 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using U-Net Network for Efficient Brain Tumor Segmentation in MRI Images
Nov 03, 2022
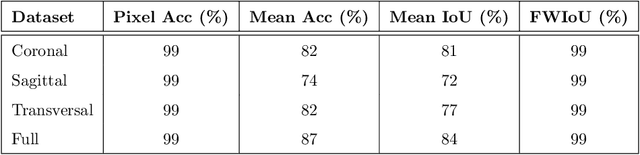
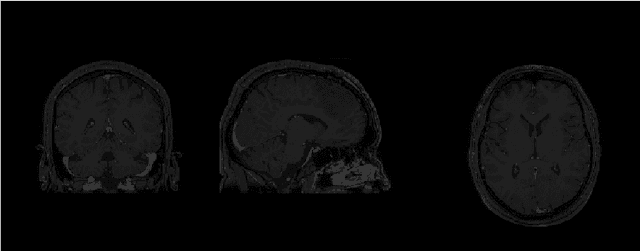
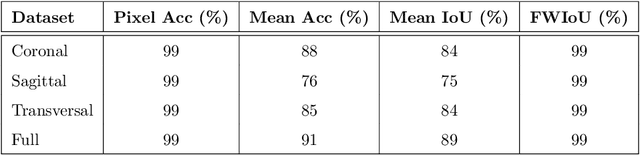
Magnetic Resonance Imaging (MRI) is the most commonly used non-intrusive technique for medical image acquisition. Brain tumor segmentation is the process of algorithmically identifying tumors in brain MRI scans. While many approaches have been proposed in the literature for brain tumor segmentation, this paper proposes a lightweight implementation of U-Net. Apart from providing real-time segmentation of MRI scans, the proposed architecture does not need large amount of data to train the proposed lightweight U-Net. Moreover, no additional data augmentation step is required. The lightweight U-Net shows very promising results on BITE dataset and it achieves a mean intersection-over-union (IoU) of 89% while outperforming the standard benchmark algorithms. Additionally, this work demonstrates an effective use of the three perspective planes, instead of the original three-dimensional volumetric images, for simplified brain tumor segmentation.
DiMBERT: Learning Vision-Language Grounded Representations with Disentangled Multimodal-Attention
Oct 28, 2022
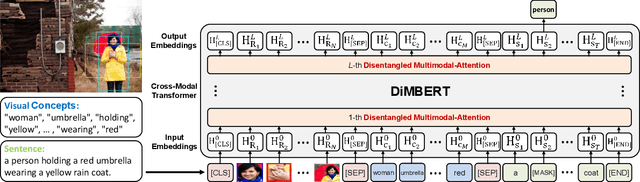
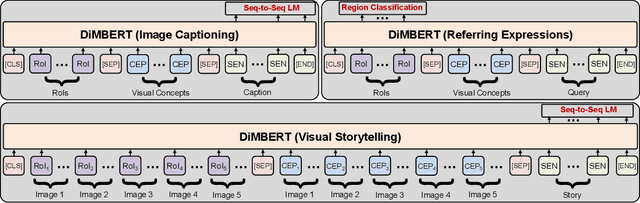
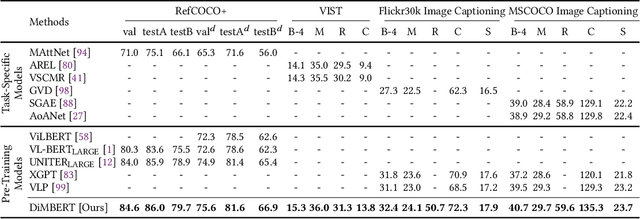
Vision-and-language (V-L) tasks require the system to understand both vision content and natural language, thus learning fine-grained joint representations of vision and language (a.k.a. V-L representations) is of paramount importance. Recently, various pre-trained V-L models are proposed to learn V-L representations and achieve improved results in many tasks. However, the mainstream models process both vision and language inputs with the same set of attention matrices. As a result, the generated V-L representations are entangled in one common latent space. To tackle this problem, we propose DiMBERT (short for Disentangled Multimodal-Attention BERT), which is a novel framework that applies separated attention spaces for vision and language, and the representations of multi-modalities can thus be disentangled explicitly. To enhance the correlation between vision and language in disentangled spaces, we introduce the visual concepts to DiMBERT which represent visual information in textual format. In this manner, visual concepts help to bridge the gap between the two modalities. We pre-train DiMBERT on a large amount of image-sentence pairs on two tasks: bidirectional language modeling and sequence-to-sequence language modeling. After pre-train, DiMBERT is further fine-tuned for the downstream tasks. Experiments show that DiMBERT sets new state-of-the-art performance on three tasks (over four datasets), including both generation tasks (image captioning and visual storytelling) and classification tasks (referring expressions). The proposed DiM (short for Disentangled Multimodal-Attention) module can be easily incorporated into existing pre-trained V-L models to boost their performance, up to a 5% increase on the representative task. Finally, we conduct a systematic analysis and demonstrate the effectiveness of our DiM and the introduced visual concepts.
Confusing Image Quality Assessment: Towards Better Augmented Reality Experience
Apr 11, 2022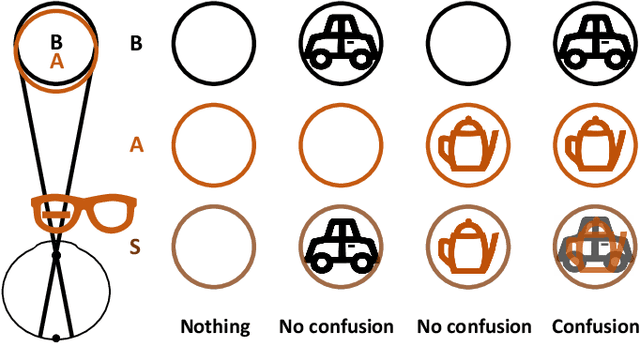
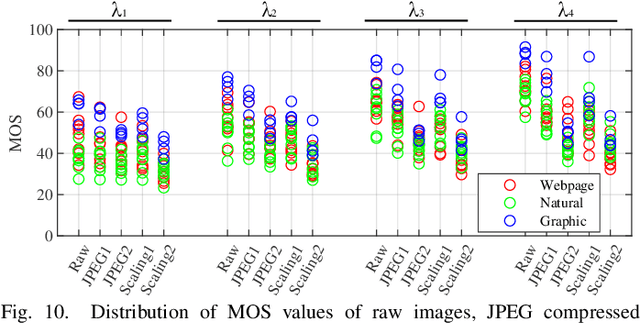
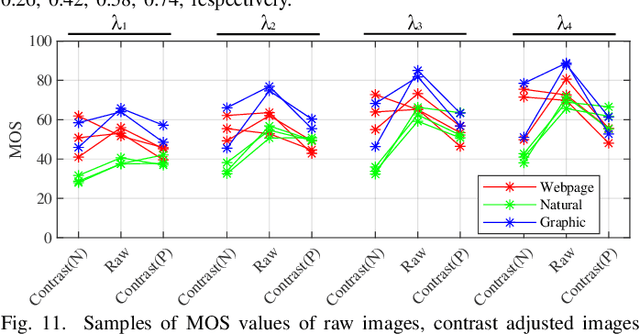
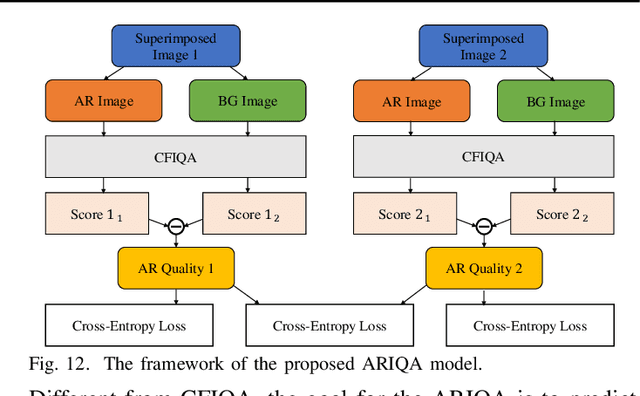
With the development of multimedia technology, Augmented Reality (AR) has become a promising next-generation mobile platform. The primary value of AR is to promote the fusion of digital contents and real-world environments, however, studies on how this fusion will influence the Quality of Experience (QoE) of these two components are lacking. To achieve better QoE of AR, whose two layers are influenced by each other, it is important to evaluate its perceptual quality first. In this paper, we consider AR technology as the superimposition of virtual scenes and real scenes, and introduce visual confusion as its basic theory. A more general problem is first proposed, which is evaluating the perceptual quality of superimposed images, i.e., confusing image quality assessment. A ConFusing Image Quality Assessment (CFIQA) database is established, which includes 600 reference images and 300 distorted images generated by mixing reference images in pairs. Then a subjective quality perception study and an objective model evaluation experiment are conducted towards attaining a better understanding of how humans perceive the confusing images. An objective metric termed CFIQA is also proposed to better evaluate the confusing image quality. Moreover, an extended ARIQA study is further conducted based on the CFIQA study. We establish an ARIQA database to better simulate the real AR application scenarios, which contains 20 AR reference images, 20 background (BG) reference images, and 560 distorted images generated from AR and BG references, as well as the correspondingly collected subjective quality ratings. We also design three types of full-reference (FR) IQA metrics to study whether we should consider the visual confusion when designing corresponding IQA algorithms. An ARIQA metric is finally proposed for better evaluating the perceptual quality of AR images.
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints
May 10, 2022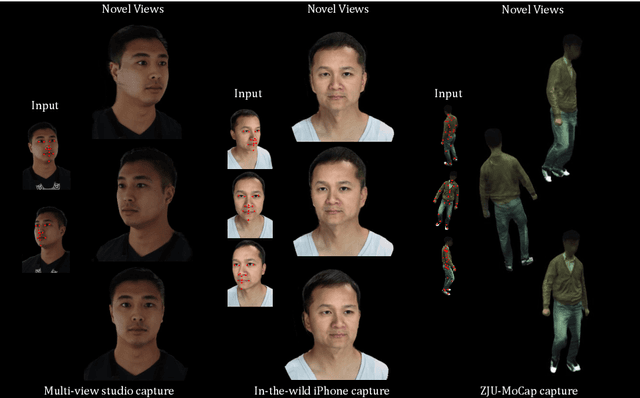

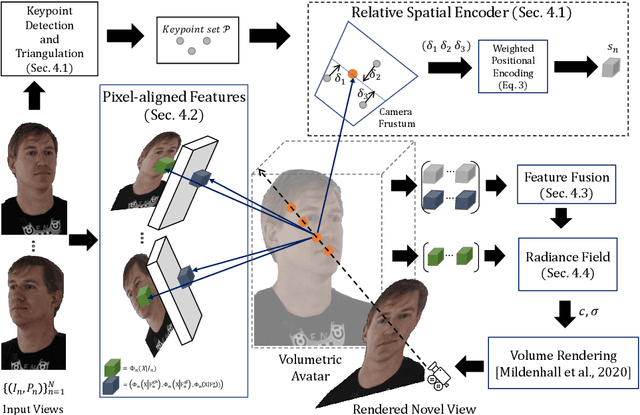
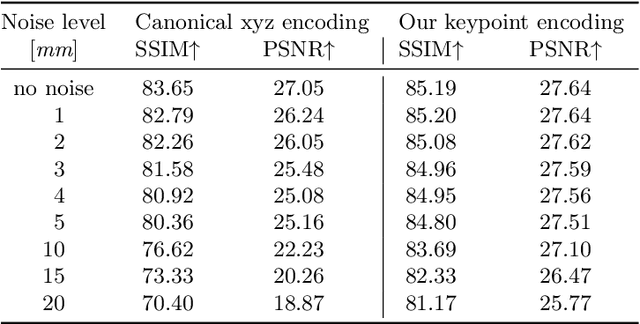
Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior work that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling. https://markomih.github.io/KeypointNeRF
D$^\text{2}$UF: Deep Coded Aperture Design and Unrolling Algorithm for Compressive Spectral Image Fusion
May 24, 2022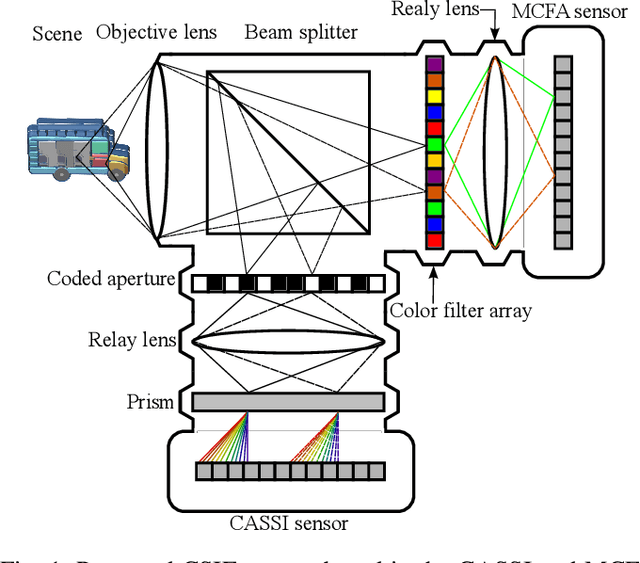
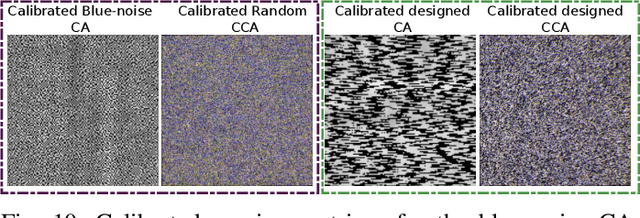
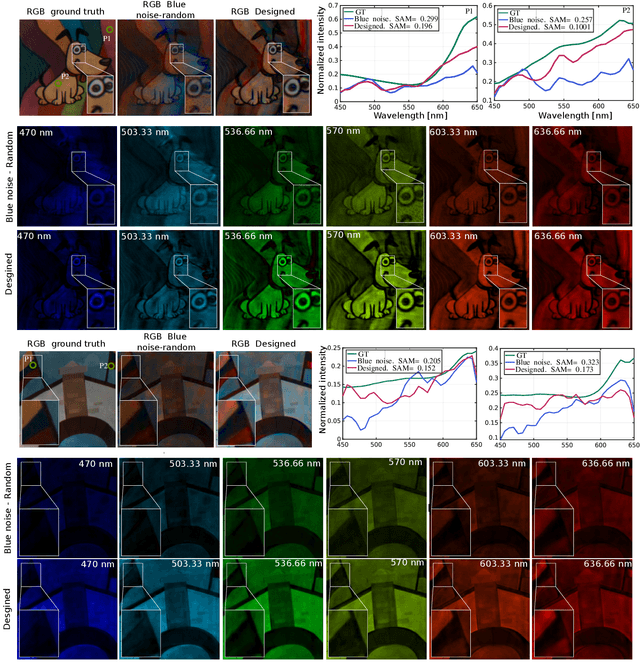
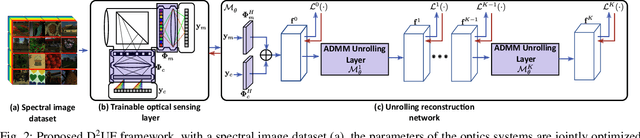
Compressive spectral imaging (CSI) has attracted significant attention since it employs synthetic apertures to codify spatial and spectral information, sensing only 2D projections of the 3D spectral image. However, these optical architectures suffer from a trade-off between the spatial and spectral resolution of the reconstructed image due to technology limitations. To overcome this issue, compressive spectral image fusion (CSIF) employs the projected measurements of two CSI architectures with different resolutions to estimate a high-spatial high-spectral resolution. This work presents the fusion of the compressive measurements of a low-spatial high-spectral resolution coded aperture snapshot spectral imager (CASSI) architecture and a high-spatial low-spectral resolution multispectral color filter array (MCFA) system. Unlike previous CSIF works, this paper proposes joint optimization of the sensing architectures and a reconstruction network in an end-to-end (E2E) manner. The trainable optical parameters are the coded aperture (CA) in the CASSI and the colored coded aperture in the MCFA system, employing a sigmoid activation function and regularization function to encourage binary values on the trainable variables for an implementation purpose. Additionally, an unrolling-based network inspired by the alternating direction method of multipliers (ADMM) optimization is formulated to address the reconstruction step and the acquisition systems design jointly. Finally, a spatial-spectral inspired loss function is employed at the end of each unrolling layer to increase the convergence of the unrolling network. The proposed method outperforms previous CSIF methods, and experimental results validate the method with real measurements.
Boosting Few-shot Fine-grained Recognition with Background Suppression and Foreground Alignment
Oct 04, 2022
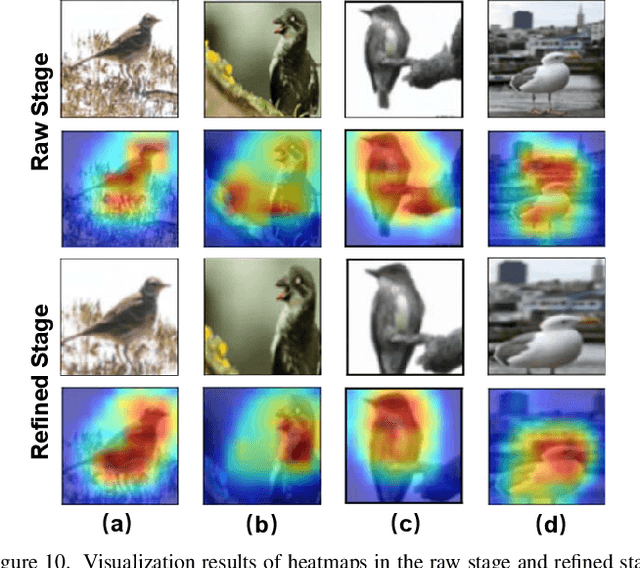
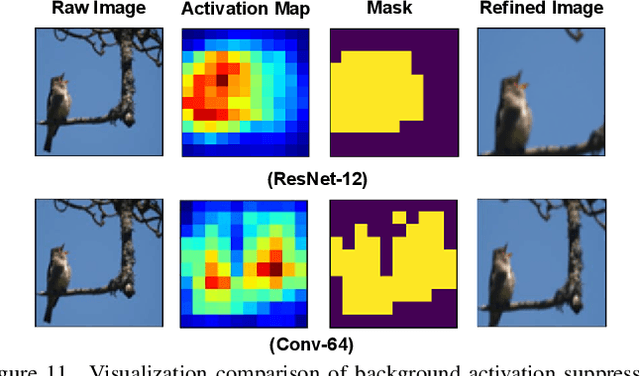
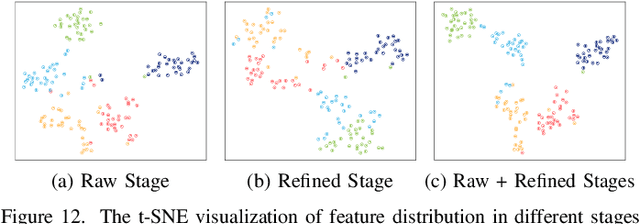
Few-shot fine-grained recognition (FS-FGR) aims to recognize novel fine-grained categories with the help of limited available samples. Undoubtedly, this task inherits the main challenges from both few-shot learning and fine-grained recognition. First, the lack of labeled samples makes the learned model easy to overfit. Second, it also suffers from high intra-class variance and low inter-class difference in the datasets. To address this challenging task, we propose a two-stage background suppression and foreground alignment framework, which is composed of a background activation suppression (BAS) module, a foreground object alignment (FOA) module, and a local to local (L2L) similarity metric. Specifically, the BAS is introduced to generate a foreground mask for localization to weaken background disturbance and enhance dominative foreground objects. What's more, considering the lack of labeled samples, we compute the pairwise similarity of feature maps using both the raw image and the refined image. The FOA then reconstructs the feature map of each support sample according to its correction to the query ones, which addresses the problem of misalignment between support-query image pairs. To enable the proposed method to have the ability to capture subtle differences in confused samples, we present a novel L2L similarity metric to further measure the local similarity between a pair of aligned spatial features in the embedding space. Extensive experiments conducted on multiple popular fine-grained benchmarks demonstrate that our method outperforms the existing state-of-the-art by a large margin.
Multiple Degradation and Reconstruction Network for Single Image Denoising via Knowledge Distillation
Apr 29, 2022
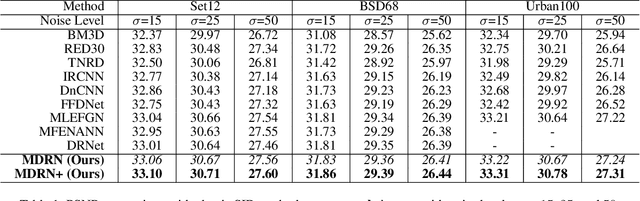

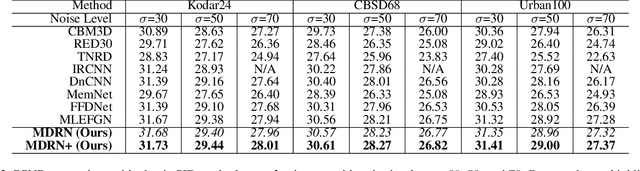
Single image denoising (SID) has achieved significant breakthroughs with the development of deep learning. However, the proposed methods are often accompanied by plenty of parameters, which greatly limits their application scenarios. Different from previous works that blindly increase the depth of the network, we explore the degradation mechanism of the noisy image and propose a lightweight Multiple Degradation and Reconstruction Network (MDRN) to progressively remove noise. Meanwhile, we propose two novel Heterogeneous Knowledge Distillation Strategies (HMDS) to enable MDRN to learn richer and more accurate features from heterogeneous models, which make it possible to reconstruct higher-quality denoised images under extreme conditions. Extensive experiments show that our MDRN achieves favorable performance against other SID models with fewer parameters. Meanwhile, plenty of ablation studies demonstrate that the introduced HMDS can improve the performance of tiny models or the model under high noise levels, which is extremely useful for related applications.
Automated analysis of diabetic retinopathy using vessel segmentation maps as inductive bias
Oct 28, 2022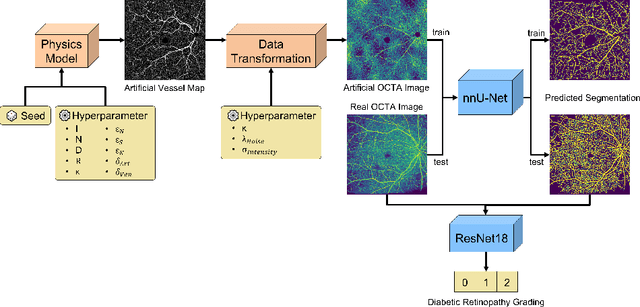

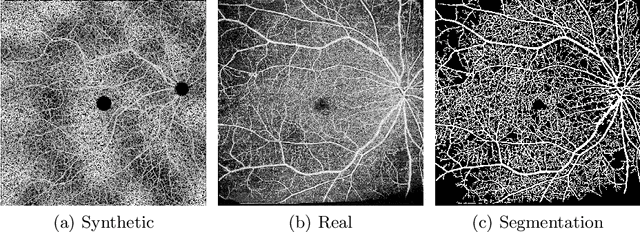
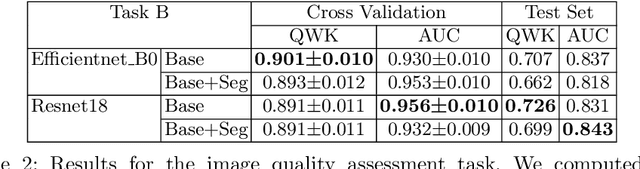
Recent studies suggest that early stages of diabetic retinopathy (DR) can be diagnosed by monitoring vascular changes in the deep vascular complex. In this work, we investigate a novel method for automated DR grading based on optical coherence tomography angiography (OCTA) images. Our work combines OCTA scans with their vessel segmentations, which then serve as inputs to task specific networks for lesion segmentation, image quality assessment and DR grading. For this, we generate synthetic OCTA images to train a segmentation network that can be directly applied on real OCTA data. We test our approach on MICCAI 2022's DR analysis challenge (DRAC). In our experiments, the proposed method performs equally well as the baseline model.
Self-Supervised Coordinate Projection Network for Sparse-View Computed Tomography
Sep 12, 2022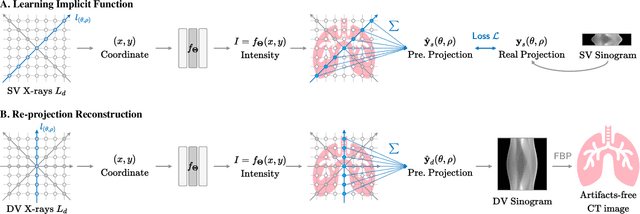
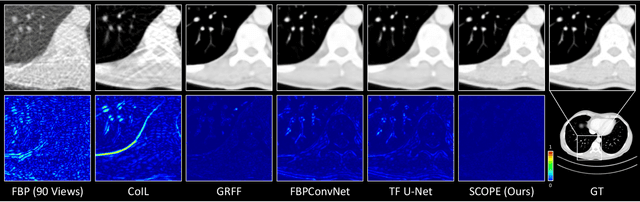
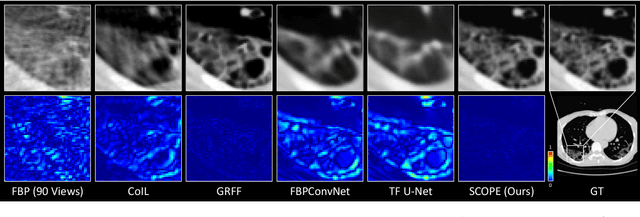
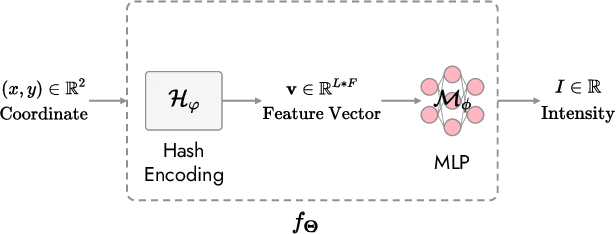
In the present work, we propose a Self-supervised COordinate Projection nEtwork (SCOPE) to reconstruct the artifacts-free CT image from a single SV sinogram by solving the inverse tomography imaging problem. Compared with recent related works that solve similar problems using implicit neural representation network (INR), our essential contribution is an effective and simple re-projection strategy that pushes the tomography image reconstruction quality over supervised deep learning CT reconstruction works. The proposed strategy is inspired by the simple relationship between linear algebra and inverse problems. To solve the under-determined linear equation system, we first introduce INR to constrain the solution space via image continuity prior and achieve a rough solution. And secondly, we propose to generate a dense view sinogram that improves the rank of the linear equation system and produces a more stable CT image solution space. Our experiment results demonstrate that the re-projection strategy significantly improves the image reconstruction quality (+3 dB for PSNR at least). Besides, we integrate the recent hash encoding into our SCOPE model, which greatly accelerates the model training. Finally, we evaluate SCOPE in parallel and fan X-ray beam SVCT reconstruction tasks. Experimental results indicate that the proposed SCOPE model outperforms two latest INR-based methods and two well-popular supervised DL methods quantitatively and qualitatively.
Sources of performance variability in deep learning-based polyp detection
Nov 17, 2022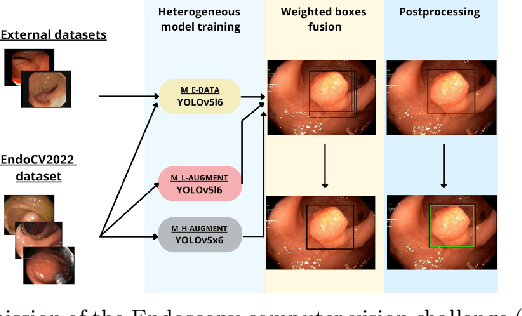
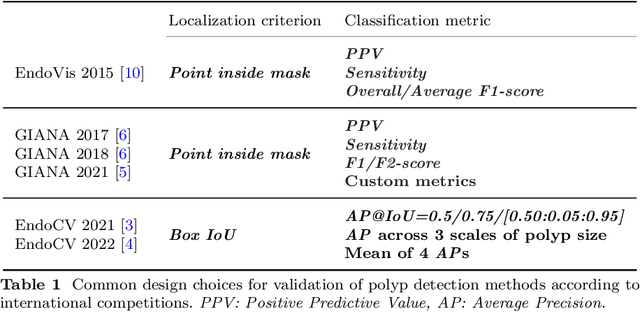
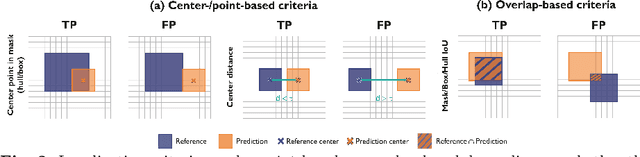
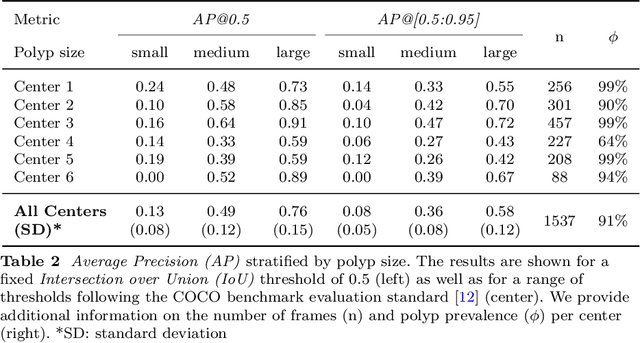
Validation metrics are a key prerequisite for the reliable tracking of scientific progress and for deciding on the potential clinical translation of methods. While recent initiatives aim to develop comprehensive theoretical frameworks for understanding metric-related pitfalls in image analysis problems, there is a lack of experimental evidence on the concrete effects of common and rare pitfalls on specific applications. We address this gap in the literature in the context of colon cancer screening. Our contribution is twofold. Firstly, we present the winning solution of the Endoscopy computer vision challenge (EndoCV) on colon cancer detection, conducted in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2022. Secondly, we demonstrate the sensitivity of commonly used metrics to a range of hyperparameters as well as the consequences of poor metric choices. Based on comprehensive validation studies performed with patient data from six clinical centers, we found all commonly applied object detection metrics to be subject to high inter-center variability. Furthermore, our results clearly demonstrate that the adaptation of standard hyperparameters used in the computer vision community does not generally lead to the clinically most plausible results. Finally, we present localization criteria that correspond well to clinical relevance. Our work could be a first step towards reconsidering common validation strategies in automatic colon cancer screening applications.