 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multipod Convolutional Network
Oct 03, 2022



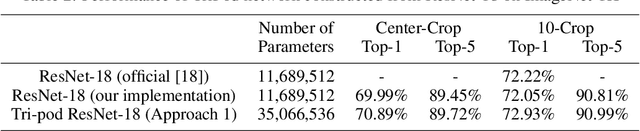
In this paper, we introduce a convolutional network which we call MultiPodNet consisting of a combination of two or more convolutional networks which process the input image in parallel to achieve the same goal. Output feature maps of parallel convolutional networks are fused at the fully connected layer of the network. We experimentally observed that three parallel pod networks (TripodNet) produce the best results in commonly used object recognition datasets. Baseline pod networks can be of any type. In this paper, we use ResNets as baseline networks and their inputs are augmented image patches. The number of parameters of the TripodNet is about three times that of a single ResNet. We train the TripodNet using the standard backpropagation type algorithms. In each individual ResNet, parameters are initialized with different random numbers during training. The TripodNet achieved state-of-the-art performance on CIFAR-10 and ImageNet datasets. For example, it improved the accuracy of a single ResNet from 91.66% to 92.47% under the same training process on the CIFAR-10 dataset.
Segment Augmentation and Differentiable Ranking for Logo Retrieval
Sep 13, 2022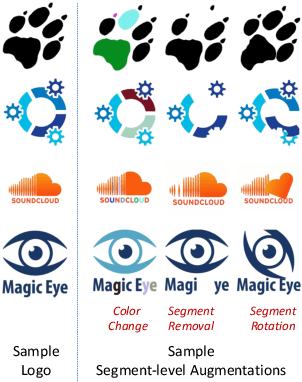
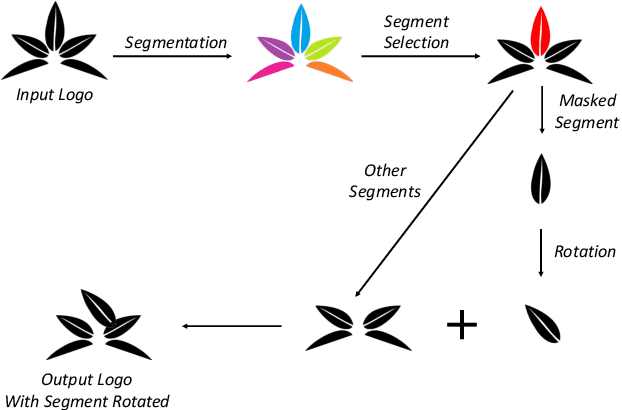
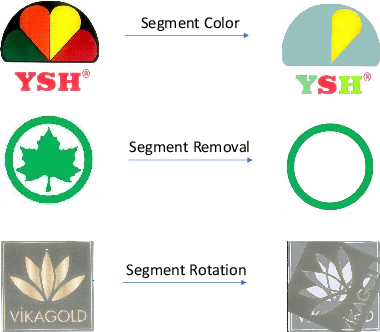
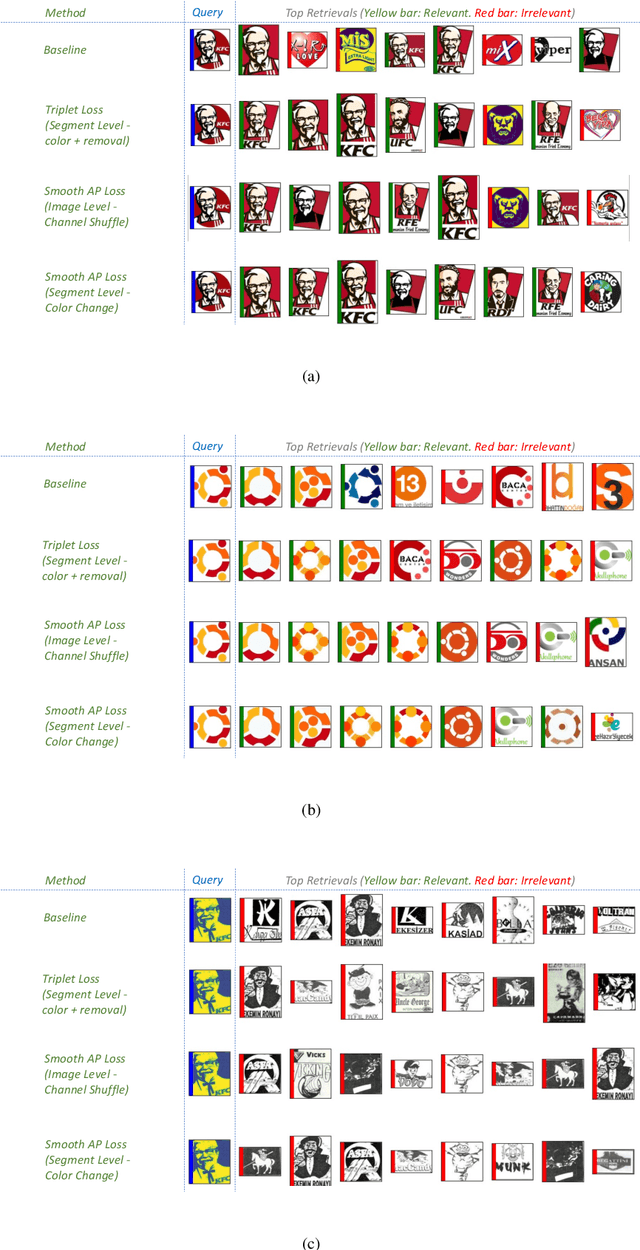
Logo retrieval is a challenging problem since the definition of similarity is more subjective compared to image retrieval tasks and the set of known similarities is very scarce. To tackle this challenge, in this paper, we propose a simple but effective segment-based augmentation strategy to introduce artificially similar logos for training deep networks for logo retrieval. In this novel augmentation strategy, we first find segments in a logo and apply transformations such as rotation, scaling, and color change, on the segments, unlike the conventional image-level augmentation strategies. Moreover, we evaluate whether the recently introduced ranking-based loss function, Smooth-AP, is a better approach for learning similarity for logo retrieval. On the large scale METU Trademark Dataset, we show that (i) our segment-based augmentation strategy improves retrieval performance compared to the baseline model or image-level augmentation strategies, and (ii) Smooth-AP indeed performs better than conventional losses for logo retrieval.
3D-GMIC: an efficient deep neural network to find small objects in large 3D images
Oct 16, 2022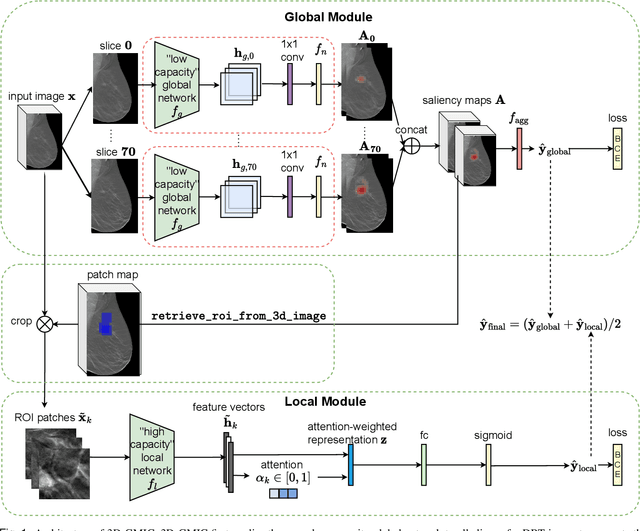
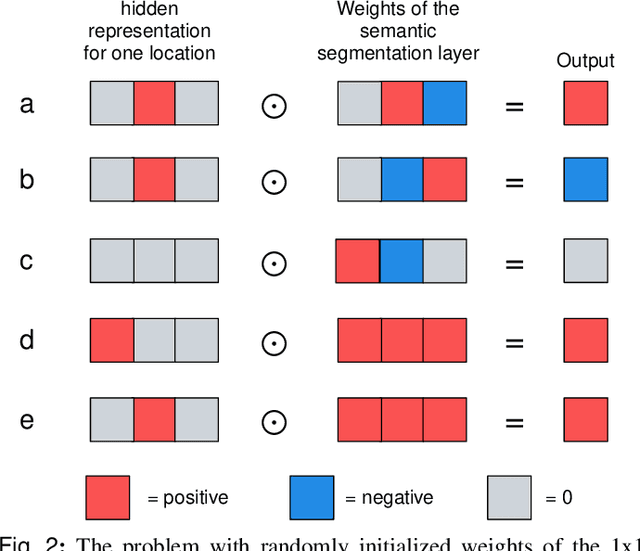
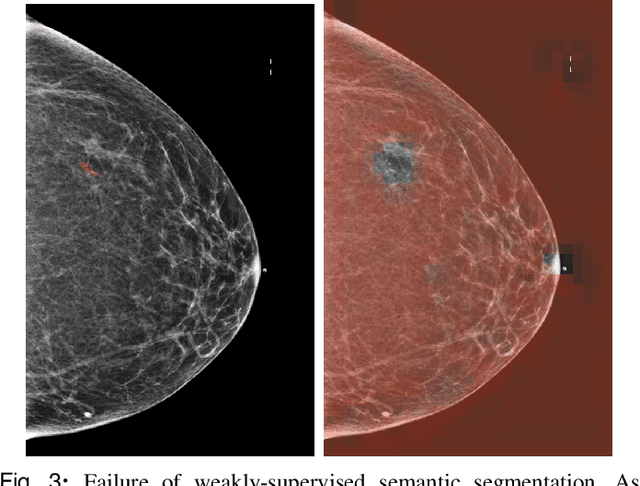
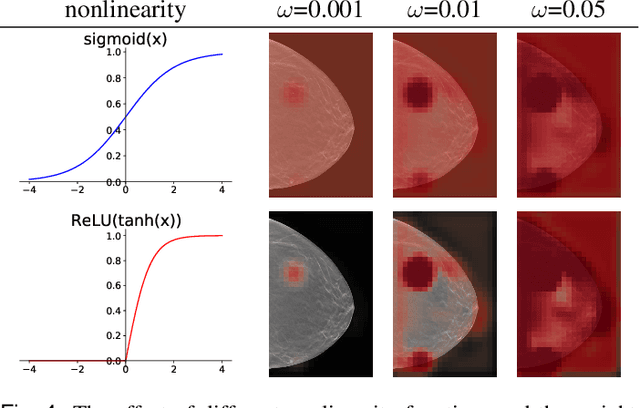
3D imaging enables a more accurate diagnosis by providing spatial information about organ anatomy. However, using 3D images to train AI models is computationally challenging because they consist of tens or hundreds of times more pixels than their 2D counterparts. To train with high-resolution 3D images, convolutional neural networks typically resort to downsampling them or projecting them to two dimensions. In this work, we propose an effective alternative, a novel neural network architecture that enables computationally efficient classification of 3D medical images in their full resolution. Compared to off-the-shelf convolutional neural networks, 3D-GMIC uses 77.98%-90.05% less GPU memory and 91.23%-96.02% less computation. While our network is trained only with image-level labels, without segmentation labels, it explains its classification predictions by providing pixel-level saliency maps. On a dataset collected at NYU Langone Health, including 85,526 patients with full-field 2D mammography (FFDM), synthetic 2D mammography, and 3D mammography (DBT), our model, the 3D Globally-Aware Multiple Instance Classifier (3D-GMIC), achieves a breast-wise AUC of 0.831 (95% CI: 0.769-0.887) in classifying breasts with malignant findings using DBT images. As DBT and 2D mammography capture different information, averaging predictions on 2D and 3D mammography together leads to a diverse ensemble with an improved breast-wise AUC of 0.841 (95% CI: 0.768-0.895). Our model generalizes well to an external dataset from Duke University Hospital, achieving an image-wise AUC of 0.848 (95% CI: 0.798-0.896) in classifying DBT images with malignant findings.
Multimodal Transformer for Parallel Concatenated Variational Autoencoders
Oct 28, 2022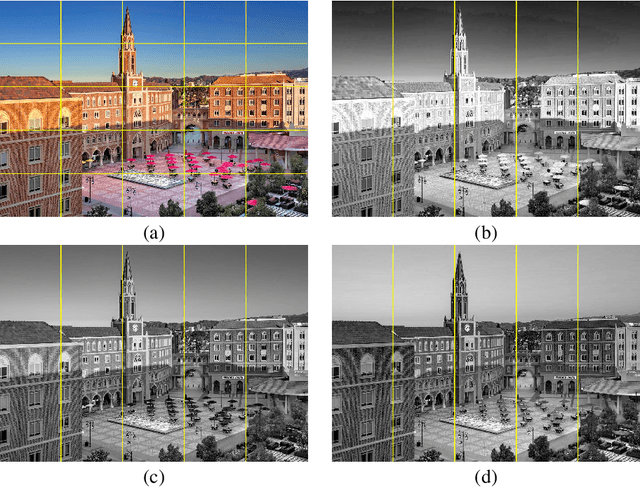
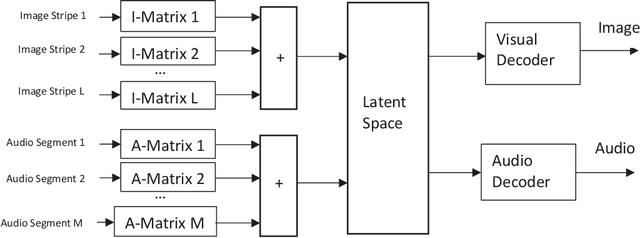
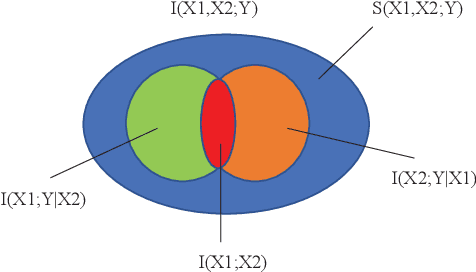

In this paper, we propose a multimodal transformer using parallel concatenated architecture. Instead of using patches, we use column stripes for images in R, G, B channels as the transformer input. The column stripes keep the spatial relations of original image. We incorporate the multimodal transformer with variational autoencoder for synthetic cross-modal data generation. The multimodal transformer is designed using multiple compression matrices, and it serves as encoders for Parallel Concatenated Variational AutoEncoders (PC-VAE). The PC-VAE consists of multiple encoders, one latent space, and two decoders. The encoders are based on random Gaussian matrices and don't need any training. We propose a new loss function based on the interaction information from partial information decomposition. The interaction information evaluates the input cross-modal information and decoder output. The PC-VAE are trained via minimizing the loss function. Experiments are performed to validate the proposed multimodal transformer for PC-VAE.
Semi-supervised domain adaptation with CycleGAN guided by a downstream task loss
Aug 18, 2022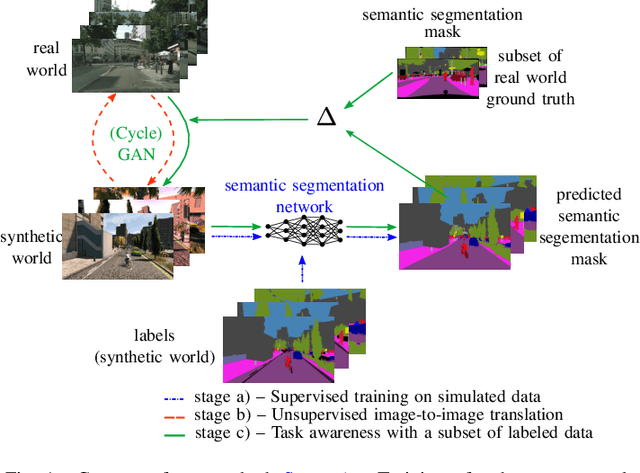
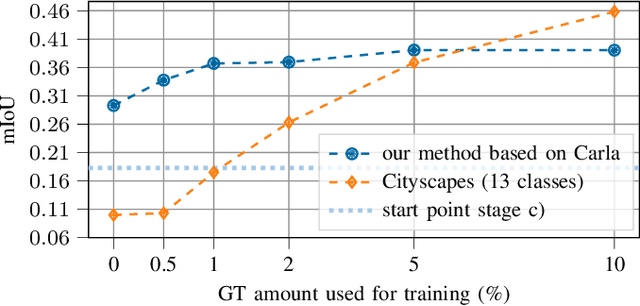


Domain adaptation is of huge interest as labeling is an expensive and error-prone task, especially when labels are needed on pixel-level like in semantic segmentation. Therefore, one would like to be able to train neural networks on synthetic domains, where data is abundant and labels are precise. However, these models often perform poorly on out-of-domain images. To mitigate the shift in the input, image-to-image approaches can be used. Nevertheless, standard image-to-image approaches that bridge the domain of deployment with the synthetic training domain do not focus on the downstream task but only on the visual inspection level. We therefore propose a "task aware" version of a GAN in an image-to-image domain adaptation approach. With the help of a small amount of labeled ground truth data, we guide the image-to-image translation to a more suitable input image for a semantic segmentation network trained on synthetic data (synthetic-domain expert). The main contributions of this work are 1) a modular semi-supervised domain adaptation method for semantic segmentation by training a downstream task aware CycleGAN while refraining from adapting the synthetic semantic segmentation expert 2) the demonstration that the method is applicable to complex domain adaptation tasks and 3) a less biased domain gap analysis by using from scratch networks. We evaluate our method on a classification task as well as on semantic segmentation. Our experiments demonstrate that our method outperforms CycleGAN - a standard image-to-image approach - by 7 percent points in accuracy in a classification task using only 70 (10%) ground truth images. For semantic segmentation we can show an improvement of about 4 to 7 percent points in mean Intersection over union on the Cityscapes evaluation dataset with only 14 ground truth images during training.
Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence
Mar 08, 2022
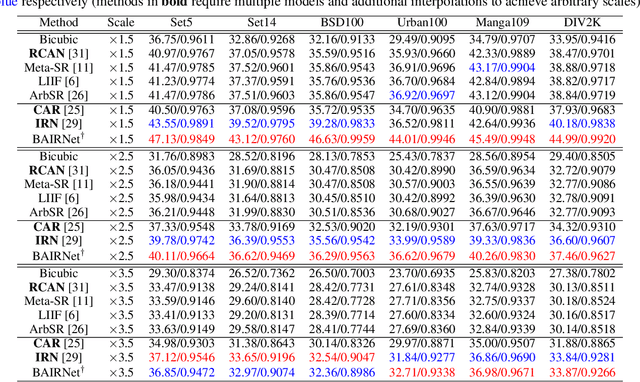
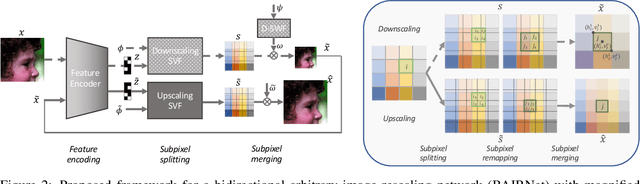

Deep learning based single image super-resolution models have been widely studied and superb results are achieved in upscaling low-resolution images with fixed scale factor and downscaling degradation kernel. To improve real world applicability of such models, there are growing interests to develop models optimized for arbitrary upscaling factors. Our proposed method is the first to treat arbitrary rescaling, both upscaling and downscaling, as one unified process. Using joint optimization of both directions, the proposed model is able to learn upscaling and downscaling simultaneously and achieve bidirectional arbitrary image rescaling. It improves the performance of current arbitrary upscaling models by a large margin while at the same time learns to maintain visual perception quality in downscaled images. The proposed model is further shown to be robust in cycle idempotence test, free of severe degradations in reconstruction accuracy when the downscaling-to-upscaling cycle is applied repetitively. This robustness is beneficial for image rescaling in the wild when this cycle could be applied to one image for multiple times. It also performs well on tests with arbitrary large scales and asymmetric scales, even when the model is not trained with such tasks. Extensive experiments are conducted to demonstrate the superior performance of our model.
Extended Feature Space-Based Automatic Melanoma Detection System
Sep 10, 2022
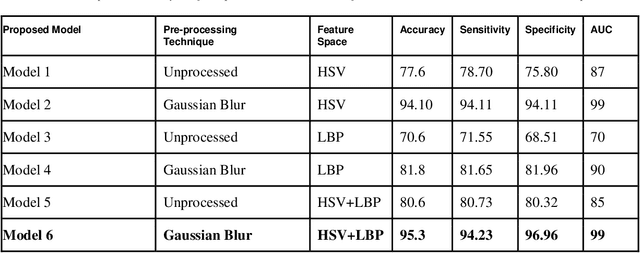
Melanoma is the deadliest form of skin cancer. Uncontrollable growth of melanocytes leads to melanoma. Melanoma has been growing wildly in the last few decades. In recent years, the detection of melanoma using image processing techniques has become a dominant research field. The Automatic Melanoma Detection System (AMDS) helps to detect melanoma based on image processing techniques by accepting infected skin area images as input. A single lesion image is a source of multiple features. Therefore, It is crucial to select the appropriate features from the image of the lesion in order to increase the accuracy of AMDS. For melanoma detection, all extracted features are not important. Some of the extracted features are complex and require more computation tasks, which impacts the classification accuracy of AMDS. The feature extraction phase of AMDS exhibits more variability, therefore it is important to study the behaviour of AMDS using individual and extended feature extraction approaches. A novel algorithm ExtFvAMDS is proposed for the calculation of Extended Feature Vector Space. The six models proposed in the comparative study revealed that the HSV feature vector space for automatic detection of melanoma using Ensemble Bagged Tree classifier on Med-Node Dataset provided 99% AUC, 95.30% accuracy, 94.23% sensitivity, and 96.96% specificity.
PP-StructureV2: A Stronger Document Analysis System
Oct 11, 2022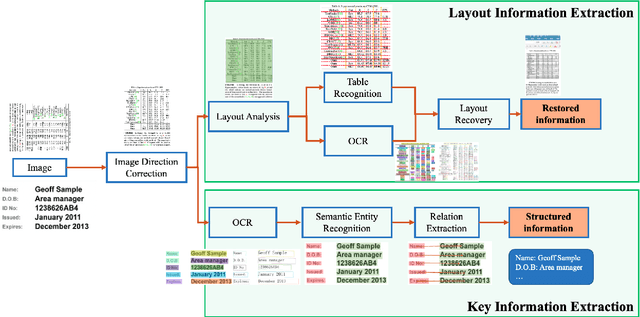



A large amount of document data exists in unstructured form such as raw images without any text information. Designing a practical document image analysis system is a meaningful but challenging task. In previous work, we proposed an intelligent document analysis system PP-Structure. In order to further upgrade the function and performance of PP-Structure, we propose PP-StructureV2 in this work, which contains two subsystems: Layout Information Extraction and Key Information Extraction. Firstly, we integrate Image Direction Correction module and Layout Restoration module to enhance the functionality of the system. Secondly, 8 practical strategies are utilized in PP-StructureV2 for better performance. For Layout Analysis model, we introduce ultra light-weight detector PP-PicoDet and knowledge distillation algorithm FGD for model lightweighting, which increased the inference speed by 11 times with comparable mAP. For Table Recognition model, we utilize PP-LCNet, CSP-PAN and SLAHead to optimize the backbone module, feature fusion module and decoding module, respectively, which improved the table structure accuracy by 6\% with comparable inference speed. For Key Information Extraction model, we introduce VI-LayoutXLM which is a visual-feature independent LayoutXLM architecture, TB-YX sorting algorithm and U-DML knowledge distillation algorithm, which brought 2.8\% and 9.1\% improvement respectively on the Hmean of Semantic Entity Recognition and Relation Extraction tasks. All the above mentioned models and code are open-sourced in the GitHub repository PaddleOCR.
The Devil Is in the Details: Window-based Attention for Image Compression
Mar 16, 2022
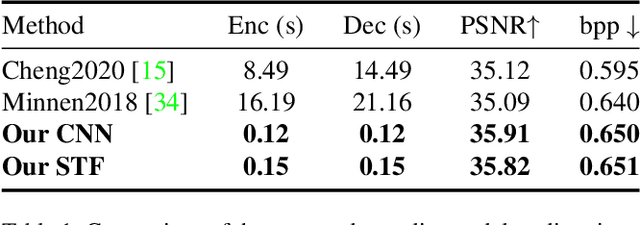
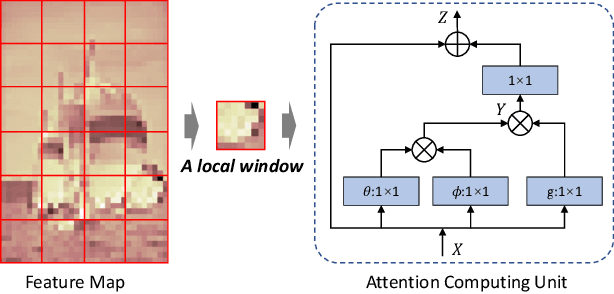
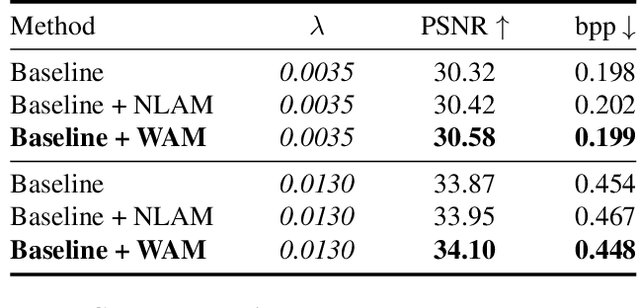
Learned image compression methods have exhibited superior rate-distortion performance than classical image compression standards. Most existing learned image compression models are based on Convolutional Neural Networks (CNNs). Despite great contributions, a main drawback of CNN based model is that its structure is not designed for capturing local redundancy, especially the non-repetitive textures, which severely affects the reconstruction quality. Therefore, how to make full use of both global structure and local texture becomes the core problem for learning-based image compression. Inspired by recent progresses of Vision Transformer (ViT) and Swin Transformer, we found that combining the local-aware attention mechanism with the global-related feature learning could meet the expectation in image compression. In this paper, we first extensively study the effects of multiple kinds of attention mechanisms for local features learning, then introduce a more straightforward yet effective window-based local attention block. The proposed window-based attention is very flexible which could work as a plug-and-play component to enhance CNN and Transformer models. Moreover, we propose a novel Symmetrical TransFormer (STF) framework with absolute transformer blocks in the down-sampling encoder and up-sampling decoder. Extensive experimental evaluations have shown that the proposed method is effective and outperforms the state-of-the-art methods. The code is publicly available at https://github.com/Googolxx/STF.
VLMAE: Vision-Language Masked Autoencoder
Aug 19, 2022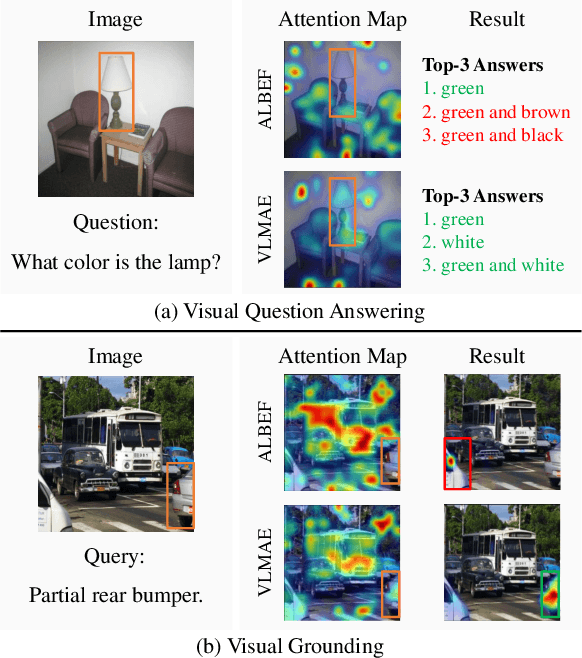
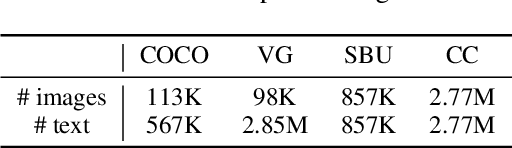
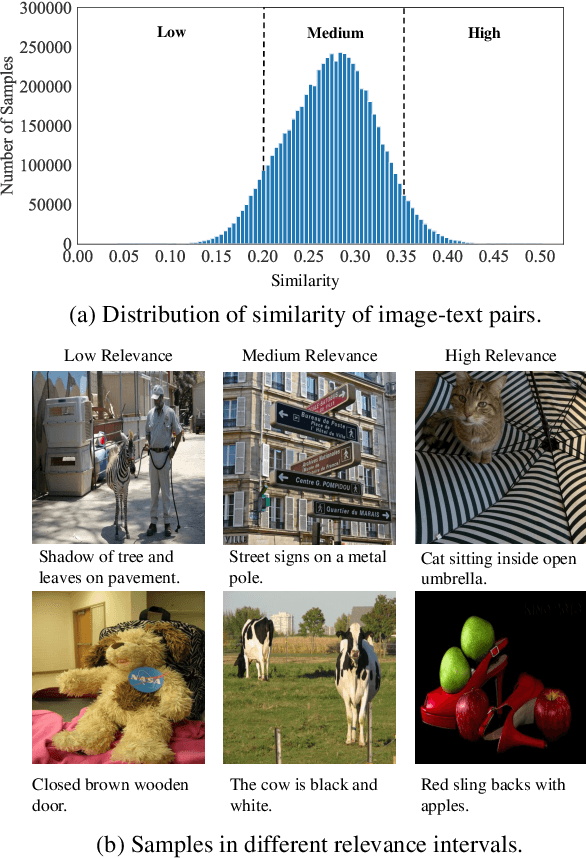
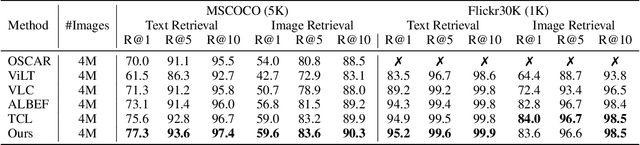
Image and language modeling is of crucial importance for vision-language pre-training (VLP), which aims to learn multi-modal representations from large-scale paired image-text data. However, we observe that most existing VLP methods focus on modeling the interactions between image and text features while neglecting the information disparity between image and text, thus suffering from focal bias. To address this problem, we propose a vision-language masked autoencoder framework (VLMAE). VLMAE employs visual generative learning, facilitating the model to acquire fine-grained and unbiased features. Unlike the previous works, VLMAE pays attention to almost all critical patches in an image, providing more comprehensive understanding. Extensive experiments demonstrate that VLMAE achieves better performance in various vision-language downstream tasks, including visual question answering, image-text retrieval and visual grounding, even with up to 20% pre-training speedup.