 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Noise-reducing attention cross fusion learning transformer for histological image classification of osteosarcoma
Apr 29, 2022
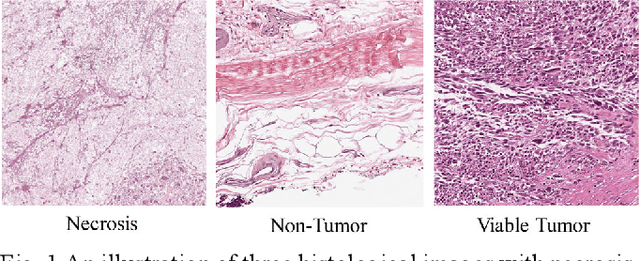
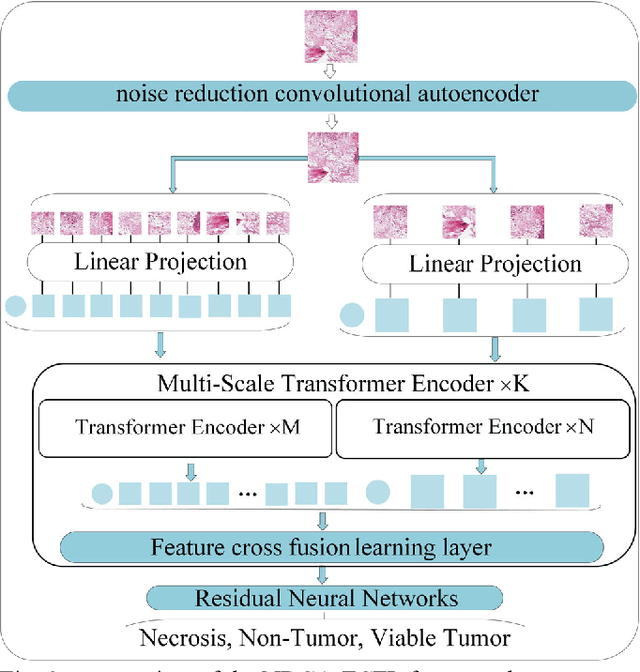
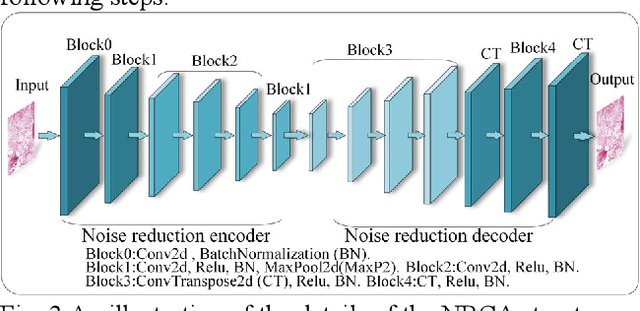
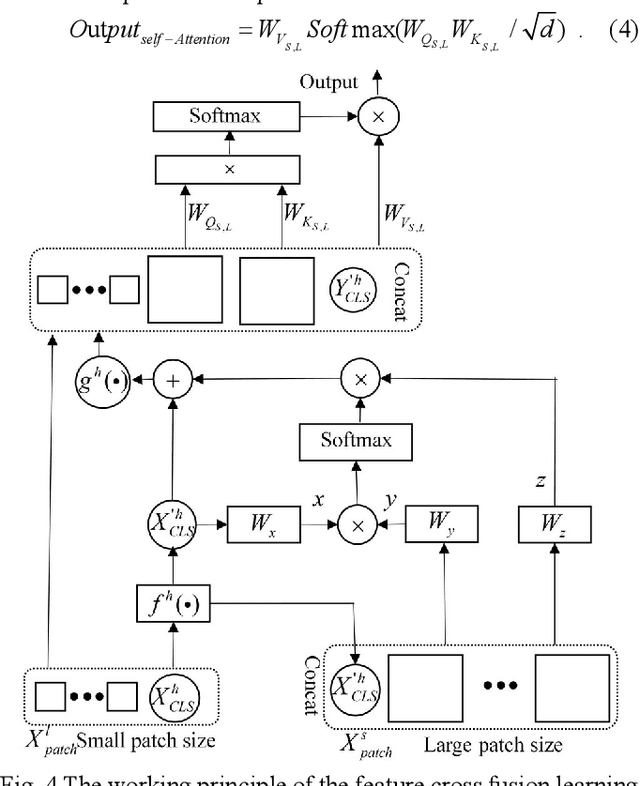
The degree of malignancy of osteosarcoma and its tendency to metastasize/spread mainly depend on the pathological grade (determined by observing the morphology of the tumor under a microscope). The purpose of this study is to use artificial intelligence to classify osteosarcoma histological images and to assess tumor survival and necrosis, which will help doctors reduce their workload, improve the accuracy of osteosarcoma cancer detection, and make a better prognosis for patients. The study proposes a typical transformer image classification framework by integrating noise reduction convolutional autoencoder and feature cross fusion learning (NRCA-FCFL) to classify osteosarcoma histological images. Noise reduction convolutional autoencoder could well denoise histological images of osteosarcoma, resulting in more pure images for osteosarcoma classification. Moreover, we introduce feature cross fusion learning, which integrates two scale image patches, to sufficiently explore their interactions by using additional classification tokens. As a result, a refined fusion feature is generated, which is fed to the residual neural network for label predictions. We conduct extensive experiments to evaluate the performance of the proposed approach. The experimental results demonstrate that our method outperforms the traditional and deep learning approaches on various evaluation metrics, with an accuracy of 99.17% to support osteosarcoma diagnosis.
Monogenic Wavelet Scattering Network for Texture Image Classification
Feb 25, 2022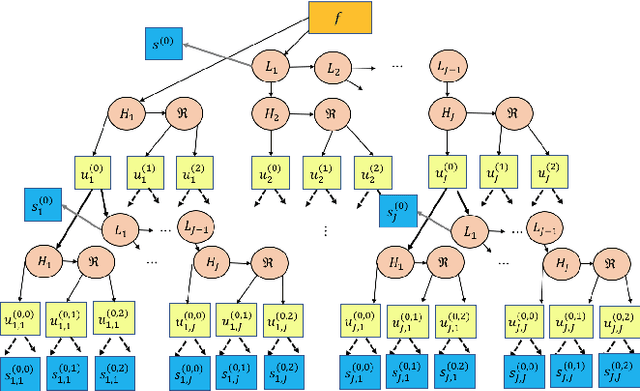
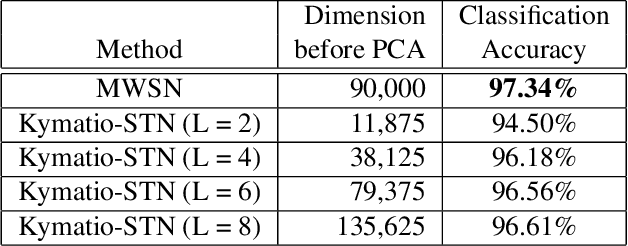


The scattering transform network (STN), which has a similar structure as that of a popular convolutional neural network except its use of predefined convolution filters and a small number of layers, can generates a robust representation of an input signal relative to small deformations. We propose a novel Monogenic Wavelet Scattering Network (MWSN) for 2D texture image classification through a cascade of monogenic wavelet filtering with nonlinear modulus and averaging operators by replacing the 2D Morlet wavelet filtering in the standard STN. Our MWSN can extract useful hierarchical and directional features with interpretable coefficients, which can be further compressed by PCA and fed into a classifier. Using the CUReT texture image database, we demonstrate the superior performance of our MWSN over the standard STN. This performance improvement can be explained by the natural extension of 1D analyticity to 2D monogenicity.
Conversion Between CT and MRI Images Using Diffusion and Score-Matching Models
Sep 29, 2022


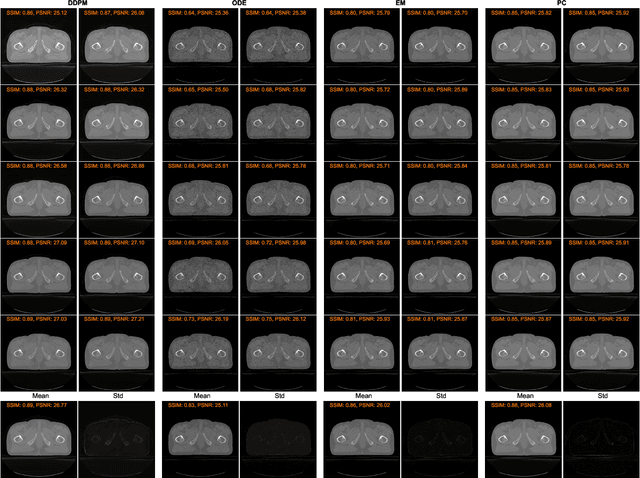
MRI and CT are most widely used medical imaging modalities. It is often necessary to acquire multi-modality images for diagnosis and treatment such as radiotherapy planning. However, multi-modality imaging is not only costly but also introduces misalignment between MRI and CT images. To address this challenge, computational conversion is a viable approach between MRI and CT images, especially from MRI to CT images. In this paper, we propose to use an emerging deep learning framework called diffusion and score-matching models in this context. Specifically, we adapt denoising diffusion probabilistic and score-matching models, use four different sampling strategies, and compare their performance metrics with that using a convolutional neural network and a generative adversarial network model. Our results show that the diffusion and score-matching models generate better synthetic CT images than the CNN and GAN models. Furthermore, we investigate the uncertainties associated with the diffusion and score-matching networks using the Monte-Carlo method, and improve the results by averaging their Monte-Carlo outputs. Our study suggests that diffusion and score-matching models are powerful to generate high quality images conditioned on an image obtained using a complementary imaging modality, analytically rigorous with clear explainability, and highly competitive with CNNs and GANs for image synthesis.
Graph Attention Network for Camera Relocalization on Dynamic Scenes
Sep 29, 2022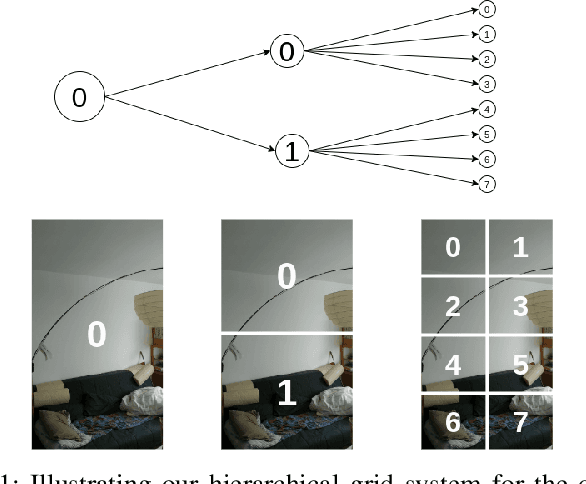
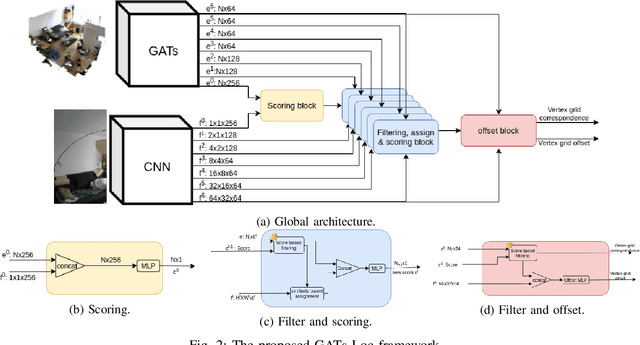
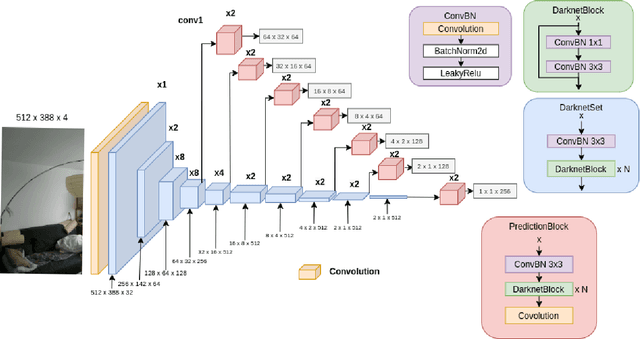
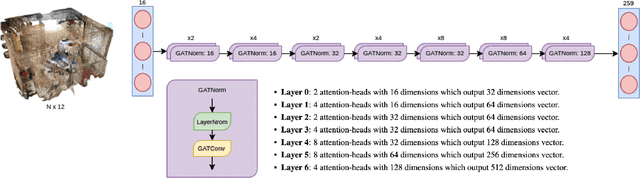
We devise a graph attention network-based approach for learning a scene triangle mesh representation in order to estimate an image camera position in a dynamic environment. Previous approaches built a scene-dependent model that explicitly or implicitly embeds the structure of the scene. They use convolution neural networks or decision trees to establish 2D/3D-3D correspondences. Such a mapping overfits the target scene and does not generalize well to dynamic changes in the environment. Our work introduces a novel approach to solve the camera relocalization problem by using the available triangle mesh. Our 3D-3D matching framework consists of three blocks: (1) a graph neural network to compute the embedding of mesh vertices, (2) a convolution neural network to compute the embedding of grid cells defined on the RGB-D image, and (3) a neural network model to establish the correspondence between the two embeddings. These three components are trained end-to-end. To predict the final pose, we run the RANSAC algorithm to generate camera pose hypotheses, and we refine the prediction using the point-cloud representation. Our approach significantly improves the camera pose accuracy of the state-of-the-art method from $0.358$ to $0.506$ on the RIO10 benchmark for dynamic indoor camera relocalization.
Video super-resolution for single-photon LIDAR
Oct 19, 2022
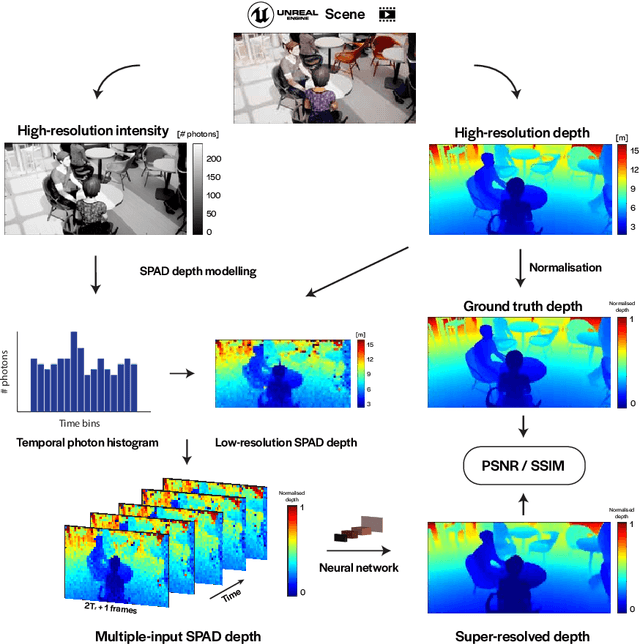
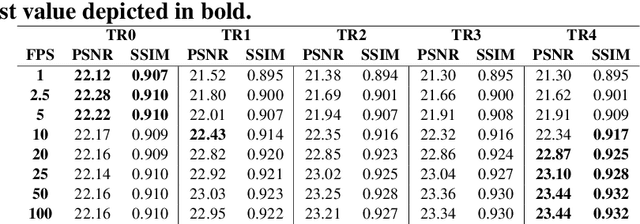
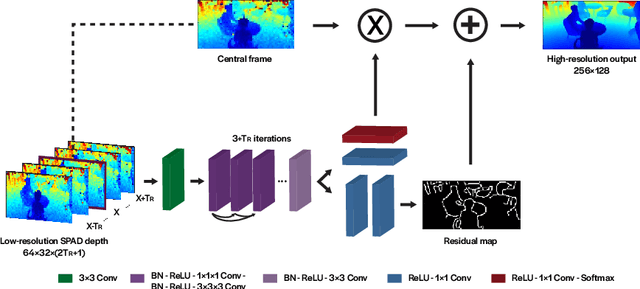
3D Time-of-Flight (ToF) image sensors are used widely in applications such as self-driving cars, Augmented Reality (AR) and robotics. When implemented with Single-Photon Avalanche Diodes (SPADs), compact, array format sensors can be made that offer accurate depth maps over long distances, without the need for mechanical scanning. However, array sizes tend to be small, leading to low lateral resolution, which combined with low Signal-to-Noise Ratio (SNR) levels under high ambient illumination, may lead to difficulties in scene interpretation. In this paper, we use synthetic depth sequences to train a 3D Convolutional Neural Network (CNN) for denoising and upscaling (x4) depth data. Experimental results, based on synthetic as well as real ToF data, are used to demonstrate the effectiveness of the scheme. With GPU acceleration, frames are processed at >30 frames per second, making the approach suitable for low-latency imaging, as required for obstacle avoidance.
VTC: Improving Video-Text Retrieval with User Comments
Oct 19, 2022
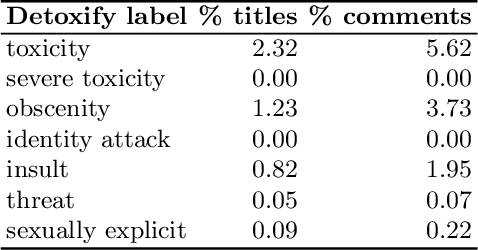
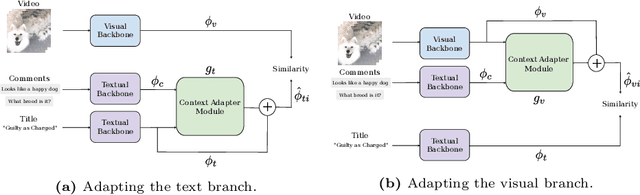
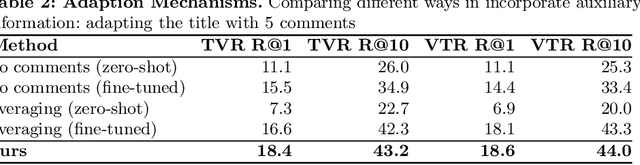
Multi-modal retrieval is an important problem for many applications, such as recommendation and search. Current benchmarks and even datasets are often manually constructed and consist of mostly clean samples where all modalities are well-correlated with the content. Thus, current video-text retrieval literature largely focuses on video titles or audio transcripts, while ignoring user comments, since users often tend to discuss topics only vaguely related to the video. Despite the ubiquity of user comments online, there is currently no multi-modal representation learning datasets that includes comments. In this paper, we a) introduce a new dataset of videos, titles and comments; b) present an attention-based mechanism that allows the model to learn from sometimes irrelevant data such as comments; c) show that by using comments, our method is able to learn better, more contextualised, representations for image, video and audio representations. Project page: https://unitaryai.github.io/vtc-paper.
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 14, 2022



Image-Text matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
Transfer Learning Application of Self-supervised Learning in ARPES
Aug 23, 2022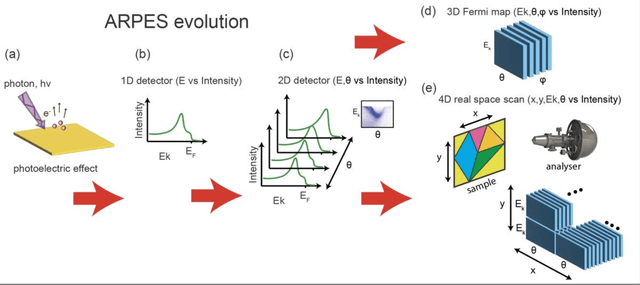
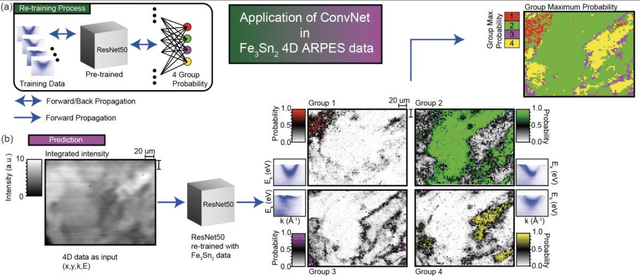
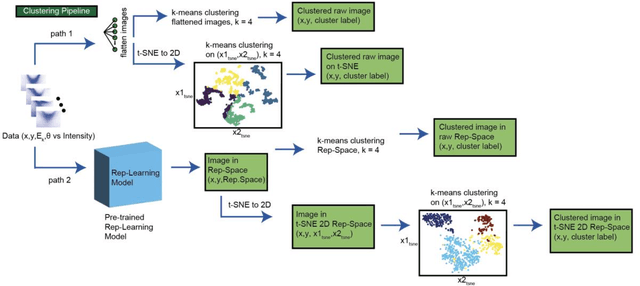
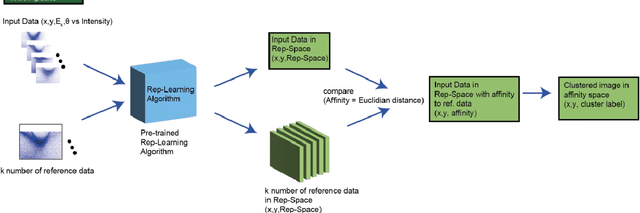
Recent development in angle-resolved photoemission spectroscopy (ARPES) technique involves spatially resolving samples while maintaining the high-resolution feature of momentum space. This development easily expands the data size and its complexity for data analysis, where one of it is to label similar dispersion cuts and map them spatially. In this work, we demonstrate that the recent development in representational learning (self-supervised learning) model combined with k-means clustering can help automate that part of data analysis and save precious time, albeit with low performance. Finally, we introduce a few-shot learning (k-nearest neighbour or kNN) in representational space where we selectively choose one (k=1) image reference for each known label and subsequently label the rest of the data with respect to the nearest reference image. This last approach demonstrates the strength of the self-supervised learning to automate the image analysis in ARPES in particular and can be generalized into any science data analysis that heavily involves image data.
Cross-Image Relational Knowledge Distillation for Semantic Segmentation
Apr 14, 2022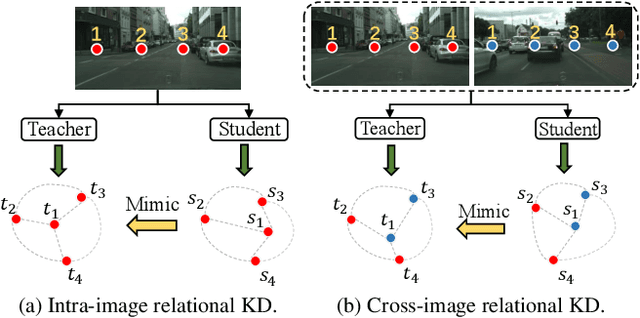
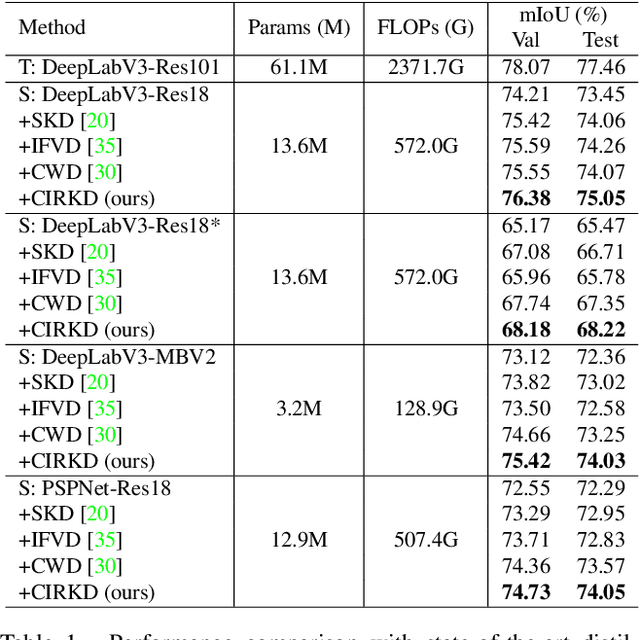
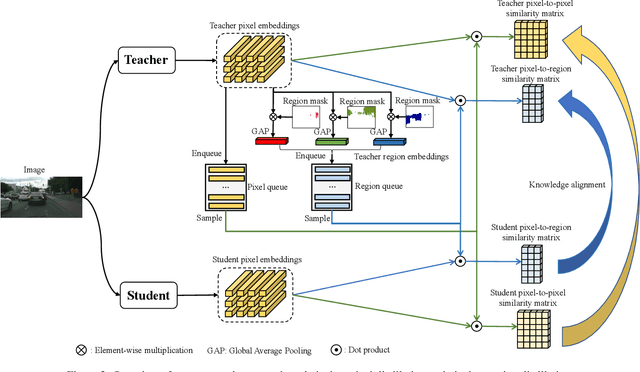
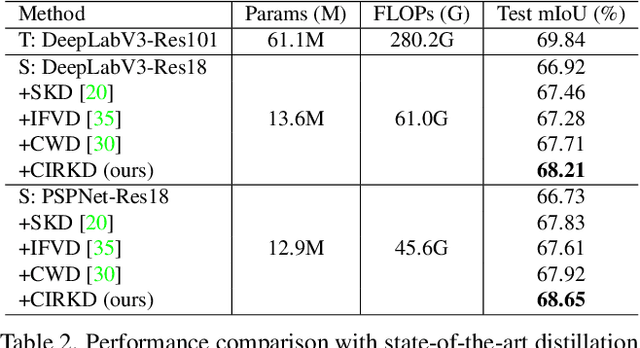
Current Knowledge Distillation (KD) methods for semantic segmentation often guide the student to mimic the teacher's structured information generated from individual data samples. However, they ignore the global semantic relations among pixels across various images that are valuable for KD. This paper proposes a novel Cross-Image Relational KD (CIRKD), which focuses on transferring structured pixel-to-pixel and pixel-to-region relations among the whole images. The motivation is that a good teacher network could construct a well-structured feature space in terms of global pixel dependencies. CIRKD makes the student mimic better structured semantic relations from the teacher, thus improving the segmentation performance. Experimental results over Cityscapes, CamVid and Pascal VOC datasets demonstrate the effectiveness of our proposed approach against state-of-the-art distillation methods. The code is available at https://github.com/winycg/CIRKD.
Non-learning Stereo-aided Depth Completion under Mis-projection via Selective Stereo Matching
Oct 04, 2022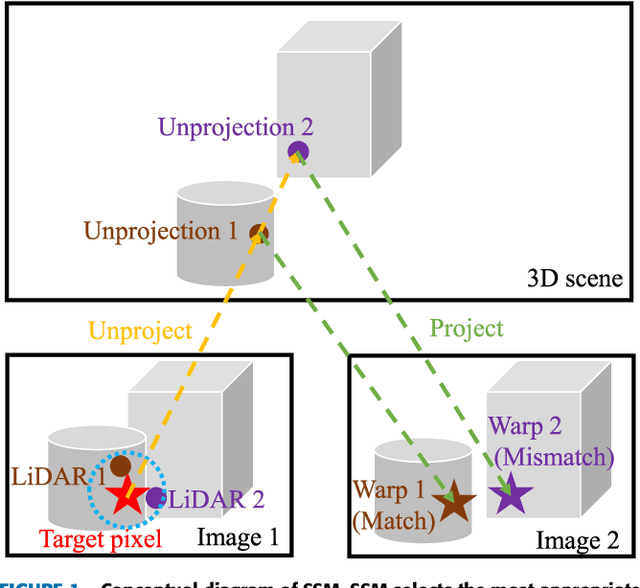
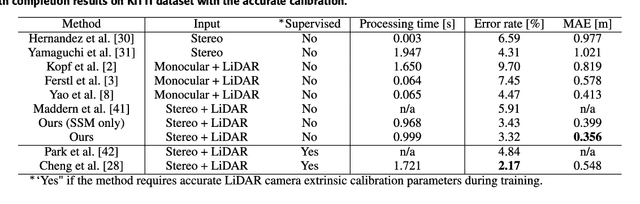
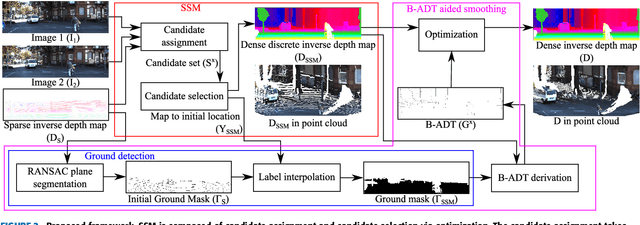

We propose a non-learning depth completion method for a sparse depth map captured using a light detection and ranging (LiDAR) sensor guided by a pair of stereo images. Generally, conventional stereo-aided depth completion methods have two limiations. (i) They assume the given sparse depth map is accurately aligned to the input image, whereas the alignment is difficult to achieve in practice. (ii) They have limited accuracy in the long range because the depth is estimated by pixel disparity. To solve the abovementioned limitations, we propose selective stereo matching (SSM) that searches the most appropriate depth value for each image pixel from its neighborly projected LiDAR points based on an energy minimization framework. This depth selection approach can handle any type of mis-projection. Moreover, SSM has an advantage in terms of long-range depth accuracy because it directly uses the LiDAR measurement rather than the depth acquired from the stereo. SSM is a discrete process; thus, we apply variational smoothing with binary anisotropic diffusion tensor (B-ADT) to generate a continuous depth map while preserving depth discontinuity across object boundaries. Experimentally, compared with the previous state-of-the-art stereo-aided depth completion, the proposed method reduced the mean absolute error (MAE) of the depth estimation to 0.65 times and demonstrated approximately twice more accurate estimation in the long range. Moreover, under various LiDAR-camera calibration errors, the proposed method reduced the depth estimation MAE to 0.34-0.93 times from previous depth completion methods.
* 15 pages, 13 figures