 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OptGAN: Optimizing and Interpreting the Latent Space of the Conditional Text-to-Image GANs
Feb 25, 2022
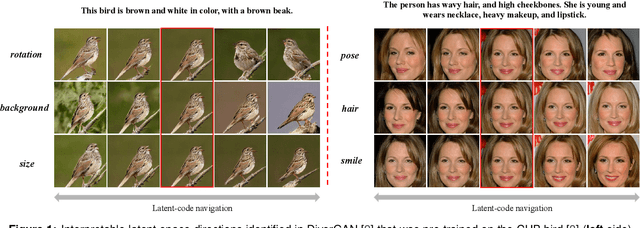

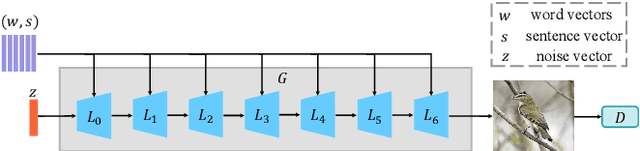
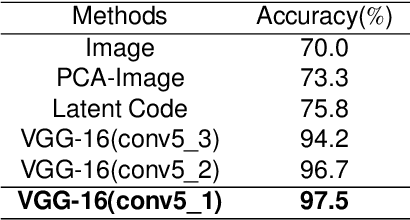
Text-to-image generation intends to automatically produce a photo-realistic image, conditioned on a textual description. It can be potentially employed in the field of art creation, data augmentation, photo-editing, etc. Although many efforts have been dedicated to this task, it remains particularly challenging to generate believable, natural scenes. To facilitate the real-world applications of text-to-image synthesis, we focus on studying the following three issues: 1) How to ensure that generated samples are believable, realistic or natural? 2) How to exploit the latent space of the generator to edit a synthesized image? 3) How to improve the explainability of a text-to-image generation framework? In this work, we constructed two novel data sets (i.e., the Good & Bad bird and face data sets) consisting of successful as well as unsuccessful generated samples, according to strict criteria. To effectively and efficiently acquire high-quality images by increasing the probability of generating Good latent codes, we use a dedicated Good/Bad classifier for generated images. It is based on a pre-trained front end and fine-tuned on the basis of the proposed Good & Bad data set. After that, we present a novel algorithm which identifies semantically-understandable directions in the latent space of a conditional text-to-image GAN architecture by performing independent component analysis on the pre-trained weight values of the generator. Furthermore, we develop a background-flattening loss (BFL), to improve the background appearance in the edited image. Subsequently, we introduce linear interpolation analysis between pairs of keywords. This is extended into a similar triangular `linguistic' interpolation in order to take a deep look into what a text-to-image synthesis model has learned within the linguistic embeddings. Our data set is available at https://zenodo.org/record/6283798#.YhkN_ujMI2w.
TartanCalib: Iterative Wide-Angle Lens Calibration using Adaptive SubPixel Refinement of AprilTags
Oct 05, 2022
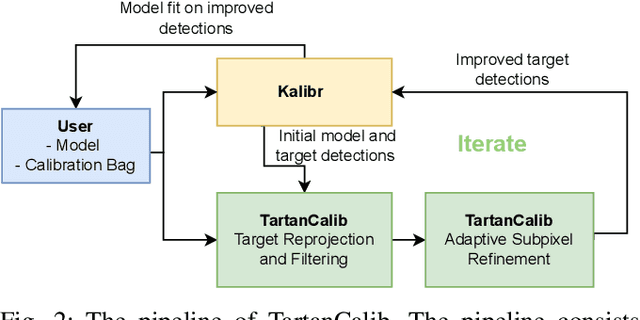

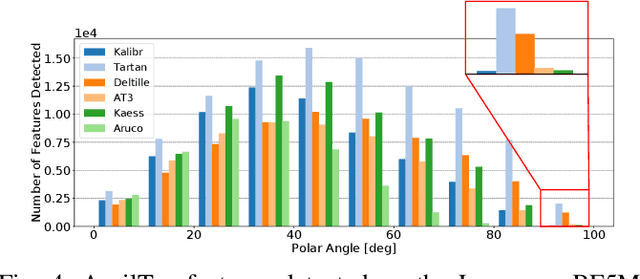
Wide-angle cameras are uniquely positioned for mobile robots, by virtue of the rich information they provide in a small, light, and cost-effective form factor. An accurate calibration of the intrinsics and extrinsics is a critical pre-requisite for using the edge of a wide-angle lens for depth perception and odometry. Calibrating wide-angle lenses with current state-of-the-art techniques yields poor results due to extreme distortion at the edge, as most algorithms assume a lens with low to medium distortion closer to a pinhole projection. In this work we present our methodology for accurate wide-angle calibration. Our pipeline generates an intermediate model, and leverages it to iteratively improve feature detection and eventually the camera parameters. We test three key methods to utilize intermediate camera models: (1) undistorting the image into virtual pinhole cameras, (2) reprojecting the target into the image frame, and (3) adaptive subpixel refinement. Combining adaptive subpixel refinement and feature reprojection significantly improves reprojection errors by up to 26.59 %, helps us detect up to 42.01 % more features, and improves performance in the downstream task of dense depth mapping. Finally, TartanCalib is open-source and implemented into an easy-to-use calibration toolbox. We also provide a translation layer with other state-of-the-art works, which allows for regressing generic models with thousands of parameters or using a more robust solver. To this end, TartanCalib is the tool of choice for wide-angle calibration. Project website and code: http://tartancalib.com.
MIPI 2022 Challenge on RGBW Sensor Fusion: Dataset and Report
Sep 27, 2022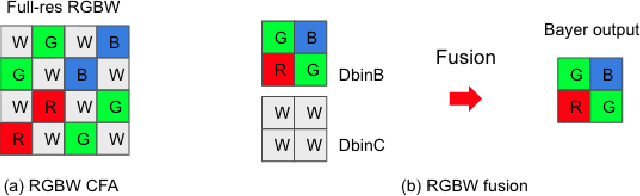
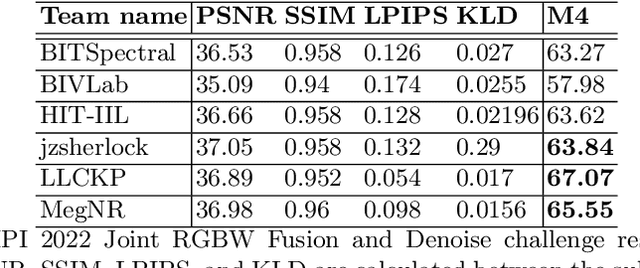


Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge, including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Fusion and Denoise, one of the five tracks, working on the fusion of binning-mode RGBW to Bayer, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 24dB and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics, including PSNR, SSIM}, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
Affection: Learning Affective Explanations for Real-World Visual Data
Oct 04, 2022
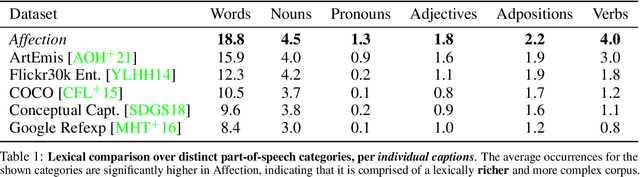
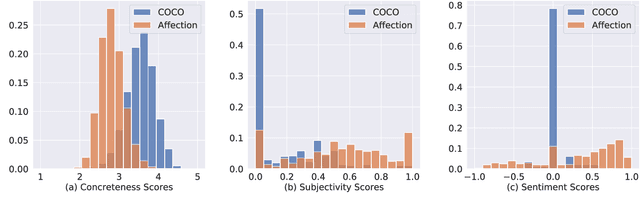
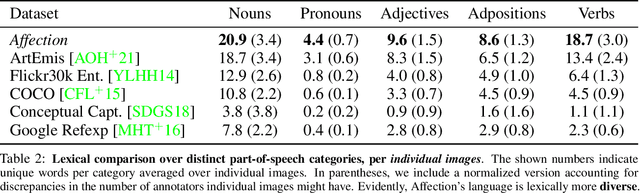
In this work, we explore the emotional reactions that real-world images tend to induce by using natural language as the medium to express the rationale behind an affective response to a given visual stimulus. To embark on this journey, we introduce and share with the research community a large-scale dataset that contains emotional reactions and free-form textual explanations for 85,007 publicly available images, analyzed by 6,283 annotators who were asked to indicate and explain how and why they felt in a particular way when observing a specific image, producing a total of 526,749 responses. Even though emotional reactions are subjective and sensitive to context (personal mood, social status, past experiences) - we show that there is significant common ground to capture potentially plausible emotional responses with a large support in the subject population. In light of this crucial observation, we ask the following questions: i) Can we develop multi-modal neural networks that provide reasonable affective responses to real-world visual data, explained with language? ii) Can we steer such methods towards producing explanations with varying degrees of pragmatic language or justifying different emotional reactions while adapting to the underlying visual stimulus? Finally, iii) How can we evaluate the performance of such methods for this novel task? With this work, we take the first steps in addressing all of these questions, thus paving the way for richer, more human-centric, and emotionally-aware image analysis systems. Our introduced dataset and all developed methods are available on https://affective-explanations.org
Vec2Face-v2: Unveil Human Faces from their Blackbox Features via Attention-based Network in Face Recognition
Sep 11, 2022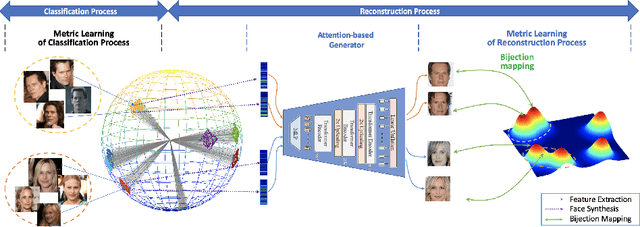

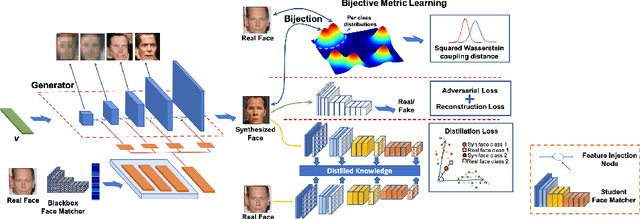
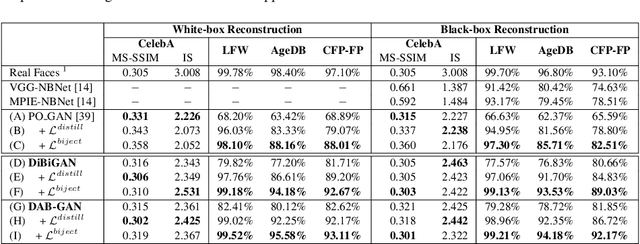
In this work, we investigate the problem of face reconstruction given a facial feature representation extracted from a blackbox face recognition engine. Indeed, it is very challenging problem in practice due to the limitations of abstracted information from the engine. We therefore introduce a new method named Attention-based Bijective Generative Adversarial Networks in a Distillation framework (DAB-GAN) to synthesize faces of a subject given his/her extracted face recognition features. Given any unconstrained unseen facial features of a subject, the DAB-GAN can reconstruct his/her faces in high definition. The DAB-GAN method includes a novel attention-based generative structure with the new defined Bijective Metrics Learning approach. The framework starts by introducing a bijective metric so that the distance measurement and metric learning process can be directly adopted in image domain for an image reconstruction task. The information from the blackbox face recognition engine will be optimally exploited using the global distillation process. Then an attention-based generator is presented for a highly robust generator to synthesize realistic faces with ID preservation. We have evaluated our method on the challenging face recognition databases, i.e. CelebA, LFW, AgeDB, CFP-FP, and consistently achieved the state-of-the-art results. The advancement of DAB-GAN is also proven on both image realism and ID preservation properties.
A new method for determining Wasserstein 1 optimal transport maps from Kantorovich potentials, with deep learning applications
Nov 02, 2022

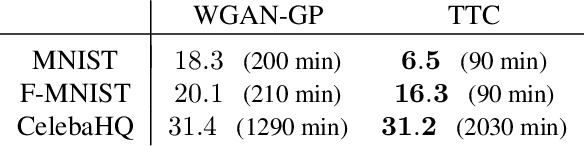

Wasserstein 1 optimal transport maps provide a natural correspondence between points from two probability distributions, $\mu$ and $\nu$, which is useful in many applications. Available algorithms for computing these maps do not appear to scale well to high dimensions. In deep learning applications, efficient algorithms have been developed for approximating solutions of the dual problem, known as Kantorovich potentials, using neural networks (e.g. [Gulrajani et al., 2017]). Importantly, such algorithms work well in high dimensions. In this paper we present an approach towards computing Wasserstein 1 optimal transport maps that relies only on Kantorovich potentials. In general, a Wasserstein 1 optimal transport map is not unique and is not computable from a potential alone. Our main result is to prove that if $\mu$ has a density and $\nu$ is supported on a submanifold of codimension at least 2, an optimal transport map is unique and can be written explicitly in terms of a potential. These assumptions are natural in many image processing contexts and other applications. When the Kantorovich potential is only known approximately, our result motivates an iterative procedure wherein data is moved in optimal directions and with the correct average displacement. Since this provides an approach for transforming one distribution to another, it can be used as a multipurpose algorithm for various transport problems; we demonstrate through several proof of concept experiments that this algorithm successfully performs various imaging tasks, such as denoising, generation, translation and deblurring, which normally require specialized techniques.
Unsupervised Model Adaptation for Source-free Segmentation of Medical Images
Nov 02, 2022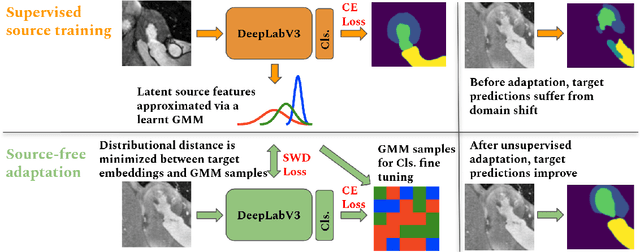
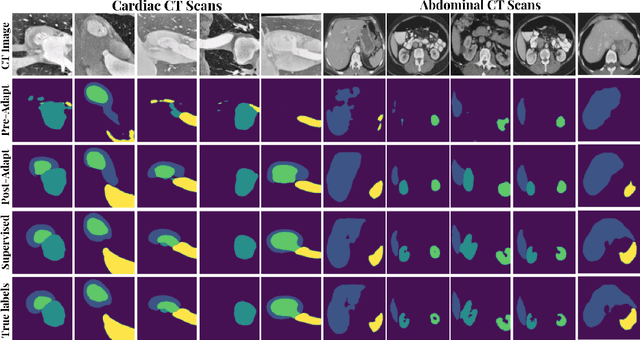

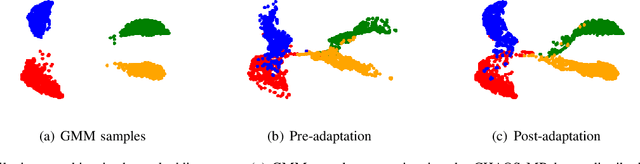
The recent prevalence of deep neural networks has lead semantic segmentation networks to achieve human-level performance in the medical field when sufficient training data is provided. Such networks however fail to generalize when tasked with predicting semantic maps for out-of-distribution images, requiring model re-training on the new distributions. This expensive process necessitates expert knowledge in order to generate training labels. Distribution shifts can arise naturally in the medical field via the choice of imaging device, i.e. MRI or CT scanners. To combat the need for labeling images in a target domain after a model is successfully trained in a fully annotated \textit{source domain} with a different data distribution, unsupervised domain adaptation (UDA) can be used. Most UDA approaches ensure target generalization by creating a shared source/target latent feature space. This allows a source trained classifier to maintain performance on the target domain. However most UDA approaches require joint source and target data access, which may create privacy leaks with respect to patient information. We propose an UDA algorithm for medical image segmentation that does not require access to source data during adaptation, and is thus capable in maintaining patient data privacy. We rely on an approximation of the source latent features at adaptation time, and create a joint source/target embedding space by minimizing a distributional distance metric based on optimal transport. We demonstrate our approach is competitive to recent UDA medical segmentation works even with the added privacy requisite.
Low-Light Video Enhancement with Synthetic Event Guidance
Aug 23, 2022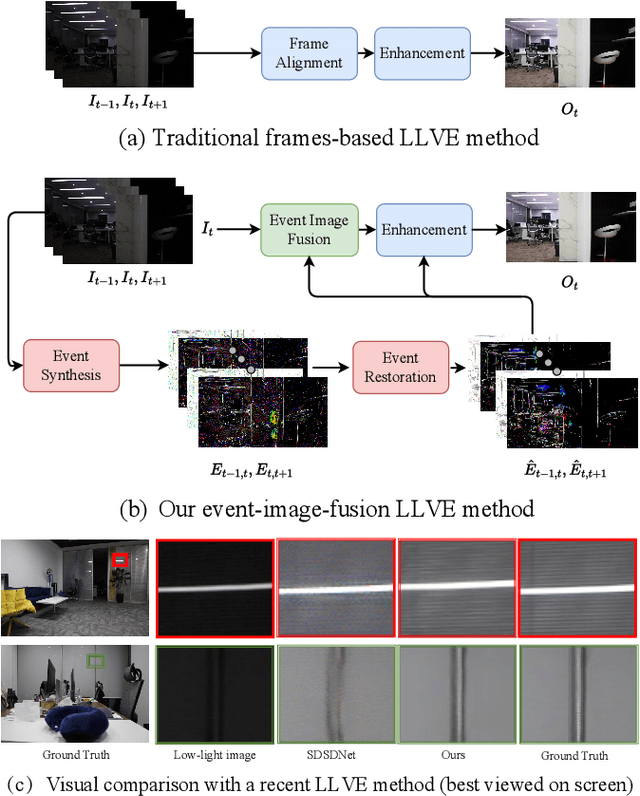
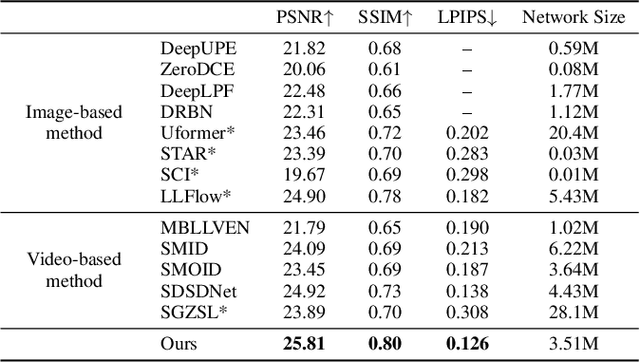

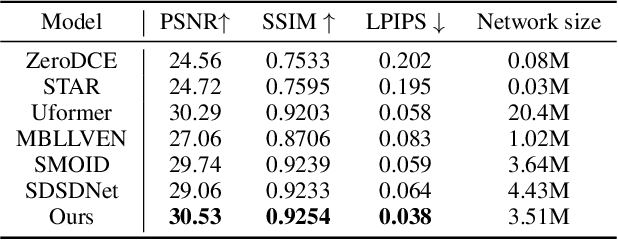
Low-light video enhancement (LLVE) is an important yet challenging task with many applications such as photographing and autonomous driving. Unlike single image low-light enhancement, most LLVE methods utilize temporal information from adjacent frames to restore the color and remove the noise of the target frame. However, these algorithms, based on the framework of multi-frame alignment and enhancement, may produce multi-frame fusion artifacts when encountering extreme low light or fast motion. In this paper, inspired by the low latency and high dynamic range of events, we use synthetic events from multiple frames to guide the enhancement and restoration of low-light videos. Our method contains three stages: 1) event synthesis and enhancement, 2) event and image fusion, and 3) low-light enhancement. In this framework, we design two novel modules (event-image fusion transform and event-guided dual branch) for the second and third stages, respectively. Extensive experiments show that our method outperforms existing low-light video or single image enhancement approaches on both synthetic and real LLVE datasets.
Artifact-Tolerant Clustering-Guided Contrastive Embedding Learning for Ophthalmic Images
Sep 02, 2022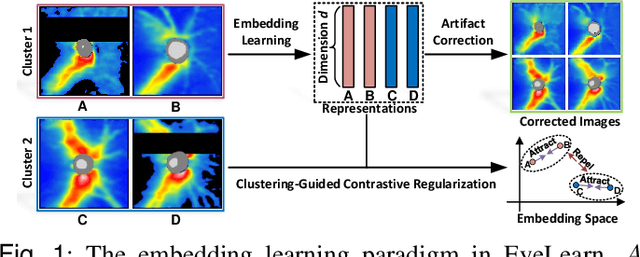
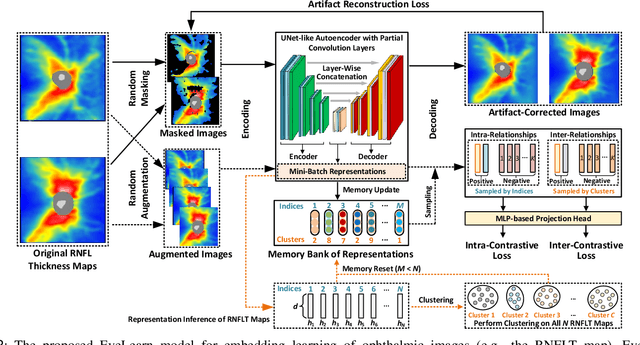
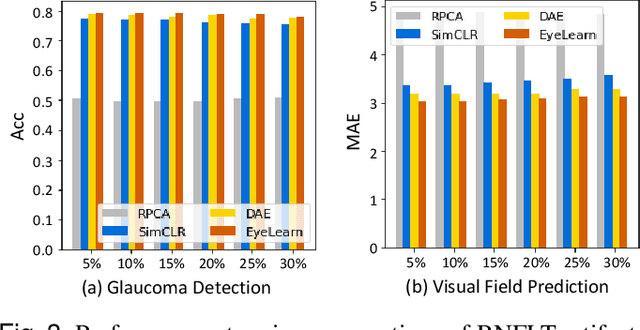
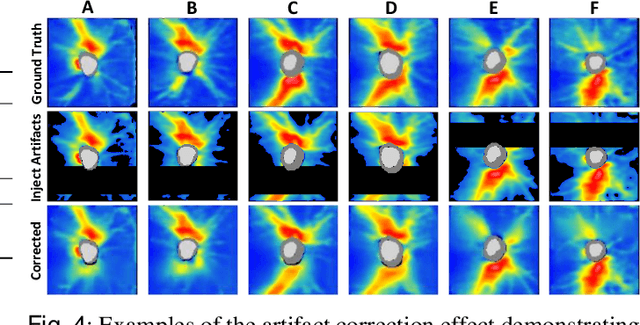
Ophthalmic images and derivatives such as the retinal nerve fiber layer (RNFL) thickness map are crucial for detecting and monitoring ophthalmic diseases (e.g., glaucoma). For computer-aided diagnosis of eye diseases, the key technique is to automatically extract meaningful features from ophthalmic images that can reveal the biomarkers (e.g., RNFL thinning patterns) linked to functional vision loss. However, representation learning from ophthalmic images that links structural retinal damage with human vision loss is non-trivial mostly due to large anatomical variations between patients. The task becomes even more challenging in the presence of image artifacts, which are common due to issues with image acquisition and automated segmentation. In this paper, we propose an artifact-tolerant unsupervised learning framework termed EyeLearn for learning representations of ophthalmic images. EyeLearn has an artifact correction module to learn representations that can best predict artifact-free ophthalmic images. In addition, EyeLearn adopts a clustering-guided contrastive learning strategy to explicitly capture the intra- and inter-image affinities. During training, images are dynamically organized in clusters to form contrastive samples in which images in the same or different clusters are encouraged to learn similar or dissimilar representations, respectively. To evaluate EyeLearn, we use the learned representations for visual field prediction and glaucoma detection using a real-world ophthalmic image dataset of glaucoma patients. Extensive experiments and comparisons with state-of-the-art methods verified the effectiveness of EyeLearn for learning optimal feature representations from ophthalmic images.
Grafting Vision Transformers
Oct 28, 2022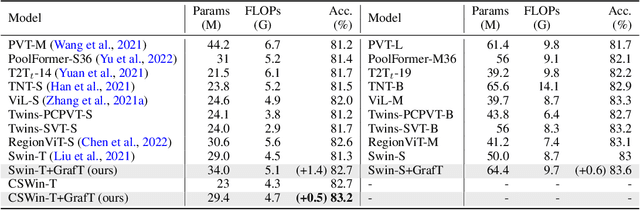
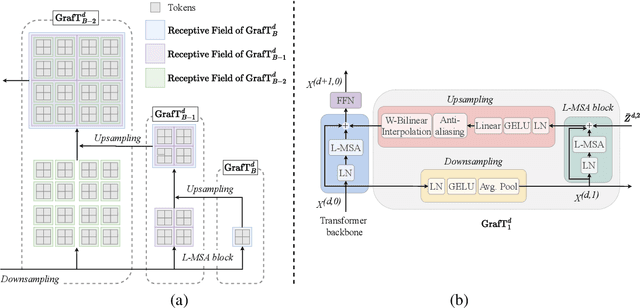
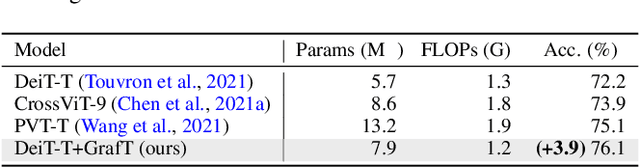
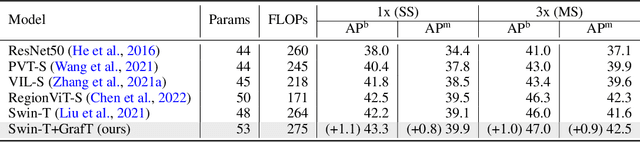
Vision Transformers (ViTs) have recently become the state-of-the-art across many computer vision tasks. In contrast to convolutional networks (CNNs), ViTs enable global information sharing even within shallow layers of a network, i.e., among high-resolution features. However, this perk was later overlooked with the success of pyramid architectures such as Swin Transformer, which show better performance-complexity trade-offs. In this paper, we present a simple and efficient add-on component (termed GrafT) that considers global dependencies and multi-scale information throughout the network, in both high- and low-resolution features alike. GrafT can be easily adopted in both homogeneous and pyramid Transformers while showing consistent gains. It has the flexibility of branching-out at arbitrary depths, widening a network with multiple scales. This grafting operation enables us to share most of the parameters and computations of the backbone, adding only minimal complexity, but with a higher yield. In fact, the process of progressively compounding multi-scale receptive fields in GrafT enables communications between local regions. We show the benefits of the proposed method on multiple benchmarks, including image classification (ImageNet-1K), semantic segmentation (ADE20K), object detection and instance segmentation (COCO2017). Our code and models will be made available.