 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic-shape Adaptive Feature Modulation for Semantic Image Synthesis
Mar 31, 2022
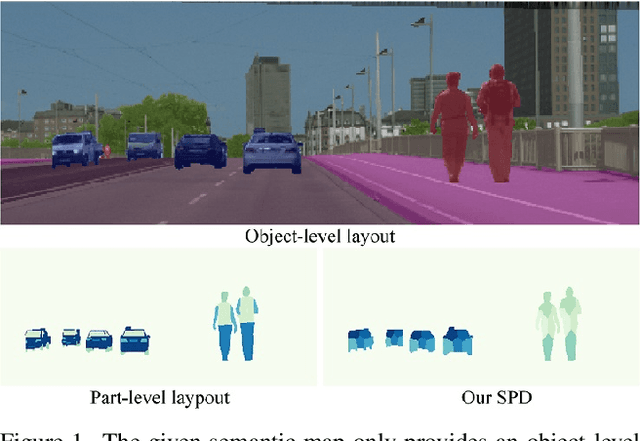
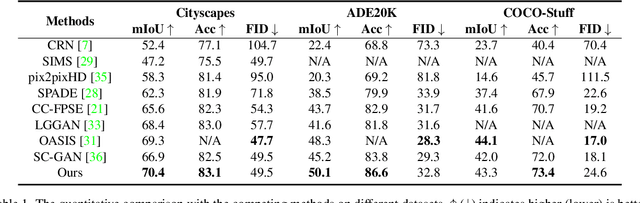
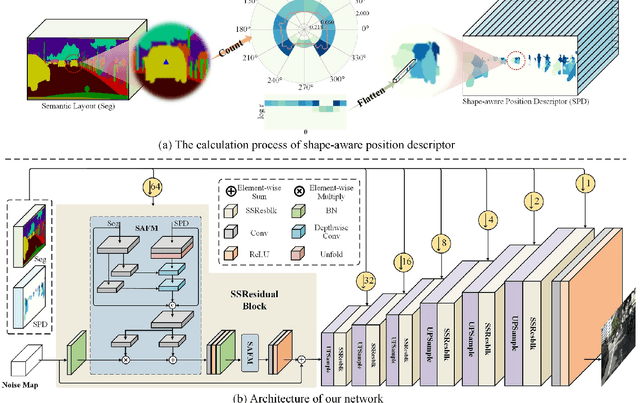
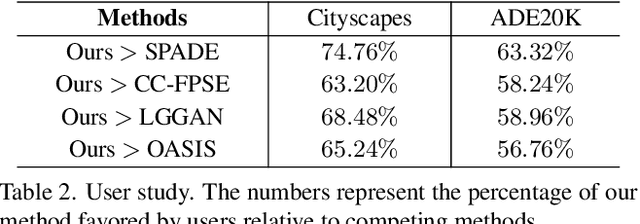
Recent years have witnessed substantial progress in semantic image synthesis, it is still challenging in synthesizing photo-realistic images with rich details. Most previous methods focus on exploiting the given semantic map, which just captures an object-level layout for an image. Obviously, a fine-grained part-level semantic layout will benefit object details generation, and it can be roughly inferred from an object's shape. In order to exploit the part-level layouts, we propose a Shape-aware Position Descriptor (SPD) to describe each pixel's positional feature, where object shape is explicitly encoded into the SPD feature. Furthermore, a Semantic-shape Adaptive Feature Modulation (SAFM) block is proposed to combine the given semantic map and our positional features to produce adaptively modulated features. Extensive experiments demonstrate that the proposed SPD and SAFM significantly improve the generation of objects with rich details. Moreover, our method performs favorably against the SOTA methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SAFM.
Blueprint Separable Residual Network for Efficient Image Super-Resolution
May 12, 2022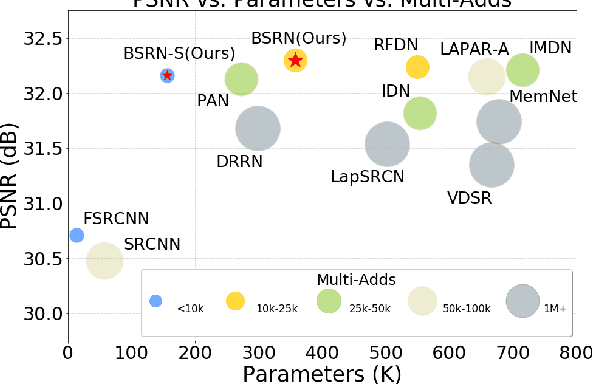



Recent advances in single image super-resolution (SISR) have achieved extraordinary performance, but the computational cost is too heavy to apply in edge devices. To alleviate this problem, many novel and effective solutions have been proposed. Convolutional neural network (CNN) with the attention mechanism has attracted increasing attention due to its efficiency and effectiveness. However, there is still redundancy in the convolution operation. In this paper, we propose Blueprint Separable Residual Network (BSRN) containing two efficient designs. One is the usage of blueprint separable convolution (BSConv), which takes place of the redundant convolution operation. The other is to enhance the model ability by introducing more effective attention modules. The experimental results show that BSRN achieves state-of-the-art performance among existing efficient SR methods. Moreover, a smaller variant of our model BSRN-S won the first place in model complexity track of NTIRE 2022 Efficient SR Challenge. The code is available at https://github.com/xiaom233/BSRN.
Compressive Ptychography using Deep Image and Generative Priors
May 16, 2022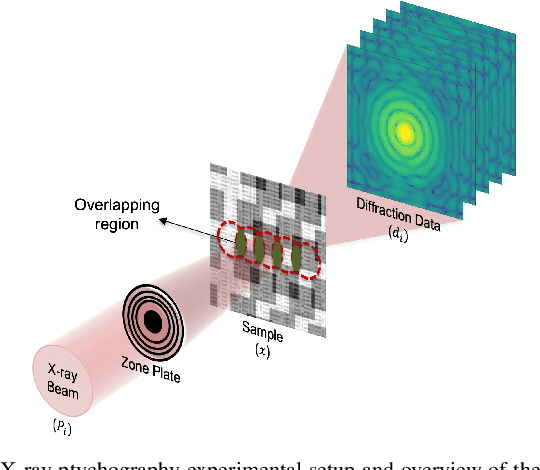


Ptychography is a well-established coherent diffraction imaging technique that enables non-invasive imaging of samples at a nanometer scale. It has been extensively used in various areas such as the defense industry or materials science. One major limitation of ptychography is the long data acquisition time due to mechanical scanning of the sample; therefore, approaches to reduce the scan points are highly desired. However, reconstructions with less number of scan points lead to imaging artifacts and significant distortions, hindering a quantitative evaluation of the results. To address this bottleneck, we propose a generative model combining deep image priors with deep generative priors. The self-training approach optimizes the deep generative neural network to create a solution for a given dataset. We complement our approach with a prior acquired from a previously trained discriminator network to avoid a possible divergence from the desired output caused by the noise in the measurements. We also suggest using the total variation as a complementary before combat artifacts due to measurement noise. We analyze our approach with numerical experiments through different probe overlap percentages and varying noise levels. We also demonstrate improved reconstruction accuracy compared to the state-of-the-art method and discuss the advantages and disadvantages of our approach.
Audio Time-Scale Modification with Temporal Compressing Networks
Oct 31, 2022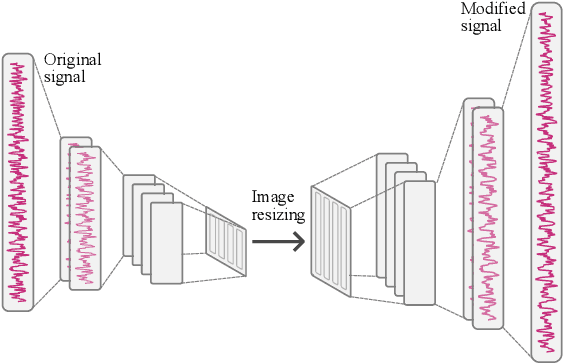
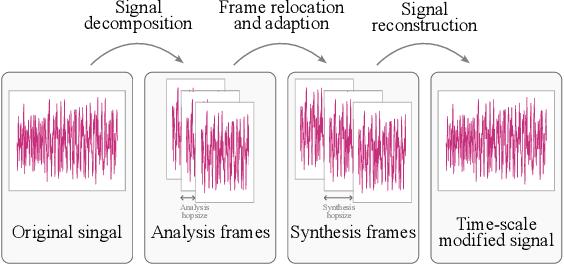
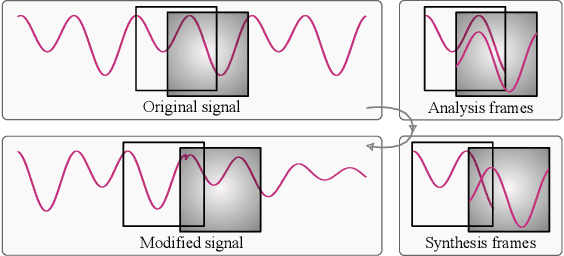
We proposed a novel approach in the field of time-scale modification on audio signals. While traditional methods use the framing technique, spectral approach uses the short-time Fourier transform to preserve the frequency during temporal stretching. TSM-Net, our neural-network model encodes the raw audio into a high-level latent representation. We call it Neuralgram, in which one vector represents 1024 audio samples. It is inspired by the framing technique but addresses the clipping artifacts. The Neuralgram is a two-dimensional matrix with real values, we can apply some existing image resizing techniques on the Neuralgram and decode it using our neural decoder to obtain the time-scaled audio. Both the encoder and decoder are trained with GANs, which shows fair generalization ability on the scaled Neuralgrams. Our method yields little artifacts and opens a new possibility in the research of modern time-scale modification. The audio samples can be found on https://ernestchu.github.io/tsm-net-demo/
Prompt-Based Multi-Modal Image Segmentation
Dec 18, 2021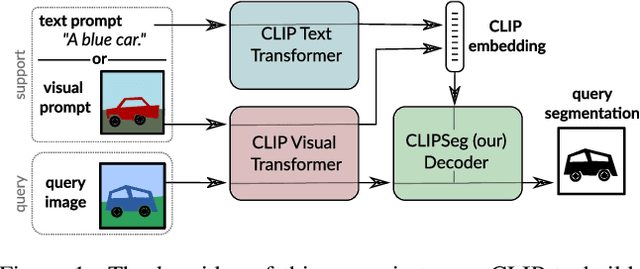

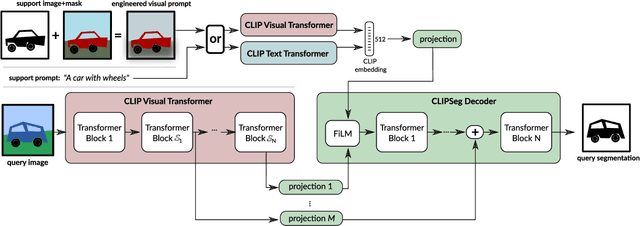

Image segmentation is usually addressed by training a model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system that can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text or an image. This approach enables us to create a unified model (trained once) for three common segmentation tasks, which come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation. We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense prediction. After training on an extended version of the PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on an additional image expressing the query. Different variants of the latter image-based prompts are analyzed in detail. This novel hybrid input allows for dynamic adaptation not only to the three segmentation tasks mentioned above, but to any binary segmentation task where a text or image query can be formulated. Finally, we find our system to adapt well to generalized queries involving affordances or properties. Source code: https://eckerlab.org/code/clipseg
Learning-based Inverse Rendering of Complex Indoor Scenes with Differentiable Monte Carlo Raytracing
Nov 06, 2022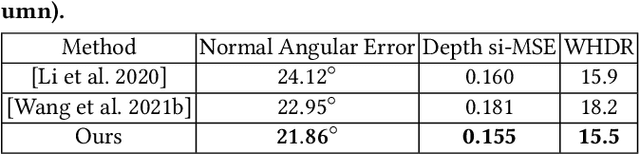

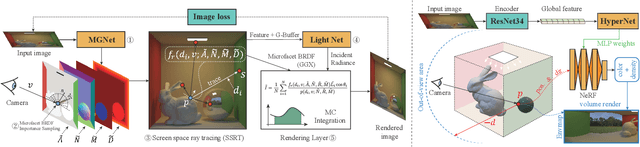

Indoor scenes typically exhibit complex, spatially-varying appearance from global illumination, making inverse rendering a challenging ill-posed problem. This work presents an end-to-end, learning-based inverse rendering framework incorporating differentiable Monte Carlo raytracing with importance sampling. The framework takes a single image as input to jointly recover the underlying geometry, spatially-varying lighting, and photorealistic materials. Specifically, we introduce a physically-based differentiable rendering layer with screen-space ray tracing, resulting in more realistic specular reflections that match the input photo. In addition, we create a large-scale, photorealistic indoor scene dataset with significantly richer details like complex furniture and dedicated decorations. Further, we design a novel out-of-view lighting network with uncertainty-aware refinement leveraging hypernetwork-based neural radiance fields to predict lighting outside the view of the input photo. Through extensive evaluations on common benchmark datasets, we demonstrate superior inverse rendering quality of our method compared to state-of-the-art baselines, enabling various applications such as complex object insertion and material editing with high fidelity. Code and data will be made available at \url{https://jingsenzhu.github.io/invrend}.
Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest
Sep 13, 2022

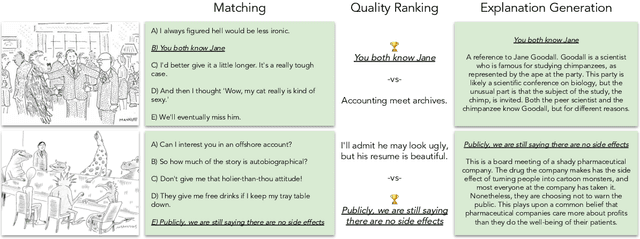
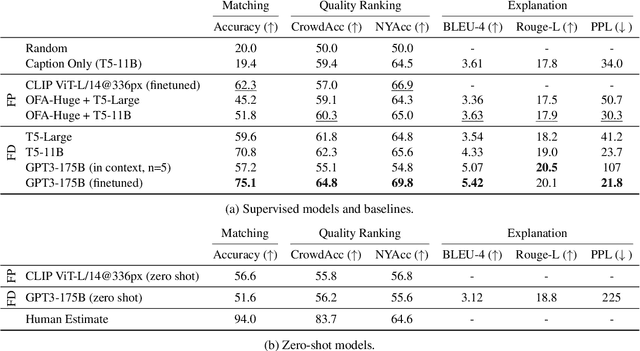
We challenge AI models to "demonstrate understanding" of the sophisticated multimodal humor of The New Yorker Caption Contest. Concretely, we develop three carefully circumscribed tasks for which it suffices (but is not necessary) to grasp potentially complex and unexpected relationships between image and caption, and similarly complex and unexpected allusions to the wide varieties of human experience; these are the hallmarks of a New Yorker-caliber cartoon. We investigate vision-and-language models that take as input the cartoon pixels and caption directly, as well as language-only models for which we circumvent image-processing by providing textual descriptions of the image. Even with the rich multifaceted annotations we provide for the cartoon images, we identify performance gaps between high-quality machine learning models (e.g., a fine-tuned, 175B parameter language model) and humans. We publicly release our corpora including annotations describing the image's locations/entities, what's unusual about the scene, and an explanation of the joke.
Intensity Image-based LiDAR Fiducial Marker System
Mar 03, 2022
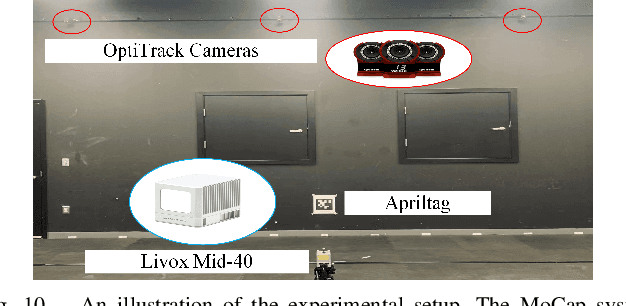
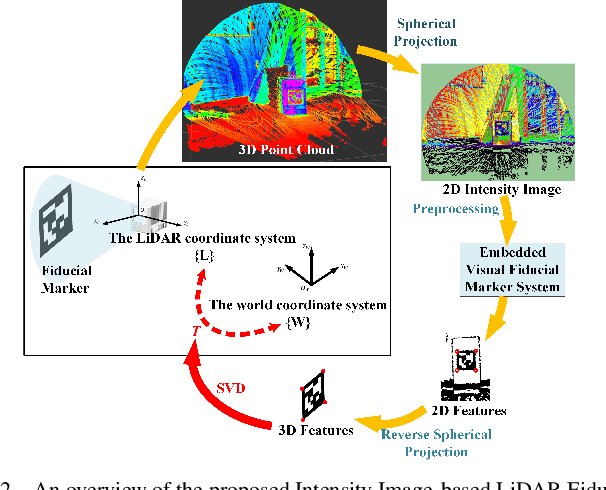
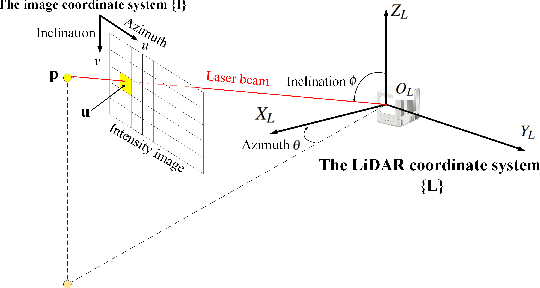
The fiducial marker system for LiDAR is crucial for the robotic application but it is still rare to date. In this paper, an Intensity Image-based LiDAR Fiducial Marker (IILFM) system is developed. This system only requires an unstructured point cloud with intensity as the input and it has no restriction on marker placement and shape. A marker detection method that locates the predefined 3D fiducials in the point cloud through the intensity image is introduced. Then, an approach that utilizes the detected 3D fiducials to estimate the LiDAR 6-DOF pose that describes the transmission from the world coordinate system to the LiDAR coordinate system is developed. Moreover, all these processes run in real-time (approx 40 Hz on Livox Mid-40 and approx 143 Hz on VLP-16). Qualitative and quantitative experiments are conducted to demonstrate that the proposed system has similar convenience and accuracy as the conventional visual fiducial marker system. The codes and results are available at: https://github.com/York-SDCNLab/IILFM.
Large Scale Real-World Multi-Person Tracking
Nov 03, 2022
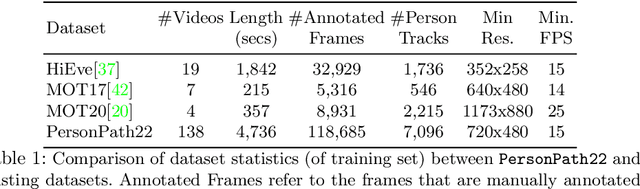
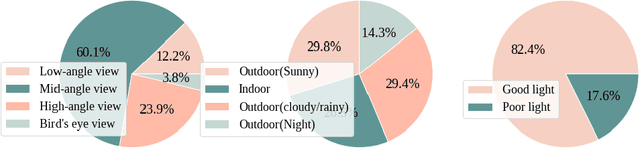
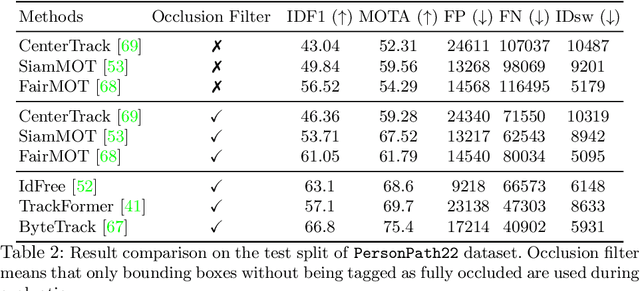
This paper presents a new large scale multi-person tracking dataset -- \texttt{PersonPath22}, which is over an order of magnitude larger than currently available high quality multi-object tracking datasets such as MOT17, HiEve, and MOT20 datasets. The lack of large scale training and test data for this task has limited the community's ability to understand the performance of their tracking systems on a wide range of scenarios and conditions such as variations in person density, actions being performed, weather, and time of day. \texttt{PersonPath22} dataset was specifically sourced to provide a wide variety of these conditions and our annotations include rich meta-data such that the performance of a tracker can be evaluated along these different dimensions. The lack of training data has also limited the ability to perform end-to-end training of tracking systems. As such, the highest performing tracking systems all rely on strong detectors trained on external image datasets. We hope that the release of this dataset will enable new lines of research that take advantage of large scale video based training data.
Sparse Image based Navigation Architecture to Mitigate the need of precise Localization in Mobile Robots
Mar 29, 2022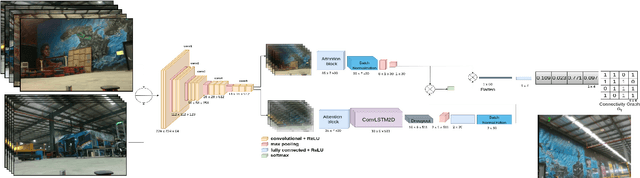
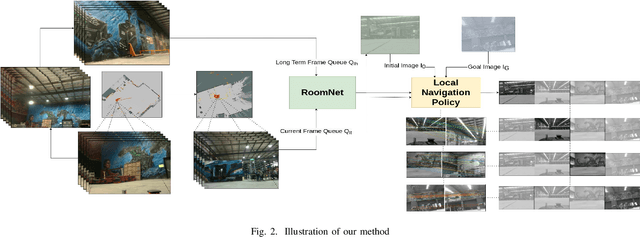


Traditional simultaneous localization and mapping (SLAM) methods focus on improvement in the robot's localization under environment and sensor uncertainty. This paper, however, focuses on mitigating the need for exact localization of a mobile robot to pursue autonomous navigation using a sparse set of images. The proposed method consists of a model architecture - RoomNet, for unsupervised learning resulting in a coarse identification of the environment and a separate local navigation policy for local identification and navigation. The former learns and predicts the scene based on the short term image sequences seen by the robot along with the transition image scenarios using long term image sequences. The latter uses sparse image matching to characterise the similarity of frames achieved vis-a-vis the frames viewed by the robot during the mapping and training stage. A sparse graph of the image sequence is created which is then used to carry out robust navigation purely on the basis of visual goals. The proposed approach is evaluated on two robots in a test environment and demonstrates the ability to navigate in dynamic environments where landmarks are obscured and classical localization methods fail.