 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Trustworthy Partial Label Learning with Out-of-distribution Detection
Mar 11, 2024
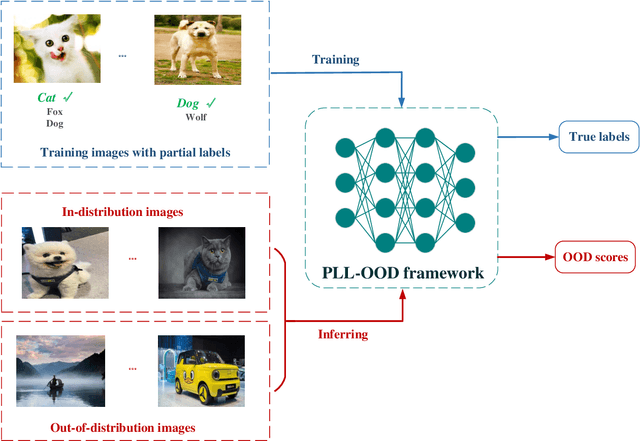
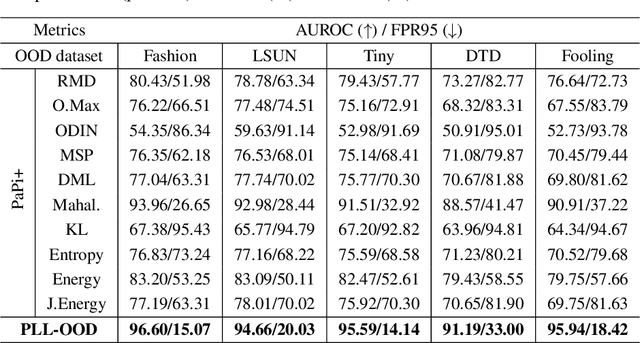
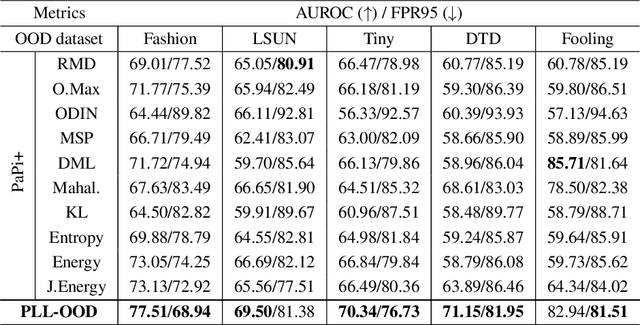
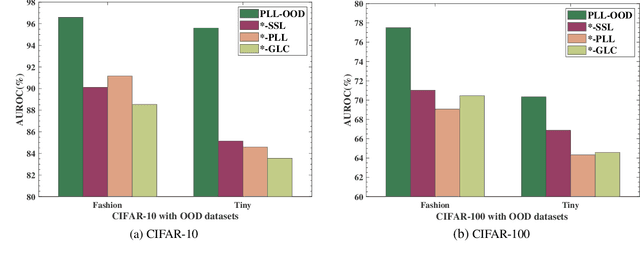
Partial Label Learning (PLL) grapples with learning from ambiguously labelled data, and it has been successfully applied in fields such as image recognition. Nevertheless, traditional PLL methods rely on the closed-world assumption, which can be limiting in open-world scenarios and negatively impact model performance and generalization. To tackle these challenges, our study introduces a novel method called PLL-OOD, which is the first to incorporate Out-of-Distribution (OOD) detection into the PLL framework. PLL-OOD significantly enhances model adaptability and accuracy by merging self-supervised learning with partial label loss and pioneering the Partial-Energy (PE) score for OOD detection. This approach improves data feature representation and effectively disambiguates candidate labels, using a dynamic label confidence matrix to refine predictions. The PE score, adjusted by label confidence, precisely identifies OOD instances, optimizing model training towards in-distribution data. This innovative method markedly boosts PLL model robustness and performance in open-world settings. To validate our approach, we conducted a comprehensive comparative experiment combining the existing state-of-the-art PLL model with multiple OOD scores on the CIFAR-10 and CIFAR-100 datasets with various OOD datasets. The results demonstrate that the proposed PLL-OOD framework is highly effective and effectiveness outperforms existing models, showcasing its superiority and effectiveness.
How to Understand Named Entities: Using Common Sense for News Captioning
Mar 11, 2024
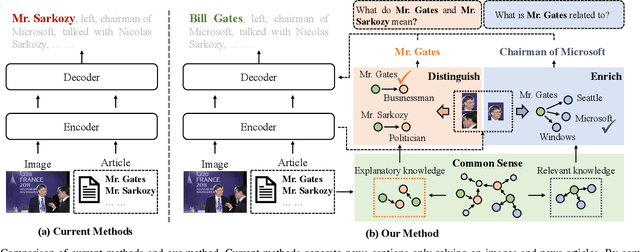
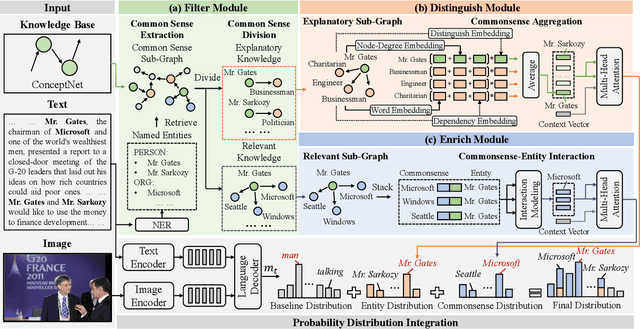
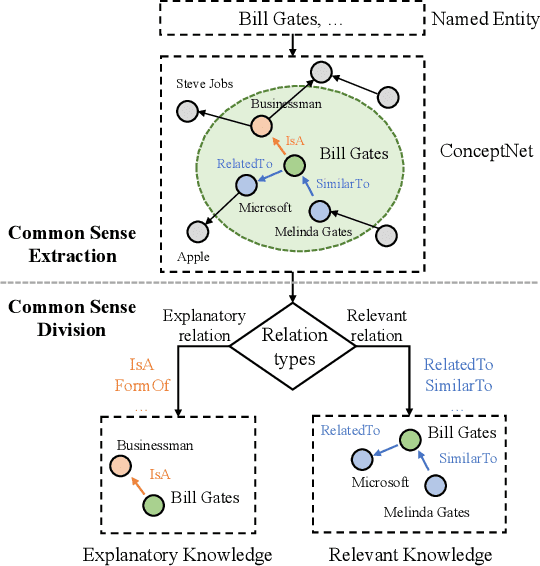
News captioning aims to describe an image with its news article body as input. It greatly relies on a set of detected named entities, including real-world people, organizations, and places. This paper exploits commonsense knowledge to understand named entities for news captioning. By ``understand'', we mean correlating the news content with common sense in the wild, which helps an agent to 1) distinguish semantically similar named entities and 2) describe named entities using words outside of training corpora. Our approach consists of three modules: (a) Filter Module aims to clarify the common sense concerning a named entity from two aspects: what does it mean? and what is it related to?, which divide the common sense into explanatory knowledge and relevant knowledge, respectively. (b) Distinguish Module aggregates explanatory knowledge from node-degree, dependency, and distinguish three aspects to distinguish semantically similar named entities. (c) Enrich Module attaches relevant knowledge to named entities to enrich the entity description by commonsense information (e.g., identity and social position). Finally, the probability distributions from both modules are integrated to generate the news captions. Extensive experiments on two challenging datasets (i.e., GoodNews and NYTimes) demonstrate the superiority of our method. Ablation studies and visualization further validate its effectiveness in understanding named entities.
Explainable Transformer Prototypes for Medical Diagnoses
Mar 11, 2024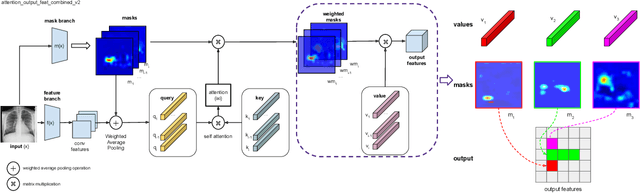
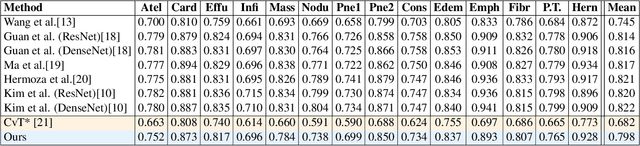
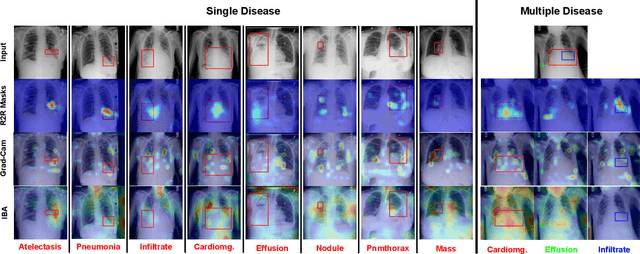
Deployments of artificial intelligence in medical diagnostics mandate not just accuracy and efficacy but also trust, emphasizing the need for explainability in machine decisions. The recent trend in automated medical image diagnostics leans towards the deployment of Transformer-based architectures, credited to their impressive capabilities. Since the self-attention feature of transformers contributes towards identifying crucial regions during the classification process, they enhance the trustability of the methods. However, the complex intricacies of these attention mechanisms may fall short of effectively pinpointing the regions of interest directly influencing AI decisions. Our research endeavors to innovate a unique attention block that underscores the correlation between 'regions' rather than 'pixels'. To address this challenge, we introduce an innovative system grounded in prototype learning, featuring an advanced self-attention mechanism that goes beyond conventional ad-hoc visual explanation techniques by offering comprehensible visual insights. A combined quantitative and qualitative methodological approach was used to demonstrate the effectiveness of the proposed method on the large-scale NIH chest X-ray dataset. Experimental results showed that our proposed method offers a promising direction for explainability, which can lead to the development of more trustable systems, which can facilitate easier and rapid adoption of such technology into routine clinics. The code is available at www.github.com/NUBagcilab/r2r_proto.
Real-Time Simulated Avatar from Head-Mounted Sensors
Mar 11, 2024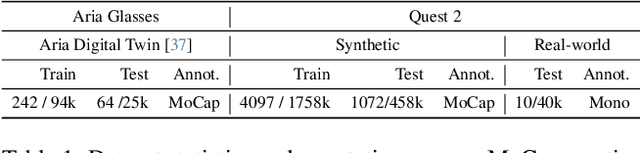

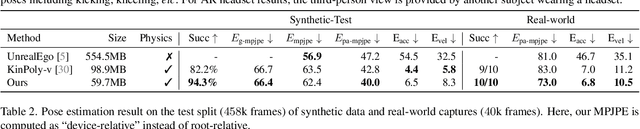
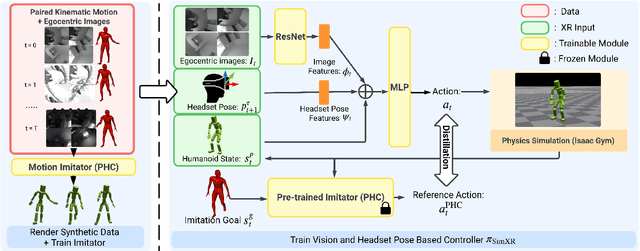
We present SimXR, a method for controlling a simulated avatar from information (headset pose and cameras) obtained from AR / VR headsets. Due to the challenging viewpoint of head-mounted cameras, the human body is often clipped out of view, making traditional image-based egocentric pose estimation challenging. On the other hand, headset poses provide valuable information about overall body motion, but lack fine-grained details about the hands and feet. To synergize headset poses with cameras, we control a humanoid to track headset movement while analyzing input images to decide body movement. When body parts are seen, the movements of hands and feet will be guided by the images; when unseen, the laws of physics guide the controller to generate plausible motion. We design an end-to-end method that does not rely on any intermediate representations and learns to directly map from images and headset poses to humanoid control signals. To train our method, we also propose a large-scale synthetic dataset created using camera configurations compatible with a commercially available VR headset (Quest 2) and show promising results on real-world captures. To demonstrate the applicability of our framework, we also test it on an AR headset with a forward-facing camera.
Attention Prompt Tuning: Parameter-efficient Adaptation of Pre-trained Models for Spatiotemporal Modeling
Mar 11, 2024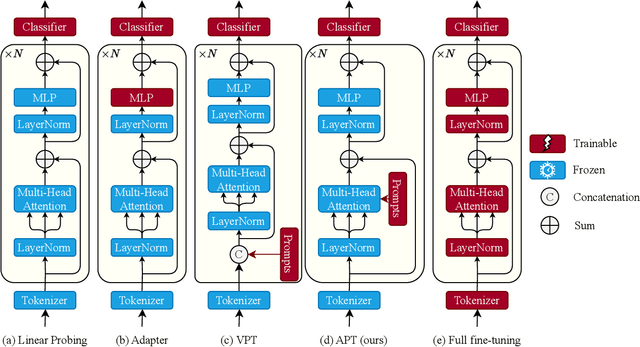
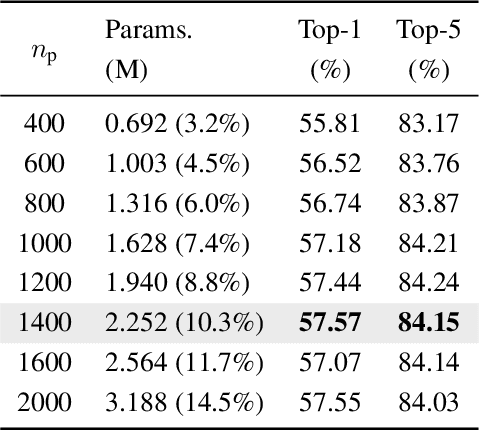
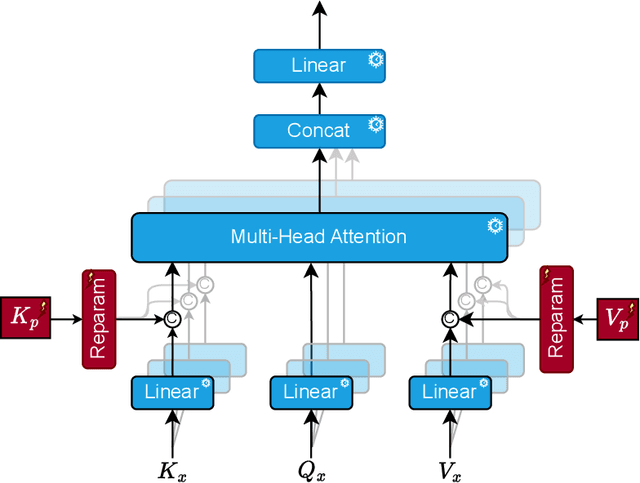
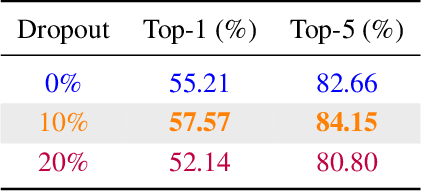
In this paper, we introduce Attention Prompt Tuning (APT) - a computationally efficient variant of prompt tuning for video-based applications such as action recognition. Prompt tuning approaches involve injecting a set of learnable prompts along with data tokens during fine-tuning while keeping the backbone frozen. This approach greatly reduces the number of learnable parameters compared to full tuning. For image-based downstream tasks, normally a couple of learnable prompts achieve results close to those of full tuning. However, videos, which contain more complex spatiotemporal information, require hundreds of tunable prompts to achieve reasonably good results. This reduces the parameter efficiency observed in images and significantly increases latency and the number of floating-point operations (FLOPs) during inference. To tackle these issues, we directly inject the prompts into the keys and values of the non-local attention mechanism within the transformer block. Additionally, we introduce a novel prompt reparameterization technique to make APT more robust against hyperparameter selection. The proposed APT approach greatly reduces the number of FLOPs and latency while achieving a significant performance boost over the existing parameter-efficient tuning methods on UCF101, HMDB51, and SSv2 datasets for action recognition. The code and pre-trained models are available at https://github.com/wgcban/apt
Temporal-Mapping Photography for Event Cameras
Mar 11, 2024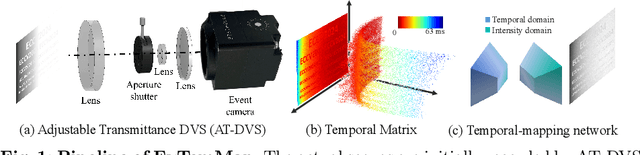

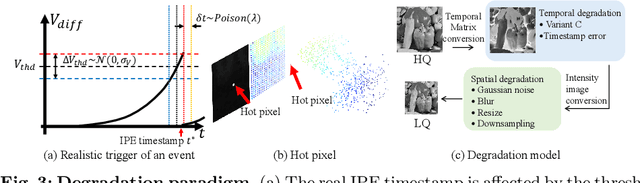
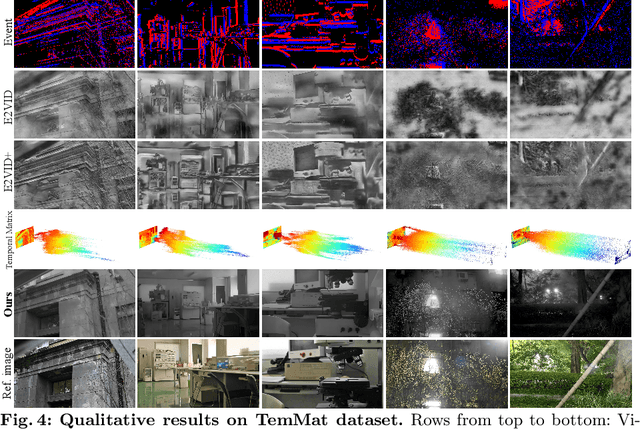
Event cameras, or Dynamic Vision Sensors (DVS) are novel neuromorphic sensors that capture brightness changes as a continuous stream of ``events'' rather than traditional intensity frames. Converting sparse events to dense intensity frames faithfully has long been an ill-posed problem. Previous methods have primarily focused on converting events to video in dynamic scenes or with a moving camera. In this paper, for the first time, we realize events to dense intensity image conversion using a stationary event camera in static scenes. Different from traditional methods that mainly rely on event integration, the proposed Event-Based Temporal Mapping Photography (EvTemMap) measures the time of event emitting for each pixel. Then, the resulting Temporal Matrix is converted to an intensity frame with a temporal mapping neural network. At the hardware level, the proposed EvTemMap is implemented by combining a transmittance adjustment device with a DVS, named Adjustable Transmittance Dynamic Vision Sensor. Additionally, we collected TemMat dataset under various conditions including low-light and high dynamic range scenes. The experimental results showcase the high dynamic range, fine-grained details, and high-grayscale-resolution of the proposed EvTemMap, as well as the enhanced performance on downstream computer vision tasks compared to other methods. The code and TemMat dataset will be made publicly available.
MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets
Mar 05, 2024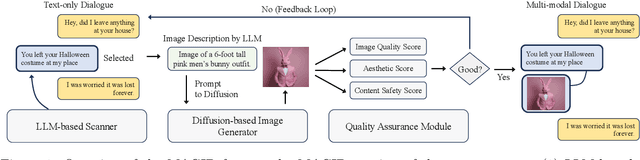
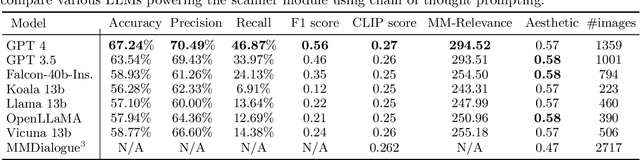

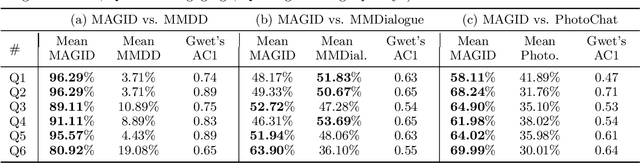
Development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints. In this work, we introduce \textbf{M}ultimodal \textbf{A}ugmented \textbf{G}enerative \textbf{I}mages \textbf{D}ialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text. Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation. Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.
Combined optimization ghost imaging based on random speckle field
Mar 06, 2024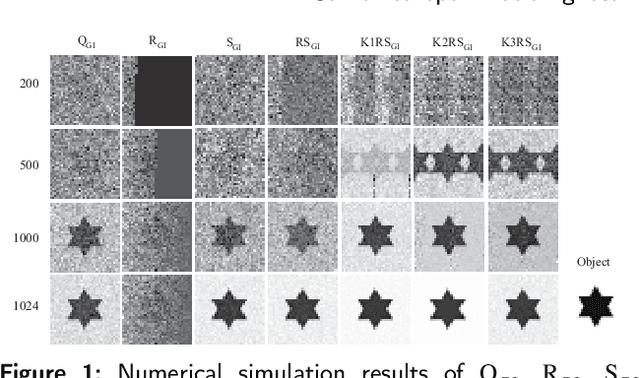

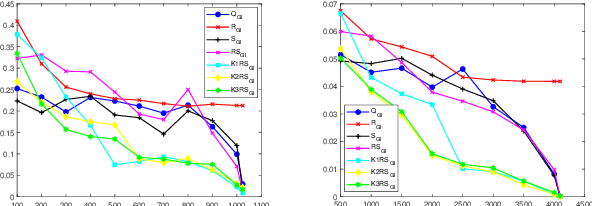
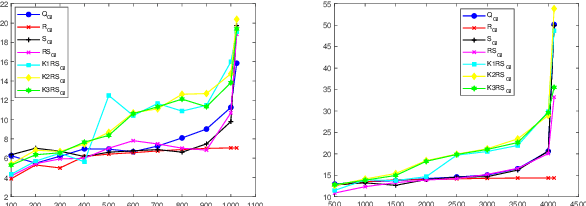
Ghost imaging is a non local imaging technology, which can obtain target information by measuring the second-order intensity correlation between the reference light field and the target detection light field. However, the current imaging environment requires a large number of measurement data, and the imaging results also have the problems of low image resolution and long reconstruction time. Therefore, using orthogonal methods such as QR decomposition, a variety of optimization methods for speckle patterns are designed combined with Kronecker product,which can help to shorten the imaging time, improve the imaging quality and image noise resistance.
Fast, nonlocal and neural: a lightweight high quality solution to image denoising
Mar 06, 2024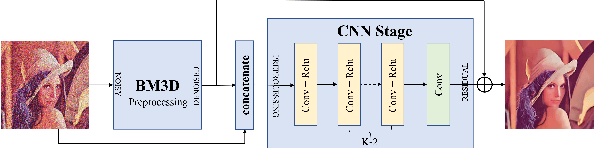

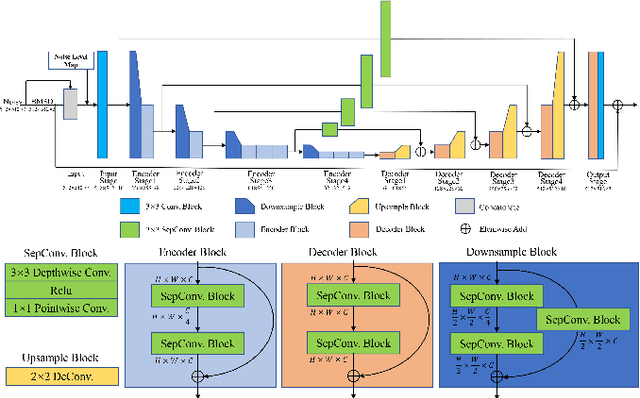

With the widespread application of convolutional neural networks (CNNs), the traditional model based denoising algorithms are now outperformed. However, CNNs face two problems. First, they are computationally demanding, which makes their deployment especially difficult for mobile terminals. Second, experimental evidence shows that CNNs often over-smooth regular textures present in images, in contrast to traditional non-local models. In this letter, we propose a solution to both issues by combining a nonlocal algorithm with a lightweight residual CNN. This solution gives full latitude to the advantages of both models. We apply this framework to two GPU implementations of classic nonlocal algorithms (NLM and BM3D) and observe a substantial gain in both cases, performing better than the state-of-the-art with low computational requirements. Our solution is between 10 and 20 times faster than CNNs with equivalent performance and attains higher PSNR. In addition the final method shows a notable gain on images containing complex textures like the ones of the MIT Moire dataset.
* 5 pages. This paper was accepted by IEEE Signal Processing Letters on July 1, 2021
Debiasing Text-to-Image Diffusion Models
Feb 22, 2024Learning-based Text-to-Image (TTI) models like Stable Diffusion have revolutionized the way visual content is generated in various domains. However, recent research has shown that nonnegligible social bias exists in current state-of-the-art TTI systems, which raises important concerns. In this work, we target resolving the social bias in TTI diffusion models. We begin by formalizing the problem setting and use the text descriptions of bias groups to establish an unsafe direction for guiding the diffusion process. Next, we simplify the problem into a weight optimization problem and attempt a Reinforcement solver, Policy Gradient, which shows sub-optimal performance with slow convergence. Further, to overcome limitations, we propose an iterative distribution alignment (IDA) method. Despite its simplicity, we show that IDA shows efficiency and fast convergence in resolving the social bias in TTI diffusion models. Our code will be released.