 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Early Diagnosis of Retinal Blood Vessel Damage via Deep Learning-Powered Collective Intelligence Models
Oct 17, 2022
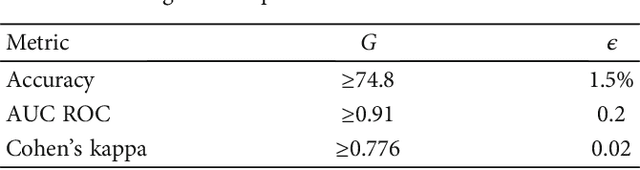
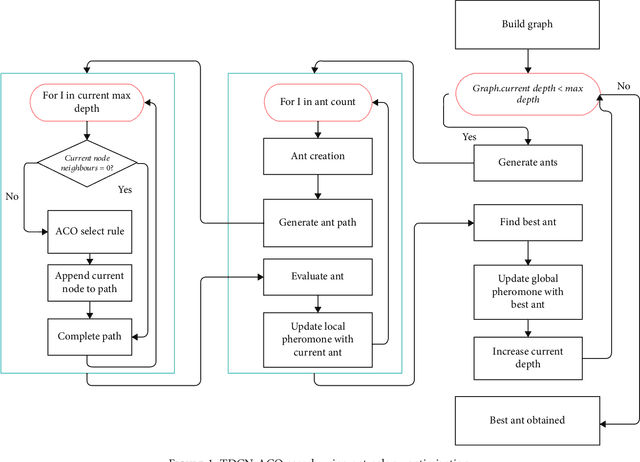

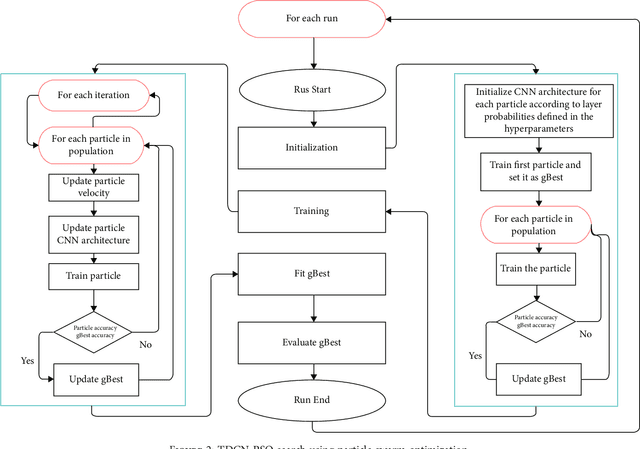
Early diagnosis of retinal diseases such as diabetic retinopathy has had the attention of many researchers. Deep learning through the introduction of convolutional neural networks has become a prominent solution for image-related tasks such as classification and segmentation. Most tasks in image classification are handled by deep CNNs pretrained and evaluated on imagenet dataset. However, these models do not always translate to the best result on other datasets. Devising a neural network manually from scratch based on heuristics may not lead to an optimal model as there are numerous hyperparameters in play. In this paper, we use two nature-inspired swarm algorithms: particle swarm optimization (PSO) and ant colony optimization (ACO) to obtain TDCN models to perform classification of fundus images into severity classes. The power of swarm algorithms is used to search for various combinations of convolutional, pooling, and normalization layers to provide the best model for the task. It is observed that TDCN-PSO outperforms imagenet models and existing literature, while TDCN-ACO achieves faster architecture search. The best TDCN model achieves an accuracy of 90.3%, AUC ROC of 0.956, and a Cohen kappa score of 0.967. The results were compared with the previous studies to show that the proposed TDCN models exhibit superior performance.
City-wide Street-to-Satellite Image Geolocalization of a Mobile Ground Agent
Mar 10, 2022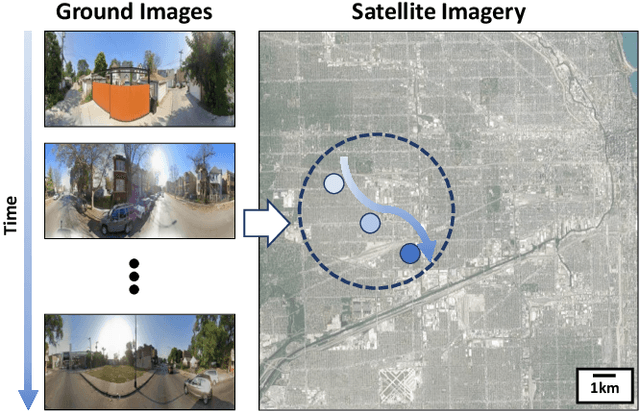
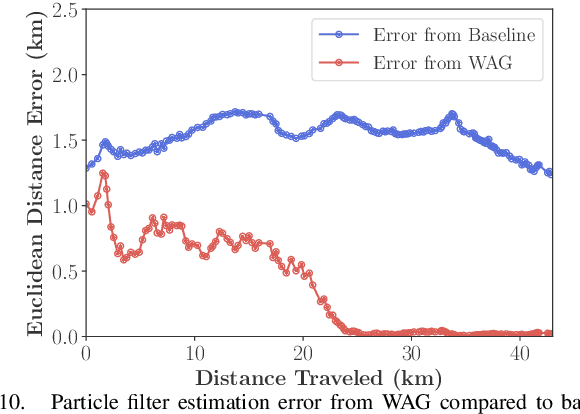
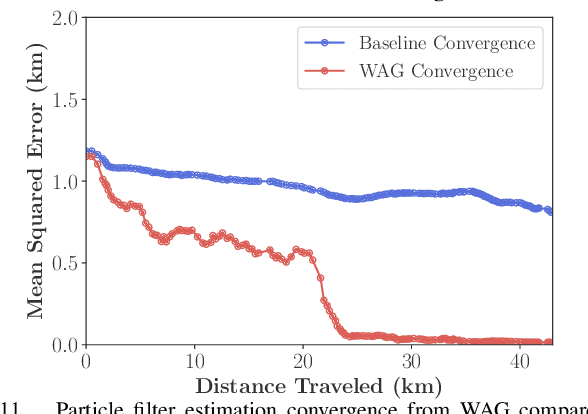
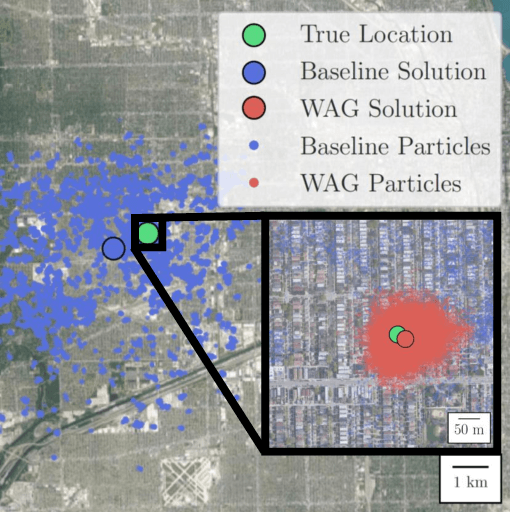
Cross-view image geolocalization provides an estimate of an agent's global position by matching a local ground image to an overhead satellite image without the need for GPS. It is challenging to reliably match a ground image to the correct satellite image since the images have significant viewpoint differences. Existing works have demonstrated localization in constrained scenarios over small areas but have not demonstrated wider-scale localization. Our approach, called Wide-Area Geolocalization (WAG), combines a neural network with a particle filter to achieve global position estimates for agents moving in GPS-denied environments, scaling efficiently to city-scale regions. WAG introduces a trinomial loss function for a Siamese network to robustly match non-centered image pairs and thus enables the generation of a smaller satellite image database by coarsely discretizing the search area. A modified particle filter weighting scheme is also presented to improve localization accuracy and convergence. Taken together, WAG's network training and particle filter weighting approach achieves city-scale position estimation accuracies on the order of 20 meters, a 98% reduction compared to a baseline training and weighting approach. Applied to a smaller-scale testing area, WAG reduces the final position estimation error by 64% compared to a state-of-the-art baseline from the literature. WAG's search space discretization additionally significantly reduces storage and processing requirements.
Cross Language Image Matching for Weakly Supervised Semantic Segmentation
Mar 25, 2022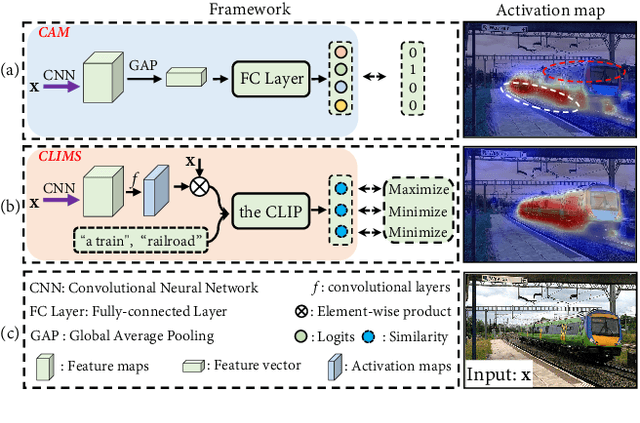
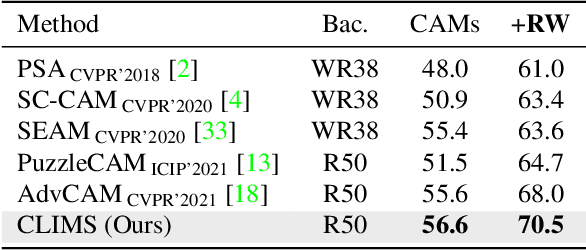
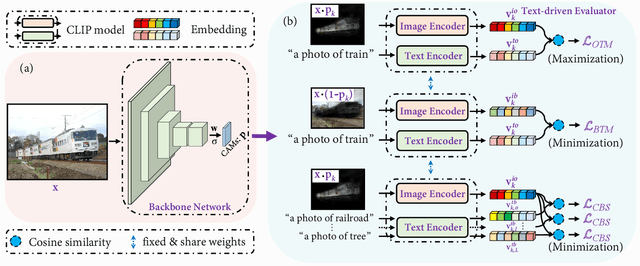

It has been widely known that CAM (Class Activation Map) usually only activates discriminative object regions and falsely includes lots of object-related backgrounds. As only a fixed set of image-level object labels are available to the WSSS (weakly supervised semantic segmentation) model, it could be very difficult to suppress those diverse background regions consisting of open set objects. In this paper, we propose a novel Cross Language Image Matching (CLIMS) framework, based on the recently introduced Contrastive Language-Image Pre-training (CLIP) model, for WSSS. The core idea of our framework is to introduce natural language supervision to activate more complete object regions and suppress closely-related open background regions. In particular, we design object, background region and text label matching losses to guide the model to excite more reasonable object regions for CAM of each category. In addition, we design a co-occurring background suppression loss to prevent the model from activating closely-related background regions, with a predefined set of class-related background text descriptions. These designs enable the proposed CLIMS to generate a more complete and compact activation map for the target objects. Extensive experiments on PASCAL VOC2012 dataset show that our CLIMS significantly outperforms the previous state-of-the-art methods.
SC-DepthV3: Robust Self-supervised Monocular Depth Estimation for Dynamic Scenes
Nov 07, 2022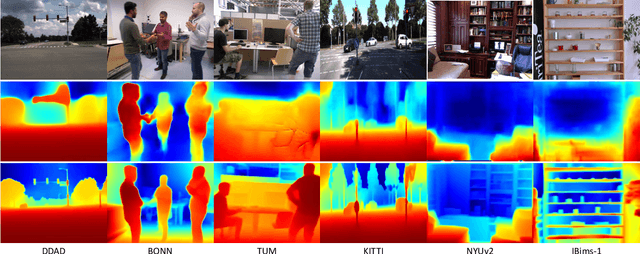
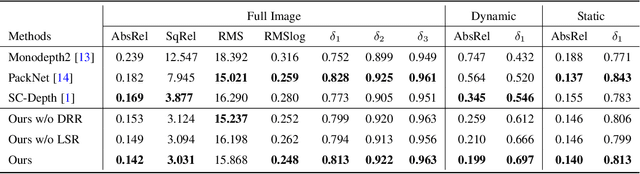
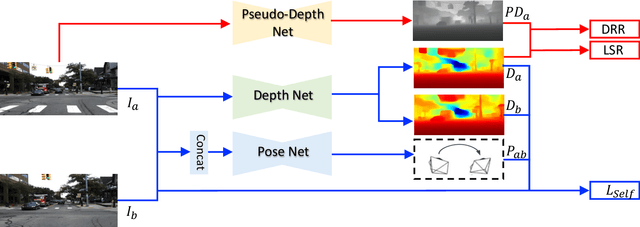
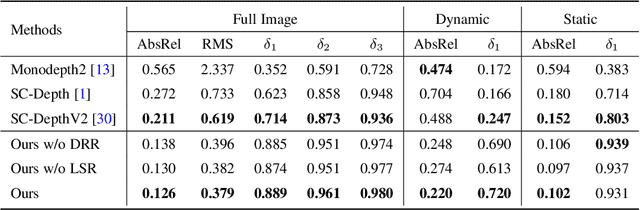
Self-supervised monocular depth estimation has shown impressive results in static scenes. It relies on the multi-view consistency assumption for training networks, however, that is violated in dynamic object regions and occlusions. Consequently, existing methods show poor accuracy in dynamic scenes, and the estimated depth map is blurred at object boundaries because they are usually occluded in other training views. In this paper, we propose SC-DepthV3 for addressing the challenges. Specifically, we introduce an external pretrained monocular depth estimation model for generating single-image depth prior, namely pseudo-depth, based on which we propose novel losses to boost self-supervised training. As a result, our model can predict sharp and accurate depth maps, even when training from monocular videos of highly-dynamic scenes. We demonstrate the significantly superior performance of our method over previous methods on six challenging datasets, and we provide detailed ablation studies for the proposed terms. Source code and data will be released at https://github.com/JiawangBian/sc_depth_pl
SIOD: Single Instance Annotated Per Category Per Image for Object Detection
Mar 30, 2022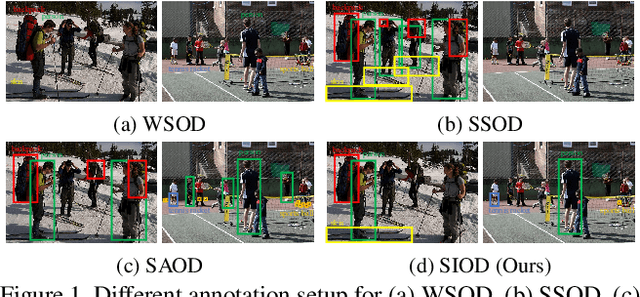



Object detection under imperfect data receives great attention recently. Weakly supervised object detection (WSOD) suffers from severe localization issues due to the lack of instance-level annotation, while semi-supervised object detection (SSOD) remains challenging led by the inter-image discrepancy between labeled and unlabeled data. In this study, we propose the Single Instance annotated Object Detection (SIOD), requiring only one instance annotation for each existing category in an image. Degraded from inter-task (WSOD) or inter-image (SSOD) discrepancies to the intra-image discrepancy, SIOD provides more reliable and rich prior knowledge for mining the rest of unlabeled instances and trades off the annotation cost and performance. Under the SIOD setting, we propose a simple yet effective framework, termed Dual-Mining (DMiner), which consists of a Similarity-based Pseudo Label Generating module (SPLG) and a Pixel-level Group Contrastive Learning module (PGCL). SPLG firstly mines latent instances from feature representation space to alleviate the annotation missing problem. To avoid being misled by inaccurate pseudo labels, we propose PGCL to boost the tolerance to false pseudo labels. Extensive experiments on MS COCO verify the feasibility of the SIOD setting and the superiority of the proposed method, which obtains consistent and significant improvements compared to baseline methods and achieves comparable results with fully supervised object detection (FSOD) methods with only 40% instances annotated.
Exploring Structural Sparsity in Neural Image Compression
Feb 10, 2022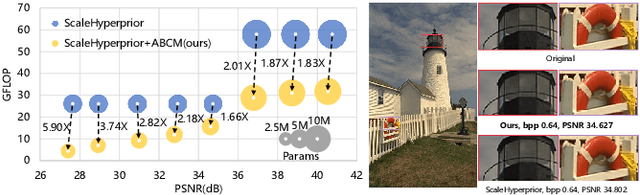
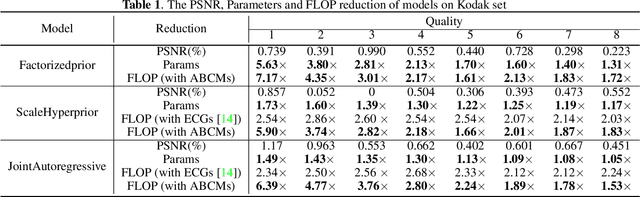
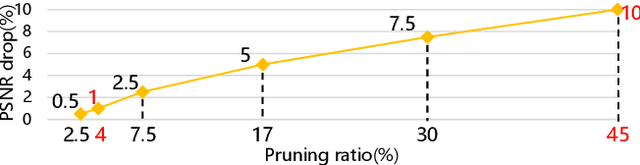

Neural image compression have reached or out-performed traditional methods (such as JPEG, BPG, WebP). However,their sophisticated network structures with cascaded convolution layers bring heavy computational burden for practical deployment. In this paper, we explore the structural sparsity in neural image compression network to obtain real-time acceleration without any specialized hardware design or algorithm. We propose a simple plug-in adaptive binary channel masking(ABCM) to judge the importance of each convolution channel and introduce sparsity during training. During inference, the unimportant channels are pruned to obtain slimmer network and less computation. We implement our method into three neural image compression networks with different entropy models to verify its effectiveness and generalization, the experiment results show that up to 7x computation reduction and 3x acceleration can be achieved with negligible performance drop.
Low-Light Hyperspectral Image Enhancement
Aug 05, 2022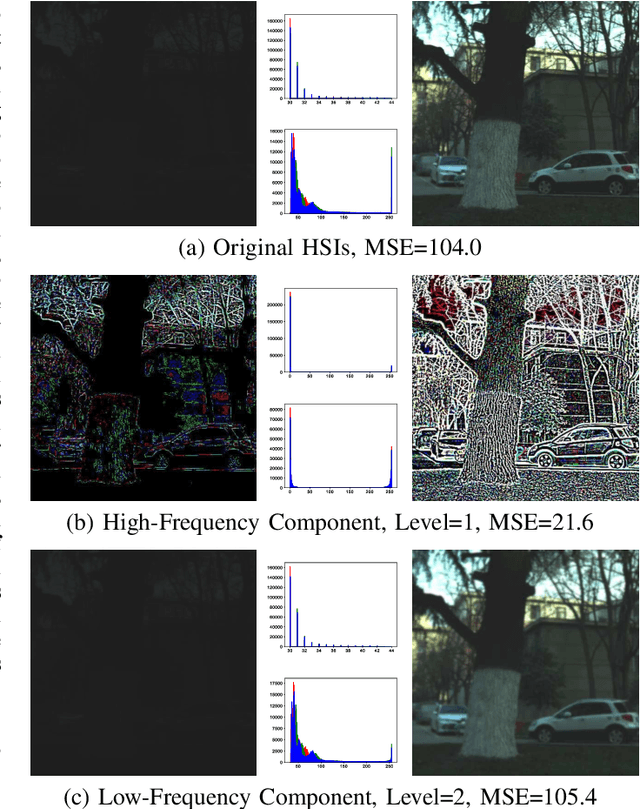


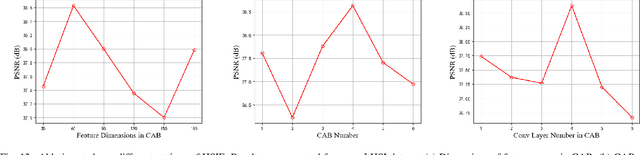
Due to inadequate energy captured by the hyperspectral camera sensor in poor illumination conditions, low-light hyperspectral images (HSIs) usually suffer from low visibility, spectral distortion, and various noises. A range of HSI restoration methods have been developed, yet their effectiveness in enhancing low-light HSIs is constrained. This work focuses on the low-light HSI enhancement task, which aims to reveal the spatial-spectral information hidden in darkened areas. To facilitate the development of low-light HSI processing, we collect a low-light HSI (LHSI) dataset of both indoor and outdoor scenes. Based on Laplacian pyramid decomposition and reconstruction, we developed an end-to-end data-driven low-light HSI enhancement (HSIE) approach trained on the LHSI dataset. With the observation that illumination is related to the low-frequency component of HSI, while textural details are closely correlated to the high-frequency component, the proposed HSIE is designed to have two branches. The illumination enhancement branch is adopted to enlighten the low-frequency component with reduced resolution. The high-frequency refinement branch is utilized for refining the high-frequency component via a predicted mask. In addition, to improve information flow and boost performance, we introduce an effective channel attention block (CAB) with residual dense connection, which served as the basic block of the illumination enhancement branch. The effectiveness and efficiency of HSIE both in quantitative assessment measures and visual effects are demonstrated by experimental results on the LHSI dataset. According to the classification performance on the remote sensing Indian Pines dataset, downstream tasks benefit from the enhanced HSI. Datasets and codes are available: \href{https://github.com/guanguanboy/HSIE}{https://github.com/guanguanboy/HSIE}.
Unifying Flow, Stereo and Depth Estimation
Nov 10, 2022
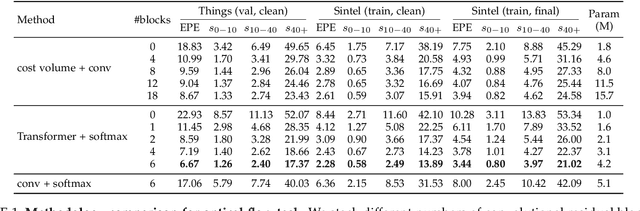
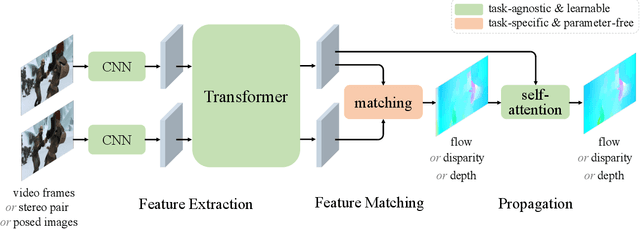
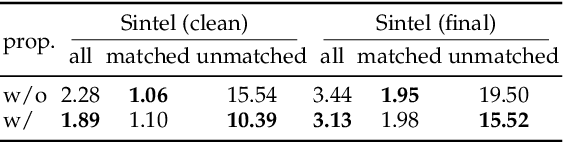
We present a unified formulation and model for three motion and 3D perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation from posed images. Unlike previous specialized architectures for each specific task, we formulate all three tasks as a unified dense correspondence matching problem, which can be solved with a single model by directly comparing feature similarities. Such a formulation calls for discriminative feature representations, which we achieve using a Transformer, in particular the cross-attention mechanism. We demonstrate that cross-attention enables integration of knowledge from another image via cross-view interactions, which greatly improves the quality of the extracted features. Our unified model naturally enables cross-task transfer since the model architecture and parameters are shared across tasks. We outperform RAFT with our unified model on the challenging Sintel dataset, and our final model that uses a few additional task-specific refinement steps outperforms or compares favorably to recent state-of-the-art methods on 10 popular flow, stereo and depth datasets, while being simpler and more efficient in terms of model design and inference speed.
Enabling ISP-less Low-Power Computer Vision
Oct 11, 2022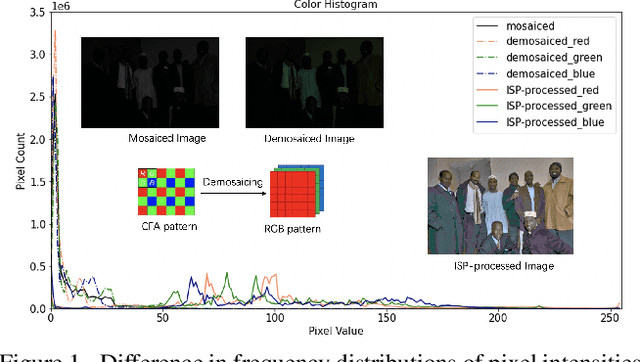
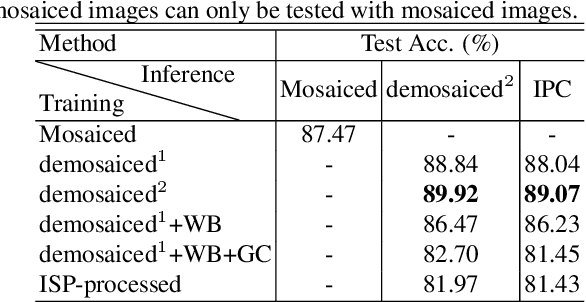
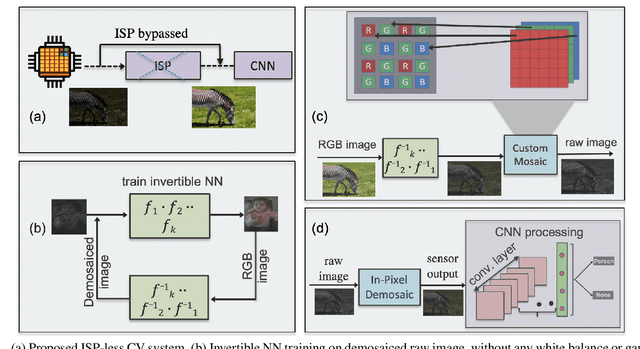
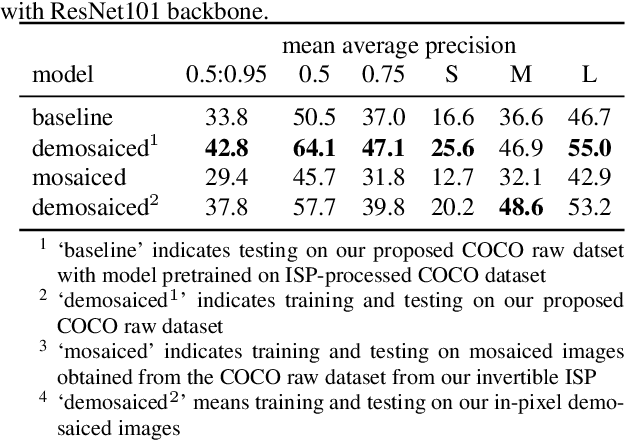
In order to deploy current computer vision (CV) models on resource-constrained low-power devices, recent works have proposed in-sensor and in-pixel computing approaches that try to partly/fully bypass the image signal processor (ISP) and yield significant bandwidth reduction between the image sensor and the CV processing unit by downsampling the activation maps in the initial convolutional neural network (CNN) layers. However, direct inference on the raw images degrades the test accuracy due to the difference in covariance of the raw images captured by the image sensors compared to the ISP-processed images used for training. Moreover, it is difficult to train deep CV models on raw images, because most (if not all) large-scale open-source datasets consist of RGB images. To mitigate this concern, we propose to invert the ISP pipeline, which can convert the RGB images of any dataset to its raw counterparts, and enable model training on raw images. We release the raw version of the COCO dataset, a large-scale benchmark for generic high-level vision tasks. For ISP-less CV systems, training on these raw images result in a 7.1% increase in test accuracy on the visual wake works (VWW) dataset compared to relying on training with traditional ISP-processed RGB datasets. To further improve the accuracy of ISP-less CV models and to increase the energy and bandwidth benefits obtained by in-sensor/in-pixel computing, we propose an energy-efficient form of analog in-pixel demosaicing that may be coupled with in-pixel CNN computations. When evaluated on raw images captured by real sensors from the PASCALRAW dataset, our approach results in a 8.1% increase in mAP. Lastly, we demonstrate a further 20.5% increase in mAP by using a novel application of few-shot learning with thirty shots each for the novel PASCALRAW dataset, constituting 3 classes.
Learning Fine-Grained Visual Understanding for Video Question Answering via Decoupling Spatial-Temporal Modeling
Oct 08, 2022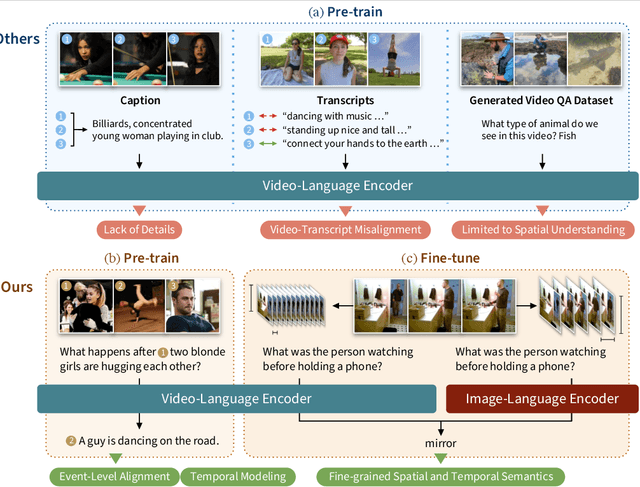
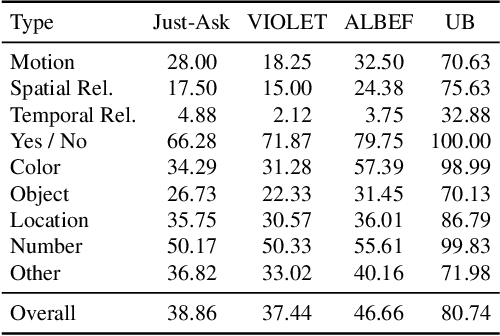
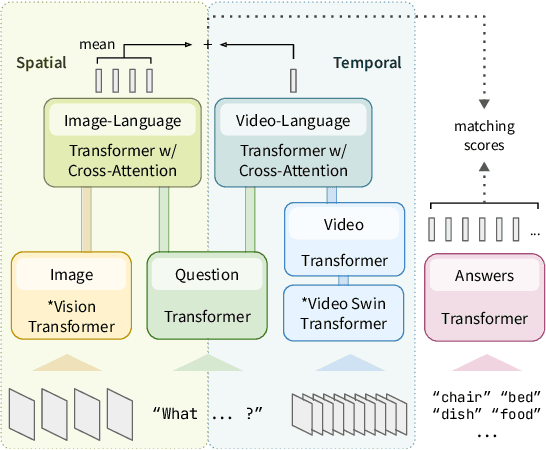
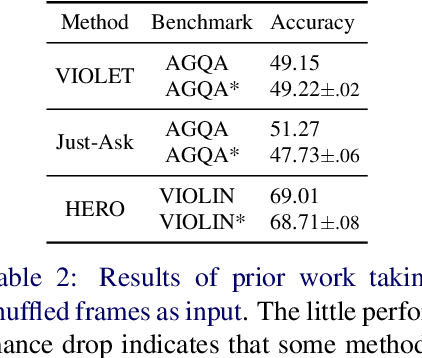
While recent large-scale video-language pre-training made great progress in video question answering, the design of spatial modeling of video-language models is less fine-grained than that of image-language models; existing practices of temporal modeling also suffer from weak and noisy alignment between modalities. To learn fine-grained visual understanding, we decouple spatial-temporal modeling and propose a hybrid pipeline, Decoupled Spatial-Temporal Encoders, integrating an image- and a video-language encoder. The former encodes spatial semantics from larger but sparsely sampled frames independently of time, while the latter models temporal dynamics at lower spatial but higher temporal resolution. To help the video-language model learn temporal relations for video QA, we propose a novel pre-training objective, Temporal Referring Modeling, which requires the model to identify temporal positions of events in video sequences. Extensive experiments demonstrate that our model outperforms previous work pre-trained on orders of magnitude larger datasets.