 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reward Guided Latent Consistency Distillation
Mar 16, 2024

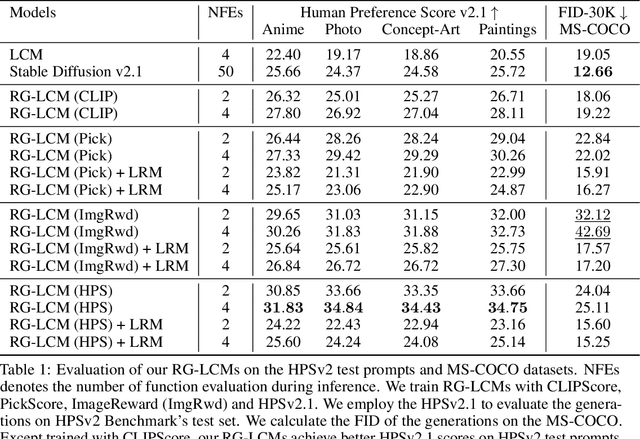
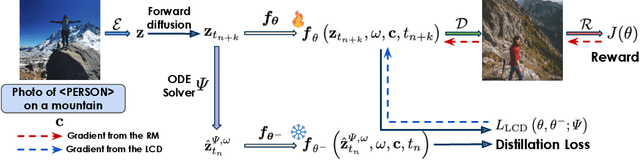

Latent Consistency Distillation (LCD) has emerged as a promising paradigm for efficient text-to-image synthesis. By distilling a latent consistency model (LCM) from a pre-trained teacher latent diffusion model (LDM), LCD facilitates the generation of high-fidelity images within merely 2 to 4 inference steps. However, the LCM's efficient inference is obtained at the cost of the sample quality. In this paper, we propose compensating the quality loss by aligning LCM's output with human preference during training. Specifically, we introduce Reward Guided LCD (RG-LCD), which integrates feedback from a reward model (RM) into the LCD process by augmenting the original LCD loss with the objective of maximizing the reward associated with LCM's single-step generation. As validated through human evaluation, when trained with the feedback of a good RM, the 2-step generations from our RG-LCM are favored by humans over the 50-step DDIM samples from the teacher LDM, representing a 25 times inference acceleration without quality loss. As directly optimizing towards differentiable RMs can suffer from over-optimization, we overcome this difficulty by proposing the use of a latent proxy RM (LRM). This novel component serves as an intermediary, connecting our LCM with the RM. Empirically, we demonstrate that incorporating the LRM into our RG-LCD successfully avoids high-frequency noise in the generated images, contributing to both improved FID on MS-COCO and a higher HPSv2.1 score on HPSv2's test set, surpassing those achieved by the baseline LCM.
Forward Learning of Graph Neural Networks
Mar 16, 2024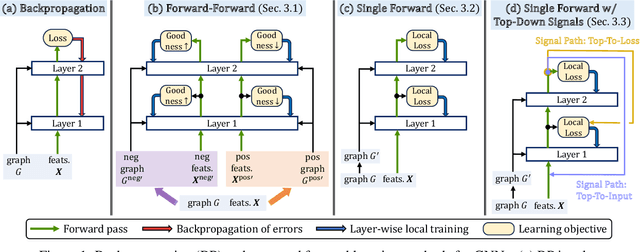
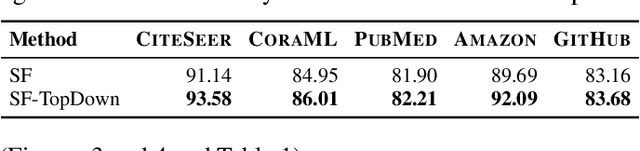
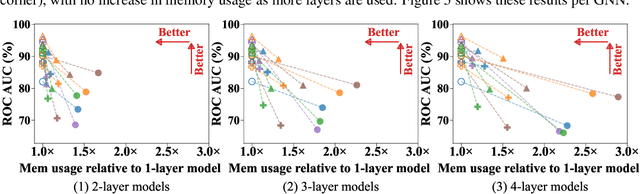
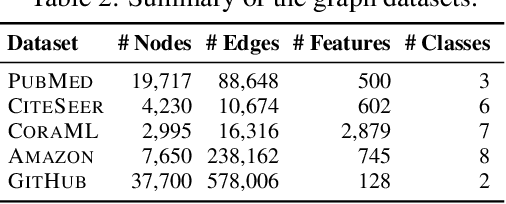
Graph neural networks (GNNs) have achieved remarkable success across a wide range of applications, such as recommendation, drug discovery, and question answering. Behind the success of GNNs lies the backpropagation (BP) algorithm, which is the de facto standard for training deep neural networks (NNs). However, despite its effectiveness, BP imposes several constraints, which are not only biologically implausible, but also limit the scalability, parallelism, and flexibility in learning NNs. Examples of such constraints include storage of neural activities computed in the forward pass for use in the subsequent backward pass, and the dependence of parameter updates on non-local signals. To address these limitations, the forward-forward algorithm (FF) was recently proposed as an alternative to BP in the image classification domain, which trains NNs by performing two forward passes over positive and negative data. Inspired by this advance, we propose ForwardGNN in this work, a new forward learning procedure for GNNs, which avoids the constraints imposed by BP via an effective layer-wise local forward training. ForwardGNN extends the original FF to deal with graph data and GNNs, and makes it possible to operate without generating negative inputs (hence no longer forward-forward). Further, ForwardGNN enables each layer to learn from both the bottom-up and top-down signals without relying on the backpropagation of errors. Extensive experiments on real-world datasets show the effectiveness and generality of the proposed forward graph learning framework. We release our code at https://github.com/facebookresearch/forwardgnn.
Analyzing Data Augmentation for Medical Images: A Case Study in Ultrasound Images
Mar 14, 2024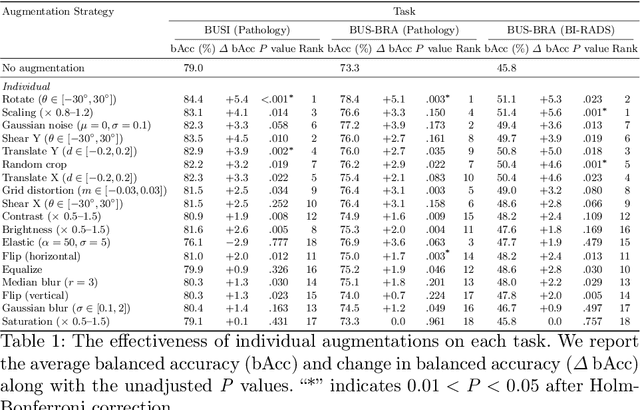
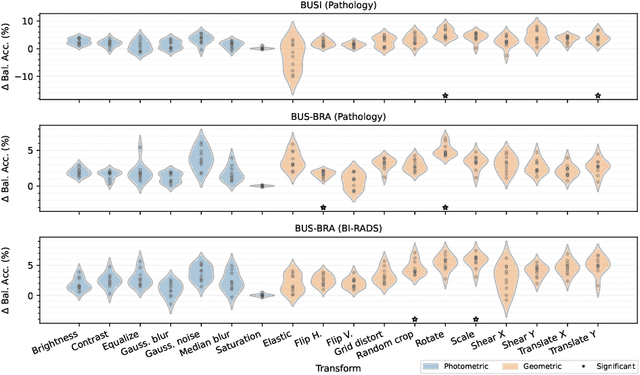
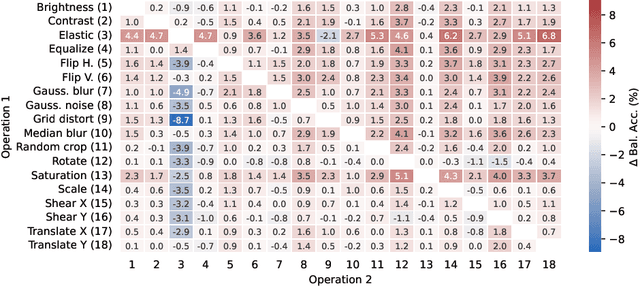
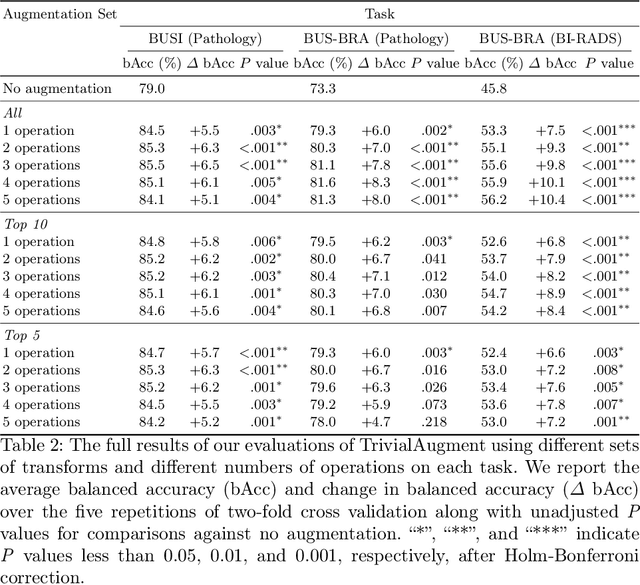
Data augmentation is one of the most effective techniques to improve the generalization performance of deep neural networks. Yet, despite often facing limited data availability in medical image analysis, it is frequently underutilized. This appears to be due to a gap in our collective understanding of the efficacy of different augmentation techniques across medical imaging tasks and modalities. One domain where this is especially true is breast ultrasound images. This work addresses this issue by analyzing the effectiveness of different augmentation techniques for the classification of breast lesions in ultrasound images. We assess the generalizability of our findings across several datasets, demonstrate that certain augmentations are far more effective than others, and show that their usage leads to significant performance gains.
Spatiotemporal Diffusion Model with Paired Sampling for Accelerated Cardiac Cine MRI
Mar 13, 2024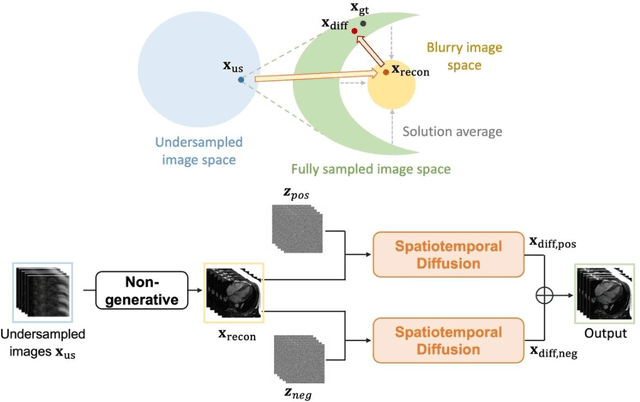
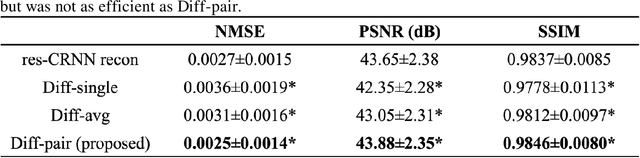
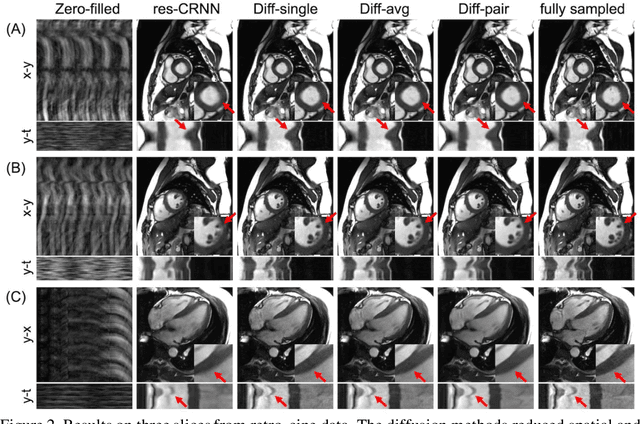
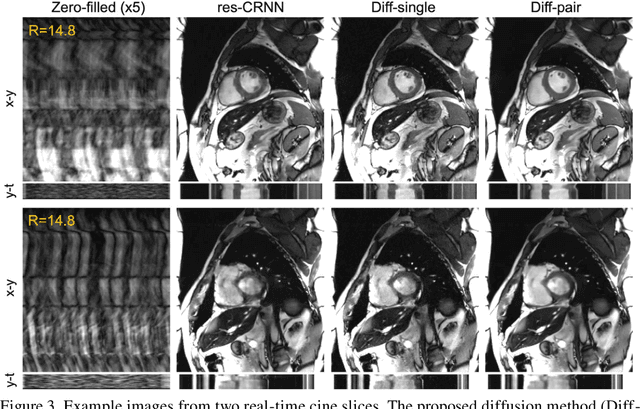
Current deep learning reconstruction for accelerated cardiac cine MRI suffers from spatial and temporal blurring. We aim to improve image sharpness and motion delineation for cine MRI under high undersampling rates. A spatiotemporal diffusion enhancement model conditional on an existing deep learning reconstruction along with a novel paired sampling strategy was developed. The diffusion model provided sharper tissue boundaries and clearer motion than the original reconstruction in experts evaluation on clinical data. The innovative paired sampling strategy substantially reduced artificial noises in the generative results.
Training Generative Image Super-Resolution Models by Wavelet-Domain Losses Enables Better Control of Artifacts
Feb 29, 2024Super-resolution (SR) is an ill-posed inverse problem, where the size of the set of feasible solutions that are consistent with a given low-resolution image is very large. Many algorithms have been proposed to find a "good" solution among the feasible solutions that strike a balance between fidelity and perceptual quality. Unfortunately, all known methods generate artifacts and hallucinations while trying to reconstruct high-frequency (HF) image details. A fundamental question is: Can a model learn to distinguish genuine image details from artifacts? Although some recent works focused on the differentiation of details and artifacts, this is a very challenging problem and a satisfactory solution is yet to be found. This paper shows that the characterization of genuine HF details versus artifacts can be better learned by training GAN-based SR models using wavelet-domain loss functions compared to RGB-domain or Fourier-space losses. Although wavelet-domain losses have been used in the literature before, they have not been used in the context of the SR task. More specifically, we train the discriminator only on the HF wavelet sub-bands instead of on RGB images and the generator is trained by a fidelity loss over wavelet subbands to make it sensitive to the scale and orientation of structures. Extensive experimental results demonstrate that our model achieves better perception-distortion trade-off according to multiple objective measures and visual evaluations.
One Category One Prompt: Dataset Distillation using Diffusion Models
Mar 11, 2024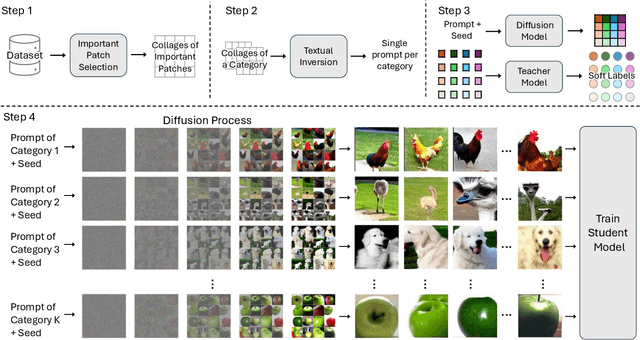
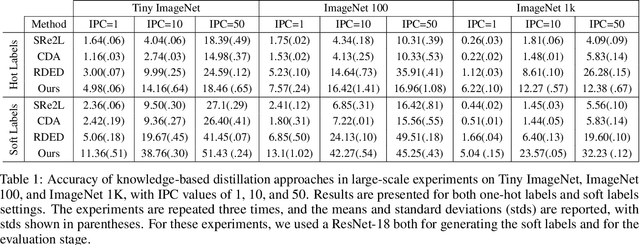
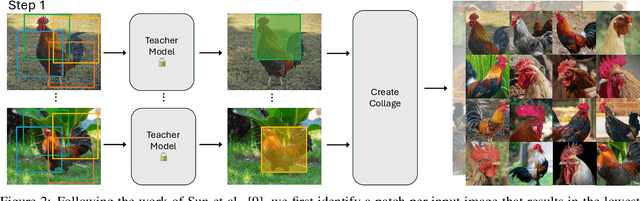
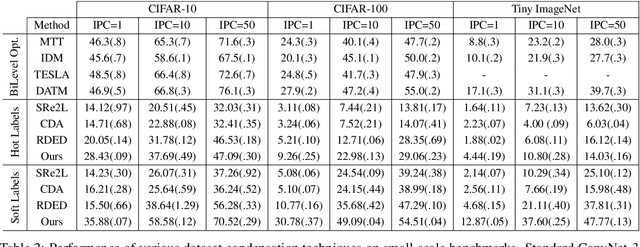
The extensive amounts of data required for training deep neural networks pose significant challenges on storage and transmission fronts. Dataset distillation has emerged as a promising technique to condense the information of massive datasets into a much smaller yet representative set of synthetic samples. However, traditional dataset distillation approaches often struggle to scale effectively with high-resolution images and more complex architectures due to the limitations in bi-level optimization. Recently, several works have proposed exploiting knowledge distillation with decoupled optimization schemes to scale up dataset distillation. Although these methods effectively address the scalability issue, they rely on extensive image augmentations requiring the storage of soft labels for augmented images. In this paper, we introduce Dataset Distillation using Diffusion Models (D3M) as a novel paradigm for dataset distillation, leveraging recent advancements in generative text-to-image foundation models. Our approach utilizes textual inversion, a technique for fine-tuning text-to-image generative models, to create concise and informative representations for large datasets. By employing these learned text prompts, we can efficiently store and infer new samples for introducing data variability within a fixed memory budget. We show the effectiveness of our method through extensive experiments across various computer vision benchmark datasets with different memory budgets.
Distribution-Aware Data Expansion with Diffusion Models
Mar 11, 2024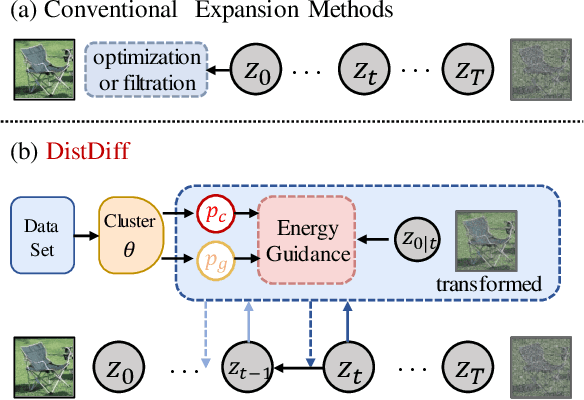

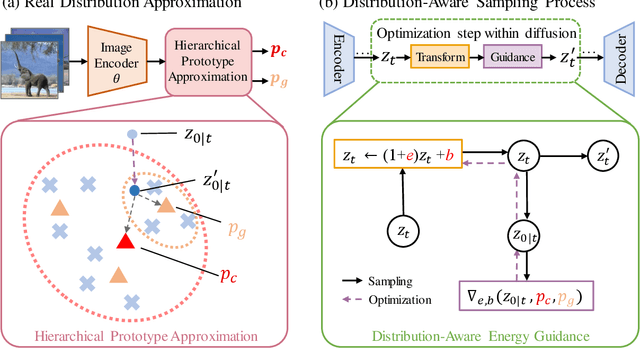
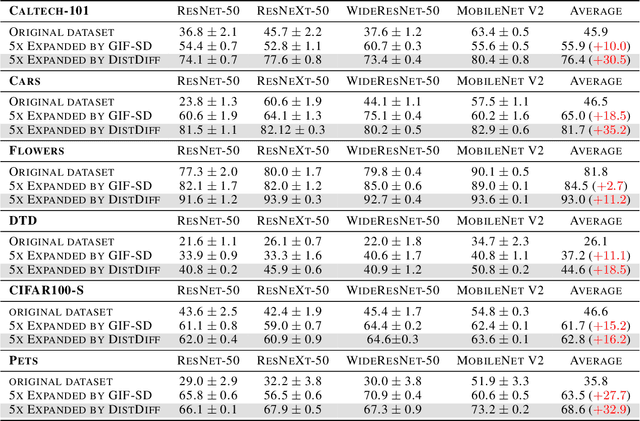
The scale and quality of a dataset significantly impact the performance of deep models. However, acquiring large-scale annotated datasets is both a costly and time-consuming endeavor. To address this challenge, dataset expansion technologies aim to automatically augment datasets, unlocking the full potential of deep models. Current data expansion methods encompass image transformation-based and synthesis-based methods. The transformation-based methods introduce only local variations, resulting in poor diversity. While image synthesis-based methods can create entirely new content, significantly enhancing informativeness. However, existing synthesis methods carry the risk of distribution deviations, potentially degrading model performance with out-of-distribution samples. In this paper, we propose DistDiff, an effective data expansion framework based on the distribution-aware diffusion model. DistDiff constructs hierarchical prototypes to approximate the real data distribution, optimizing latent data points within diffusion models with hierarchical energy guidance. We demonstrate its ability to generate distribution-consistent samples, achieving substantial improvements in data expansion tasks. Specifically, without additional training, DistDiff achieves a 30.7% improvement in accuracy across six image datasets compared to the model trained on original datasets and a 9.8% improvement compared to the state-of-the-art diffusion-based method. Our code is available at https://github.com/haoweiz23/DistDiff
MAP-Elites with Transverse Assessment for Multimodal Problems in Creative Domains
Mar 11, 2024The recent advances in language-based generative models have paved the way for the orchestration of multiple generators of different artefact types (text, image, audio, etc.) into one system. Presently, many open-source pre-trained models combine text with other modalities, thus enabling shared vector embeddings to be compared across different generators. Within this context we propose a novel approach to handle multimodal creative tasks using Quality Diversity evolution. Our contribution is a variation of the MAP-Elites algorithm, MAP-Elites with Transverse Assessment (MEliTA), which is tailored for multimodal creative tasks and leverages deep learned models that assess coherence across modalities. MEliTA decouples the artefacts' modalities and promotes cross-pollination between elites. As a test bed for this algorithm, we generate text descriptions and cover images for a hypothetical video game and assign each artefact a unique modality-specific behavioural characteristic. Results indicate that MEliTA can improve text-to-image mappings within the solution space, compared to a baseline MAP-Elites algorithm that strictly treats each image-text pair as one solution. Our approach represents a significant step forward in multimodal bottom-up orchestration and lays the groundwork for more complex systems coordinating multimodal creative agents in the future.
Advancing Generative Model Evaluation: A Novel Algorithm for Realistic Image Synthesis and Comparison in OCR System
Mar 01, 2024This research addresses a critical challenge in the field of generative models, particularly in the generation and evaluation of synthetic images. Given the inherent complexity of generative models and the absence of a standardized procedure for their comparison, our study introduces a pioneering algorithm to objectively assess the realism of synthetic images. This approach significantly enhances the evaluation methodology by refining the Fr\'echet Inception Distance (FID) score, allowing for a more precise and subjective assessment of image quality. Our algorithm is particularly tailored to address the challenges in generating and evaluating realistic images of Arabic handwritten digits, a task that has traditionally been near-impossible due to the subjective nature of realism in image generation. By providing a systematic and objective framework, our method not only enables the comparison of different generative models but also paves the way for improvements in their design and output. This breakthrough in evaluation and comparison is crucial for advancing the field of OCR, especially for scripts that present unique complexities, and sets a new standard in the generation and assessment of high-quality synthetic images.
Time-Efficient Light-Field Acquisition Using Coded Aperture and Events
Mar 12, 2024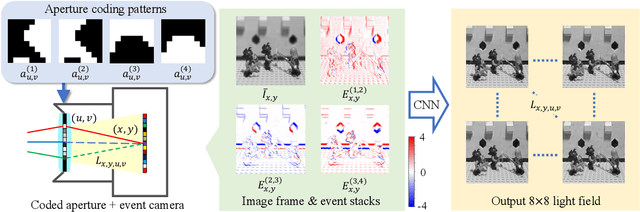
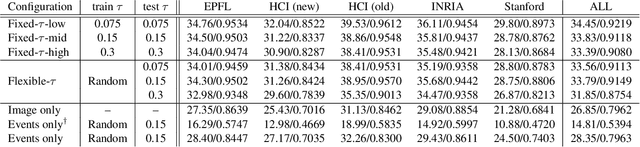
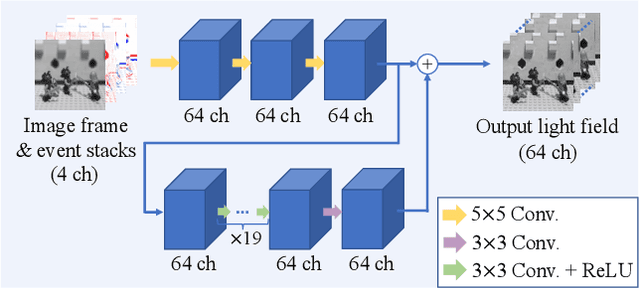
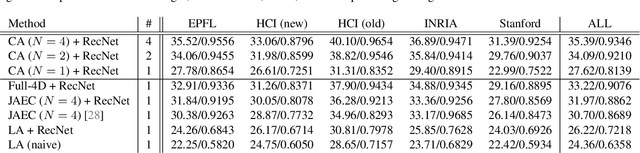
We propose a computational imaging method for time-efficient light-field acquisition that combines a coded aperture with an event-based camera. Different from the conventional coded-aperture imaging method, our method applies a sequence of coding patterns during a single exposure for an image frame. The parallax information, which is related to the differences in coding patterns, is recorded as events. The image frame and events, all of which are measured in a single exposure, are jointly used to computationally reconstruct a light field. We also designed an algorithm pipeline for our method that is end-to-end trainable on the basis of deep optics and compatible with real camera hardware. We experimentally showed that our method can achieve more accurate reconstruction than several other imaging methods with a single exposure. We also developed a hardware prototype with the potential to complete the measurement on the camera within 22 msec and demonstrated that light fields from real 3-D scenes can be obtained with convincing visual quality. Our software and supplementary video are available from our project website.