 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Shift Invariance of Max Pooling Feature Maps in Convolutional Neural Networks
Sep 19, 2022

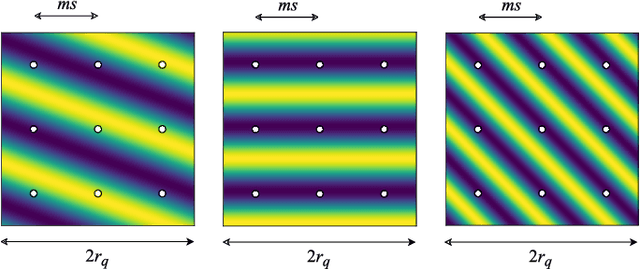
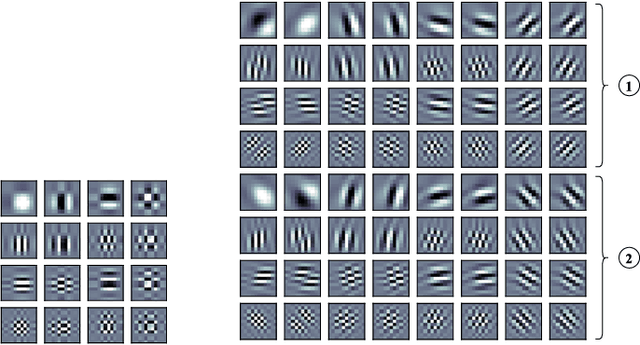
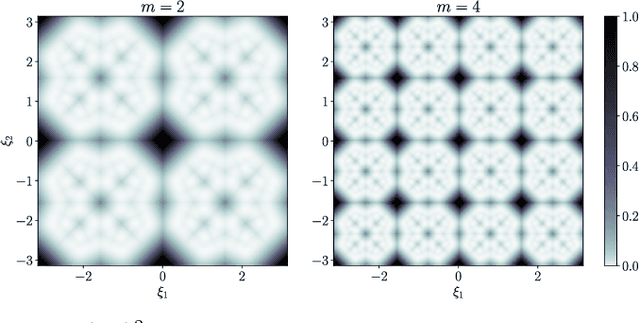
In this paper, we aim to improve the mathematical interpretability of convolutional neural networks for image classification. When trained on natural image datasets, such networks tend to learn parameters in the first layer that closely resemble oriented Gabor filters. By leveraging the properties of discrete Gabor-like convolutions, we prove that, under specific conditions, feature maps computed by the subsequent max pooling operator tend to approximate the modulus of complex Gabor-like coefficients, and as such, are stable with respect to certain input shifts. We then compute a probabilistic measure of shift invariance for these layers. More precisely, we show that some filters, depending on their frequency and orientation, are more likely than others to produce stable image representations. We experimentally validate our theory by considering a deterministic feature extractor based on the dual-tree wavelet packet transform, a particular case of discrete Gabor-like decomposition. We demonstrate a strong correlation between shift invariance on the one hand and similarity with complex modulus on the other hand.
Dual-Cycle: Self-Supervised Dual-View Fluorescence Microscopy Image Reconstruction using CycleGAN
Sep 23, 2022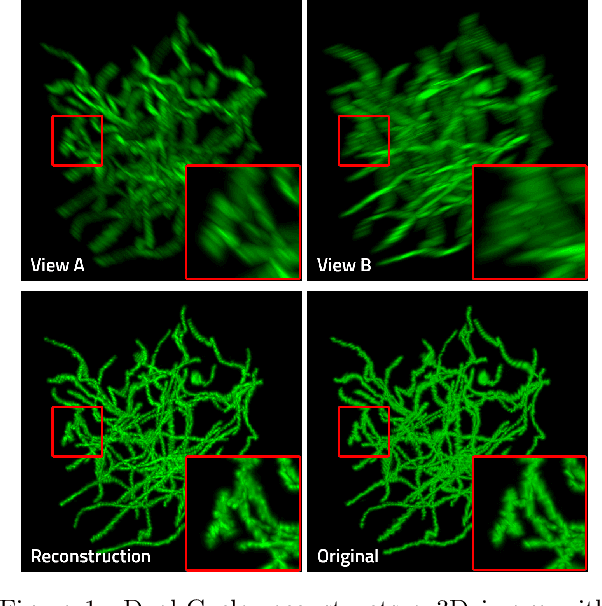

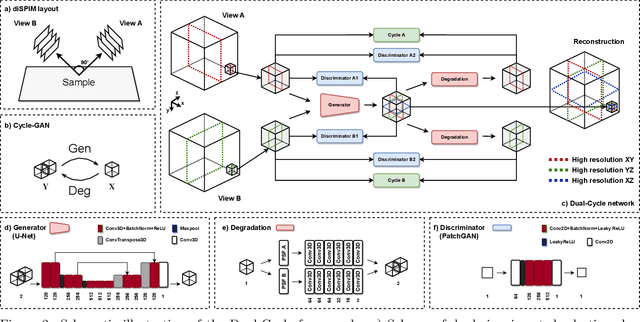
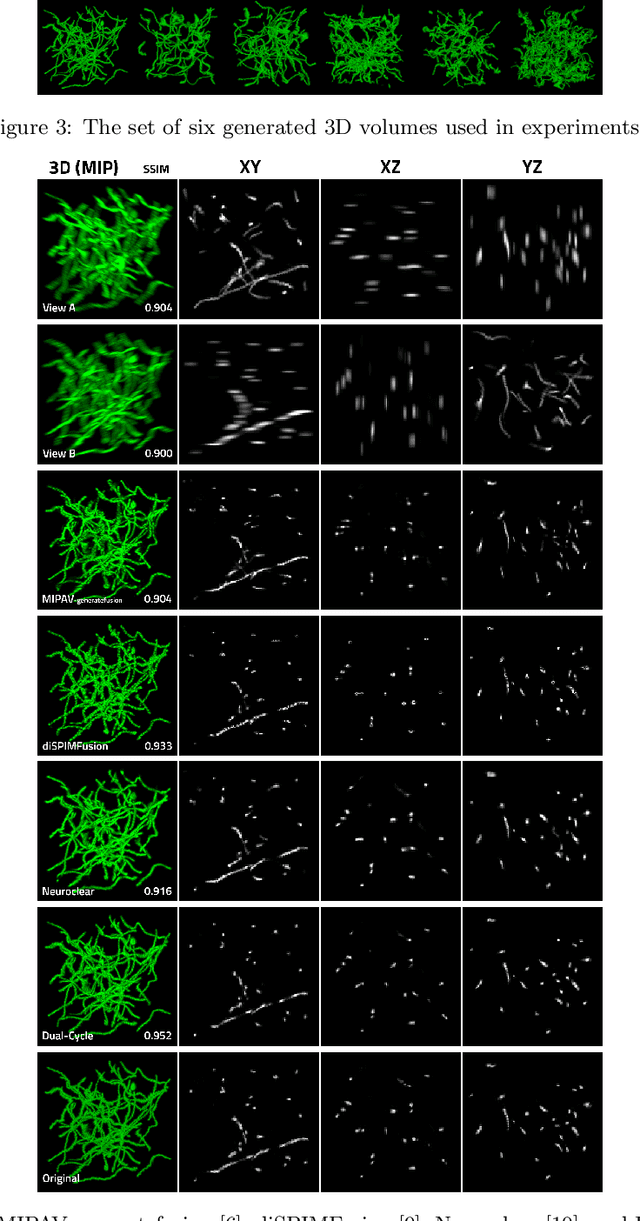
Three-dimensional fluorescence microscopy often suffers from anisotropy, where the resolution along the axial direction is lower than that within the lateral imaging plane. We address this issue by presenting Dual-Cycle, a new framework for joint deconvolution and fusion of dual-view fluorescence images. Inspired by the recent Neuroclear method, Dual-Cycle is designed as a cycle-consistent generative network trained in a self-supervised fashion by combining a dual-view generator and prior-guided degradation model. We validate Dual-Cycle on both synthetic and real data showing its state-of-the-art performance without any external training data.
Best Prompts for Text-to-Image Models and How to Find Them
Sep 23, 2022

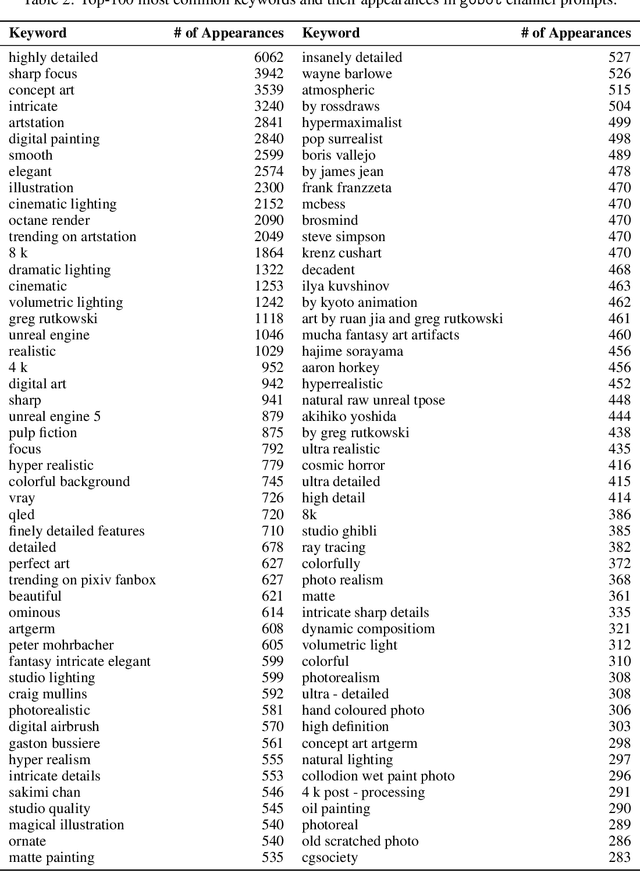

Recent progress in generative models, especially in text-guided diffusion models, has enabled the production of aesthetically-pleasing imagery resembling the works of professional human artists. However, one has to carefully compose the textual description, called the prompt, and augment it with a set of clarifying keywords. Since aesthetics are challenging to evaluate computationally, human feedback is needed to determine the optimal prompt formulation and keyword combination. In this paper, we present a human-in-the-loop approach to learning the most useful combination of prompt keywords using a genetic algorithm. We also show how such an approach can improve the aesthetic appeal of images depicting the same descriptions.
Accelerating Score-based Generative Models for High-Resolution Image Synthesis
Jun 09, 2022



Score-based generative models (SGMs) have recently emerged as a promising class of generative models. The key idea is to produce high-quality images by recurrently adding Gaussian noises and gradients to a Gaussian sample until converging to the target distribution, a.k.a. the diffusion sampling. To ensure stability of convergence in sampling and generation quality, however, this sequential sampling process has to take a small step size and many sampling iterations (e.g., 2000). Several acceleration methods have been proposed with focus on low-resolution generation. In this work, we consider the acceleration of high-resolution generation with SGMs, a more challenging yet more important problem. We prove theoretically that this slow convergence drawback is primarily due to the ignorance of the target distribution. Further, we introduce a novel Target Distribution Aware Sampling (TDAS) method by leveraging the structural priors in space and frequency domains. Extensive experiments on CIFAR-10, CelebA, LSUN, and FFHQ datasets validate that TDAS can consistently accelerate state-of-the-art SGMs, particularly on more challenging high resolution (1024x1024) image generation tasks by up to 18.4x, whilst largely maintaining the synthesis quality. With fewer sampling iterations, TDAS can still generate good quality images. In contrast, the existing methods degrade drastically or even fails completely
A Mosquito is Worth 16x16 Larvae: Evaluation of Deep Learning Architectures for Mosquito Larvae Classification
Sep 16, 2022
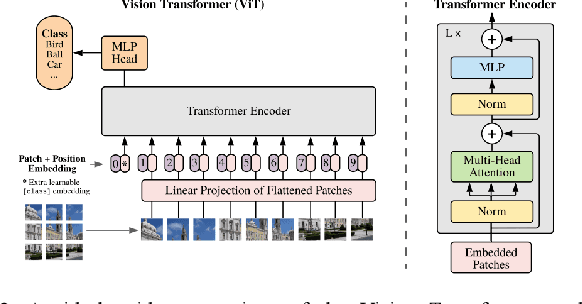
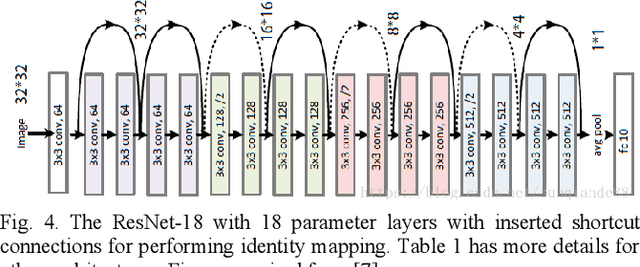
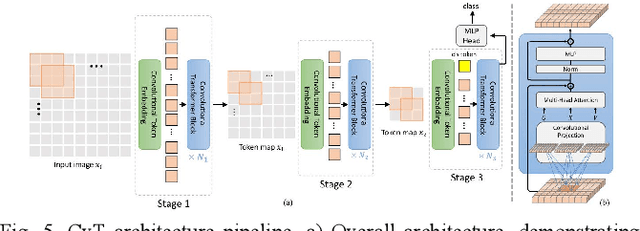
Mosquito-borne diseases (MBDs), such as dengue virus, chikungunya virus, and West Nile virus, cause over one million deaths globally every year. Because many such diseases are spread by the Aedes and Culex mosquitoes, tracking these larvae becomes critical in mitigating the spread of MBDs. Even as citizen science grows and obtains larger mosquito image datasets, the manual annotation of mosquito images becomes ever more time-consuming and inefficient. Previous research has used computer vision to identify mosquito species, and the Convolutional Neural Network (CNN) has become the de-facto for image classification. However, these models typically require substantial computational resources. This research introduces the application of the Vision Transformer (ViT) in a comparative study to improve image classification on Aedes and Culex larvae. Two ViT models, ViT-Base and CvT-13, and two CNN models, ResNet-18 and ConvNeXT, were trained on mosquito larvae image data and compared to determine the most effective model to distinguish mosquito larvae as Aedes or Culex. Testing revealed that ConvNeXT obtained the greatest values across all classification metrics, demonstrating its viability for mosquito larvae classification. Based on these results, future research includes creating a model specifically designed for mosquito larvae classification by combining elements of CNN and transformer architecture.
Bayesian Convolutional Neural Networks for Limited Data Hyperspectral Remote Sensing Image Classification
May 19, 2022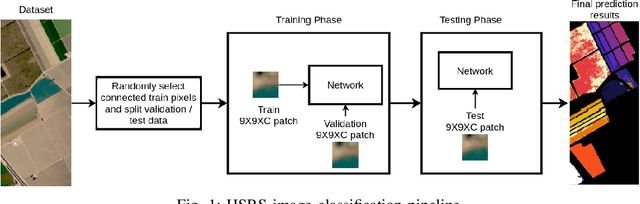

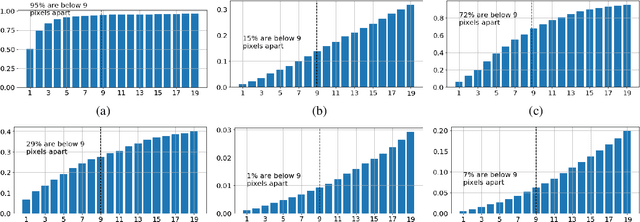
Employing deep neural networks for Hyper-spectral remote sensing (HSRS) image classification is a challenging task. HSRS images have high dimensionality and a large number of channels with substantial redundancy between channels. In addition, the training data for classifying HSRS images is limited and the amount of available training data is much smaller compared to other classification tasks. These factors complicate the training process of deep neural networks with many parameters and cause them to not perform well even compared to conventional models. Moreover, convolutional neural networks produce over-confident predictions, which is highly undesirable considering the aforementioned problem. In this work, we use a special class of deep neural networks, namely Bayesian neural network, to classify HSRS images. To the extent of our knowledge, this is the first time that this class of neural networks has been used in HSRS image classification. Bayesian neural networks provide an inherent tool for measuring uncertainty. We show that a Bayesian network can outperform a similarly-constructed non-Bayesian convolutional neural network (CNN) and an off-the-shelf Random Forest (RF). Moreover, experimental results for the Pavia Centre, Salinas, and Botswana datasets show that the Bayesian network is more stable and robust to model pruning. Furthermore, we analyze the prediction uncertainty of the Bayesian model and show that the prediction uncertainty metric can provide information about the model predictions and has a positive correlation with the prediction error.
Pruning-based Topology Refinement of 3D Mesh using a 2D Alpha Mask
Oct 17, 2022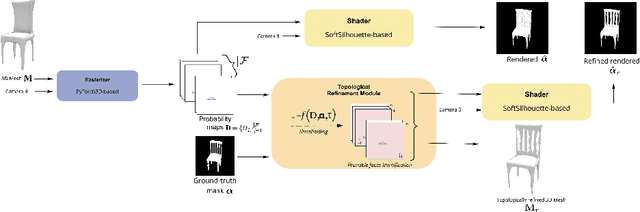


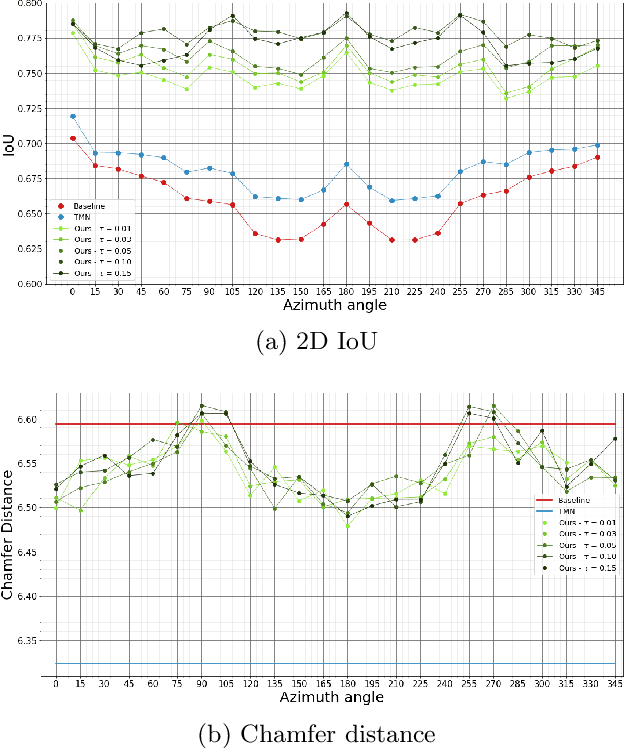
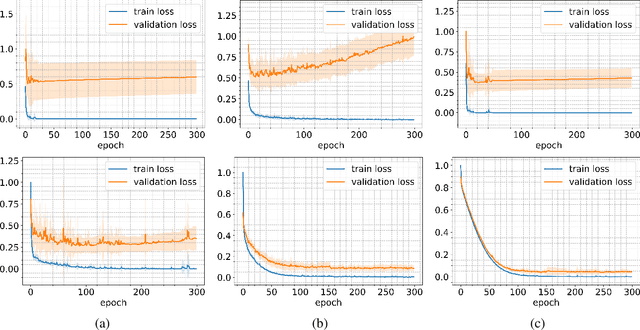
Image-based 3D reconstruction has increasingly stunning results over the past few years with the latest improvements in computer vision and graphics. Geometry and topology are two fundamental concepts when dealing with 3D mesh structures. But the latest often remains a side issue in the 3D mesh-based reconstruction literature. Indeed, performing per-vertex elementary displacements over a 3D sphere mesh only impacts its geometry and leaves the topological structure unchanged and fixed. Whereas few attempts propose to update the geometry and the topology, all need to lean on costly 3D ground-truth to determine the faces/edges to prune. We present in this work a method that aims to refine the topology of any 3D mesh through a face-pruning strategy that extensively relies upon 2D alpha masks and camera pose information. Our solution leverages a differentiable renderer that renders each face as a 2D soft map. Its pixel intensity reflects the probability of being covered during the rendering process by such a face. Based on the 2D soft-masks available, our method is thus able to quickly highlight all the incorrectly rendered faces for a given viewpoint. Because our module is agnostic to the network that produces the 3D mesh, it can be easily plugged into any self-supervised image-based (either synthetic or natural) 3D reconstruction pipeline to get complex meshes with a non-spherical topology.
Detecting Line Segments in Motion-blurred Images with Events
Nov 20, 2022
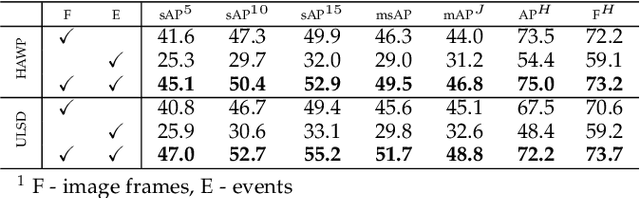

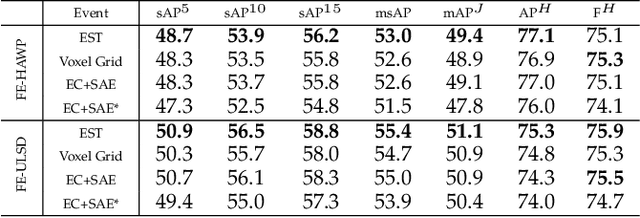
Making line segment detectors more reliable under motion blurs is one of the most important challenges for practical applications, such as visual SLAM and 3D reconstruction. Existing line segment detection methods face severe performance degradation for accurately detecting and locating line segments when motion blur occurs. While event data shows strong complementary characteristics to images for minimal blur and edge awareness at high-temporal resolution, potentially beneficial for reliable line segment recognition. To robustly detect line segments over motion blurs, we propose to leverage the complementary information of images and events. To achieve this, we first design a general frame-event feature fusion network to extract and fuse the detailed image textures and low-latency event edges, which consists of a channel-attention-based shallow fusion module and a self-attention-based dual hourglass module. We then utilize two state-of-the-art wireframe parsing networks to detect line segments on the fused feature map. Besides, we contribute a synthetic and a realistic dataset for line segment detection, i.e., FE-Wireframe and FE-Blurframe, with pairwise motion-blurred images and events. Extensive experiments on both datasets demonstrate the effectiveness of the proposed method. When tested on the real dataset, our method achieves 63.3% mean structural average precision (msAP) with the model pre-trained on the FE-Wireframe and fine-tuned on the FE-Blurframe, improved by 32.6 and 11.3 points compared with models trained on synthetic only and real only, respectively. The codes, datasets, and trained models are released at: https://levenberg.github.io/FE-LSD
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Apr 06, 2022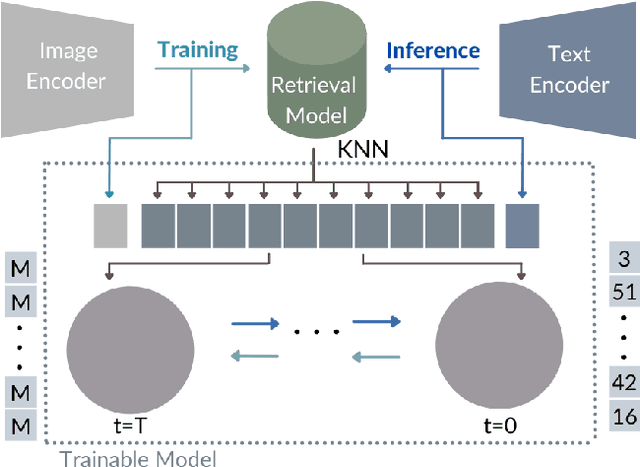
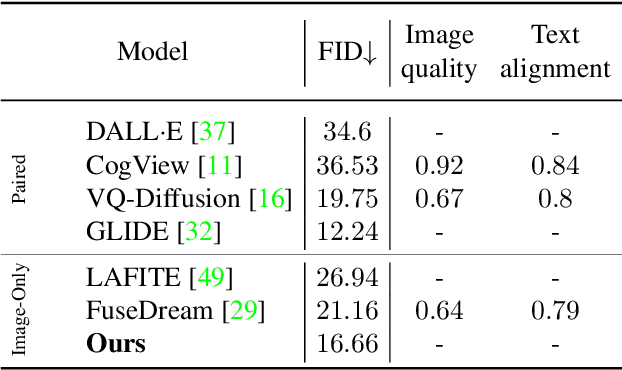
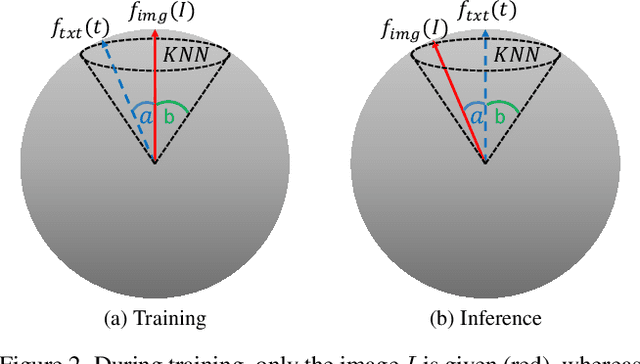

While the availability of massive Text-Image datasets is shown to be extremely useful in training large-scale generative models (e.g. DDPMs, Transformers), their output typically depends on the quality of both the input text, as well as the training dataset. In this work, we show how large-scale retrieval methods, in particular efficient K-Nearest-Neighbors (KNN) search, can be used in order to train a model to adapt to new samples. Learning to adapt enables several new capabilities. Sifting through billions of records at inference time is extremely efficient and can alleviate the need to train or memorize an adequately large generative model. Additionally, fine-tuning trained models to new samples can be achieved by simply adding them to the table. Rare concepts, even without any presence in the training set, can be then leveraged during test time without any modification to the generative model. Our diffusion-based model trains on images only, by leveraging a joint Text-Image multi-modal metric. Compared to baseline methods, our generations achieve state of the art results both in human evaluations as well as with perceptual scores when tested on a public multimodal dataset of natural images, as well as on a collected dataset of 400 million Stickers.
Multi-modal unsupervised brain image registration using edge maps
Feb 22, 2022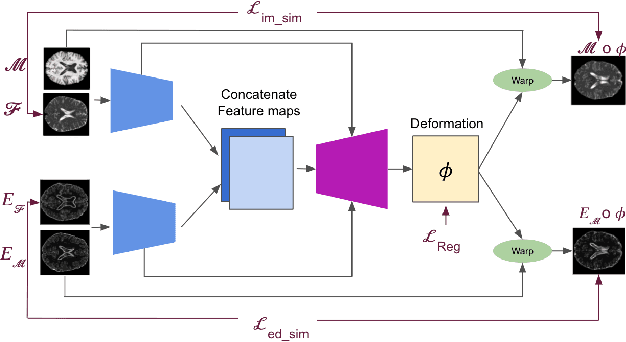
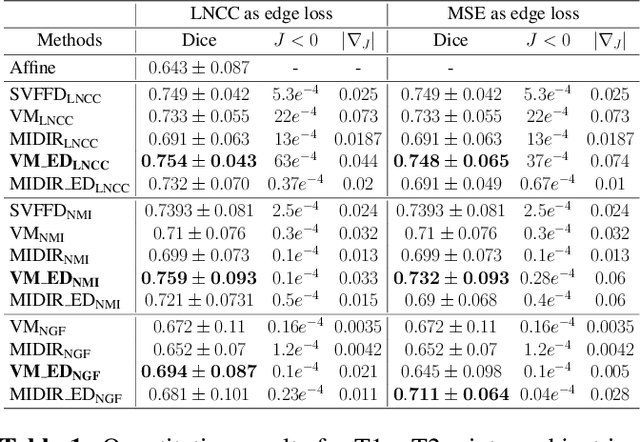


Diffeomorphic deformable multi-modal image registration is a challenging task which aims to bring images acquired by different modalities to the same coordinate space and at the same time to preserve the topology and the invertibility of the transformation. Recent research has focused on leveraging deep learning approaches for this task as these have been shown to achieve competitive registration accuracy while being computationally more efficient than traditional iterative registration methods. In this work, we propose a simple yet effective unsupervised deep learning-based {\em multi-modal} image registration approach that benefits from auxiliary information coming from the gradient magnitude of the image, i.e. the image edges, during the training. The intuition behind this is that image locations with a strong gradient are assumed to denote a transition of tissues, which are locations of high information value able to act as a geometry constraint. The task is similar to using segmentation maps to drive the training, but the edge maps are easier and faster to acquire and do not require annotations. We evaluate our approach in the context of registering multi-modal (T1w to T2w) magnetic resonance (MR) brain images of different subjects using three different loss functions that are said to assist multi-modal registration, showing that in all cases the auxiliary information leads to better results without compromising the runtime.