 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Keep the Caption Information: Preventing Shortcut Learning in Contrastive Image-Caption Retrieval
Apr 28, 2022
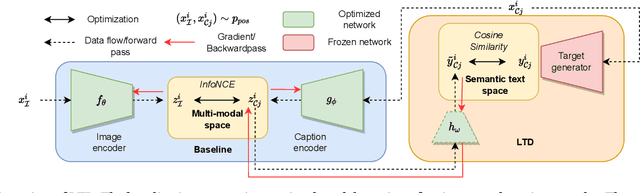
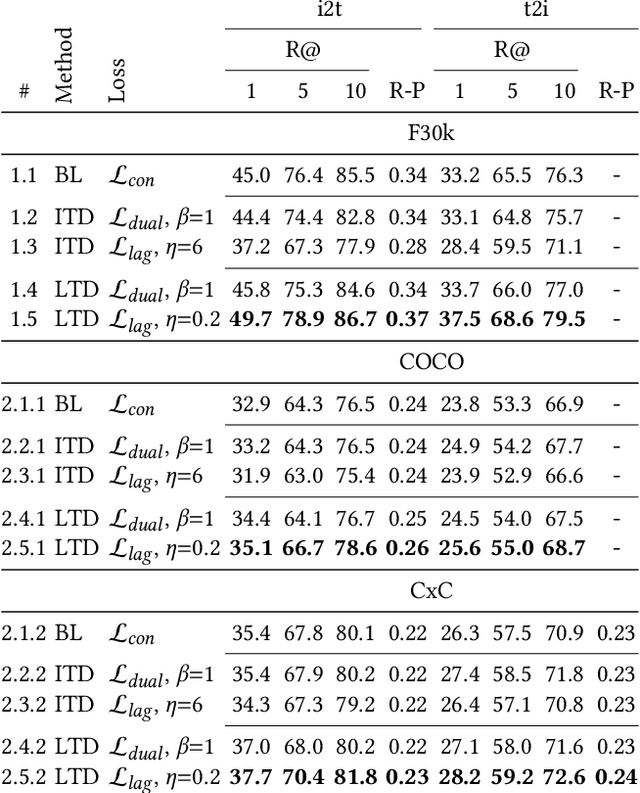
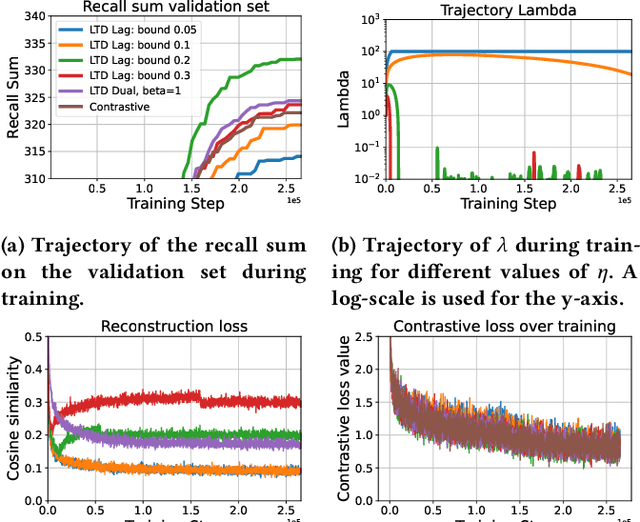
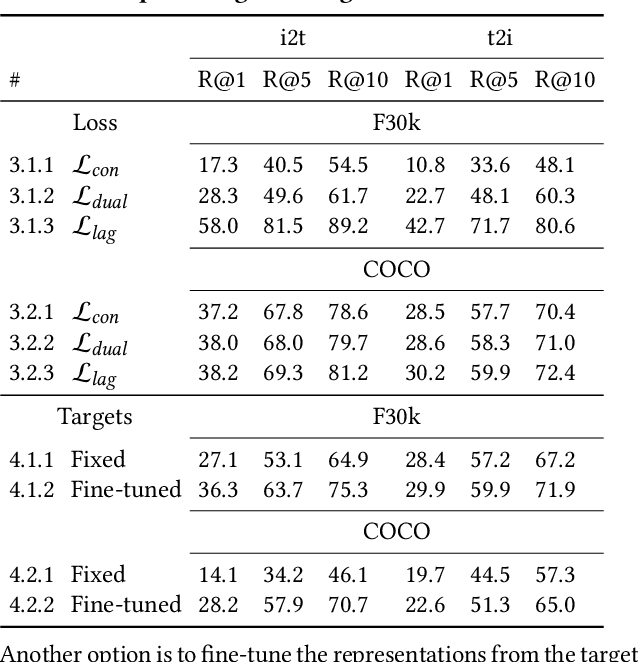
To train image-caption retrieval (ICR) methods, contrastive loss functions are a common choice for optimization functions. Unfortunately, contrastive ICR methods are vulnerable to learning shortcuts: decision rules that perform well on the training data but fail to transfer to other testing conditions. We introduce an approach to reduce shortcut feature representations for the ICR task: latent target decoding (LTD). We add an additional decoder to the learning framework to reconstruct the input caption, which prevents the image and caption encoder from learning shortcut features. Instead of reconstructing input captions in the input space, we decode the semantics of the caption in a latent space. We implement the LTD objective as an optimization constraint, to ensure that the reconstruction loss is below a threshold value while primarily optimizing for the contrastive loss. Importantly, LTD does not depend on additional training data or expensive (hard) negative mining strategies. Our experiments show that, unlike reconstructing the input caption, LTD reduces shortcut learning and improves generalizability by obtaining higher recall@k and r-precision scores. Additionally, we show that the evaluation scores benefit from implementing LTD as an optimization constraint instead of a dual loss.
Perception Over Time: Temporal Dynamics for Robust Image Understanding
Mar 11, 2022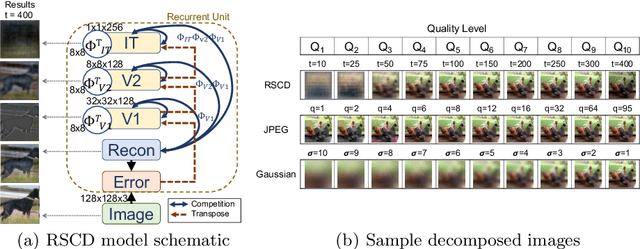

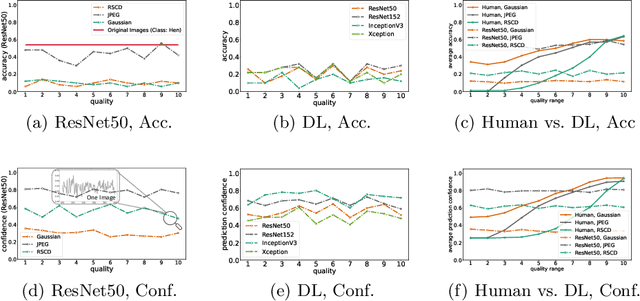
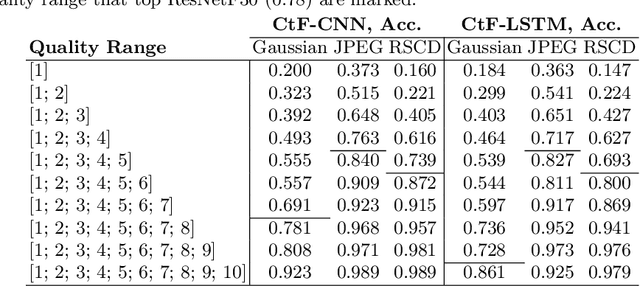
While deep learning surpasses human-level performance in narrow and specific vision tasks, it is fragile and over-confident in classification. For example, minor transformations in perspective, illumination, or object deformation in the image space can result in drastically different labeling, which is especially transparent via adversarial perturbations. On the other hand, human visual perception is orders of magnitude more robust to changes in the input stimulus. But unfortunately, we are far from fully understanding and integrating the underlying mechanisms that result in such robust perception. In this work, we introduce a novel method of incorporating temporal dynamics into static image understanding. We describe a neuro-inspired method that decomposes a single image into a series of coarse-to-fine images that simulates how biological vision integrates information over time. Next, we demonstrate how our novel visual perception framework can utilize this information "over time" using a biologically plausible algorithm with recurrent units, and as a result, significantly improving its accuracy and robustness over standard CNNs. We also compare our proposed approach with state-of-the-art models and explicitly quantify our adversarial robustness properties through multiple ablation studies. Our quantitative and qualitative results convincingly demonstrate exciting and transformative improvements over the standard computer vision and deep learning architectures used today.
Image Denoising Using Convolutional Autoencoder
Jul 24, 2022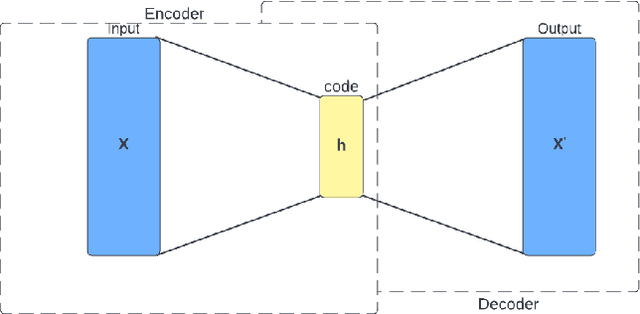
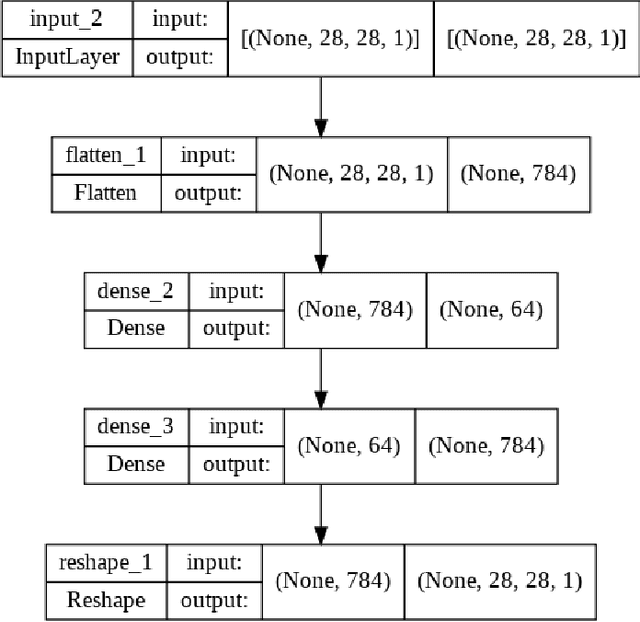


With the inexorable digitalisation of the modern world, every subset in the field of technology goes through major advancements constantly. One such subset is digital images which are ever so popular. Images can not always be as visually pleasing or clear as you would want them to be and are often distorted or obscured with noise. A number of techniques to enhance images have come up as the years passed, all with their own respective pros and cons. In this paper, we look at one such particular technique which accomplishes this task with the help of a neural network model commonly known as an autoencoder. We construct different architectures for the model and compare results in order to decide the one best suited for the task. The characteristics and working of the model are discussed briefly knowing which can help set a path for future research.
CIGLI: Conditional Image Generation from Language & Image
Aug 20, 2021
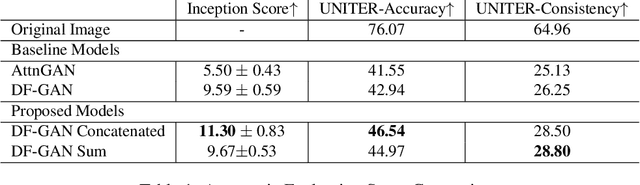
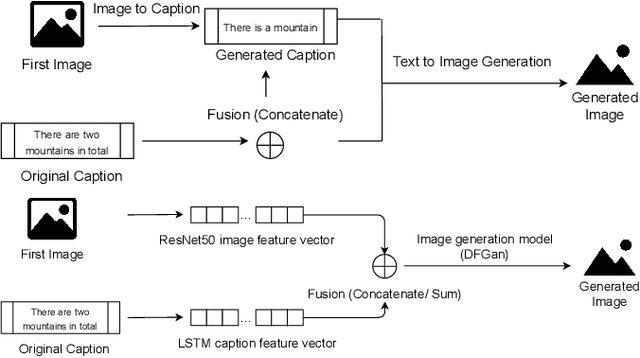
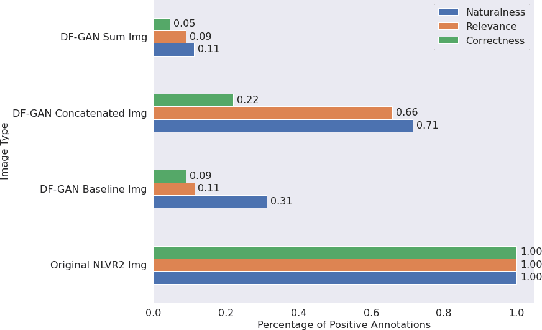
Multi-modal generation has been widely explored in recent years. Current research directions involve generating text based on an image or vice versa. In this paper, we propose a new task called CIGLI: Conditional Image Generation from Language and Image. Instead of generating an image based on text as in text-image generation, this task requires the generation of an image from a textual description and an image prompt. We designed a new dataset to ensure that the text description describes information from both images, and that solely analyzing the description is insufficient to generate an image. We then propose a novel language-image fusion model which improves the performance over two established baseline methods, as evaluated by quantitative (automatic) and qualitative (human) evaluations. The code and dataset is available at https://github.com/vincentlux/CIGLI.
End-to-End Transformer Based Model for Image Captioning
Mar 29, 2022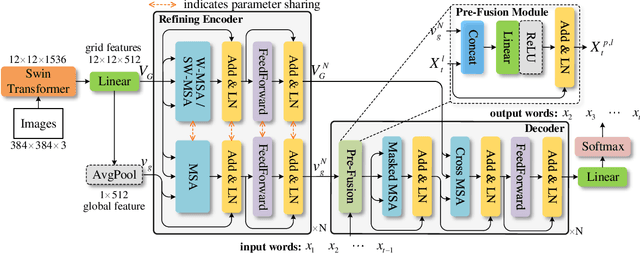
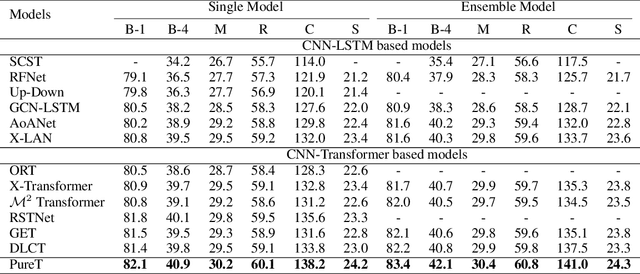
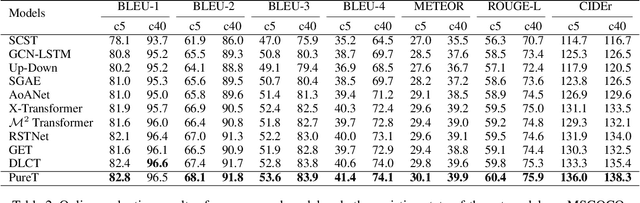
CNN-LSTM based architectures have played an important role in image captioning, but limited by the training efficiency and expression ability, researchers began to explore the CNN-Transformer based models and achieved great success. Meanwhile, almost all recent works adopt Faster R-CNN as the backbone encoder to extract region-level features from given images. However, Faster R-CNN needs a pre-training on an additional dataset, which divides the image captioning task into two stages and limits its potential applications. In this paper, we build a pure Transformer-based model, which integrates image captioning into one stage and realizes end-to-end training. Firstly, we adopt SwinTransformer to replace Faster R-CNN as the backbone encoder to extract grid-level features from given images; Then, referring to Transformer, we build a refining encoder and a decoder. The refining encoder refines the grid features by capturing the intra-relationship between them, and the decoder decodes the refined features into captions word by word. Furthermore, in order to increase the interaction between multi-modal (vision and language) features to enhance the modeling capability, we calculate the mean pooling of grid features as the global feature, then introduce it into refining encoder to refine with grid features together, and add a pre-fusion process of refined global feature and generated words in decoder. To validate the effectiveness of our proposed model, we conduct experiments on MSCOCO dataset. The experimental results compared to existing published works demonstrate that our model achieves new state-of-the-art performances of 138.2% (single model) and 141.0% (ensemble of 4 models) CIDEr scores on `Karpathy' offline test split and 136.0% (c5) and 138.3% (c40) CIDEr scores on the official online test server. Trained models and source code will be released.
Revealing the Dark Secrets of Masked Image Modeling
May 27, 2022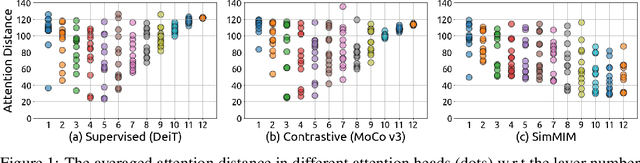

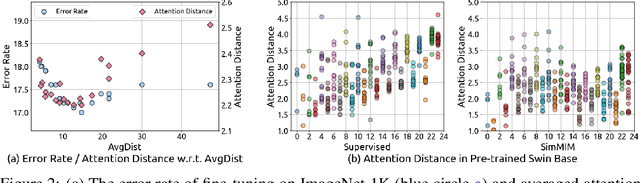
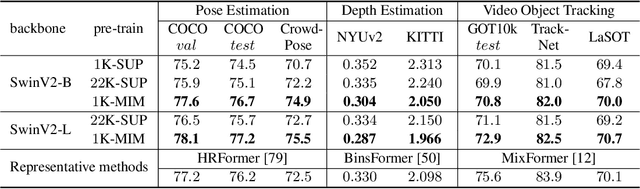
Masked image modeling (MIM) as pre-training is shown to be effective for numerous vision downstream tasks, but how and where MIM works remain unclear. In this paper, we compare MIM with the long-dominant supervised pre-trained models from two perspectives, the visualizations and the experiments, to uncover their key representational differences. From the visualizations, we find that MIM brings locality inductive bias to all layers of the trained models, but supervised models tend to focus locally at lower layers but more globally at higher layers. That may be the reason why MIM helps Vision Transformers that have a very large receptive field to optimize. Using MIM, the model can maintain a large diversity on attention heads in all layers. But for supervised models, the diversity on attention heads almost disappears from the last three layers and less diversity harms the fine-tuning performance. From the experiments, we find that MIM models can perform significantly better on geometric and motion tasks with weak semantics or fine-grained classification tasks, than their supervised counterparts. Without bells and whistles, a standard MIM pre-trained SwinV2-L could achieve state-of-the-art performance on pose estimation (78.9 AP on COCO test-dev and 78.0 AP on CrowdPose), depth estimation (0.287 RMSE on NYUv2 and 1.966 RMSE on KITTI), and video object tracking (70.7 SUC on LaSOT). For the semantic understanding datasets where the categories are sufficiently covered by the supervised pre-training, MIM models can still achieve highly competitive transfer performance. With a deeper understanding of MIM, we hope that our work can inspire new and solid research in this direction.
Radiomics-enhanced Deep Multi-task Learning for Outcome Prediction in Head and Neck Cancer
Nov 10, 2022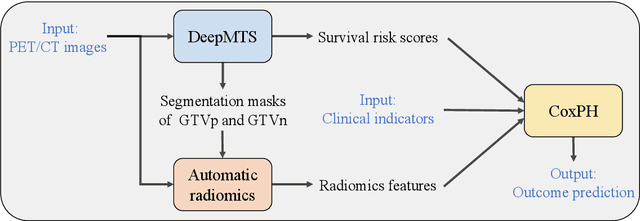
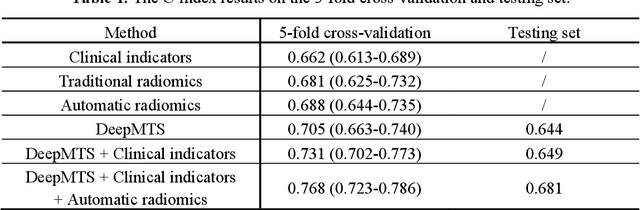
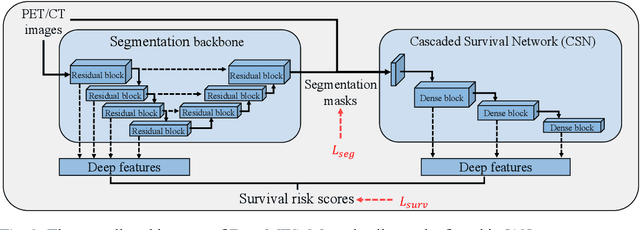

Outcome prediction is crucial for head and neck cancer patients as it can provide prognostic information for early treatment planning. Radiomics methods have been widely used for outcome prediction from medical images. However, these methods are limited by their reliance on intractable manual segmentation of tumor regions. Recently, deep learning methods have been proposed to perform end-to-end outcome prediction so as to remove the reliance on manual segmentation. Unfortunately, without segmentation masks, these methods will take the whole image as input, such that makes them difficult to focus on tumor regions and potentially unable to fully leverage the prognostic information within the tumor regions. In this study, we propose a radiomics-enhanced deep multi-task framework for outcome prediction from PET/CT images, in the context of HEad and neCK TumOR segmentation and outcome prediction challenge (HECKTOR 2022). In our framework, our novelty is to incorporate radiomics as an enhancement to our recently proposed Deep Multi-task Survival model (DeepMTS). The DeepMTS jointly learns to predict the survival risk scores of patients and the segmentation masks of tumor regions. Radiomics features are extracted from the predicted tumor regions and combined with the predicted survival risk scores for final outcome prediction, through which the prognostic information in tumor regions can be further leveraged. Our method achieved a C-index of 0.681 on the testing set, placing the 2nd on the leaderboard with only 0.00068 lower in C-index than the 1st place.
Open-Vocabulary Image Segmentation
Dec 22, 2021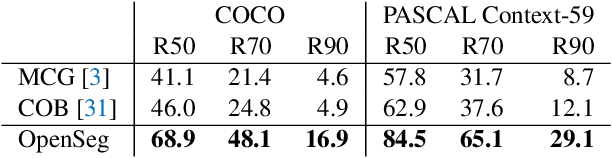

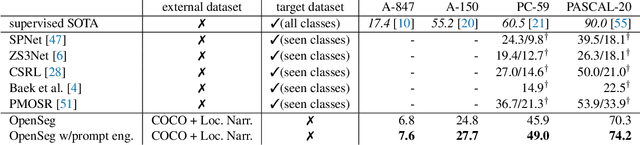
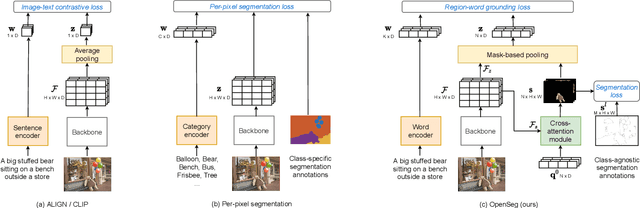
We design an open-vocabulary image segmentation model to organize an image into meaningful regions indicated by arbitrary texts. We identify that recent open-vocabulary models can not localize visual concepts well despite recognizing what are in an image. We argue that these models miss an important step of visual grouping, which organizes pixels into groups before learning visual-semantic alignments. We propose OpenSeg to address the above issue. First, it learns to propose segmentation masks for possible organizations. Then it learns visual-semantic alignments by aligning each word in a caption to one or a few predicted masks. We find the mask representations are the key to support learning from captions, making it possible to scale up the dataset and vocabulary sizes. Our work is the first to perform zero-shot transfer on holdout segmentation datasets. We set up two strong baselines by applying class activation maps or fine-tuning with pixel-wise labels on a pre-trained ALIGN model. OpenSeg outperforms these baselines by 3.4 mIoU on PASCAL-Context (459 classes) and 2.7 mIoU on ADE-20k (847 classes).
Super-Resolution by Predicting Offsets: An Ultra-Efficient Super-Resolution Network for Rasterized Images
Oct 09, 2022
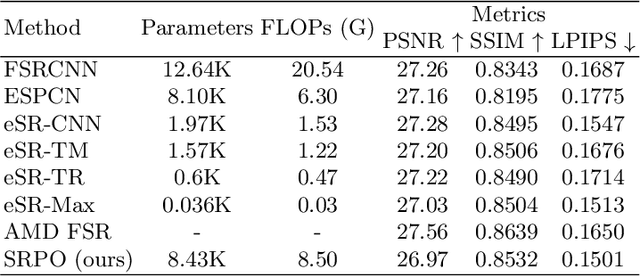
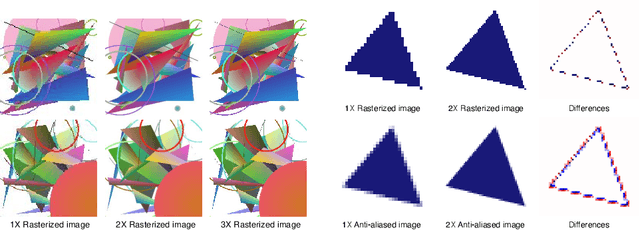
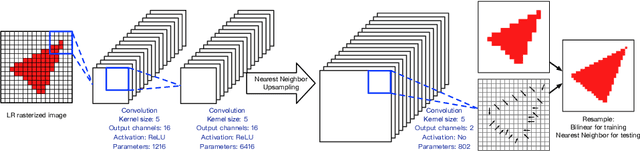
Rendering high-resolution (HR) graphics brings substantial computational costs. Efficient graphics super-resolution (SR) methods may achieve HR rendering with small computing resources and have attracted extensive research interests in industry and research communities. We present a new method for real-time SR for computer graphics, namely Super-Resolution by Predicting Offsets (SRPO). Our algorithm divides the image into two parts for processing, i.e., sharp edges and flatter areas. For edges, different from the previous SR methods that take the anti-aliased images as inputs, our proposed SRPO takes advantage of the characteristics of rasterized images to conduct SR on the rasterized images. To complement the residual between HR and low-resolution (LR) rasterized images, we train an ultra-efficient network to predict the offset maps to move the appropriate surrounding pixels to the new positions. For flat areas, we found simple interpolation methods can already generate reasonable output. We finally use a guided fusion operation to integrate the sharp edges generated by the network and flat areas by the interpolation method to get the final SR image. The proposed network only contains 8,434 parameters and can be accelerated by network quantization. Extensive experiments show that the proposed SRPO can achieve superior visual effects at a smaller computational cost than the existing state-of-the-art methods.
ReMix: A General and Efficient Framework for Multiple Instance Learning based Whole Slide Image Classification
Jul 05, 2022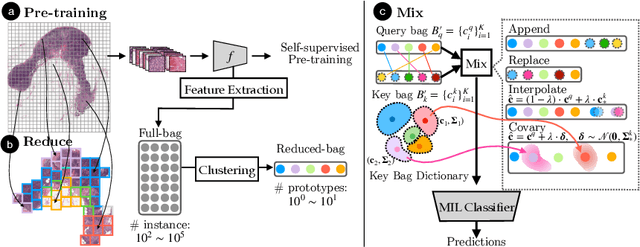
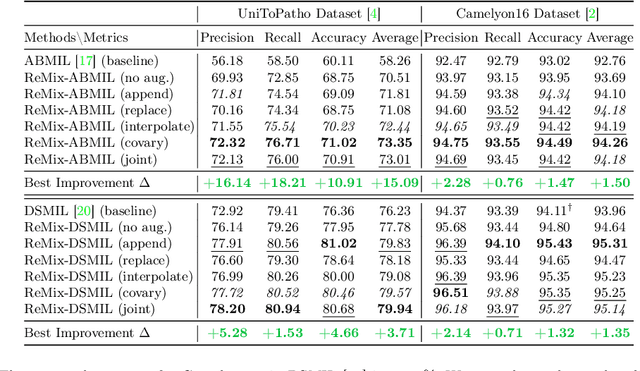
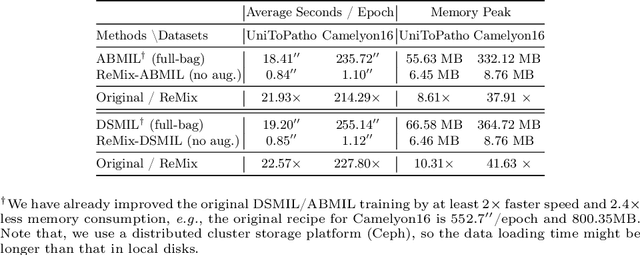

Whole slide image (WSI) classification often relies on deep weakly supervised multiple instance learning (MIL) methods to handle gigapixel resolution images and slide-level labels. Yet the decent performance of deep learning comes from harnessing massive datasets and diverse samples, urging the need for efficient training pipelines for scaling to large datasets and data augmentation techniques for diversifying samples. However, current MIL-based WSI classification pipelines are memory-expensive and computation-inefficient since they usually assemble tens of thousands of patches as bags for computation. On the other hand, despite their popularity in other tasks, data augmentations are unexplored for WSI MIL frameworks. To address them, we propose ReMix, a general and efficient framework for MIL based WSI classification. It comprises two steps: reduce and mix. First, it reduces the number of instances in WSI bags by substituting instances with instance prototypes, i.e., patch cluster centroids. Then, we propose a ``Mix-the-bag'' augmentation that contains four online, stochastic and flexible latent space augmentations. It brings diverse and reliable class-identity-preserving semantic changes in the latent space while enforcing semantic-perturbation invariance. We evaluate ReMix on two public datasets with two state-of-the-art MIL methods. In our experiments, consistent improvements in precision, accuracy, and recall have been achieved but with orders of magnitude reduced training time and memory consumption, demonstrating ReMix's effectiveness and efficiency. Code is available.