 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving trajectory calculations using deep learning inspired single image superresolution
Jun 07, 2022
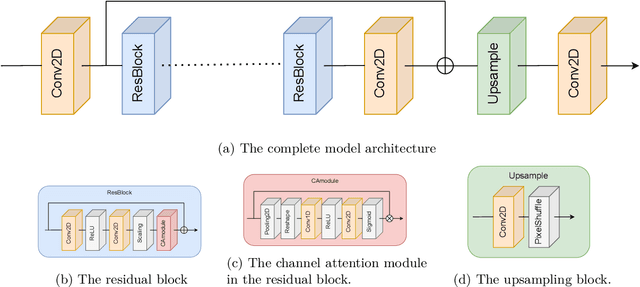


Lagrangian trajectory or particle dispersion models as well as semi-Lagrangian advection schemes require meteorological data such as wind, temperature and geopotential at the exact spatio-temporal locations of the particles that move independently from a regular grid. Traditionally, this high-resolution data has been obtained by interpolating the meteorological parameters from the gridded data of a meteorological model or reanalysis, e.g. using linear interpolation in space and time. However, interpolation errors are a large source of error for these models. Reducing them requires meteorological input fields with high space and time resolution, which may not always be available and can cause severe data storage and transfer problems. Here, we interpret this problem as a single image superresolution task. We interpret meteorological fields available at their native resolution as low-resolution images and train deep neural networks to up-scale them to higher resolution, thereby providing more accurate data for Lagrangian models. We train various versions of the state-of-the-art Enhanced Deep Residual Networks for Superresolution on low-resolution ERA5 reanalysis data with the goal to up-scale these data to arbitrary spatial resolution. We show that the resulting up-scaled wind fields have root-mean-squared errors half the size of the winds obtained with linear spatial interpolation at acceptable computational inference costs. In a test setup using the Lagrangian particle dispersion model FLEXPART and reduced-resolution wind fields, we demonstrate that absolute horizontal transport deviations of calculated trajectories from "ground-truth" trajectories calculated with undegraded 0.5{\deg} winds are reduced by at least 49.5% (21.8%) after 48 hours relative to trajectories using linear interpolation of the wind data when training on 2{\deg} to 1{\deg} (4{\deg} to 2{\deg}) resolution data.
NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations
May 09, 2022

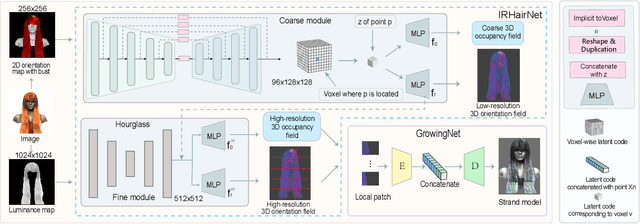

Undoubtedly, high-fidelity 3D hair plays an indispensable role in digital humans. However, existing monocular hair modeling methods are either tricky to deploy in digital systems (e.g., due to their dependence on complex user interactions or large databases) or can produce only a coarse geometry. In this paper, we introduce NeuralHDHair, a flexible, fully automatic system for modeling high-fidelity hair from a single image. The key enablers of our system are two carefully designed neural networks: an IRHairNet (Implicit representation for hair using neural network) for inferring high-fidelity 3D hair geometric features (3D orientation field and 3D occupancy field) hierarchically and a GrowingNet(Growing hair strands using neural network) to efficiently generate 3D hair strands in parallel. Specifically, we perform a coarse-to-fine manner and propose a novel voxel-aligned implicit function (VIFu) to represent the global hair feature, which is further enhanced by the local details extracted from a hair luminance map. To improve the efficiency of a traditional hair growth algorithm, we adopt a local neural implicit function to grow strands based on the estimated 3D hair geometric features. Extensive experiments show that our method is capable of constructing a high-fidelity 3D hair model from a single image, both efficiently and effectively, and achieves the-state-of-the-art performance.
Noise-reducing attention cross fusion learning transformer for histological image classification of osteosarcoma
Apr 29, 2022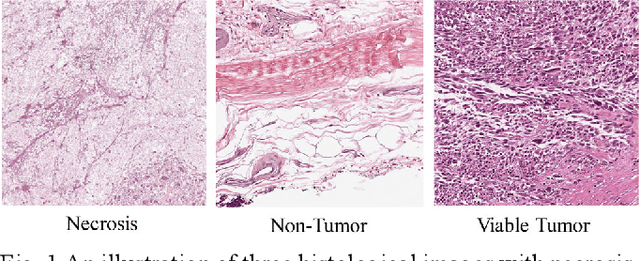
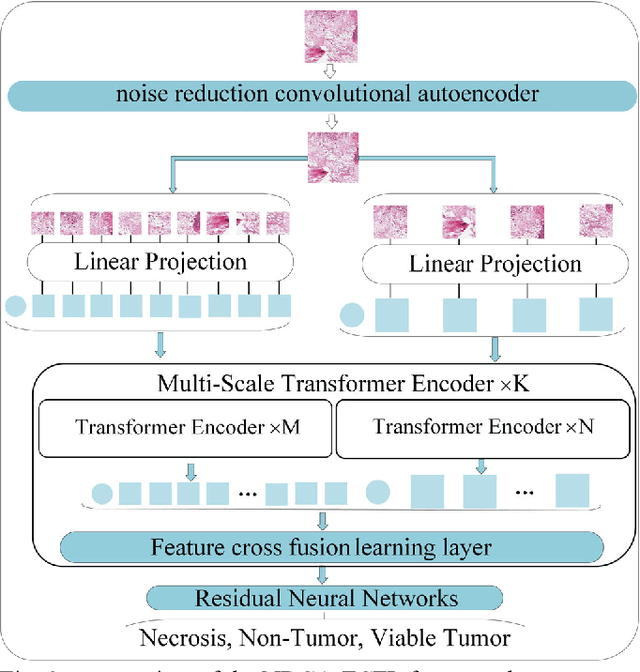
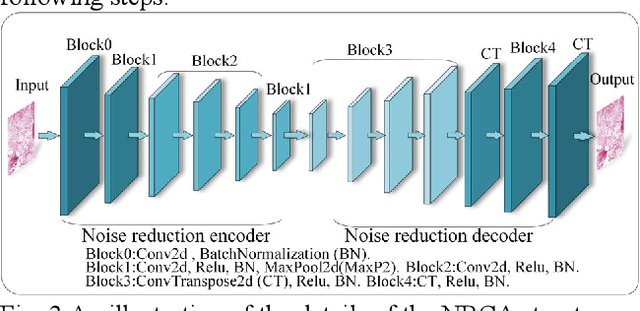
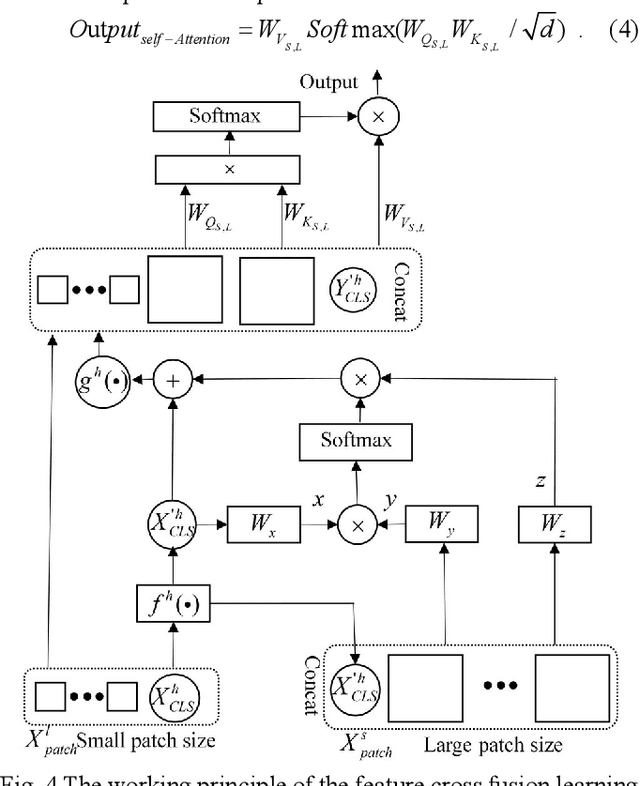
The degree of malignancy of osteosarcoma and its tendency to metastasize/spread mainly depend on the pathological grade (determined by observing the morphology of the tumor under a microscope). The purpose of this study is to use artificial intelligence to classify osteosarcoma histological images and to assess tumor survival and necrosis, which will help doctors reduce their workload, improve the accuracy of osteosarcoma cancer detection, and make a better prognosis for patients. The study proposes a typical transformer image classification framework by integrating noise reduction convolutional autoencoder and feature cross fusion learning (NRCA-FCFL) to classify osteosarcoma histological images. Noise reduction convolutional autoencoder could well denoise histological images of osteosarcoma, resulting in more pure images for osteosarcoma classification. Moreover, we introduce feature cross fusion learning, which integrates two scale image patches, to sufficiently explore their interactions by using additional classification tokens. As a result, a refined fusion feature is generated, which is fed to the residual neural network for label predictions. We conduct extensive experiments to evaluate the performance of the proposed approach. The experimental results demonstrate that our method outperforms the traditional and deep learning approaches on various evaluation metrics, with an accuracy of 99.17% to support osteosarcoma diagnosis.
StylePart: Image-based Shape Part Manipulation
Nov 20, 2021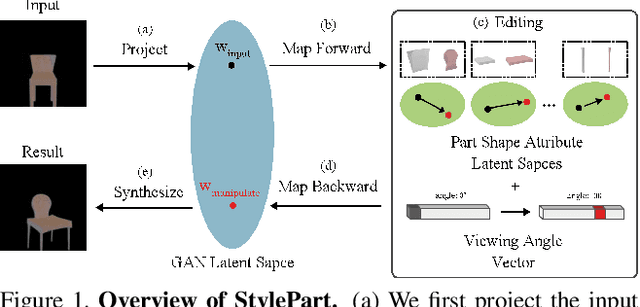
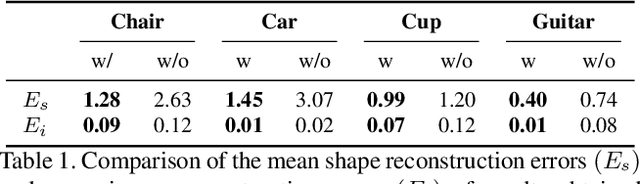
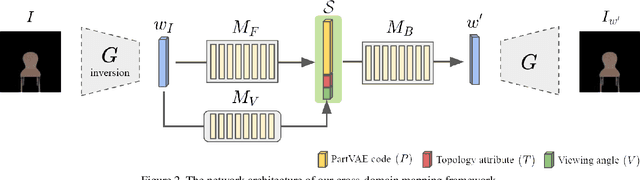

Due to a lack of image-based "part controllers", shape manipulation of man-made shape images, such as resizing the backrest of a chair or replacing a cup handle is not intuitive because of the lack of image-based part controllers. To tackle this problem, we present StylePart, a framework that enables direct shape manipulation of an image by leveraging generative models of both images and 3D shapes. Our key contribution is a shape-consistent latent mapping function that connects the image generative latent space and the 3D man-made shape attribute latent space. Our method "forwardly maps" the image content to its corresponding 3D shape attributes, where the shape part can be easily manipulated. The attribute codes of the manipulated 3D shape are then "backwardly mapped" to the image latent code to obtain the final manipulated image. We demonstrate our approach through various manipulation tasks, including part replacement, part resizing, and viewpoint manipulation, and evaluate its effectiveness through extensive ablation studies.
Design of the topology for contrastive visual-textual alignment
Sep 05, 2022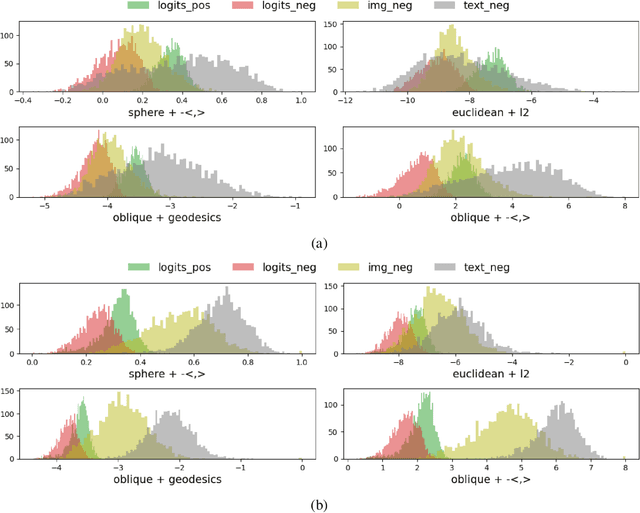
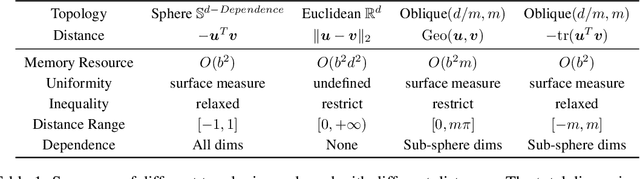
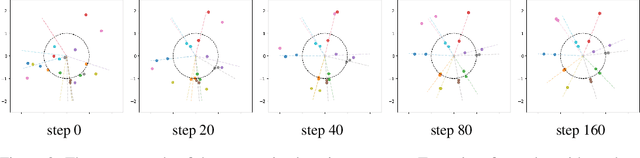
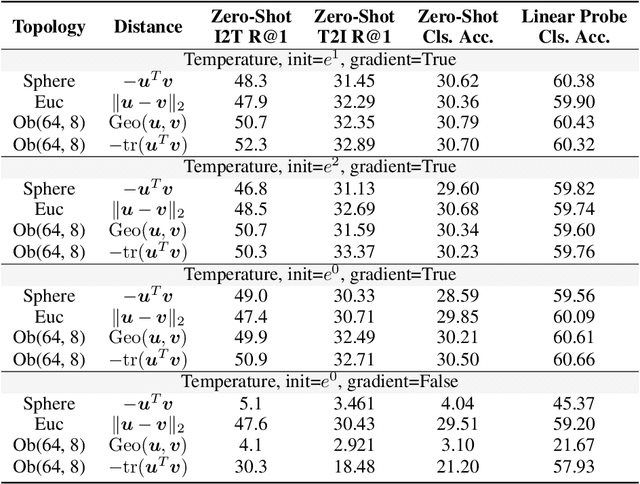
Pre-training weakly related image-text pairs in the contrastive style shows great power in learning semantic aligning cross-modal models. The common choice to measure the distance between the feature representations of the image-text pairs is the cosine similarity, which can be considered as the negative inner product of features embedded on a sphere mathematically. While such topology benefits from the low computational resources consumption and a properly defined uniformity, typically, there are two major drawbacks when applied. First, it is vulnerable to the semantic ambiguity phenomenon resulting from the noise in the weakly-related image-text pairs. Second, the learning progress is unstable and fragile at the beginning. Although, in the practice of former studies, a learnable softmax temperature parameter and a long warmup scheme are employed to meliorate the training progress, still there lacks an in-depth analysis of these problems. In this work, we discuss the desired properties of the topology and its endowed distance function for the embedding vectors of feature representations from the view of optimization. We then propose a rather simple solution to improve the aforementioned problem. That is, we map the feature representations onto the oblique manifold endowed with the negative inner product as the distance function. In the experimental analysis, we show that we can improve the baseline performance by a large margin (e.g. 4% in the zero-shot image to text retrieval task) by changing only two lines of the training codes.
Routine Usage of AI-based Chest X-ray Reading Support in a Multi-site Medical Supply Center
Oct 17, 2022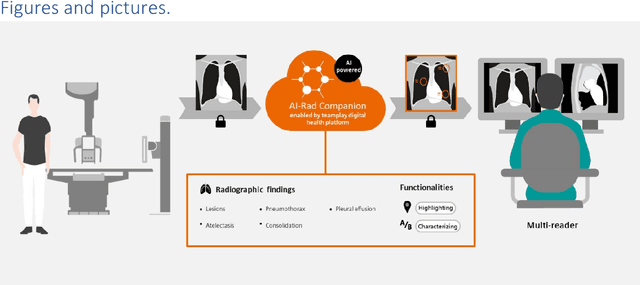
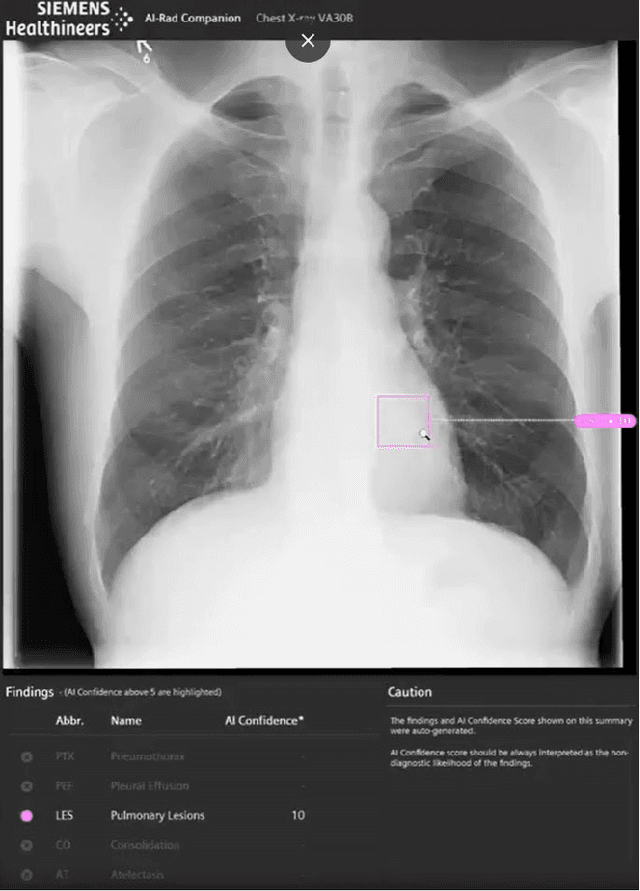
Research question: How can we establish an AI support for reading of chest X-rays in clinical routine and which benefits emerge for the clinicians and radiologists. Can it perform 24/7 support for practicing clinicians? 2. Findings: We installed an AI solution for Chest X-ray in a given structure (MVZ Uhlenbrock & Partner, Germany). We could demonstrate the practicability, performance, and benefits in 10 connected clinical sites. 3. Meaning: A commercially available AI solution for the evaluation of Chest X-ray images is able to help radiologists and clinical colleagues 24/7 in a complex environment. The system performs in a robust manner, supporting radiologists and clinical colleagues in their important decisions, in practises and hospitals regardless of the user and X-ray system type producing the image-data.
Wiener Guided DIP for Unsupervised Blind Image Deconvolution
Dec 19, 2021
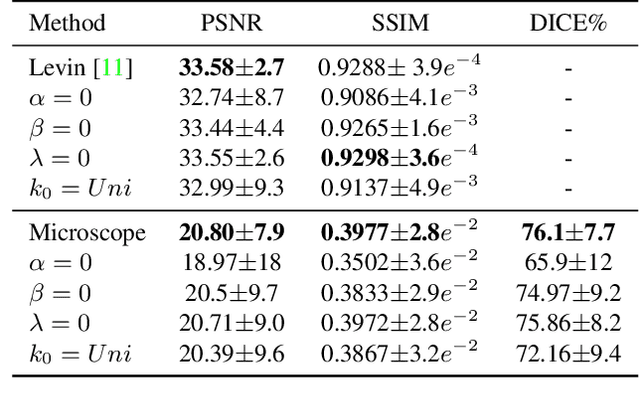

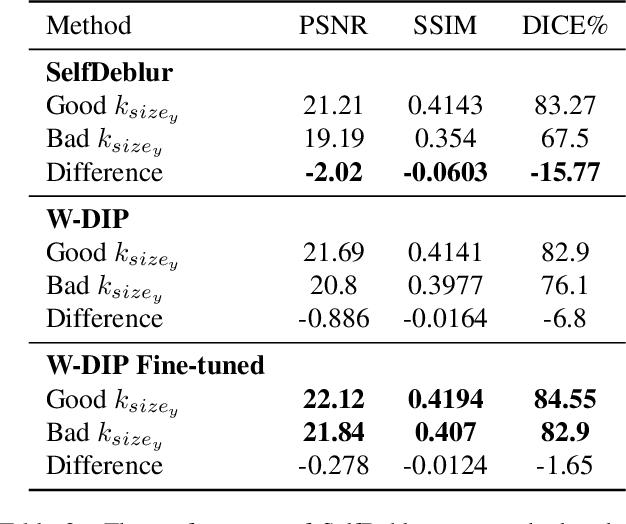
Blind deconvolution is an ill-posed problem arising in various fields ranging from microscopy to astronomy. The ill-posed nature of the problem requires adequate priors to arrive to a desirable solution. Recently, it has been shown that deep learning architectures can serve as an image generation prior during unsupervised blind deconvolution optimization, however often exhibiting a performance fluctuation even on a single image. We propose to use Wiener-deconvolution to guide the image generator during optimization by providing it a sharpened version of the blurry image using an auxiliary kernel estimate starting from a Gaussian. We observe that the high-frequency artifacts of deconvolution are reproduced with a delay compared to low-frequency features. In addition, the image generator reproduces low-frequency features of the deconvolved image faster than that of a blurry image. We embed the computational process in a constrained optimization framework and show that the proposed method yields higher stability and performance across multiple datasets. In addition, we provide the code.
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 14, 2022



Image-Text matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
Centerpoints Are All You Need in Overhead Imagery
Oct 04, 2022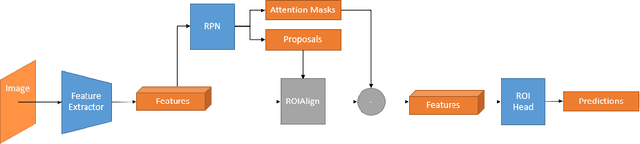
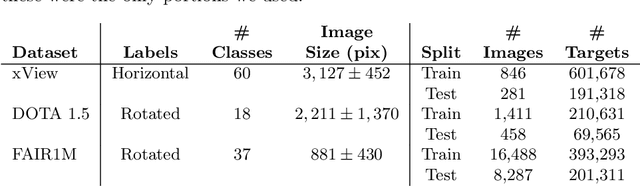

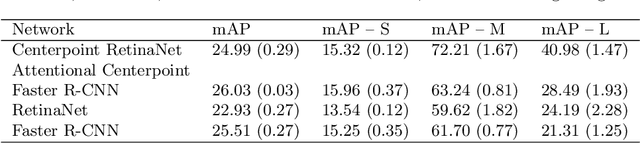
Labeling data to use for training object detectors is expensive and time consuming. Publicly available overhead datasets for object detection are labeled with image-aligned bounding boxes, object-aligned bounding boxes, or object masks, but it is not clear whether such detailed labeling is necessary. To test the idea, we developed novel single- and two-stage network architectures that use centerpoints for labeling. In this paper we show that these architectures achieve nearly equivalent performance to approaches using more detailed labeling on three overhead object detection datasets.
Cross-Image Relational Knowledge Distillation for Semantic Segmentation
Apr 14, 2022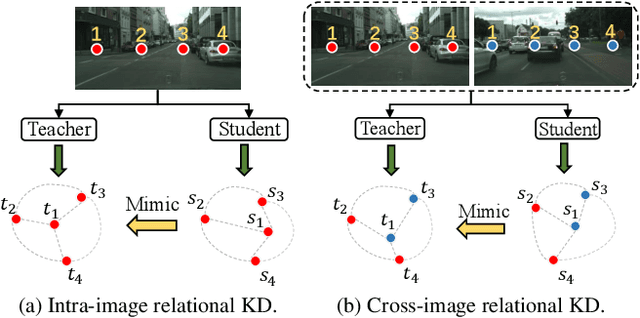
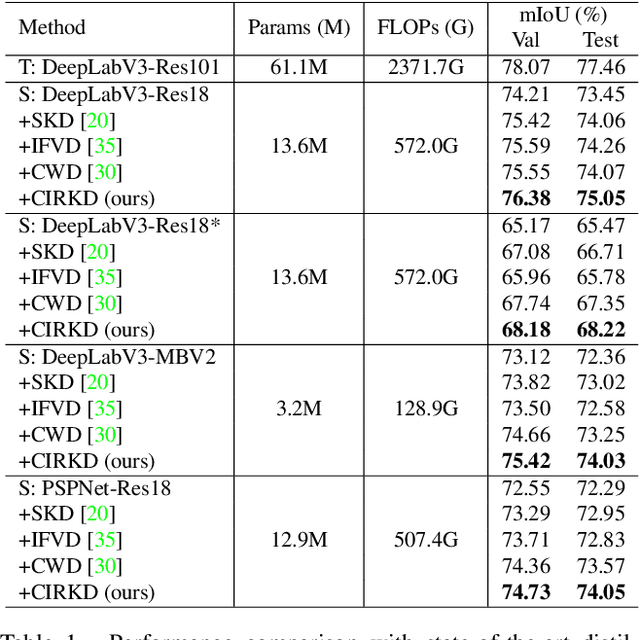
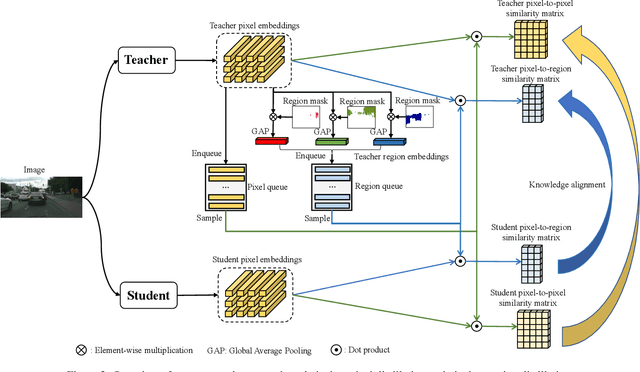
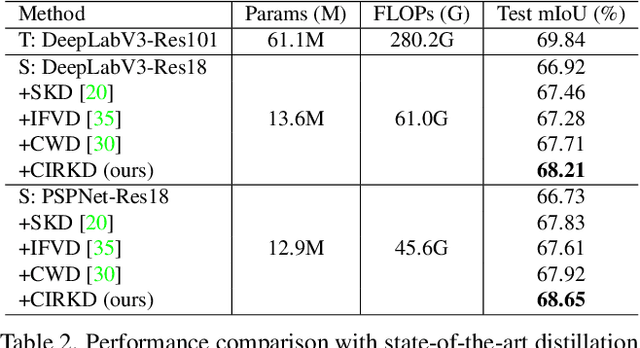
Current Knowledge Distillation (KD) methods for semantic segmentation often guide the student to mimic the teacher's structured information generated from individual data samples. However, they ignore the global semantic relations among pixels across various images that are valuable for KD. This paper proposes a novel Cross-Image Relational KD (CIRKD), which focuses on transferring structured pixel-to-pixel and pixel-to-region relations among the whole images. The motivation is that a good teacher network could construct a well-structured feature space in terms of global pixel dependencies. CIRKD makes the student mimic better structured semantic relations from the teacher, thus improving the segmentation performance. Experimental results over Cityscapes, CamVid and Pascal VOC datasets demonstrate the effectiveness of our proposed approach against state-of-the-art distillation methods. The code is available at https://github.com/winycg/CIRKD.