 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
COOD: Combined out-of-distribution detection using multiple measures for anomaly & novel class detection in large-scale hierarchical classification
Mar 11, 2024
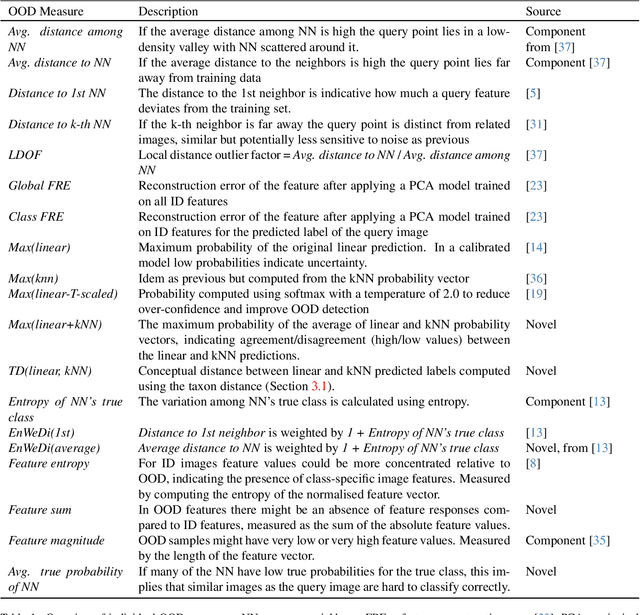
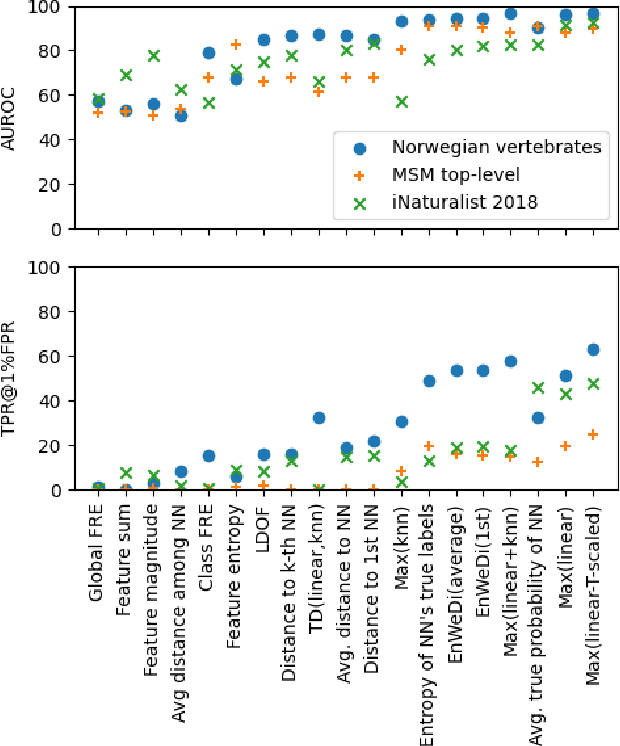

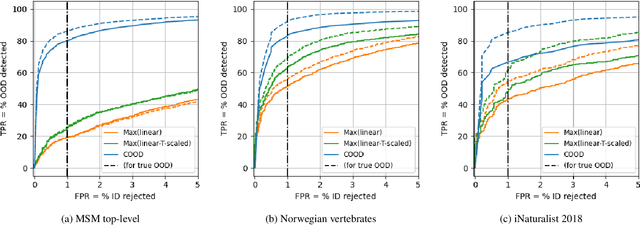
High-performing out-of-distribution (OOD) detection, both anomaly and novel class, is an important prerequisite for the practical use of classification models. In this paper, we focus on the species recognition task in images concerned with large databases, a large number of fine-grained hierarchical classes, severe class imbalance, and varying image quality. We propose a framework for combining individual OOD measures into one combined OOD (COOD) measure using a supervised model. The individual measures are several existing state-of-the-art measures and several novel OOD measures developed with novel class detection and hierarchical class structure in mind. COOD was extensively evaluated on three large-scale (500k+ images) biodiversity datasets in the context of anomaly and novel class detection. We show that COOD outperforms individual, including state-of-the-art, OOD measures by a large margin in terms of TPR@1% FPR in the majority of experiments, e.g., improving detecting ImageNet images (OOD) from 54.3% to 85.4% for the iNaturalist 2018 dataset. SHAP (feature contribution) analysis shows that different individual OOD measures are essential for various tasks, indicating that multiple OOD measures and combinations are needed to generalize. Additionally, we show that explicitly considering ID images that are incorrectly classified for the original (species) recognition task is important for constructing high-performing OOD detection methods and for practical applicability. The framework can easily be extended or adapted to other tasks and media modalities.
Towards Zero-Shot Interpretable Human Recognition: A 2D-3D Registration Framework
Mar 11, 2024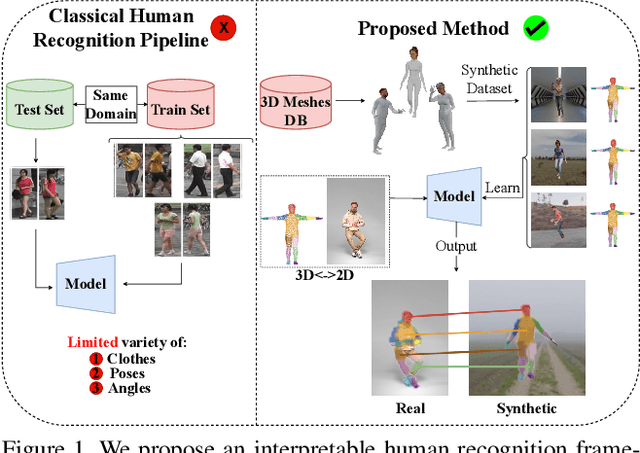
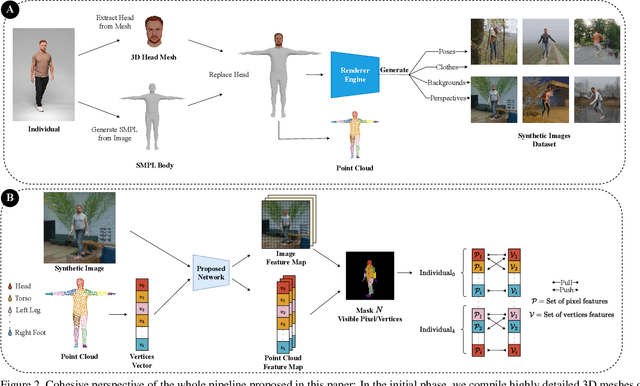
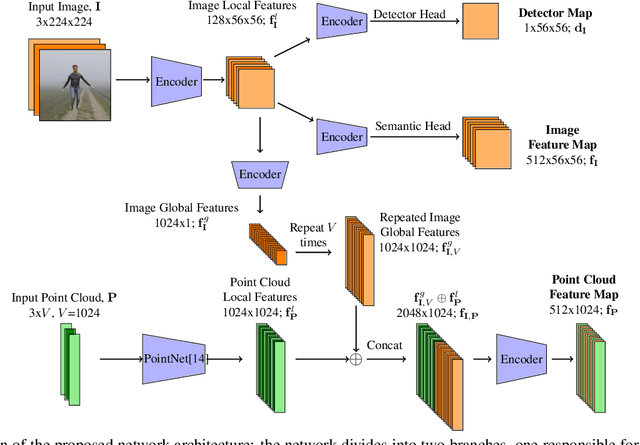

Large vision models based in deep learning architectures have been consistently advancing the state-of-the-art in biometric recognition. However, three weaknesses are commonly reported for such kind of approaches: 1) their extreme demands in terms of learning data; 2) the difficulties in generalising between different domains; and 3) the lack of interpretability/explainability, with biometrics being of particular interest, as it is important to provide evidence able to be used for forensics/legal purposes (e.g., in courts). To the best of our knowledge, this paper describes the first recognition framework/strategy that aims at addressing the three weaknesses simultaneously. At first, it relies exclusively in synthetic samples for learning purposes. Instead of requiring a large amount and variety of samples for each subject, the idea is to exclusively enroll a 3D point cloud per identity. Then, using generative strategies, we synthesize a very large (potentially infinite) number of samples, containing all the desired covariates (poses, clothing, distances, perspectives, lighting, occlusions,...). Upon the synthesizing method used, it is possible to adapt precisely to different kind of domains, which accounts for generalization purposes. Such data are then used to learn a model that performs local registration between image pairs, establishing positive correspondences between body parts that are the key, not only to recognition (according to cardinality and distribution), but also to provide an interpretable description of the response (e.g.: "both samples are from the same person, as they have similar facial shape, hair color and legs thickness").
DiPrompT: Disentangled Prompt Tuning for Multiple Latent Domain Generalization in Federated Learning
Mar 11, 2024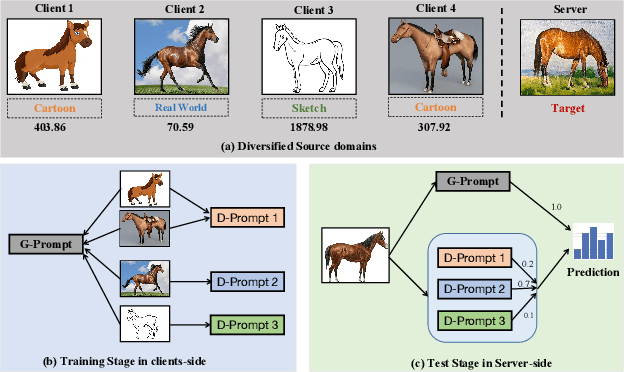
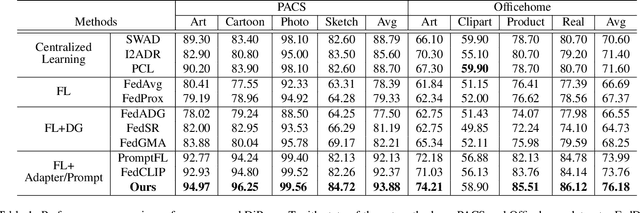
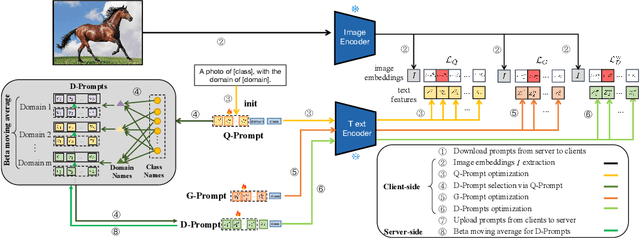
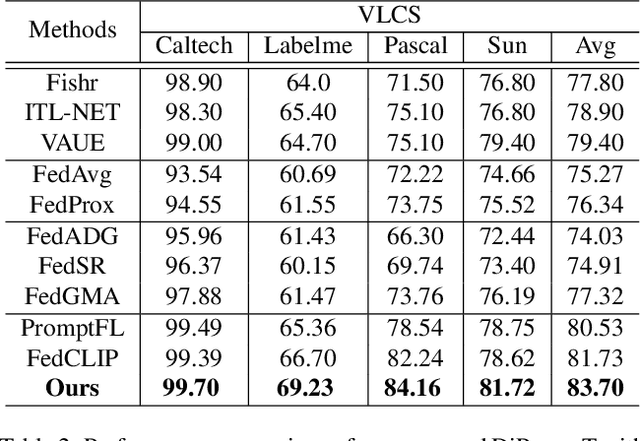
Federated learning (FL) has emerged as a powerful paradigm for learning from decentralized data, and federated domain generalization further considers the test dataset (target domain) is absent from the decentralized training data (source domains). However, most existing FL methods assume that domain labels are provided during training, and their evaluation imposes explicit constraints on the number of domains, which must strictly match the number of clients. Because of the underutilization of numerous edge devices and additional cross-client domain annotations in the real world, such restrictions may be impractical and involve potential privacy leaks. In this paper, we propose an efficient and novel approach, called Disentangled Prompt Tuning (DiPrompT), a method that tackles the above restrictions by learning adaptive prompts for domain generalization in a distributed manner. Specifically, we first design two types of prompts, i.e., global prompt to capture general knowledge across all clients and domain prompts to capture domain-specific knowledge. They eliminate the restriction on the one-to-one mapping between source domains and local clients. Furthermore, a dynamic query metric is introduced to automatically search the suitable domain label for each sample, which includes two-substep text-image alignments based on prompt tuning without labor-intensive annotation. Extensive experiments on multiple datasets demonstrate that our DiPrompT achieves superior domain generalization performance over state-of-the-art FL methods when domain labels are not provided, and even outperforms many centralized learning methods using domain labels.
Toward Robust Canine Cardiac Diagnosis: Deep Prototype Alignment Network-Based Few-Shot Segmentation in Veterinary Medicine
Mar 11, 2024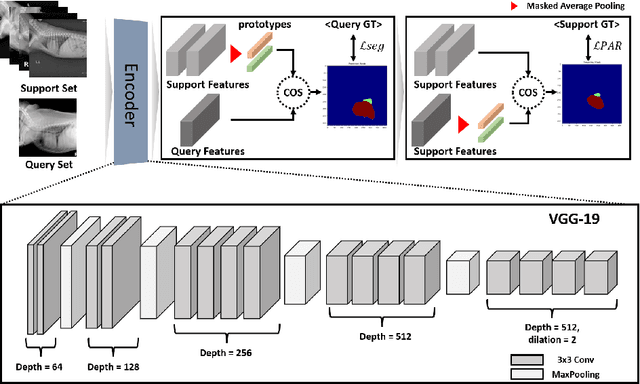
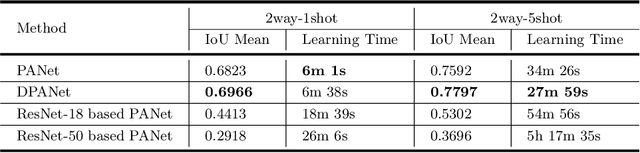
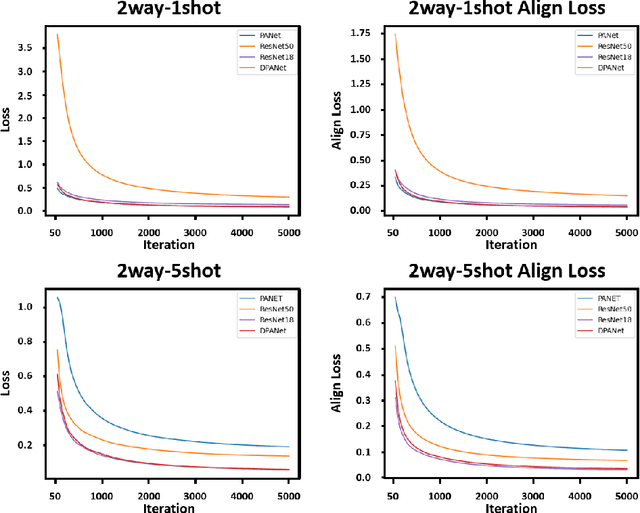
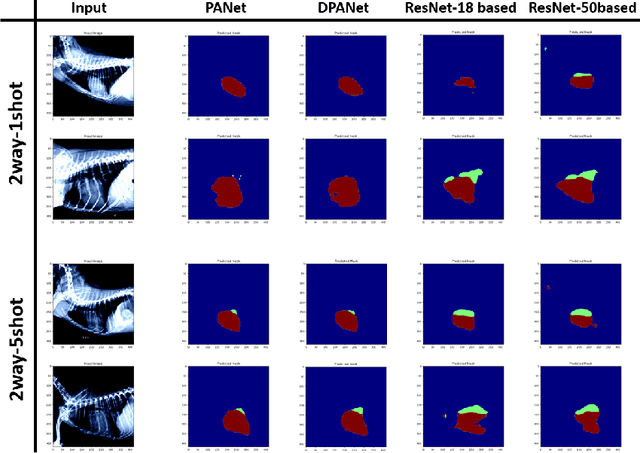
In the cutting-edge domain of medical artificial intelligence (AI), remarkable advances have been achieved in areas such as diagnosis, prediction, and therapeutic interventions. Despite these advances, the technology for image segmentation faces the significant barrier of having to produce extensively annotated datasets. To address this challenge, few-shot segmentation (FSS) has been recognized as one of the innovative solutions. Although most of the FSS research has focused on human health care, its application in veterinary medicine, particularly for pet care, remains largely limited. This study has focused on accurate segmentation of the heart and left atrial enlargement on canine chest radiographs using the proposed deep prototype alignment network (DPANet). The PANet architecture is adopted as the backbone model, and experiments are conducted using various encoders based on VGG-19, ResNet-18, and ResNet-50 to extract features. Experimental results demonstrate that the proposed DPANet achieves the highest performance. In the 2way-1shot scenario, it achieves the highest intersection over union (IoU) value of 0.6966, and in the 2way-5shot scenario, it achieves the highest IoU value of 0.797. The DPANet not only signifies a performance improvement, but also shows an improved training speed in the 2way-5shot scenario. These results highlight our model's exceptional capability as a trailblazing solution for segmenting the heart and left atrial enlargement in veterinary applications through FSS, setting a new benchmark in veterinary AI research, and demonstrating its superior potential to veterinary medicine advances.
SDPL: Shifting-Dense Partition Learning for UAV-View Geo-Localization
Mar 07, 2024Cross-view geo-localization aims to match images of the same target from different platforms, e.g., drone and satellite. It is a challenging task due to the changing both appearance of targets and environmental content from different views. Existing methods mainly focus on digging more comprehensive information through feature maps segmentation, while inevitably destroy the image structure and are sensitive to the shifting and scale of the target in the query. To address the above issues, we introduce a simple yet effective part-based representation learning, called shifting-dense partition learning (SDPL). Specifically, we propose the dense partition strategy (DPS), which divides the image into multiple parts to explore contextual-information while explicitly maintain the global structure. To handle scenarios with non-centered targets, we further propose the shifting-fusion strategy, which generates multiple sets of parts in parallel based on various segmentation centers and then adaptively fuses all features to select the best partitions. Extensive experiments show that our SDPL is robust to position shifting and scale variations, and achieves competitive performance on two prevailing benchmarks, i.e., University-1652 and SUES-200.
Learning to Remove Wrinkled Transparent Film with Polarized Prior
Mar 07, 2024
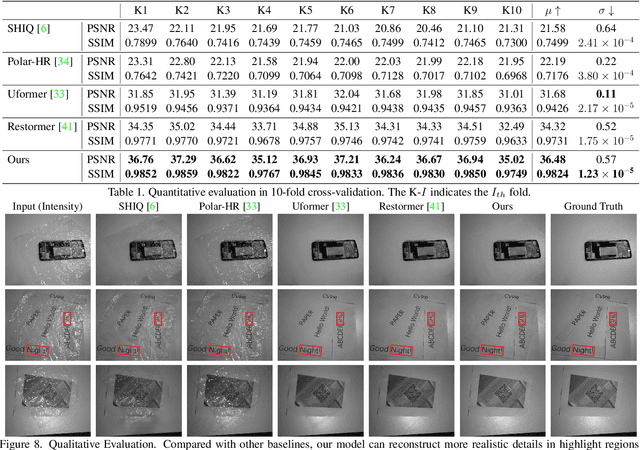
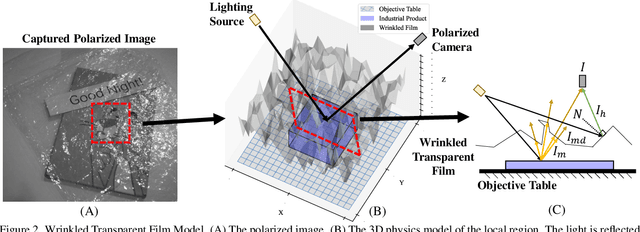
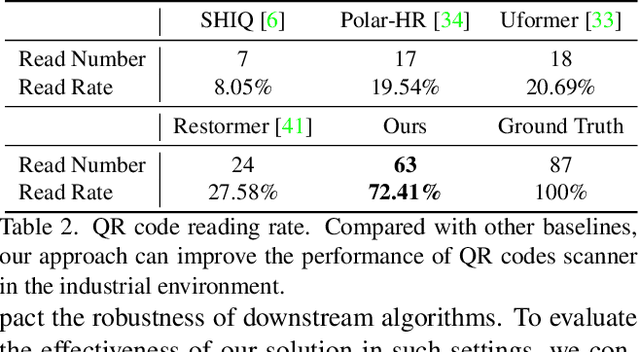
In this paper, we study a new problem, Film Removal (FR), which attempts to remove the interference of wrinkled transparent films and reconstruct the original information under films for industrial recognition systems. We first physically model the imaging of industrial materials covered by the film. Considering the specular highlight from the film can be effectively recorded by the polarized camera, we build a practical dataset with polarization information containing paired data with and without transparent film. We aim to remove interference from the film (specular highlights and other degradations) with an end-to-end framework. To locate the specular highlight, we use an angle estimation network to optimize the polarization angle with the minimized specular highlight. The image with minimized specular highlight is set as a prior for supporting the reconstruction network. Based on the prior and the polarized images, the reconstruction network can decouple all degradations from the film. Extensive experiments show that our framework achieves SOTA performance in both image reconstruction and industrial downstream tasks. Our code will be released at \url{https://github.com/jqtangust/FilmRemoval}.
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures
Mar 07, 2024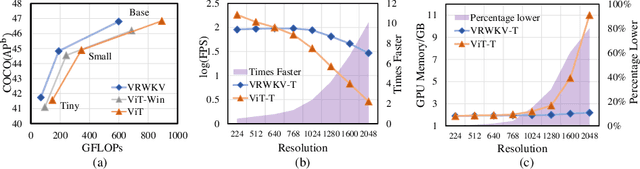

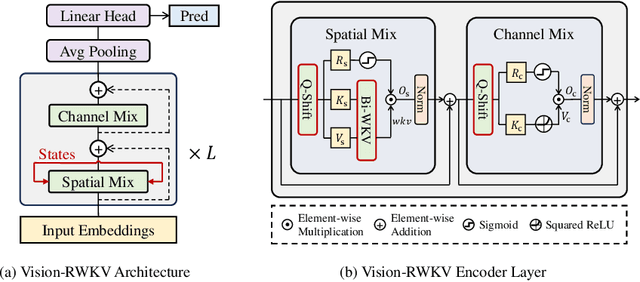
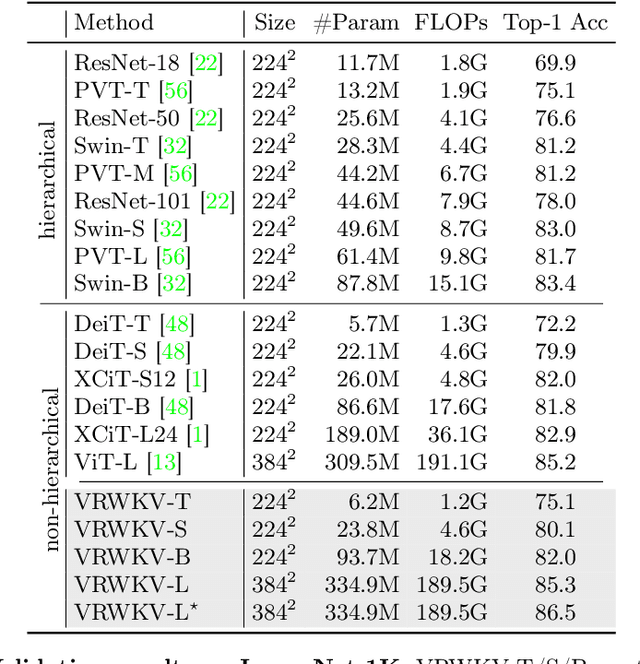
Transformers have revolutionized computer vision and natural language processing, but their high computational complexity limits their application in high-resolution image processing and long-context analysis. This paper introduces Vision-RWKV (VRWKV), a model adapted from the RWKV model used in the NLP field with necessary modifications for vision tasks. Similar to the Vision Transformer (ViT), our model is designed to efficiently handle sparse inputs and demonstrate robust global processing capabilities, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage lies in its reduced spatial aggregation complexity, which renders it exceptionally adept at processing high-resolution images seamlessly, eliminating the necessity for windowing operations. Our evaluations demonstrate that VRWKV surpasses ViT's performance in image classification and has significantly faster speeds and lower memory usage processing high-resolution inputs. In dense prediction tasks, it outperforms window-based models, maintaining comparable speeds. These results highlight VRWKV's potential as a more efficient alternative for visual perception tasks. Code is released at \url{https://github.com/OpenGVLab/Vision-RWKV}.
C2P-GCN: Cell-to-Patch Graph Convolutional Network for Colorectal Cancer Grading
Mar 08, 2024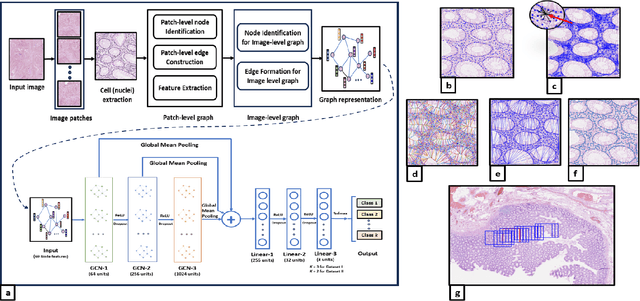
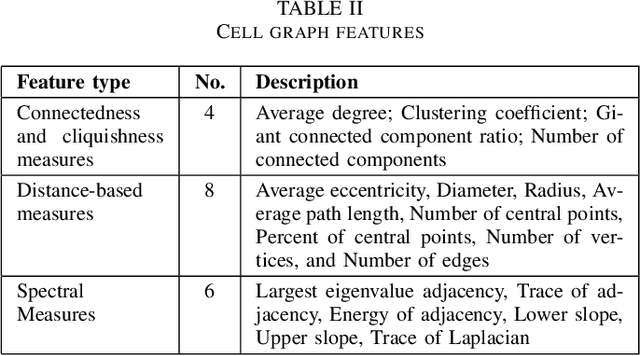

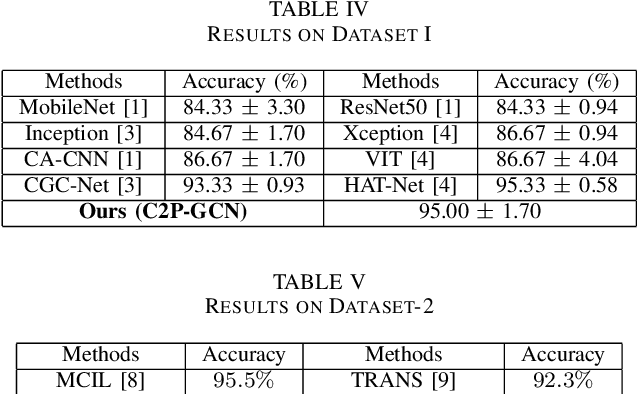
Graph-based learning approaches, due to their ability to encode tissue/organ structure information, are increasingly favored for grading colorectal cancer histology images. Recent graph-based techniques involve dividing whole slide images (WSIs) into smaller or medium-sized patches, and then building graphs on each patch for direct use in training. This method, however, fails to capture the tissue structure information present in an entire WSI and relies on training from a significantly large dataset of image patches. In this paper, we propose a novel cell-to-patch graph convolutional network (C2P-GCN), which is a two-stage graph formation-based approach. In the first stage, it forms a patch-level graph based on the cell organization on each patch of a WSI. In the second stage, it forms an image-level graph based on a similarity measure between patches of a WSI considering each patch as a node of a graph. This graph representation is then fed into a multi-layer GCN-based classification network. Our approach, through its dual-phase graph construction, effectively gathers local structural details from individual patches and establishes a meaningful connection among all patches across a WSI. As C2P-GCN integrates the structural data of an entire WSI into a single graph, it allows our model to work with significantly fewer training data compared to the latest models for colorectal cancer. Experimental validation of C2P-GCN on two distinct colorectal cancer datasets demonstrates the effectiveness of our method.
(Un)paired signal-to-signal translation with 1D conditional GANs
Mar 05, 2024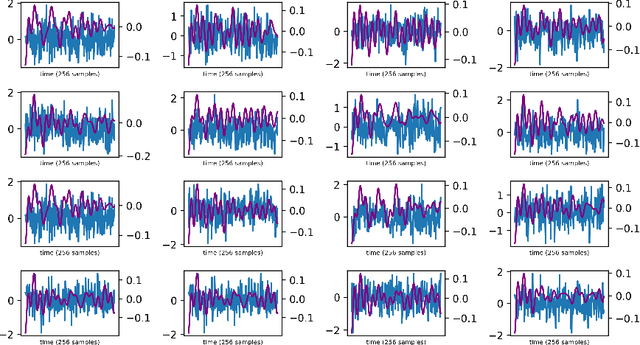
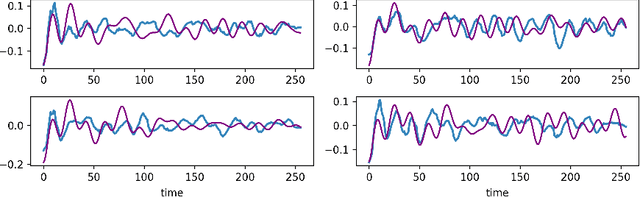
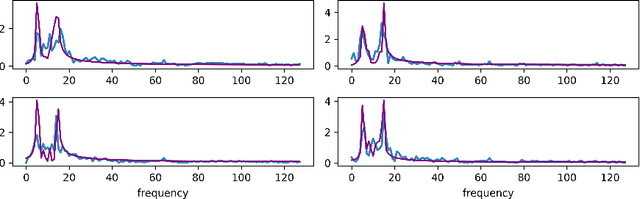
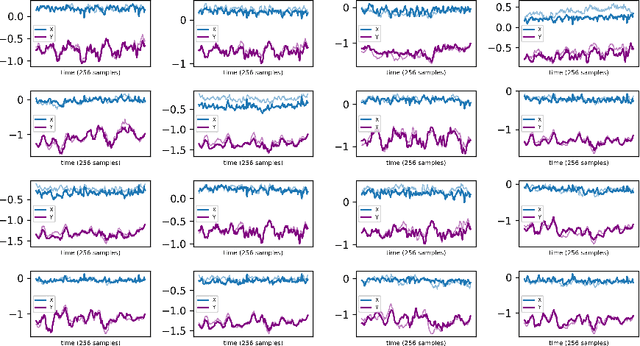
I show that a one-dimensional (1D) conditional generative adversarial network (cGAN) with an adversarial training architecture is capable of unpaired signal-to-signal ("sig2sig") translation. Using a simplified CycleGAN model with 1D layers and wider convolutional kernels, mirroring WaveGAN to reframe two-dimensional (2D) image generation as 1D audio generation, I show that recasting the 2D image-to-image translation task to a 1D signal-to-signal translation task with deep convolutional GANs is possible without substantial modification to the conventional U-Net model and adversarial architecture developed as CycleGAN. With this I show for a small tunable dataset that noisy test signals unseen by the 1D CycleGAN model and without paired training transform from the source domain to signals similar to paired test signals in the translated domain, especially in terms of frequency, and I quantify these differences in terms of correlation and error.
TinyLIC-High efficiency lossy image compression method
Feb 17, 2024Image compression has been the subject of extensive research for several decades, resulting in the development of well-known standards such as JPEG, JPEG2000, and H.264/AVC. However, recent advancements in deep learning have led to the emergence of learned image compression methods that offer significant improvements in coding efficiency compared to traditional codecs. These learned compression techniques have shown noticeable gains and even outperformed traditional schemes