 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PL-EVIO: Robust Monocular Event-based Visual Inertial Odometry with Point and Line Features
Sep 25, 2022
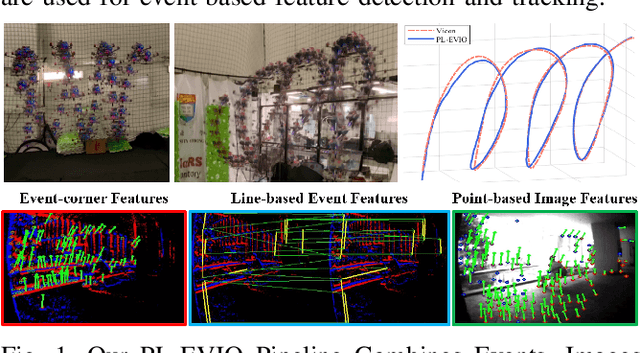
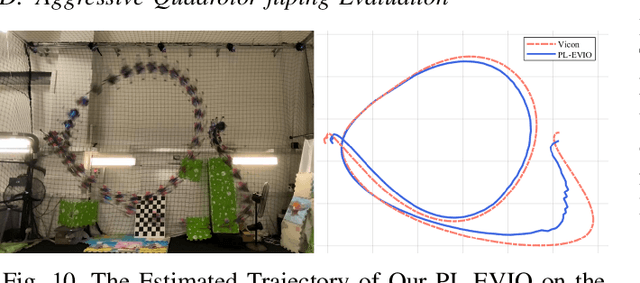
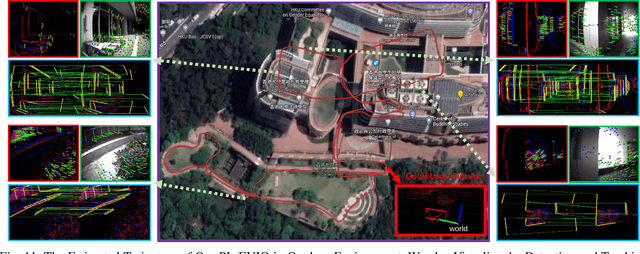
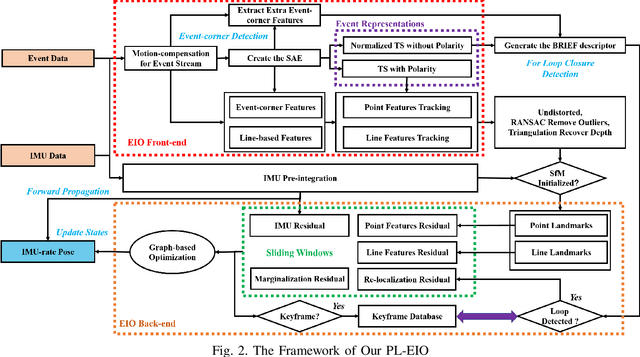
Event cameras are motion-activated sensors that capture pixel-level illumination changes instead of the intensity image with a fixed frame rate. Compared with the standard cameras, it can provide reliable visual perception during high-speed motions and in high dynamic range scenarios. However, event cameras output only a little information or even noise when the relative motion between the camera and the scene is limited, such as in a still state. While standard cameras can provide rich perception information in most scenarios, especially in good lighting conditions. These two cameras are exactly complementary. In this paper, we proposed a robust, high-accurate, and real-time optimization-based monocular event-based visual-inertial odometry (VIO) method with event-corner features, line-based event features, and point-based image features. The proposed method offers to leverage the point-based features in the nature scene and line-based features in the human-made scene to provide more additional structure or constraints information through well-design feature management. Experiments in the public benchmark datasets show that our method can achieve superior performance compared with the state-of-the-art image-based or event-based VIO. Finally, we used our method to demonstrate an onboard closed-loop autonomous quadrotor flight and large-scale outdoor experiments. Videos of the evaluations are presented on our project website: https://b23.tv/OE3QM6j
Sparse Semantic Map-Based Monocular Localization in Traffic Scenes Using Learned 2D-3D Point-Line Correspondences
Oct 10, 2022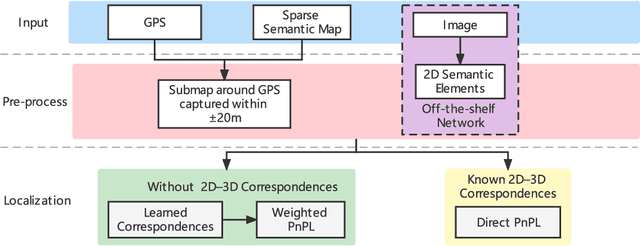
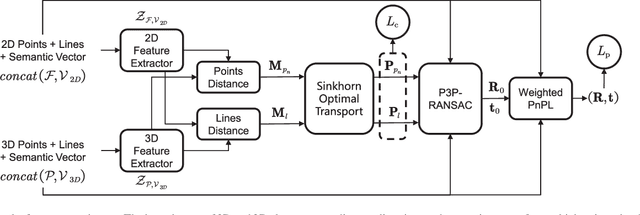
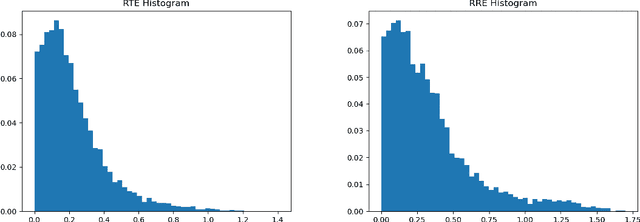
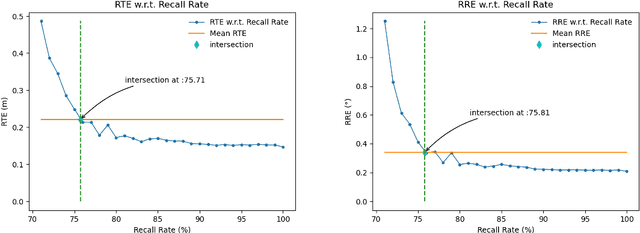
Vision-based localization in a prior map is of crucial importance for autonomous vehicles. Given a query image, the goal is to estimate the camera pose corresponding to the prior map, and the key is the registration problem of camera images within the map. While autonomous vehicles drive on the road under occlusion (e.g., car, bus, truck) and changing environment appearance (e.g., illumination changes, seasonal variation), existing approaches rely heavily on dense point descriptors at the feature level to solve the registration problem, entangling features with appearance and occlusion. As a result, they often fail to estimate the correct poses. To address these issues, we propose a sparse semantic map-based monocular localization method, which solves 2D-3D registration via a well-designed deep neural network. Given a sparse semantic map that consists of simplified elements (e.g., pole lines, traffic sign midpoints) with multiple semantic labels, the camera pose is then estimated by learning the corresponding features between the 2D semantic elements from the image and the 3D elements from the sparse semantic map. The proposed sparse semantic map-based localization approach is robust against occlusion and long-term appearance changes in the environments. Extensive experimental results show that the proposed method outperforms the state-of-the-art approaches.
A Transformer Framework for Data Fusion and Multi-Task Learning in Smart Cities
Nov 18, 2022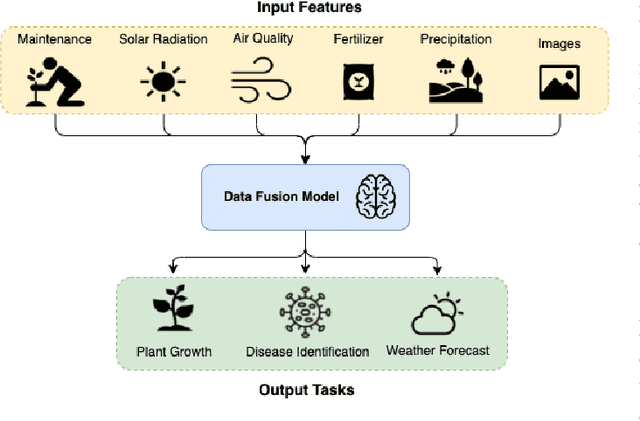
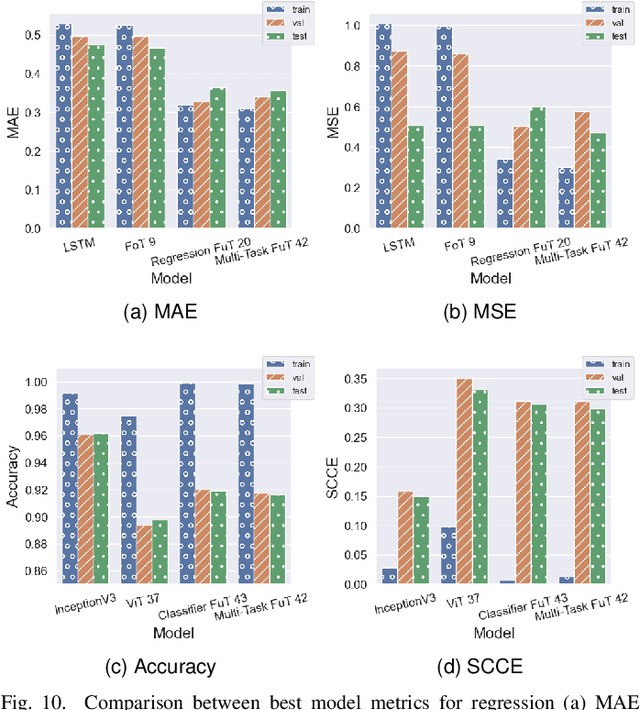
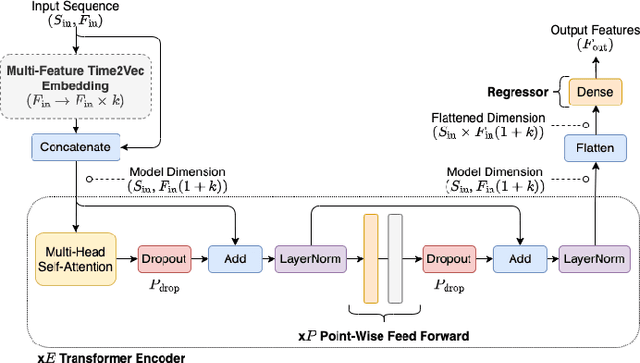
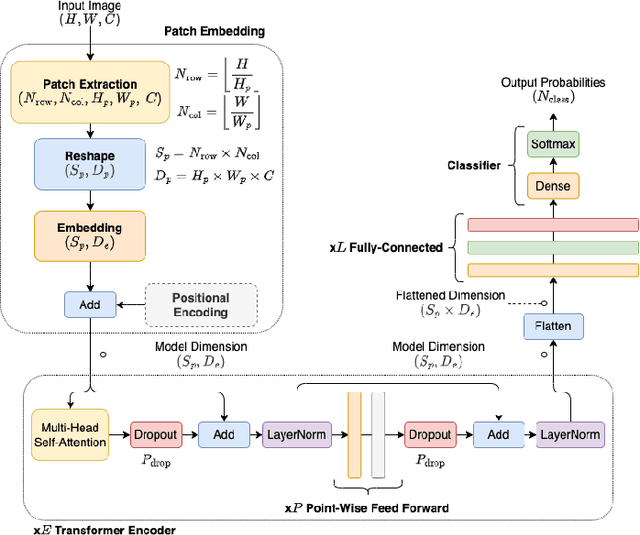
Rapid global urbanization is a double-edged sword, heralding promises of economical prosperity and public health while also posing unique environmental and humanitarian challenges. Smart and connected communities (S&CCs) apply data-centric solutions to these problems by integrating artificial intelligence (AI) and the Internet of Things (IoT). This coupling of intelligent technologies also poses interesting system design challenges regarding heterogeneous data fusion and task diversity. Transformers are of particular interest to address these problems, given their success across diverse fields of natural language processing (NLP), computer vision, time-series regression, and multi-modal data fusion. This begs the question whether Transformers can be further diversified to leverage fusions of IoT data sources for heterogeneous multi-task learning in S&CC trade spaces. In this paper, a Transformer-based AI system for emerging smart cities is proposed. Designed using a pure encoder backbone, and further customized through interchangeable input embedding and output task heads, the system supports virtually any input data and output task types present S&CCs. This generalizability is demonstrated through learning diverse task sets representative of S&CC environments, including multivariate time-series regression, visual plant disease classification, and image-time-series fusion tasks using a combination of Beijing PM2.5 and Plant Village datasets. Simulation results show that the proposed Transformer-based system can handle various input data types via custom sequence embedding techniques, and are naturally suited to learning a diverse set of tasks. The results also show that multi-task learners increase both memory and computational efficiency while maintaining comparable performance to both single-task variants, and non-Transformer baselines.
CIGLI: Conditional Image Generation from Language & Image
Aug 20, 2021
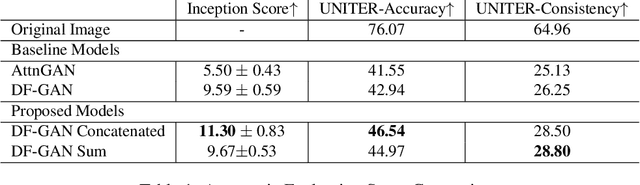
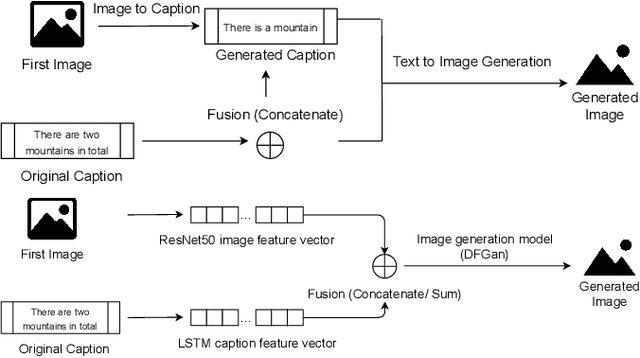
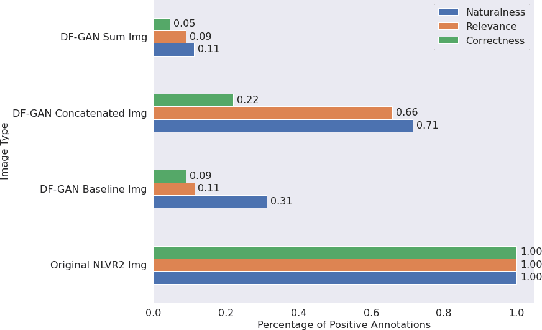
Multi-modal generation has been widely explored in recent years. Current research directions involve generating text based on an image or vice versa. In this paper, we propose a new task called CIGLI: Conditional Image Generation from Language and Image. Instead of generating an image based on text as in text-image generation, this task requires the generation of an image from a textual description and an image prompt. We designed a new dataset to ensure that the text description describes information from both images, and that solely analyzing the description is insufficient to generate an image. We then propose a novel language-image fusion model which improves the performance over two established baseline methods, as evaluated by quantitative (automatic) and qualitative (human) evaluations. The code and dataset is available at https://github.com/vincentlux/CIGLI.
Stereo Unstructured Magnification: Multiple Homography Image for View Synthesis
Apr 01, 2022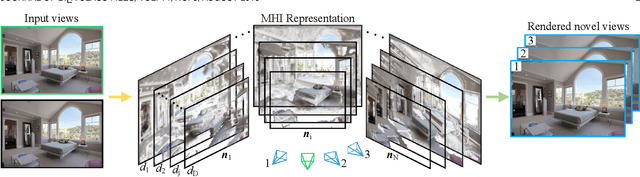
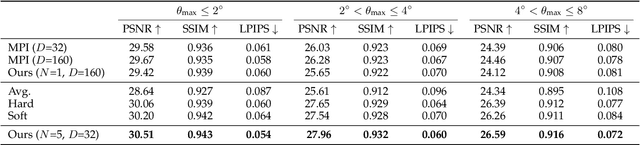
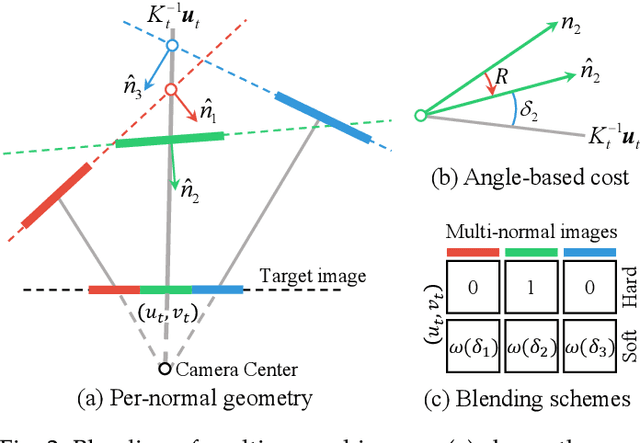
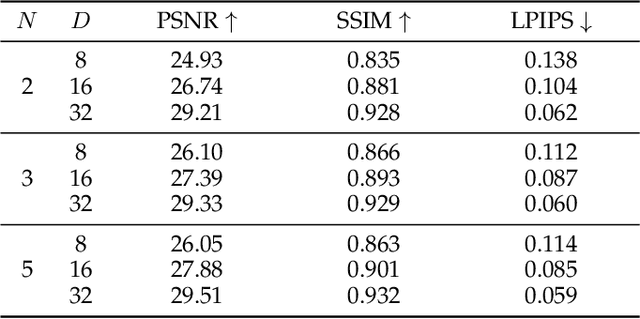
This paper studies the problem of view synthesis with certain amount of rotations from a pair of images, what we called stereo unstructured magnification. While the multi-plane image representation is well suited for view synthesis with depth invariant, how to generalize it to unstructured views remains a significant challenge. This is primarily due to the depth-dependency caused by camera frontal parallel representation. Here we propose a novel multiple homography image (MHI) representation, comprising of a set of scene planes with fixed normals and distances. A two-stage network is developed for novel view synthesis. Stage-1 is an MHI reconstruction module that predicts the MHIs and composites layered multi-normal images along the normal direction. Stage-2 is a normal-blending module to find blending weights. We also derive an angle-based cost to guide the blending of multi-normal images by exploiting per-normal geometry. Compared with the state-of-the-art methods, our method achieves superior performance for view synthesis qualitatively and quantitatively, especially for cases when the cameras undergo rotations.
Understanding the Role of Mixup in Knowledge Distillation: An Empirical Study
Nov 09, 2022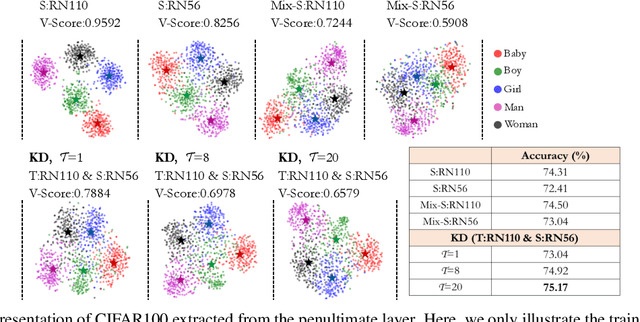
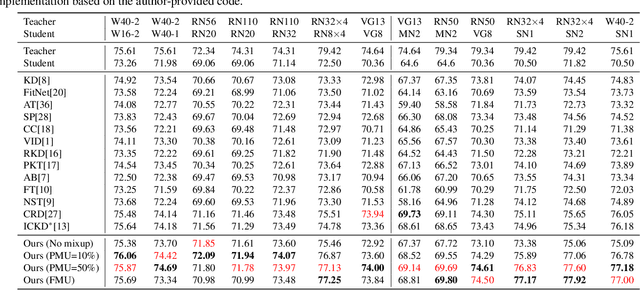
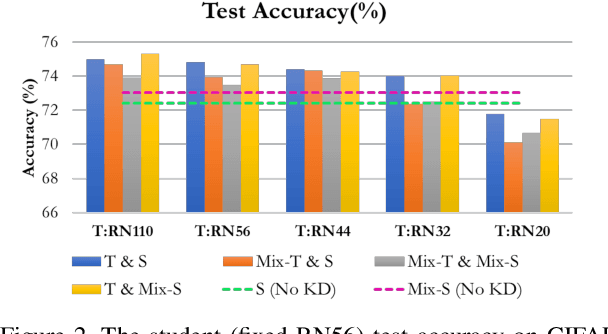

Mixup is a popular data augmentation technique based on creating new samples by linear interpolation between two given data samples, to improve both the generalization and robustness of the trained model. Knowledge distillation (KD), on the other hand, is widely used for model compression and transfer learning, which involves using a larger network's implicit knowledge to guide the learning of a smaller network. At first glance, these two techniques seem very different, however, we found that "smoothness" is the connecting link between the two and is also a crucial attribute in understanding KD's interplay with mixup. Although many mixup variants and distillation methods have been proposed, much remains to be understood regarding the role of a mixup in knowledge distillation. In this paper, we present a detailed empirical study on various important dimensions of compatibility between mixup and knowledge distillation. We also scrutinize the behavior of the networks trained with a mixup in the light of knowledge distillation through extensive analysis, visualizations, and comprehensive experiments on image classification. Finally, based on our findings, we suggest improved strategies to guide the student network to enhance its effectiveness. Additionally, the findings of this study provide insightful suggestions to researchers and practitioners that commonly use techniques from KD. Our code is available at https://github.com/hchoi71/MIX-KD.
The Best of Both Worlds: a Framework for Combining Degradation Prediction with High Performance Super-Resolution Networks
Nov 09, 2022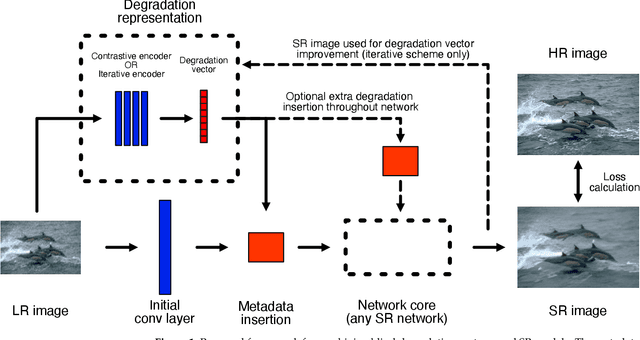
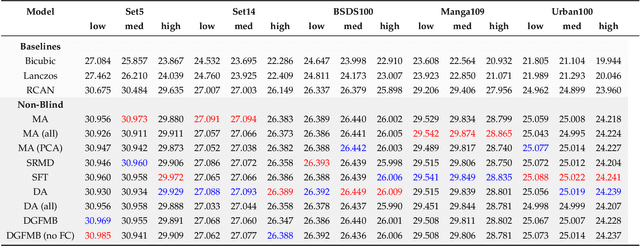
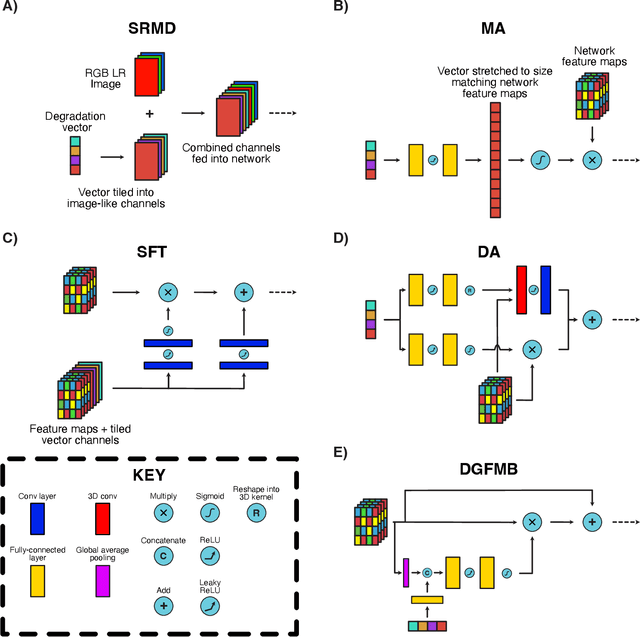

To date, the best-performing blind super-resolution (SR) techniques follow one of two paradigms: A) generate and train a standard SR network on synthetic low-resolution - high-resolution (LR - HR) pairs or B) attempt to predict the degradations an LR image has suffered and use these to inform a customised SR network. Despite significant progress, subscribers to the former miss out on useful degradation information that could be used to improve the SR process. On the other hand, followers of the latter rely on weaker SR networks, which are significantly outperformed by the latest architectural advancements. In this work, we present a framework for combining any blind SR prediction mechanism with any deep SR network, using a metadata insertion block to insert prediction vectors into SR network feature maps. Through comprehensive testing, we prove that state-of-the-art contrastive and iterative prediction schemes can be successfully combined with high-performance SR networks such as RCAN and HAN within our framework. We show that our hybrid models consistently achieve stronger SR performance than both their non-blind and blind counterparts. Furthermore, we demonstrate our framework's robustness by predicting degradations and super-resolving images from a complex pipeline of blurring, noise and compression.
Imbalanced Data Classification via Generative Adversarial Network with Application to Anomaly Detection in Additive Manufacturing Process
Nov 09, 2022
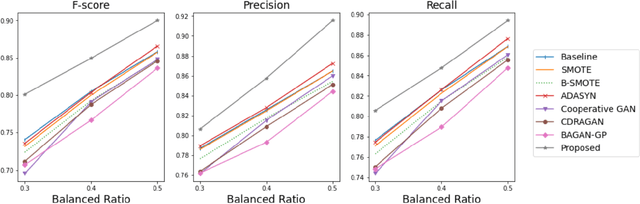

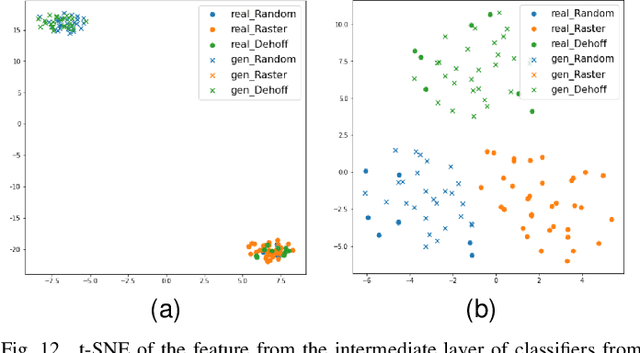
Supervised classification methods have been widely utilized for the quality assurance of the advanced manufacturing process, such as additive manufacturing (AM) for anomaly (defects) detection. However, since abnormal states (with defects) occur much less frequently than normal ones (without defects) in the manufacturing process, the number of sensor data samples collected from a normal state outweighs that from an abnormal state. This issue causes imbalanced training data for classification models, thus deteriorating the performance of detecting abnormal states in the process. It is beneficial to generate effective artificial sample data for the abnormal states to make a more balanced training set. To achieve this goal, this paper proposes a novel data augmentation method based on a generative adversarial network (GAN) using additive manufacturing process image sensor data. The novelty of our approach is that a standard GAN and classifier are jointly optimized with techniques to stabilize the learning process of standard GAN. The diverse and high-quality generated samples provide balanced training data to the classifier. The iterative optimization between GAN and classifier provides the high-performance classifier. The effectiveness of the proposed method is validated by both open-source data and real-world case studies in polymer and metal AM processes.
SUPRA: Superpixel Guided Loss for Improved Multi-modal Segmentation in Endoscopy
Nov 09, 2022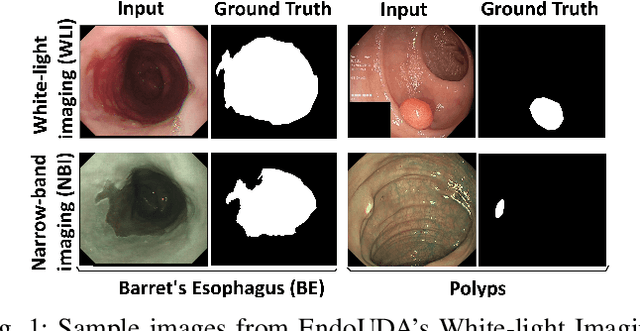
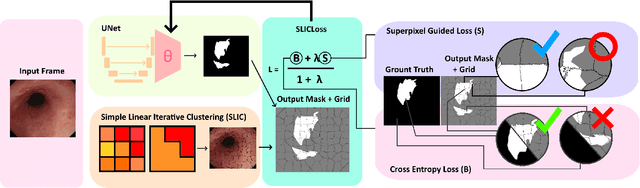
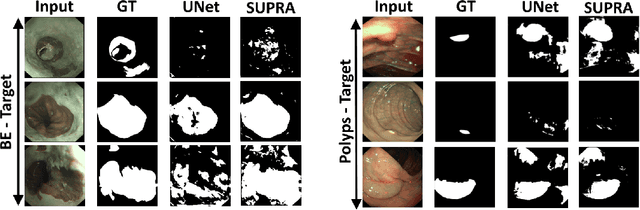
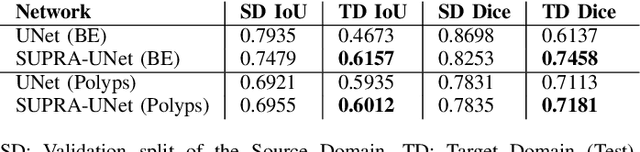
Domain shift is a well-known problem in the medical imaging community. In particular, for endoscopic image analysis where the data can have different modalities the performance of deep learning (DL) methods gets adversely affected. In other words, methods developed on one modality cannot be used for a different modality. However, in real clinical settings, endoscopists switch between modalities for better mucosal visualisation. In this paper, we explore the domain generalisation technique to enable DL methods to be used in such scenarios. To this extend, we propose to use super pixels generated with Simple Linear Iterative Clustering (SLIC) which we refer to as "SUPRA" for SUPeRpixel Augmented method. SUPRA first generates a preliminary segmentation mask making use of our new loss "SLICLoss" that encourages both an accurate and color-consistent segmentation. We demonstrate that SLICLoss when combined with Binary Cross Entropy loss (BCE) can improve the model's generalisability with data that presents significant domain shift. We validate this novel compound loss on a vanilla U-Net using the EndoUDA dataset, which contains images for Barret's Esophagus and polyps from two modalities. We show that our method yields an improvement of nearly 25% in the target domain set compared to the baseline.
Graph representation learning for street networks
Nov 09, 2022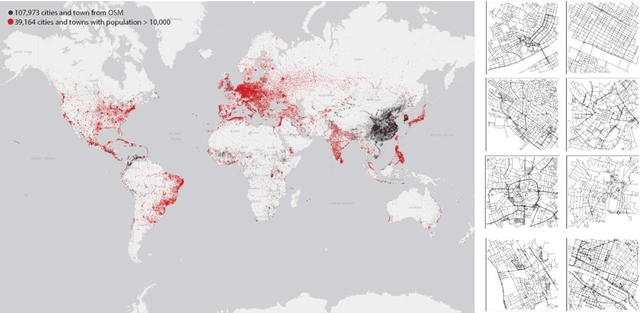
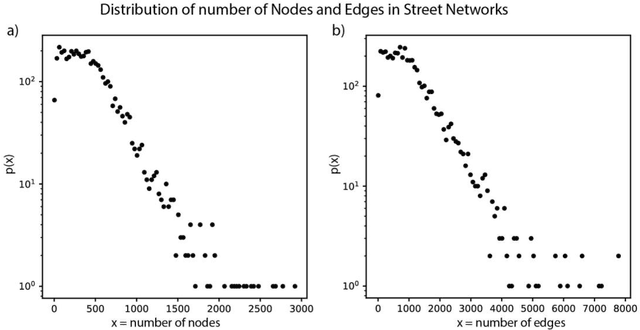
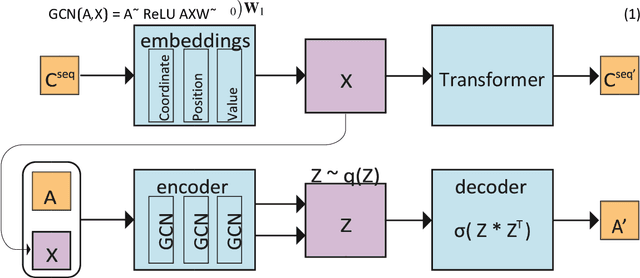
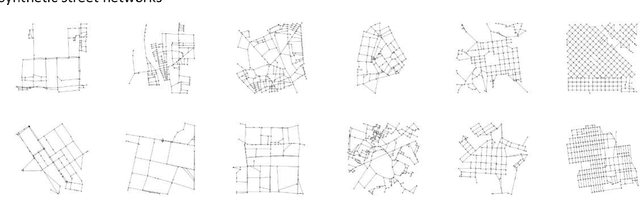
Streets networks provide an invaluable source of information about the different temporal and spatial patterns emerging in our cities. These streets are often represented as graphs where intersections are modelled as nodes and streets as links between them. Previous work has shown that raster representations of the original data can be created through a learning algorithm on low-dimensional representations of the street networks. In contrast, models that capture high-level urban network metrics can be trained through convolutional neural networks. However, the detailed topological data is lost through the rasterisation of the street network. The models cannot recover this information from the image alone, failing to capture complex street network features. This paper proposes a model capable of inferring good representations directly from the street network. Specifically, we use a variational autoencoder with graph convolutional layers and a decoder that outputs a probabilistic fully-connected graph to learn latent representations that encode both local network structure and the spatial distribution of nodes. We train the model on thousands of street network segments and use the learnt representations to generate synthetic street configurations. Finally, we proposed a possible application to classify the urban morphology of different network segments by investigating their common characteristics in the learnt space.