 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Semantic Segmentation Based on Few/Zero-Shot Learning: An Overview
Nov 13, 2022
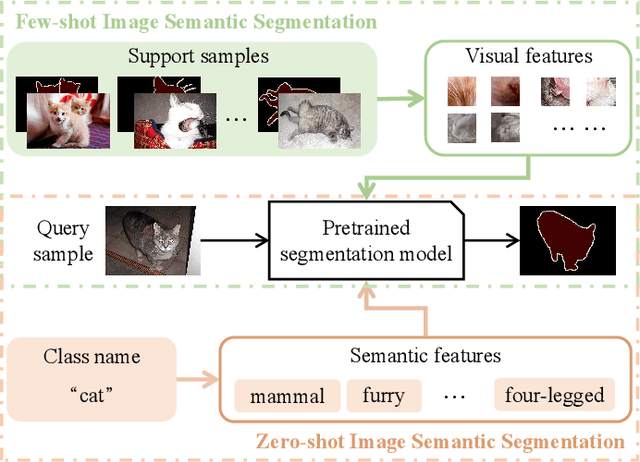
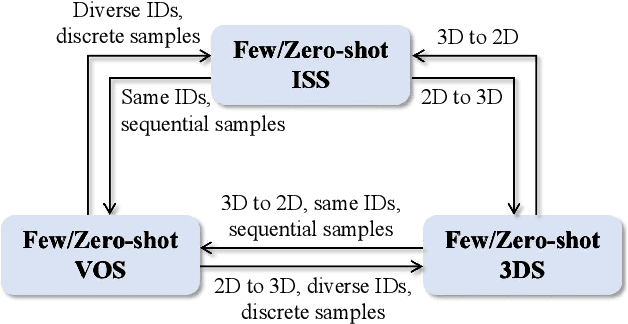
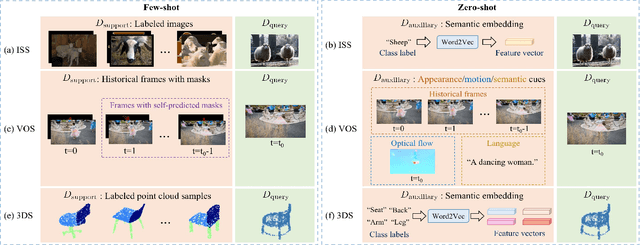
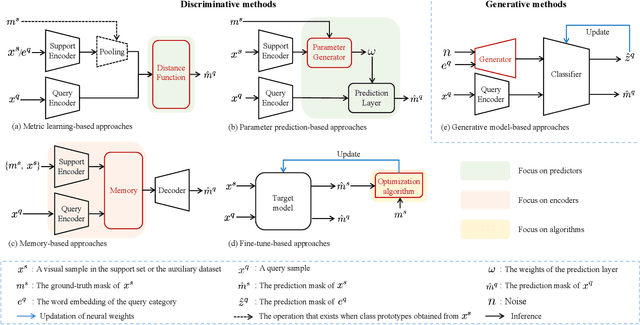
Visual semantic segmentation aims at separating a visual sample into diverse blocks with specific semantic attributes and identifying the category for each block, and it plays a crucial role in environmental perception. Conventional learning-based visual semantic segmentation approaches count heavily on large-scale training data with dense annotations and consistently fail to estimate accurate semantic labels for unseen categories. This obstruction spurs a craze for studying visual semantic segmentation with the assistance of few/zero-shot learning. The emergence and rapid progress of few/zero-shot visual semantic segmentation make it possible to learn unseen-category from a few labeled or zero-labeled samples, which advances the extension to practical applications. Therefore, this paper focuses on the recently published few/zero-shot visual semantic segmentation methods varying from 2D to 3D space and explores the commonalities and discrepancies of technical settlements under different segmentation circumstances. Specifically, the preliminaries on few/zero-shot visual semantic segmentation, including the problem definitions, typical datasets, and technical remedies, are briefly reviewed and discussed. Moreover, three typical instantiations are involved to uncover the interactions of few/zero-shot learning with visual semantic segmentation, including image semantic segmentation, video object segmentation, and 3D segmentation. Finally, the future challenges of few/zero-shot visual semantic segmentation are discussed.
Scale-Aware Crowd Counting Using a Joint Likelihood Density Map and Synthetic Fusion Pyramid Network
Nov 13, 2022
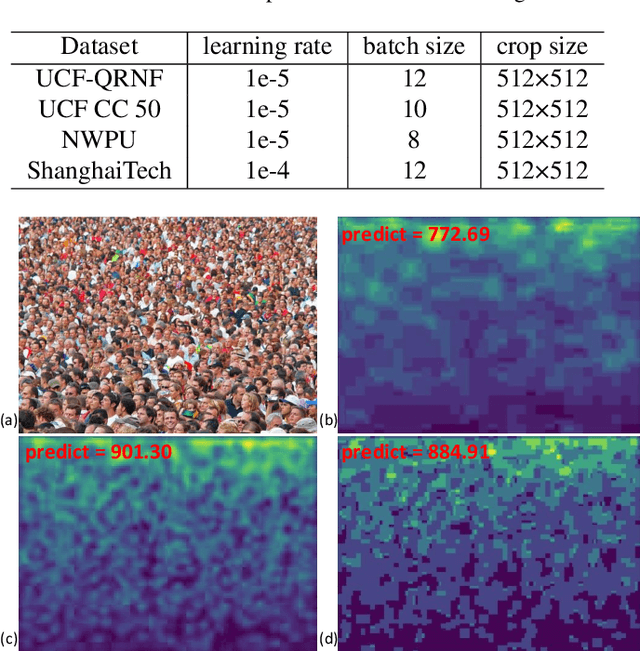
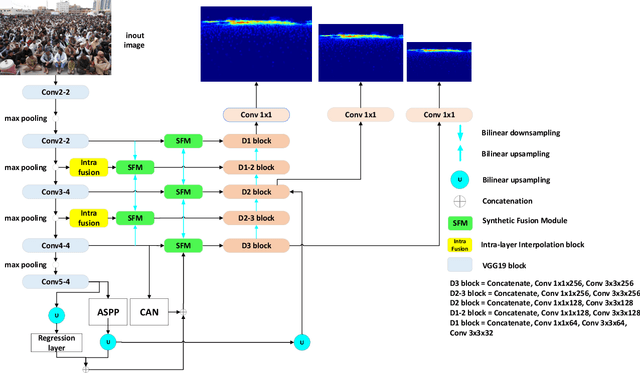
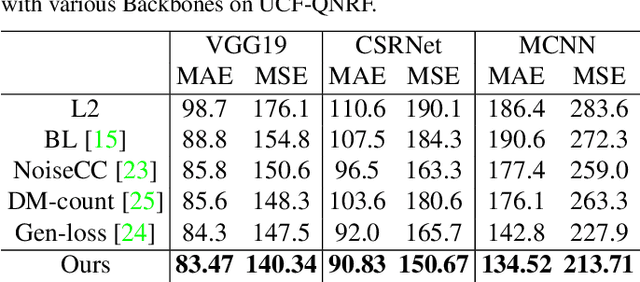
We develop a Synthetic Fusion Pyramid Network (SPF-Net) with a scale-aware loss function design for accurate crowd counting. Existing crowd-counting methods assume that the training annotation points were accurate and thus ignore the fact that noisy annotations can lead to large model-learning bias and counting error, especially for counting highly dense crowds that appear far away. To the best of our knowledge, this work is the first to properly handle such noise at multiple scales in end-to-end loss design and thus push the crowd counting state-of-the-art. We model the noise of crowd annotation points as a Gaussian and derive the crowd probability density map from the input image. We then approximate the joint distribution of crowd density maps with the full covariance of multiple scales and derive a low-rank approximation for tractability and efficient implementation. The derived scale-aware loss function is used to train the SPF-Net. We show that it outperforms various loss functions on four public datasets: UCF-QNRF, UCF CC 50, NWPU and ShanghaiTech A-B datasets. The proposed SPF-Net can accurately predict the locations of people in the crowd, despite training on noisy training annotations.
Quantum Natural Language Generation on Near-Term Devices
Nov 01, 2022
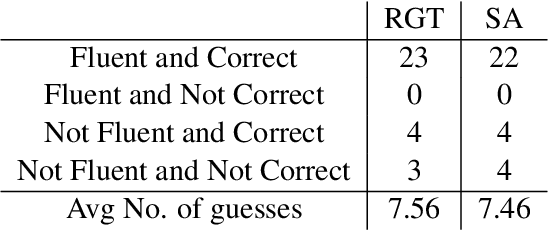
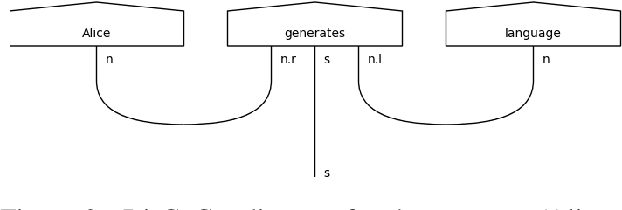
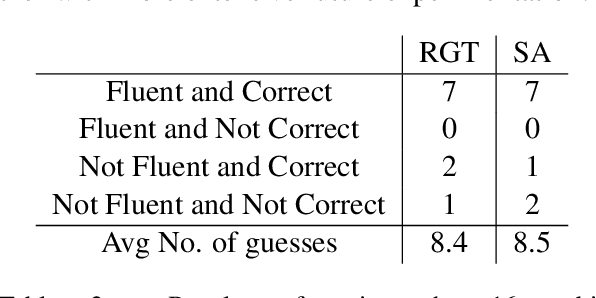
The emergence of noisy medium-scale quantum devices has led to proof-of-concept applications for quantum computing in various domains. Examples include Natural Language Processing (NLP) where sentence classification experiments have been carried out, as well as procedural generation, where tasks such as geopolitical map creation, and image manipulation have been performed. We explore applications at the intersection of these two areas by designing a hybrid quantum-classical algorithm for sentence generation. Our algorithm is based on the well-known simulated annealing technique for combinatorial optimisation. An implementation is provided and used to demonstrate successful sentence generation on both simulated and real quantum hardware. A variant of our algorithm can also be used for music generation. This paper aims to be self-contained, introducing all the necessary background on NLP and quantum computing along the way.
Single UHD Image Dehazing via Interpretable Pyramid Network
Feb 17, 2022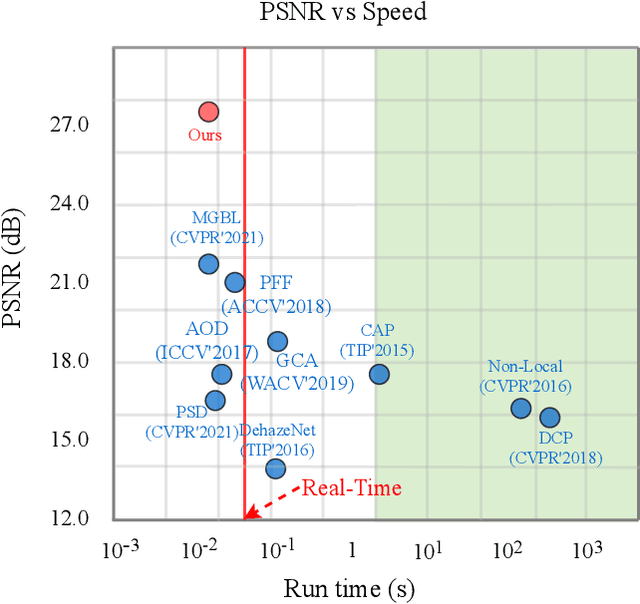

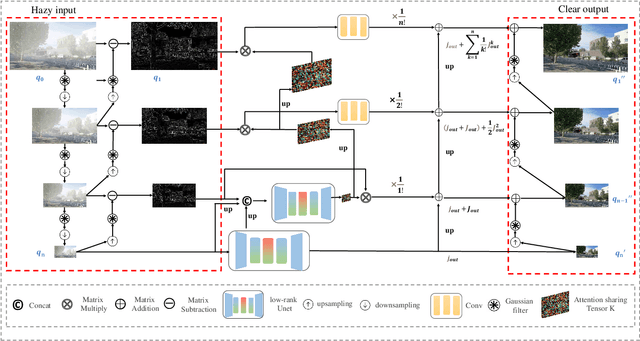

Currently, most single image dehazing models cannot run an ultra-high-resolution (UHD) image with a single GPU shader in real-time. To address the problem, we introduce the principle of infinite approximation of Taylor's theorem with the Laplace pyramid pattern to build a model which is capable of handling 4K hazy images in real-time. The N branch networks of the pyramid network correspond to the N constraint terms in Taylor's theorem. Low-order polynomials reconstruct the low-frequency information of the image (e.g. color, illumination). High-order polynomials regress the high-frequency information of the image (e.g. texture). In addition, we propose a Tucker reconstruction-based regularization term that acts on each branch network of the pyramid model. It further constrains the generation of anomalous signals in the feature space. Extensive experimental results demonstrate that our approach can not only run 4K images with haze in real-time on a single GPU (80FPS) but also has unparalleled interpretability. The developed method achieves state-of-the-art (SOTA) performance on two benchmarks (O/I-HAZE) and our updated 4KID dataset while providing the reliable groundwork for subsequent optimization schemes.
Accelerating Score-based Generative Models for High-Resolution Image Synthesis
Jun 09, 2022



Score-based generative models (SGMs) have recently emerged as a promising class of generative models. The key idea is to produce high-quality images by recurrently adding Gaussian noises and gradients to a Gaussian sample until converging to the target distribution, a.k.a. the diffusion sampling. To ensure stability of convergence in sampling and generation quality, however, this sequential sampling process has to take a small step size and many sampling iterations (e.g., 2000). Several acceleration methods have been proposed with focus on low-resolution generation. In this work, we consider the acceleration of high-resolution generation with SGMs, a more challenging yet more important problem. We prove theoretically that this slow convergence drawback is primarily due to the ignorance of the target distribution. Further, we introduce a novel Target Distribution Aware Sampling (TDAS) method by leveraging the structural priors in space and frequency domains. Extensive experiments on CIFAR-10, CelebA, LSUN, and FFHQ datasets validate that TDAS can consistently accelerate state-of-the-art SGMs, particularly on more challenging high resolution (1024x1024) image generation tasks by up to 18.4x, whilst largely maintaining the synthesis quality. With fewer sampling iterations, TDAS can still generate good quality images. In contrast, the existing methods degrade drastically or even fails completely
Efficient Noise Filtration of Images by Low-Rank Singular Vector Approximations of Geodesics' Gramian Matrix
Sep 27, 2022
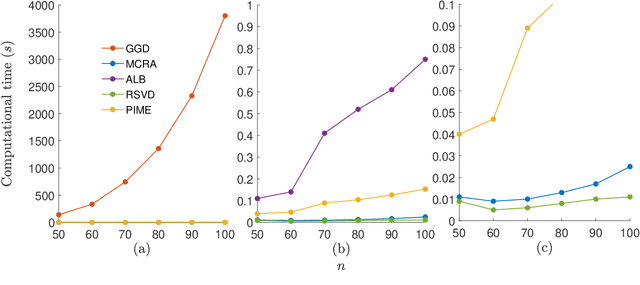

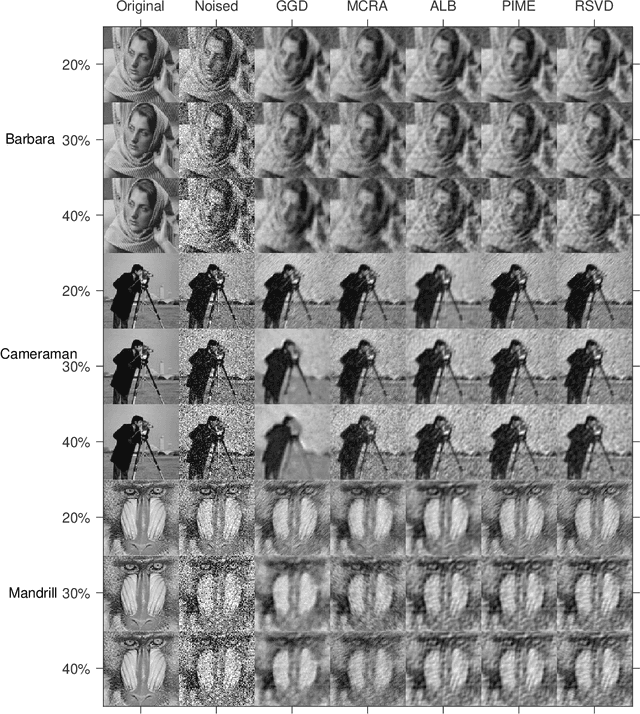
Modern society is interested in capturing high-resolution and fine-quality images due to the surge of sophisticated cameras. However, the noise contamination in the images not only inferior people's expectations but also conversely affects the subsequent processes if such images are utilized in computer vision tasks such as remote sensing, object tracking, etc. Even though noise filtration plays an essential role, real-time processing of a high-resolution image is limited by the hardware limitations of the image-capturing instruments. Geodesic Gramian Denoising (GGD) is a manifold-based noise filtering method that we introduced in our past research which utilizes a few prominent singular vectors of the geodesics' Gramian matrix for the noise filtering process. The applicability of GDD is limited as it encounters $\mathcal{O}(n^6)$ when denoising a given image of size $n\times n$ since GGD computes the prominent singular vectors of a $n^2 \times n^2$ data matrix that is implemented by singular value decomposition (SVD). In this research, we increase the efficiency of our GGD framework by replacing its SVD step with four diverse singular vector approximation techniques. Here, we compare both the computational time and the noise filtering performance between the four techniques integrated into GGD.
Natural Color Fool: Towards Boosting Black-box Unrestricted Attacks
Oct 05, 2022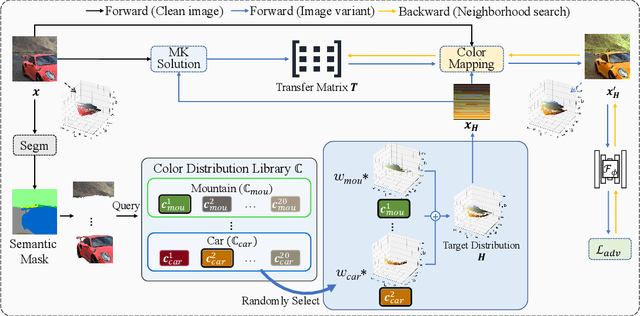
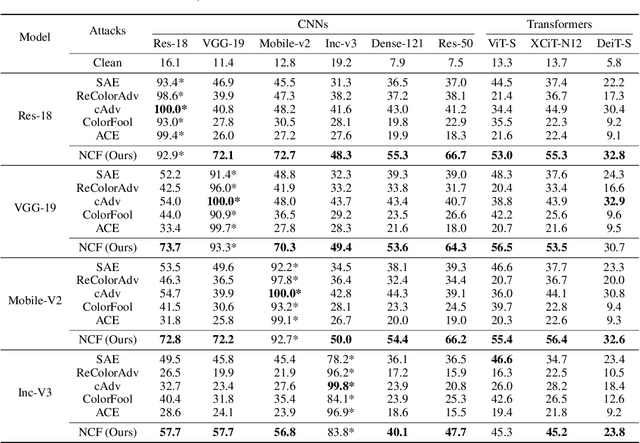

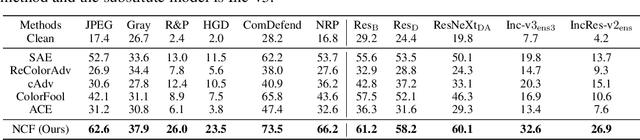
Unrestricted color attacks, which manipulate semantically meaningful color of an image, have shown their stealthiness and success in fooling both human eyes and deep neural networks. However, current works usually sacrifice the flexibility of the uncontrolled setting to ensure the naturalness of adversarial examples. As a result, the black-box attack performance of these methods is limited. To boost transferability of adversarial examples without damaging image quality, we propose a novel Natural Color Fool (NCF) which is guided by realistic color distributions sampled from a publicly available dataset and optimized by our neighborhood search and initialization reset. By conducting extensive experiments and visualizations, we convincingly demonstrate the effectiveness of our proposed method. Notably, on average, results show that our NCF can outperform state-of-the-art approaches by 15.0%$\sim$32.9% for fooling normally trained models and 10.0%$\sim$25.3% for evading defense methods. Our code is available at https://github.com/ylhz/Natural-Color-Fool.
mm-Wave Radar Hand Shape Classification Using Deformable Transformers
Oct 24, 2022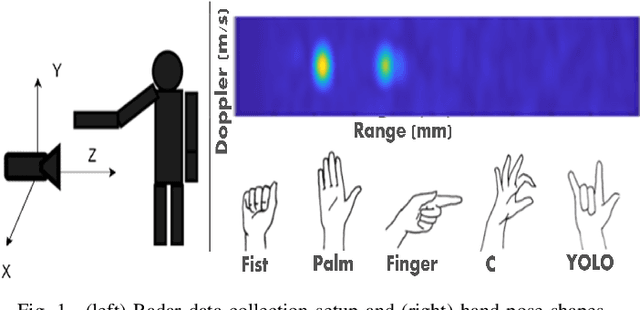

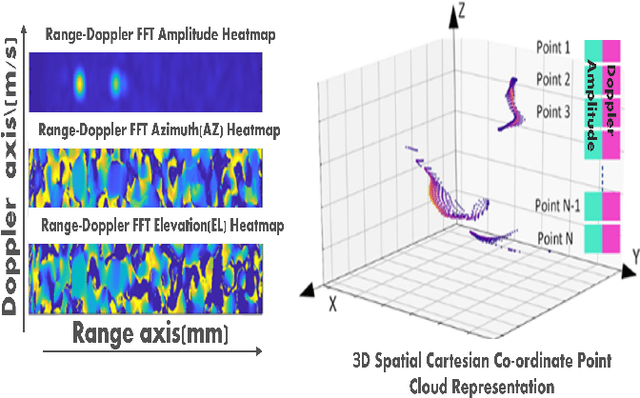
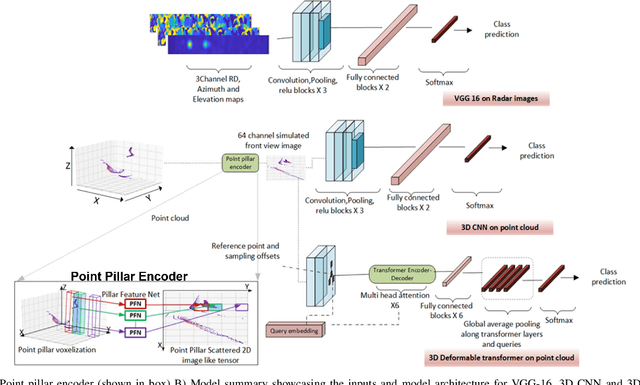
A novel, real-time, mm-Wave radar-based static hand shape classification algorithm and implementation are proposed. The method finds several applications in low cost and privacy sensitive touchless control technology using 60 Ghz radar as the sensor input. As opposed to prior Range-Doppler image based 2D classification solutions, our method converts raw radar data to 3D sparse cartesian point clouds.The demonstrated 3D radar neural network model using deformable transformers significantly surpasses the performance results set by prior methods which either utilize custom signal processing or apply generic convolutional techniques on Range-Doppler FFT images. Experiments are performed on an internally collected dataset using an off-the-shelf radar sensor.
Bayesian Convolutional Neural Networks for Limited Data Hyperspectral Remote Sensing Image Classification
May 19, 2022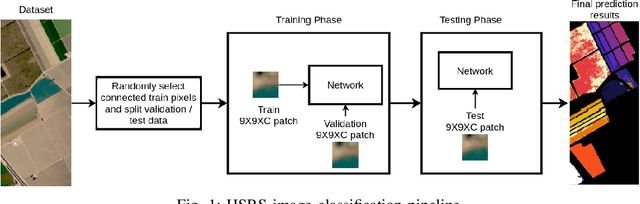

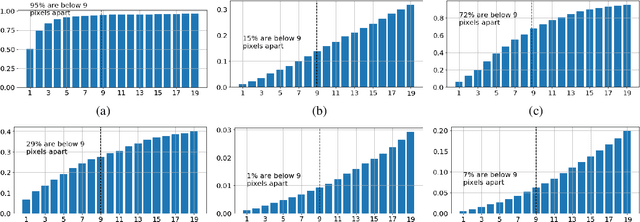
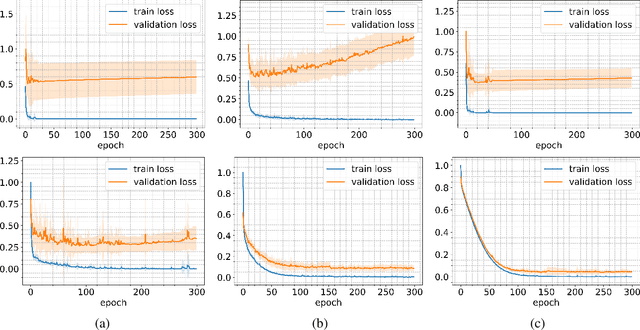
Employing deep neural networks for Hyper-spectral remote sensing (HSRS) image classification is a challenging task. HSRS images have high dimensionality and a large number of channels with substantial redundancy between channels. In addition, the training data for classifying HSRS images is limited and the amount of available training data is much smaller compared to other classification tasks. These factors complicate the training process of deep neural networks with many parameters and cause them to not perform well even compared to conventional models. Moreover, convolutional neural networks produce over-confident predictions, which is highly undesirable considering the aforementioned problem. In this work, we use a special class of deep neural networks, namely Bayesian neural network, to classify HSRS images. To the extent of our knowledge, this is the first time that this class of neural networks has been used in HSRS image classification. Bayesian neural networks provide an inherent tool for measuring uncertainty. We show that a Bayesian network can outperform a similarly-constructed non-Bayesian convolutional neural network (CNN) and an off-the-shelf Random Forest (RF). Moreover, experimental results for the Pavia Centre, Salinas, and Botswana datasets show that the Bayesian network is more stable and robust to model pruning. Furthermore, we analyze the prediction uncertainty of the Bayesian model and show that the prediction uncertainty metric can provide information about the model predictions and has a positive correlation with the prediction error.
Recurrent Super-Resolution Method for Enhancing Low Quality Thermal Facial Data
Sep 21, 2022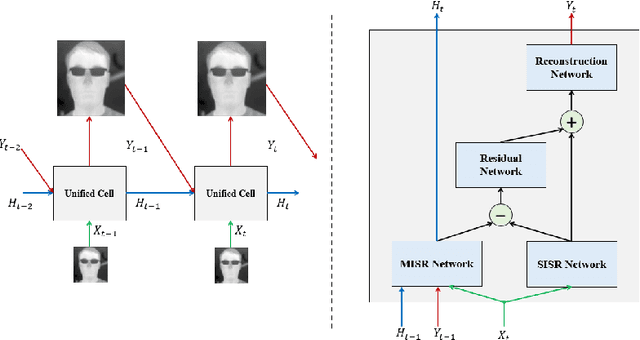

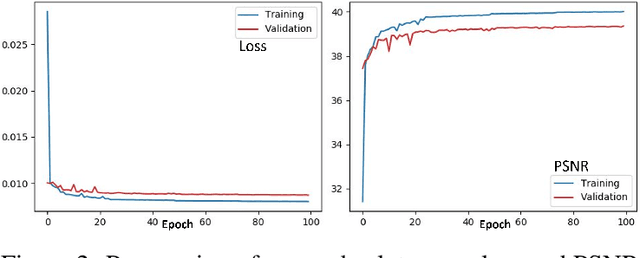

The process of obtaining high-resolution images from single or multiple low-resolution images of the same scene is of great interest for real-world image and signal processing applications. This study is about exploring the potential usage of deep learning based image super-resolution algorithms on thermal data for producing high quality thermal imaging results for in-cabin vehicular driver monitoring systems. In this work we have proposed and developed a novel multi-image super-resolution recurrent neural network to enhance the resolution and improve the quality of low-resolution thermal imaging data captured from uncooled thermal cameras. The end-to-end fully convolutional neural network is trained from scratch on newly acquired thermal data of 30 different subjects in indoor environmental conditions. The effectiveness of the thermally tuned super-resolution network is validated quantitatively as well as qualitatively on test data of 6 distinct subjects. The network was able to achieve a mean peak signal to noise ratio of 39.24 on the validation dataset for 4x super-resolution, outperforming bicubic interpolation both quantitatively and qualitatively.