 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CustomSketching: Sketch Concept Extraction for Sketch-based Image Synthesis and Editing
Feb 27, 2024
Personalization techniques for large text-to-image (T2I) models allow users to incorporate new concepts from reference images. However, existing methods primarily rely on textual descriptions, leading to limited control over customized images and failing to support fine-grained and local editing (e.g., shape, pose, and details). In this paper, we identify sketches as an intuitive and versatile representation that can facilitate such control, e.g., contour lines capturing shape information and flow lines representing texture. This motivates us to explore a novel task of sketch concept extraction: given one or more sketch-image pairs, we aim to extract a special sketch concept that bridges the correspondence between the images and sketches, thus enabling sketch-based image synthesis and editing at a fine-grained level. To accomplish this, we introduce CustomSketching, a two-stage framework for extracting novel sketch concepts. Considering that an object can often be depicted by a contour for general shapes and additional strokes for internal details, we introduce a dual-sketch representation to reduce the inherent ambiguity in sketch depiction. We employ a shape loss and a regularization loss to balance fidelity and editability during optimization. Through extensive experiments, a user study, and several applications, we show our method is effective and superior to the adapted baselines.
A Modular and Robust Physics-Based Approach for Lensless Image Reconstruction
Mar 01, 2024
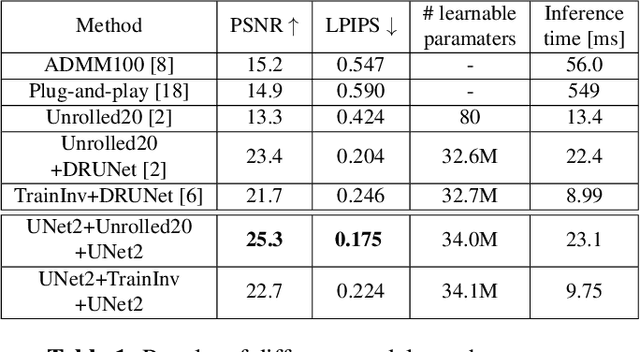
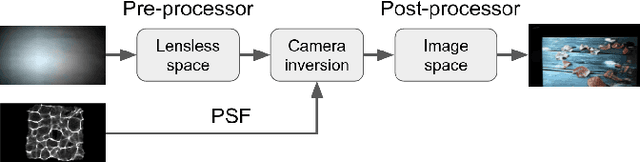
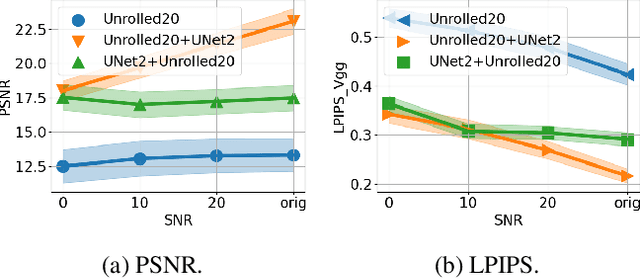
In this paper, we present a modular approach for reconstructing lensless measurements. It consists of three components: a newly-proposed pre-processor, a physics-based camera inverter to undo the multiplexing of lensless imaging, and a post-processor. The pre- and post-processors address noise and artifacts unique to lensless imaging before and after camera inversion respectively. By training the three components end-to-end, we obtain a 1.9 dB increase in PSNR and a 14% relative improvement in a perceptual image metric (LPIPS) with respect to previously proposed physics-based methods. We also demonstrate how the proposed pre-processor provides more robustness to input noise, and how an auxiliary loss can improve interpretability.
A novel image space formalism of Fourier domain interpolation neural networks for noise propagation analysis
Feb 27, 2024Purpose: To develop an image space formalism of multi-layer convolutional neural networks (CNNs) for Fourier domain interpolation in MRI reconstructions and analytically estimate noise propagation during CNN inference. Theory and Methods: Nonlinear activations in the Fourier domain (also known as k-space) using complex-valued Rectifier Linear Units are expressed as elementwise multiplication with activation masks. This operation is transformed into a convolution in the image space. After network training in k-space, this approach provides an algebraic expression for the derivative of the reconstructed image with respect to the aliased coil images, which serve as the input tensors to the network in the image space. This allows the variance in the network inference to be estimated analytically and to be used to describe noise characteristics. Monte-Carlo simulations and numerical approaches based on auto-differentiation were used for validation. The framework was tested on retrospectively undersampled invivo brain images. Results: Inferences conducted in the image domain are quasi-identical to inferences in the k-space, underlined by corresponding quantitative metrics. Noise variance maps obtained from the analytical expression correspond with those obtained via Monte-Carlo simulations, as well as via an auto-differentiation approach. The noise resilience is well characterized, as in the case of classical Parallel Imaging. Komolgorov-Smirnov tests demonstrate Gaussian distributions of voxel magnitudes in variance maps obtained via Monte-Carlo simulations. Conclusion: The quasi-equivalent image space formalism for neural networks for k-space interpolation enables fast and accurate description of the noise characteristics during CNN inference, analogous to geometry-factor maps in traditional parallel imaging methods.
Open-World Semantic Segmentation Including Class Similarity
Mar 12, 2024

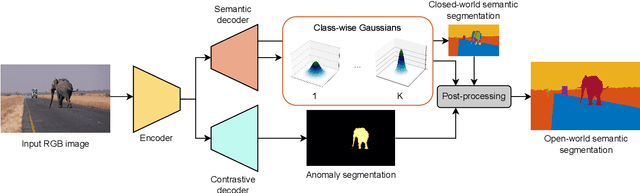
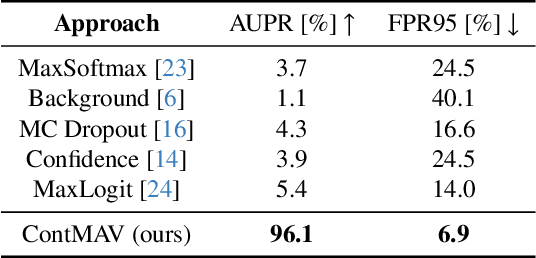
Interpreting camera data is key for autonomously acting systems, such as autonomous vehicles. Vision systems that operate in real-world environments must be able to understand their surroundings and need the ability to deal with novel situations. This paper tackles open-world semantic segmentation, i.e., the variant of interpreting image data in which objects occur that have not been seen during training. We propose a novel approach that performs accurate closed-world semantic segmentation and, at the same time, can identify new categories without requiring any additional training data. Our approach additionally provides a similarity measure for every newly discovered class in an image to a known category, which can be useful information in downstream tasks such as planning or mapping. Through extensive experiments, we show that our model achieves state-of-the-art results on classes known from training data as well as for anomaly segmentation and can distinguish between different unknown classes.
Rule-driven News Captioning
Mar 11, 2024
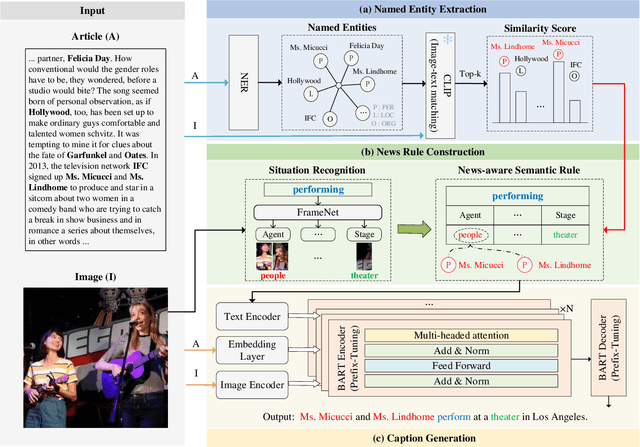
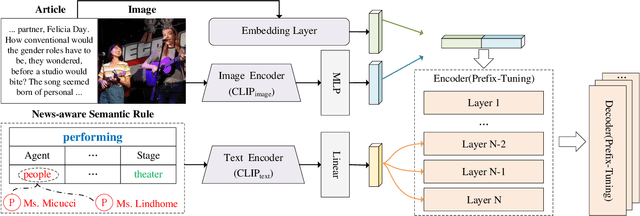
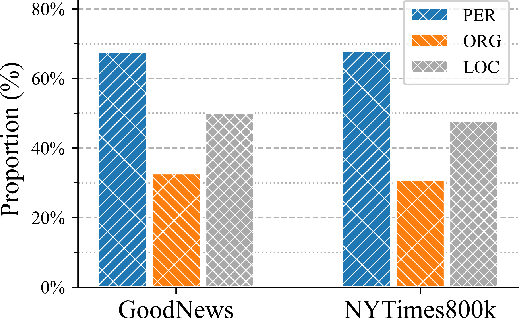
News captioning task aims to generate sentences by describing named entities or concrete events for an image with its news article. Existing methods have achieved remarkable results by relying on the large-scale pre-trained models, which primarily focus on the correlations between the input news content and the output predictions. However, the news captioning requires adhering to some fundamental rules of news reporting, such as accurately describing the individuals and actions associated with the event. In this paper, we propose the rule-driven news captioning method, which can generate image descriptions following designated rule signal. Specifically, we first design the news-aware semantic rule for the descriptions. This rule incorporates the primary action depicted in the image (e.g., "performing") and the roles played by named entities involved in the action (e.g., "Agent" and "Place"). Second, we inject this semantic rule into the large-scale pre-trained model, BART, with the prefix-tuning strategy, where multiple encoder layers are embedded with news-aware semantic rule. Finally, we can effectively guide BART to generate news sentences that comply with the designated rule. Extensive experiments on two widely used datasets (i.e., GoodNews and NYTimes800k) demonstrate the effectiveness of our method.
DAM: Dynamic Adapter Merging for Continual Video QA Learning
Mar 13, 2024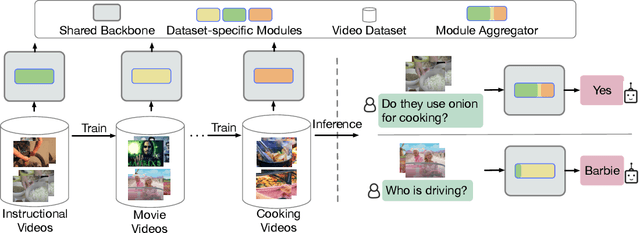
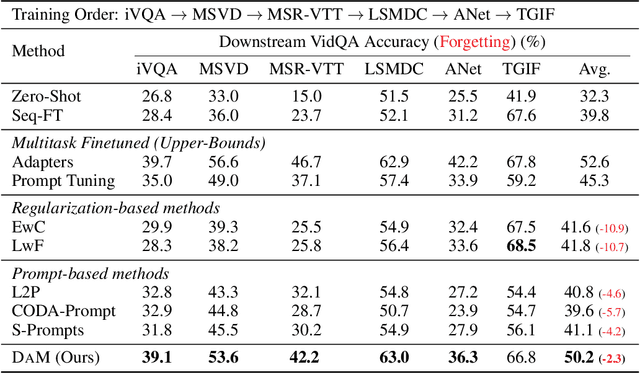
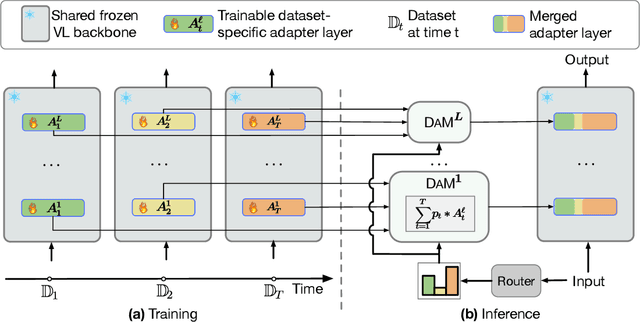

We present a parameter-efficient method for continual video question-answering (VidQA) learning. Our method, named DAM, uses the proposed Dynamic Adapter Merging to (i) mitigate catastrophic forgetting, (ii) enable efficient adaptation to continually arriving datasets, (iii) handle inputs from unknown datasets during inference, and (iv) enable knowledge sharing across similar dataset domains. Given a set of continually streaming VidQA datasets, we sequentially train dataset-specific adapters for each dataset while freezing the parameters of a large pretrained video-language backbone. During inference, given a video-question sample from an unknown domain, our method first uses the proposed non-parametric router function to compute a probability for each adapter, reflecting how relevant that adapter is to the current video-question input instance. Subsequently, the proposed dynamic adapter merging scheme aggregates all the adapter weights into a new adapter instance tailored for that particular test sample to compute the final VidQA prediction, mitigating the impact of inaccurate router predictions and facilitating knowledge sharing across domains. Our DAM model outperforms prior state-of-the-art continual learning approaches by 9.1% while exhibiting 1.9% less forgetting on 6 VidQA datasets spanning various domains. We further extend DAM to continual image classification and image QA and outperform prior methods by a large margin. The code is publicly available at: https://github.com/klauscc/DAM
FocusMAE: Gallbladder Cancer Detection from Ultrasound Videos with Focused Masked Autoencoders
Mar 13, 2024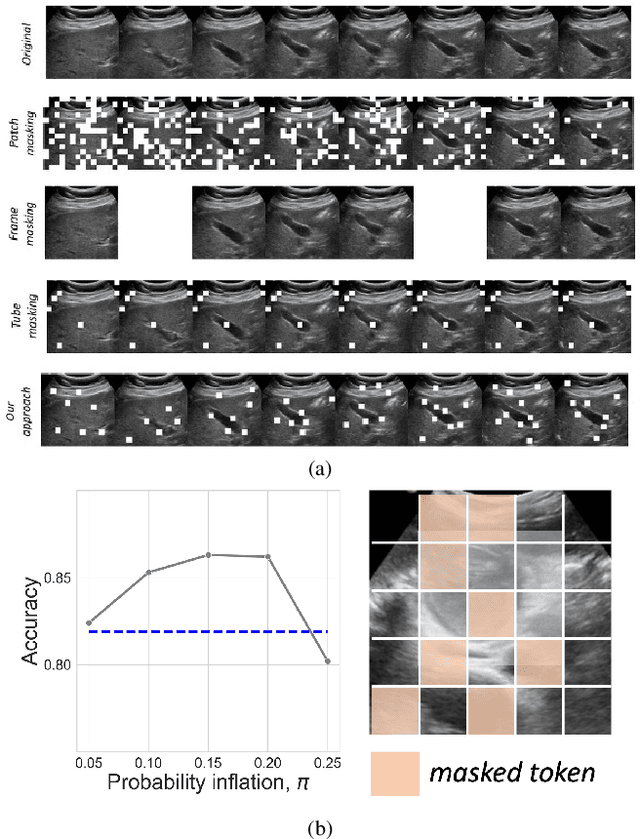
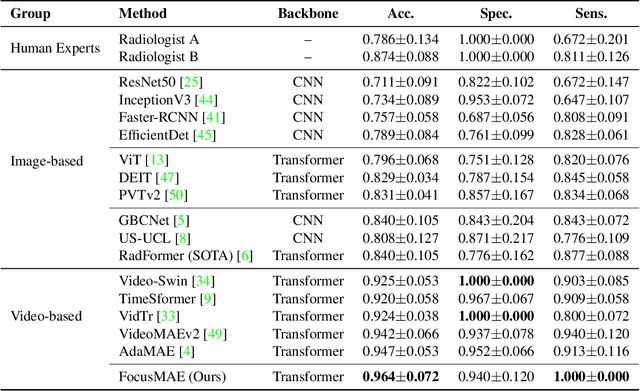
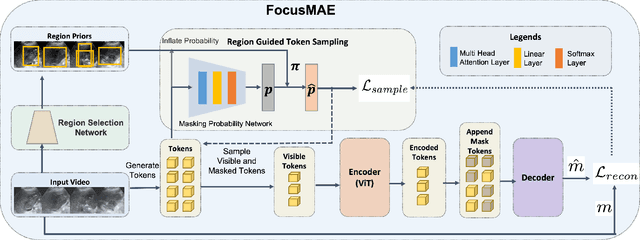
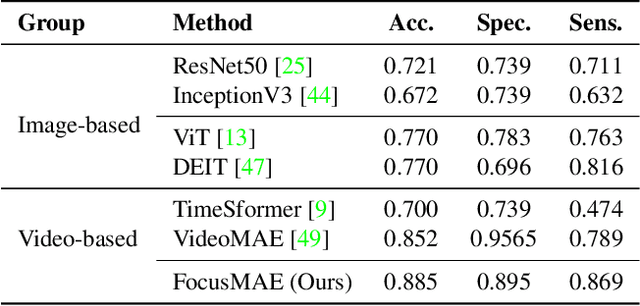
In recent years, automated Gallbladder Cancer (GBC) detection has gained the attention of researchers. Current state-of-the-art (SOTA) methodologies relying on ultrasound sonography (US) images exhibit limited generalization, emphasizing the need for transformative approaches. We observe that individual US frames may lack sufficient information to capture disease manifestation. This study advocates for a paradigm shift towards video-based GBC detection, leveraging the inherent advantages of spatiotemporal representations. Employing the Masked Autoencoder (MAE) for representation learning, we address shortcomings in conventional image-based methods. We propose a novel design called FocusMAE to systematically bias the selection of masking tokens from high-information regions, fostering a more refined representation of malignancy. Additionally, we contribute the most extensive US video dataset for GBC detection. We also note that, this is the first study on US video-based GBC detection. We validate the proposed methods on the curated dataset, and report a new state-of-the-art (SOTA) accuracy of 96.4% for the GBC detection problem, against an accuracy of 84% by current Image-based SOTA - GBCNet, and RadFormer, and 94.7% by Video-based SOTA - AdaMAE. We further demonstrate the generality of the proposed FocusMAE on a public CT-based Covid detection dataset, reporting an improvement in accuracy by 3.3% over current baselines. The source code and pretrained models are available at: https://github.com/sbasu276/FocusMAE.
FSViewFusion: Few-Shots View Generation of Novel Objects
Mar 13, 2024
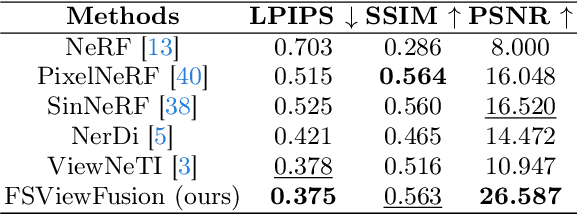
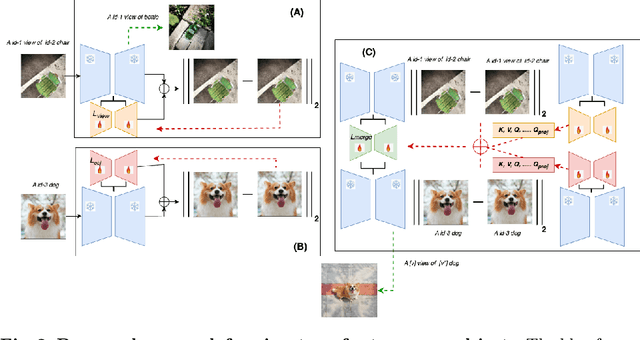

Novel view synthesis has observed tremendous developments since the arrival of NeRFs. However, Nerf models overfit on a single scene, lacking generalization to out of distribution objects. Recently, diffusion models have exhibited remarkable performance on introducing generalization in view synthesis. Inspired by these advancements, we explore the capabilities of a pretrained stable diffusion model for view synthesis without explicit 3D priors. Specifically, we base our method on a personalized text to image model, Dreambooth, given its strong ability to adapt to specific novel objects with a few shots. Our research reveals two interesting findings. First, we observe that Dreambooth can learn the high level concept of a view, compared to arguably more complex strategies which involve finetuning diffusions on large amounts of multi-view data. Second, we establish that the concept of a view can be disentangled and transferred to a novel object irrespective of the original object's identify from which the views are learnt. Motivated by this, we introduce a learning strategy, FSViewFusion, which inherits a specific view through only one image sample of a single scene, and transfers the knowledge to a novel object, learnt from few shots, using low rank adapters. Through extensive experiments we demonstrate that our method, albeit simple, is efficient in generating reliable view samples for in the wild images. Code and models will be released.
HIR-Diff: Unsupervised Hyperspectral Image Restoration Via Improved Diffusion Models
Feb 24, 2024Hyperspectral image (HSI) restoration aims at recovering clean images from degraded observations and plays a vital role in downstream tasks. Existing model-based methods have limitations in accurately modeling the complex image characteristics with handcraft priors, and deep learning-based methods suffer from poor generalization ability. To alleviate these issues, this paper proposes an unsupervised HSI restoration framework with pre-trained diffusion model (HIR-Diff), which restores the clean HSIs from the product of two low-rank components, i.e., the reduced image and the coefficient matrix. Specifically, the reduced image, which has a low spectral dimension, lies in the image field and can be inferred from our improved diffusion model where a new guidance function with total variation (TV) prior is designed to ensure that the reduced image can be well sampled. The coefficient matrix can be effectively pre-estimated based on singular value decomposition (SVD) and rank-revealing QR (RRQR) factorization. Furthermore, a novel exponential noise schedule is proposed to accelerate the restoration process (about 5$\times$ acceleration for denoising) with little performance decrease. Extensive experimental results validate the superiority of our method in both performance and speed on a variety of HSI restoration tasks, including HSI denoising, noisy HSI super-resolution, and noisy HSI inpainting. The code is available at https://github.com/LiPang/HIRDiff.
IRConStyle: Image Restoration Framework Using Contrastive Learning and Style Transfer
Feb 24, 2024Recently, the contrastive learning paradigm has achieved remarkable success in high-level tasks such as classification, detection, and segmentation. However, contrastive learning applied in low-level tasks, like image restoration, is limited, and its effectiveness is uncertain. This raises a question: Why does the contrastive learning paradigm not yield satisfactory results in image restoration? In this paper, we conduct in-depth analyses and propose three guidelines to address the above question. In addition, inspired by style transfer and based on contrastive learning, we propose a novel module for image restoration called \textbf{ConStyle}, which can be efficiently integrated into any U-Net structure network. By leveraging the flexibility of ConStyle, we develop a \textbf{general restoration network} for image restoration. ConStyle and the general restoration network together form an image restoration framework, namely \textbf{IRConStyle}. To demonstrate the capability and compatibility of ConStyle, we replace the general restoration network with transformer-based, CNN-based, and MLP-based networks, respectively. We perform extensive experiments on various image restoration tasks, including denoising, deblurring, deraining, and dehazing. The results on 19 benchmarks demonstrate that ConStyle can be integrated with any U-Net-based network and significantly enhance performance. For instance, ConStyle NAFNet significantly outperforms the original NAFNet on SOTS outdoor (dehazing) and Rain100H (deraining) datasets, with PSNR improvements of 4.16 dB and 3.58 dB with 85% fewer parameters.