 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sparse Video Representation Using Steered Mixture-of-Experts With Global Motion Compensation
Sep 13, 2022



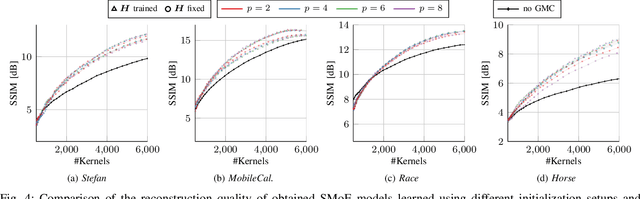
Steered-Mixtures-of Experts (SMoE) present a unified framework for sparse representation and compression of image data with arbitrary dimensionality. Recent work has shown great improvements in the performance of such models for image and light-field representation. However, for the case of videos the straight-forward application yields limited success as the SMoE framework leads to a piece-wise linear representation of the underlying imagery which is disrupted by nonlinear motion. We incorporate a global motion model into the SMoE framework which allows for higher temporal steering of the kernels. This drastically increases its capabilities to exploit correlations between adjacent frames by only adding 2 to 8 motion parameters per frame to the model but decreasing the required amount of kernels on average by 54.25%, respectively, while maintaining the same reconstruction quality yielding higher compression gains.
360FusionNeRF: Panoramic Neural Radiance Fields with Joint Guidance
Sep 28, 2022
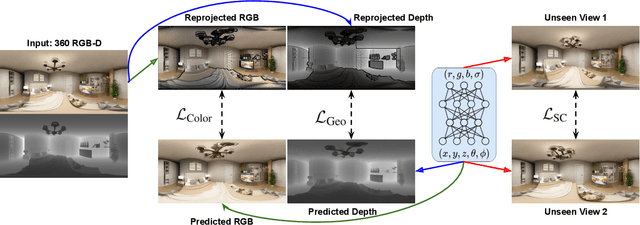

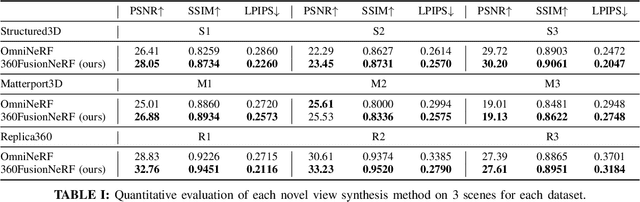
We present a method to synthesize novel views from a single $360^\circ$ panorama image based on the neural radiance field (NeRF). Prior studies in a similar setting rely on the neighborhood interpolation capability of multi-layer perceptions to complete missing regions caused by occlusion, which leads to artifacts in their predictions. We propose 360FusionNeRF, a semi-supervised learning framework where we introduce geometric supervision and semantic consistency to guide the progressive training process. Firstly, the input image is re-projected to $360^\circ$ images, and auxiliary depth maps are extracted at other camera positions. The depth supervision, in addition to the NeRF color guidance, improves the geometry of the synthesized views. Additionally, we introduce a semantic consistency loss that encourages realistic renderings of novel views. We extract these semantic features using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse 2D photographs mined from the web with natural language supervision. Experiments indicate that our proposed method can produce plausible completions of unobserved regions while preserving the features of the scene. When trained across various scenes, 360FusionNeRF consistently achieves the state-of-the-art performance when transferring to synthetic Structured3D dataset (PSNR~5%, SSIM~3% LPIPS~13%), real-world Matterport3D dataset (PSNR~3%, SSIM~3% LPIPS~9%) and Replica360 dataset (PSNR~8%, SSIM~2% LPIPS~18%).
StylePart: Image-based Shape Part Manipulation
Nov 23, 2021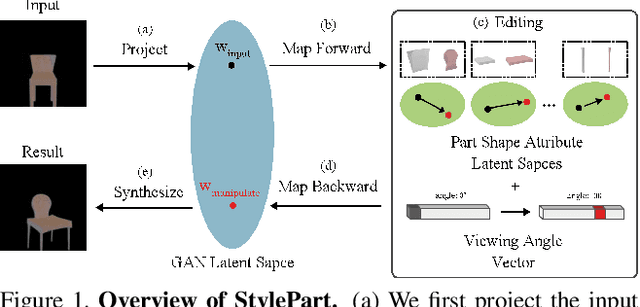
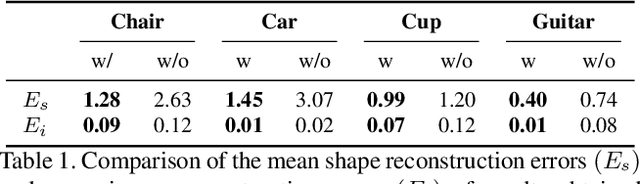
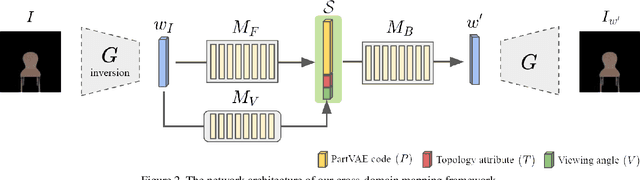

Due to a lack of image-based "part controllers", shape manipulation of man-made shape images, such as resizing the backrest of a chair or replacing a cup handle is not intuitive. To tackle this problem, we present StylePart, a framework that enables direct shape manipulation of an image by leveraging generative models of both images and 3D shapes. Our key contribution is a shape-consistent latent mapping function that connects the image generative latent space and the 3D man-made shape attribute latent space. Our method "forwardly maps" the image content to its corresponding 3D shape attributes, where the shape part can be easily manipulated. The attribute codes of the manipulated 3D shape are then "backwardly mapped" to the image latent code to obtain the final manipulated image. We demonstrate our approach through various manipulation tasks, including part replacement, part resizing, and viewpoint manipulation, and evaluate its effectiveness through extensive ablation studies.
Ultra-high-resolution unpaired stain transformation via Kernelized Instance Normalization
Aug 23, 2022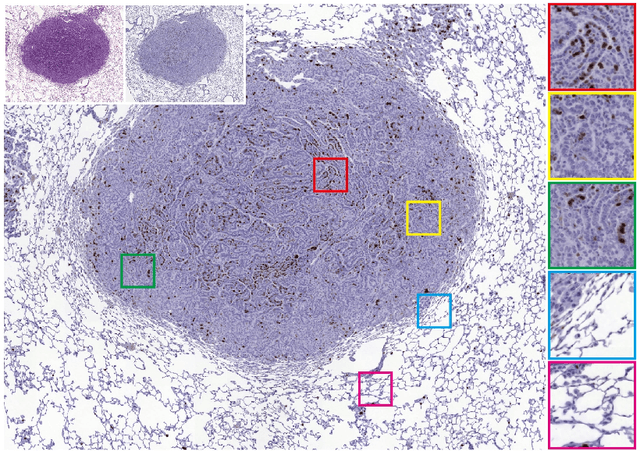
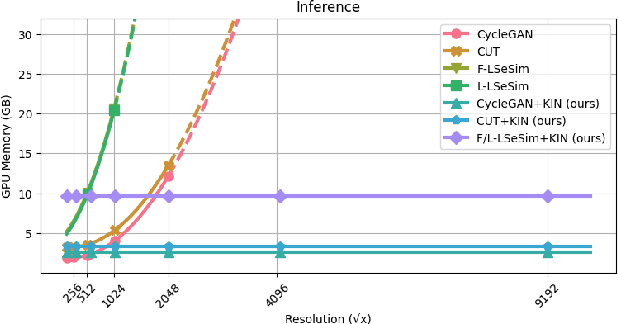
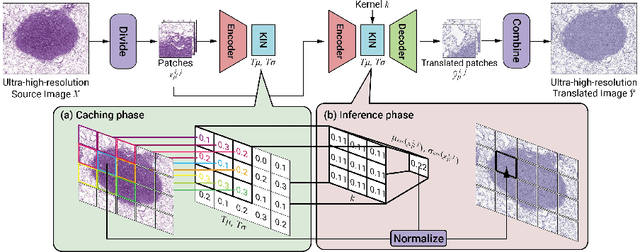
While hematoxylin and eosin (H&E) is a standard staining procedure, immunohistochemistry (IHC) staining further serves as a diagnostic and prognostic method. However, acquiring special staining results requires substantial costs. Hence, we proposed a strategy for ultra-high-resolution unpaired image-to-image translation: Kernelized Instance Normalization (KIN), which preserves local information and successfully achieves seamless stain transformation with constant GPU memory usage. Given a patch, corresponding position, and a kernel, KIN computes local statistics using convolution operation. In addition, KIN can be easily plugged into most currently developed frameworks without re-training. We demonstrate that KIN achieves state-of-the-art stain transformation by replacing instance normalization (IN) layers with KIN layers in three popular frameworks and testing on two histopathological datasets. Furthermore, we manifest the generalizability of KIN with high-resolution natural images. Finally, human evaluation and several objective metrics are used to compare the performance of different approaches. Overall, this is the first successful study for the ultra-high-resolution unpaired image-to-image translation with constant space complexity. Code is available at: https://github.com/Kaminyou/URUST
Dynamic MLP for Fine-Grained Image Classification by Leveraging Geographical and Temporal Information
Mar 07, 2022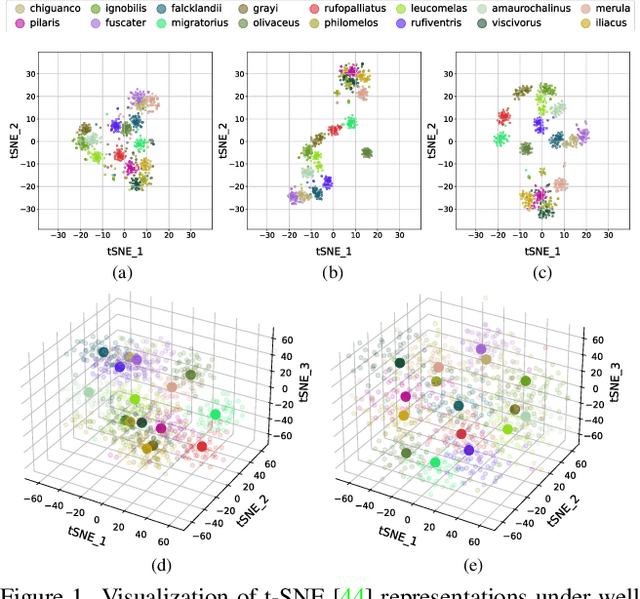
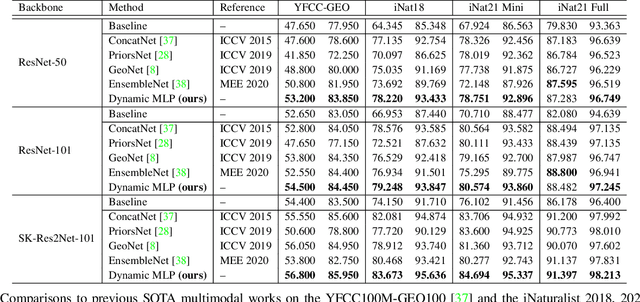
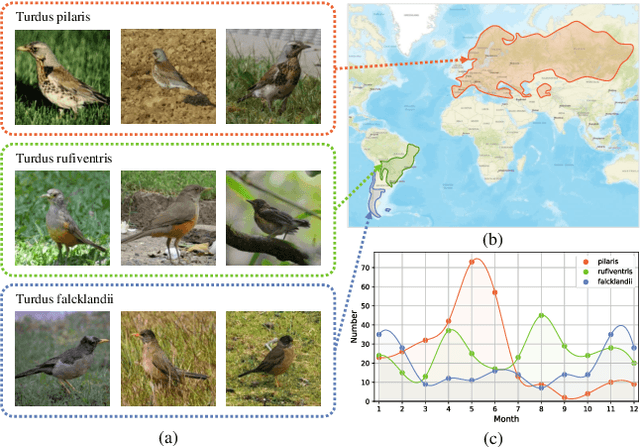
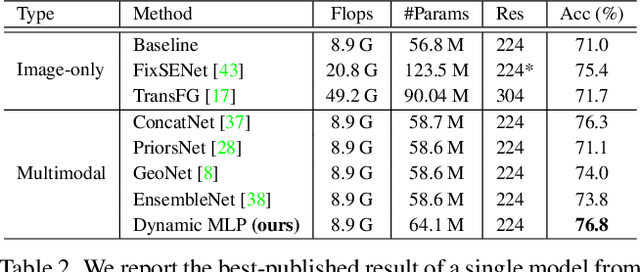
Fine-grained image classification is a challenging computer vision task where various species share similar visual appearances, resulting in misclassification if merely based on visual clues. Therefore, it is helpful to leverage additional information, e.g., the locations and dates for data shooting, which can be easily accessible but rarely exploited. In this paper, we first demonstrate that existing multimodal methods fuse multiple features only on a single dimension, which essentially has insufficient help in feature discrimination. To fully explore the potential of multimodal information, we propose a dynamic MLP on top of the image representation, which interacts with multimodal features at a higher and broader dimension. The dynamic MLP is an efficient structure parameterized by the learned embeddings of variable locations and dates. It can be regarded as an adaptive nonlinear projection for generating more discriminative image representations in visual tasks. To our best knowledge, it is the first attempt to explore the idea of dynamic networks to exploit multimodal information in fine-grained image classification tasks. Extensive experiments demonstrate the effectiveness of our method. The t-SNE algorithm visually indicates that our technique improves the recognizability of image representations that are visually similar but with different categories. Furthermore, among published works across multiple fine-grained datasets, dynamic MLP consistently achieves SOTA results https://paperswithcode.com/dataset/inaturalist and takes third place in the iNaturalist challenge at FGVC8 https://www.kaggle.com/c/inaturalist-2021/leaderboard. Code is available at https://github.com/ylingfeng/DynamicMLP.git
LWA-HAND: Lightweight Attention Hand for Interacting Hand Reconstruction
Aug 23, 2022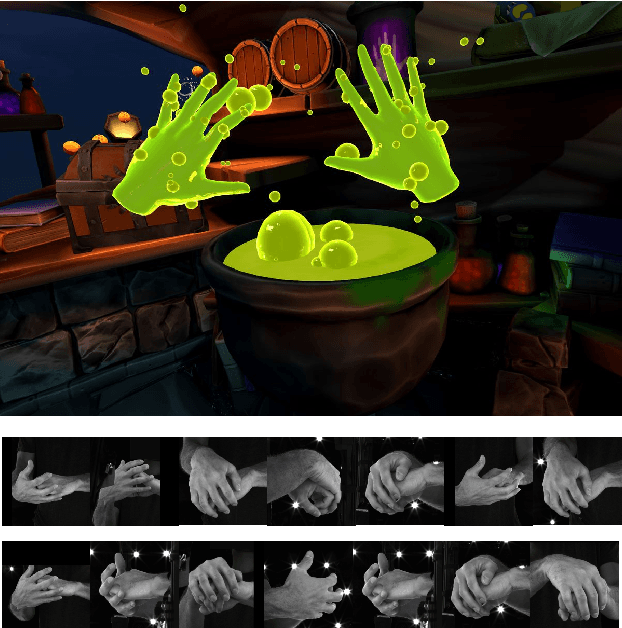

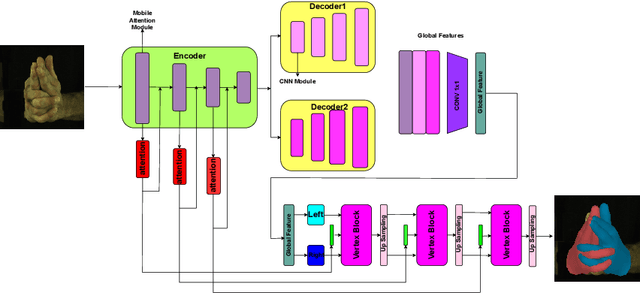

Hand reconstruction has achieved great success in real-time applications such as visual reality and augmented reality while interacting with two-hand reconstruction through efficient transformers is left unexplored. In this paper, we propose a method called lightweight attention hand (LWA-HAND) to reconstruct hands in low flops from a single RGB image. To solve the occlusion and interaction challenges in efficient attention architectures, we introduce three mobile attention modules. The first module is a lightweight feature attention module that extracts both local occlusion representation and global image patch representation in a coarse-to-fine manner. The second module is a cross image and graph bridge module which fuses image context and hand vertex. The third module is a lightweight cross-attention mechanism that uses element-wise operation for cross attention of two hands in linear complexity. The resulting model achieves comparable performance on the InterHand2.6M benchmark in comparison with the state-of-the-art models. Simultaneously, it reduces the flops to $0.47GFlops$ while the state-of-the-art models have heavy computations between $10GFlops$ and $20GFlops$.
Paraphrasing Is All You Need for Novel Object Captioning
Sep 25, 2022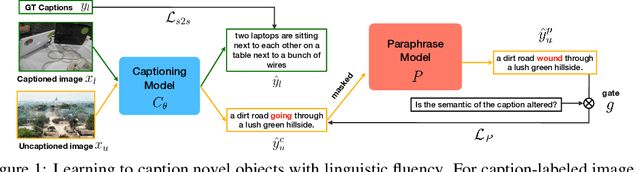
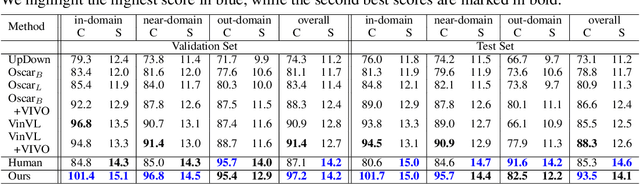
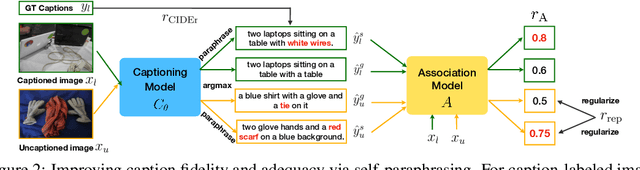
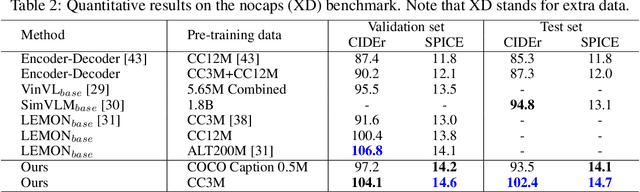
Novel object captioning (NOC) aims to describe images containing objects without observing their ground truth captions during training. Due to the absence of caption annotation, captioning models cannot be directly optimized via sequence-to-sequence training or CIDEr optimization. As a result, we present Paraphrasing-to-Captioning (P2C), a two-stage learning framework for NOC, which would heuristically optimize the output captions via paraphrasing. With P2C, the captioning model first learns paraphrasing from a language model pre-trained on text-only corpus, allowing expansion of the word bank for improving linguistic fluency. To further enforce the output caption sufficiently describing the visual content of the input image, we perform self-paraphrasing for the captioning model with fidelity and adequacy objectives introduced. Since no ground truth captions are available for novel object images during training, our P2C leverages cross-modality (image-text) association modules to ensure the above caption characteristics can be properly preserved. In the experiments, we not only show that our P2C achieves state-of-the-art performances on nocaps and COCO Caption datasets, we also verify the effectiveness and flexibility of our learning framework by replacing language and cross-modality association models for NOC. Implementation details and code are available in the supplementary materials.
EMDS-6: Environmental Microorganism Image Dataset Sixth Version for Image Denoising, Segmentation, Feature Extraction, Classification and Detection Methods Evaluation
Dec 14, 2021
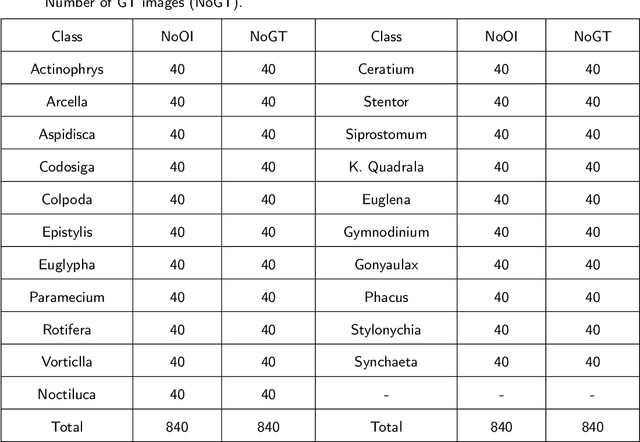
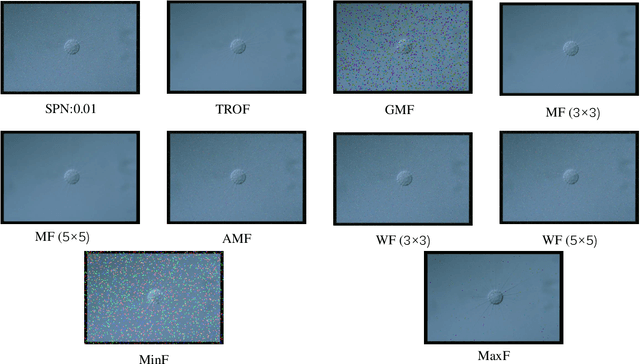
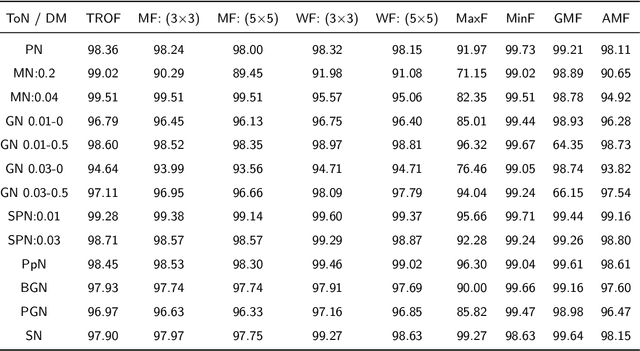
Environmental microorganisms (EMs) are ubiquitous around us and have an important impact on the survival and development of human society. However, the high standards and strict requirements for the preparation of environmental microorganism (EM) data have led to the insufficient of existing related databases, not to mention the databases with GT images. This problem seriously affects the progress of related experiments. Therefore, This study develops the Environmental Microorganism Dataset Sixth Version (EMDS-6), which contains 21 types of EMs. Each type of EM contains 40 original and 40 GT images, in total 1680 EM images. In this study, in order to test the effectiveness of EMDS-6. We choose the classic algorithms of image processing methods such as image denoising, image segmentation and target detection. The experimental result shows that EMDS-6 can be used to evaluate the performance of image denoising, image segmentation, image feature extraction, image classification, and object detection methods.
Rare Wildlife Recognition with Self-Supervised Representation Learning
Oct 29, 2022

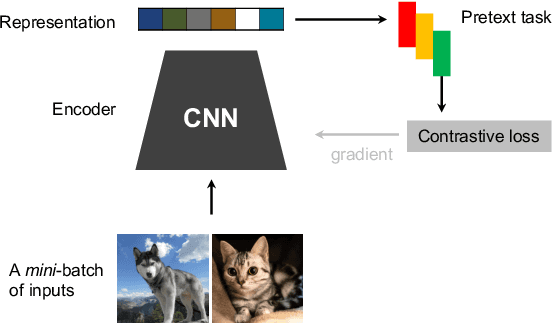
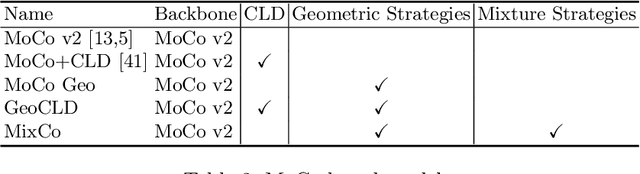
Automated animal censuses with aerial imagery are a vital ingredient towards wildlife conservation. Recent models are generally based on supervised learning and thus require vast amounts of training data. Due to their scarcity and minuscule size, annotating animals in aerial imagery is a highly tedious process. In this project, we present a methodology to reduce the amount of required training data by resorting to self-supervised pretraining. In detail, we examine a combination of recent contrastive learning methodologies like Momentum Contrast (MoCo) and Cross-Level Instance-Group Discrimination (CLD) to condition our model on the aerial images without the requirement for labels. We show that a combination of MoCo, CLD, and geometric augmentations outperforms conventional models pretrained on ImageNet by a large margin. Meanwhile, strategies for smoothing label or prediction distribution in supervised learning have been proven useful in preventing the model from overfitting. We combine the self-supervised contrastive models with image mixup strategies and find that it is useful for learning more robust visual representations. Crucially, our methods still yield favorable results even if we reduce the number of training animals to just 10%, at which point our best model scores double the recall of the baseline at similar precision. This effectively allows reducing the number of required annotations to a fraction while still being able to train high-accuracy models in such highly challenging settings.
Observations on K-image Expansion of Image-Mixing Augmentation for Classification
Oct 08, 2021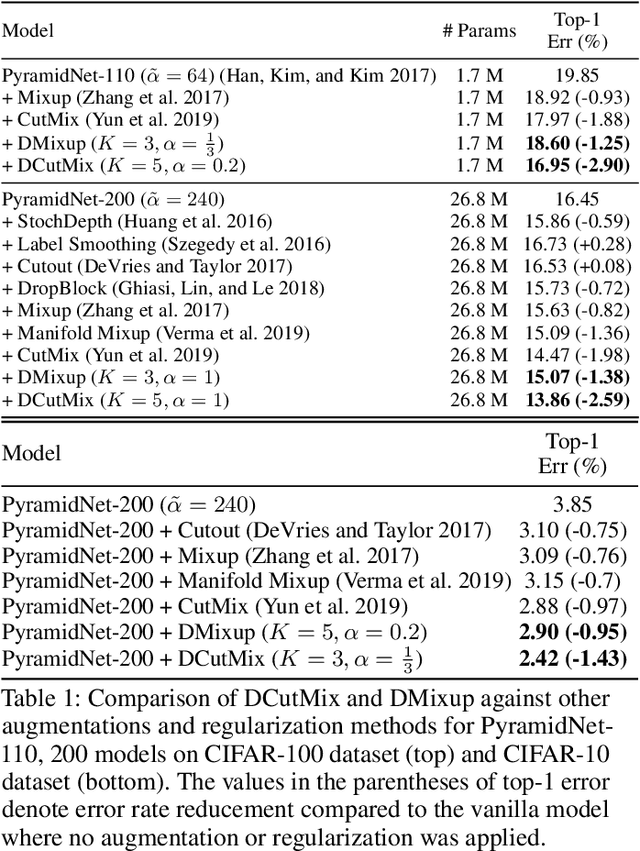
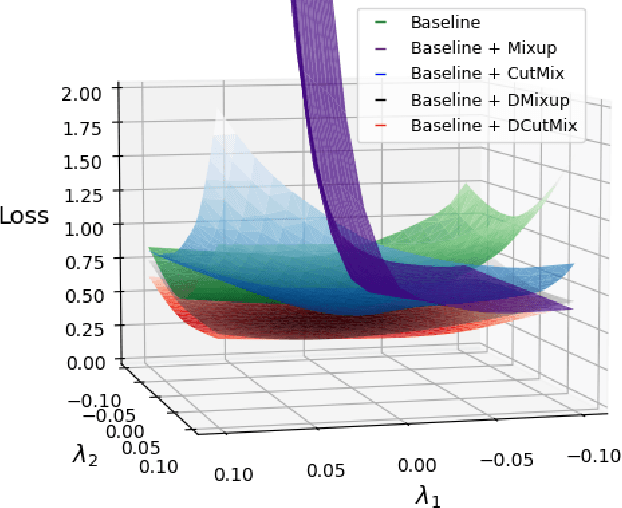

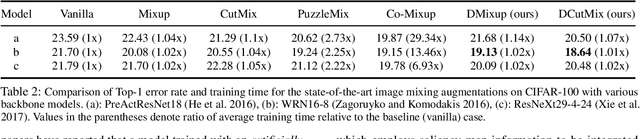
Image-mixing augmentations (e.g., Mixup or CutMix), which typically mix two images, have become de-facto training tricks for image classification. Despite their huge success on image classification, the number of images to mix has not been profoundly investigated by the previous works, only showing the naive K-image expansion leads to poor performance degradation. This paper derives a new K-image mixing augmentation based on the stick-breaking process under Dirichlet prior. We show that our method can train more robust and generalized classifiers through extensive experiments and analysis on classification accuracy, a shape of a loss landscape and adversarial robustness, than the usual two-image methods. Furthermore, we show that our probabilistic model can measure the sample-wise uncertainty and can boost the efficiency for Network Architecture Search (NAS) with 7x reduced search time.