 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MicroISP: Processing 32MP Photos on Mobile Devices with Deep Learning
Nov 08, 2022

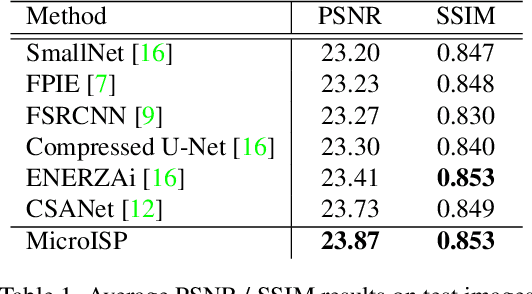

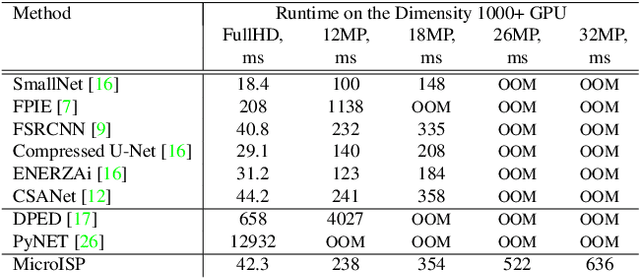
While neural networks-based photo processing solutions can provide a better image quality compared to the traditional ISP systems, their application to mobile devices is still very limited due to their very high computational complexity. In this paper, we present a novel MicroISP model designed specifically for edge devices, taking into account their computational and memory limitations. The proposed solution is capable of processing up to 32MP photos on recent smartphones using the standard mobile ML libraries and requiring less than 1 second to perform the inference, while for FullHD images it achieves real-time performance. The architecture of the model is flexible, allowing to adjust its complexity to devices of different computational power. To evaluate the performance of the model, we collected a novel Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The experiments demonstrated that, despite its compact size, the MicroISP model is able to provide comparable or better visual results than the traditional mobile ISP systems, while outperforming the previously proposed efficient deep learning based solutions. Finally, this model is also compatible with the latest mobile AI accelerators, achieving good runtime and low power consumption on smartphone NPUs and APUs. The code, dataset and pre-trained models are available on the project website: https://people.ee.ethz.ch/~ihnatova/microisp.html
Rethinking Hierarchies in Pre-trained Plain Vision Transformer
Nov 08, 2022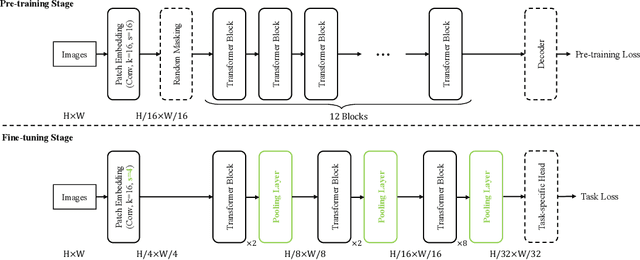

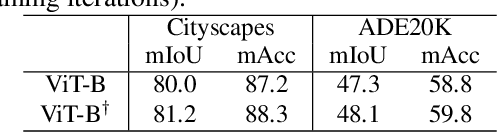
Self-supervised pre-training vision transformer (ViT) via masked image modeling (MIM) has been proven very effective. However, customized algorithms should be carefully designed for the hierarchical ViTs, e.g., GreenMIM, instead of using the vanilla and simple MAE for the plain ViT. More importantly, since these hierarchical ViTs cannot reuse the off-the-shelf pre-trained weights of the plain ViTs, the requirement of pre-training them leads to a massive amount of computational cost, thereby incurring both algorithmic and computational complexity. In this paper, we address this problem by proposing a novel idea of disentangling the hierarchical architecture design from the self-supervised pre-training. We transform the plain ViT into a hierarchical one with minimal changes. Technically, we change the stride of linear embedding layer from 16 to 4 and add convolution (or simple average) pooling layers between the transformer blocks, thereby reducing the feature size from 1/4 to 1/32 sequentially. Despite its simplicity, it outperforms the plain ViT baseline in classification, detection, and segmentation tasks on ImageNet, MS COCO, Cityscapes, and ADE20K benchmarks, respectively. We hope this preliminary study could draw more attention from the community on developing effective (hierarchical) ViTs while avoiding the pre-training cost by leveraging the off-the-shelf checkpoints. The code and models will be released at https://github.com/ViTAE-Transformer/HPViT.
Privacy Meets Explainability: A Comprehensive Impact Benchmark
Nov 08, 2022
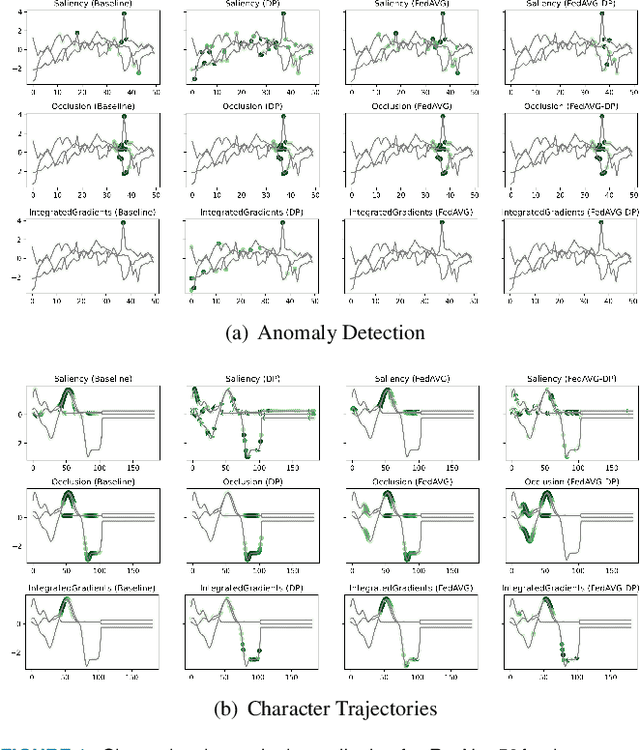
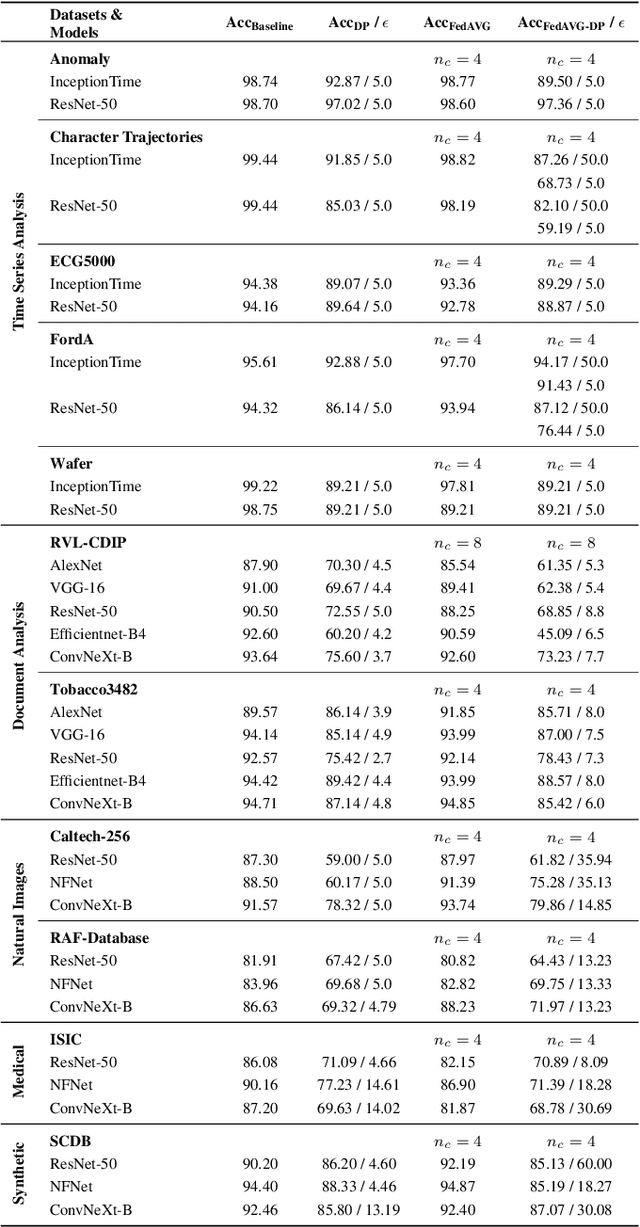

Since the mid-10s, the era of Deep Learning (DL) has continued to this day, bringing forth new superlatives and innovations each year. Nevertheless, the speed with which these innovations translate into real applications lags behind this fast pace. Safety-critical applications, in particular, underlie strict regulatory and ethical requirements which need to be taken care of and are still active areas of debate. eXplainable AI (XAI) and privacy-preserving machine learning (PPML) are both crucial research fields, aiming at mitigating some of the drawbacks of prevailing data-hungry black-box models in DL. Despite brisk research activity in the respective fields, no attention has yet been paid to their interaction. This work is the first to investigate the impact of private learning techniques on generated explanations for DL-based models. In an extensive experimental analysis covering various image and time series datasets from multiple domains, as well as varying privacy techniques, XAI methods, and model architectures, the effects of private training on generated explanations are studied. The findings suggest non-negligible changes in explanations through the introduction of privacy. Apart from reporting individual effects of PPML on XAI, the paper gives clear recommendations for the choice of techniques in real applications. By unveiling the interdependencies of these pivotal technologies, this work is a first step towards overcoming the remaining hurdles for practically applicable AI in safety-critical domains.
RZSR: Reference-based Zero-Shot Super-Resolution with Depth Guided Self-Exemplars
Aug 24, 2022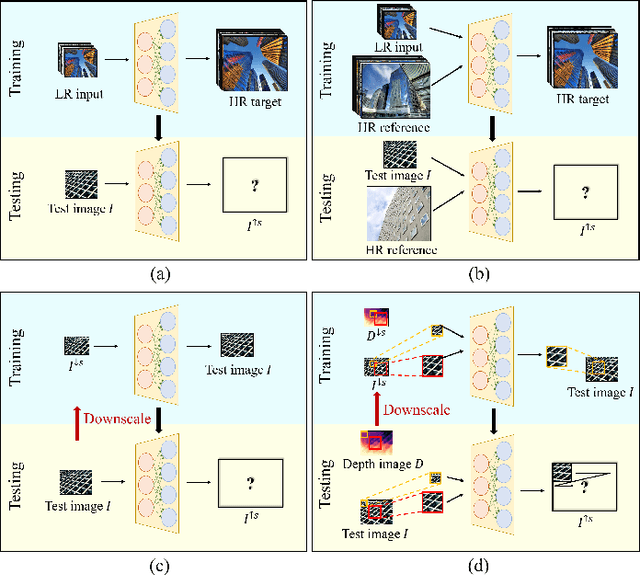
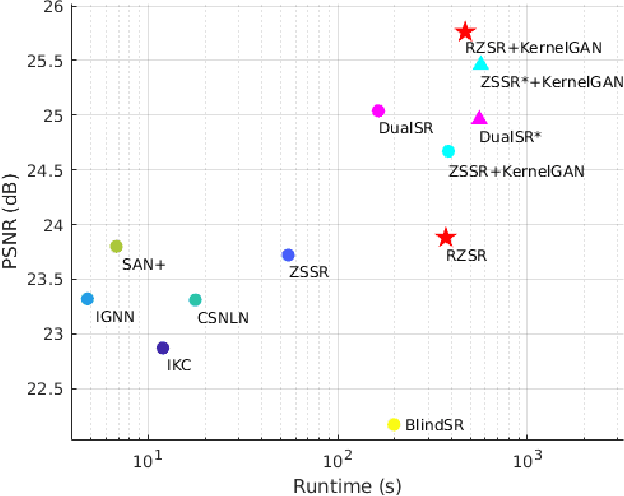
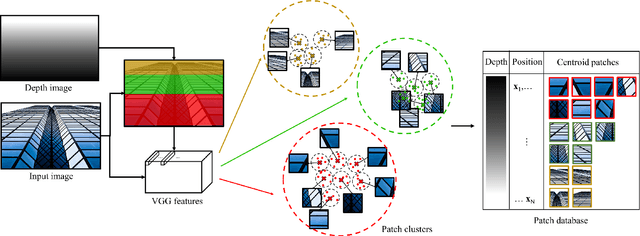
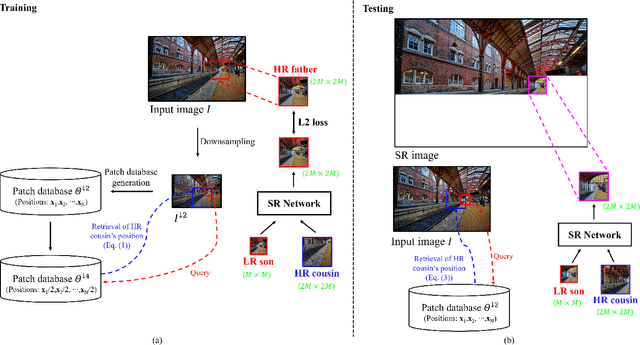
Recent methods for single image super-resolution (SISR) have demonstrated outstanding performance in generating high-resolution (HR) images from low-resolution (LR) images. However, most of these methods show their superiority using synthetically generated LR images, and their generalizability to real-world images is often not satisfactory. In this paper, we pay attention to two well-known strategies developed for robust super-resolution (SR), i.e., reference-based SR (RefSR) and zero-shot SR (ZSSR), and propose an integrated solution, called reference-based zero-shot SR (RZSR). Following the principle of ZSSR, we train an image-specific SR network at test time using training samples extracted only from the input image itself. To advance ZSSR, we obtain reference image patches with rich textures and high-frequency details which are also extracted only from the input image using cross-scale matching. To this end, we construct an internal reference dataset and retrieve reference image patches from the dataset using depth information. Using LR patches and their corresponding HR reference patches, we train a RefSR network that is embodied with a non-local attention module. Experimental results demonstrate the superiority of the proposed RZSR compared to the previous ZSSR methods and robustness to unseen images compared to other fully supervised SISR methods.
Vision-Based Defect Classification and Weight Estimation of Rice Kernels
Oct 06, 2022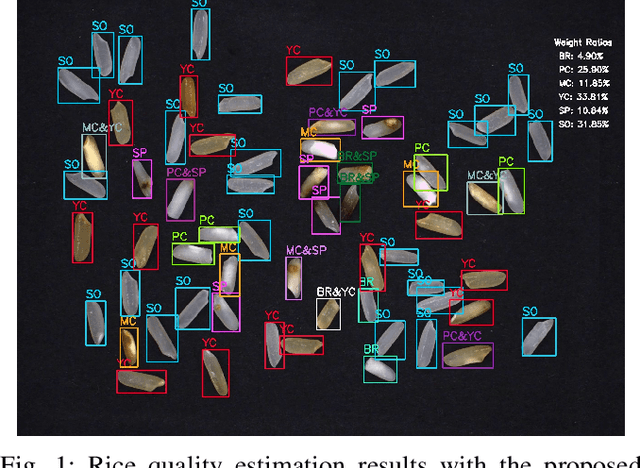



Rice is one of the main staple food in many areas of the world. The quality estimation of rice kernels are crucial in terms of both food safety and socio-economic impact. This was usually carried out by quality inspectors in the past, which may result in both objective and subjective inaccuracies. In this paper, we present an automatic visual quality estimation system of rice kernels, to classify the sampled rice kernels according to their types of flaws, and evaluate their quality via the weight ratios of the perspective kernel types. To compensate for the imbalance of different kernel numbers and classify kernels with multiple flaws accurately, we propose a multi-stage workflow which is able to locate the kernels in the captured image and classify their properties. We define a novel metric to measure the relative weight of each kernel in the image from its area, such that the relative weight of each type of kernels with regard to the all samples can be computed and used as the basis for rice quality estimation. Various experiments are carried out to show that our system is able to output precise results in a contactless way and replace tedious and error-prone manual works.
The Lie Derivative for Measuring Learned Equivariance
Oct 06, 2022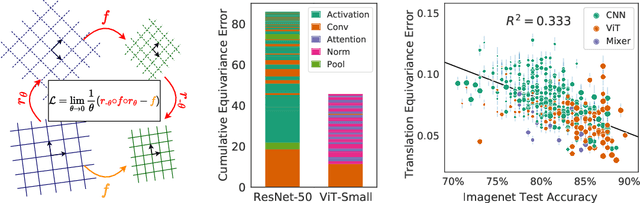
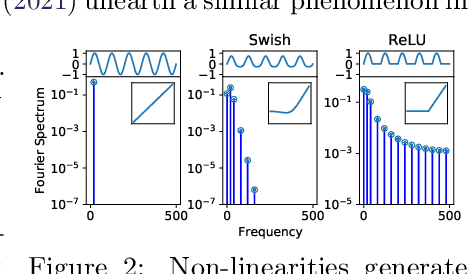
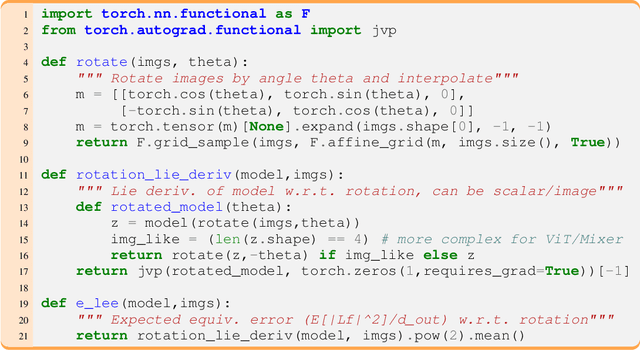
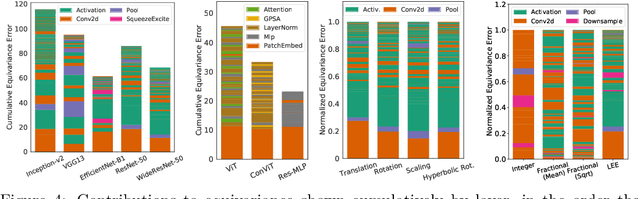
Equivariance guarantees that a model's predictions capture key symmetries in data. When an image is translated or rotated, an equivariant model's representation of that image will translate or rotate accordingly. The success of convolutional neural networks has historically been tied to translation equivariance directly encoded in their architecture. The rising success of vision transformers, which have no explicit architectural bias towards equivariance, challenges this narrative and suggests that augmentations and training data might also play a significant role in their performance. In order to better understand the role of equivariance in recent vision models, we introduce the Lie derivative, a method for measuring equivariance with strong mathematical foundations and minimal hyperparameters. Using the Lie derivative, we study the equivariance properties of hundreds of pretrained models, spanning CNNs, transformers, and Mixer architectures. The scale of our analysis allows us to separate the impact of architecture from other factors like model size or training method. Surprisingly, we find that many violations of equivariance can be linked to spatial aliasing in ubiquitous network layers, such as pointwise non-linearities, and that as models get larger and more accurate they tend to display more equivariance, regardless of architecture. For example, transformers can be more equivariant than convolutional neural networks after training.
2D-MRI of the Central Nervous System: The effect of a deep learning-based reconstruction pipeline on the overall image quality
Jun 02, 2022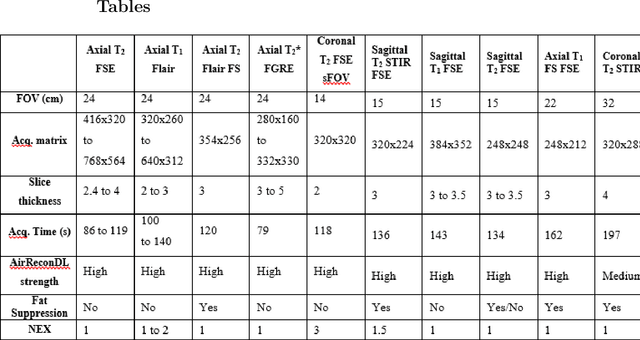
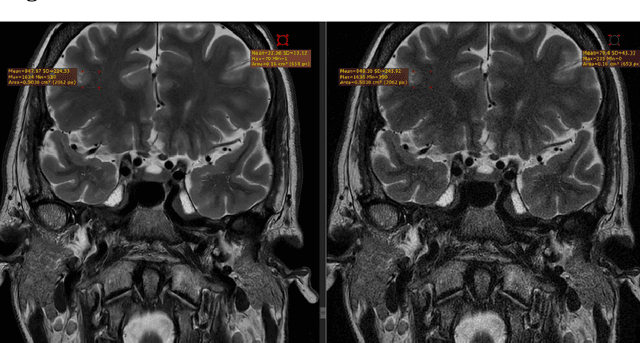
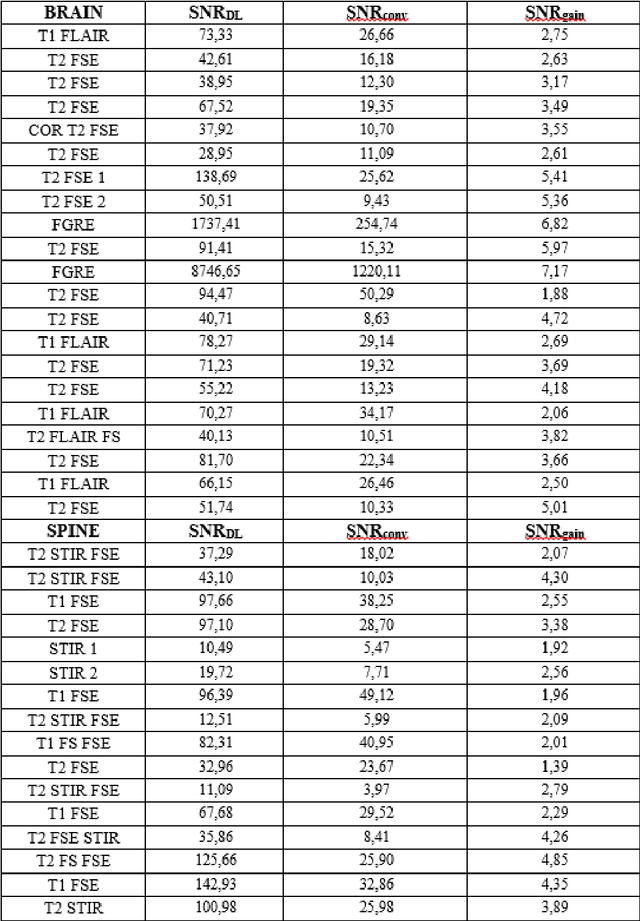
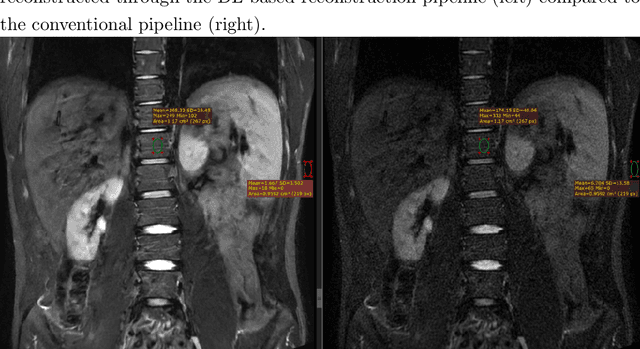
Purpose of this study was to evaluate the effect of a robust magnetic resonance reconstruction pipeline equipped with a deep convolutional neural network on the overall image quality, in terms of Gibbs artifact reduction, and SNR improvement. Sixteen (16) healthy volunteers enrolled in this study and were imaged at 3T. Representative images of each image series that were reconstructed through the pipeline that leverages a deep learning (DL) algorithm were retrospectively benchmarked against corresponding images reconstructed through a conventional pipeline. DL-reconstructed images showed significant SNR improvements compared to the corresponding conventionally reconstructed images. In addition to that, Gibbs artifacts were effectively eliminated, when the raw data were reconstructed through the DL pipeline. Gibbs artifact reduction was qualitatively assessed by two experienced medical physicists and two experienced radiologists. DL-based reconstruction can lead to an SNR surplus which can be further invested into either higher spatial resolution and thinner slices, or into shorter scan times.
UnGANable: Defending Against GAN-based Face Manipulation
Oct 03, 2022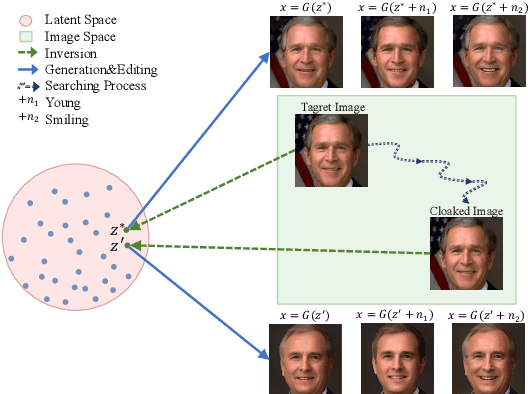

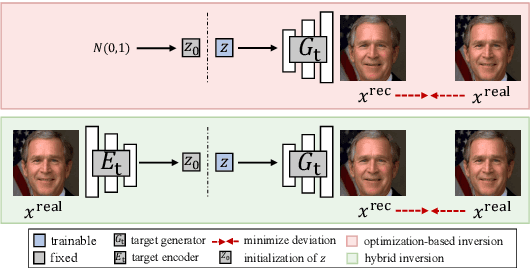
Deepfakes pose severe threats of visual misinformation to our society. One representative deepfake application is face manipulation that modifies a victim's facial attributes in an image, e.g., changing her age or hair color. The state-of-the-art face manipulation techniques rely on Generative Adversarial Networks (GANs). In this paper, we propose the first defense system, namely UnGANable, against GAN-inversion-based face manipulation. In specific, UnGANable focuses on defending GAN inversion, an essential step for face manipulation. Its core technique is to search for alternative images (called cloaked images) around the original images (called target images) in image space. When posted online, these cloaked images can jeopardize the GAN inversion process. We consider two state-of-the-art inversion techniques including optimization-based inversion and hybrid inversion, and design five different defenses under five scenarios depending on the defender's background knowledge. Extensive experiments on four popular GAN models trained on two benchmark face datasets show that UnGANable achieves remarkable effectiveness and utility performance, and outperforms multiple baseline methods. We further investigate four adaptive adversaries to bypass UnGANable and show that some of them are slightly effective.
Digitization of Raster Logs: A Deep Learning Approach
Oct 11, 2022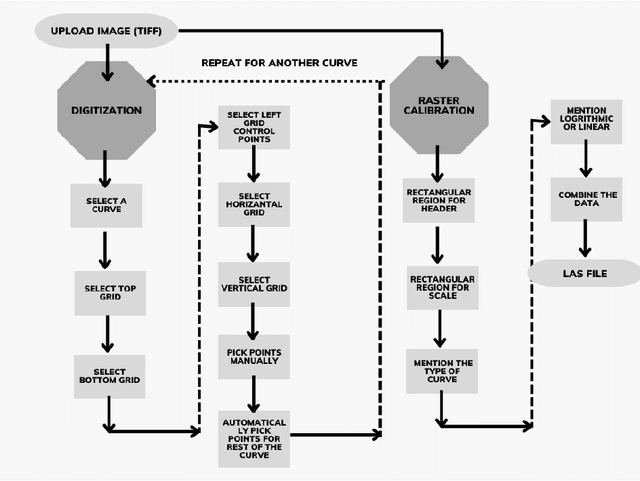
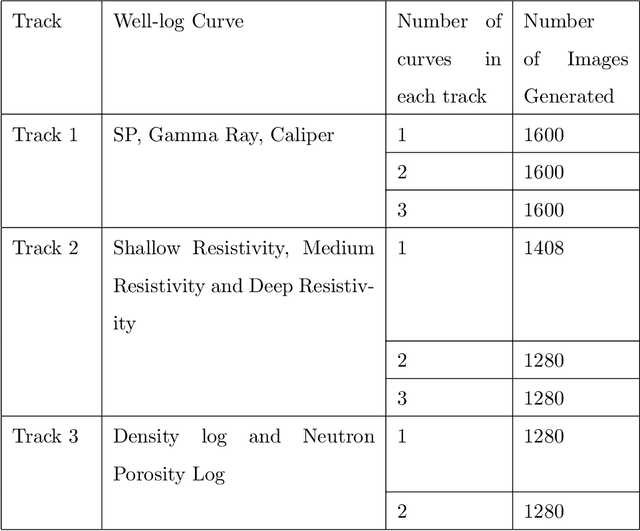
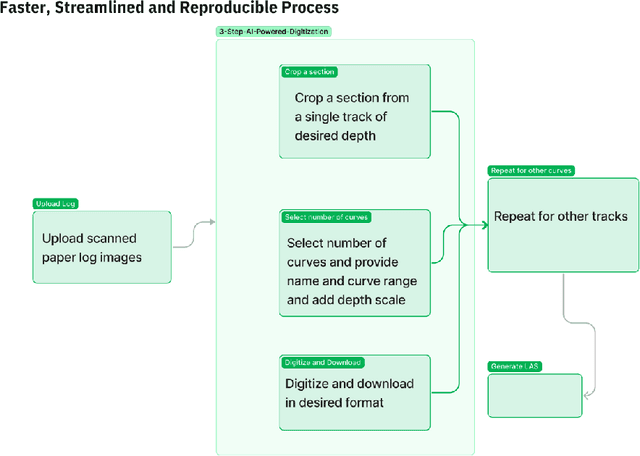
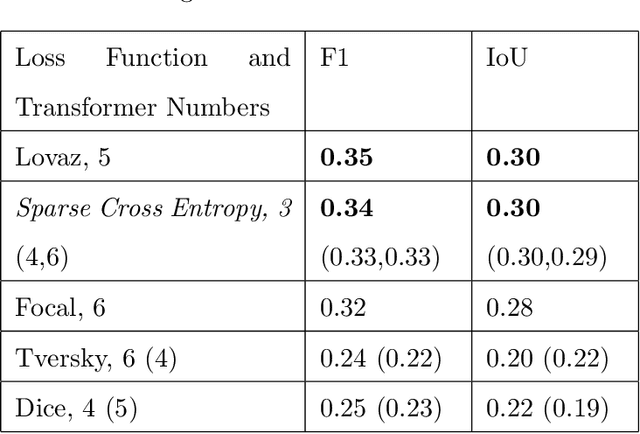
Raster well-log images are digital representations of well-logs data generated over the years. Raster digital well logs represent bitmaps of the log image in a rectangular array of black (zeros) and white dots (ones) called pixels. Experts study the raster logs manually or with software applications that still require a tremendous amount of manual input. Besides the loss of thousands of person-hours, this process is erroneous and tedious. To digitize these raster logs, one must buy a costly digitizer that is not only manual and time-consuming but also a hidden technical debt since enterprises stand to lose more money in additional servicing and consulting charges. We propose a deep neural network architecture called VeerNet to semantically segment the raster images from the background grid and classify and digitize the well-log curves. Raster logs have a substantially greater resolution than images traditionally consumed by image segmentation pipelines. Since the input has a low signal-to-resolution ratio, we require rapid downsampling to alleviate unnecessary computation. We thus employ a modified UNet-inspired architecture that balances retaining key signals and reducing result dimensionality. We use attention augmented read-process-write architecture. This architecture efficiently classifies and digitizes the curves with an overall F1 score of 35% and IoU of 30%. When compared to the actual las values for Gamma-ray and derived value of Gamma-ray from VeerNet, a high Pearson coefficient score of 0.62 was achieved.
Learning-Driven Lossy Image Compression; A Comprehensive Survey
Jan 23, 2022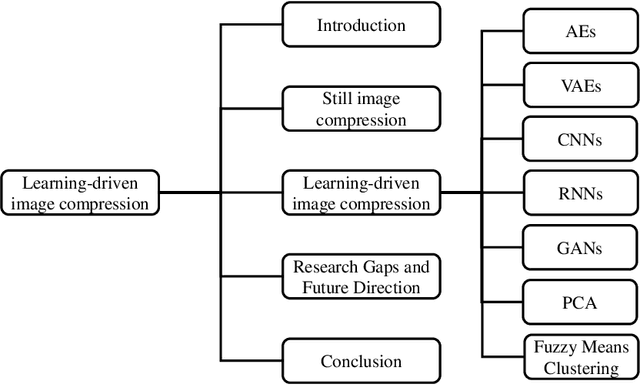
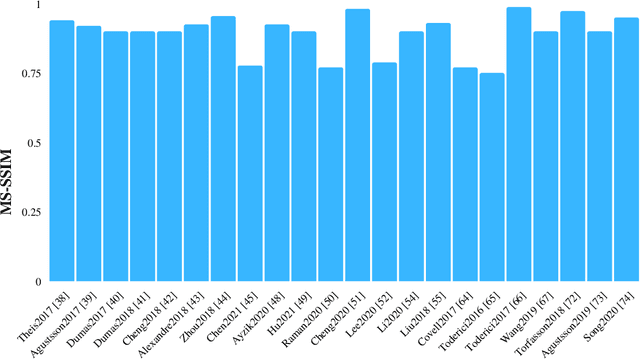
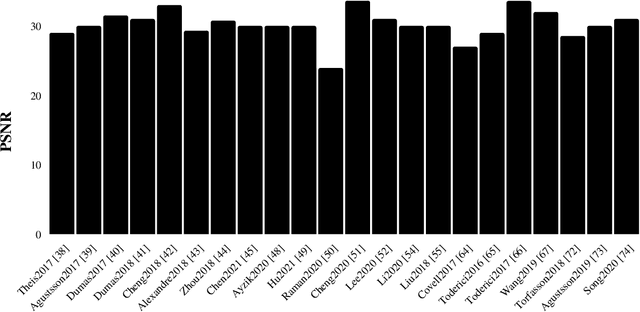
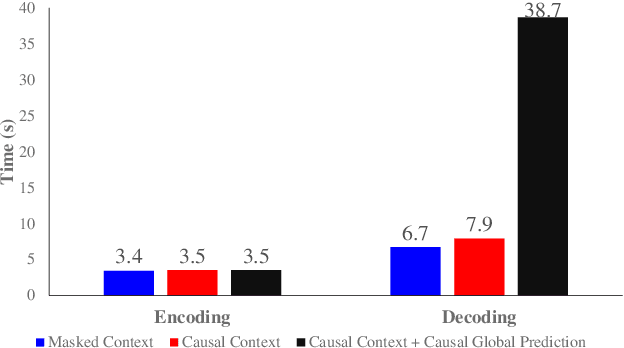
In the realm of image processing and computer vision (CV), machine learning (ML) architectures are widely applied. Convolutional neural networks (CNNs) solve a wide range of image processing issues and can solve image compression problem. Compression of images is necessary due to bandwidth and memory constraints. Helpful, redundant, and irrelevant information are three different forms of information found in images. This paper aims to survey recent techniques utilizing mostly lossy image compression using ML architectures including different auto-encoders (AEs) such as convolutional auto-encoders (CAEs), variational auto-encoders (VAEs), and AEs with hyper-prior models, recurrent neural networks (RNNs), CNNs, generative adversarial networks (GANs), principal component analysis (PCA) and fuzzy means clustering. We divide all of the algorithms into several groups based on architecture. We cover still image compression in this survey. Various discoveries for the researchers are emphasized and possible future directions for researchers. The open research problems such as out of memory (OOM), striped region distortion (SRD), aliasing, and compatibility of the frameworks with central processing unit (CPU) and graphics processing unit (GPU) simultaneously are explained. The majority of the publications in the compression domain surveyed are from the previous five years and use a variety of approaches.