 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ReMix: A General and Efficient Framework for Multiple Instance Learning based Whole Slide Image Classification
Jul 05, 2022
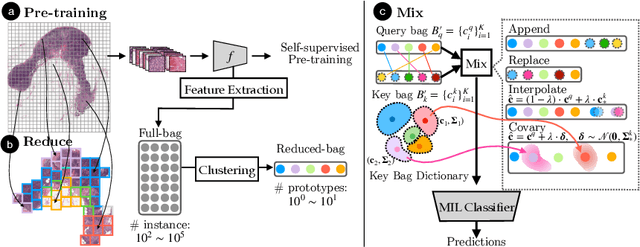
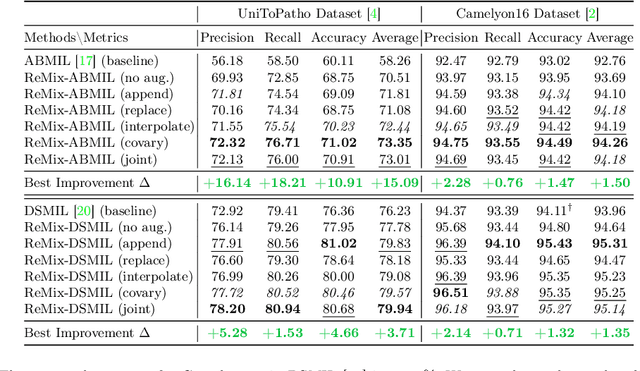
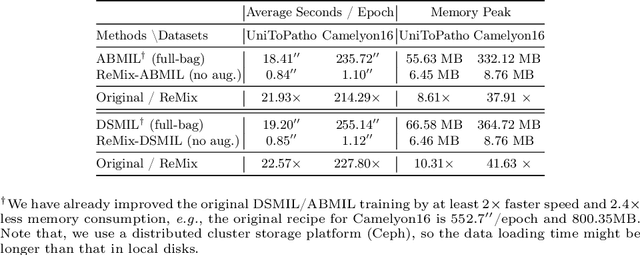

Whole slide image (WSI) classification often relies on deep weakly supervised multiple instance learning (MIL) methods to handle gigapixel resolution images and slide-level labels. Yet the decent performance of deep learning comes from harnessing massive datasets and diverse samples, urging the need for efficient training pipelines for scaling to large datasets and data augmentation techniques for diversifying samples. However, current MIL-based WSI classification pipelines are memory-expensive and computation-inefficient since they usually assemble tens of thousands of patches as bags for computation. On the other hand, despite their popularity in other tasks, data augmentations are unexplored for WSI MIL frameworks. To address them, we propose ReMix, a general and efficient framework for MIL based WSI classification. It comprises two steps: reduce and mix. First, it reduces the number of instances in WSI bags by substituting instances with instance prototypes, i.e., patch cluster centroids. Then, we propose a ``Mix-the-bag'' augmentation that contains four online, stochastic and flexible latent space augmentations. It brings diverse and reliable class-identity-preserving semantic changes in the latent space while enforcing semantic-perturbation invariance. We evaluate ReMix on two public datasets with two state-of-the-art MIL methods. In our experiments, consistent improvements in precision, accuracy, and recall have been achieved but with orders of magnitude reduced training time and memory consumption, demonstrating ReMix's effectiveness and efficiency. Code is available.
Errorless Robust JPEG Steganography using Outputs of JPEG Coders
Nov 09, 2022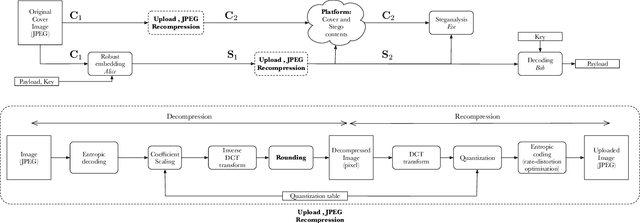
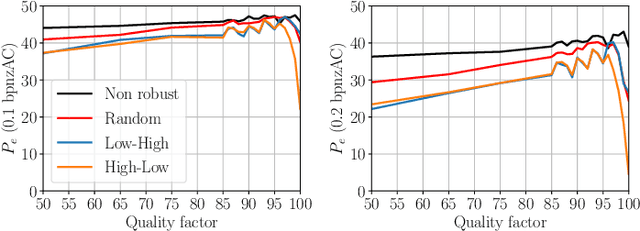

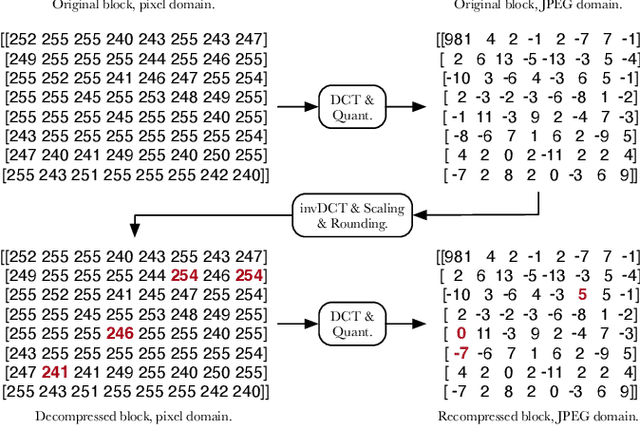
Robust steganography is a technique of hiding secret messages in images so that the message can be recovered after additional image processing. One of the most popular processing operations is JPEG recompression. Unfortunately, most of today's steganographic methods addressing this issue only provide a probabilistic guarantee of recovering the secret and are consequently not errorless. That is unacceptable since even a single unexpected change can make the whole message unreadable if it is encrypted. We propose to create a robust set of DCT coefficients by inspecting their behavior during recompression, which requires access to the targeted JPEG compressor. This is done by dividing the DCT coefficients into 64 non-overlapping lattices because one embedding change can potentially affect many other coefficients from the same DCT block during recompression. The robustness is then combined with standard steganographic costs creating a lattice embedding scheme robust against JPEG recompression. Through experiments, we show that the size of the robust set and the scheme's security depends on the ordering of lattices during embedding. We verify the validity of the proposed method with three typical JPEG compressors and benchmark its security for various embedding payloads, three different ways of ordering the lattices, and a range of Quality Factors. Finally, this method is errorless by construction, meaning the embedded message will always be readable.
Interpretable Explainability in Facial Emotion Recognition and Gamification for Data Collection
Nov 09, 2022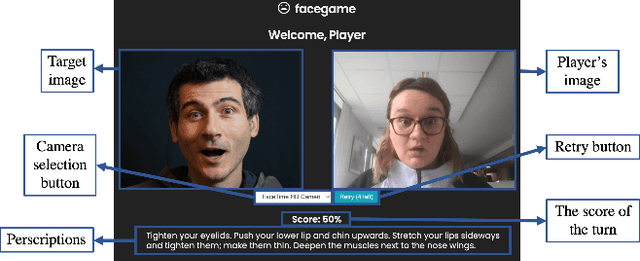
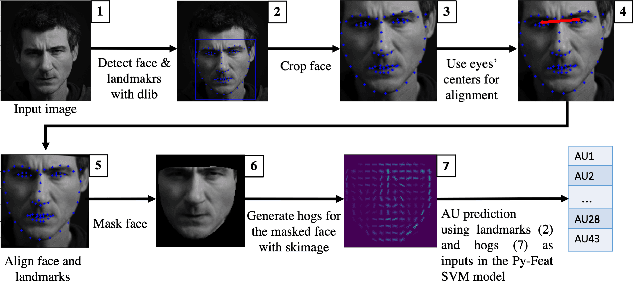
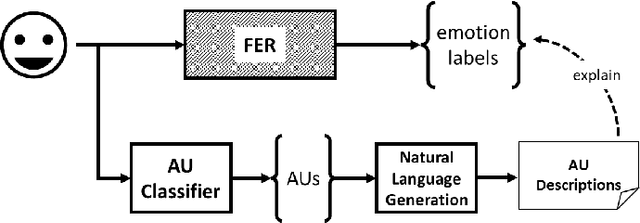
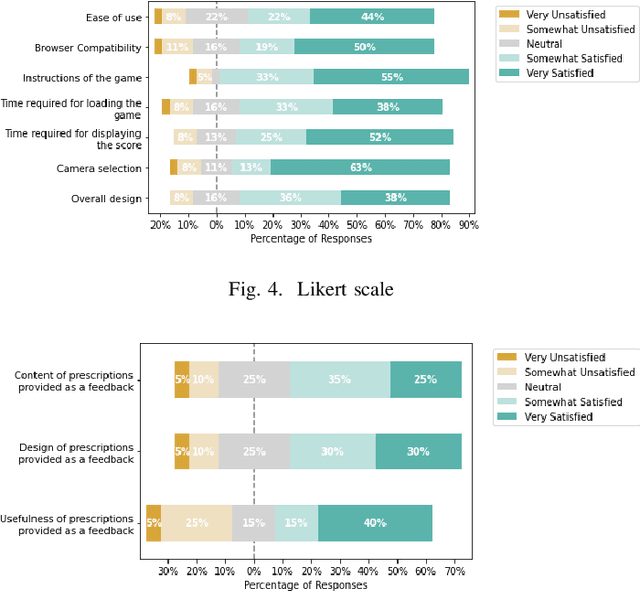
Training facial emotion recognition models requires large sets of data and costly annotation processes. To alleviate this problem, we developed a gamified method of acquiring annotated facial emotion data without an explicit labeling effort by humans. The game, which we named Facegame, challenges the players to imitate a displayed image of a face that portrays a particular basic emotion. Every round played by the player creates new data that consists of a set of facial features and landmarks, already annotated with the emotion label of the target facial expression. Such an approach effectively creates a robust, sustainable, and continuous machine learning training process. We evaluated Facegame with an experiment that revealed several contributions to the field of affective computing. First, the gamified data collection approach allowed us to access a rich variation of facial expressions of each basic emotion due to the natural variations in the players' facial expressions and their expressive abilities. We report improved accuracy when the collected data were used to enrich well-known in-the-wild facial emotion datasets and consecutively used for training facial emotion recognition models. Second, the natural language prescription method used by the Facegame constitutes a novel approach for interpretable explainability that can be applied to any facial emotion recognition model. Finally, we observed significant improvements in the facial emotion perception and expression skills of the players through repeated game play.
Automated MRI Field of View Prescription from Region of Interest Prediction by Intra-stack Attention Neural Network
Nov 09, 2022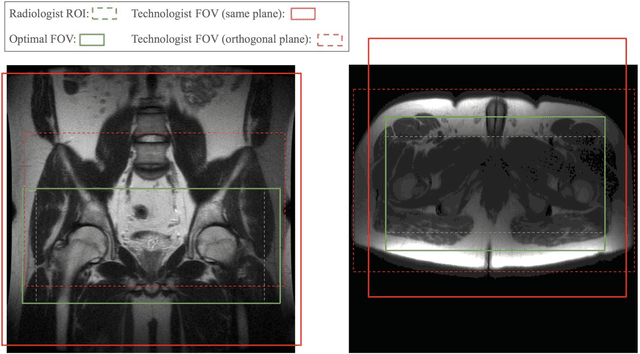
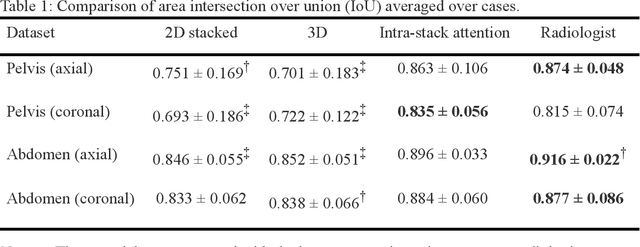
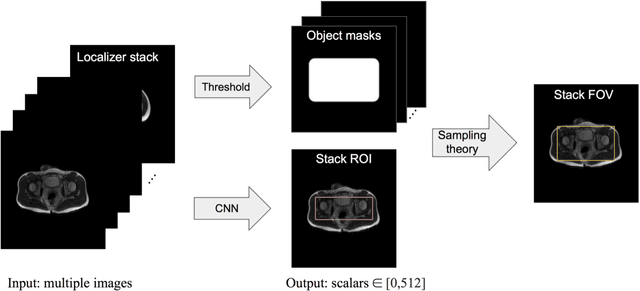
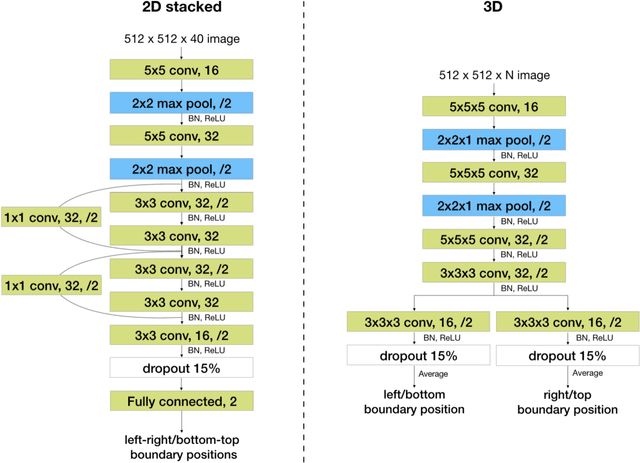
Manual prescription of the field of view (FOV) by MRI technologists is variable and prolongs the scanning process. Often, the FOV is too large or crops critical anatomy. We propose a deep-learning framework, trained by radiologists' supervision, for automating FOV prescription. An intra-stack shared feature extraction network and an attention network are used to process a stack of 2D image inputs to generate output scalars defining the location of a rectangular region of interest (ROI). The attention mechanism is used to make the model focus on the small number of informative slices in a stack. Then the smallest FOV that makes the neural network predicted ROI free of aliasing is calculated by an algebraic operation derived from MR sampling theory. We retrospectively collected 595 cases between February 2018 and February 2022. The framework's performance is examined quantitatively with intersection over union (IoU) and pixel error on position, and qualitatively with a reader study. We use the t-test for comparing quantitative results from all models and a radiologist. The proposed model achieves an average IoU of 0.867 and average ROI position error of 9.06 out of 512 pixels on 80 test cases, significantly better (P<0.05) than two baseline models and not significantly different from a radiologist (P>0.12). Finally, the FOV given by the proposed framework achieves an acceptance rate of 92% from an experienced radiologist.
A Robust Document Image Watermarking Scheme using Deep Neural Network
Feb 26, 2022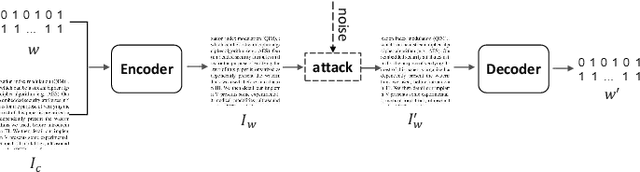



Watermarking is an important copyright protection technology which generally embeds the identity information into the carrier imperceptibly. Then the identity can be extracted to prove the copyright from the watermarked carrier even after suffering various attacks. Most of the existing watermarking technologies take the nature images as carriers. Different from the natural images, document images are not so rich in color and texture, and thus have less redundant information to carry watermarks. This paper proposes an end-to-end document image watermarking scheme using the deep neural network. Specifically, an encoder and a decoder are designed to embed and extract the watermark. A noise layer is added to simulate the various attacks that could be encountered in reality, such as the Cropout, Dropout, Gaussian blur, Gaussian noise, Resize, and JPEG Compression. A text-sensitive loss function is designed to limit the embedding modification on characters. An embedding strength adjustment strategy is proposed to improve the quality of watermarked image with little loss of extraction accuracy. Experimental results show that the proposed document image watermarking technology outperforms three state-of-the-arts in terms of the robustness and image quality.
Transformer-based dimensionality reduction
Oct 15, 2022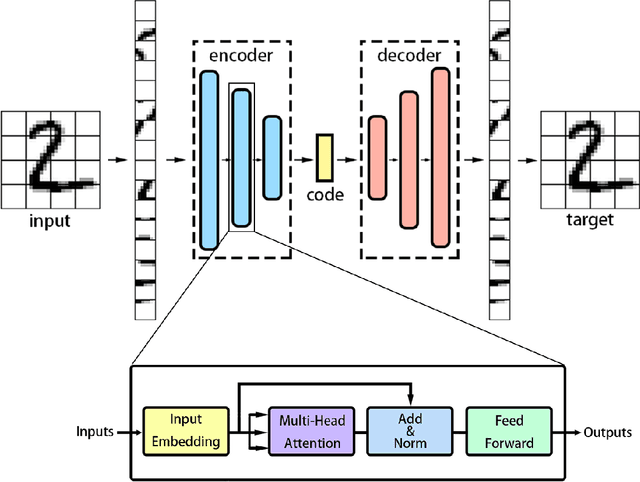
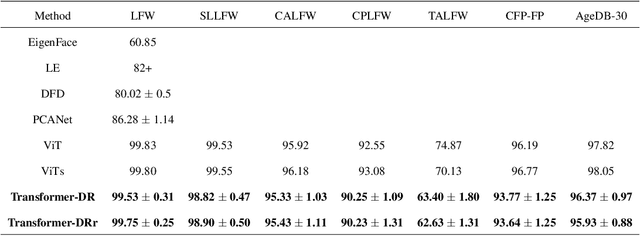
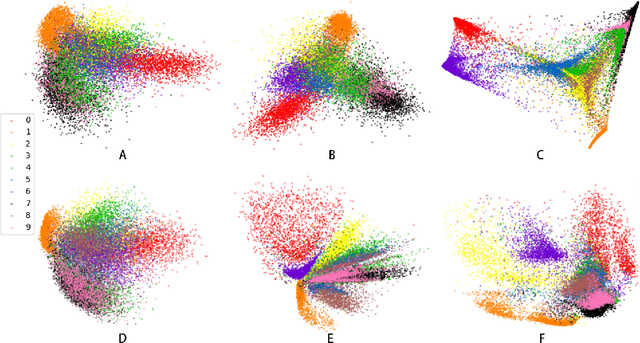

Recently, Transformer is much popular and plays an important role in the fields of Machine Learning (ML), Natural Language Processing (NLP), and Computer Vision (CV), etc. In this paper, based on the Vision Transformer (ViT) model, a new dimensionality reduction (DR) model is proposed, named Transformer-DR. From data visualization, image reconstruction and face recognition, the representation ability of Transformer-DR after dimensionality reduction is studied, and it is compared with some representative DR methods to understand the difference between Transformer-DR and existing DR methods. The experimental results show that Transformer-DR is an effective dimensionality reduction method.
Image Denoising Using Convolutional Autoencoder
Jul 24, 2022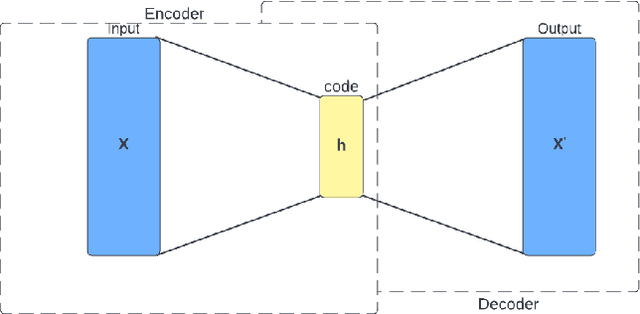
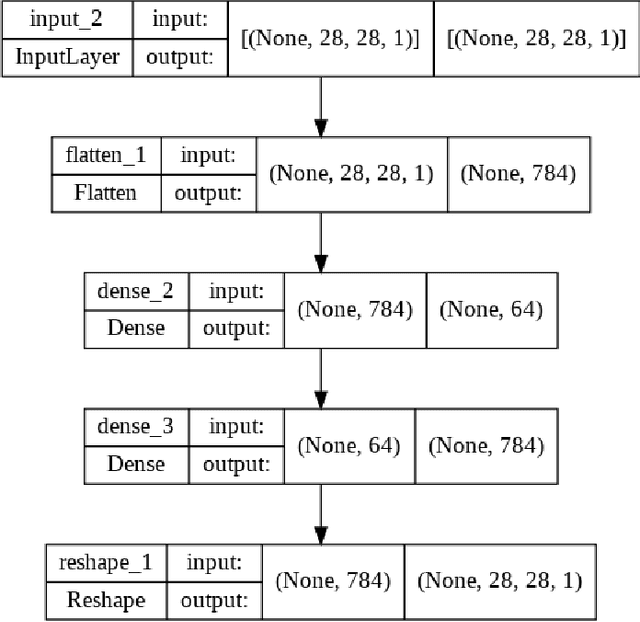


With the inexorable digitalisation of the modern world, every subset in the field of technology goes through major advancements constantly. One such subset is digital images which are ever so popular. Images can not always be as visually pleasing or clear as you would want them to be and are often distorted or obscured with noise. A number of techniques to enhance images have come up as the years passed, all with their own respective pros and cons. In this paper, we look at one such particular technique which accomplishes this task with the help of a neural network model commonly known as an autoencoder. We construct different architectures for the model and compare results in order to decide the one best suited for the task. The characteristics and working of the model are discussed briefly knowing which can help set a path for future research.
SVL-Adapter: Self-Supervised Adapter for Vision-Language Pretrained Models
Oct 07, 2022
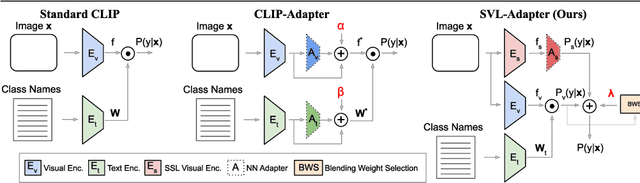
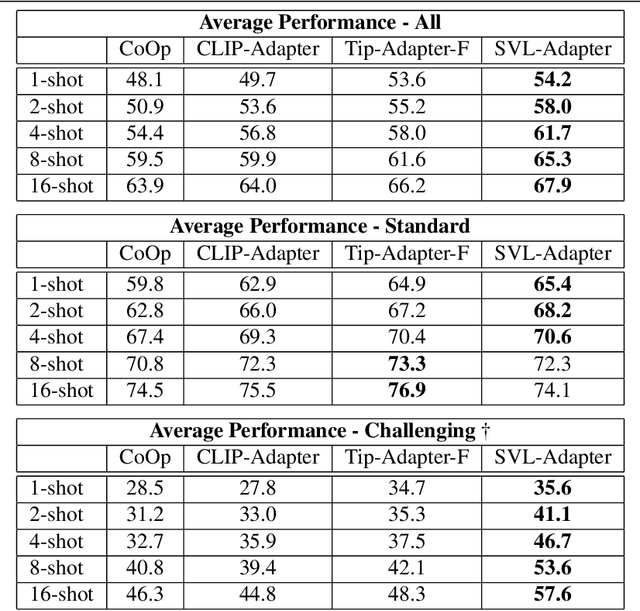
Vision-language models such as CLIP are pretrained on large volumes of internet sourced image and text pairs, and have been shown to sometimes exhibit impressive zero- and low-shot image classification performance. However, due to their size, fine-tuning these models on new datasets can be prohibitively expensive, both in terms of the supervision and compute required. To combat this, a series of light-weight adaptation methods have been proposed to efficiently adapt such models when limited supervision is available. In this work, we show that while effective on internet-style datasets, even those remedies under-deliver on classification tasks with images that differ significantly from those commonly found online. To address this issue, we present a new approach called SVL-Adapter that combines the complementary strengths of both vision-language pretraining and self-supervised representation learning. We report an average classification accuracy improvement of 10% in the low-shot setting when compared to existing methods, on a set of challenging visual classification tasks. Further, we present a fully automatic way of selecting an important blending hyperparameter for our model that does not require any held-out labeled validation data. Code for our project is available here: https://github.com/omipan/svl_adapter.
The UTE and ZTE Sequences at Ultra-High Magnetic Field Strengths: A Survey
Oct 07, 2022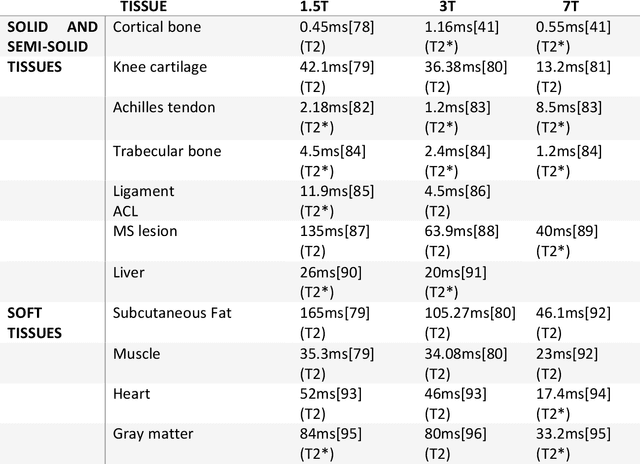
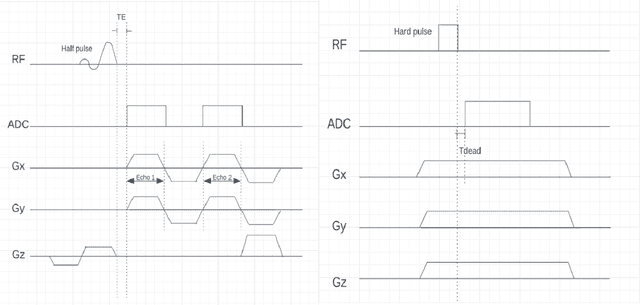
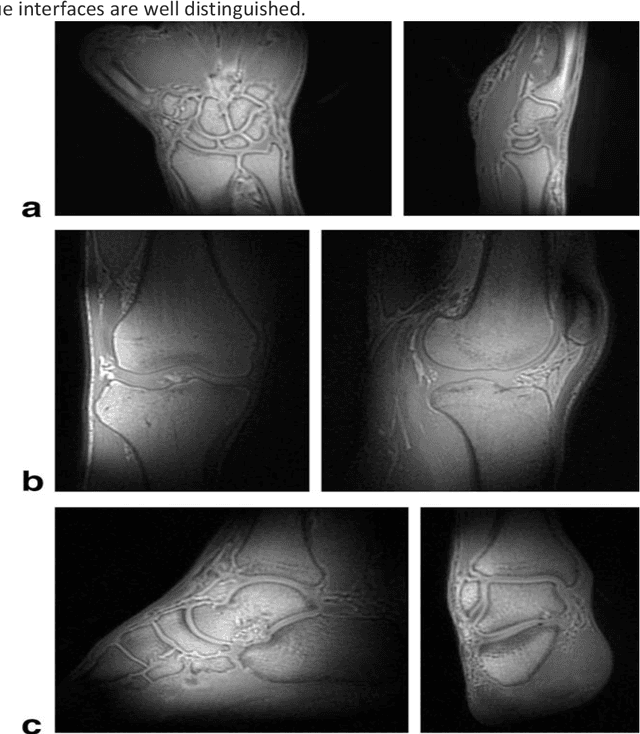
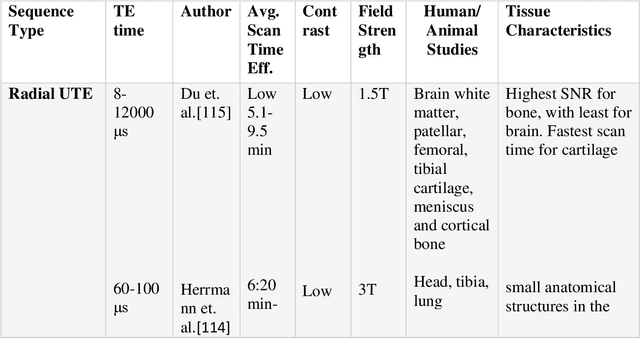
UTE (Ultrashort Echo Time) and ZTE (Zero Echo Time) sequences have been developed to detect short T2 relaxation signals coming from regions that are unable to be detected by conventional MRI methods. Due to the high dipole-dipole interactions in solid and semi-solid tissues, the echo time generated is simply not enough to produce a signal using conventional imaging method, often leading to void signal coming from the discussed areas. By the application of these techniques, solid and semi-solid areas can be imaged which can have a profound impact in clinical imaging. High and Ultra-high field strength (UHF) provides a vital advantage in providing better sensitivity and specificity of MR imaging. When coupled with the UTE and ZTE sequences, the image can recover void signals as well as a much-improved signal quality. To further this strategy, secondary data from various research tools was obtained to further validate the research while addressing the drawbacks to this approach. It was found that UTE and ZTE sequences coupled with some techniques such as qualitative imaging and new trajectories are very crucial for accurate image depiction of the areas of the musculoskeletal system, neural system, lung imaging and dental imaging.
Evaluating language-biased image classification based on semantic representations
Jan 26, 2022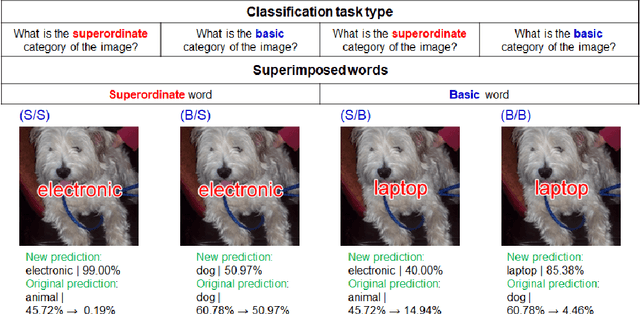

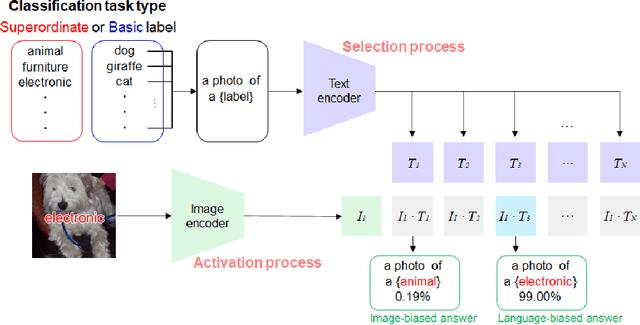

Humans show language-biased image recognition for a word-embedded image, known as picture-word interference. Such interference depends on hierarchical semantic categories and reflects that human language processing highly interacts with visual processing. Similar to humans, recent artificial models jointly trained on texts and images, e.g., OpenAI CLIP, show language-biased image classification. Exploring whether the bias leads to interferences similar to those observed in humans can contribute to understanding how much the model acquires hierarchical semantic representations from joint learning of language and vision. The present study introduces methodological tools from the cognitive science literature to assess the biases of artificial models. Specifically, we introduce a benchmark task to test whether words superimposed on images can distort the image classification across different category levels and, if it can, whether the perturbation is due to the shared semantic representation between language and vision. Our dataset is a set of word-embedded images and consists of a mixture of natural image datasets and hierarchical word labels with superordinate/basic category levels. Using this benchmark test, we evaluate the CLIP model. We show that presenting words distorts the image classification by the model across different category levels, but the effect does not depend on the semantic relationship between images and embedded words. This suggests that the semantic word representation in the CLIP visual processing is not shared with the image representation, although the word representation strongly dominates for word-embedded images.