 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dense FixMatch: a simple semi-supervised learning method for pixel-wise prediction tasks
Oct 18, 2022
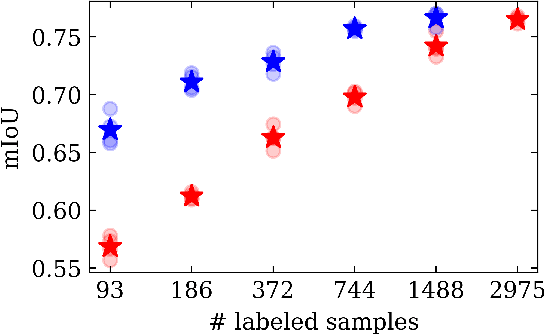

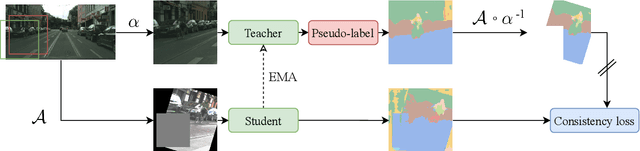
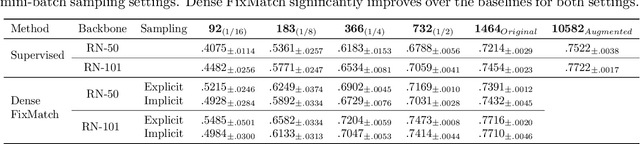
We propose Dense FixMatch, a simple method for online semi-supervised learning of dense and structured prediction tasks combining pseudo-labeling and consistency regularization via strong data augmentation. We enable the application of FixMatch in semi-supervised learning problems beyond image classification by adding a matching operation on the pseudo-labels. This allows us to still use the full strength of data augmentation pipelines, including geometric transformations. We evaluate it on semi-supervised semantic segmentation on Cityscapes and Pascal VOC with different percentages of labeled data and ablate design choices and hyper-parameters. Dense FixMatch significantly improves results compared to supervised learning using only labeled data, approaching its performance with 1/4 of the labeled samples.
Selective Residual M-Net for Real Image Denoising
Mar 03, 2022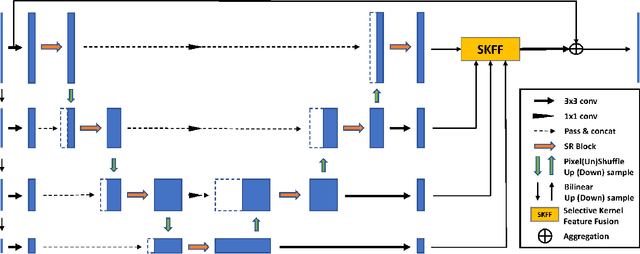
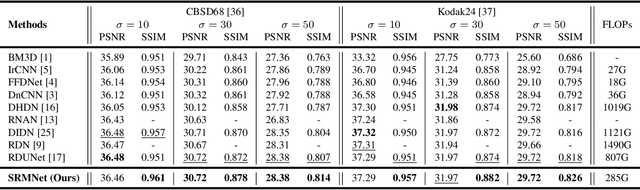
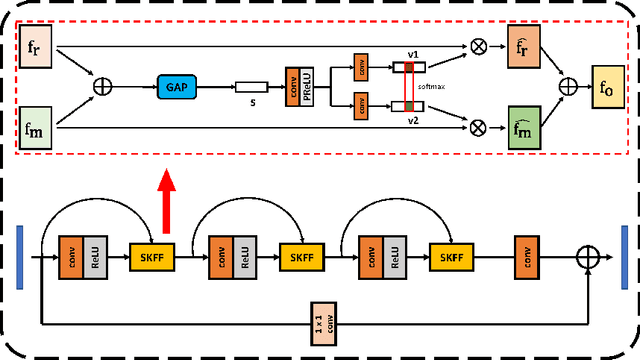
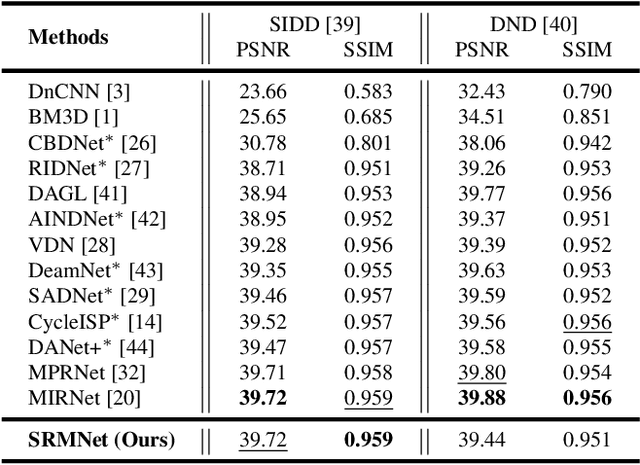
Image restoration is a low-level vision task which is to restore degraded images to noise-free images. With the success of deep neural networks, the convolutional neural networks surpass the traditional restoration methods and become the mainstream in the computer vision area. To advance the performanceof denoising algorithms, we propose a blind real image denoising network (SRMNet) by employing a hierarchical architecture improved from U-Net. Specifically, we use a selective kernel with residual block on the hierarchical structure called M-Net to enrich the multi-scale semantic information. Furthermore, our SRMNet has competitive performance results on two synthetic and two real-world noisy datasets in terms of quantitative metrics and visual quality. The source code and pretrained model are available at https://github.com/TentativeGitHub/SRMNet.
Digitization of Raster Logs: A Deep Learning Approach
Oct 11, 2022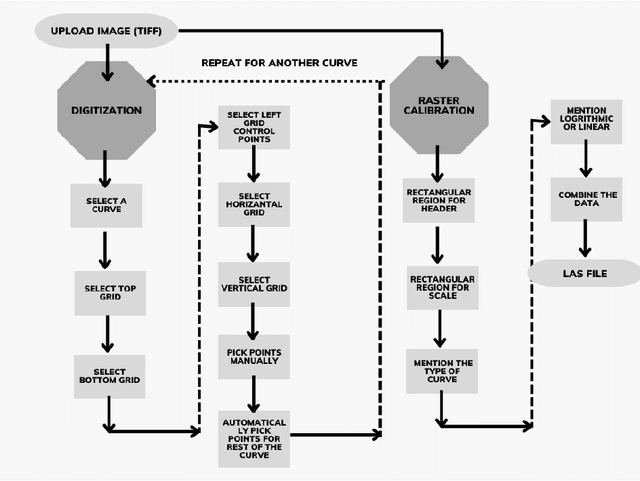
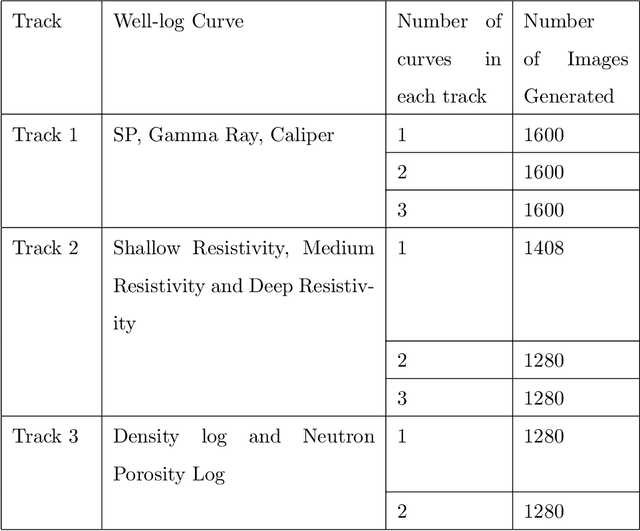
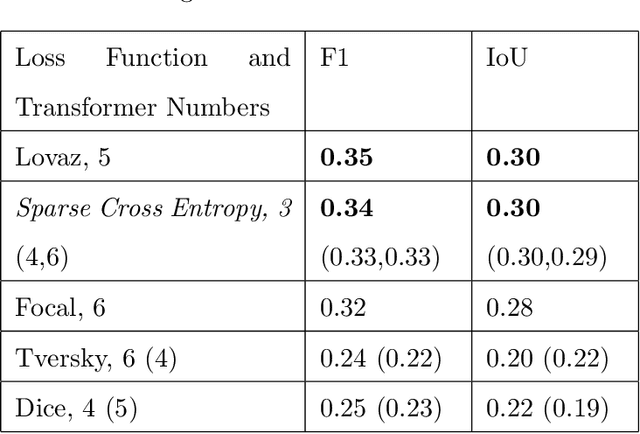
Raster well-log images are digital representations of well-logs data generated over the years. Raster digital well logs represent bitmaps of the log image in a rectangular array of black (zeros) and white dots (ones) called pixels. Experts study the raster logs manually or with software applications that still require a tremendous amount of manual input. Besides the loss of thousands of person-hours, this process is erroneous and tedious. To digitize these raster logs, one must buy a costly digitizer that is not only manual and time-consuming but also a hidden technical debt since enterprises stand to lose more money in additional servicing and consulting charges. We propose a deep neural network architecture called VeerNet to semantically segment the raster images from the background grid and classify and digitize the well-log curves. Raster logs have a substantially greater resolution than images traditionally consumed by image segmentation pipelines. Since the input has a low signal-to-resolution ratio, we require rapid downsampling to alleviate unnecessary computation. We thus employ a modified UNet-inspired architecture that balances retaining key signals and reducing result dimensionality. We use attention augmented read-process-write architecture. This architecture efficiently classifies and digitizes the curves with an overall F1 score of 35% and IoU of 30%. When compared to the actual las values for Gamma-ray and derived value of Gamma-ray from VeerNet, a high Pearson coefficient score of 0.62 was achieved.
Perception Over Time: Temporal Dynamics for Robust Image Understanding
Mar 11, 2022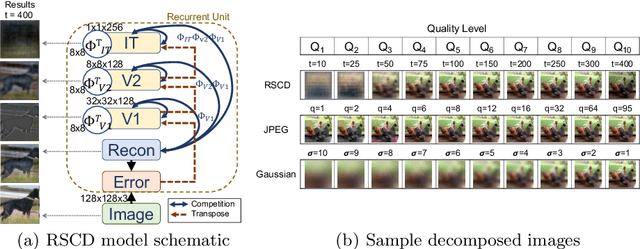

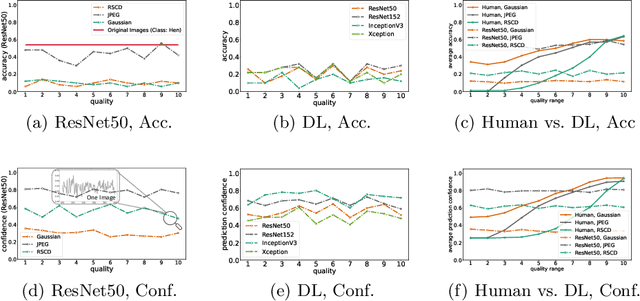
While deep learning surpasses human-level performance in narrow and specific vision tasks, it is fragile and over-confident in classification. For example, minor transformations in perspective, illumination, or object deformation in the image space can result in drastically different labeling, which is especially transparent via adversarial perturbations. On the other hand, human visual perception is orders of magnitude more robust to changes in the input stimulus. But unfortunately, we are far from fully understanding and integrating the underlying mechanisms that result in such robust perception. In this work, we introduce a novel method of incorporating temporal dynamics into static image understanding. We describe a neuro-inspired method that decomposes a single image into a series of coarse-to-fine images that simulates how biological vision integrates information over time. Next, we demonstrate how our novel visual perception framework can utilize this information "over time" using a biologically plausible algorithm with recurrent units, and as a result, significantly improving its accuracy and robustness over standard CNNs. We also compare our proposed approach with state-of-the-art models and explicitly quantify our adversarial robustness properties through multiple ablation studies. Our quantitative and qualitative results convincingly demonstrate exciting and transformative improvements over the standard computer vision and deep learning architectures used today.
End-to-End Transformer Based Model for Image Captioning
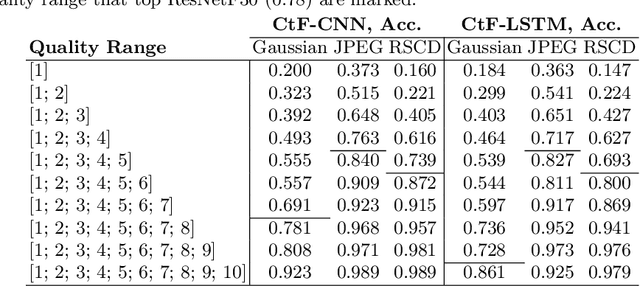
Mar 29, 2022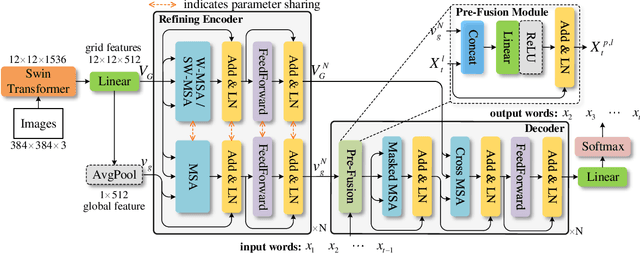
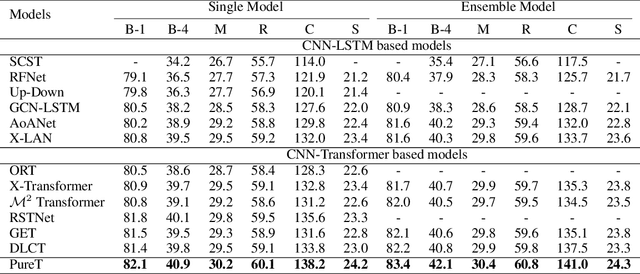
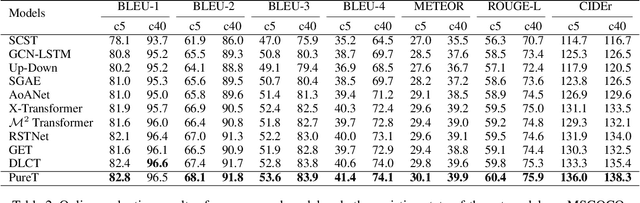
CNN-LSTM based architectures have played an important role in image captioning, but limited by the training efficiency and expression ability, researchers began to explore the CNN-Transformer based models and achieved great success. Meanwhile, almost all recent works adopt Faster R-CNN as the backbone encoder to extract region-level features from given images. However, Faster R-CNN needs a pre-training on an additional dataset, which divides the image captioning task into two stages and limits its potential applications. In this paper, we build a pure Transformer-based model, which integrates image captioning into one stage and realizes end-to-end training. Firstly, we adopt SwinTransformer to replace Faster R-CNN as the backbone encoder to extract grid-level features from given images; Then, referring to Transformer, we build a refining encoder and a decoder. The refining encoder refines the grid features by capturing the intra-relationship between them, and the decoder decodes the refined features into captions word by word. Furthermore, in order to increase the interaction between multi-modal (vision and language) features to enhance the modeling capability, we calculate the mean pooling of grid features as the global feature, then introduce it into refining encoder to refine with grid features together, and add a pre-fusion process of refined global feature and generated words in decoder. To validate the effectiveness of our proposed model, we conduct experiments on MSCOCO dataset. The experimental results compared to existing published works demonstrate that our model achieves new state-of-the-art performances of 138.2% (single model) and 141.0% (ensemble of 4 models) CIDEr scores on `Karpathy' offline test split and 136.0% (c5) and 138.3% (c40) CIDEr scores on the official online test server. Trained models and source code will be released.
An Aggregation of Aggregation Methods in Computational Pathology
Nov 02, 2022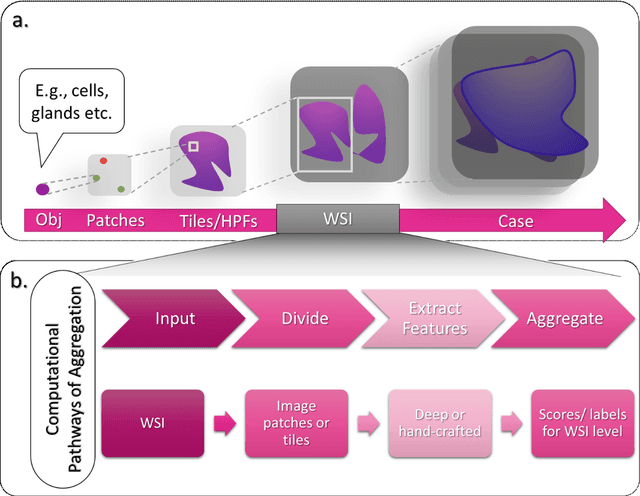
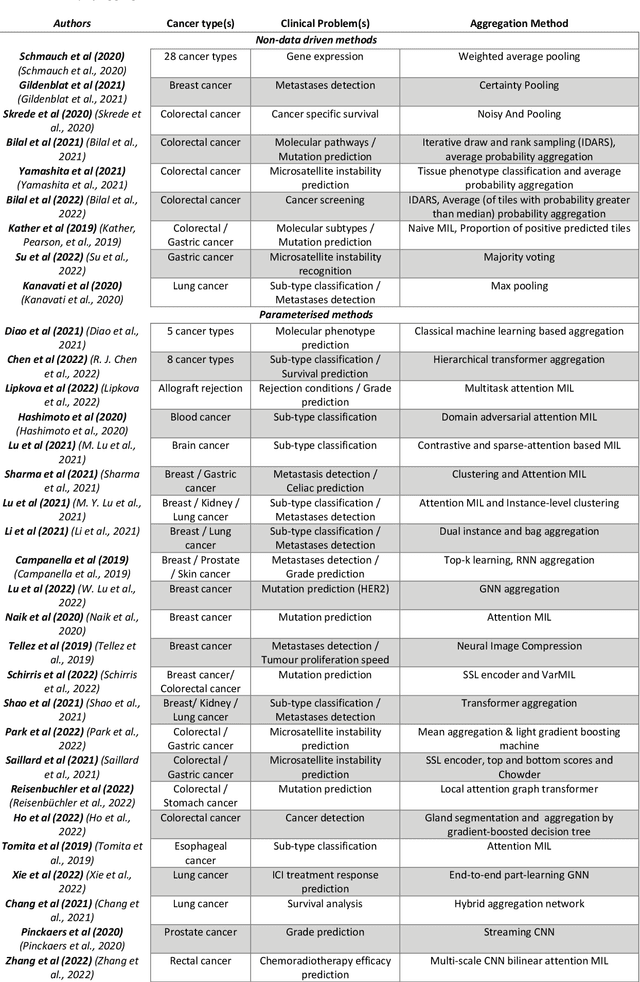
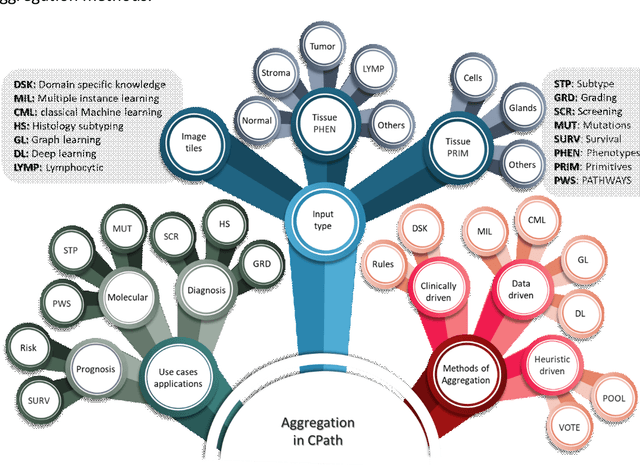

Image analysis and machine learning algorithms operating on multi-gigapixel whole-slide images (WSIs) often process a large number of tiles (sub-images) and require aggregating predictions from the tiles in order to predict WSI-level labels. In this paper, we present a review of existing literature on various types of aggregation methods with a view to help guide future research in the area of computational pathology (CPath). We propose a general CPath workflow with three pathways that consider multiple levels and types of data and the nature of computation to analyse WSIs for predictive modelling. We categorize aggregation methods according to the context and representation of the data, features of computational modules and CPath use cases. We compare and contrast different methods based on the principle of multiple instance learning, perhaps the most commonly used aggregation method, covering a wide range of CPath literature. To provide a fair comparison, we consider a specific WSI-level prediction task and compare various aggregation methods for that task. Finally, we conclude with a list of objectives and desirable attributes of aggregation methods in general, pros and cons of the various approaches, some recommendations and possible future directions.
Interpretable Modeling and Reduction of Unknown Errors in Mechanistic Operators
Nov 02, 2022Prior knowledge about the imaging physics provides a mechanistic forward operator that plays an important role in image reconstruction, although myriad sources of possible errors in the operator could negatively impact the reconstruction solutions. In this work, we propose to embed the traditional mechanistic forward operator inside a neural function, and focus on modeling and correcting its unknown errors in an interpretable manner. This is achieved by a conditional generative model that transforms a given mechanistic operator with unknown errors, arising from a latent space of self-organizing clusters of potential sources of error generation. Once learned, the generative model can be used in place of a fixed forward operator in any traditional optimization-based reconstruction process where, together with the inverse solution, the error in prior mechanistic forward operator can be minimized and the potential source of error uncovered. We apply the presented method to the reconstruction of heart electrical potential from body surface potential. In controlled simulation experiments and in-vivo real data experiments, we demonstrate that the presented method allowed reduction of errors in the physics-based forward operator and thereby delivered inverse reconstruction of heart-surface potential with increased accuracy.
* 11 pages, Conference: Medical Image Computing and Computer Assisted Intervention
Concrete Score Matching: Generalized Score Matching for Discrete Data
Nov 02, 2022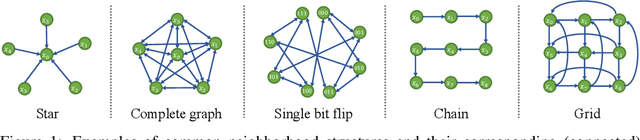
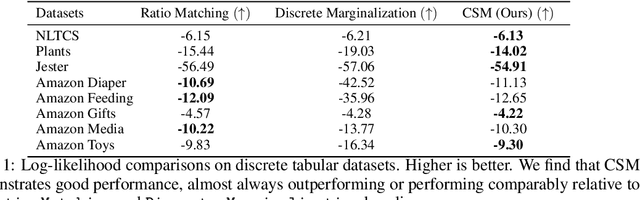

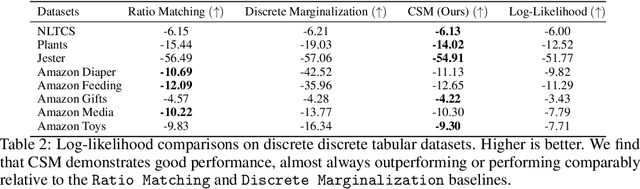
Representing probability distributions by the gradient of their density functions has proven effective in modeling a wide range of continuous data modalities. However, this representation is not applicable in discrete domains where the gradient is undefined. To this end, we propose an analogous score function called the "Concrete score", a generalization of the (Stein) score for discrete settings. Given a predefined neighborhood structure, the Concrete score of any input is defined by the rate of change of the probabilities with respect to local directional changes of the input. This formulation allows us to recover the (Stein) score in continuous domains when measuring such changes by the Euclidean distance, while using the Manhattan distance leads to our novel score function in discrete domains. Finally, we introduce a new framework to learn such scores from samples called Concrete Score Matching (CSM), and propose an efficient training objective to scale our approach to high dimensions. Empirically, we demonstrate the efficacy of CSM on density estimation tasks on a mixture of synthetic, tabular, and high-dimensional image datasets, and demonstrate that it performs favorably relative to existing baselines for modeling discrete data.
Neural Networks with Quantization Constraints
Oct 27, 2022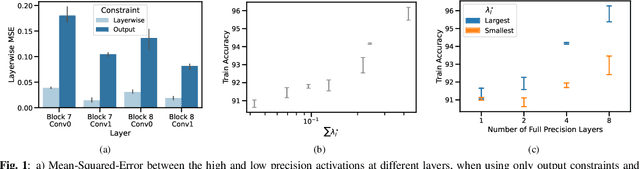

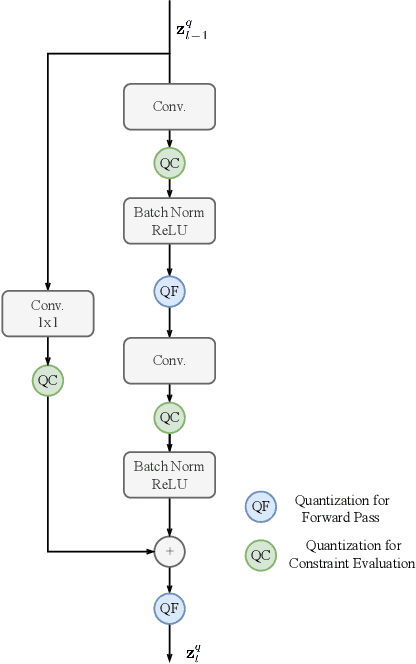
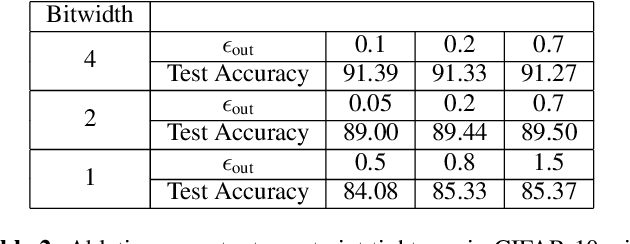
Enabling low precision implementations of deep learning models, without considerable performance degradation, is necessary in resource and latency constrained settings. Moreover, exploiting the differences in sensitivity to quantization across layers can allow mixed precision implementations to achieve a considerably better computation performance trade-off. However, backpropagating through the quantization operation requires introducing gradient approximations, and choosing which layers to quantize is challenging for modern architectures due to the large search space. In this work, we present a constrained learning approach to quantization aware training. We formulate low precision supervised learning as a constrained optimization problem, and show that despite its non-convexity, the resulting problem is strongly dual and does away with gradient estimations. Furthermore, we show that dual variables indicate the sensitivity of the objective with respect to constraint perturbations. We demonstrate that the proposed approach exhibits competitive performance in image classification tasks, and leverage the sensitivity result to apply layer selective quantization based on the value of dual variables, leading to considerable performance improvements.
Prompt-Based Multi-Modal Image Segmentation
Dec 18, 2021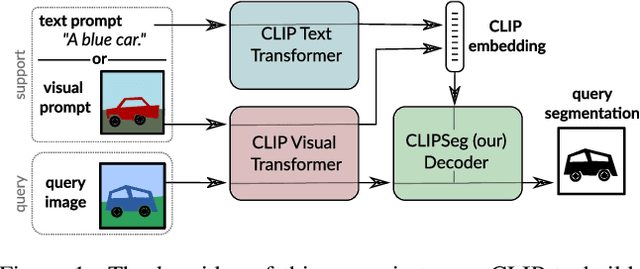

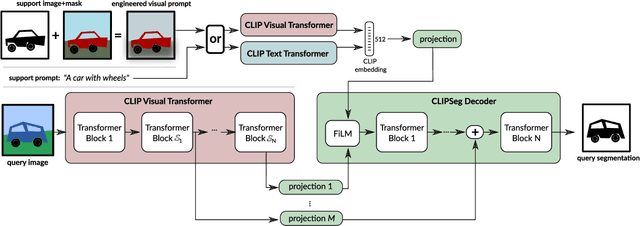

Image segmentation is usually addressed by training a model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system that can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text or an image. This approach enables us to create a unified model (trained once) for three common segmentation tasks, which come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation. We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense prediction. After training on an extended version of the PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on an additional image expressing the query. Different variants of the latter image-based prompts are analyzed in detail. This novel hybrid input allows for dynamic adaptation not only to the three segmentation tasks mentioned above, but to any binary segmentation task where a text or image query can be formulated. Finally, we find our system to adapt well to generalized queries involving affordances or properties. Source code: https://eckerlab.org/code/clipseg