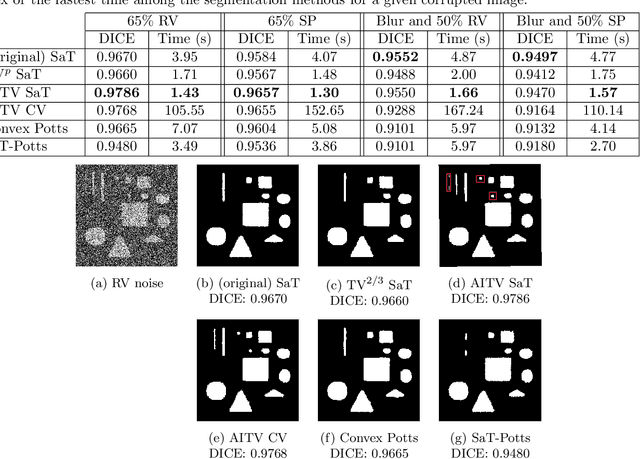

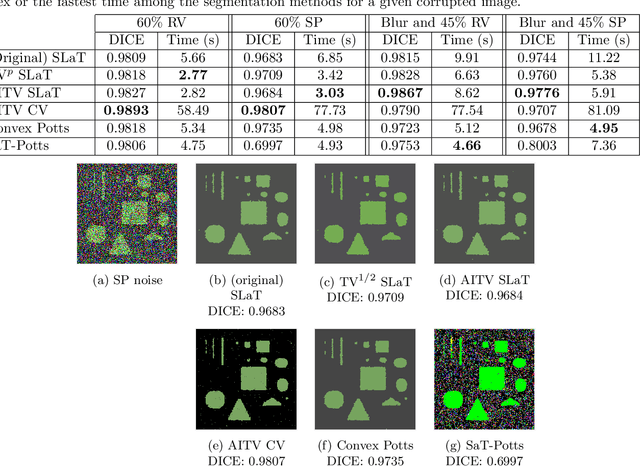
In this paper, we propose a multi-stage image segmentation framework that incorporates a weighted difference of anisotropic and isotropic total variation (AITV). The segmentation framework generally consists of two stages: smoothing and thresholding, thus referred to as SaT. In the first stage, a smoothed image is obtained by an AITV-regularized Mumford-Shah (MS) model, which can be solved efficiently by the alternating direction method of multipliers (ADMM) with a closed-form solution of a proximal operator of the $\ell_1 -\alpha \ell_2$ regularizer. Convergence of the ADMM algorithm is analyzed. In the second stage, we threshold the smoothed image by $k$-means clustering to obtain the final segmentation result. Numerical experiments demonstrate that the proposed segmentation framework is versatile for both grayscale and color images, efficient in producing high-quality segmentation results within a few seconds, and robust to input images that are corrupted with noise, blur, or both. We compare the AITV method with its original convex and nonconvex TV$^p (0<p<1)$ counterparts, showcasing the qualitative and quantitative advantages of our proposed method.
Multiple Instance Learning via Iterative Self-Paced Supervised Contrastive Learning
Oct 17, 2022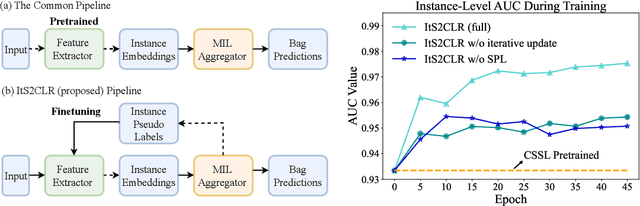
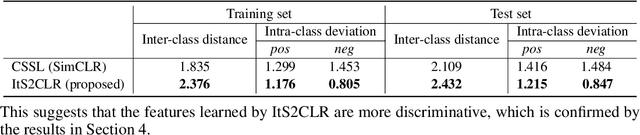
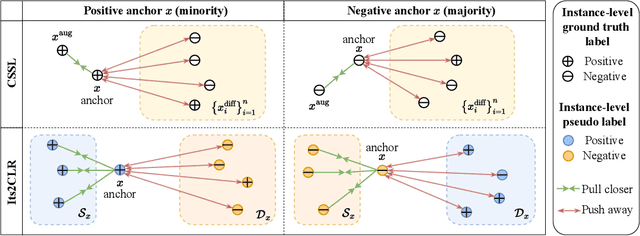

Learning representations for individual instances when only bag-level labels are available is a fundamental challenge in multiple instance learning (MIL). Recent works have shown promising results using contrastive self-supervised learning (CSSL), which learns to push apart representations corresponding to two different randomly-selected instances. Unfortunately, in real-world applications such as medical image classification, there is often class imbalance, so randomly-selected instances mostly belong to the same majority class, which precludes CSSL from learning inter-class differences. To address this issue, we propose a novel framework, Iterative Self-paced Supervised Contrastive Learning for MIL Representations (ItS2CLR), which improves the learned representation by exploiting instance-level pseudo labels derived from the bag-level labels. The framework employs a novel self-paced sampling strategy to ensure the accuracy of pseudo labels. We evaluate ItS2CLR on three medical datasets, showing that it improves the quality of instance-level pseudo labels and representations, and outperforms existing MIL methods in terms of both bag and instance level accuracy.
A Novel Membership Inference Attack against Dynamic Neural Networks by Utilizing Policy Networks Information
Oct 17, 2022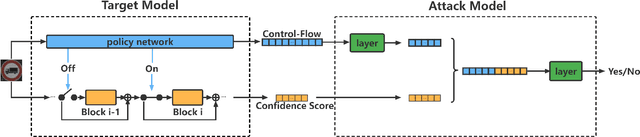
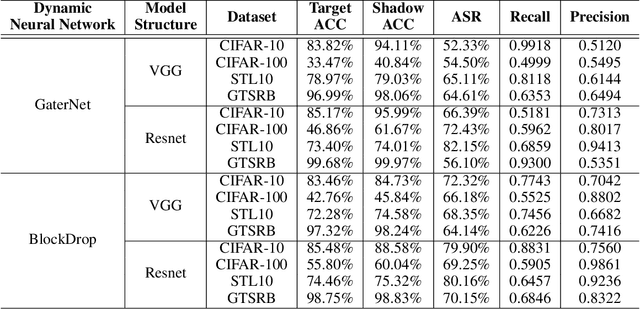
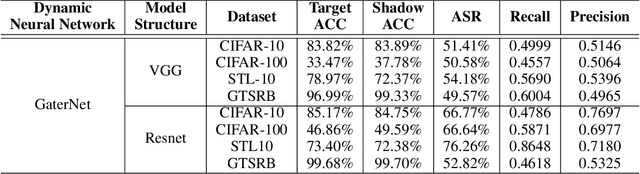

Unlike traditional static deep neural networks (DNNs), dynamic neural networks (NNs) adjust their structures or parameters to different inputs to guarantee accuracy and computational efficiency. Meanwhile, it has been an emerging research area in deep learning recently. Although traditional static DNNs are vulnerable to the membership inference attack (MIA) , which aims to infer whether a particular point was used to train the model, little is known about how such an attack performs on the dynamic NNs. In this paper, we propose a novel MI attack against dynamic NNs, leveraging the unique policy networks mechanism of dynamic NNs to increase the effectiveness of membership inference. We conducted extensive experiments using two dynamic NNs, i.e., GaterNet, BlockDrop, on four mainstream image classification tasks, i.e., CIFAR-10, CIFAR-100, STL-10, and GTSRB. The evaluation results demonstrate that the control-flow information can significantly promote the MIA. Based on backbone-finetuning and information-fusion, our method achieves better results than baseline attack and traditional attack using intermediate information.
ArtFacePoints: High-resolution Facial Landmark Detection in Paintings and Prints
Oct 17, 2022
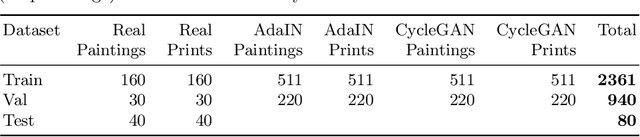

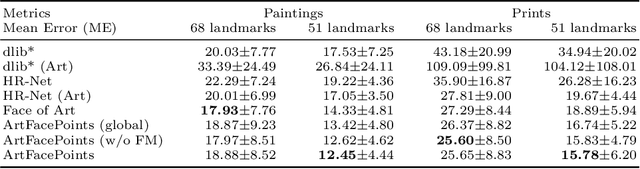
Facial landmark detection plays an important role for the similarity analysis in artworks to compare portraits of the same or similar artists. With facial landmarks, portraits of different genres, such as paintings and prints, can be automatically aligned using control-point-based image registration. We propose a deep-learning-based method for facial landmark detection in high-resolution images of paintings and prints. It divides the task into a global network for coarse landmark prediction and multiple region networks for precise landmark refinement in regions of the eyes, nose, and mouth that are automatically determined based on the predicted global landmark coordinates. We created a synthetically augmented facial landmark art dataset including artistic style transfer and geometric landmark shifts. Our method demonstrates an accurate detection of the inner facial landmarks for our high-resolution dataset of artworks while being comparable for a public low-resolution artwork dataset in comparison to competing methods.
Massive MIMO Channel Prediction Via Meta-Learning and Deep Denoising: Is a Small Dataset Enough?
Oct 17, 2022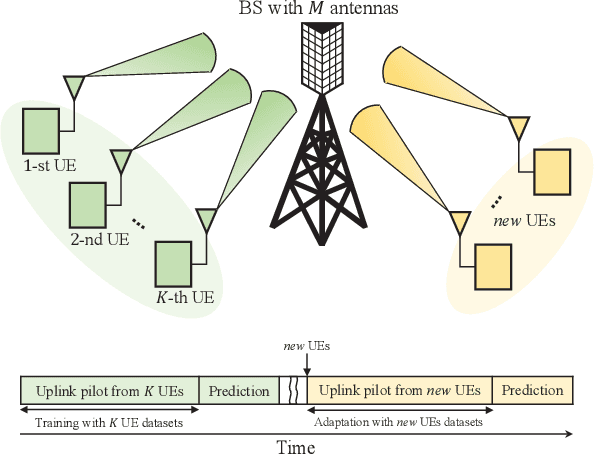
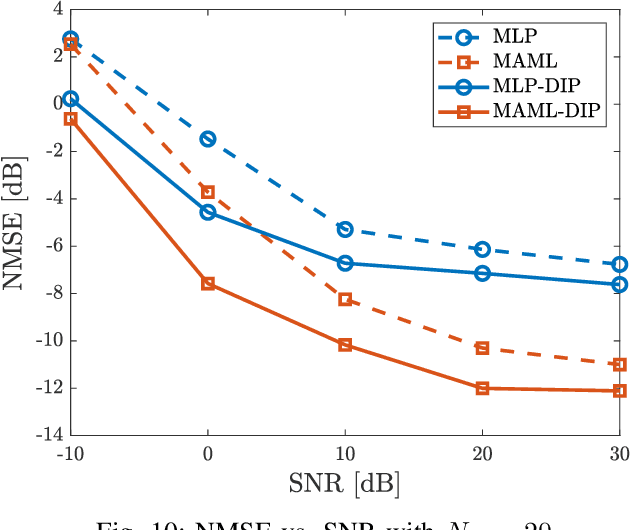
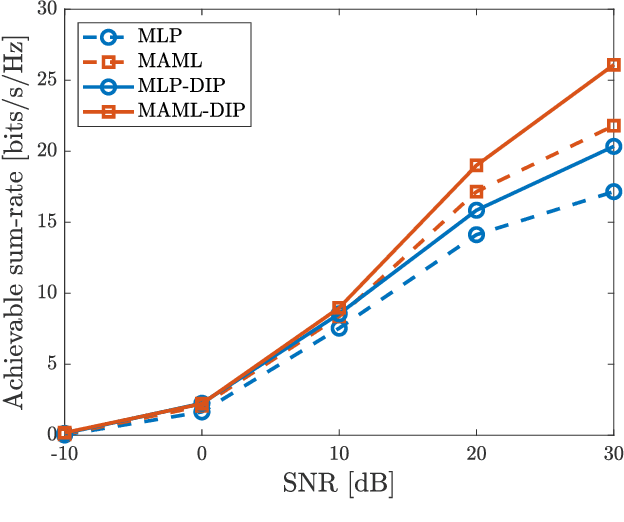
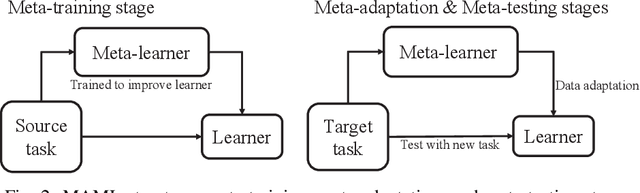
Accurate channel knowledge is critical in massive multiple-input multiple-output (MIMO), which motivates the use of channel prediction. Machine learning techniques for channel prediction hold much promise, but current schemes are limited in their ability to adapt to changes in the environment because they require large training overheads. To accurately predict wireless channels for new environments with reduced training overhead, we propose a fast adaptive channel prediction technique based on a meta-learning algorithm for massive MIMO communications. We exploit the model-agnostic meta-learning (MAML) algorithm to achieve quick adaptation with a small amount of labeled data. Also, to improve the prediction accuracy, we adopt the denoising process for the training data by using deep image prior (DIP). Numerical results show that the proposed MAML-based channel predictor can improve the prediction accuracy with only a few fine-tuning samples. The DIP-based denoising process gives an additional gain in channel prediction, especially in low signal-to-noise ratio regimes.
KXNet: A Model-Driven Deep Neural Network for Blind Super-Resolution
Sep 22, 2022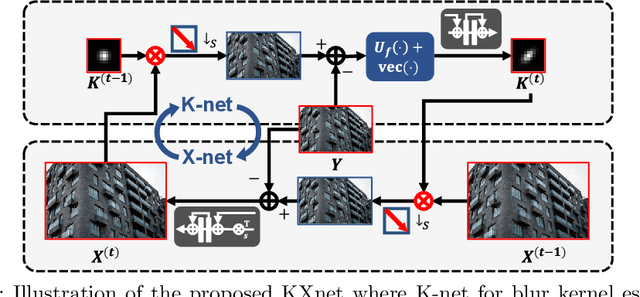
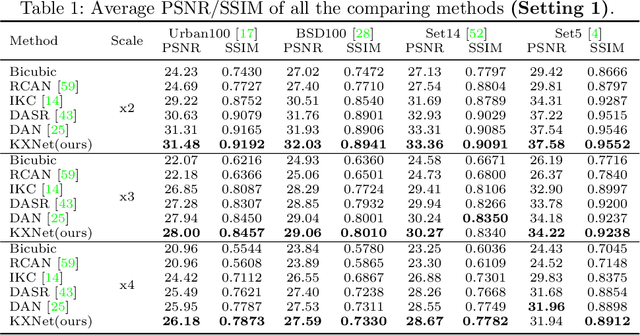
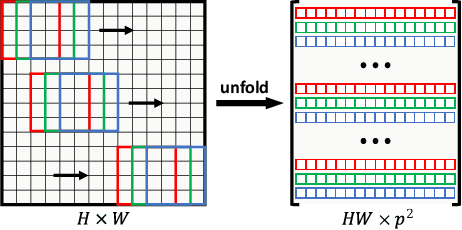
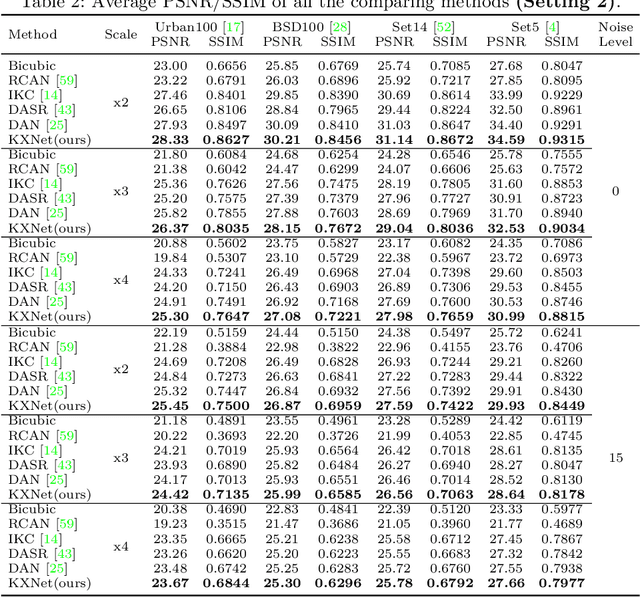
Although current deep learning-based methods have gained promising performance in the blind single image super-resolution (SISR) task, most of them mainly focus on heuristically constructing diverse network architectures and put less emphasis on the explicit embedding of the physical generation mechanism between blur kernels and high-resolution (HR) images. To alleviate this issue, we propose a model-driven deep neural network, called KXNet, for blind SISR. Specifically, to solve the classical SISR model, we propose a simple-yet-effective iterative algorithm. Then by unfolding the involved iterative steps into the corresponding network module, we naturally construct the KXNet. The main specificity of the proposed KXNet is that the entire learning process is fully and explicitly integrated with the inherent physical mechanism underlying this SISR task. Thus, the learned blur kernel has clear physical patterns and the mutually iterative process between blur kernel and HR image can soundly guide the KXNet to be evolved in the right direction. Extensive experiments on synthetic and real data finely demonstrate the superior accuracy and generality of our method beyond the current representative state-of-the-art blind SISR methods. Code is available at: https://github.com/jiahong-fu/KXNet.
Image-to-image Translation as a Unique Source of Knowledge
Dec 03, 2021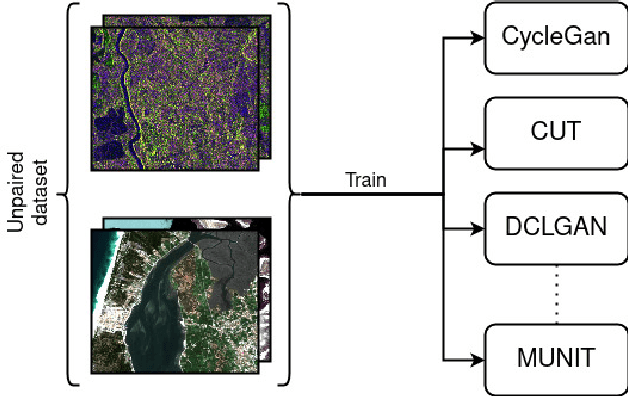
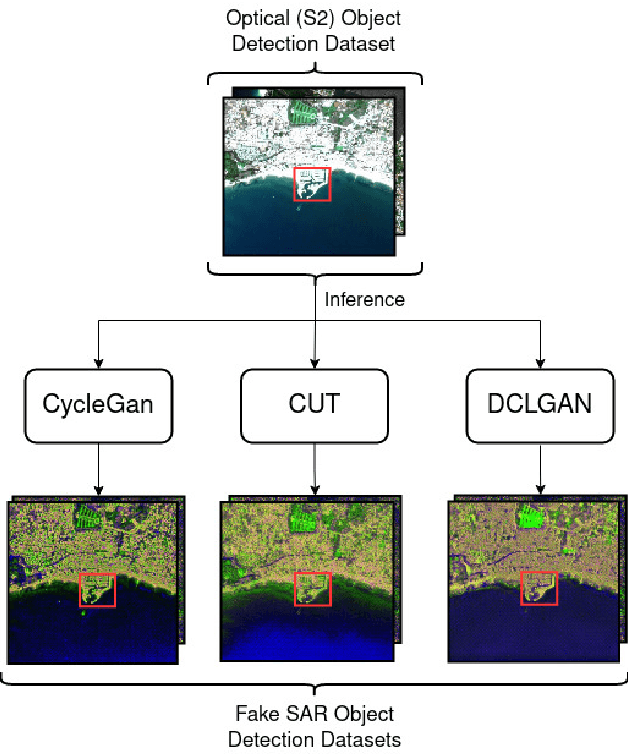
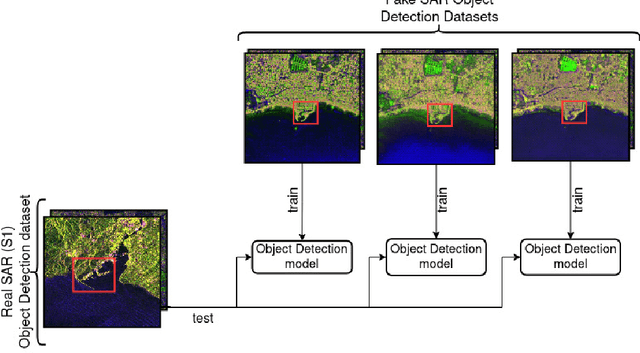
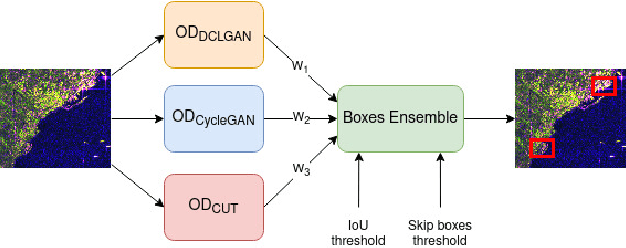
Image-to-image (I2I) translation is an established way of translating data from one domain to another but the usability of the translated images in the target domain when working with such dissimilar domains as the SAR/optical satellite imagery ones and how much of the origin domain is translated to the target domain is still not clear enough. This article address this by performing translations of labelled datasets from the optical domain to the SAR domain with different I2I algorithms from the state-of-the-art, learning from transferred features in the destination domain and evaluating later how much from the original dataset was transferred. Added to this, stacking is proposed as a way of combining the knowledge learned from the different I2I translations and evaluated against single models.
SpeechCLIP: Integrating Speech with Pre-Trained Vision and Language Model
Oct 03, 2022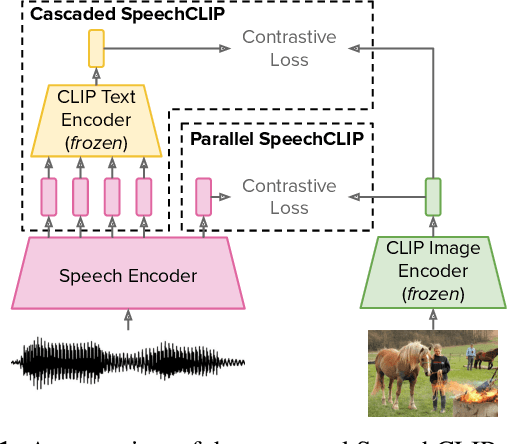

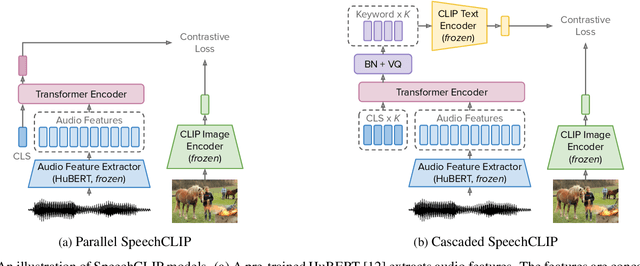
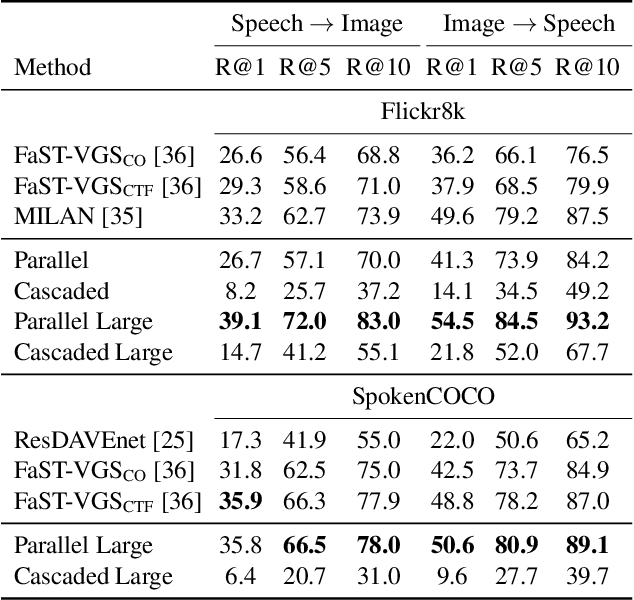
Data-driven speech processing models usually perform well with a large amount of text supervision, but collecting transcribed speech data is costly. Therefore, we propose SpeechCLIP, a novel framework bridging speech and text through images to enhance speech models without transcriptions. We leverage state-of-the-art pre-trained HuBERT and CLIP, aligning them via paired images and spoken captions with minimal fine-tuning. SpeechCLIP outperforms prior state-of-the-art on image-speech retrieval and performs zero-shot speech-text retrieval without direct supervision from transcriptions. Moreover, SpeechCLIP can directly retrieve semantically related keywords from speech.
Conversion Between CT and MRI Images Using Diffusion and Score-Matching Models
Sep 24, 2022


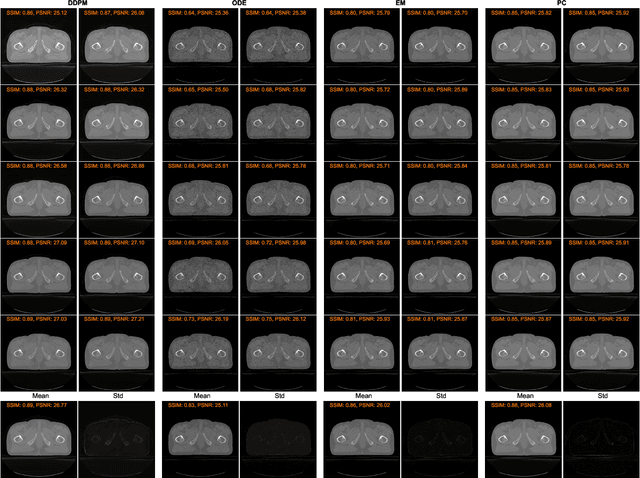
MRI and CT are most widely used medical imaging modalities. It is often necessary to acquire multi-modality images for diagnosis and treatment such as radiotherapy planning. However, multi-modality imaging is not only costly but also introduces misalignment between MRI and CT images. To address this challenge, computational conversion is a viable approach between MRI and CT images, especially from MRI to CT images. In this paper, we propose to use an emerging deep learning framework called diffusion and score-matching models in this context. Specifically, we adapt denoising diffusion probabilistic and score-matching models, use four different sampling strategies, and compare their performance metrics with that using a convolutional neural network and a generative adversarial network model. Our results show that the diffusion and score-matching models generate better synthetic CT images than the CNN and GAN models. Furthermore, we investigate the uncertainties associated with the diffusion and score-matching networks using the Monte-Carlo method, and improve the results by averaging their Monte-Carlo outputs. Our study suggests that diffusion and score-matching models are powerful to generate high quality images conditioned on an image obtained using a complementary imaging modality, analytically rigorous with clear explainability, and highly competitive with CNNs and GANs for image synthesis.