 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Probabilistic Deep Image Prior for Computational Tomography
Feb 28, 2022
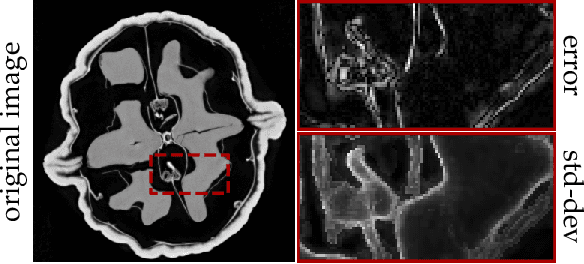
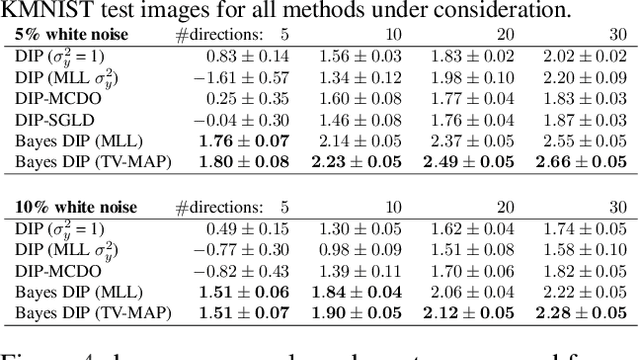

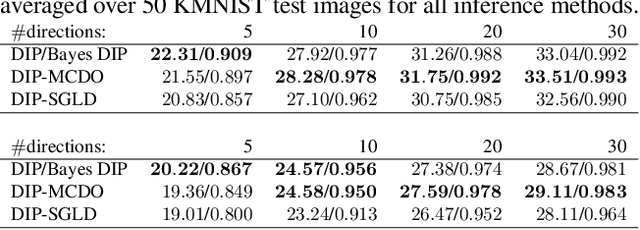
Existing deep-learning based tomographic image reconstruction methods do not provide accurate estimates of reconstruction uncertainty, hindering their real-world deployment. To address this limitation, we construct a Bayesian prior for tomographic reconstruction, which combines the classical total variation (TV) regulariser with the modern deep image prior (DIP). Specifically, we use a change of variables to connect our prior beliefs on the image TV semi-norm with the hyper-parameters of the DIP network. For the inference, we develop an approach based on the linearised Laplace method, which is scalable to high-dimensional settings. The resulting framework provides pixel-wise uncertainty estimates and a marginal likelihood objective for hyperparameter optimisation. We demonstrate the method on synthetic and real-measured high-resolution $\mu$CT data, and show that it provides superior calibration of uncertainty estimates relative to previous probabilistic formulations of the DIP.
Ollivier-Ricci Curvature For Head Pose Estimation From a Single Image
Apr 27, 2022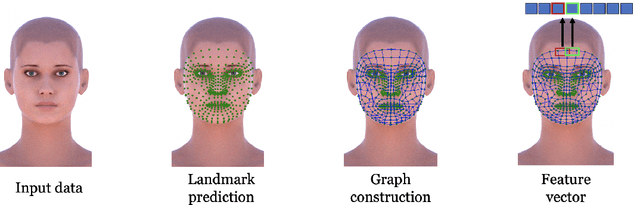
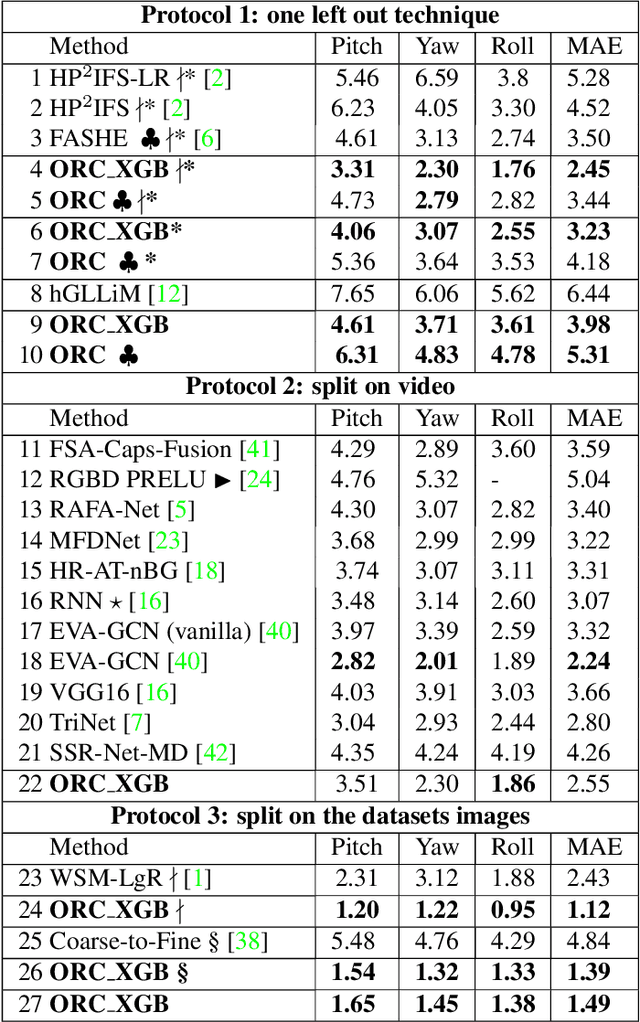
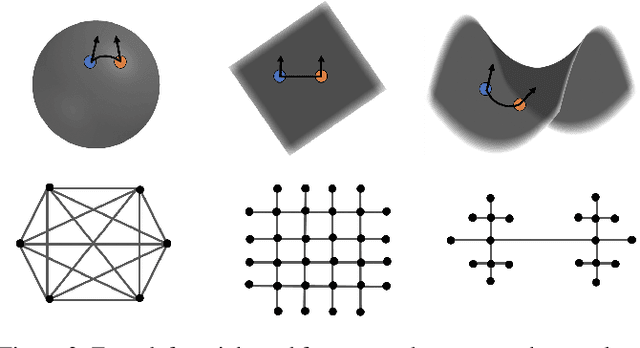
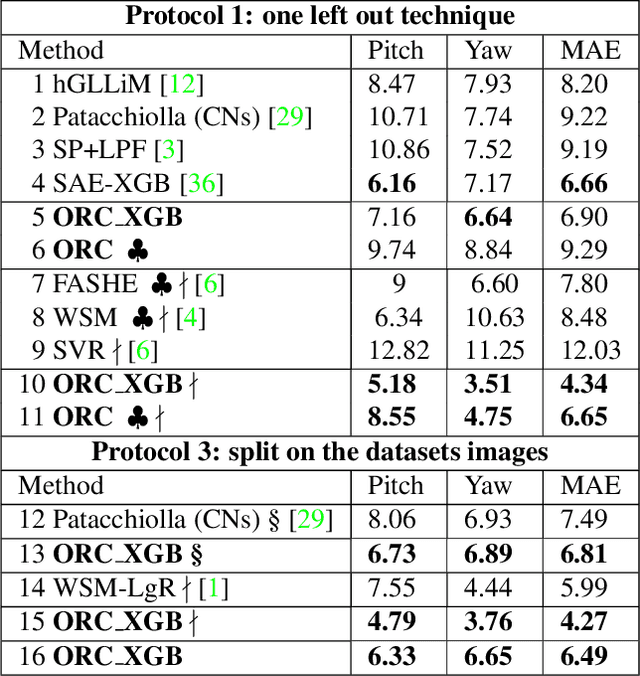
Head pose estimation is a crucial challenge for many real-world applications, such as attention and human behavior analysis. This paper aims to estimate head pose from a single image by applying notions of network curvature. In the real world, many complex networks have groups of nodes that are well connected to each other with significant functional roles. Similarly, the interactions of facial landmarks can be represented as complex dynamic systems modeled by weighted graphs. The functionalities of such systems are therefore intrinsically linked to the topology and geometry of the underlying graph. In this work, using the geometric notion of Ollivier-Ricci curvature (ORC) on weighted graphs as input to the XGBoost regression model, we show that the intrinsic geometric basis of ORC offers a natural approach to discovering underlying common structure within a pool of poses. Experiments on the BIWI, AFLW2000 and Pointing'04 datasets show that the ORC_XGB method performs well compared to state-of-the-art methods, both landmark-based and image-only.
Activating More Pixels in Image Super-Resolution Transformer
May 16, 2022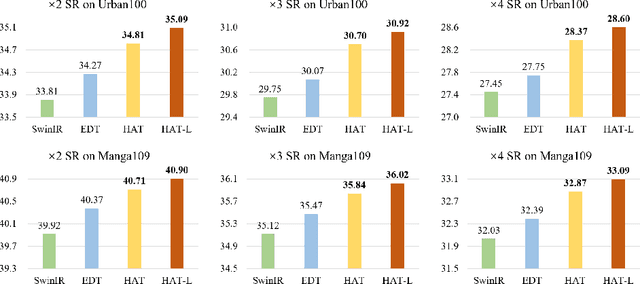

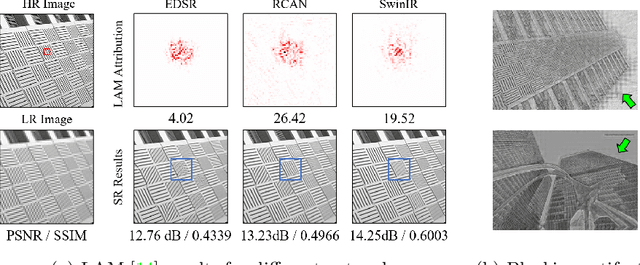

Transformer-based methods have shown impressive performance in low-level vision tasks, such as image super-resolution. However, we find that these networks can only utilize a limited spatial range of input information through attribution analysis. This implies that the potential of Transformer is still not fully exploited in existing networks. In order to activate more input pixels for reconstruction, we propose a novel Hybrid Attention Transformer (HAT). It combines channel attention and self-attention schemes, thus making use of their complementary advantages. Moreover, to better aggregate the cross-window information, we introduce an overlapping cross-attention module to enhance the interaction between neighboring window features. In the training stage, we additionally propose a same-task pre-training strategy to bring further improvement. Extensive experiments show the effectiveness of the proposed modules, and the overall method significantly outperforms the state-of-the-art methods by more than 1dB. Codes and models will be available at https://github.com/chxy95/HAT.
Grassmann Manifold Flow
Nov 05, 2022
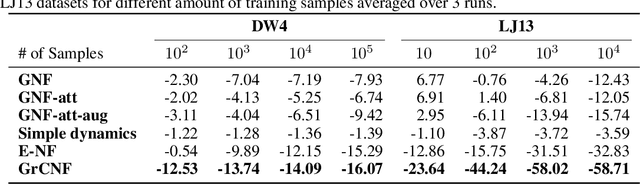
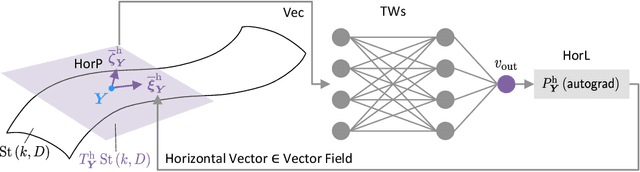
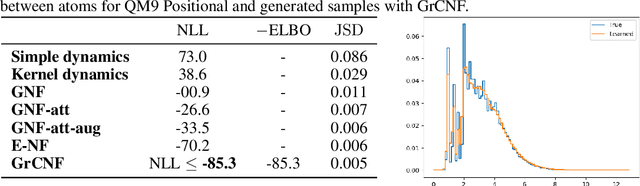
Recently, studies on machine learning have focused on methods that use symmetry implicit in a specific manifold as an inductive bias. In particular, approaches using Grassmann manifolds have been found to exhibit effective performance in fields such as point cloud and image set analysis. However, there is a lack of research on the construction of general learning models to learn distributions on the Grassmann manifold. In this paper, we lay the theoretical foundations for learning distributions on the Grassmann manifold via continuous normalizing flows. Experimental results show that the proposed method can generate high-quality samples by capturing the data structure. Further, the proposed method significantly outperformed state-of-the-art methods in terms of log-likelihood or evidence lower bound. The results obtained are expected to usher in further research in this field of study.
Calibrating Histopathology Image Classifiers using Label Smoothing
Jan 28, 2022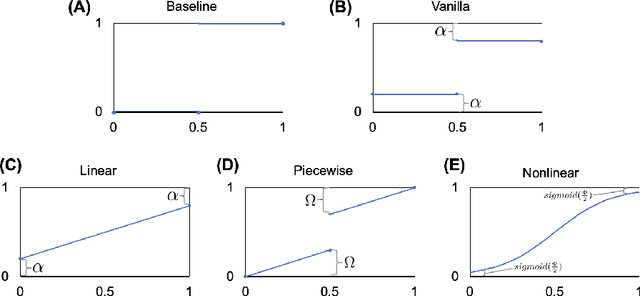
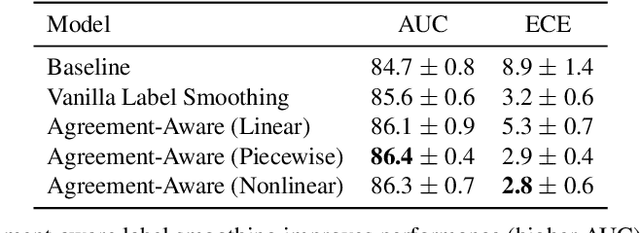
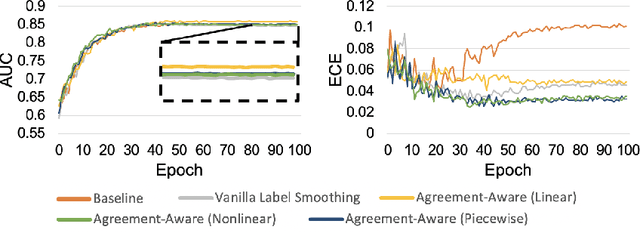

The classification of histopathology images fundamentally differs from traditional image classification tasks because histopathology images naturally exhibit a range of diagnostic features, resulting in a diverse range of annotator agreement levels. However, examples with high annotator disagreement are often either assigned the majority label or discarded entirely when training histopathology image classifiers. This widespread practice often yields classifiers that do not account for example difficulty and exhibit poor model calibration. In this paper, we ask: can we improve model calibration by endowing histopathology image classifiers with inductive biases about example difficulty? We propose several label smoothing methods that utilize per-image annotator agreement. Though our methods are simple, we find that they substantially improve model calibration, while maintaining (or even improving) accuracy. For colorectal polyp classification, a common yet challenging task in gastrointestinal pathology, we find that our proposed agreement-aware label smoothing methods reduce calibration error by almost 70%. Moreover, we find that using model confidence as a proxy for annotator agreement also improves calibration and accuracy, suggesting that datasets without multiple annotators can still benefit from our proposed label smoothing methods via our proposed confidence-aware label smoothing methods. Given the importance of calibration (especially in histopathology image analysis), the improvements from our proposed techniques merit further exploration and potential implementation in other histopathology image classification tasks.
SAC-GAN: Structure-Aware Image-to-Image Composition for Self-Driving
Dec 13, 2021
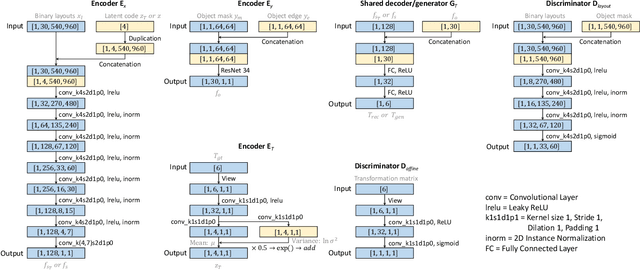
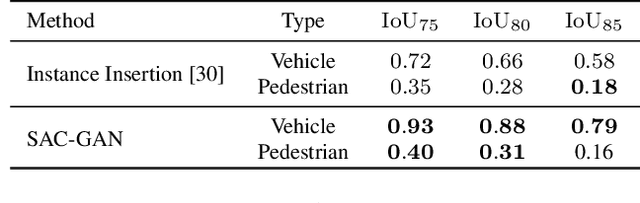

We present a compositional approach to image augmentation for self-driving applications. It is an end-to-end neural network that is trained to seamlessly compose an object (e.g., a vehicle or pedestrian) represented as a cropped patch from an object image, into a background scene image. As our approach emphasizes more on semantic and structural coherence of the composed images, rather than their pixel-level RGB accuracies, we tailor the input and output of our network with structure-aware features and design our network losses accordingly. Specifically, our network takes the semantic layout features from the input scene image, features encoded from the edges and silhouette in the input object patch, as well as a latent code as inputs, and generates a 2D spatial affine transform defining the translation and scaling of the object patch. The learned parameters are further fed into a differentiable spatial transformer network to transform the object patch into the target image, where our model is trained adversarially using an affine transform discriminator and a layout discriminator. We evaluate our network, coined SAC-GAN for structure-aware composition, on prominent self-driving datasets in terms of quality, composability, and generalizability of the composite images. Comparisons are made to state-of-the-art alternatives, confirming superiority of our method.
A Novel Mask R-CNN Model to Segment Heterogeneous Brain Tumors through Image Subtraction
Apr 04, 2022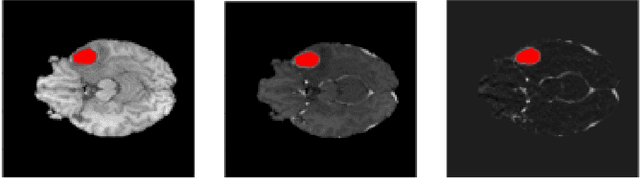
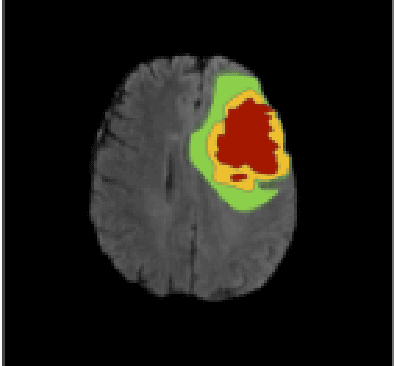

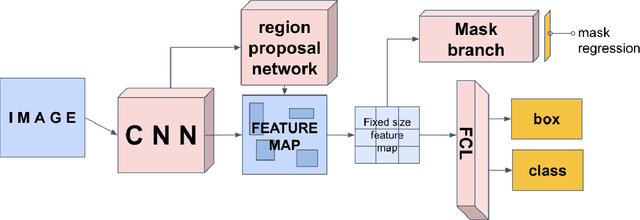
The segmentation of diseases is a popular topic explored by researchers in the field of machine learning. Brain tumors are extremely dangerous and require the utmost precision to segment for a successful surgery. Patients with tumors usually take 4 MRI scans, T1, T1gd, T2, and FLAIR, which are then sent to radiologists to segment and analyze for possible future surgery. To create a second segmentation, it would be beneficial to both radiologists and patients in being more confident in their conclusions. We propose using a method performed by radiologists called image segmentation and applying it to machine learning models to prove a better segmentation. Using Mask R-CNN, its ResNet backbone being pre-trained on the RSNA pneumonia detection challenge dataset, we can train a model on the Brats2020 Brain Tumor dataset. Center for Biomedical Image Computing & Analytics provides MRI data on patients with and without brain tumors and the corresponding segmentations. We can see how well the method of image subtraction works by comparing it to models without image subtraction through DICE coefficient (F1 score), recall, and precision on the untouched test set. Our model performed with a DICE coefficient of 0.75 in comparison to 0.69 without image subtraction. To further emphasize the usefulness of image subtraction, we compare our final model to current state-of-the-art models to segment tumors from MRI scans.
Use Classifier as Generator
Sep 10, 2022



Image recognition/classification is a widely studied problem, but its reverse problem, image generation, has drawn much less attention until recently. But the vast majority of current methods for image generation require training/retraining a classifier and/or a generator with certain constraints, which can be hard to achieve. In this paper, we propose a simple approach to directly use a normally trained classifier to generate images. We evaluate our method on MNIST and show that it produces recognizable results for human eyes with limited quality with experiments.
Translated Skip Connections -- Expanding the Receptive Fields of Fully Convolutional Neural Networks
Nov 03, 2022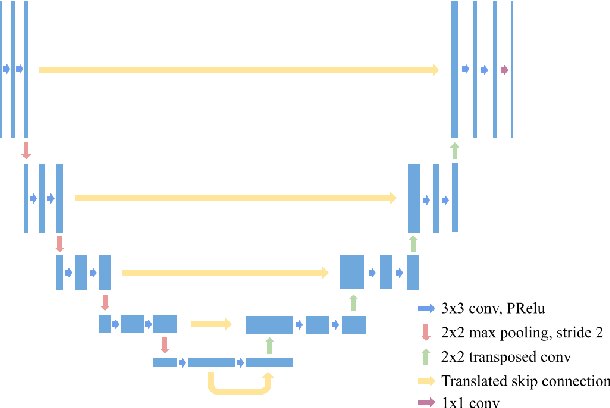
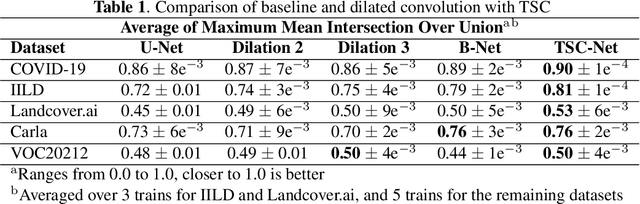
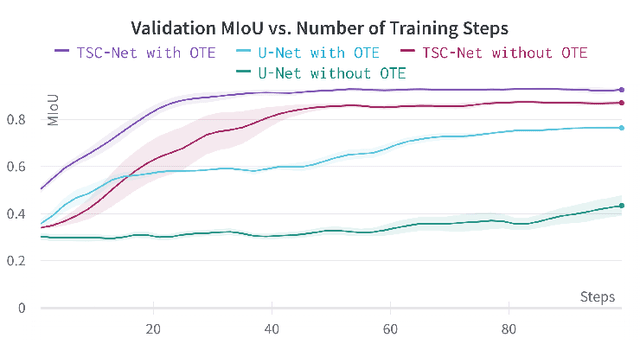
The effective receptive field of a fully convolutional neural network is an important consideration when designing an architecture, as it defines the portion of the input visible to each convolutional kernel. We propose a neural network module, extending traditional skip connections, called the translated skip connection. Translated skip connections geometrically increase the receptive field of an architecture with negligible impact on both the size of the parameter space and computational complexity. By embedding translated skip connections into a benchmark architecture, we demonstrate that our module matches or outperforms four other approaches to expanding the effective receptive fields of fully convolutional neural networks. We confirm this result across five contemporary image segmentation datasets from disparate domains, including the detection of COVID-19 infection, segmentation of aerial imagery, common object segmentation, and segmentation for self-driving cars.
* 5 pages, 2 figures, 1 table, published at the 2022 IEEE International Conference on Image Processing
A Rigorous Study Of The Deep Taylor Decomposition
Nov 14, 2022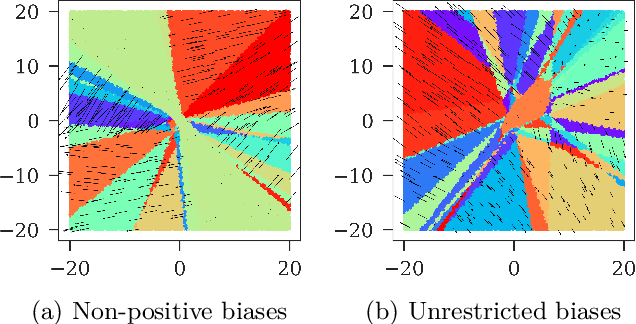


Saliency methods attempt to explain deep neural networks by highlighting the most salient features of a sample. Some widely used methods are based on a theoretical framework called Deep Taylor Decomposition (DTD), which formalizes the recursive application of the Taylor Theorem to the network's layers. However, recent work has found these methods to be independent of the network's deeper layers and appear to respond only to lower-level image structure. Here, we investigate the DTD theory to better understand this perplexing behavior and found that the Deep Taylor Decomposition is equivalent to the basic gradient$\times$input method when the Taylor root points (an important parameter of the algorithm chosen by the user) are locally constant. If the root points are locally input-dependent, then one can justify any explanation. In this case, the theory is under-constrained. In an empirical evaluation, we find that DTD roots do not lie in the same linear regions as the input - contrary to a fundamental assumption of the Taylor theorem. The theoretical foundations of DTD were cited as a source of reliability for the explanations. However, our findings urge caution in making such claims.