 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Half Wavelet Attention on M-Net+ for Low-Light Image Enhancement
Mar 02, 2022
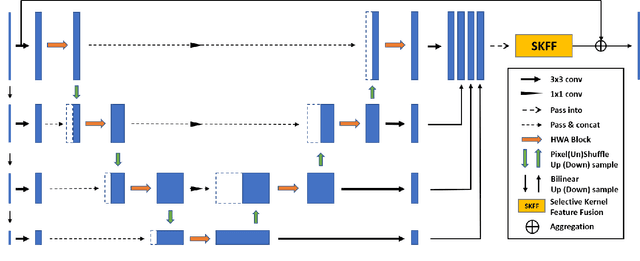
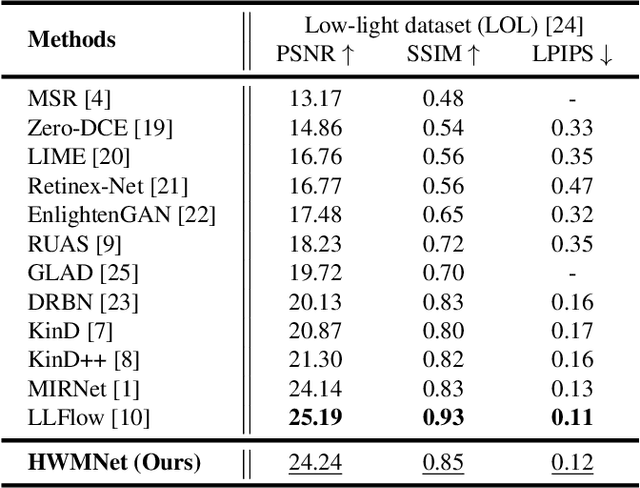
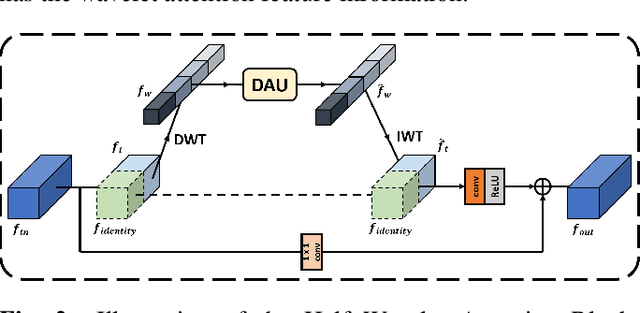

Low-Light Image Enhancement is a computer vision task which intensifies the dark images to appropriate brightness. It can also be seen as an ill-posed problem in image restoration domain. With the success of deep neural networks, the convolutional neural networks surpass the traditional algorithm-based methods and become the mainstream in the computer vision area. To advance the performance of enhancement algorithms, we propose an image enhancement network (HWMNet) based on an improved hierarchical model: M-Net+. Specifically, we use a half wavelet attention block on M-Net+ to enrich the features from wavelet domain. Furthermore, our HWMNet has competitive performance results on two image enhancement datasets in terms of quantitative metrics and visual quality. The source code and pretrained model are available at https://github.com/FanChiMao/HWMNet.
MonoNHR: Monocular Neural Human Renderer
Oct 02, 2022
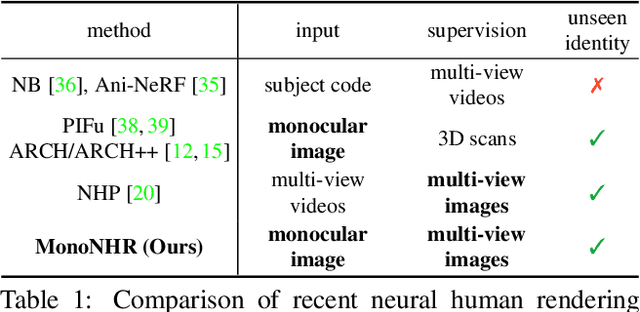
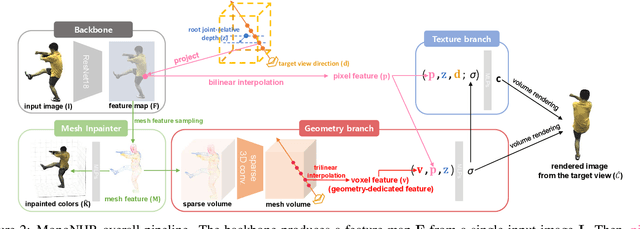
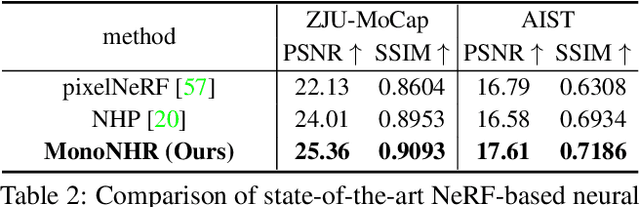
Existing neural human rendering methods struggle with a single image input due to the lack of information in invisible areas and the depth ambiguity of pixels in visible areas. In this regard, we propose Monocular Neural Human Renderer (MonoNHR), a novel approach that renders robust free-viewpoint images of an arbitrary human given only a single image. MonoNHR is the first method that (i) renders human subjects never seen during training in a monocular setup, and (ii) is trained in a weakly-supervised manner without geometry supervision. First, we propose to disentangle 3D geometry and texture features and to condition the texture inference on the 3D geometry features. Second, we introduce a Mesh Inpainter module that inpaints the occluded parts exploiting human structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, and HUMBI datasets show that our approach significantly outperforms the recent methods adapted to the monocular case.
Separating Content and Style for Unsupervised Image-to-Image Translation
Oct 27, 2021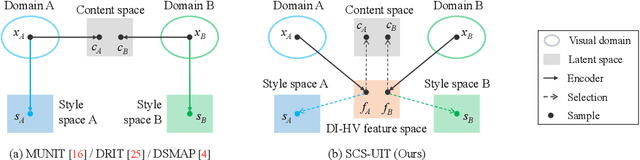
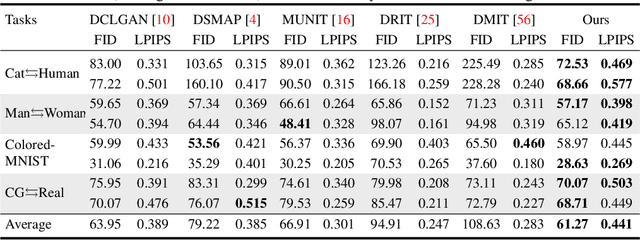
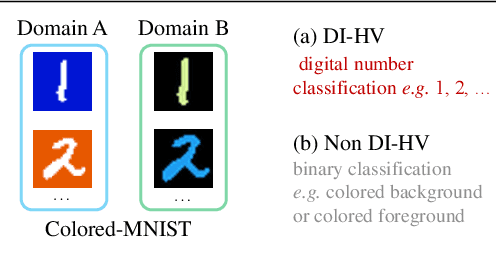
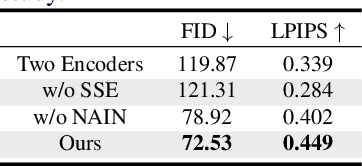
Unsupervised image-to-image translation aims to learn the mapping between two visual domains with unpaired samples. Existing works focus on disentangling domain-invariant content code and domain-specific style code individually for multimodal purposes. However, less attention has been paid to interpreting and manipulating the translated image. In this paper, we propose to separate the content code and style code simultaneously in a unified framework. Based on the correlation between the latent features and the high-level domain-invariant tasks, the proposed framework demonstrates superior performance in multimodal translation, interpretability and manipulation of the translated image. Experimental results show that the proposed approach outperforms the existing unsupervised image translation methods in terms of visual quality and diversity.
AGCN: Augmented Graph Convolutional Network for Lifelong Multi-label Image Recognition
Mar 10, 2022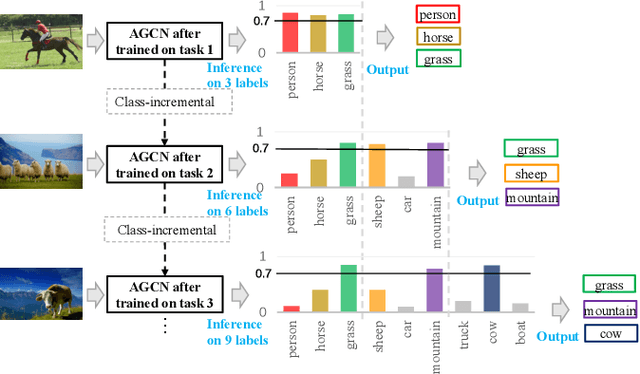
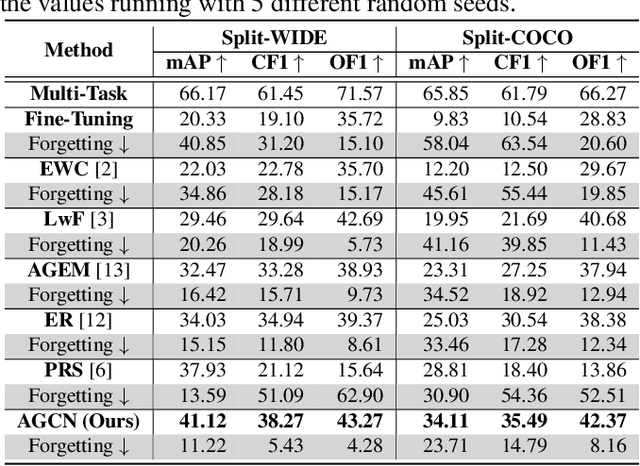
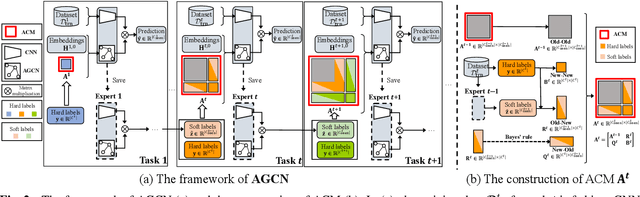
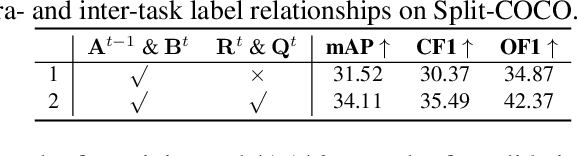
The Lifelong Multi-Label (LML) image recognition builds an online class-incremental classifier in a sequential multi-label image recognition data stream. The key challenges of LML image recognition are the construction of label relationships on Partial Labels of training data and the Catastrophic Forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN) model that can construct the label relationships across the sequential recognition tasks and sustain the catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics while the inter-task relationships leverage both hard and soft labels from data and a constructed expert network. Then, based on the ACM, the proposed AGCN captures label dependencies with dynamic augmented structure and yields effective class representations. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving loss as a constraint to the construction of label relationships. The proposed method is evaluated using two multi-label image benchmarks and the experimental results show that the proposed method is effective for LML image recognition and can build convincing correlation across tasks even if the labels of previous tasks are missing. Our code is available at https://github.com/Kaile-Du/AGCN.
Towards Stable Co-saliency Detection and Object Co-segmentation
Sep 25, 2022



In this paper, we present a novel model for simultaneous stable co-saliency detection (CoSOD) and object co-segmentation (CoSEG). To detect co-saliency (segmentation) accurately, the core problem is to well model inter-image relations between an image group. Some methods design sophisticated modules, such as recurrent neural network (RNN), to address this problem. However, order-sensitive problem is the major drawback of RNN, which heavily affects the stability of proposed CoSOD (CoSEG) model. In this paper, inspired by RNN-based model, we first propose a multi-path stable recurrent unit (MSRU), containing dummy orders mechanisms (DOM) and recurrent unit (RU). Our proposed MSRU not only helps CoSOD (CoSEG) model captures robust inter-image relations, but also reduces order-sensitivity, resulting in a more stable inference and training process. { Moreover, we design a cross-order contrastive loss (COCL) that can further address order-sensitive problem by pulling close the feature embedding generated from different input orders.} We validate our model on five widely used CoSOD datasets (CoCA, CoSOD3k, Cosal2015, iCoseg and MSRC), and three widely used datasets (Internet, iCoseg and PASCAL-VOC) for object co-segmentation, the performance demonstrates the superiority of the proposed approach as compared to the state-of-the-art (SOTA) methods.
Hand Gestures Recognition in Videos Taken with Lensless Camera
Oct 15, 2022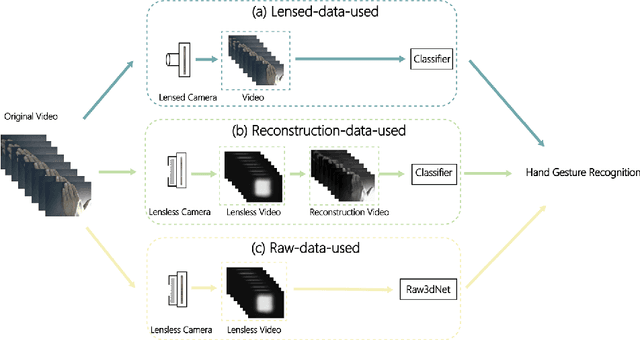
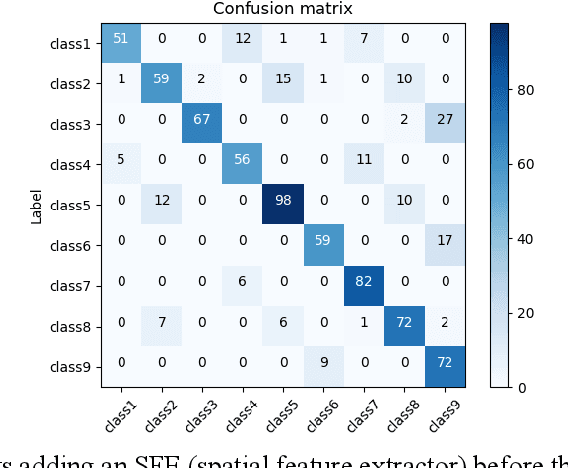
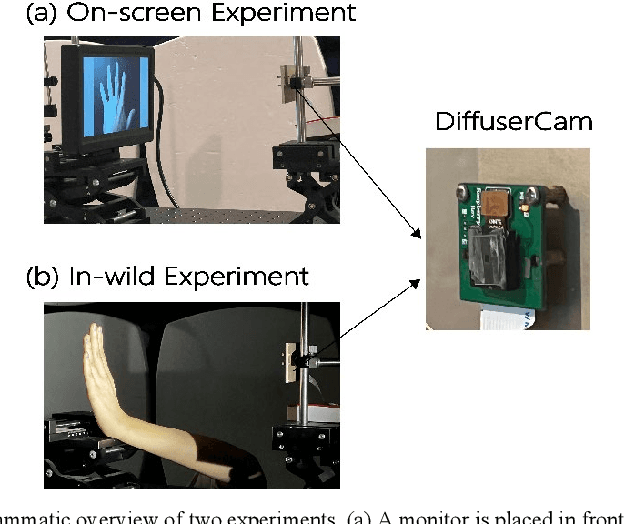

A lensless camera is an imaging system that uses a mask in place of a lens, making it thinner, lighter, and less expensive than a lensed camera. However, additional complex computation and time are required for image reconstruction. This work proposes a deep learning model named Raw3dNet that recognizes hand gestures directly on raw videos captured by a lensless camera without the need for image restoration. In addition to conserving computational resources, the reconstruction-free method provides privacy protection. Raw3dNet is a novel end-to-end deep neural network model for the recognition of hand gestures in lensless imaging systems. It is created specifically for raw video captured by a lensless camera and has the ability to properly extract and combine temporal and spatial features. The network is composed of two stages: 1. spatial feature extractor (SFE), which enhances the spatial features of each frame prior to temporal convolution; 2. 3D-ResNet, which implements spatial and temporal convolution of video streams. The proposed model achieves 98.59% accuracy on the Cambridge Hand Gesture dataset in the lensless optical experiment, which is comparable to the lensed-camera result. Additionally, the feasibility of physical object recognition is assessed. Furtherly, we show that the recognition can be achieved with respectable accuracy using only a tiny portion of the original raw data, indicating the potential for reducing data traffic in cloud computing scenarios.
Draw Your Art Dream: Diverse Digital Art Synthesis with Multimodal Guided Diffusion
Sep 28, 2022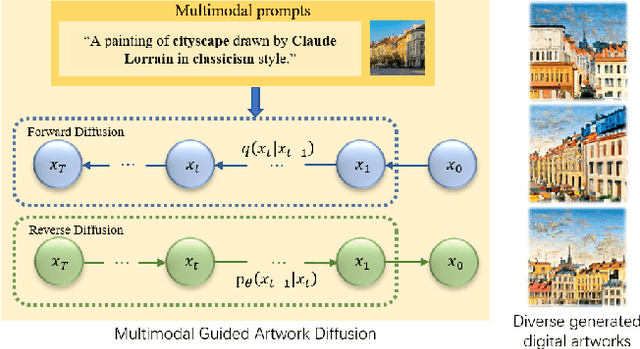



Digital art synthesis is receiving increasing attention in the multimedia community because of engaging the public with art effectively. Current digital art synthesis methods usually use single-modality inputs as guidance, thereby limiting the expressiveness of the model and the diversity of generated results. To solve this problem, we propose the multimodal guided artwork diffusion (MGAD) model, which is a diffusion-based digital artwork generation approach that utilizes multimodal prompts as guidance to control the classifier-free diffusion model. Additionally, the contrastive language-image pretraining (CLIP) model is used to unify text and image modalities. Extensive experimental results on the quality and quantity of the generated digital art paintings confirm the effectiveness of the combination of the diffusion model and multimodal guidance. Code is available at https://github.com/haha-lisa/MGAD-multimodal-guided-artwork-diffusion.
What to Hide from Your Students: Attention-Guided Masked Image Modeling
Mar 23, 2022
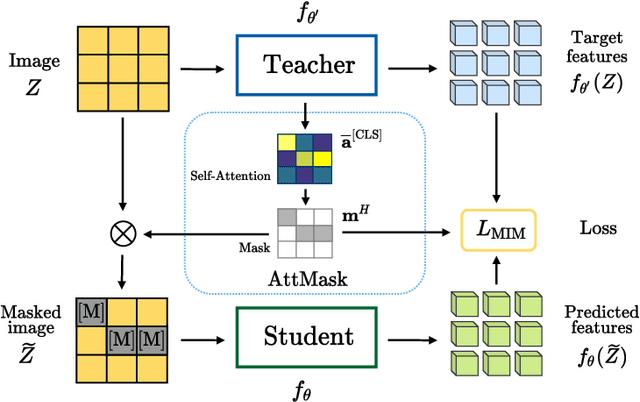
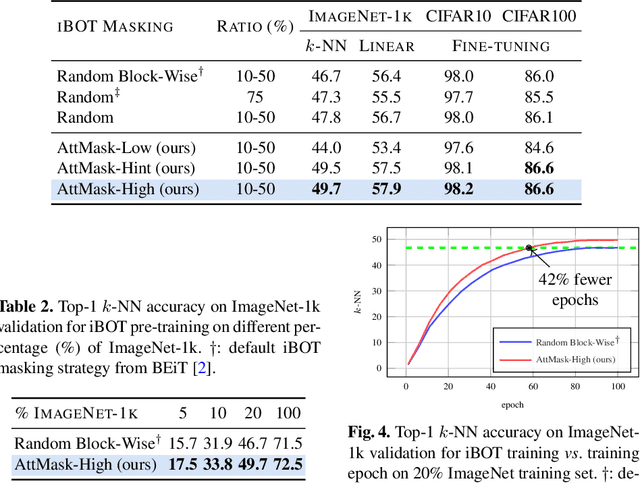
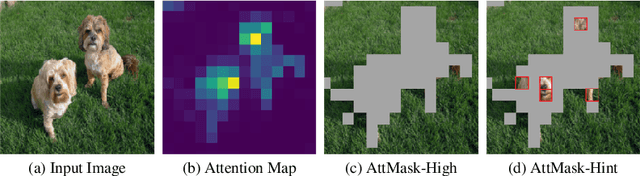
Transformers and masked language modeling are quickly being adopted and explored in computer vision as vision transformers and masked image modeling (MIM). In this work, we argue that image token masking is fundamentally different from token masking in text, due to the amount and correlation of tokens in an image. In particular, to generate a challenging pretext task for MIM, we advocate a shift from random masking to informed masking. We develop and exhibit this idea in the context of distillation-based MIM, where a teacher transformer encoder generates an attention map, which we use to guide masking for the student encoder. We thus introduce a novel masking strategy, called attention-guided masking (AttMask), and we demonstrate its effectiveness over random masking for dense distillation-based MIM as well as plain distillation-based self-supervised learning on classification tokens. We confirm that AttMask accelerates the learning process and improves the performance on a variety of downstream tasks.
Graph Flow: Cross-layer Graph Flow Distillation for Dual Efficient Medical Image Segmentation
Mar 29, 2022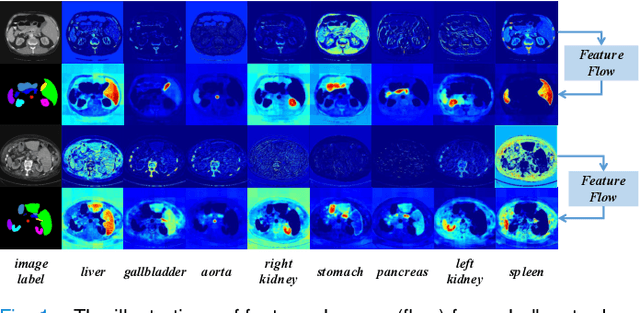
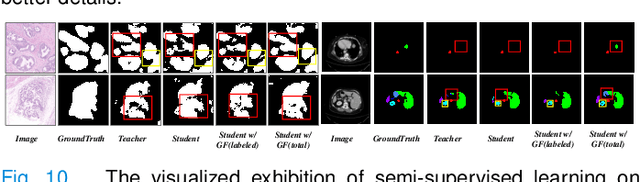
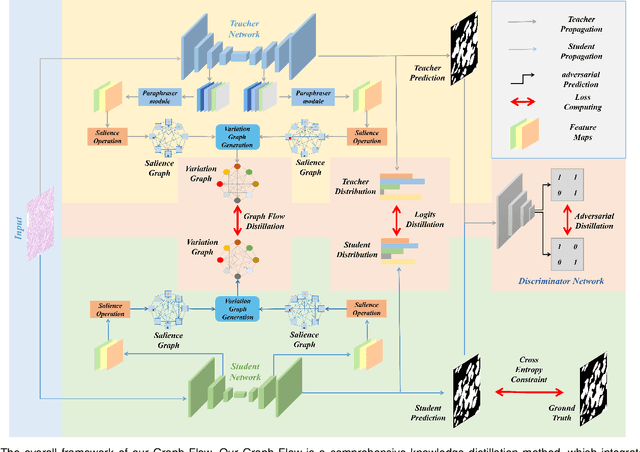
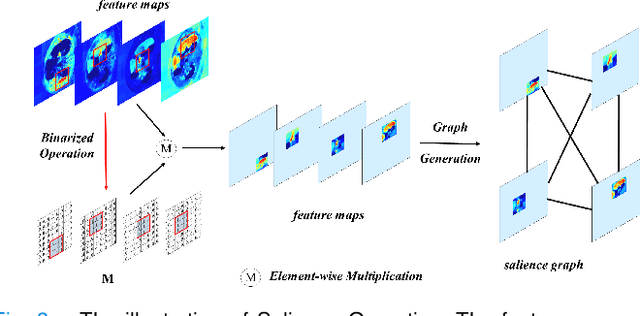
With the development of deep convolutional neural networks, medical image segmentation has achieved a series of breakthroughs in recent years. However, the higher-performance convolutional neural networks always mean numerous parameters and high computation costs, which will hinder the applications in clinical scenarios. Meanwhile, the scarceness of large-scale annotated medical image datasets further impedes the application of high-performance networks. To tackle these problems, we propose Graph Flow, a comprehensive knowledge distillation framework, for both network-efficiency and annotation-efficiency medical image segmentation. Specifically, our core Graph Flow Distillation transfer the essence of cross-layer variations from a well-trained cumbersome teacher network to a non-trained compact student network. In addition, an unsupervised Paraphraser Module is designed to purify the knowledge of the teacher network, which is also beneficial for the stabilization of training procedure. Furthermore, we build a unified distillation framework by integrating the adversarial distillation and the vanilla logits distillation, which can further refine the final predictions of the compact network. Extensive experiments conducted on Gastric Cancer Segmentation Dataset and Synapse Multi-organ Segmentation Dataset demonstrate the prominent ability of our method which achieves state-of-the-art performance on these different-modality and multi-category medical image datasets. Moreover, we demonstrate the effectiveness of our Graph Flow through a new semi-supervised paradigm for dual efficient medical image segmentation. Our code will be available at Graph Flow.
Let's Enhance: A Deep Learning Approach to Extreme Deblurring of Text Images
Nov 18, 2022
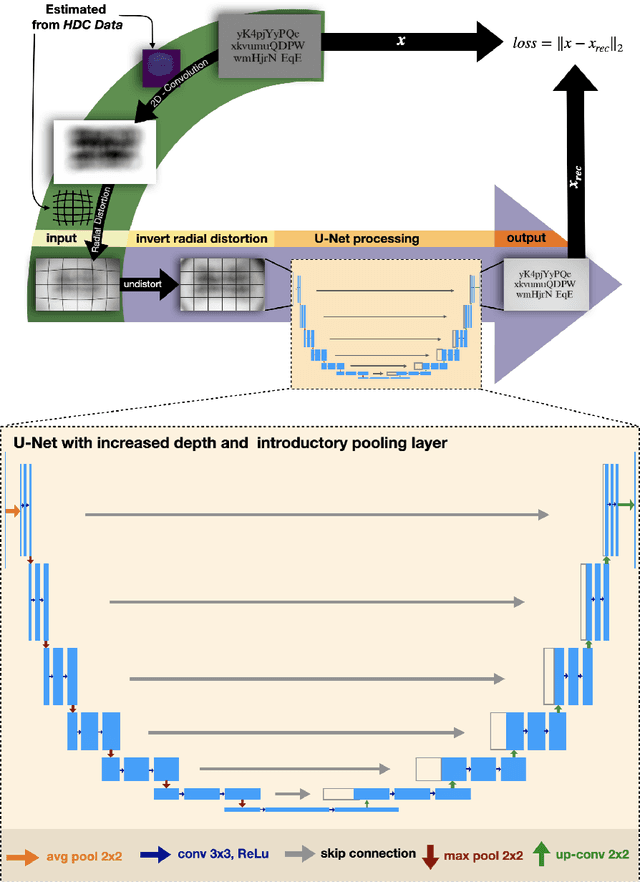
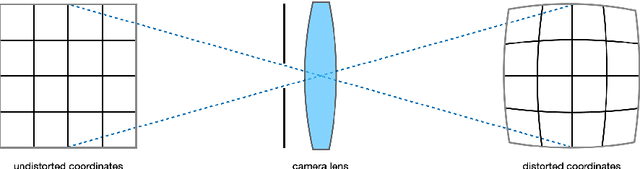
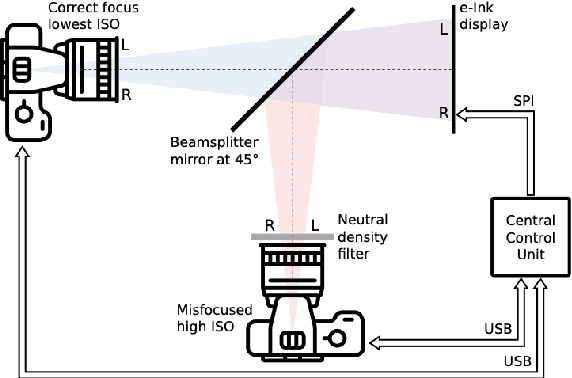
This work presents a novel deep-learning-based pipeline for the inverse problem of image deblurring, leveraging augmentation and pre-training with synthetic data. Our results build on our winning submission to the recent Helsinki Deblur Challenge 2021, whose goal was to explore the limits of state-of-the-art deblurring algorithms in a real-world data setting. The task of the challenge was to deblur out-of-focus images of random text, thereby in a downstream task, maximizing an optical-character-recognition-based score function. A key step of our solution is the data-driven estimation of the physical forward model describing the blur process. This enables a stream of synthetic data, generating pairs of ground-truth and blurry images on-the-fly, which is used for an extensive augmentation of the small amount of challenge data provided. The actual deblurring pipeline consists of an approximate inversion of the radial lens distortion (determined by the estimated forward model) and a U-Net architecture, which is trained end-to-end. Our algorithm was the only one passing the hardest challenge level, achieving over 70% character recognition accuracy. Our findings are well in line with the paradigm of data-centric machine learning, and we demonstrate its effectiveness in the context of inverse problems. Apart from a detailed presentation of our methodology, we also analyze the importance of several design choices in a series of ablation studies. The code of our challenge submission is available under https://github.com/theophil-trippe/HDC_TUBerlin_version_1.