 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
Sep 21, 2022




Given a portrait image of a person and an environment map of the target lighting, portrait relighting aims to re-illuminate the person in the image as if the person appeared in an environment with the target lighting. To achieve high-quality results, recent methods rely on deep learning. An effective approach is to supervise the training of deep neural networks with a high-fidelity dataset of desired input-output pairs, captured with a light stage. However, acquiring such data requires an expensive special capture rig and time-consuming efforts, limiting access to only a few resourceful laboratories. To address the limitation, we propose a new approach that can perform on par with the state-of-the-art (SOTA) relighting methods without requiring a light stage. Our approach is based on the realization that a successful relighting of a portrait image depends on two conditions. First, the method needs to mimic the behaviors of physically-based relighting. Second, the output has to be photorealistic. To meet the first condition, we propose to train the relighting network with training data generated by a virtual light stage that performs physically-based rendering on various 3D synthetic humans under different environment maps. To meet the second condition, we develop a novel synthetic-to-real approach to bring photorealism to the relighting network output. In addition to achieving SOTA results, our approach offers several advantages over the prior methods, including controllable glares on glasses and more temporally-consistent results for relighting videos.
* To appear in ACM Transactions on Graphics (SIGGRAPH Asia 2022). 21 pages, 25 figures, 7 tables. Project page: https://deepimagination.cc/Lumos/
BirdSoundsDenoising: Deep Visual Audio Denoising for Bird Sounds
Oct 18, 2022

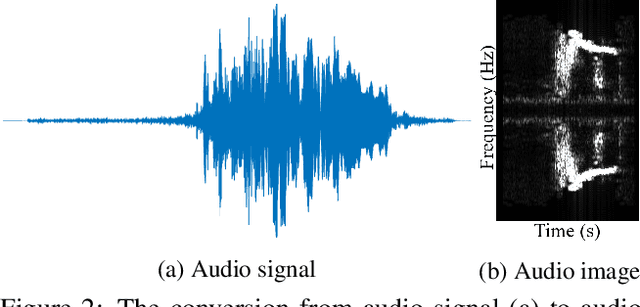
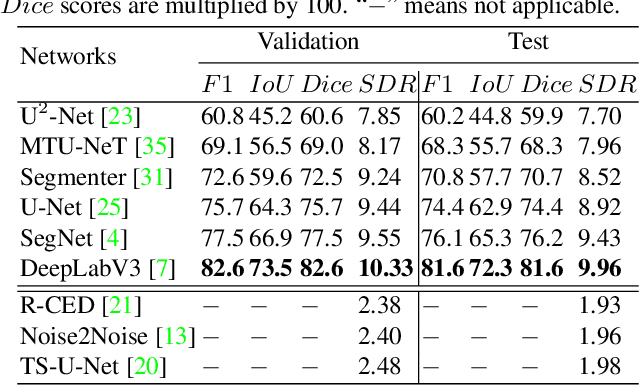
Audio denoising has been explored for decades using both traditional and deep learning-based methods. However, these methods are still limited to either manually added artificial noise or lower denoised audio quality. To overcome these challenges, we collect a large-scale natural noise bird sound dataset. We are the first to transfer the audio denoising problem into an image segmentation problem and propose a deep visual audio denoising (DVAD) model. With a total of 14,120 audio images, we develop an audio ImageMask tool and propose to use a few-shot generalization strategy to label these images. Extensive experimental results demonstrate that the proposed model achieves state-of-the-art performance. We also show that our method can be easily generalized to speech denoising, audio separation, audio enhancement, and noise estimation.
Global and Local Alignment Networks for Unpaired Image-to-Image Translation
Nov 19, 2021
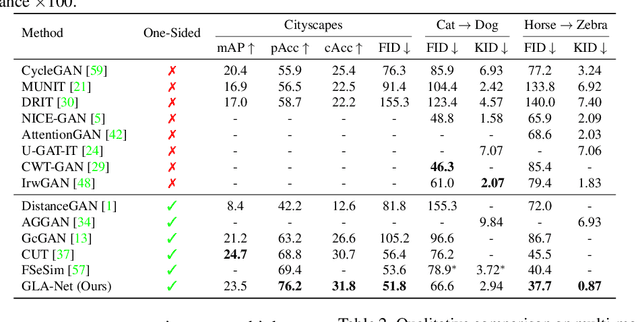
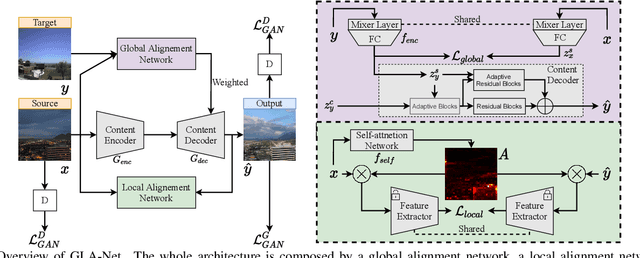
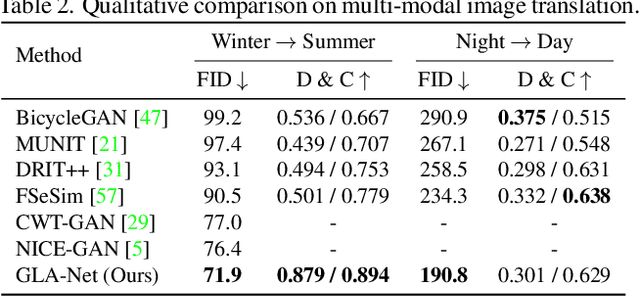
The goal of unpaired image-to-image translation is to produce an output image reflecting the target domain's style while keeping unrelated contents of the input source image unchanged. However, due to the lack of attention to the content change in existing methods, the semantic information from source images suffers from degradation during translation. In the paper, to address this issue, we introduce a novel approach, Global and Local Alignment Networks (GLA-Net). The global alignment network aims to transfer the input image from the source domain to the target domain. To effectively do so, we learn the parameters (mean and standard deviation) of multivariate Gaussian distributions as style features by using an MLP-Mixer based style encoder. To transfer the style more accurately, we employ an adaptive instance normalization layer in the encoder, with the parameters of the target multivariate Gaussian distribution as input. We also adopt regularization and likelihood losses to further reduce the domain gap and produce high-quality outputs. Additionally, we introduce a local alignment network, which employs a pretrained self-supervised model to produce an attention map via a novel local alignment loss, ensuring that the translation network focuses on relevant pixels. Extensive experiments conducted on five public datasets demonstrate that our method effectively generates sharper and more realistic images than existing approaches. Our code is available at https://github.com/ygjwd12345/GLANet.
Receiver Bandwidth Extension Beyond Nyquist Using Channel Bonding
Oct 14, 2022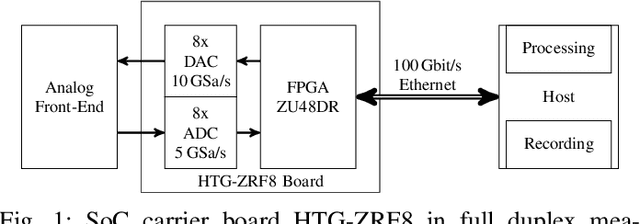
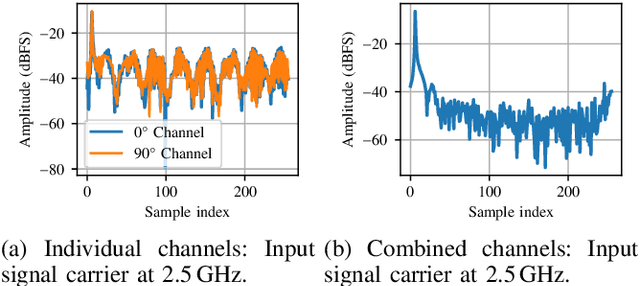
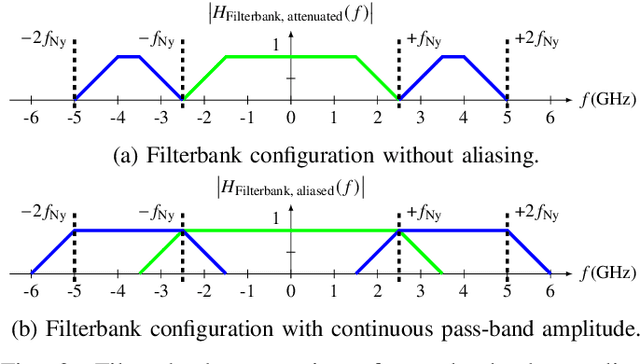
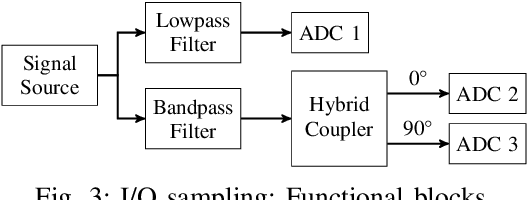
Current and upcoming communication and sensing technologies require ever larger bandwidths. Channel bonding can be utilized to extend a receiver's instantaneous bandwidth beyond a single converter's Nyquist limit. Two potential joint front-end and converter design approaches are theoretically introduced, realized and evaluated in this paper. The Xilinx RFSoC platform with its 5 GSa/s analog to digital converters (ADCs) is used to implement both a hybrid coupler based in-phase/quadrature (I/Q) sampling and a time-interleaved sampling approach along with channel bonding. Both realizations are demonstrated to be able to reconstruct instantaneous bandwidths of 5 GHz with up to 49 dB image rejection ratio (IRR) typically within 4 to 8 dB the front-ends' theoretical limits.
Increasing Visual Awareness in Multimodal Neural Machine Translation from an Information Theoretic Perspective
Oct 16, 2022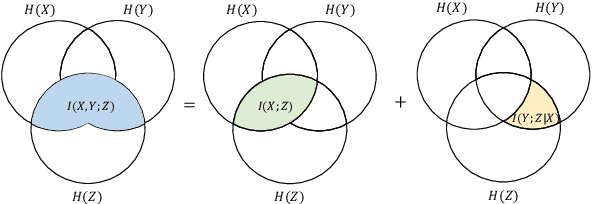
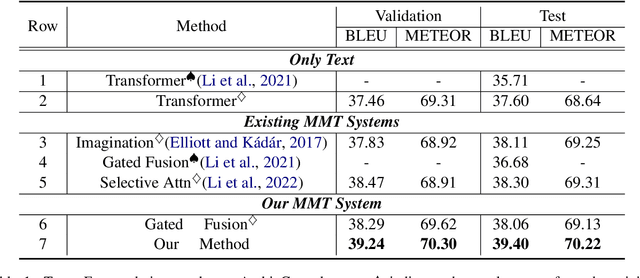
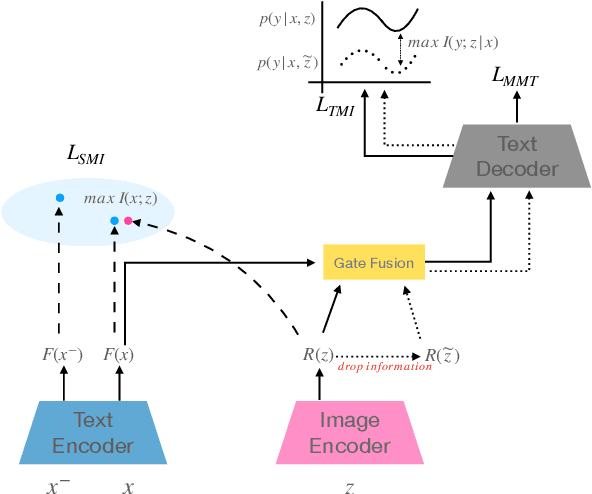
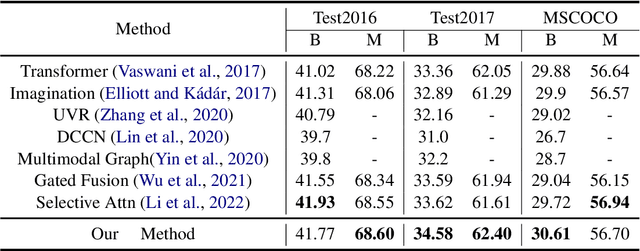
Multimodal machine translation (MMT) aims to improve translation quality by equipping the source sentence with its corresponding image. Despite the promising performance, MMT models still suffer the problem of input degradation: models focus more on textual information while visual information is generally overlooked. In this paper, we endeavor to improve MMT performance by increasing visual awareness from an information theoretic perspective. In detail, we decompose the informative visual signals into two parts: source-specific information and target-specific information. We use mutual information to quantify them and propose two methods for objective optimization to better leverage visual signals. Experiments on two datasets demonstrate that our approach can effectively enhance the visual awareness of MMT model and achieve superior results against strong baselines.
Semantic Image Fusion
Oct 13, 2021
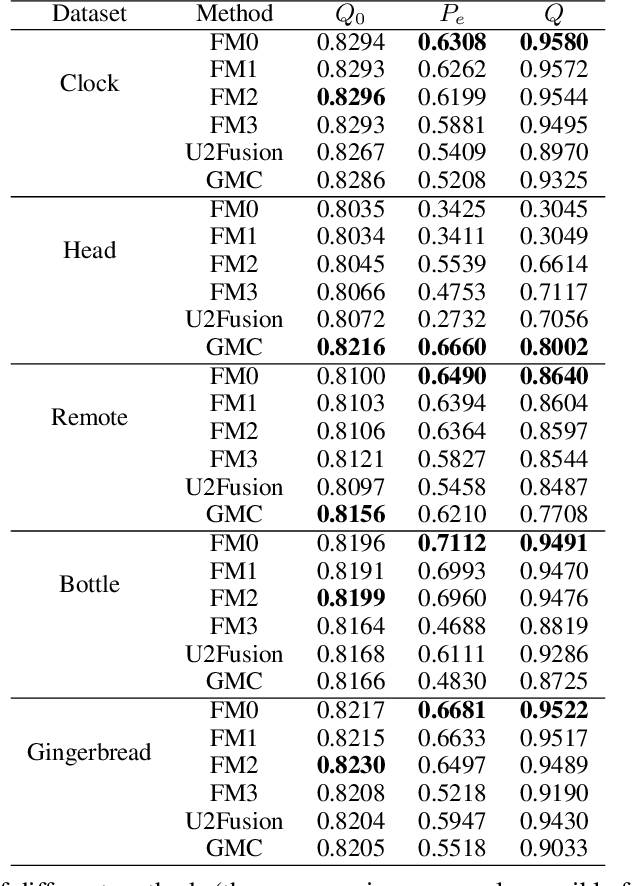
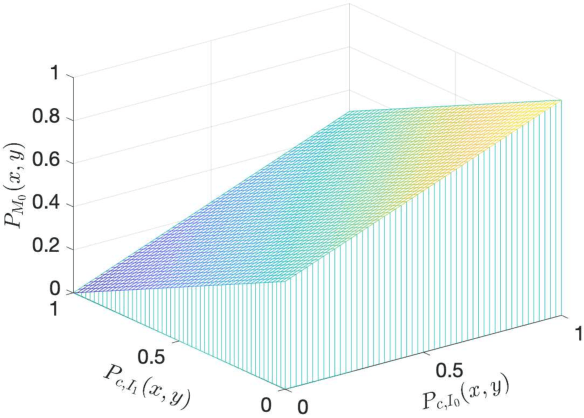
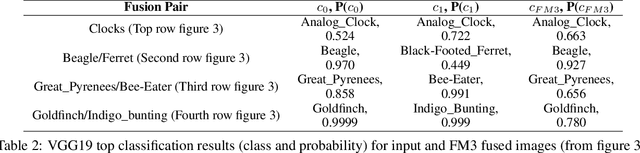
Image fusion methods and metrics for their evaluation have conventionally used pixel-based or low-level features. However, for many applications, the aim of image fusion is to effectively combine the semantic content of the input images. This paper proposes a novel system for the semantic combination of visual content using pre-trained CNN network architectures. Our proposed semantic fusion is initiated through the fusion of the top layer feature map outputs (for each input image)through gradient updating of the fused image input (so-called image optimisation). Simple "choose maximum" and "local majority" filter based fusion rules are utilised for feature map fusion. This provides a simple method to combine layer outputs and thus a unique framework to fuse single-channel and colour images within a decomposition pre-trained for classification and therefore aligned with semantic fusion. Furthermore, class activation mappings of each input image are used to combine semantic information at a higher level. The developed methods are able to give equivalent low-level fusion performance to state of the art methods while providing a unique architecture to combine semantic information from multiple images.
Label Structure Preserving Contrastive Embedding for Multi-Label Learning with Missing Labels
Sep 03, 2022
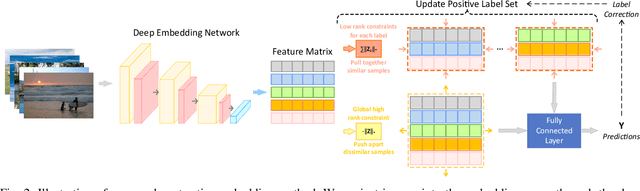
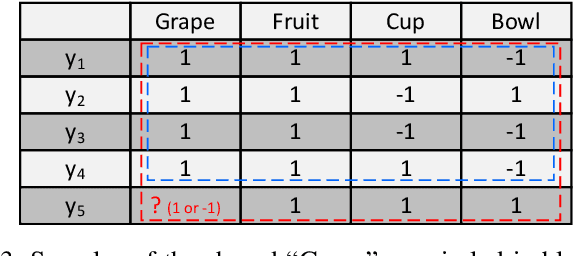
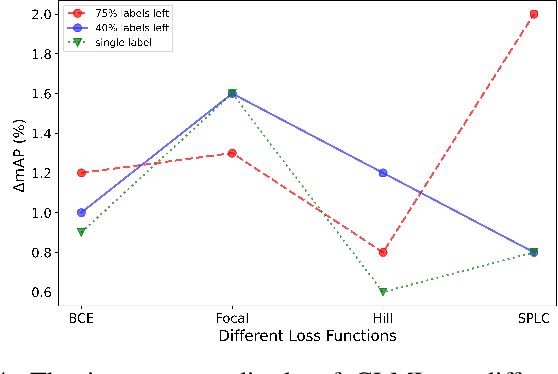
Contrastive learning (CL) has shown impressive advances in image representation learning in whichever supervised multi-class classification or unsupervised learning. However, these CL methods fail to be directly adapted to multi-label image classification due to the difficulty in defining the positive and negative instances to contrast a given anchor image in multi-label scenario, let the label missing one alone, implying that borrowing a commonly-used way from contrastive multi-class learning to define them will incur a lot of false negative instances unfavorable for learning. In this paper, with the introduction of a label correction mechanism to identify missing labels, we first elegantly generate positives and negatives for individual semantic labels of an anchor image, then define a unique contrastive loss for multi-label image classification with missing labels (CLML), the loss is able to accurately bring images close to their true positive images and false negative images, far away from their true negative images. Different from existing multi-label CL losses, CLML also preserves low-rank global and local label dependencies in the latent representation space where such dependencies have been shown to be helpful in dealing with missing labels. To the best of our knowledge, this is the first general multi-label CL loss in the missing-label scenario and thus can seamlessly be paired with those losses of any existing multi-label learning methods just via a single hyperparameter. The proposed strategy has been shown to improve the classification performance of the Resnet101 model by margins of 1.2%, 1.6%, and 1.3% respectively on three standard datasets, MSCOCO, VOC, and NUS-WIDE. Code is available at https://github.com/chuangua/ContrastiveLossMLML.
This is what a pandemic looks like: Visual framing of COVID-19 on search engines
Sep 22, 2022
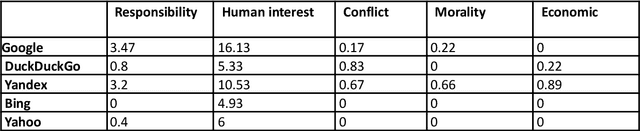
In today's high-choice media environment, search engines play an integral role in informing individuals and societies about the latest events. The importance of search algorithms is even higher at the time of crisis, when users search for information to understand the causes and the consequences of the current situation and decide on their course of action. In our paper, we conduct a comparative audit of how different search engines prioritize visual information related to COVID-19 and what consequences it has for the representation of the pandemic. Using a virtual agent-based audit approach, we examine image search results for the term "coronavirus" in English, Russian and Chinese on five major search engines: Google, Yandex, Bing, Yahoo, and DuckDuckGo. Specifically, we focus on how image search results relate to generic news frames (e.g., the attribution of responsibility, human interest, and economics) used in relation to COVID-19 and how their visual composition varies between the search engines.
KOLOMVERSE: KRISO open large-scale image dataset for object detection in the maritime universe
Jun 20, 2022

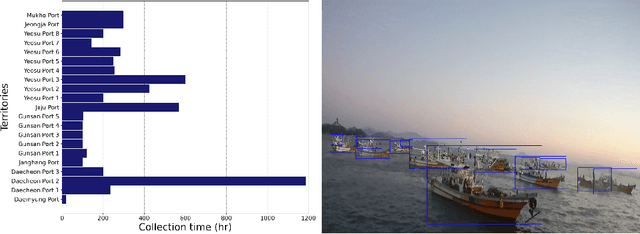
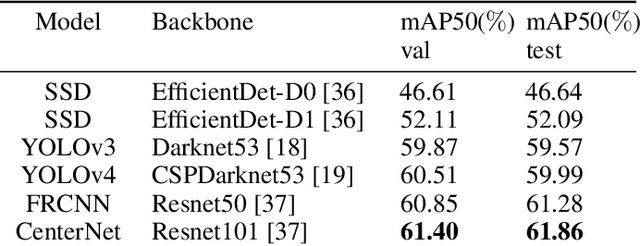
Over the years, datasets have been developed for various object detection tasks. Object detection in the maritime domain is essential for the safety and navigation of ships. However, there is still a lack of publicly available large-scale datasets in the maritime domain. To overcome this challenge, we present KOLOMVERSE, an open large-scale image dataset for object detection in the maritime domain by KRISO (Korea Research Institute of Ships and Ocean Engineering). We collected 5,845 hours of video data captured from 21 territorial waters of South Korea. Through an elaborate data quality assessment process, we gathered around 2,151,470 4K resolution images from the video data. This dataset considers various environments: weather, time, illumination, occlusion, viewpoint, background, wind speed, and visibility. The KOLOMVERSE consists of five classes (ship, buoy, fishnet buoy, lighthouse and wind farm) for maritime object detection. The dataset has images of 3840$\times$2160 pixels and to our knowledge, it is by far the largest publicly available dataset for object detection in the maritime domain. We performed object detection experiments and evaluated our dataset on several pre-trained state-of-the-art architectures to show the effectiveness and usefulness of our dataset. The dataset is available at: \url{https://github.com/MaritimeDataset/KOLOMVERSE}.
Adaptive Patch Exiting for Scalable Single Image Super-Resolution
Mar 22, 2022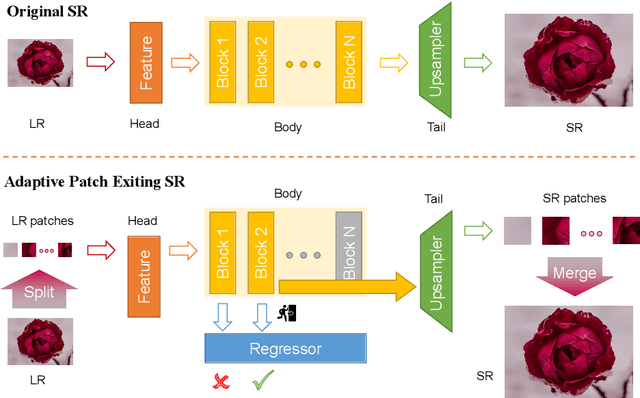
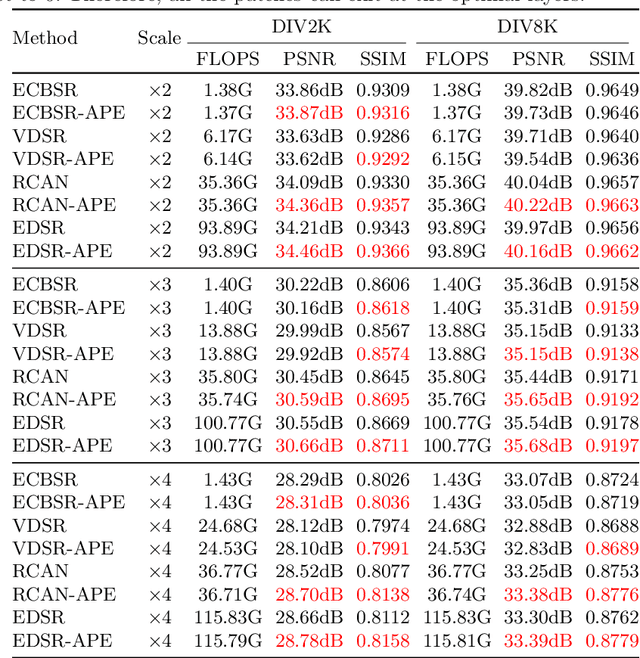
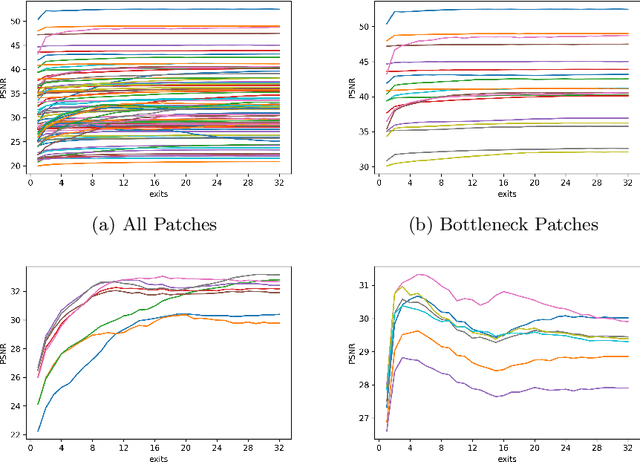
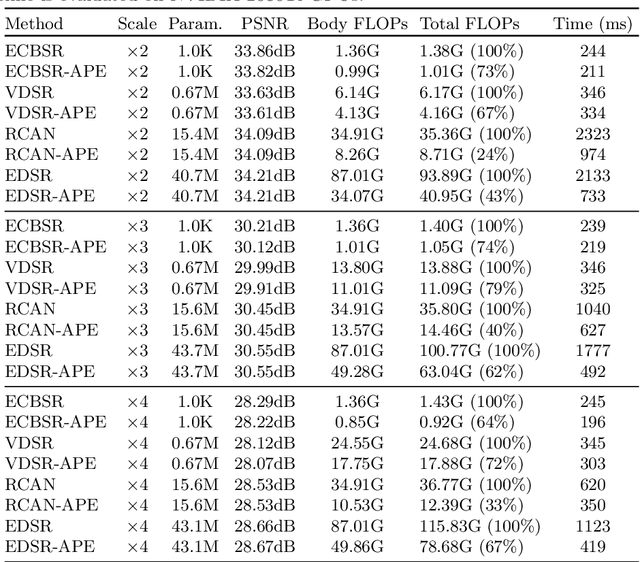
Since the future of computing is heterogeneous, scalability is a crucial problem for single image super-resolution. Recent works try to train one network, which can be deployed on platforms with different capacities. However, they rely on the pixel-wise sparse convolution, which is not hardware-friendly and achieves limited practical speedup. As image can be divided into patches, which have various restoration difficulties, we present a scalable method based on Adaptive Patch Exiting (APE) to achieve more practical speedup. Specifically, we propose to train a regressor to predict the incremental capacity of each layer for the patch. Once the incremental capacity is below the threshold, the patch can exit at the specific layer. Our method can easily adjust the trade-off between performance and efficiency by changing the threshold of incremental capacity. Furthermore, we propose a novel strategy to enable the network training of our method. We conduct extensive experiments across various backbones, datasets and scaling factors to demonstrate the advantages of our method. Code will be released.