 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Understands Point Cloud: Weakly Supervised 3D Semantic Segmentation via Association Learning
Sep 16, 2022
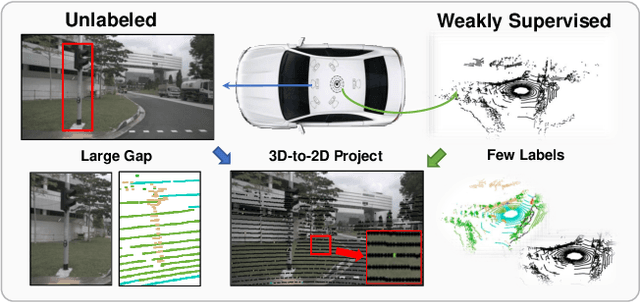
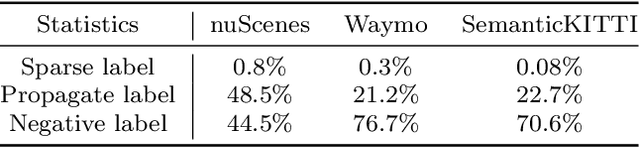

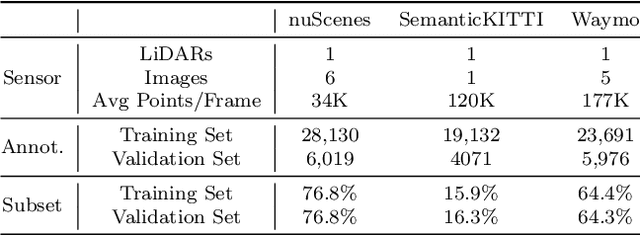
Weakly supervised point cloud semantic segmentation methods that require 1\% or fewer labels, hoping to realize almost the same performance as fully supervised approaches, which recently, have attracted extensive research attention. A typical solution in this framework is to use self-training or pseudo labeling to mine the supervision from the point cloud itself, but ignore the critical information from images. In fact, cameras widely exist in LiDAR scenarios and this complementary information seems to be greatly important for 3D applications. In this paper, we propose a novel cross-modality weakly supervised method for 3D segmentation, incorporating complementary information from unlabeled images. Basically, we design a dual-branch network equipped with an active labeling strategy, to maximize the power of tiny parts of labels and directly realize 2D-to-3D knowledge transfer. Afterwards, we establish a cross-modal self-training framework in an Expectation-Maximum (EM) perspective, which iterates between pseudo labels estimation and parameters updating. In the M-Step, we propose a cross-modal association learning to mine complementary supervision from images by reinforcing the cycle-consistency between 3D points and 2D superpixels. In the E-step, a pseudo label self-rectification mechanism is derived to filter noise labels thus providing more accurate labels for the networks to get fully trained. The extensive experimental results demonstrate that our method even outperforms the state-of-the-art fully supervised competitors with less than 1\% actively selected annotations.
Composite Feature Selection using Deep Ensembles
Nov 01, 2022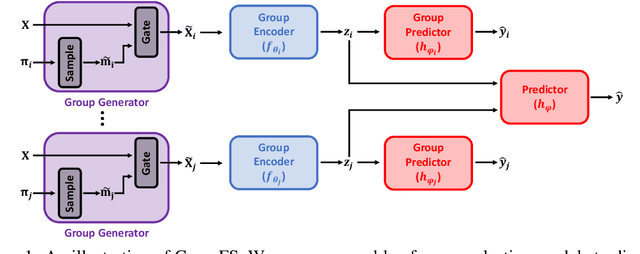
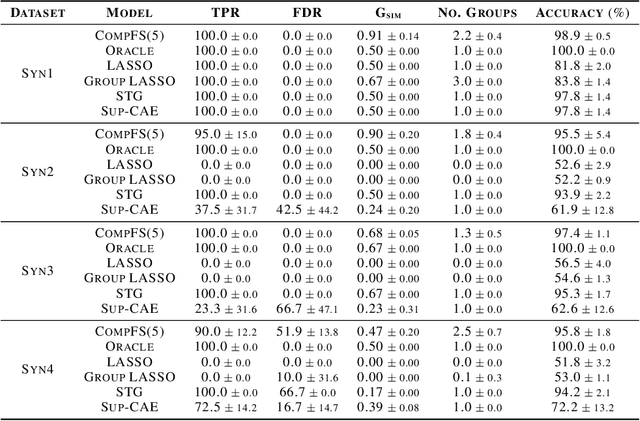
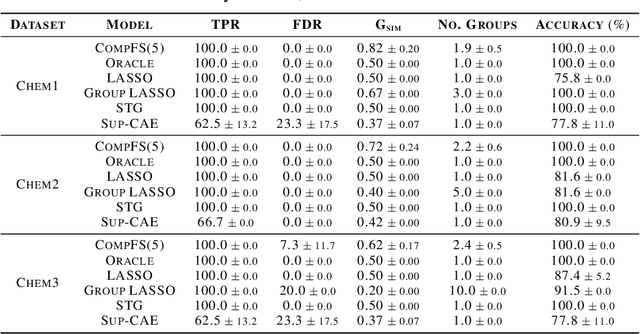

In many real world problems, features do not act alone but in combination with each other. For example, in genomics, diseases might not be caused by any single mutation but require the presence of multiple mutations. Prior work on feature selection either seeks to identify individual features or can only determine relevant groups from a predefined set. We investigate the problem of discovering groups of predictive features without predefined grouping. To do so, we define predictive groups in terms of linear and non-linear interactions between features. We introduce a novel deep learning architecture that uses an ensemble of feature selection models to find predictive groups, without requiring candidate groups to be provided. The selected groups are sparse and exhibit minimum overlap. Furthermore, we propose a new metric to measure similarity between discovered groups and the ground truth. We demonstrate the utility of our model on multiple synthetic tasks and semi-synthetic chemistry datasets, where the ground truth structure is known, as well as an image dataset and a real-world cancer dataset.
LARO: Learned Acquisition and Reconstruction Optimization to accelerate Quantitative Susceptibility Mapping
Nov 01, 2022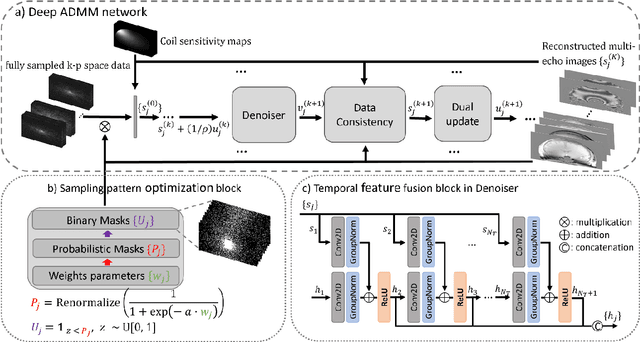
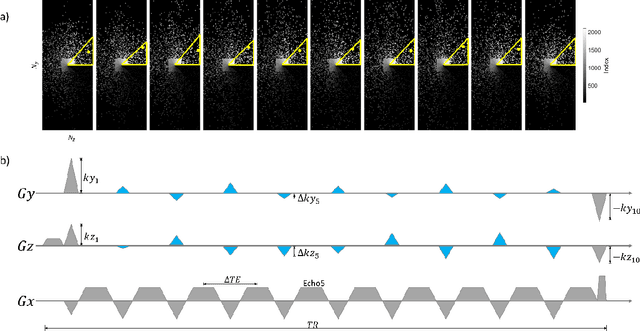

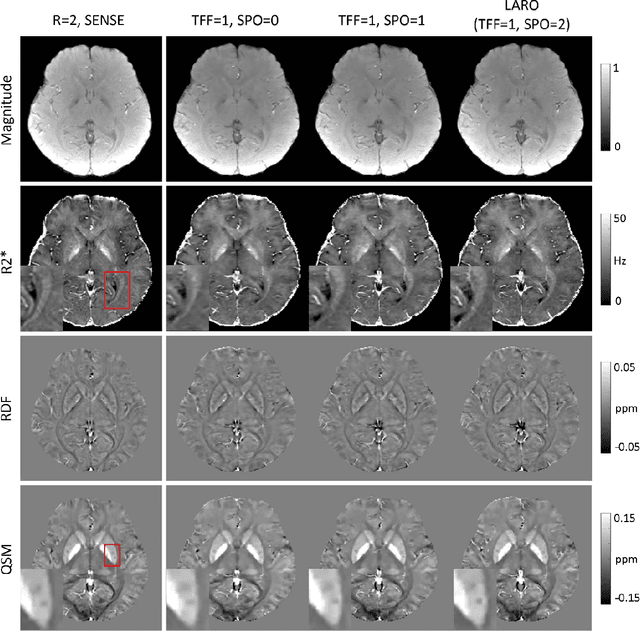
Quantitative susceptibility mapping (QSM) involves acquisition and reconstruction of a series of images at multi-echo time points to estimate tissue field, which prolongs scan time and requires specific reconstruction technique. In this paper, we present our new framework, called Learned Acquisition and Reconstruction Optimization (LARO), which aims to accelerate the multi-echo gradient echo (mGRE) pulse sequence for QSM. Our approach involves optimizing a Cartesian multi-echo k-space sampling pattern with a deep reconstruction network. Next, this optimized sampling pattern was implemented in an mGRE sequence using Cartesian fan-beam k-space segmenting and ordering for prospective scans. Furthermore, we propose to insert a recurrent temporal feature fusion module into the reconstruction network to capture signal redundancies along echo time. Our ablation studies show that both the optimized sampling pattern and proposed reconstruction strategy help improve the quality of the multi-echo image reconstructions. Generalization experiments show that LARO is robust on the test data with new pathologies and different sequence parameters. Our code is available at https://github.com/Jinwei1209/LARO.git.
MHITNet: a minimize network with a hierarchical context-attentional filter for segmenting medical ct images
Nov 01, 2022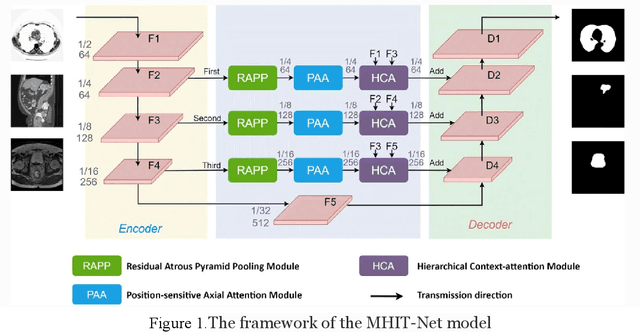
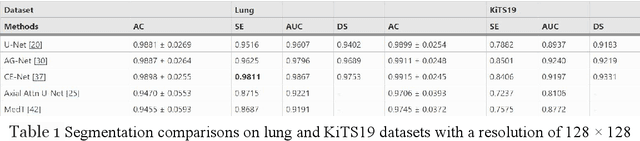
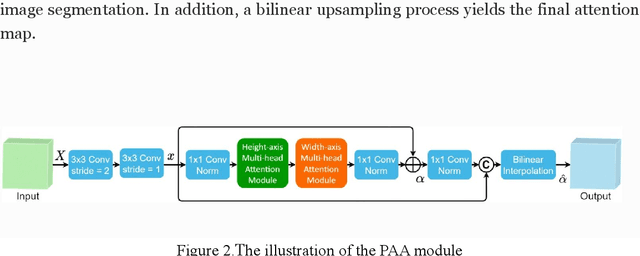
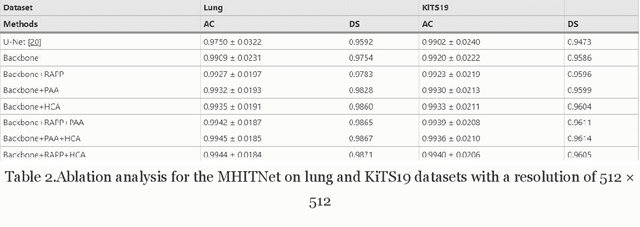
In the field of medical CT image processing, convolutional neural networks (CNNs) have been the dominant technique.Encoder-decoder CNNs utilise locality for efficiency, but they cannot simulate distant pixel interactions properly.Recent research indicates that self-attention or transformer layers can be stacked to efficiently learn long-range dependencies.By constructing and processing picture patches as embeddings, transformers have been applied to computer vision applications. However, transformer-based architectures lack global semantic information interaction and require a large-scale training dataset, making it challenging to train with small data samples. In order to solve these challenges, we present a hierarchical contextattention transformer network (MHITNet) that combines the multi-scale, transformer, and hierarchical context extraction modules in skip-connections. The multi-scale module captures deeper CT semantic information, enabling transformers to encode feature maps of tokenized picture patches from various CNN stages as input attention sequences more effectively. The hierarchical context attention module augments global data and reweights pixels to capture semantic context.Extensive trials on three datasets show that the proposed MHITNet beats current best practises
Stay Positive: Non-Negative Image Synthesis for Augmented Reality
Feb 01, 2022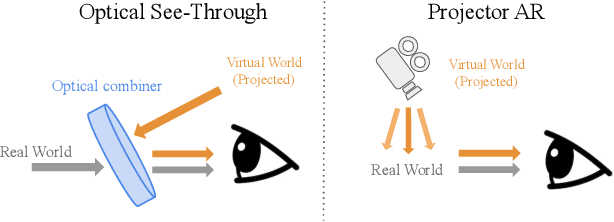
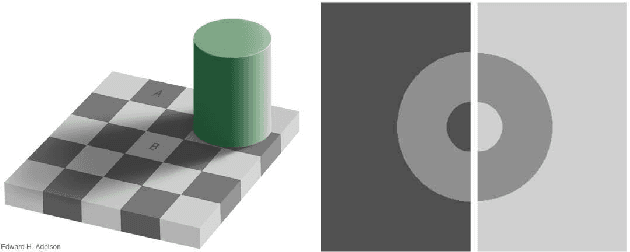
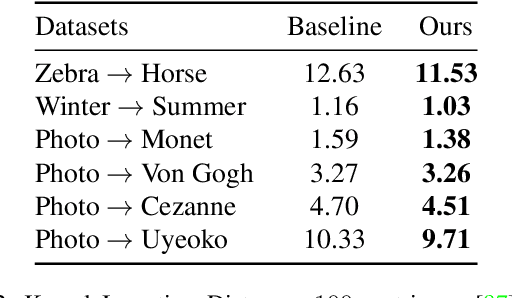
In applications such as optical see-through and projector augmented reality, producing images amounts to solving non-negative image generation, where one can only add light to an existing image. Most image generation methods, however, are ill-suited to this problem setting, as they make the assumption that one can assign arbitrary color to each pixel. In fact, naive application of existing methods fails even in simple domains such as MNIST digits, since one cannot create darker pixels by adding light. We know, however, that the human visual system can be fooled by optical illusions involving certain spatial configurations of brightness and contrast. Our key insight is that one can leverage this behavior to produce high quality images with negligible artifacts. For example, we can create the illusion of darker patches by brightening surrounding pixels. We propose a novel optimization procedure to produce images that satisfy both semantic and non-negativity constraints. Our approach can incorporate existing state-of-the-art methods, and exhibits strong performance in a variety of tasks including image-to-image translation and style transfer.
Energy-Efficient Deployment of Machine Learning Workloads on Neuromorphic Hardware
Oct 10, 2022

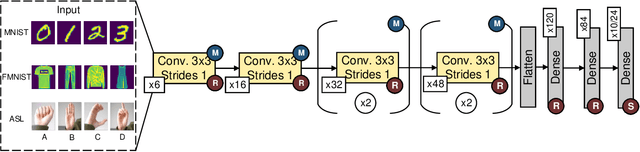
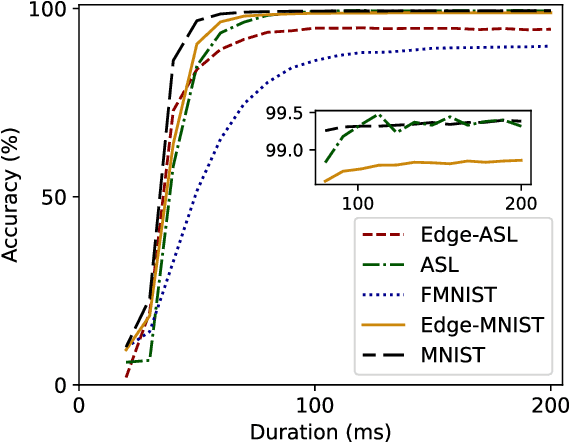
As the technology industry is moving towards implementing tasks such as natural language processing, path planning, image classification, and more on smaller edge computing devices, the demand for more efficient implementations of algorithms and hardware accelerators has become a significant area of research. In recent years, several edge deep learning hardware accelerators have been released that specifically focus on reducing the power and area consumed by deep neural networks (DNNs). On the other hand, spiking neural networks (SNNs) which operate on discrete time-series data, have been shown to achieve substantial power reductions over even the aforementioned edge DNN accelerators when deployed on specialized neuromorphic event-based/asynchronous hardware. While neuromorphic hardware has demonstrated great potential for accelerating deep learning tasks at the edge, the current space of algorithms and hardware is limited and still in rather early development. Thus, many hybrid approaches have been proposed which aim to convert pre-trained DNNs into SNNs. In this work, we provide a general guide to converting pre-trained DNNs into SNNs while also presenting techniques to improve the deployment of converted SNNs on neuromorphic hardware with respect to latency, power, and energy. Our experimental results show that when compared against the Intel Neural Compute Stick 2, Intel's neuromorphic processor, Loihi, consumes up to 27x less power and 5x less energy in the tested image classification tasks by using our SNN improvement techniques.
Visual Recipe Flow: A Dataset for Learning Visual State Changes of Objects with Recipe Flows
Sep 13, 2022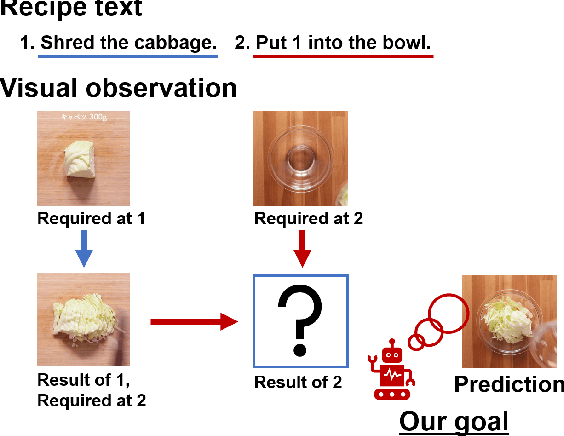
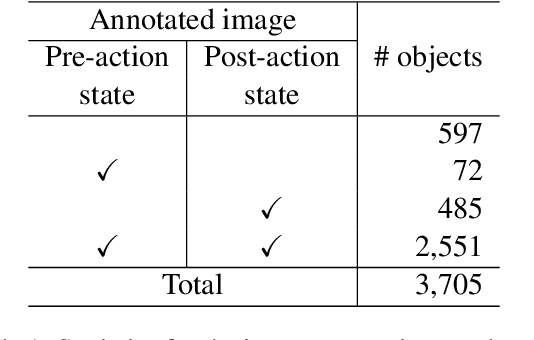
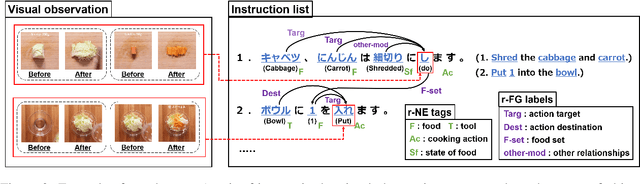
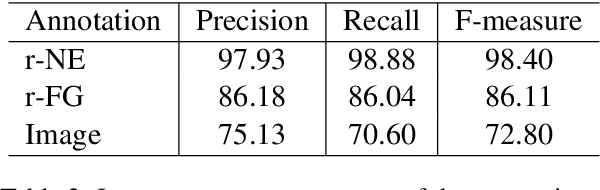
We present a new multimodal dataset called Visual Recipe Flow, which enables us to learn each cooking action result in a recipe text. The dataset consists of object state changes and the workflow of the recipe text. The state change is represented as an image pair, while the workflow is represented as a recipe flow graph (r-FG). The image pairs are grounded in the r-FG, which provides the cross-modal relation. With our dataset, one can try a range of applications, from multimodal commonsense reasoning and procedural text generation.
Errorless Robust JPEG Steganography using Outputs of JPEG Coders
Nov 09, 2022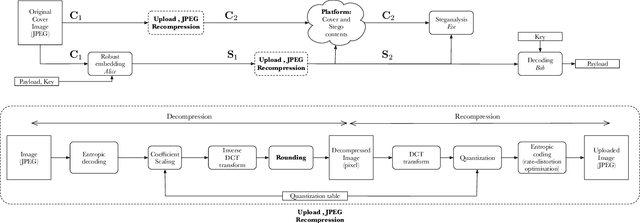
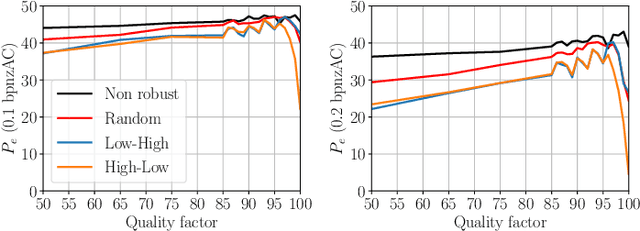

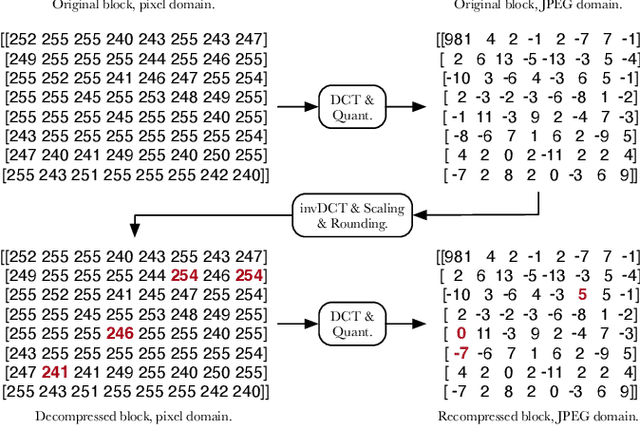
Robust steganography is a technique of hiding secret messages in images so that the message can be recovered after additional image processing. One of the most popular processing operations is JPEG recompression. Unfortunately, most of today's steganographic methods addressing this issue only provide a probabilistic guarantee of recovering the secret and are consequently not errorless. That is unacceptable since even a single unexpected change can make the whole message unreadable if it is encrypted. We propose to create a robust set of DCT coefficients by inspecting their behavior during recompression, which requires access to the targeted JPEG compressor. This is done by dividing the DCT coefficients into 64 non-overlapping lattices because one embedding change can potentially affect many other coefficients from the same DCT block during recompression. The robustness is then combined with standard steganographic costs creating a lattice embedding scheme robust against JPEG recompression. Through experiments, we show that the size of the robust set and the scheme's security depends on the ordering of lattices during embedding. We verify the validity of the proposed method with three typical JPEG compressors and benchmark its security for various embedding payloads, three different ways of ordering the lattices, and a range of Quality Factors. Finally, this method is errorless by construction, meaning the embedded message will always be readable.
Interpretable Explainability in Facial Emotion Recognition and Gamification for Data Collection
Nov 09, 2022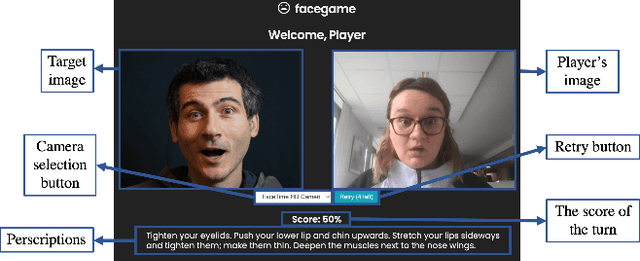
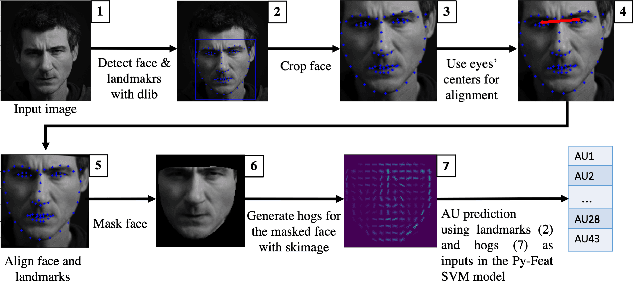
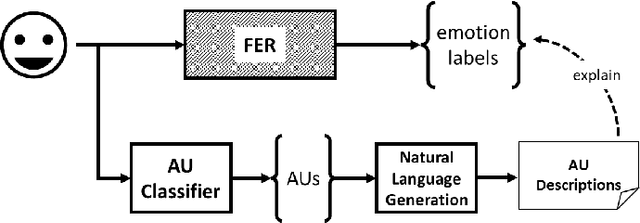
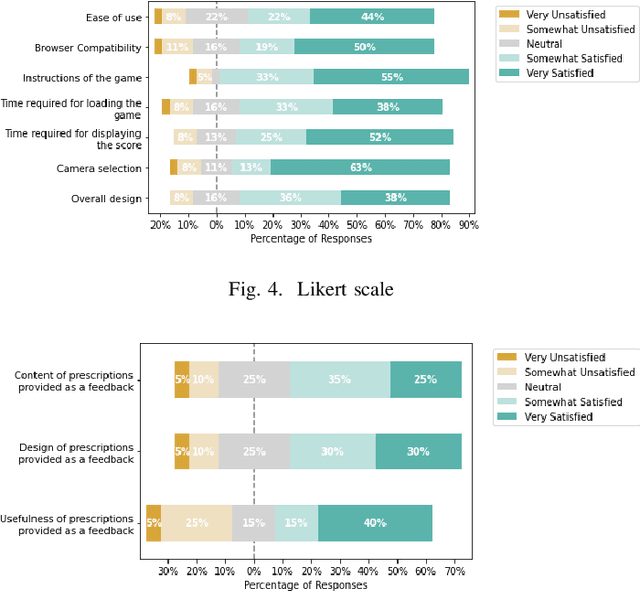
Training facial emotion recognition models requires large sets of data and costly annotation processes. To alleviate this problem, we developed a gamified method of acquiring annotated facial emotion data without an explicit labeling effort by humans. The game, which we named Facegame, challenges the players to imitate a displayed image of a face that portrays a particular basic emotion. Every round played by the player creates new data that consists of a set of facial features and landmarks, already annotated with the emotion label of the target facial expression. Such an approach effectively creates a robust, sustainable, and continuous machine learning training process. We evaluated Facegame with an experiment that revealed several contributions to the field of affective computing. First, the gamified data collection approach allowed us to access a rich variation of facial expressions of each basic emotion due to the natural variations in the players' facial expressions and their expressive abilities. We report improved accuracy when the collected data were used to enrich well-known in-the-wild facial emotion datasets and consecutively used for training facial emotion recognition models. Second, the natural language prescription method used by the Facegame constitutes a novel approach for interpretable explainability that can be applied to any facial emotion recognition model. Finally, we observed significant improvements in the facial emotion perception and expression skills of the players through repeated game play.
Automated MRI Field of View Prescription from Region of Interest Prediction by Intra-stack Attention Neural Network
Nov 09, 2022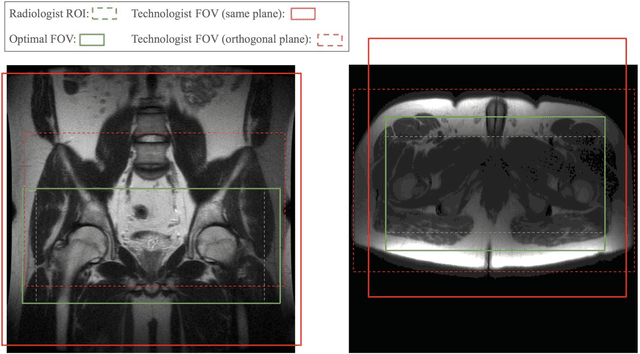
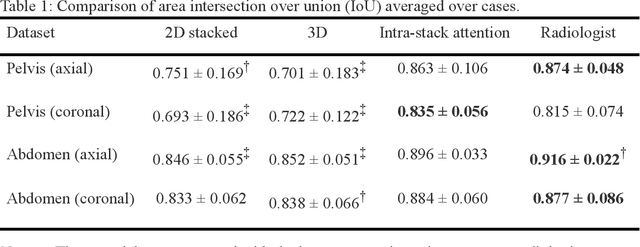
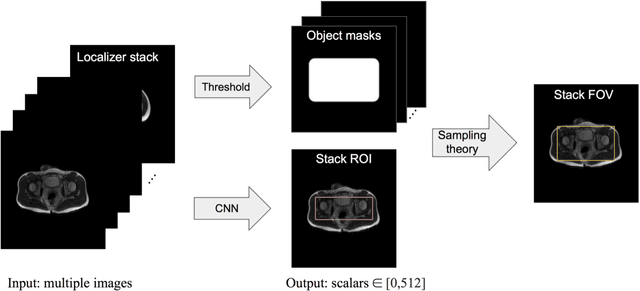
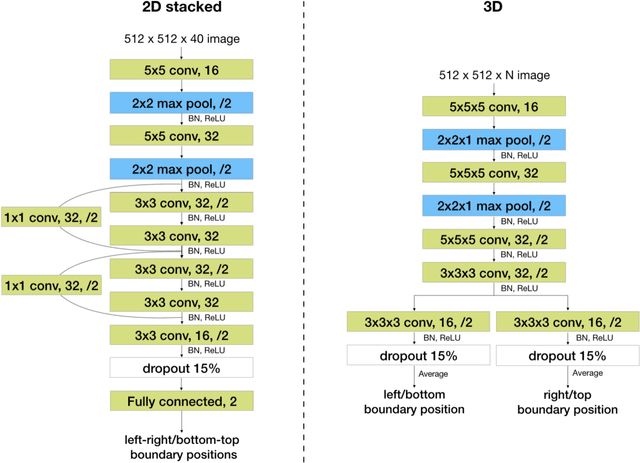
Manual prescription of the field of view (FOV) by MRI technologists is variable and prolongs the scanning process. Often, the FOV is too large or crops critical anatomy. We propose a deep-learning framework, trained by radiologists' supervision, for automating FOV prescription. An intra-stack shared feature extraction network and an attention network are used to process a stack of 2D image inputs to generate output scalars defining the location of a rectangular region of interest (ROI). The attention mechanism is used to make the model focus on the small number of informative slices in a stack. Then the smallest FOV that makes the neural network predicted ROI free of aliasing is calculated by an algebraic operation derived from MR sampling theory. We retrospectively collected 595 cases between February 2018 and February 2022. The framework's performance is examined quantitatively with intersection over union (IoU) and pixel error on position, and qualitatively with a reader study. We use the t-test for comparing quantitative results from all models and a radiologist. The proposed model achieves an average IoU of 0.867 and average ROI position error of 9.06 out of 512 pixels on 80 test cases, significantly better (P<0.05) than two baseline models and not significantly different from a radiologist (P>0.12). Finally, the FOV given by the proposed framework achieves an acceptance rate of 92% from an experienced radiologist.