 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Keypoint Based Enhancement Method for Audio Driven Free View Talking Head Synthesis
Oct 07, 2022
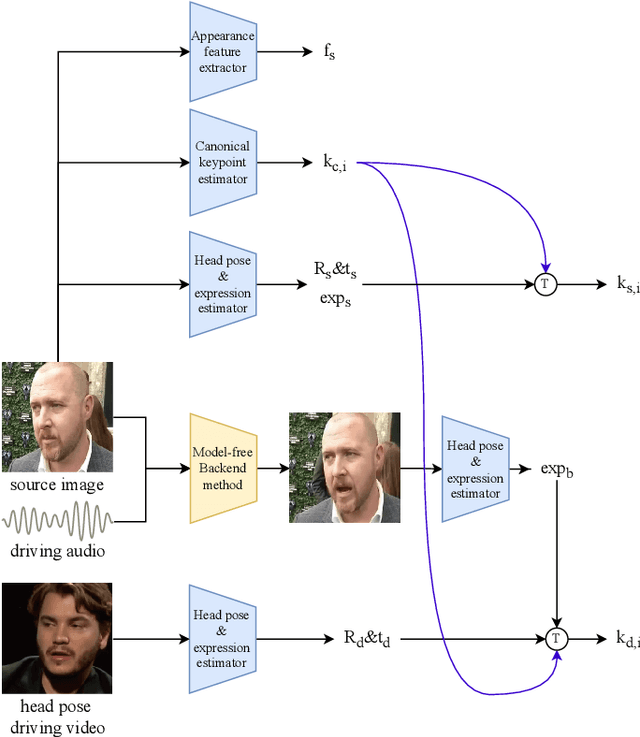
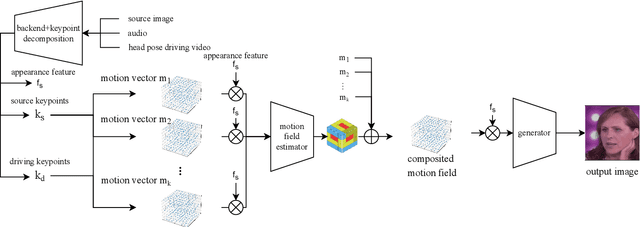


Audio driven talking head synthesis is a challenging task that attracts increasing attention in recent years. Although existing methods based on 2D landmarks or 3D face models can synthesize accurate lip synchronization and rhythmic head pose for arbitrary identity, they still have limitations, such as the cut feeling in the mouth mapping and the lack of skin highlights. The morphed region is blurry compared to the surrounding face. A Keypoint Based Enhancement (KPBE) method is proposed for audio driven free view talking head synthesis to improve the naturalness of the generated video. Firstly, existing methods were used as the backend to synthesize intermediate results. Then we used keypoint decomposition to extract video synthesis controlling parameters from the backend output and the source image. After that, the controlling parameters were composited to the source keypoints and the driving keypoints. A motion field based method was used to generate the final image from the keypoint representation. With keypoint representation, we overcame the cut feeling in the mouth mapping and the lack of skin highlights. Experiments show that our proposed enhancement method improved the quality of talking-head videos in terms of mean opinion score.
I see what you hear: a vision-inspired method to localize words
Oct 24, 2022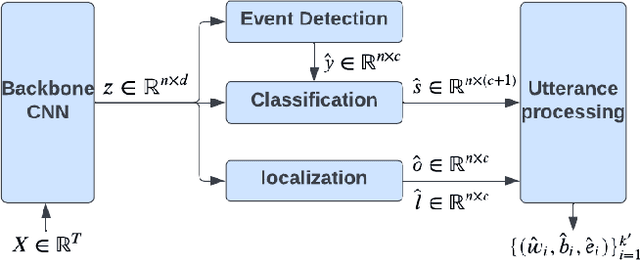
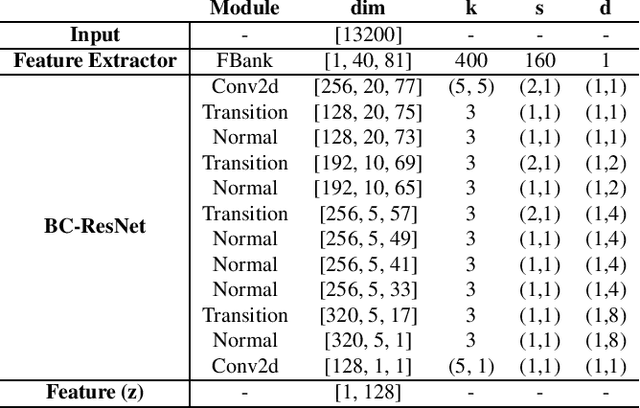
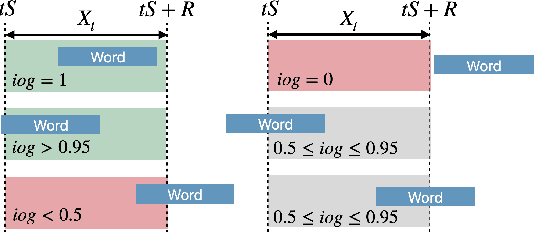

This paper explores the possibility of using visual object detection techniques for word localization in speech data. Object detection has been thoroughly studied in the contemporary literature for visual data. Noting that an audio can be interpreted as a 1-dimensional image, object localization techniques can be fundamentally useful for word localization. Building upon this idea, we propose a lightweight solution for word detection and localization. We use bounding box regression for word localization, which enables our model to detect the occurrence, offset, and duration of keywords in a given audio stream. We experiment with LibriSpeech and train a model to localize 1000 words. Compared to existing work, our method reduces model size by 94%, and improves the F1 score by 6.5\%.
Stereo Unstructured Magnification: Multiple Homography Image for View Synthesis
Apr 01, 2022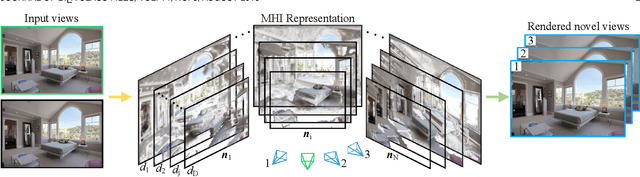
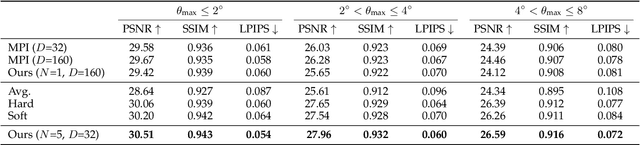
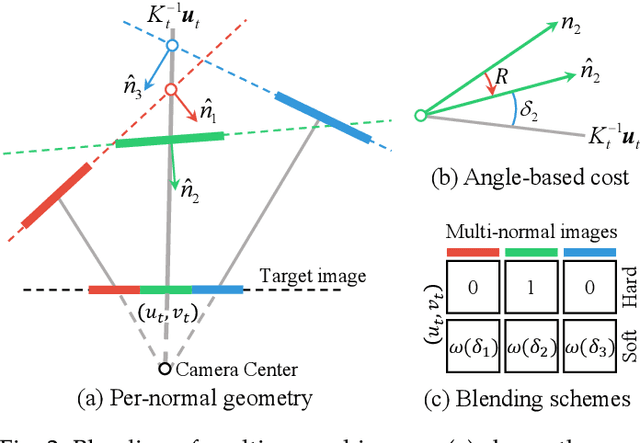
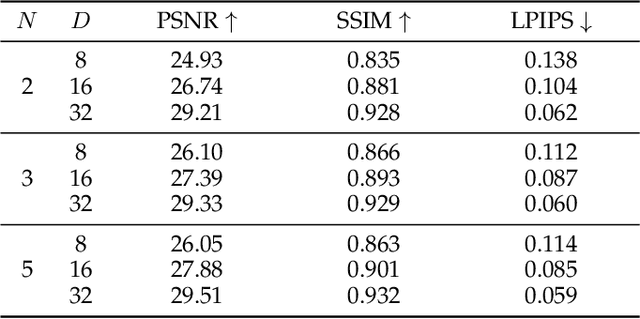
This paper studies the problem of view synthesis with certain amount of rotations from a pair of images, what we called stereo unstructured magnification. While the multi-plane image representation is well suited for view synthesis with depth invariant, how to generalize it to unstructured views remains a significant challenge. This is primarily due to the depth-dependency caused by camera frontal parallel representation. Here we propose a novel multiple homography image (MHI) representation, comprising of a set of scene planes with fixed normals and distances. A two-stage network is developed for novel view synthesis. Stage-1 is an MHI reconstruction module that predicts the MHIs and composites layered multi-normal images along the normal direction. Stage-2 is a normal-blending module to find blending weights. We also derive an angle-based cost to guide the blending of multi-normal images by exploiting per-normal geometry. Compared with the state-of-the-art methods, our method achieves superior performance for view synthesis qualitatively and quantitatively, especially for cases when the cameras undergo rotations.
Audio Time-Scale Modification with Temporal Compressing Networks
Oct 31, 2022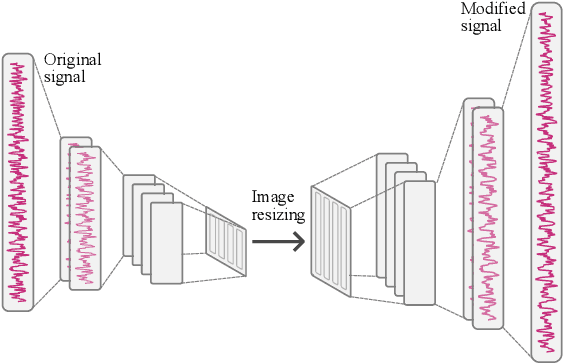
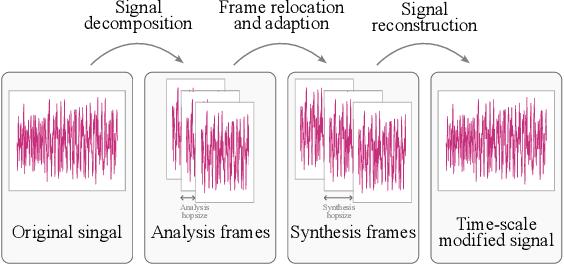
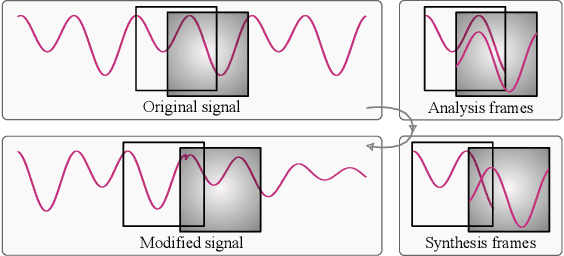
We proposed a novel approach in the field of time-scale modification on audio signals. While traditional methods use the framing technique, spectral approach uses the short-time Fourier transform to preserve the frequency during temporal stretching. TSM-Net, our neural-network model encodes the raw audio into a high-level latent representation. We call it Neuralgram, in which one vector represents 1024 audio samples. It is inspired by the framing technique but addresses the clipping artifacts. The Neuralgram is a two-dimensional matrix with real values, we can apply some existing image resizing techniques on the Neuralgram and decode it using our neural decoder to obtain the time-scaled audio. Both the encoder and decoder are trained with GANs, which shows fair generalization ability on the scaled Neuralgrams. Our method yields little artifacts and opens a new possibility in the research of modern time-scale modification. The audio samples can be found on https://ernestchu.github.io/tsm-net-demo/
Learning-based Inverse Rendering of Complex Indoor Scenes with Differentiable Monte Carlo Raytracing
Nov 06, 2022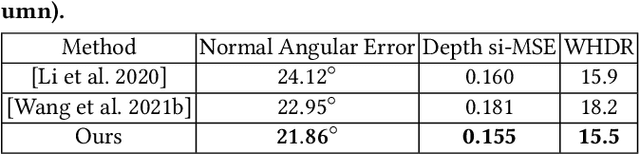


Indoor scenes typically exhibit complex, spatially-varying appearance from global illumination, making inverse rendering a challenging ill-posed problem. This work presents an end-to-end, learning-based inverse rendering framework incorporating differentiable Monte Carlo raytracing with importance sampling. The framework takes a single image as input to jointly recover the underlying geometry, spatially-varying lighting, and photorealistic materials. Specifically, we introduce a physically-based differentiable rendering layer with screen-space ray tracing, resulting in more realistic specular reflections that match the input photo. In addition, we create a large-scale, photorealistic indoor scene dataset with significantly richer details like complex furniture and dedicated decorations. Further, we design a novel out-of-view lighting network with uncertainty-aware refinement leveraging hypernetwork-based neural radiance fields to predict lighting outside the view of the input photo. Through extensive evaluations on common benchmark datasets, we demonstrate superior inverse rendering quality of our method compared to state-of-the-art baselines, enabling various applications such as complex object insertion and material editing with high fidelity. Code and data will be made available at \url{https://jingsenzhu.github.io/invrend}.
GrowliFlower: An image time series dataset for GROWth analysis of cauLIFLOWER
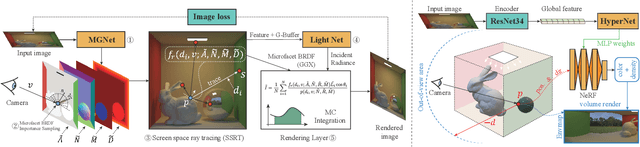
Apr 01, 2022

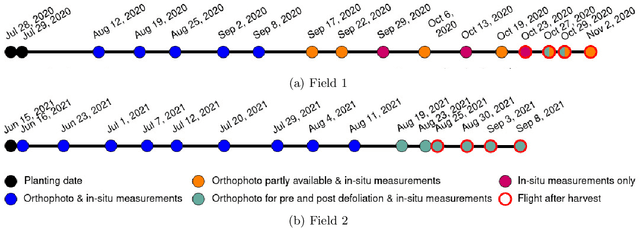

This article presents GrowliFlower, a georeferenced, image-based UAV time series dataset of two monitored cauliflower fields of size 0.39 and 0.60 ha acquired in 2020 and 2021. The dataset contains RGB and multispectral orthophotos from which about 14,000 individual plant coordinates are derived and provided. The coordinates enable the dataset users the extraction of complete and incomplete time series of image patches showing individual plants. The dataset contains collected phenotypic traits of 740 plants, including the developmental stage as well as plant and cauliflower size. As the harvestable product is completely covered by leaves, plant IDs and coordinates are provided to extract image pairs of plants pre and post defoliation, to facilitate estimations of cauliflower head size. Moreover, the dataset contains pixel-accurate leaf and plant instance segmentations, as well as stem annotations to address tasks like classification, detection, segmentation, instance segmentation, and similar computer vision tasks. The dataset aims to foster the development and evaluation of machine learning approaches. It specifically focuses on the analysis of growth and development of cauliflower and the derivation of phenotypic traits to foster the development of automation in agriculture. Two baseline results of instance segmentation at plant and leaf level based on the labeled instance segmentation data are presented. The entire data set is publicly available.
CIGLI: Conditional Image Generation from Language & Image
Aug 20, 2021
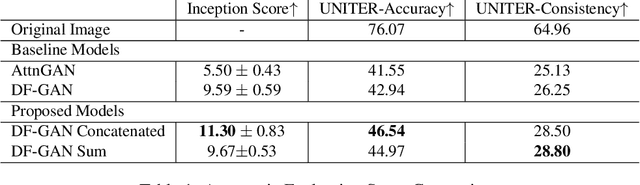
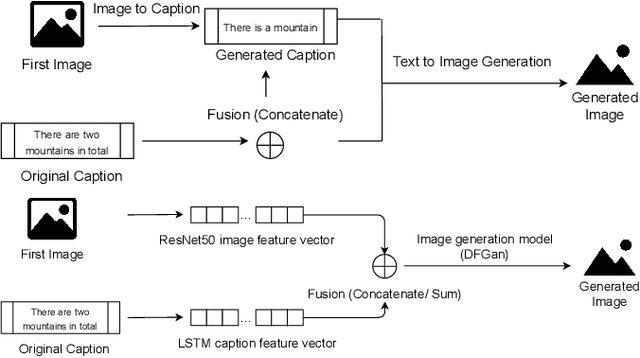
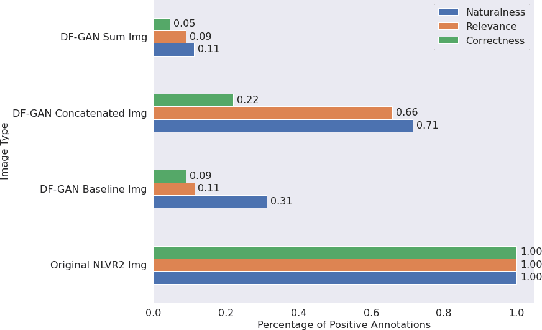
Multi-modal generation has been widely explored in recent years. Current research directions involve generating text based on an image or vice versa. In this paper, we propose a new task called CIGLI: Conditional Image Generation from Language and Image. Instead of generating an image based on text as in text-image generation, this task requires the generation of an image from a textual description and an image prompt. We designed a new dataset to ensure that the text description describes information from both images, and that solely analyzing the description is insufficient to generate an image. We then propose a novel language-image fusion model which improves the performance over two established baseline methods, as evaluated by quantitative (automatic) and qualitative (human) evaluations. The code and dataset is available at https://github.com/vincentlux/CIGLI.
Large Scale Real-World Multi-Person Tracking
Nov 03, 2022
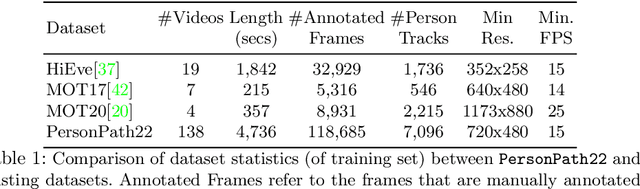
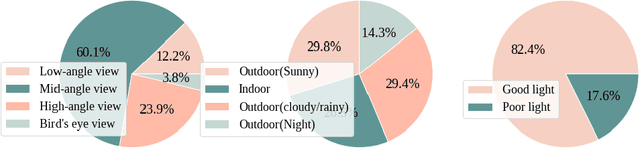
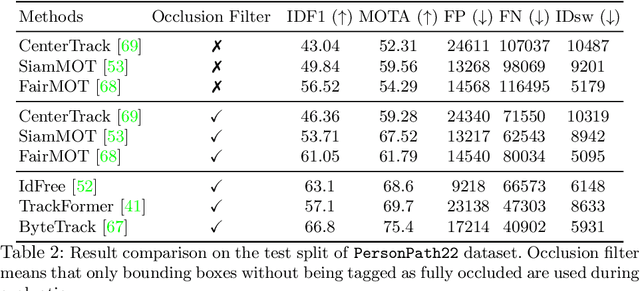
This paper presents a new large scale multi-person tracking dataset -- \texttt{PersonPath22}, which is over an order of magnitude larger than currently available high quality multi-object tracking datasets such as MOT17, HiEve, and MOT20 datasets. The lack of large scale training and test data for this task has limited the community's ability to understand the performance of their tracking systems on a wide range of scenarios and conditions such as variations in person density, actions being performed, weather, and time of day. \texttt{PersonPath22} dataset was specifically sourced to provide a wide variety of these conditions and our annotations include rich meta-data such that the performance of a tracker can be evaluated along these different dimensions. The lack of training data has also limited the ability to perform end-to-end training of tracking systems. As such, the highest performing tracking systems all rely on strong detectors trained on external image datasets. We hope that the release of this dataset will enable new lines of research that take advantage of large scale video based training data.
Scaling Cross-Domain Content-Based Image Retrieval for E-commerce Snap and Search Application
Apr 13, 2022

In this industry talk at ECIR 2022, we illustrate how we approach the main challenges from large scale cross-domain content-based image retrieval using a cascade method and a combination of our visual search and classification capabilities. Specifically, we present a system that is able to handle the scale of the data for e-commerce usage and the cross-domain nature of the query and gallery image pools. We showcase the approach applied in real-world e-commerce snap and search use case and its impact on ranking and latency performance.
Physically-Based Face Rendering for NIR-VIS Face Recognition
Nov 11, 2022



Near infrared (NIR) to Visible (VIS) face matching is challenging due to the significant domain gaps as well as a lack of sufficient data for cross-modality model training. To overcome this problem, we propose a novel method for paired NIR-VIS facial image generation. Specifically, we reconstruct 3D face shape and reflectance from a large 2D facial dataset and introduce a novel method of transforming the VIS reflectance to NIR reflectance. We then use a physically-based renderer to generate a vast, high-resolution and photorealistic dataset consisting of various poses and identities in the NIR and VIS spectra. Moreover, to facilitate the identity feature learning, we propose an IDentity-based Maximum Mean Discrepancy (ID-MMD) loss, which not only reduces the modality gap between NIR and VIS images at the domain level but encourages the network to focus on the identity features instead of facial details, such as poses and accessories. Extensive experiments conducted on four challenging NIR-VIS face recognition benchmarks demonstrate that the proposed method can achieve comparable performance with the state-of-the-art (SOTA) methods without requiring any existing NIR-VIS face recognition datasets. With slightly fine-tuning on the target NIR-VIS face recognition datasets, our method can significantly surpass the SOTA performance. Code and pretrained models are released under the insightface (https://github.com/deepinsight/insightface/tree/master/recognition).