 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey of Cross-Modality Brain Image Synthesis
Feb 16, 2022
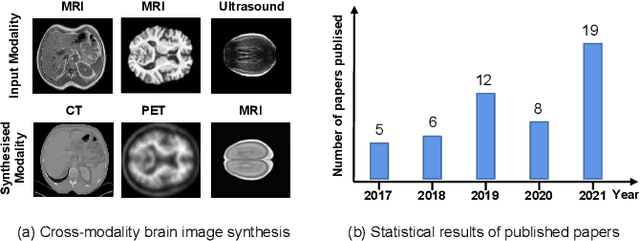
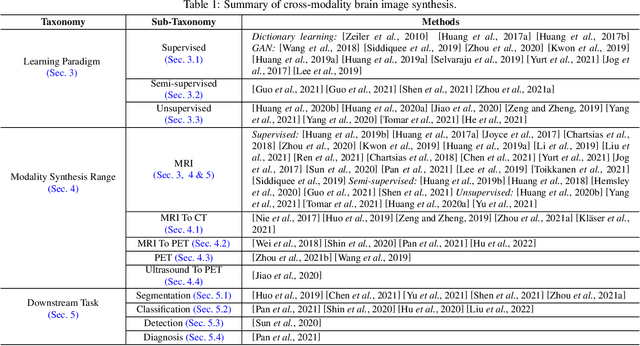
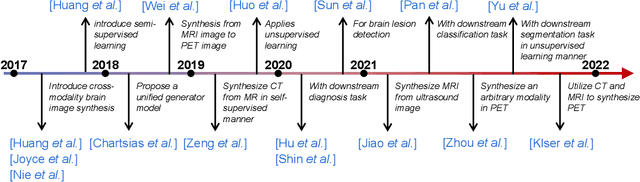
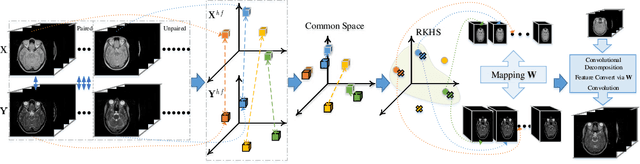
The existence of completely aligned and paired multi-modal neuroimaging data has proved its effectiveness in diagnosis of brain diseases. However, collecting the full set of well-aligned and paired data is impractical or even luxurious, since the practical difficulties may include high cost, long time acquisition, image corruption, and privacy issues. A realistic solution is to explore either an unsupervised learning or a semi-supervised learning to synthesize the absent neuroimaging data. In this paper, we tend to approach multi-modality brain image synthesis task from different perspectives, which include the level of supervision, the range of modality synthesis, and the synthesis-based downstream tasks. Particularly, we provide in-depth analysis on how cross-modality brain image synthesis can improve the performance of different downstream tasks. Finally, we evaluate the challenges and provide several open directions for this community. All resources are available at https://github.com/M-3LAB/awesome-multimodal-brain-image-systhesis
Deep Equilibrium Approaches to Diffusion Models
Oct 23, 2022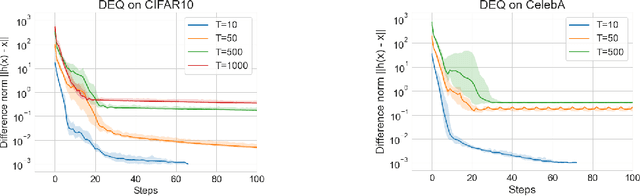
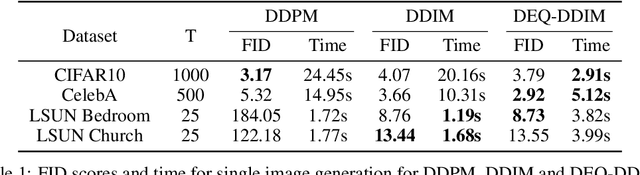

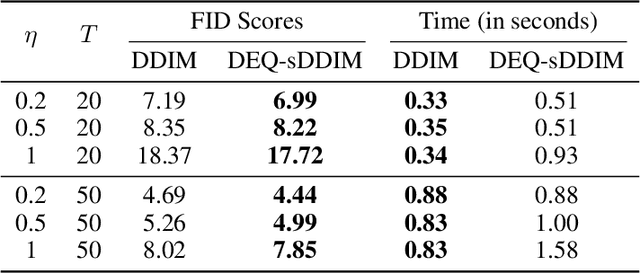
Diffusion-based generative models are extremely effective in generating high-quality images, with generated samples often surpassing the quality of those produced by other models under several metrics. One distinguishing feature of these models, however, is that they typically require long sampling chains to produce high-fidelity images. This presents a challenge not only from the lenses of sampling time, but also from the inherent difficulty in backpropagating through these chains in order to accomplish tasks such as model inversion, i.e. approximately finding latent states that generate known images. In this paper, we look at diffusion models through a different perspective, that of a (deep) equilibrium (DEQ) fixed point model. Specifically, we extend the recent denoising diffusion implicit model (DDIM; Song et al. 2020), and model the entire sampling chain as a joint, multivariate fixed point system. This setup provides an elegant unification of diffusion and equilibrium models, and shows benefits in 1) single image sampling, as it replaces the fully-serial typical sampling process with a parallel one; and 2) model inversion, where we can leverage fast gradients in the DEQ setting to much more quickly find the noise that generates a given image. The approach is also orthogonal and thus complementary to other methods used to reduce the sampling time, or improve model inversion. We demonstrate our method's strong performance across several datasets, including CIFAR10, CelebA, and LSUN Bedrooms and Churches.
Delving into Masked Autoencoders for Multi-Label Thorax Disease Classification
Oct 23, 2022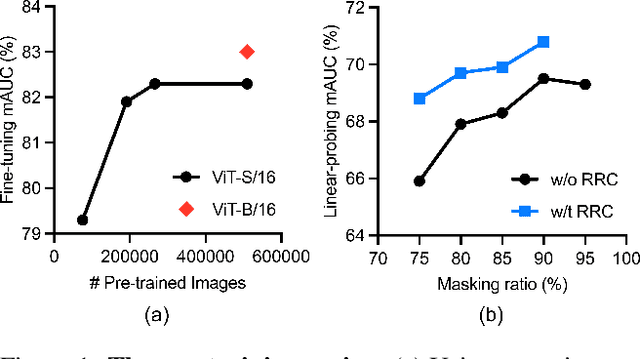
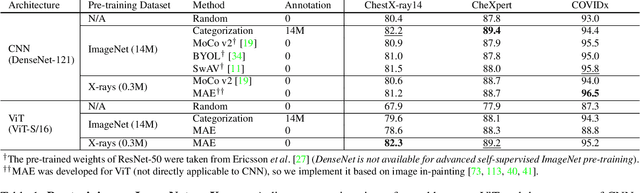

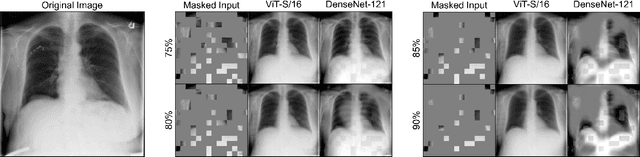
Vision Transformer (ViT) has become one of the most popular neural architectures due to its great scalability, computational efficiency, and compelling performance in many vision tasks. However, ViT has shown inferior performance to Convolutional Neural Network (CNN) on medical tasks due to its data-hungry nature and the lack of annotated medical data. In this paper, we pre-train ViTs on 266,340 chest X-rays using Masked Autoencoders (MAE) which reconstruct missing pixels from a small part of each image. For comparison, CNNs are also pre-trained on the same 266,340 X-rays using advanced self-supervised methods (e.g., MoCo v2). The results show that our pre-trained ViT performs comparably (sometimes better) to the state-of-the-art CNN (DenseNet-121) for multi-label thorax disease classification. This performance is attributed to the strong recipes extracted from our empirical studies for pre-training and fine-tuning ViT. The pre-training recipe signifies that medical reconstruction requires a much smaller proportion of an image (10% vs. 25%) and a more moderate random resized crop range (0.5~1.0 vs. 0.2~1.0) compared with natural imaging. Furthermore, we remark that in-domain transfer learning is preferred whenever possible. The fine-tuning recipe discloses that layer-wise LR decay, RandAug magnitude, and DropPath rate are significant factors to consider. We hope that this study can direct future research on the application of Transformers to a larger variety of medical imaging tasks.
Background-Mixed Augmentation for Weakly Supervised Change Detection
Nov 21, 2022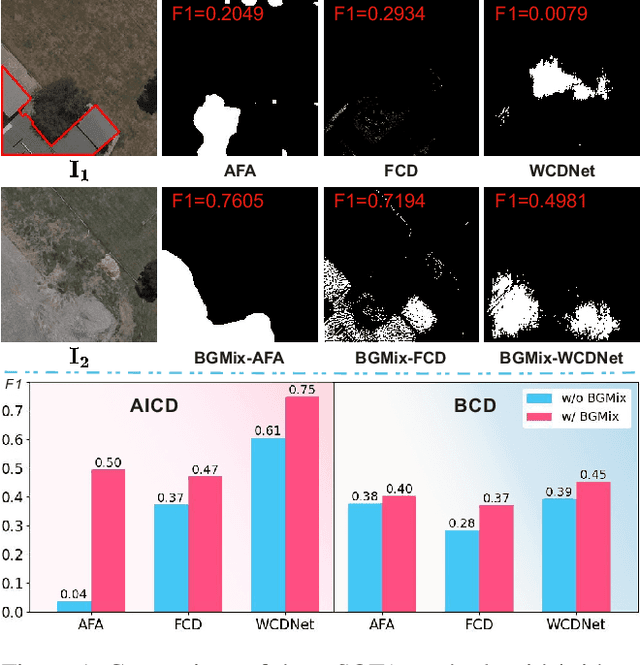
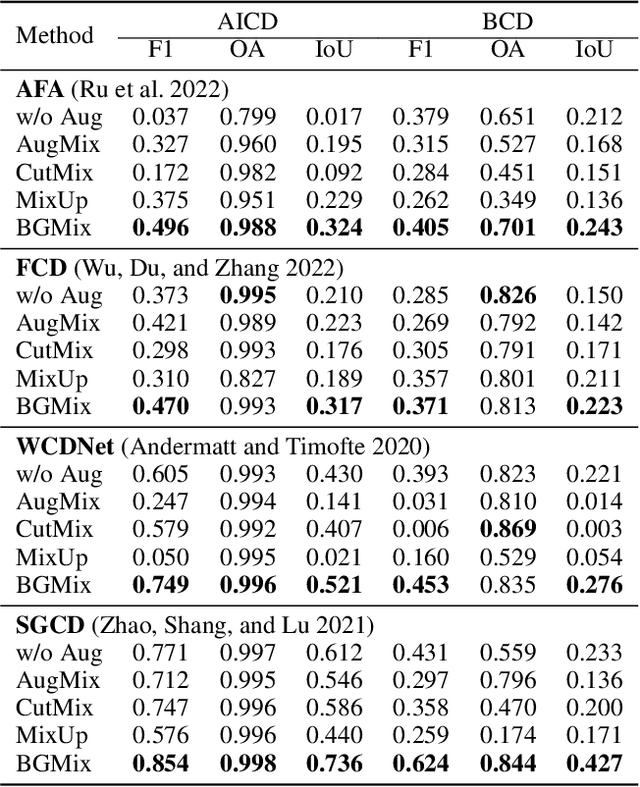

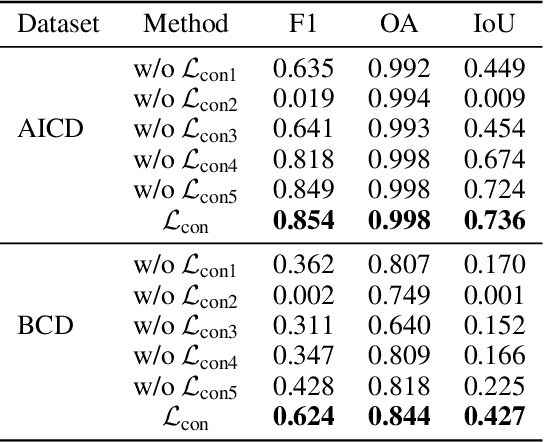
Change detection (CD) is to decouple object changes (i.e., object missing or appearing) from background changes (i.e., environment variations) like light and season variations in two images captured in the same scene over a long time span, presenting critical applications in disaster management, urban development, etc. In particular, the endless patterns of background changes require detectors to have a high generalization against unseen environment variations, making this task significantly challenging. Recent deep learning-based methods develop novel network architectures or optimization strategies with paired-training examples, which do not handle the generalization issue explicitly and require huge manual pixel-level annotation efforts. In this work, for the first attempt in the CD community, we study the generalization issue of CD from the perspective of data augmentation and develop a novel weakly supervised training algorithm that only needs image-level labels. Different from general augmentation techniques for classification, we propose the background-mixed augmentation that is specifically designed for change detection by augmenting examples under the guidance of a set of background changing images and letting deep CD models see diverse environment variations. Moreover, we propose the augmented & real data consistency loss that encourages the generalization increase significantly. Our method as a general framework can enhance a wide range of existing deep learning-based detectors. We conduct extensive experiments in two public datasets and enhance four state-of-the-art methods, demonstrating the advantages of
Open-Source Skull Reconstruction with MONAI
Nov 25, 2022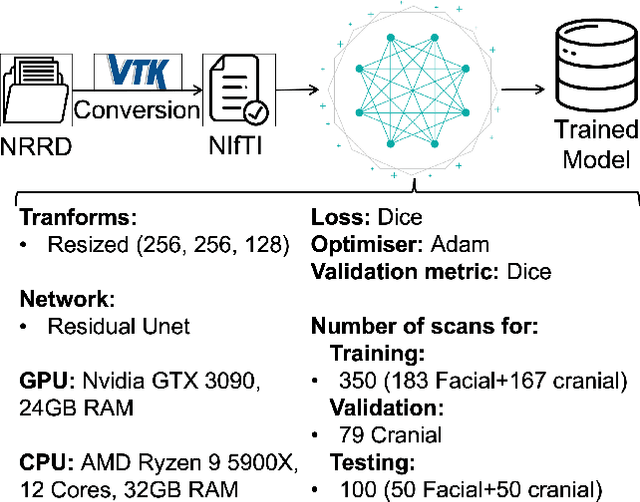
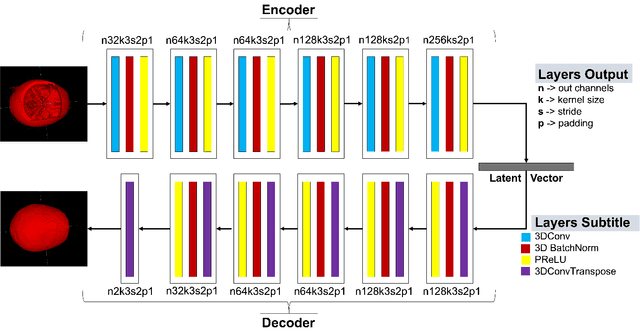
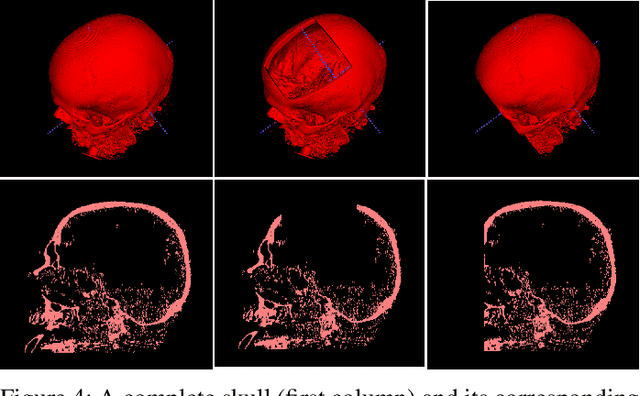
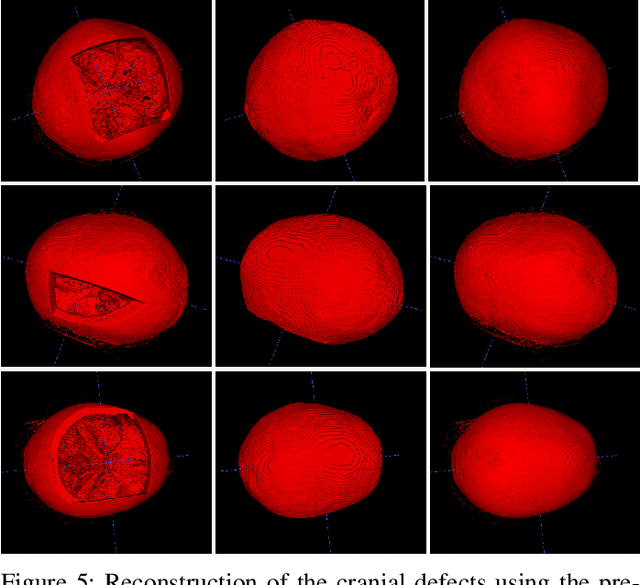
We present a deep learning-based approach for skull reconstruction for MONAI, which has been pre-trained on the MUG500+ skull dataset. The implementation follows the MONAI contribution guidelines, hence, it can be easily tried out and used, and extended by MONAI users. The primary goal of this paper lies in the investigation of open-sourcing codes and pre-trained deep learning models under the MONAI framework. Nowadays, open-sourcing software, especially (pre-trained) deep learning models, has become increasingly important. Over the years, medical image analysis experienced a tremendous transformation. Over a decade ago, algorithms had to be implemented and optimized with low-level programming languages, like C or C++, to run in a reasonable time on a desktop PC, which was not as powerful as today's computers. Nowadays, users have high-level scripting languages like Python, and frameworks like PyTorch and TensorFlow, along with a sea of public code repositories at hand. As a result, implementations that had thousands of lines of C or C++ code in the past, can now be scripted with a few lines and in addition executed in a fraction of the time. To put this even on a higher level, the Medical Open Network for Artificial Intelligence (MONAI) framework tailors medical imaging research to an even more convenient process, which can boost and push the whole field. The MONAI framework is a freely available, community-supported, open-source and PyTorch-based framework, that also enables to provide research contributions with pre-trained models to others. Codes and pre-trained weights for skull reconstruction are publicly available at: https://github.com/Project-MONAI/research-contributions/tree/master/SkullRec
Towards Universal GAN Image Detection
Dec 23, 2021
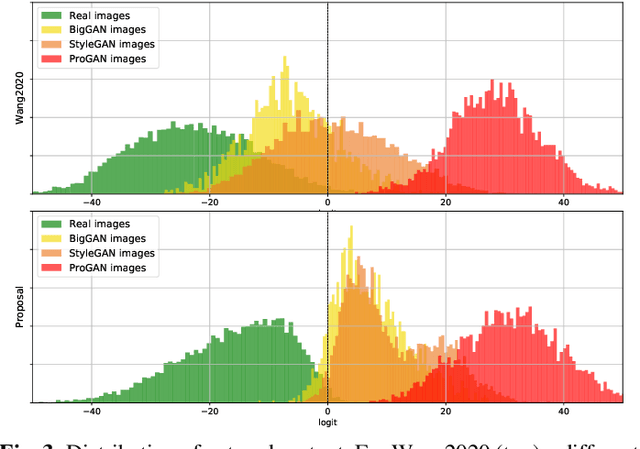
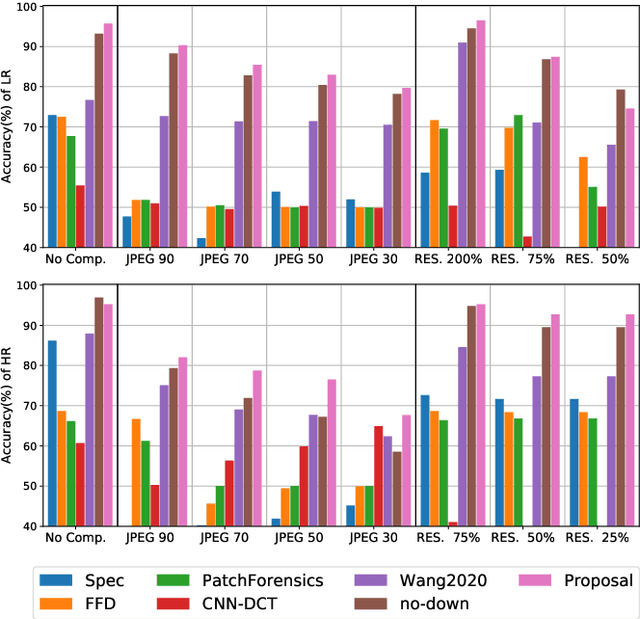
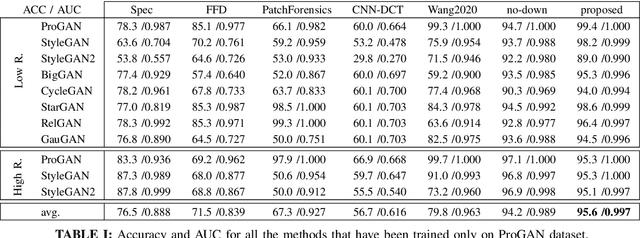
The ever higher quality and wide diffusion of fake images have spawn a quest for reliable forensic tools. Many GAN image detectors have been proposed, recently. In real world scenarios, however, most of them show limited robustness and generalization ability. Moreover, they often rely on side information not available at test time, that is, they are not universal. We investigate these problems and propose a new GAN image detector based on a limited sub-sampling architecture and a suitable contrastive learning paradigm. Experiments carried out in challenging conditions prove the proposed method to be a first step towards universal GAN image detection, ensuring also good robustness to common image impairments, and good generalization to unseen architectures.
Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing
Oct 10, 2022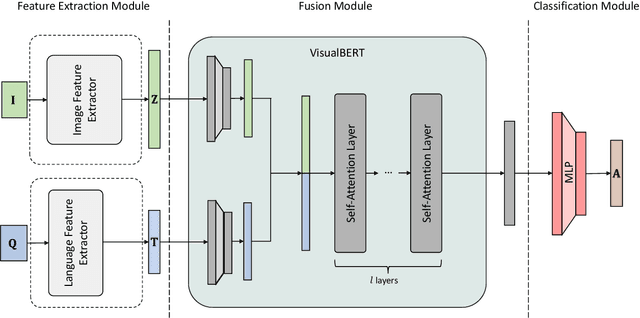
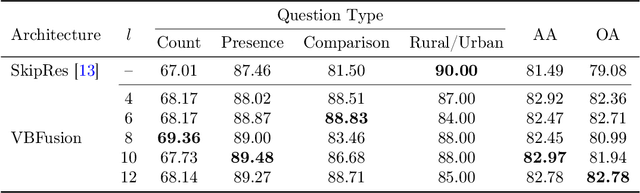
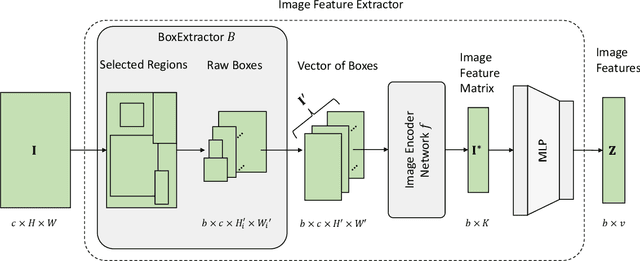
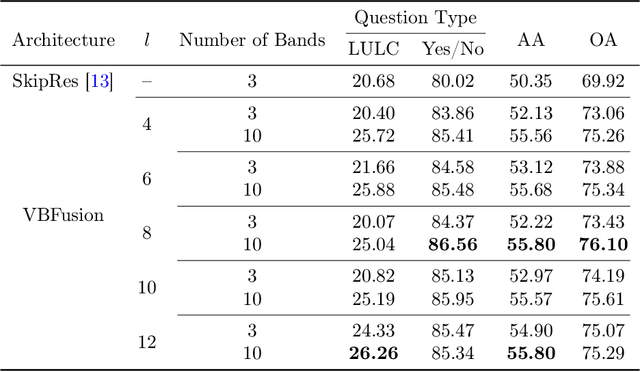
With the new generation of satellite technologies, the archives of remote sensing (RS) images are growing very fast. To make the intrinsic information of each RS image easily accessible, visual question answering (VQA) has been introduced in RS. VQA allows a user to formulate a free-form question concerning the content of RS images to extract generic information. It has been shown that the fusion of the input modalities (i.e., image and text) is crucial for the performance of VQA systems. Most of the current fusion approaches use modality-specific representations in their fusion modules instead of joint representation learning. However, to discover the underlying relation between both the image and question modality, the model is required to learn the joint representation instead of simply combining (e.g., concatenating, adding, or multiplying) the modality-specific representations. We propose a multi-modal transformer-based architecture to overcome this issue. Our proposed architecture consists of three main modules: i) the feature extraction module for extracting the modality-specific features; ii) the fusion module, which leverages a user-defined number of multi-modal transformer layers of the VisualBERT model (VB); and iii) the classification module to obtain the answer. Experimental results obtained on the RSVQAxBEN and RSVQA-LR datasets (which are made up of RGB bands of Sentinel-2 images) demonstrate the effectiveness of VBFusion for VQA tasks in RS. To analyze the importance of using other spectral bands for the description of the complex content of RS images in the framework of VQA, we extend the RSVQAxBEN dataset to include all the spectral bands of Sentinel-2 images with 10m and 20m spatial resolution.
Privacy-Enhancing Optical Embeddings for Lensless Classification
Nov 23, 2022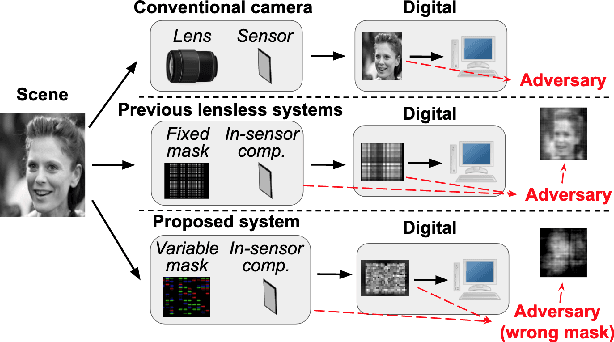
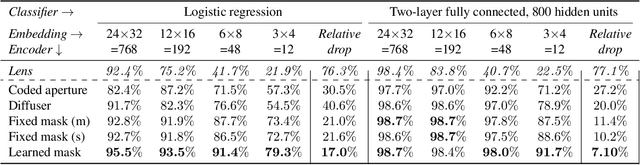
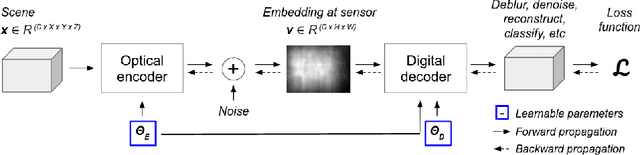
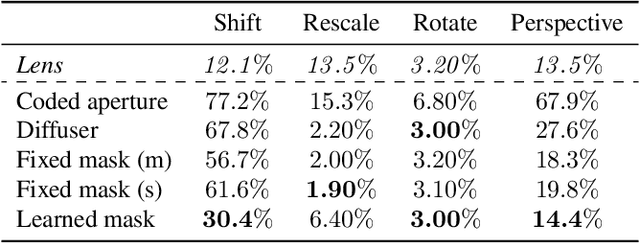
Lensless imaging can provide visual privacy due to the highly multiplexed characteristic of its measurements. However, this alone is a weak form of security, as various adversarial attacks can be designed to invert the one-to-many scene mapping of such cameras. In this work, we enhance the privacy provided by lensless imaging by (1) downsampling at the sensor and (2) using a programmable mask with variable patterns as our optical encoder. We build a prototype from a low-cost LCD and Raspberry Pi components, for a total cost of around 100 USD. This very low price point allows our system to be deployed and leveraged in a broad range of applications. In our experiments, we first demonstrate the viability and reconfigurability of our system by applying it to various classification tasks: MNIST, CelebA (face attributes), and CIFAR10. By jointly optimizing the mask pattern and a digital classifier in an end-to-end fashion, low-dimensional, privacy-enhancing embeddings are learned directly at the sensor. Secondly, we show how the proposed system, through variable mask patterns, can thwart adversaries that attempt to invert the system (1) via plaintext attacks or (2) in the event of camera parameters leaks. We demonstrate the defense of our system to both risks, with 55% and 26% drops in image quality metrics for attacks based on model-based convex optimization and generative neural networks respectively. We open-source a wave propagation and camera simulator needed for end-to-end optimization, the training software, and a library for interfacing with the camera.
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding
Mar 16, 2022
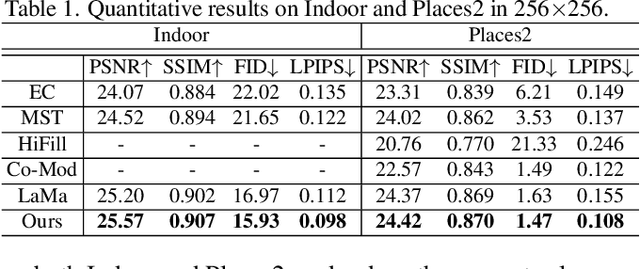
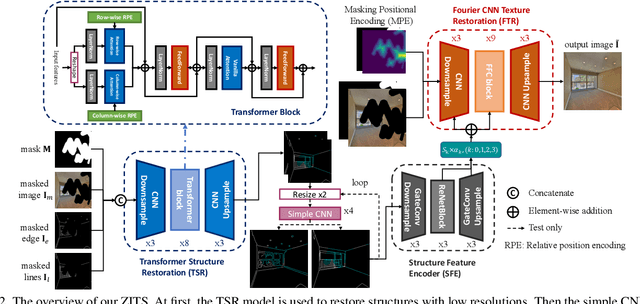
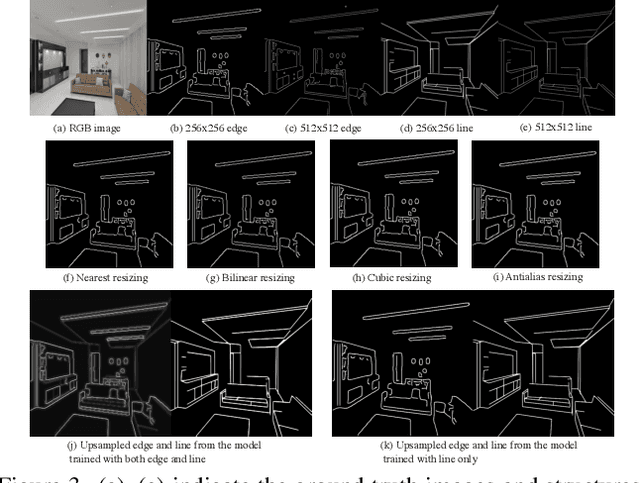
Image inpainting has made significant advances in recent years. However, it is still challenging to recover corrupted images with both vivid textures and reasonable structures. Some specific methods only tackle regular textures while losing holistic structures due to the limited receptive fields of convolutional neural networks (CNNs). On the other hand, attention-based models can learn better long-range dependency for the structure recovery, but they are limited by the heavy computation for inference with large image sizes. To address these issues, we propose to leverage an additional structure restorer to facilitate the image inpainting incrementally. The proposed model restores holistic image structures with a powerful attention-based transformer model in a fixed low-resolution sketch space. Such a grayscale space is easy to be upsampled to larger scales to convey correct structural information. Our structure restorer can be integrated with other pretrained inpainting models efficiently with the zero-initialized residual addition. Furthermore, a masking positional encoding strategy is utilized to improve the performance with large irregular masks. Extensive experiments on various datasets validate the efficacy of our model compared with other competitors. Our codes are released in https://github.com/DQiaole/ZITS_inpainting.
Efficient Lung Cancer Image Classification and Segmentation Algorithm Based on Improved Swin Transformer
Jul 04, 2022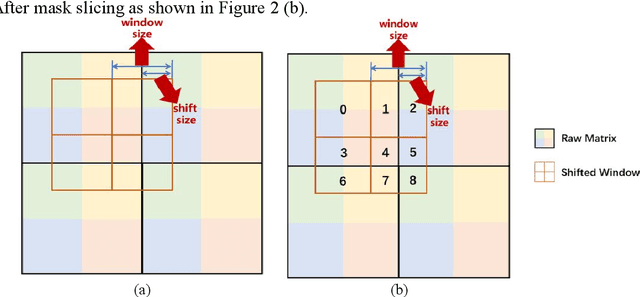
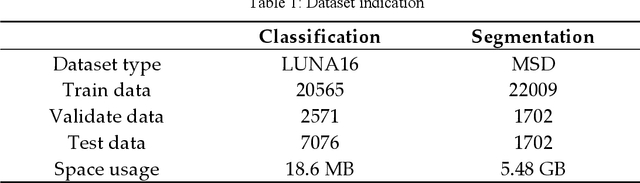
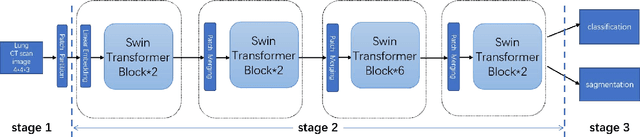
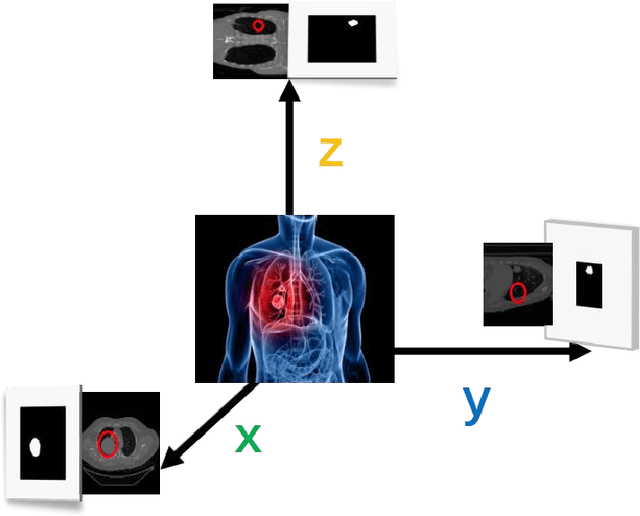
With the development of computer technology, various models have emerged in artificial intelligence. The transformer model has been applied to the field of computer vision (CV) after its success in natural language processing (NLP). Radiologists continue to face multiple challenges in today's rapidly evolving medical field, such as increased workload and increased diagnostic demands. Although there are some conventional methods for lung cancer detection before, their accuracy still needs to be improved, especially in realistic diagnostic scenarios. This paper creatively proposes a segmentation method based on efficient transformer and applies it to medical image analysis. The algorithm completes the task of lung cancer classification and segmentation by analyzing lung cancer data, and aims to provide efficient technical support for medical staff. In addition, we evaluated and compared the results in various aspects. For the classification mission, the max accuracy of Swin-T by regular training and Swin-B in two resolutions by pre-training can be up to 82.3%. For the segmentation mission, we use pre-training to help the model improve the accuracy of our experiments. The accuracy of the three models reaches over 95%. The experiments demonstrate that the algorithm can be well applied to lung cancer classification and segmentation missions.