 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Low-Light Video Enhancement with Synthetic Event Guidance
Aug 23, 2022
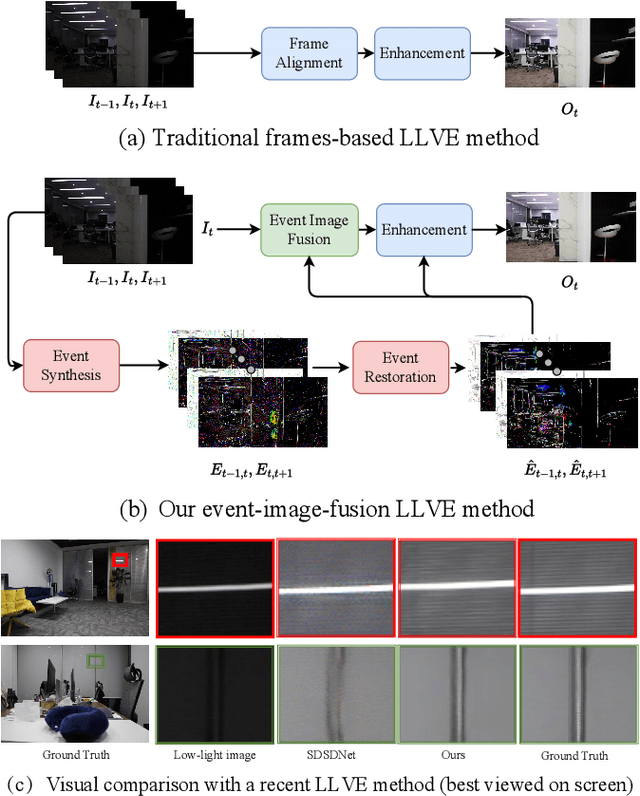
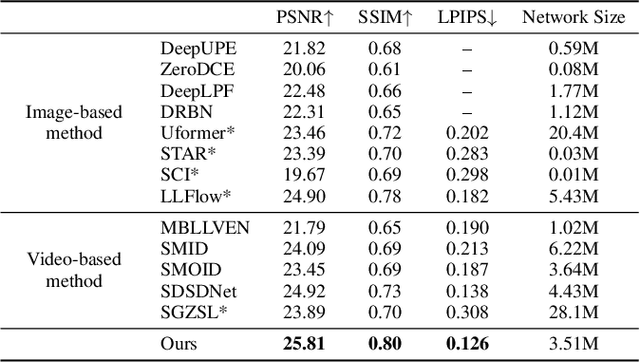

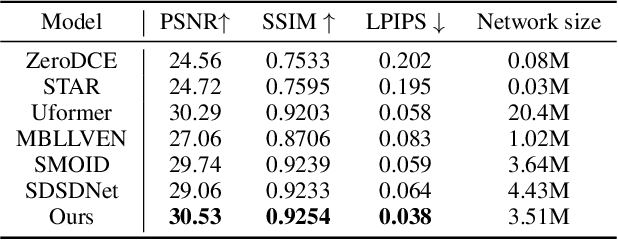
Low-light video enhancement (LLVE) is an important yet challenging task with many applications such as photographing and autonomous driving. Unlike single image low-light enhancement, most LLVE methods utilize temporal information from adjacent frames to restore the color and remove the noise of the target frame. However, these algorithms, based on the framework of multi-frame alignment and enhancement, may produce multi-frame fusion artifacts when encountering extreme low light or fast motion. In this paper, inspired by the low latency and high dynamic range of events, we use synthetic events from multiple frames to guide the enhancement and restoration of low-light videos. Our method contains three stages: 1) event synthesis and enhancement, 2) event and image fusion, and 3) low-light enhancement. In this framework, we design two novel modules (event-image fusion transform and event-guided dual branch) for the second and third stages, respectively. Extensive experiments show that our method outperforms existing low-light video or single image enhancement approaches on both synthetic and real LLVE datasets.
A scan-specific unsupervised method for parallel MRI reconstruction via implicit neural representation
Oct 19, 2022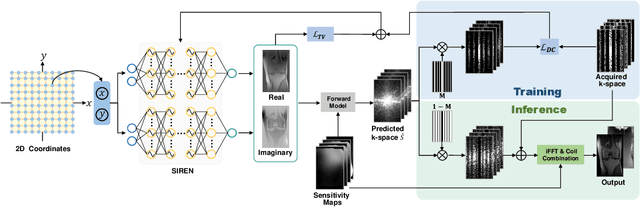
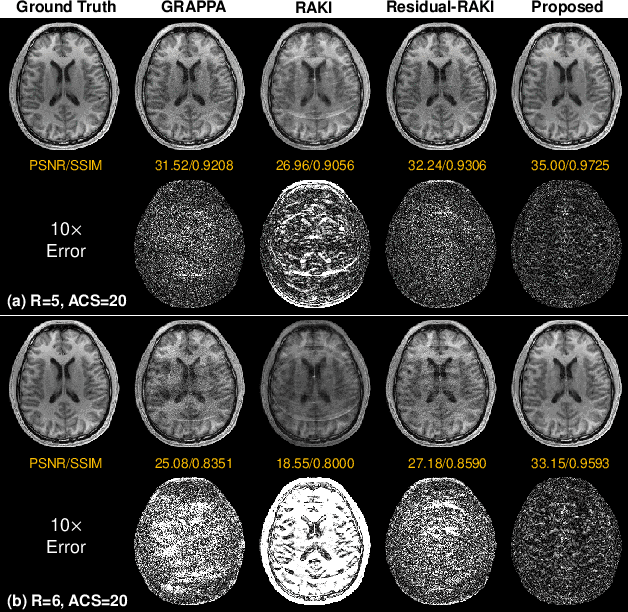

Parallel imaging is a widely-used technique to accelerate magnetic resonance imaging (MRI). However, current methods still perform poorly in reconstructing artifact-free MRI images from highly undersampled k-space data. Recently, implicit neural representation (INR) has emerged as a new deep learning paradigm for learning the internal continuity of an object. In this study, we adopted INR to parallel MRI reconstruction. The MRI image was modeled as a continuous function of spatial coordinates. This function was parameterized by a neural network and learned directly from the measured k-space itself without additional fully sampled high-quality training data. Benefitting from the powerful continuous representations provided by INR, the proposed method outperforms existing methods by suppressing the aliasing artifacts and noise, especially at higher acceleration rates and smaller sizes of the auto-calibration signals. The high-quality results and scanning specificity make the proposed method hold the potential for further accelerating the data acquisition of parallel MRI.
Artifact-Tolerant Clustering-Guided Contrastive Embedding Learning for Ophthalmic Images
Sep 02, 2022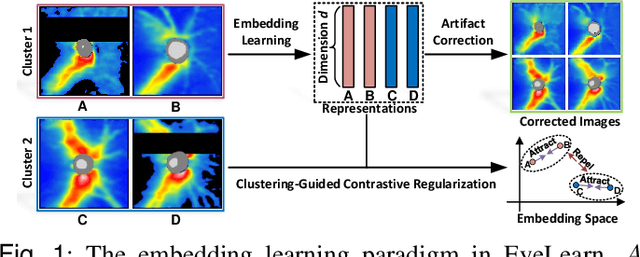
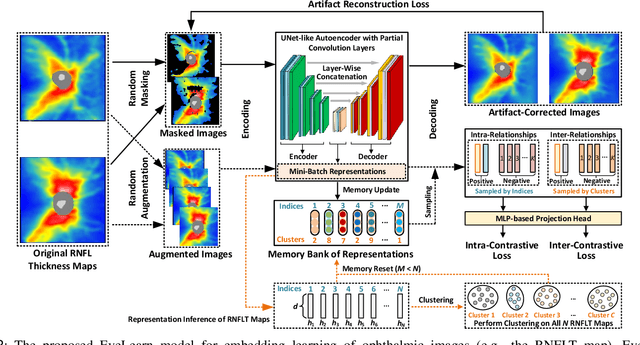
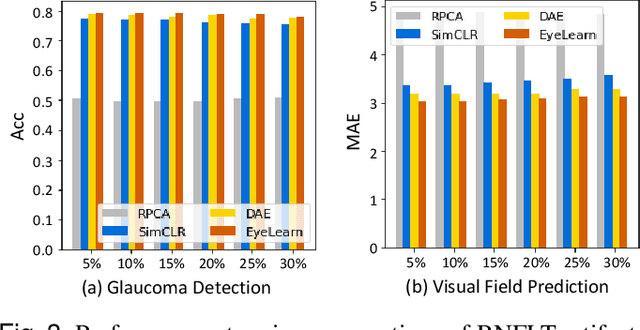
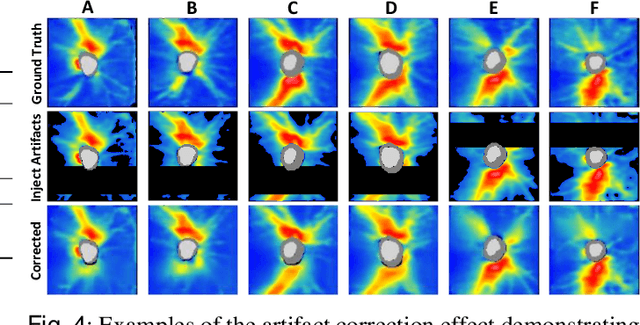
Ophthalmic images and derivatives such as the retinal nerve fiber layer (RNFL) thickness map are crucial for detecting and monitoring ophthalmic diseases (e.g., glaucoma). For computer-aided diagnosis of eye diseases, the key technique is to automatically extract meaningful features from ophthalmic images that can reveal the biomarkers (e.g., RNFL thinning patterns) linked to functional vision loss. However, representation learning from ophthalmic images that links structural retinal damage with human vision loss is non-trivial mostly due to large anatomical variations between patients. The task becomes even more challenging in the presence of image artifacts, which are common due to issues with image acquisition and automated segmentation. In this paper, we propose an artifact-tolerant unsupervised learning framework termed EyeLearn for learning representations of ophthalmic images. EyeLearn has an artifact correction module to learn representations that can best predict artifact-free ophthalmic images. In addition, EyeLearn adopts a clustering-guided contrastive learning strategy to explicitly capture the intra- and inter-image affinities. During training, images are dynamically organized in clusters to form contrastive samples in which images in the same or different clusters are encouraged to learn similar or dissimilar representations, respectively. To evaluate EyeLearn, we use the learned representations for visual field prediction and glaucoma detection using a real-world ophthalmic image dataset of glaucoma patients. Extensive experiments and comparisons with state-of-the-art methods verified the effectiveness of EyeLearn for learning optimal feature representations from ophthalmic images.
DomainATM: Domain Adaptation Toolbox for Medical Data Analysis
Sep 24, 2022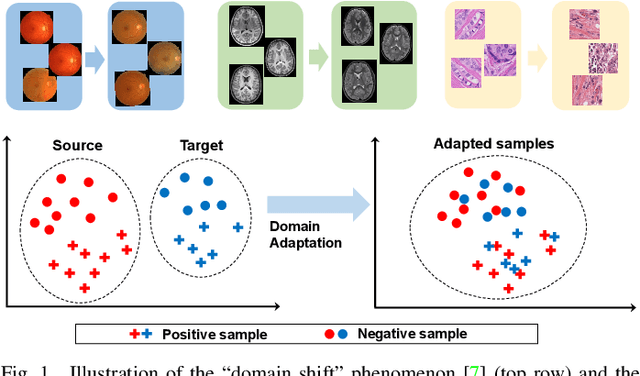
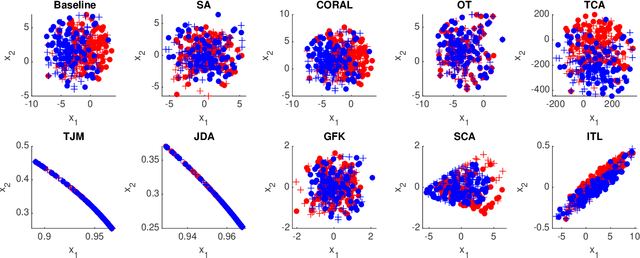
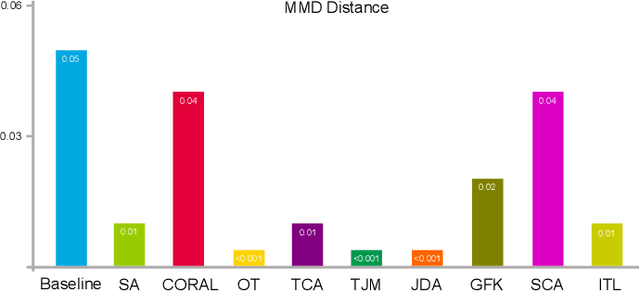
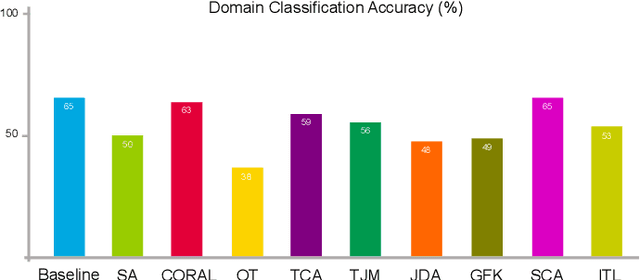
Domain adaptation (DA) is an important technique for modern machine learning-based medical data analysis, which aims at reducing distribution differences between different medical datasets. A proper domain adaptation method can significantly enhance the statistical power by pooling data acquired from multiple sites/centers. To this end, we have developed the Domain Adaptation Toolbox for Medical data analysis (DomainATM) - an open-source software package designed for fast facilitation and easy customization of domain adaptation methods for medical data analysis. The DomainATM is implemented in MATLAB with a user-friendly graphical interface, and it consists of a collection of popular data adaptation algorithms that have been extensively applied to medical image analysis and computer vision. With DomainATM, researchers are able to facilitate fast feature-level and image-level adaptation, visualization and performance evaluation of different adaptation methods for medical data analysis. More importantly, the DomainATM enables the users to develop and test their own adaptation methods through scripting, greatly enhancing its utility and extensibility. An overview characteristic and usage of DomainATM is presented and illustrated with three example experiments, demonstrating its effectiveness, simplicity, and flexibility. The software, source code, and manual are available online.
Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
Mar 21, 2022
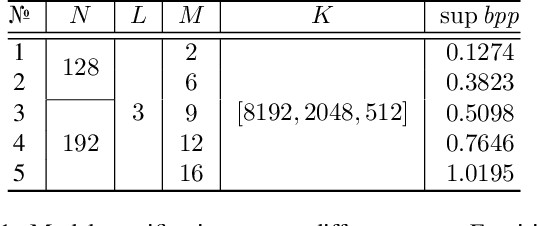
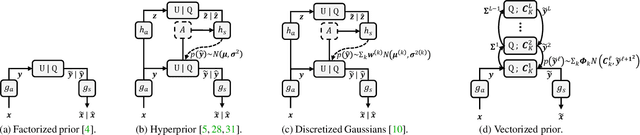
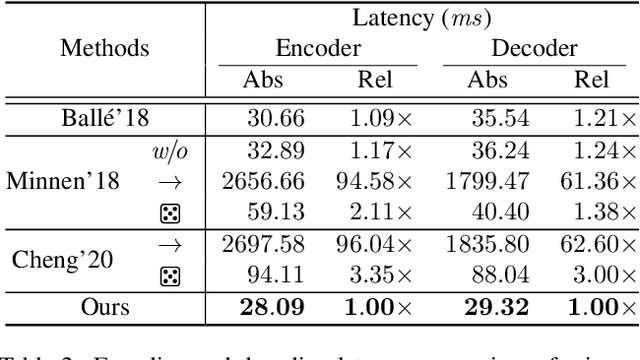
Modeling latent variables with priors and hyperpriors is an essential problem in variational image compression. Formally, trade-off between rate and distortion is handled well if priors and hyperpriors precisely describe latent variables. Current practices only adopt univariate priors and process each variable individually. However, we find inter-correlations and intra-correlations exist when observing latent variables in a vectorized perspective. These findings reveal visual redundancies to improve rate-distortion performance and parallel processing ability to speed up compression. This encourages us to propose a novel vectorized prior. Specifically, a multivariate Gaussian mixture is proposed with means and covariances to be estimated. Then, a novel probabilistic vector quantization is utilized to effectively approximate means, and remaining covariances are further induced to a unified mixture and solved by cascaded estimation without context models involved. Furthermore, codebooks involved in quantization are extended to multi-codebooks for complexity reduction, which formulates an efficient compression procedure. Extensive experiments on benchmark datasets against state-of-the-art indicate our model has better rate-distortion performance and an impressive $3.18\times$ compression speed up, giving us the ability to perform real-time, high-quality variational image compression in practice. Our source code is publicly available at \url{https://github.com/xiaosu-zhu/McQuic}.
* Accepted to CVPR 2022
Thinking Two Moves Ahead: Anticipating Other Users Improves Backdoor Attacks in Federated Learning
Oct 17, 2022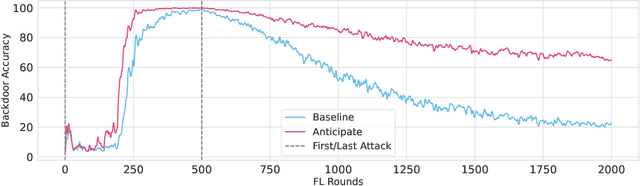
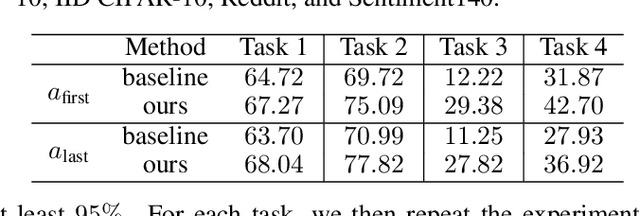
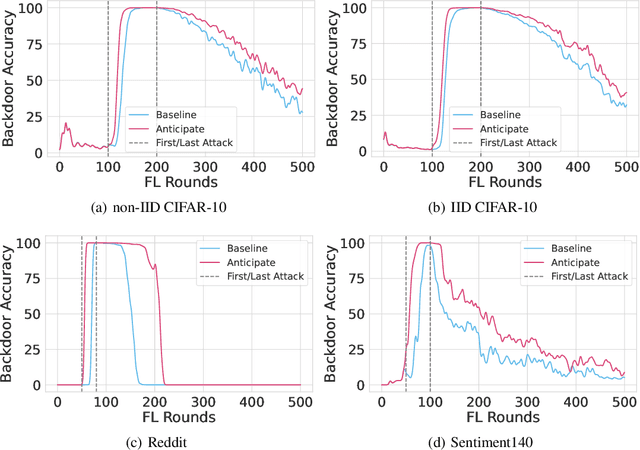
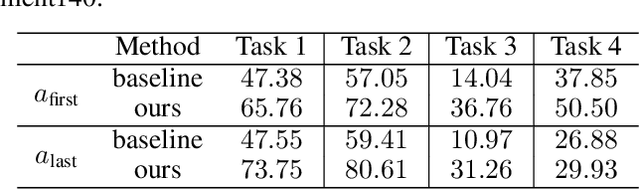
Federated learning is particularly susceptible to model poisoning and backdoor attacks because individual users have direct control over the training data and model updates. At the same time, the attack power of an individual user is limited because their updates are quickly drowned out by those of many other users. Existing attacks do not account for future behaviors of other users, and thus require many sequential updates and their effects are quickly erased. We propose an attack that anticipates and accounts for the entire federated learning pipeline, including behaviors of other clients, and ensures that backdoors are effective quickly and persist even after multiple rounds of community updates. We show that this new attack is effective in realistic scenarios where the attacker only contributes to a small fraction of randomly sampled rounds and demonstrate this attack on image classification, next-word prediction, and sentiment analysis.
Social Biases in Automatic Evaluation Metrics for NLG
Oct 17, 2022
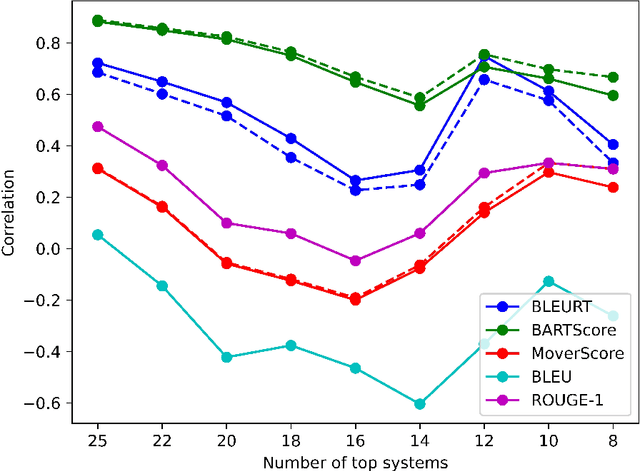

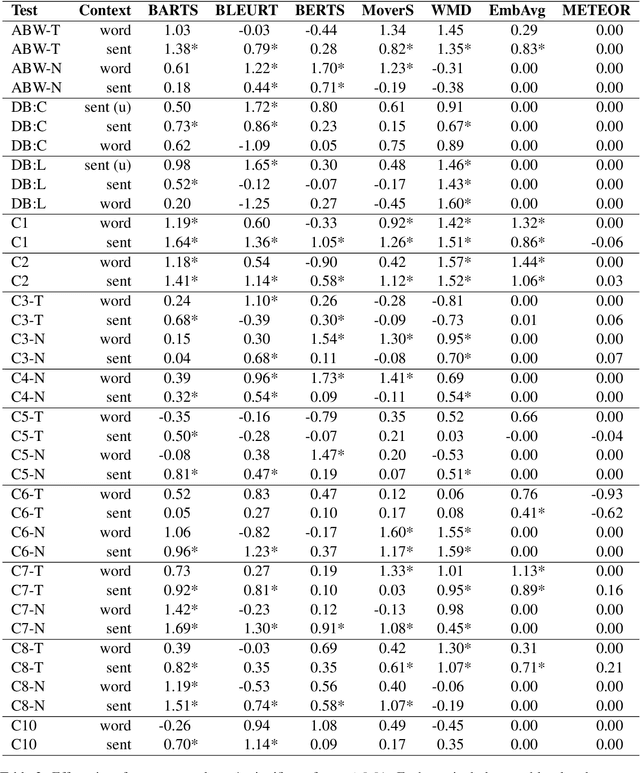
Many studies have revealed that word embeddings, language models, and models for specific downstream tasks in NLP are prone to social biases, especially gender bias. Recently these techniques have been gradually applied to automatic evaluation metrics for text generation. In the paper, we propose an evaluation method based on Word Embeddings Association Test (WEAT) and Sentence Embeddings Association Test (SEAT) to quantify social biases in evaluation metrics and discover that social biases are also widely present in some model-based automatic evaluation metrics. Moreover, we construct gender-swapped meta-evaluation datasets to explore the potential impact of gender bias in image caption and text summarization tasks. Results show that given gender-neutral references in the evaluation, model-based evaluation metrics may show a preference for the male hypothesis, and the performance of them, i.e. the correlation between evaluation metrics and human judgments, usually has more significant variation after gender swapping.
Text and Image Guided 3D Avatar Generation and Manipulation
Feb 12, 2022
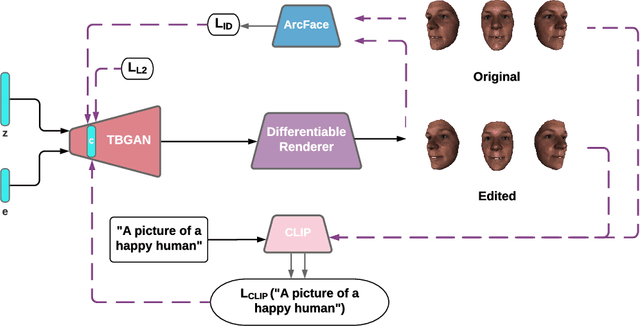
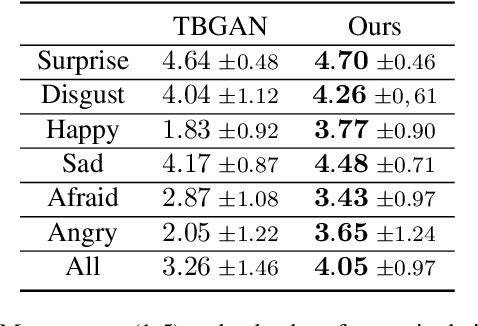
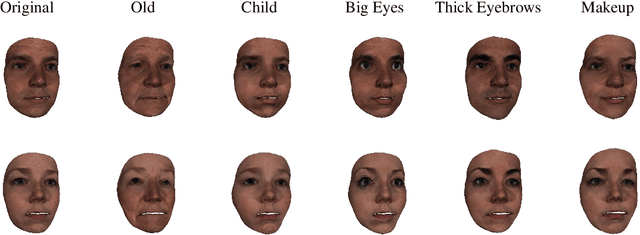
The manipulation of latent space has recently become an interesting topic in the field of generative models. Recent research shows that latent directions can be used to manipulate images towards certain attributes. However, controlling the generation process of 3D generative models remains a challenge. In this work, we propose a novel 3D manipulation method that can manipulate both the shape and texture of the model using text or image-based prompts such as 'a young face' or 'a surprised face'. We leverage the power of Contrastive Language-Image Pre-training (CLIP) model and a pre-trained 3D GAN model designed to generate face avatars, and create a fully differentiable rendering pipeline to manipulate meshes. More specifically, our method takes an input latent code and modifies it such that the target attribute specified by a text or image prompt is present or enhanced, while leaving other attributes largely unaffected. Our method requires only 5 minutes per manipulation, and we demonstrate the effectiveness of our approach with extensive results and comparisons.
Ultra-high-resolution unpaired stain transformation via Kernelized Instance Normalization
Aug 23, 2022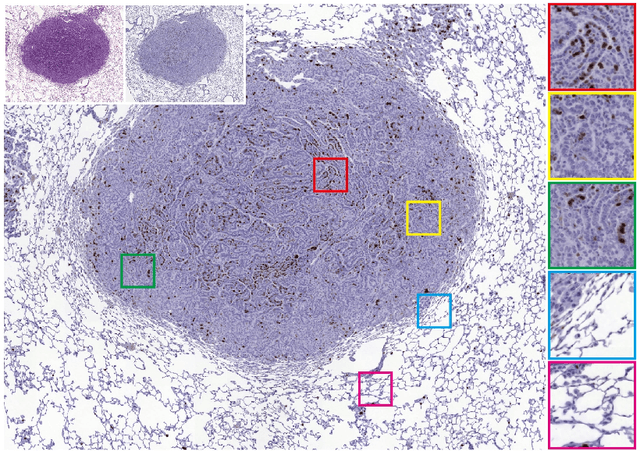
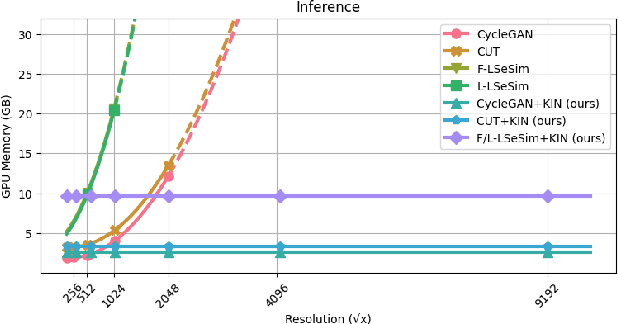
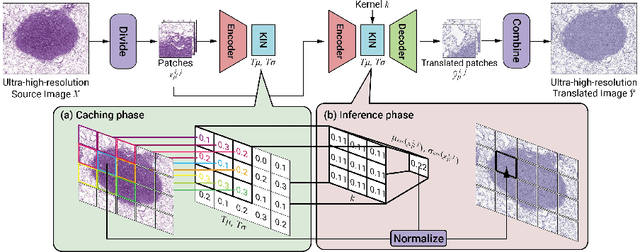
While hematoxylin and eosin (H&E) is a standard staining procedure, immunohistochemistry (IHC) staining further serves as a diagnostic and prognostic method. However, acquiring special staining results requires substantial costs. Hence, we proposed a strategy for ultra-high-resolution unpaired image-to-image translation: Kernelized Instance Normalization (KIN), which preserves local information and successfully achieves seamless stain transformation with constant GPU memory usage. Given a patch, corresponding position, and a kernel, KIN computes local statistics using convolution operation. In addition, KIN can be easily plugged into most currently developed frameworks without re-training. We demonstrate that KIN achieves state-of-the-art stain transformation by replacing instance normalization (IN) layers with KIN layers in three popular frameworks and testing on two histopathological datasets. Furthermore, we manifest the generalizability of KIN with high-resolution natural images. Finally, human evaluation and several objective metrics are used to compare the performance of different approaches. Overall, this is the first successful study for the ultra-high-resolution unpaired image-to-image translation with constant space complexity. Code is available at: https://github.com/Kaminyou/URUST
A Smoothing and Thresholding Image Segmentation Framework with Weighted Anisotropic-Isotropic Total Variation
Mar 20, 2022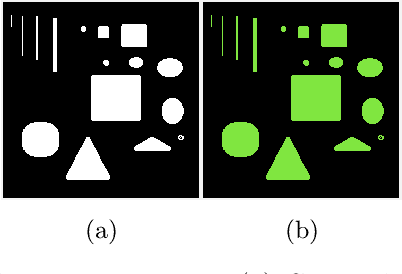
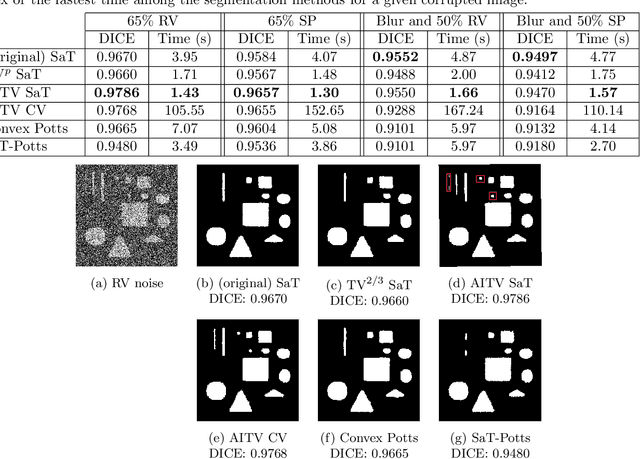

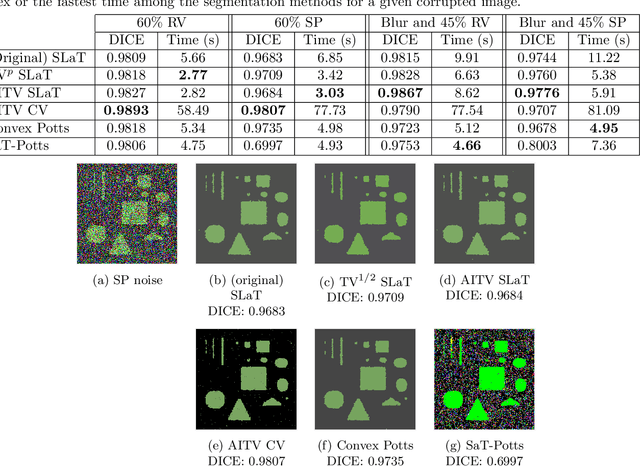
In this paper, we propose a multi-stage image segmentation framework that incorporates a weighted difference of anisotropic and isotropic total variation (AITV). The segmentation framework generally consists of two stages: smoothing and thresholding, thus referred to as SaT. In the first stage, a smoothed image is obtained by an AITV-regularized Mumford-Shah (MS) model, which can be solved efficiently by the alternating direction method of multipliers (ADMM) with a closed-form solution of a proximal operator of the $\ell_1 -\alpha \ell_2$ regularizer. Convergence of the ADMM algorithm is analyzed. In the second stage, we threshold the smoothed image by $k$-means clustering to obtain the final segmentation result. Numerical experiments demonstrate that the proposed segmentation framework is versatile for both grayscale and color images, efficient in producing high-quality segmentation results within a few seconds, and robust to input images that are corrupted with noise, blur, or both. We compare the AITV method with its original convex and nonconvex TV$^p (0<p<1)$ counterparts, showcasing the qualitative and quantitative advantages of our proposed method.