 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A novel information gain-based approach for classification and dimensionality reduction of hyperspectral images
Oct 26, 2022
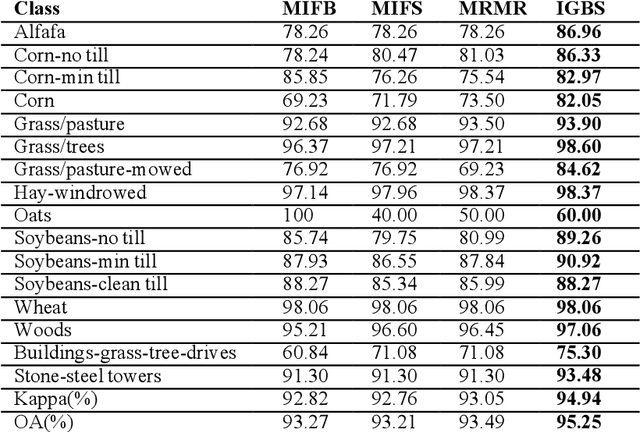
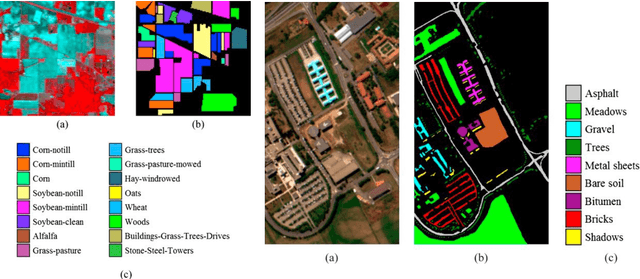
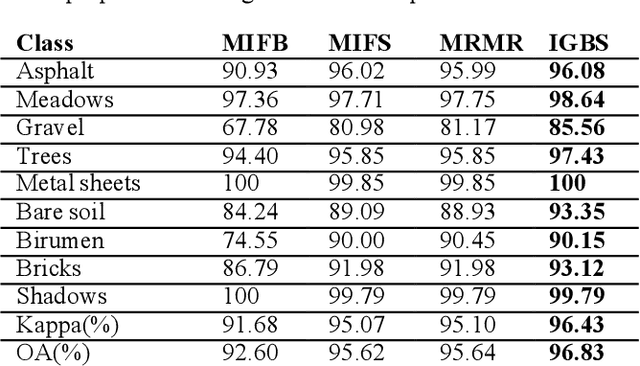
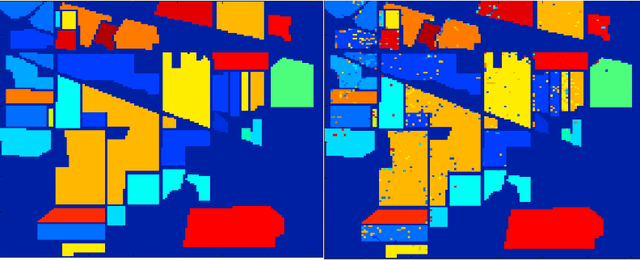
Recently, the hyperspectral sensors have improved our ability to monitor the earth surface with high spectral resolution. However, the high dimensionality of spectral data brings challenges for the image processing. Consequently, the dimensionality reduction is a necessary step in order to reduce the computational complexity and increase the classification accuracy. In this paper, we propose a new filter approach based on information gain for dimensionality reduction and classification of hyperspectral images. A special strategy based on hyperspectral bands selection is adopted to pick the most informative bands and discard the irrelevant and noisy ones. The algorithm evaluates the relevancy of the bands based on the information gain function with the support vector machine classifier. The proposed method is compared using two benchmark hyperspectral datasets (Indiana, Pavia) with three competing methods. The comparison results showed that the information gain filter approach outperforms the other methods on the tested datasets and could significantly reduce the computation cost while improving the classification accuracy. Keywords: Hyperspectral images; dimensionality reduction; information gain; classification accuracy. Keywords: Hyperspectral images; dimensionality reduction; information gain; classification accuracy.
Hardware/Software co-design with ADC-Less In-memory Computing Hardware for Spiking Neural Networks
Nov 03, 2022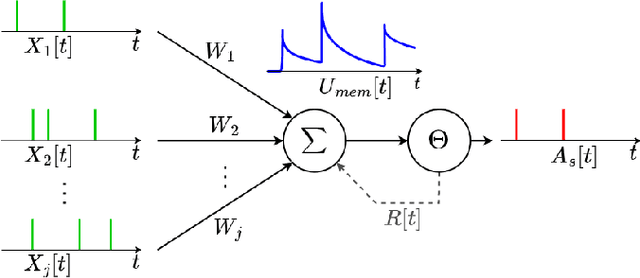
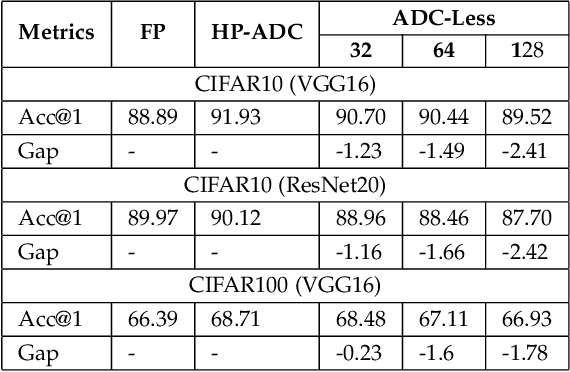
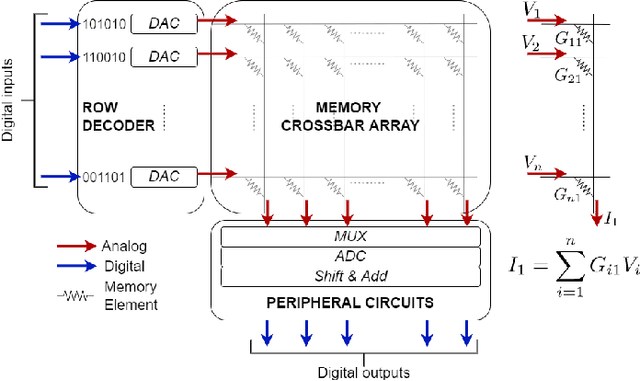
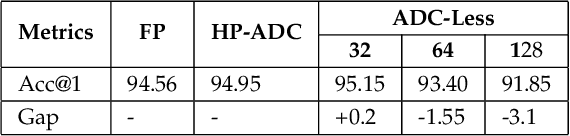
Spiking Neural Networks (SNNs) are bio-plausible models that hold great potential for realizing energy-efficient implementations of sequential tasks on resource-constrained edge devices. However, commercial edge platforms based on standard GPUs are not optimized to deploy SNNs, resulting in high energy and latency. While analog In-Memory Computing (IMC) platforms can serve as energy-efficient inference engines, they are accursed by the immense energy, latency, and area requirements of high-precision ADCs (HP-ADC), overshadowing the benefits of in-memory computations. We propose a hardware/software co-design methodology to deploy SNNs into an ADC-Less IMC architecture using sense-amplifiers as 1-bit ADCs replacing conventional HP-ADCs and alleviating the above issues. Our proposed framework incurs minimal accuracy degradation by performing hardware-aware training and is able to scale beyond simple image classification tasks to more complex sequential regression tasks. Experiments on complex tasks of optical flow estimation and gesture recognition show that progressively increasing the hardware awareness during SNN training allows the model to adapt and learn the errors due to the non-idealities associated with ADC-Less IMC. Also, the proposed ADC-Less IMC offers significant energy and latency improvements, $2-7\times$ and $8.9-24.6\times$, respectively, depending on the SNN model and the workload, compared to HP-ADC IMC.
Improving Semi-supervised Deep Learning by using Automatic Thresholding to Deal with Out of Distribution Data for COVID-19 Detection using Chest X-ray Images
Nov 03, 2022
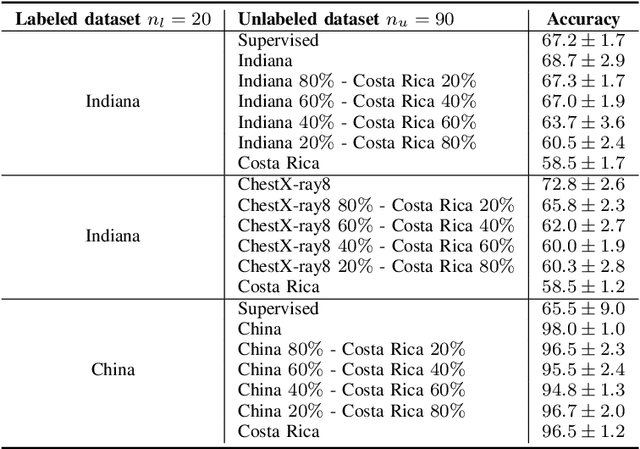
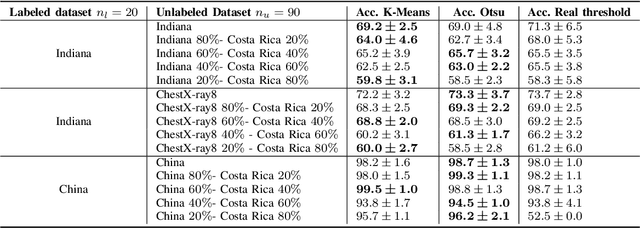
Semi-supervised learning (SSL) leverages both labeled and unlabeled data for training models when the labeled data is limited and the unlabeled data is vast. Frequently, the unlabeled data is more widely available than the labeled data, hence this data is used to improve the level of generalization of a model when the labeled data is scarce. However, in real-world settings unlabeled data might depict a different distribution than the labeled dataset distribution. This is known as distribution mismatch. Such problem generally occurs when the source of unlabeled data is different from the labeled data. For instance, in the medical imaging domain, when training a COVID-19 detector using chest X-ray images, different unlabeled datasets sampled from different hospitals might be used. In this work, we propose an automatic thresholding method to filter out-of-distribution data in the unlabeled dataset. We use the Mahalanobis distance between the labeled and unlabeled datasets using the feature space built by a pre-trained Image-net Feature Extractor (FE) to score each unlabeled observation. We test two simple automatic thresholding methods in the context of training a COVID-19 detector using chest X-ray images. The tested methods provide an automatic manner to define what unlabeled data to preserve when training a semi-supervised deep learning architecture.
Rethinking Hierarchicies in Pre-trained Plain Vision Transformer
Nov 03, 2022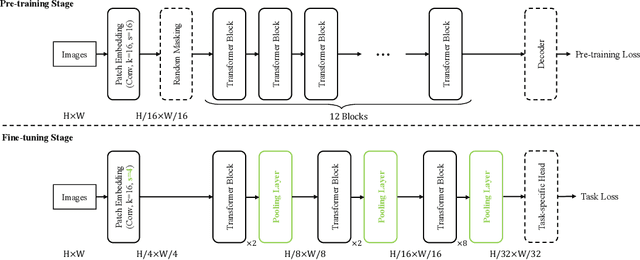

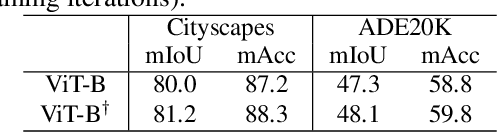
Self-supervised pre-training vision transformer (ViT) via masked image modeling (MIM) has been proven very effective. However, customized algorithms should be carefully designed for the hierarchical ViTs, e.g., GreenMIM, instead of using the vanilla and simple MAE for the plain ViT. More importantly, since these hierarchical ViTs cannot reuse the off-the-shelf pre-trained weights of the plain ViTs, the requirement of pre-training them leads to a massive amount of computational cost, thereby incurring both algorithmic and computational complexity. In this paper, we address this problem by proposing a novel idea of disentangling the hierarchical architecture design from the self-supervised pre-training. We transform the plain ViT into a hierarchical one with minimal changes. Technically, we change the stride of linear embedding layer from 16 to 4 and add convolution (or simple average) pooling layers between the transformer blocks, thereby reducing the feature size from 1/4 to 1/32 sequentially. Despite its simplicity, it outperforms the plain ViT baseline in classification, detection, and segmentation tasks on ImageNet, MS COCO, Cityscapes, and ADE20K benchmarks, respectively. We hope this preliminary study could draw more attention from the community on developing effective (hierarchical) ViTs while avoiding the pre-training cost by leveraging the off-the-shelf checkpoints. The code and models will be released at https://github.com/ViTAE-Transformer/HPViT.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022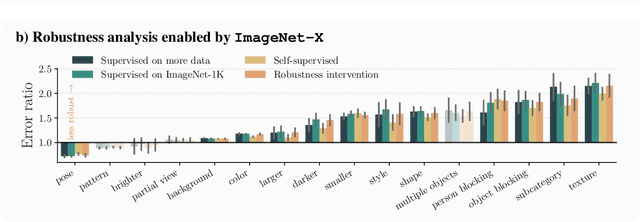
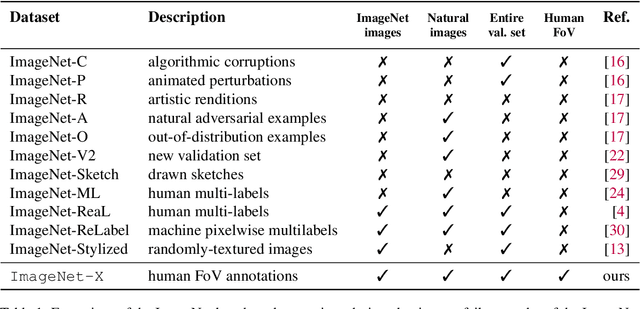
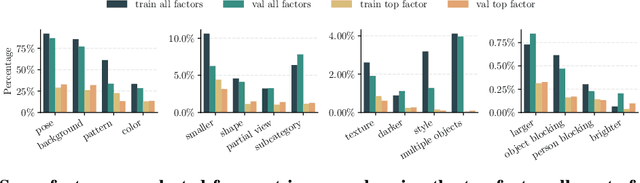
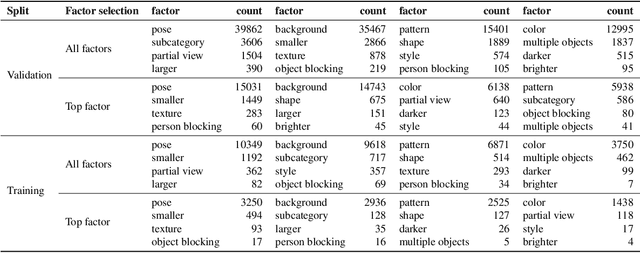
Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.
Metal Inpainting in CBCT Projections Using Score-based Generative Model
Sep 20, 2022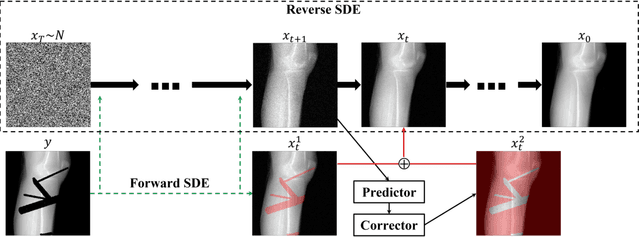
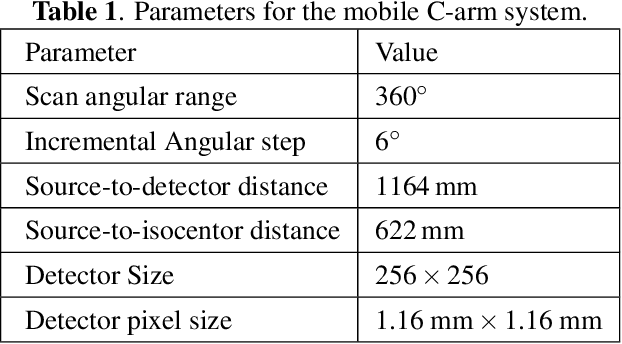
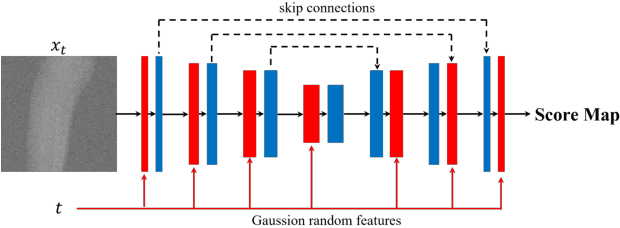
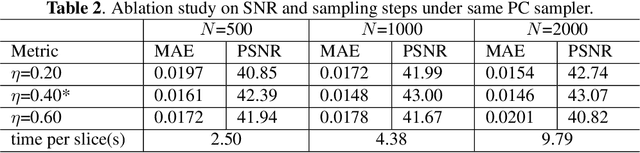
During orthopaedic surgery, the inserting of metallic implants or screws are often performed under mobile C-arm systems. Due to the high attenuation of metals, severe metal artifacts occur in 3D reconstructions, which degrade the image quality greatly. To reduce the artifacts, many metal artifact reduction algorithms have been developed and metal inpainting in projection domain is an essential step. In this work, a score-based generative model is trained on simulated knee projections and the inpainted image is obtained by removing the noise in conditional resampling process. The result implies that the inpainted images by score-based generative model have more detailed information and achieve the lowest mean absolute error and the highest peak-signal-to-noise-ratio compared with interpolation and CNN based method. Besides, the score-based model can also recover projections with big circlar and rectangular masks, showing its generalization in inpainting task.
Core Box Image Recognition and its Improvement with a New Augmentation Technique
Apr 20, 2022
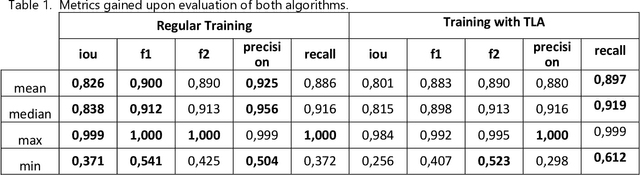

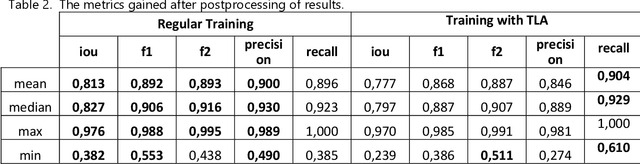
Most methods for automated full-bore rock core image analysis (description, colour, properties distribution, etc.) are based on separate core column analyses. The core is usually imaged in a box because of the significant amount of time taken to get an image for each core column. The work presents an innovative method and algorithm for core columns extraction from core boxes. The conditions for core boxes imaging may differ tremendously. Such differences are disastrous for machine learning algorithms which need a large dataset describing all possible data variations. Still, such images have some standard features - a box and core. Thus, we can emulate different environments with a unique augmentation described in this work. It is called template-like augmentation (TLA). The method is described and tested on various environments, and results are compared on an algorithm trained on both 'traditional' data and a mix of traditional and TLA data. The algorithm trained with TLA data provides better metrics and can detect core on most new images, unlike the algorithm trained on data without TLA. The algorithm for core column extraction implemented in an automated core description system speeds up the core box processing by a factor of 20.
* 20 pages, 16 figures, 1 table, the augmentation pipeline code samples published as Open-Source code for TLA at https://github.com/BEEugene/TemplateArtification/, continue of the research from arXiv:1909.10227
Rethinking the Zigzag Flattening for Image Reading
Feb 21, 2022


Sequence ordering of word vector matters a lot to text reading, which has been proven in natural language processing (NLP). However, the rule of different sequence ordering in computer vision (CV) was not well explored, e.g., why the "zigzag" flattening (ZF) is commonly utilized as a default option to get the image patches ordering in vision transformers (ViTs). Notably, when decomposing multi-scale images, the ZF could not maintain the invariance of feature point positions. To this end, we investigate the Hilbert fractal flattening (HF) as another method for sequence ordering in CV and contrast it against ZF. The HF has proven to be superior to other curves in maintaining spatial locality, when performing multi-scale transformations of dimensional space. And it can be easily plugged into most deep neural networks (DNNs). Extensive experiments demonstrate that it can yield consistent and significant performance boosts for a variety of architectures. Finally, we hope that our studies spark further research about the flattening strategy of image reading.
AccelAT: A Framework for Accelerating the Adversarial Training of Deep Neural Networks through Accuracy Gradient
Oct 13, 2022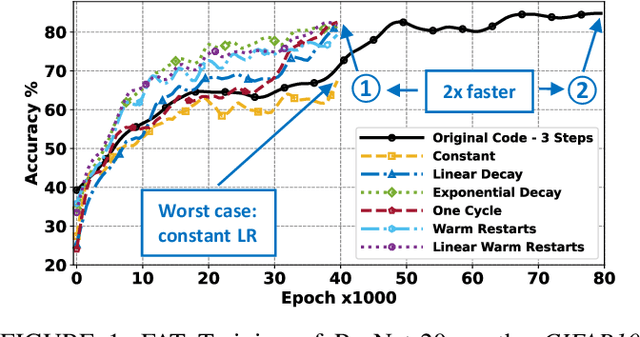

Adversarial training is exploited to develop a robust Deep Neural Network (DNN) model against the malicious altered data. These attacks may have catastrophic effects on DNN models but are indistinguishable for a human being. For example, an external attack can modify an image adding noises invisible for a human eye, but a DNN model misclassified the image. A key objective for developing robust DNN models is to use a learning algorithm that is fast but can also give model that is robust against different types of adversarial attacks. Especially for adversarial training, enormously long training times are needed for obtaining high accuracy under many different types of adversarial samples generated using different adversarial attack techniques. This paper aims at accelerating the adversarial training to enable fast development of robust DNN models against adversarial attacks. The general method for improving the training performance is the hyperparameters fine-tuning, where the learning rate is one of the most crucial hyperparameters. By modifying its shape (the value over time) and value during the training, we can obtain a model robust to adversarial attacks faster than standard training. First, we conduct experiments on two different datasets (CIFAR10, CIFAR100), exploring various techniques. Then, this analysis is leveraged to develop a novel fast training methodology, AccelAT, which automatically adjusts the learning rate for different epochs based on the accuracy gradient. The experiments show comparable results with the related works, and in several experiments, the adversarial training of DNNs using our AccelAT framework is conducted up to 2 times faster than the existing techniques. Thus, our findings boost the speed of adversarial training in an era in which security and performance are fundamental optimization objectives in DNN-based applications.
A Survey of Historical Document Image Datasets
Mar 16, 2022
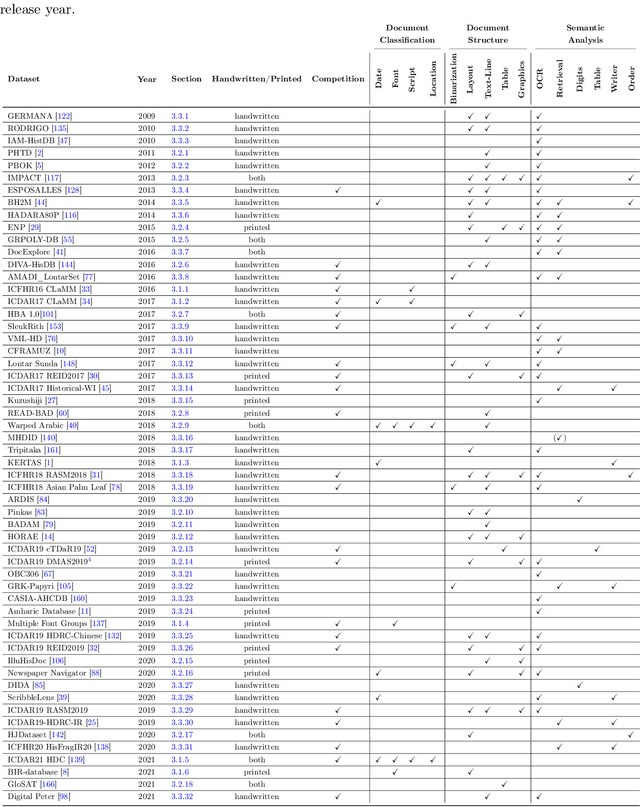
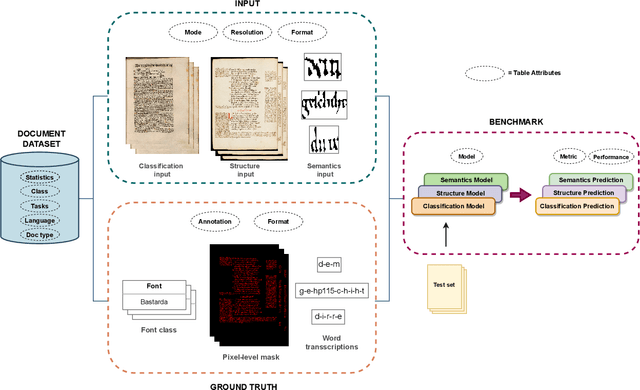
This paper presents a systematic literature review of image datasets for document image analysis, focusing on historical documents, such as handwritten manuscripts and early prints. Finding appropriate datasets for historical document analysis is a crucial prerequisite to facilitate research using different machine learning algorithms. However, because of the very large variety of the actual data (e.g., scripts, tasks, dates, support systems, and amount of deterioration), the different formats for data and label representation, and the different evaluation processes and benchmarks, finding appropriate datasets is a difficult task. This work fills this gap, presenting a meta-study on existing datasets. After a systematic selection process (according to PRISMA guidelines), we select 56 studies that are chosen based on different factors, such as the year of publication, number of methods implemented in the article, reliability of the chosen algorithms, dataset size, and journal outlet. We summarize each study by assigning it to one of three pre-defined tasks: document classification, layout structure, or semantic analysis. We present the statistics, document type, language, tasks, input visual aspects, and ground truth information for every dataset. In addition, we provide the benchmark tasks and results from these papers or recent competitions. We further discuss gaps and challenges in this domain. We advocate for providing conversion tools to common formats (e.g., COCO format for computer vision tasks) and always providing a set of evaluation metrics, instead of just one, to make results comparable across studies.