 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Mechanisms Inspired Efficient Transformers for Image and Video Quality Assessment
Apr 06, 2022
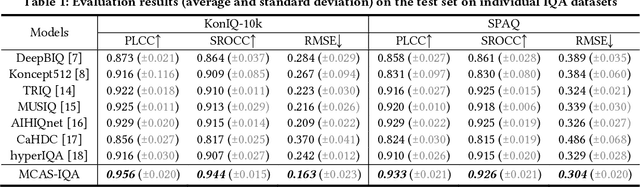

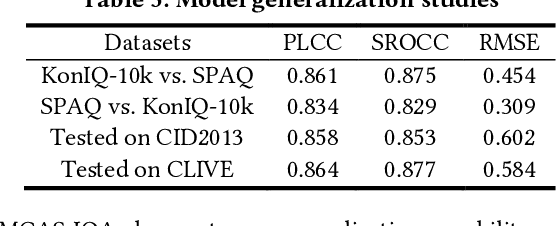
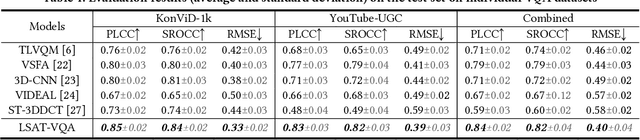
Visual (image, video) quality assessments can be modelled by visual features in different domains, e.g., spatial, frequency, and temporal domains. Perceptual mechanisms in the human visual system (HVS) play a crucial role in generation of quality perception. This paper proposes a general framework for no-reference visual quality assessment using efficient windowed transformer architectures. A lightweight module for multi-stage channel attention is integrated into Swin (shifted window) Transformer. Such module can represent appropriate perceptual mechanisms in image quality assessment (IQA) to build an accurate IQA model. Meanwhile, representative features for image quality perception in the spatial and frequency domains can also be derived from the IQA model, which are then fed into another windowed transformer architecture for video quality assessment (VQA). The VQA model efficiently reuses attention information across local windows to tackle the issue of expensive time and memory complexities of original transformer. Experimental results on both large-scale IQA and VQA databases demonstrate that the proposed quality assessment models outperform other state-of-the-art models by large margins. The complete source code will be published on Github.
CVM-Cervix: A Hybrid Cervical Pap-Smear Image Classification Framework Using CNN, Visual Transformer and Multilayer Perceptron
Jun 02, 2022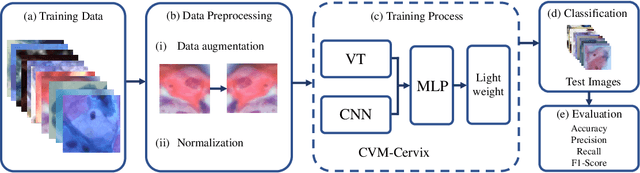
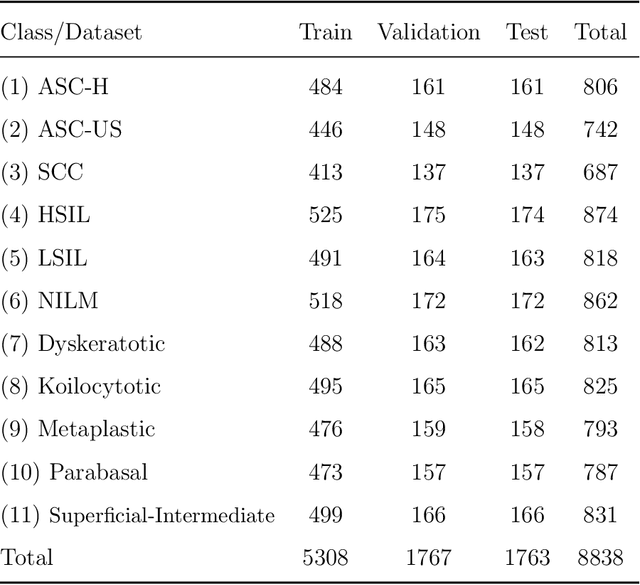
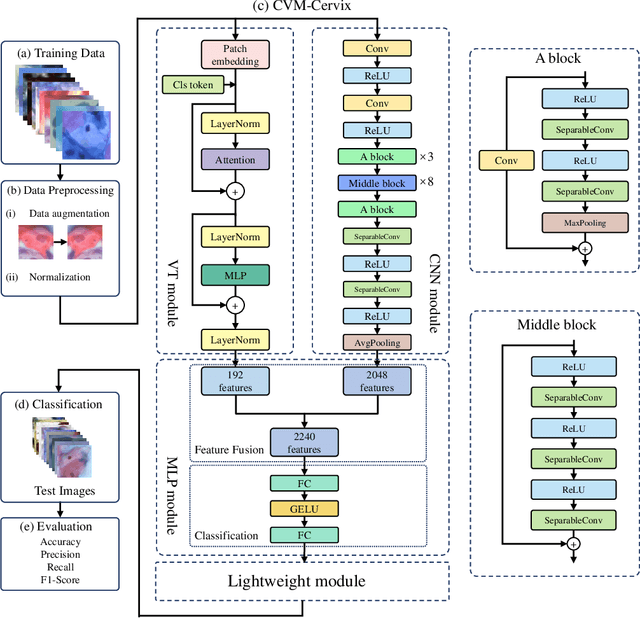
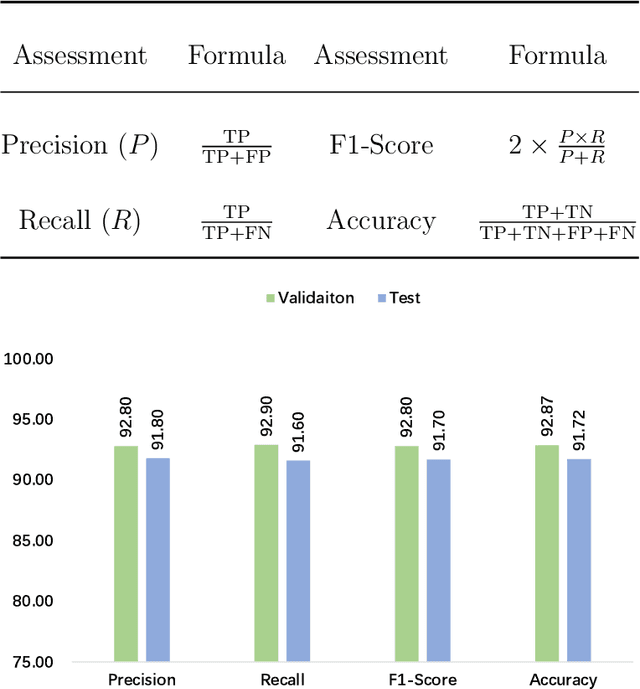
Cervical cancer is the seventh most common cancer among all the cancers worldwide and the fourth most common cancer among women. Cervical cytopathology image classification is an important method to diagnose cervical cancer. Manual screening of cytopathology images is time-consuming and error-prone. The emergence of the automatic computer-aided diagnosis system solves this problem. This paper proposes a framework called CVM-Cervix based on deep learning to perform cervical cell classification tasks. It can analyze pap slides quickly and accurately. CVM-Cervix first proposes a Convolutional Neural Network module and a Visual Transformer module for local and global feature extraction respectively, then a Multilayer Perceptron module is designed to fuse the local and global features for the final classification. Experimental results show the effectiveness and potential of the proposed CVM-Cervix in the field of cervical Pap smear image classification. In addition, according to the practical needs of clinical work, we perform a lightweight post-processing to compress the model.
Feature-based model selection for object detection from point cloud data
Sep 26, 2022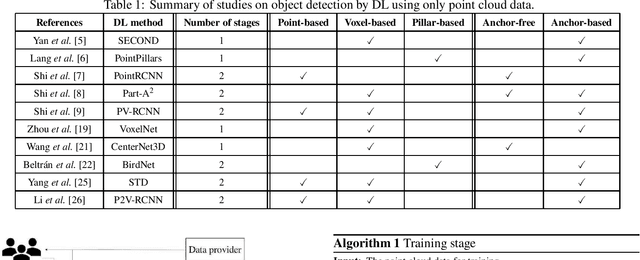
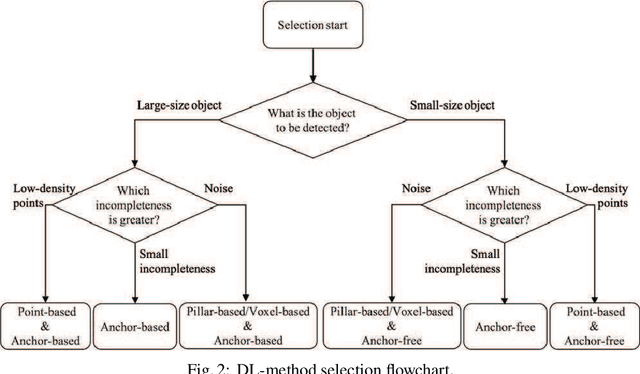
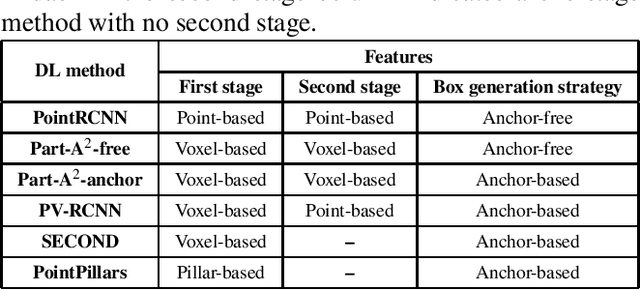
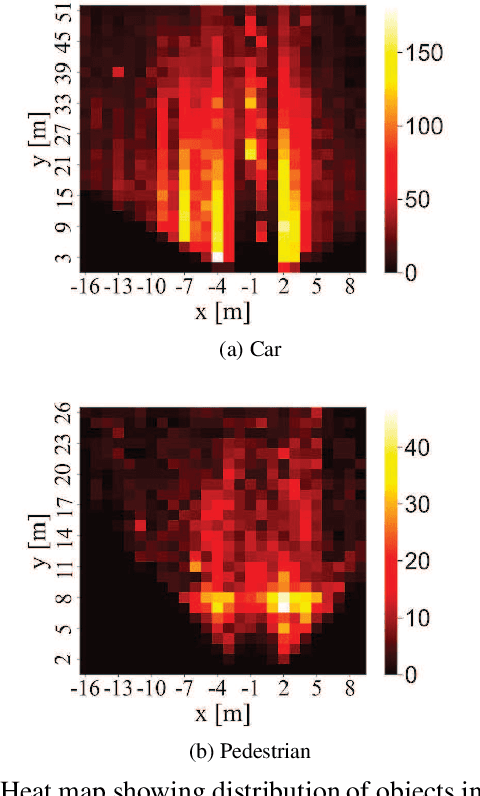
Smart monitoring using three-dimensional (3D) image sensors has been attracting attention in the context of smart cities. In smart monitoring, object detection from point cloud data acquired by 3D image sensors is implemented for detecting moving objects such as vehicles and pedestrians to ensure safety on the road. However, the features of point cloud data are diversified due to the characteristics of light detection and ranging (LIDAR) units used as 3D image sensors or the install position of the 3D image sensors. Although a variety of deep learning (DL) models for object detection from point cloud data have been studied to date, no research has considered how to use multiple DL models in accordance with the features of the point cloud data. In this work, we propose a feature-based model selection framework that creates various DL models by using multiple DL methods and by utilizing training data with pseudo incompleteness generated by two artificial techniques: sampling and noise adding. It selects the most suitable DL model for the object detection task in accordance with the features of the point cloud data acquired in the real environment. To demonstrate the effectiveness of the proposed framework, we compare the performance of multiple DL models using benchmark datasets created from the KITTI dataset and present example results of object detection obtained through a real outdoor experiment. Depending on the situation, the detection accuracy varies up to 32% between DL models, which confirms the importance of selecting an appropriate DL model according to the situation.
All You May Need for VQA are Image Captions
May 04, 2022
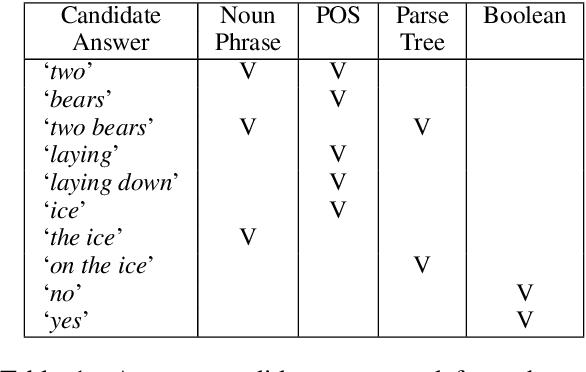
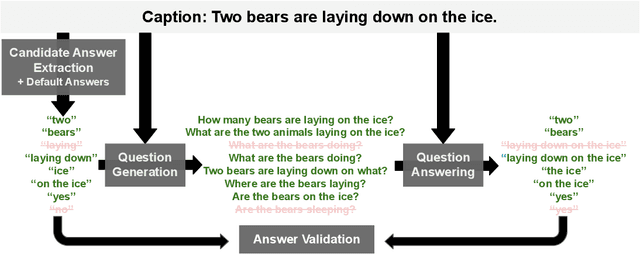
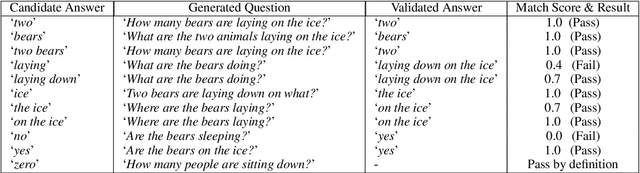
Visual Question Answering (VQA) has benefited from increasingly sophisticated models, but has not enjoyed the same level of engagement in terms of data creation. In this paper, we propose a method that automatically derives VQA examples at volume, by leveraging the abundance of existing image-caption annotations combined with neural models for textual question generation. We show that the resulting data is of high-quality. VQA models trained on our data improve state-of-the-art zero-shot accuracy by double digits and achieve a level of robustness that lacks in the same model trained on human-annotated VQA data.
Post-Training Quantization for Cross-Platform Learned Image Compression
Feb 15, 2022
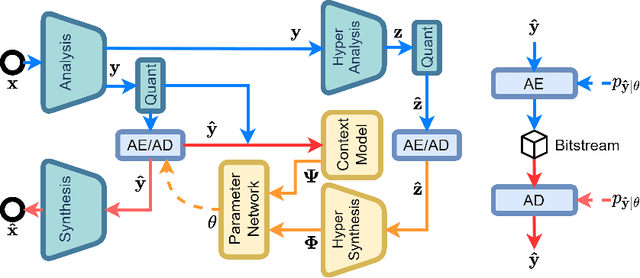

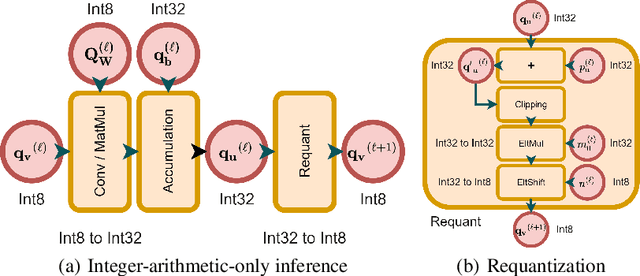
It has been witnessed that learned image compression has outperformed conventional image coding techniques and tends to be practical in industrial applications. One of the most critical issues that need to be considered is the non-deterministic calculation, which makes the probability prediction cross-platform inconsistent and frustrates successful decoding. We propose to solve this problem by introducing well-developed post-training quantization and making the model inference integer-arithmetic-only, which is much simpler than presently existing training and fine-tuning based approaches yet still keeps the superior rate-distortion performance of learned image compression. Based on that, we further improve the discretization of the entropy parameters and extend the deterministic inference to fit Gaussian mixture models. With our proposed methods, the current state-of-the-art image compression models can infer in a cross-platform consistent manner, which makes the further development and practice of learned image compression more promising.
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 12, 2022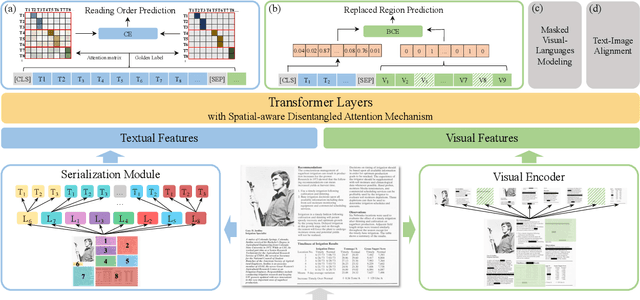
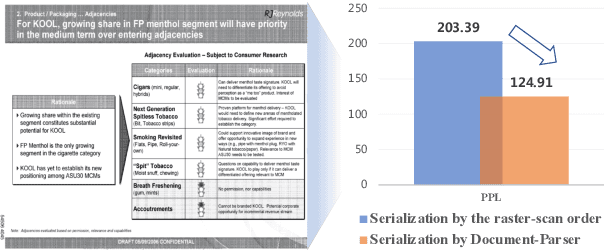
Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.
Self-Supervised Equivariant Regularization Reconciles Multiple Instance Learning: Joint Referable Diabetic Retinopathy Classification and Lesion Segmentation
Oct 12, 2022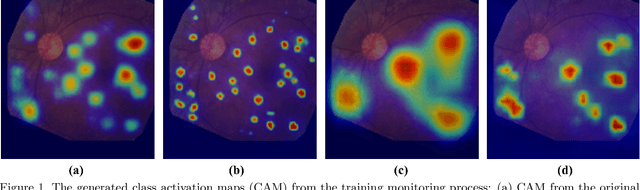
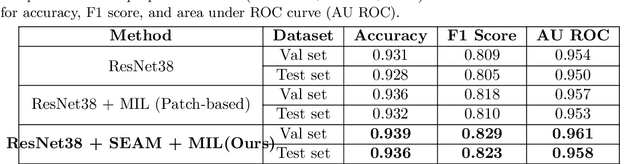
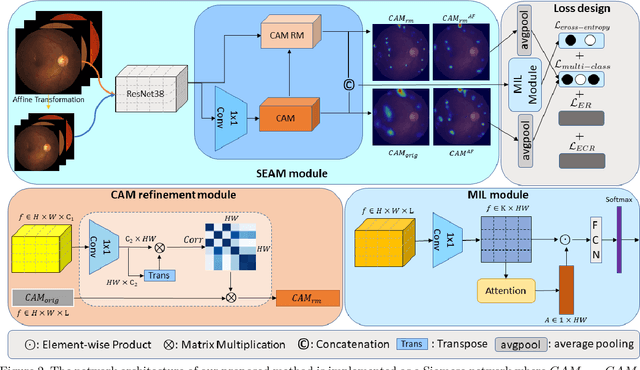

Lesion appearance is a crucial clue for medical providers to distinguish referable diabetic retinopathy (rDR) from non-referable DR. Most existing large-scale DR datasets contain only image-level labels rather than pixel-based annotations. This motivates us to develop algorithms to classify rDR and segment lesions via image-level labels. This paper leverages self-supervised equivariant learning and attention-based multi-instance learning (MIL) to tackle this problem. MIL is an effective strategy to differentiate positive and negative instances, helping us discard background regions (negative instances) while localizing lesion regions (positive ones). However, MIL only provides coarse lesion localization and cannot distinguish lesions located across adjacent patches. Conversely, a self-supervised equivariant attention mechanism (SEAM) generates a segmentation-level class activation map (CAM) that can guide patch extraction of lesions more accurately. Our work aims at integrating both methods to improve rDR classification accuracy. We conduct extensive validation experiments on the Eyepacs dataset, achieving an area under the receiver operating characteristic curve (AU ROC) of 0.958, outperforming current state-of-the-art algorithms.
Sound-Guided Semantic Image Manipulation
Nov 30, 2021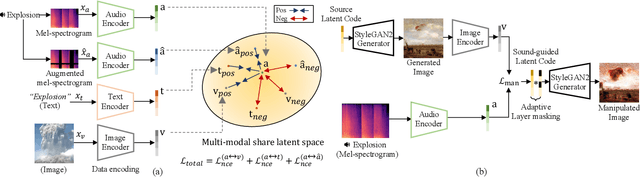
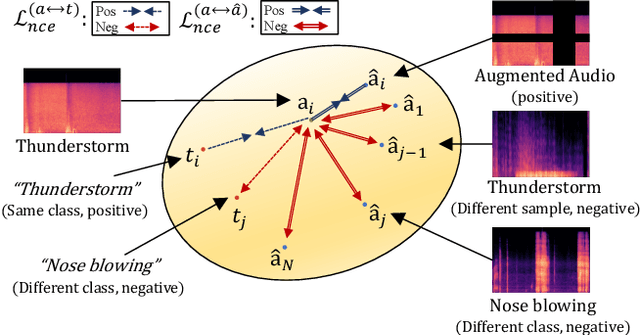


The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal (image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix text and audio modalities, which enrich the variety of the image modification. We verify the effectiveness of our sound-guided image manipulation quantitatively and qualitatively. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.
THOR-Net: End-to-end Graformer-based Realistic Two Hands and Object Reconstruction with Self-supervision
Oct 25, 2022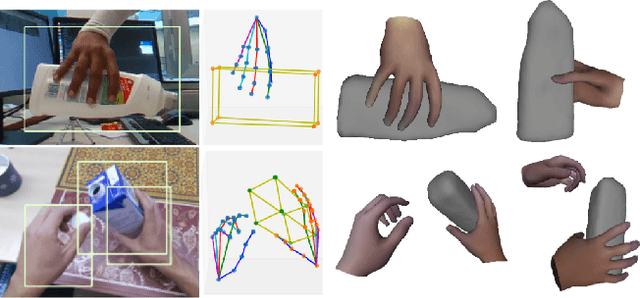
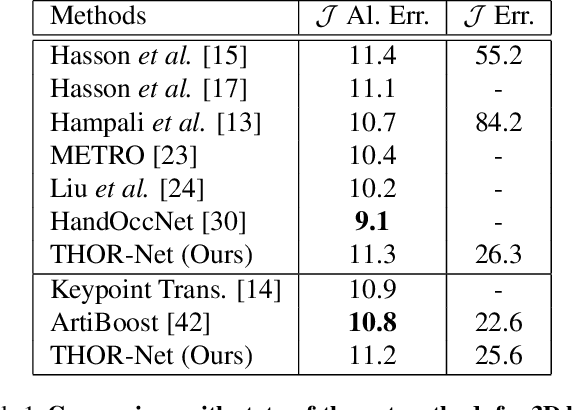
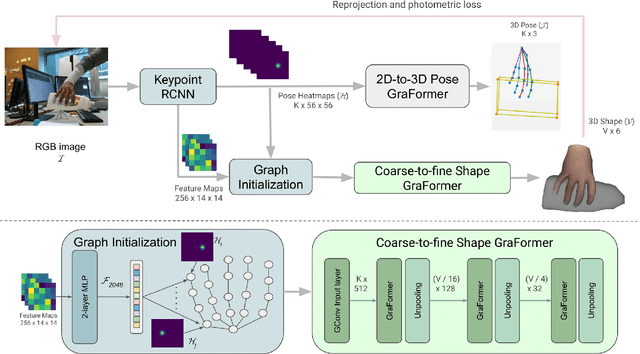
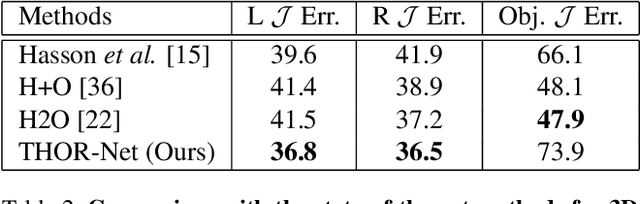
Realistic reconstruction of two hands interacting with objects is a new and challenging problem that is essential for building personalized Virtual and Augmented Reality environments. Graph Convolutional networks (GCNs) allow for the preservation of the topologies of hands poses and shapes by modeling them as a graph. In this work, we propose the THOR-Net which combines the power of GCNs, Transformer, and self-supervision to realistically reconstruct two hands and an object from a single RGB image. Our network comprises two stages; namely the features extraction stage and the reconstruction stage. In the features extraction stage, a Keypoint RCNN is used to extract 2D poses, features maps, heatmaps, and bounding boxes from a monocular RGB image. Thereafter, this 2D information is modeled as two graphs and passed to the two branches of the reconstruction stage. The shape reconstruction branch estimates meshes of two hands and an object using our novel coarse-to-fine GraFormer shape network. The 3D poses of the hands and objects are reconstructed by the other branch using a GraFormer network. Finally, a self-supervised photometric loss is used to directly regress the realistic textured of each vertex in the hands' meshes. Our approach achieves State-of-the-art results in Hand shape estimation on the HO-3D dataset (10.0mm) exceeding ArtiBoost (10.8mm). It also surpasses other methods in hand pose estimation on the challenging two hands and object (H2O) dataset by 5mm on the left-hand pose and 1 mm on the right-hand pose.
Ablation Path Saliency
Sep 26, 2022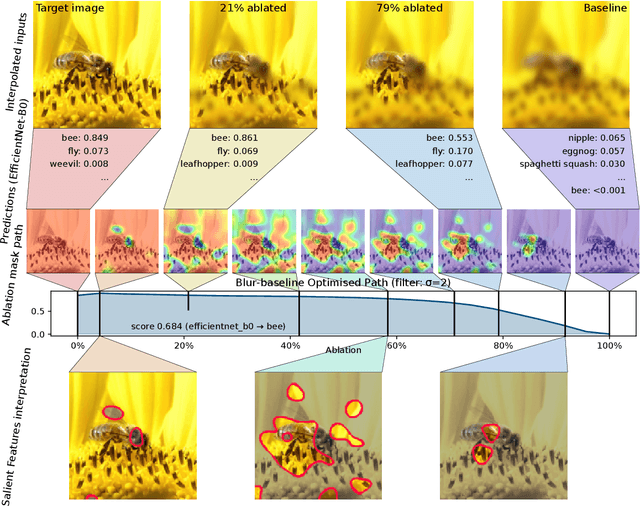


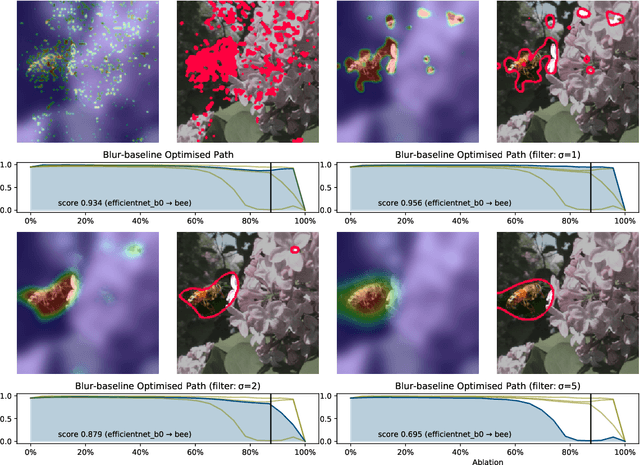
Various types of saliency methods have been proposed for explaining black-box classification. In image applications, this means highlighting the part of the image that is most relevant for the current decision. We observe that several of these methods can be seen as edge cases of a single, more general procedure based on finding a particular ablation path through the classifier's domain. This gives additional geometric insight to the existing methods. We also demonstrate that this ablation path method can be used as a technique in its own right, the higher computational cost being traded against additional information given by the path.