 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Mixture-of-Experts Approach for Cytotoxic Edema Assessment in Infants and Children
Oct 06, 2022
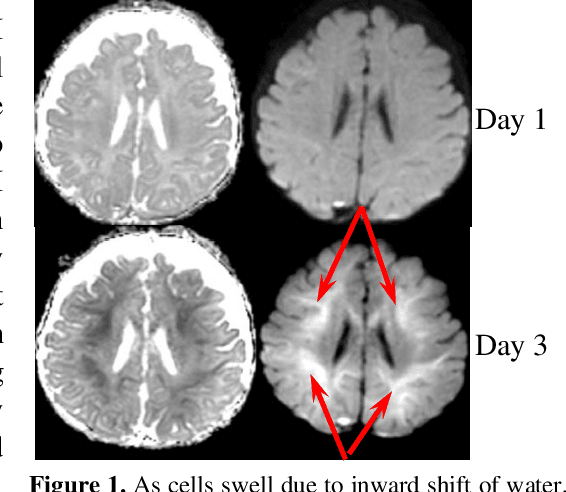
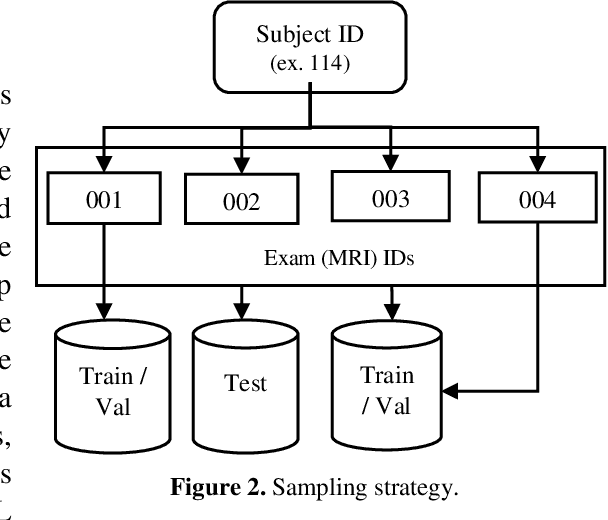
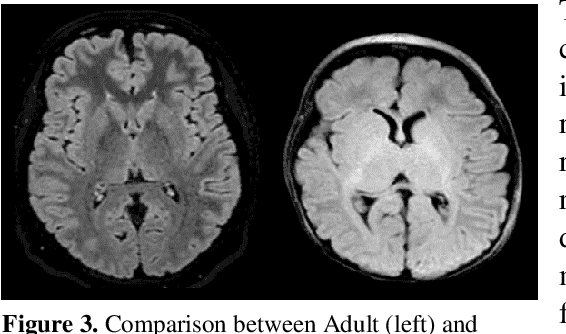
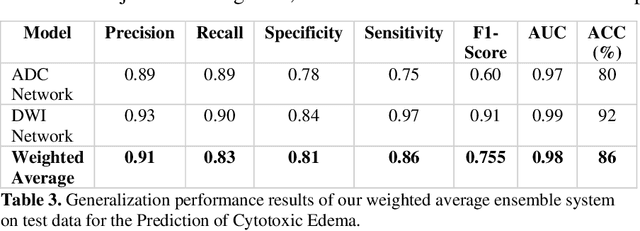
This paper presents a deep learning framework for image classification aimed at increasing predictive performance for Cytotoxic Edema (CE) diagnosis in infants and children. The proposed framework includes two 3D network architectures optimized to learn from two types of clinical MRI data , a trace Diffusion Weighted Image (DWI) and the calculated Apparent Diffusion Coefficient map (ADC). This work proposes a robust and novel solution based on volumetric analysis of 3D images (using pixels from time slices) and 3D convolutional neural network (CNN) models. While simple in architecture, the proposed framework shows significant quantitative results on the domain problem. We use a dataset curated from a Childrens Hospital Colorado (CHCO) patient registry to report a predictive performance F1 score of 0.91 at distinguishing CE patients from children with severe neurologic injury without CE. In addition, we perform analysis of our systems output to determine the association of CE with Abusive Head Trauma (AHT) , a type of traumatic brain injury (TBI) associated with abuse , and overall functional outcome and in hospital mortality of infants and young children. We used two clinical variables, AHT diagnosis and Functional Status Scale (FSS) score, to arrive at the conclusion that CE is highly correlated with overall outcome and that further study is needed to determine whether CE is a biomarker of AHT. With that, this paper introduces a simple yet powerful deep learning based solution for automated CE classification. This solution also enables an indepth analysis of progression of CE and its correlation to AHT and overall neurologic outcome, which in turn has the potential to empower experts to diagnose and mitigate AHT during early stages of a childs life.
Paraphrasing Is All You Need for Novel Object Captioning
Sep 25, 2022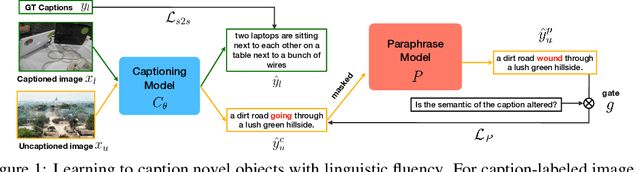
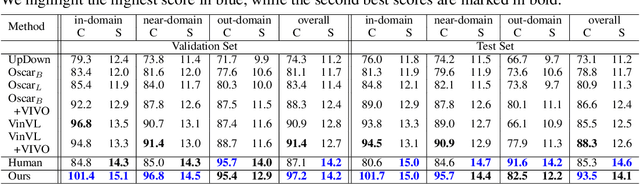
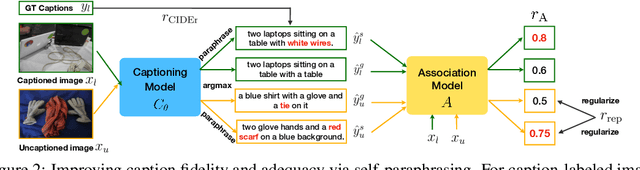
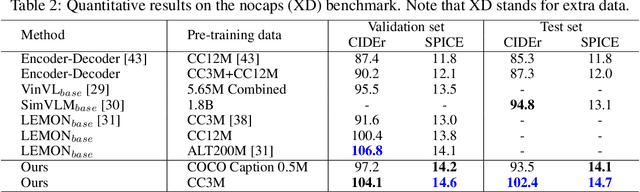
Novel object captioning (NOC) aims to describe images containing objects without observing their ground truth captions during training. Due to the absence of caption annotation, captioning models cannot be directly optimized via sequence-to-sequence training or CIDEr optimization. As a result, we present Paraphrasing-to-Captioning (P2C), a two-stage learning framework for NOC, which would heuristically optimize the output captions via paraphrasing. With P2C, the captioning model first learns paraphrasing from a language model pre-trained on text-only corpus, allowing expansion of the word bank for improving linguistic fluency. To further enforce the output caption sufficiently describing the visual content of the input image, we perform self-paraphrasing for the captioning model with fidelity and adequacy objectives introduced. Since no ground truth captions are available for novel object images during training, our P2C leverages cross-modality (image-text) association modules to ensure the above caption characteristics can be properly preserved. In the experiments, we not only show that our P2C achieves state-of-the-art performances on nocaps and COCO Caption datasets, we also verify the effectiveness and flexibility of our learning framework by replacing language and cross-modality association models for NOC. Implementation details and code are available in the supplementary materials.
OptGAN: Optimizing and Interpreting the Latent Space of the Conditional Text-to-Image GANs
Feb 25, 2022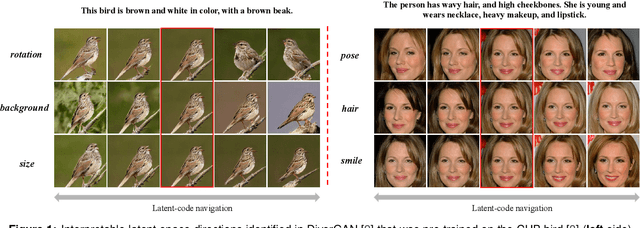

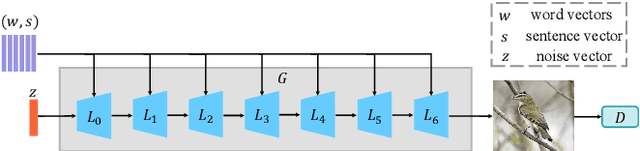
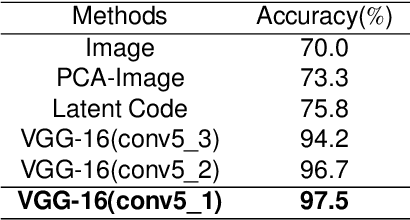
Text-to-image generation intends to automatically produce a photo-realistic image, conditioned on a textual description. It can be potentially employed in the field of art creation, data augmentation, photo-editing, etc. Although many efforts have been dedicated to this task, it remains particularly challenging to generate believable, natural scenes. To facilitate the real-world applications of text-to-image synthesis, we focus on studying the following three issues: 1) How to ensure that generated samples are believable, realistic or natural? 2) How to exploit the latent space of the generator to edit a synthesized image? 3) How to improve the explainability of a text-to-image generation framework? In this work, we constructed two novel data sets (i.e., the Good & Bad bird and face data sets) consisting of successful as well as unsuccessful generated samples, according to strict criteria. To effectively and efficiently acquire high-quality images by increasing the probability of generating Good latent codes, we use a dedicated Good/Bad classifier for generated images. It is based on a pre-trained front end and fine-tuned on the basis of the proposed Good & Bad data set. After that, we present a novel algorithm which identifies semantically-understandable directions in the latent space of a conditional text-to-image GAN architecture by performing independent component analysis on the pre-trained weight values of the generator. Furthermore, we develop a background-flattening loss (BFL), to improve the background appearance in the edited image. Subsequently, we introduce linear interpolation analysis between pairs of keywords. This is extended into a similar triangular `linguistic' interpolation in order to take a deep look into what a text-to-image synthesis model has learned within the linguistic embeddings. Our data set is available at https://zenodo.org/record/6283798#.YhkN_ujMI2w.
Self-Supervised Pyramid Representation Learning for Multi-Label Visual Analysis and Beyond
Aug 30, 2022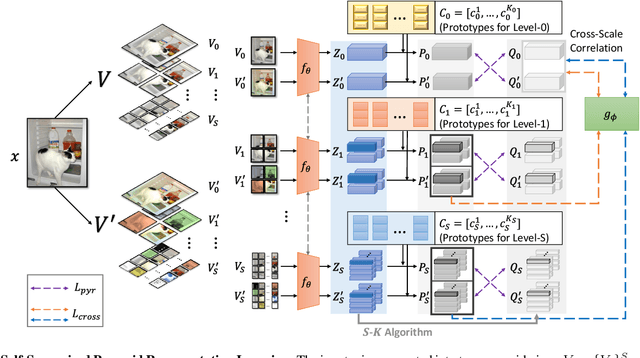
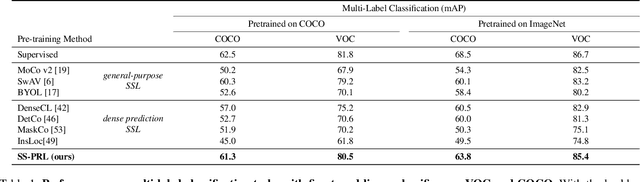
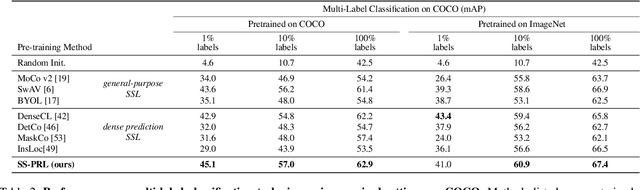
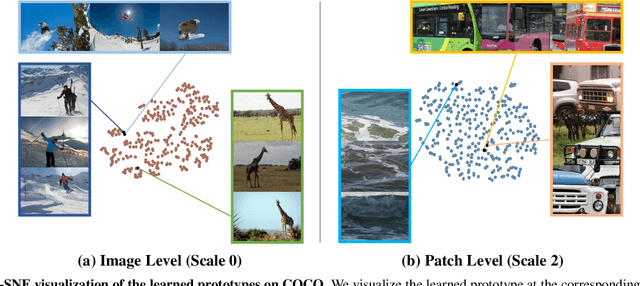
While self-supervised learning has been shown to benefit a number of vision tasks, existing techniques mainly focus on image-level manipulation, which may not generalize well to downstream tasks at patch or pixel levels. Moreover, existing SSL methods might not sufficiently describe and associate the above representations within and across image scales. In this paper, we propose a Self-Supervised Pyramid Representation Learning (SS-PRL) framework. The proposed SS-PRL is designed to derive pyramid representations at patch levels via learning proper prototypes, with additional learners to observe and relate inherent semantic information within an image. In particular, we present a cross-scale patch-level correlation learning in SS-PRL, which allows the model to aggregate and associate information learned across patch scales. We show that, with our proposed SS-PRL for model pre-training, one can easily adapt and fine-tune the models for a variety of applications including multi-label classification, object detection, and instance segmentation.
Deep Spatial and Tonal Data Optimisation for Homogeneous Diffusion Inpainting
Aug 30, 2022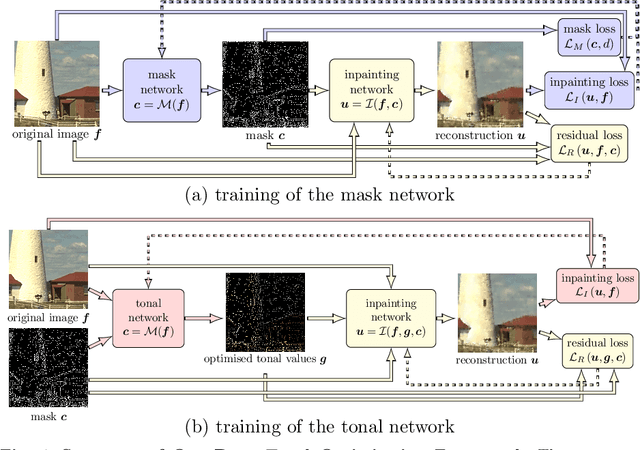
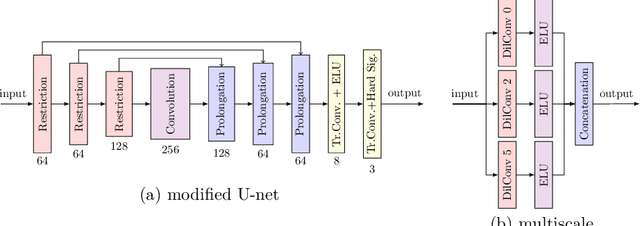
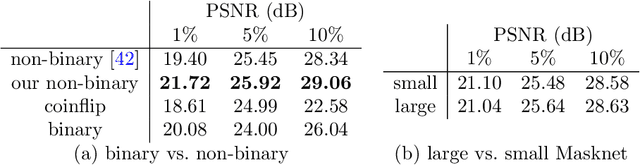
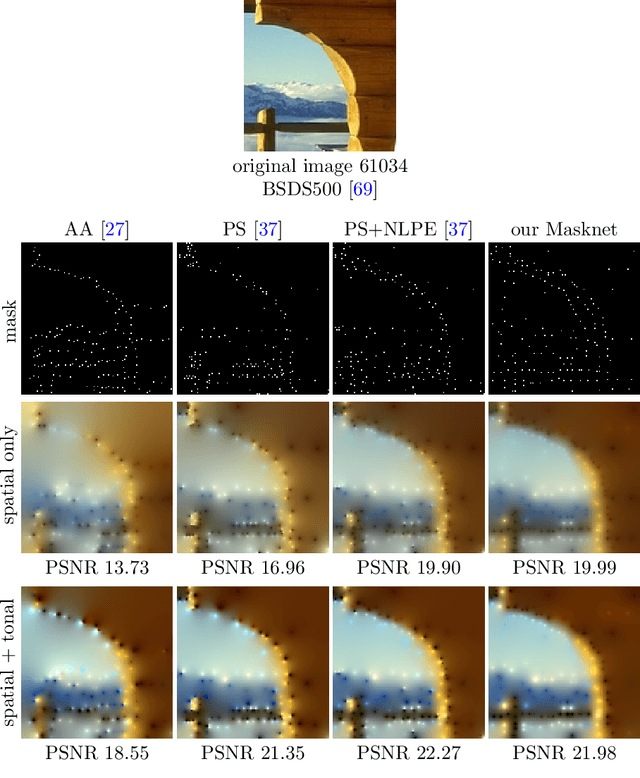
Diffusion-based inpainting can reconstruct missing image areas with high quality from sparse data, provided that their location and their values are well optimised. This is particularly useful for applications such as image compression, where the original image is known. Selecting the known data constitutes a challenging optimisation problem, that has so far been only investigated with model-based approaches. So far, these methods require a choice between either high quality or high speed since qualitatively convincing algorithms rely on many time-consuming inpaintings. We propose the first neural network architecture that allows fast optimisation of pixel positions and pixel values for homogeneous diffusion inpainting. During training, we combine two optimisation networks with a neural network-based surrogate solver for diffusion inpainting. This novel concept allows us to perform backpropagation based on inpainting results that approximate the solution of the inpainting equation. Without the need for a single inpainting during test time, our deep optimisation combines the high quality of model-based approaches with real-time performance.
A Comparative Study of Gastric Histopathology Sub-size Image Classification: from Linear Regression to Visual Transformer
May 25, 2022
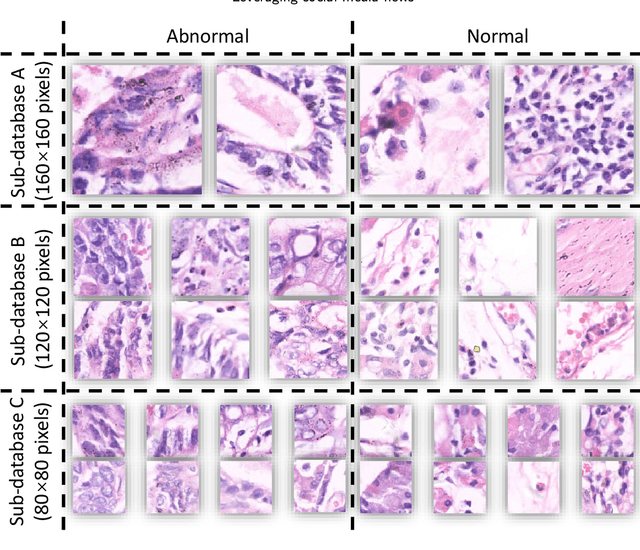
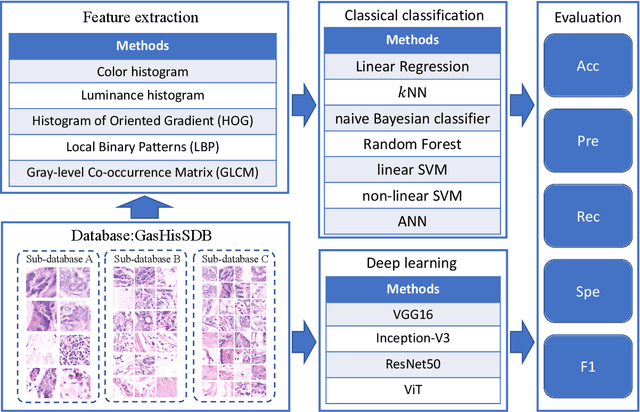

Gastric cancer is the fifth most common cancer in the world. At the same time, it is also the fourth most deadly cancer. Early detection of cancer exists as a guide for the treatment of gastric cancer. Nowadays, computer technology has advanced rapidly to assist physicians in the diagnosis of pathological pictures of gastric cancer. Ensemble learning is a way to improve the accuracy of algorithms, and finding multiple learning models with complementarity types is the basis of ensemble learning. The complementarity of sub-size pathology image classifiers when machine performance is insufficient is explored in this experimental platform. We choose seven classical machine learning classifiers and four deep learning classifiers for classification experiments on the GasHisSDB database. Among them, classical machine learning algorithms extract five different image virtual features to match multiple classifier algorithms. For deep learning, we choose three convolutional neural network classifiers. In addition, we also choose a novel Transformer-based classifier. The experimental platform, in which a large number of classical machine learning and deep learning methods are performed, demonstrates that there are differences in the performance of different classifiers on GasHisSDB. Classical machine learning models exist for classifiers that classify Abnormal categories very well, while classifiers that excel in classifying Normal categories also exist. Deep learning models also exist with multiple models that can be complementarity. Suitable classifiers are selected for ensemble learning, when machine performance is insufficient. This experimental platform demonstrates that multiple classifiers are indeed complementarity and can improve the efficiency of ensemble learning. This can better assist doctors in diagnosis, improve the detection of gastric cancer, and increase the cure rate.
A Novel Underwater Image Enhancement and Improved Underwater Biological Detection Pipeline
May 20, 2022For aquaculture resource evaluation and ecological environment monitoring, automatic detection and identification of marine organisms is critical. However, due to the low quality of underwater images and the characteristics of underwater biological, a lack of abundant features may impede traditional hand-designed feature extraction approaches or CNN-based object detection algorithms, particularly in complex underwater environment. Therefore, the goal of this paper is to perform object detection in the underwater environment. This paper proposed a novel method for capturing feature information, which adds the convolutional block attention module (CBAM) to the YOLOv5 backbone. The interference of underwater creature characteristics on object characteristics is decreased, and the output of the backbone network to object information is enhanced. In addition, the self-adaptive global histogram stretching algorithm (SAGHS) is designed to eliminate the degradation problems such as low contrast and color loss caused by underwater environmental information to better restore image quality. Extensive experiments and comprehensive evaluation on the URPC2021 benchmark dataset demonstrate the effectiveness and adaptivity of our methods. Beyond that, this paper conducts an exhaustive analysis of the role of training data on performance.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
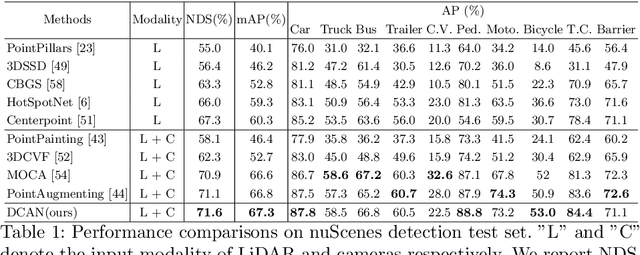
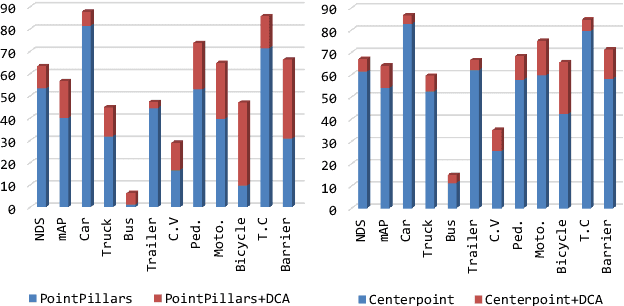
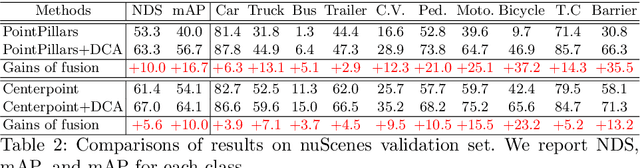
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.
Bokeh-Loss GAN: Multi-Stage Adversarial Training for Realistic Edge-Aware Bokeh
Aug 25, 2022
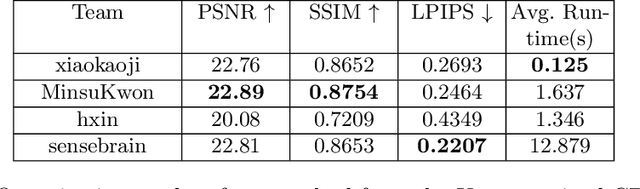
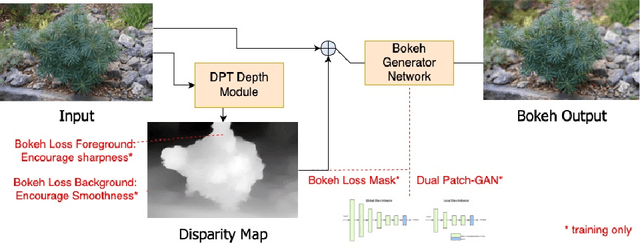
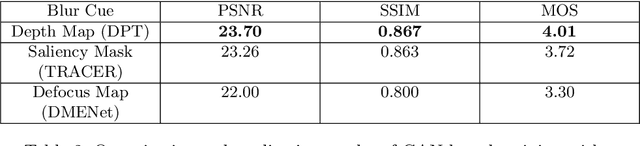
In this paper, we tackle the problem of monocular bokeh synthesis, where we attempt to render a shallow depth of field image from a single all-in-focus image. Unlike in DSLR cameras, this effect can not be captured directly in mobile cameras due to the physical constraints of the mobile aperture. We thus propose a network-based approach that is capable of rendering realistic monocular bokeh from single image inputs. To do this, we introduce three new edge-aware Bokeh Losses based on a predicted monocular depth map, that sharpens the foreground edges while blurring the background. This model is then finetuned using an adversarial loss to generate a realistic Bokeh effect. Experimental results show that our approach is capable of generating a pleasing, natural Bokeh effect with sharp edges while handling complicated scenes.
Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
Mar 21, 2022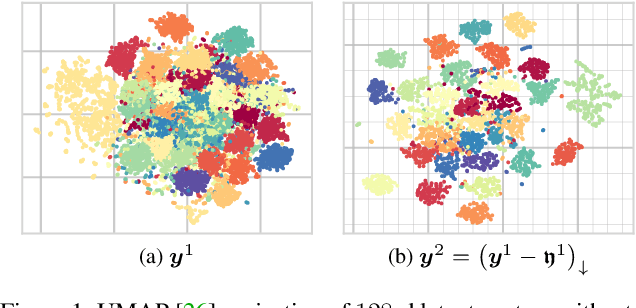
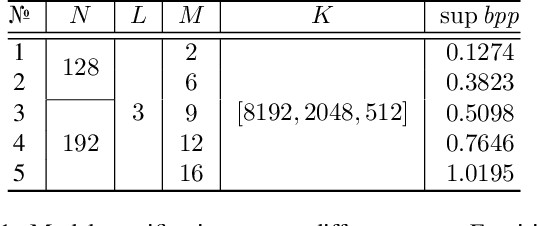
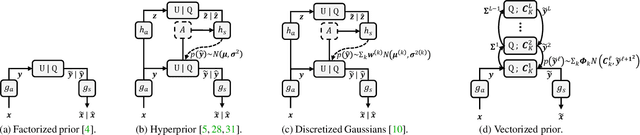
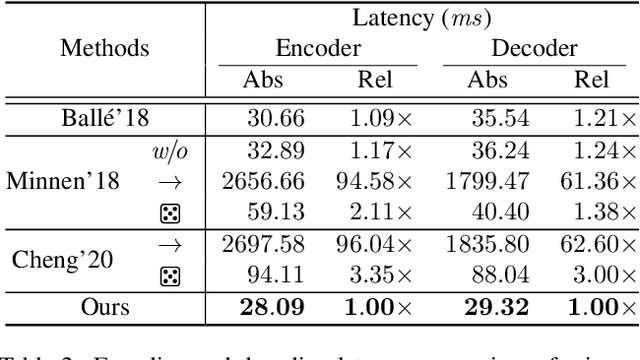
Modeling latent variables with priors and hyperpriors is an essential problem in variational image compression. Formally, trade-off between rate and distortion is handled well if priors and hyperpriors precisely describe latent variables. Current practices only adopt univariate priors and process each variable individually. However, we find inter-correlations and intra-correlations exist when observing latent variables in a vectorized perspective. These findings reveal visual redundancies to improve rate-distortion performance and parallel processing ability to speed up compression. This encourages us to propose a novel vectorized prior. Specifically, a multivariate Gaussian mixture is proposed with means and covariances to be estimated. Then, a novel probabilistic vector quantization is utilized to effectively approximate means, and remaining covariances are further induced to a unified mixture and solved by cascaded estimation without context models involved. Furthermore, codebooks involved in quantization are extended to multi-codebooks for complexity reduction, which formulates an efficient compression procedure. Extensive experiments on benchmark datasets against state-of-the-art indicate our model has better rate-distortion performance and an impressive $3.18\times$ compression speed up, giving us the ability to perform real-time, high-quality variational image compression in practice. Our source code is publicly available at \url{https://github.com/xiaosu-zhu/McQuic}.
* Accepted to CVPR 2022