 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to screen Glaucoma like the ophthalmologists
Sep 23, 2022
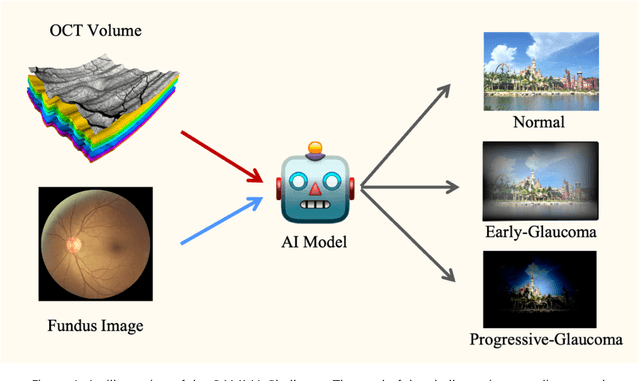
GAMMA Challenge is organized to encourage the AI models to screen the glaucoma from a combination of 2D fundus image and 3D optical coherence tomography volume, like the ophthalmologists.
One-Shot Transfer of Affordance Regions? AffCorrs!
Sep 16, 2022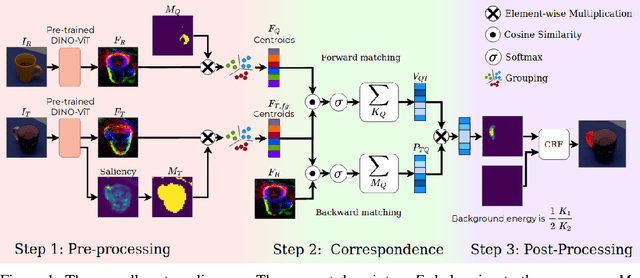
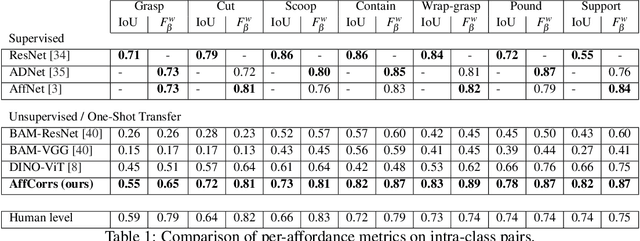


In this work, we tackle one-shot visual search of object parts. Given a single reference image of an object with annotated affordance regions, we segment semantically corresponding parts within a target scene. We propose AffCorrs, an unsupervised model that combines the properties of pre-trained DINO-ViT's image descriptors and cyclic correspondences. We use AffCorrs to find corresponding affordances both for intra- and inter-class one-shot part segmentation. This task is more difficult than supervised alternatives, but enables future work such as learning affordances via imitation and assisted teleoperation.
Graph Flow: Cross-layer Graph Flow Distillation for Dual Efficient Medical Image Segmentation
Mar 29, 2022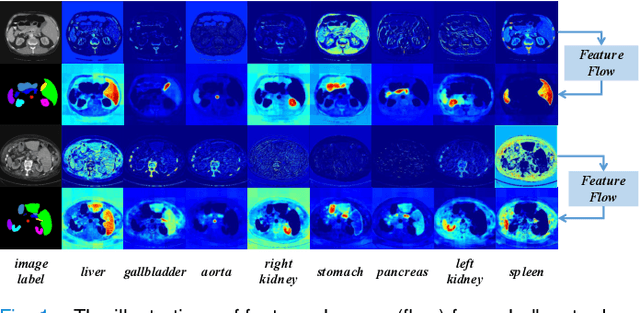
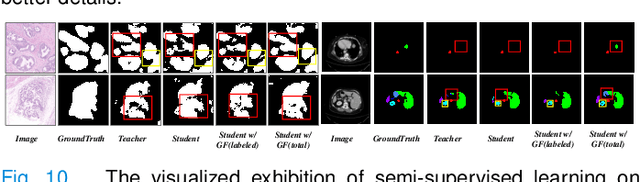
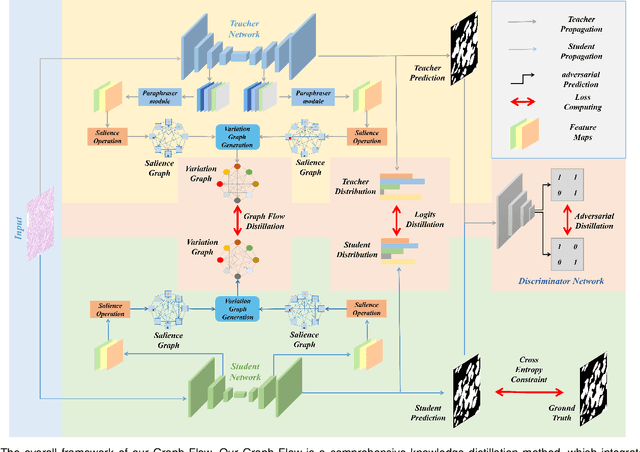
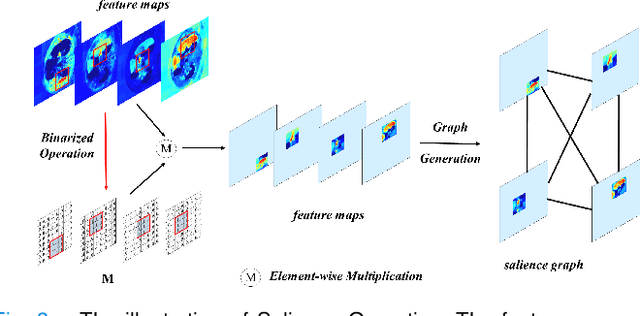
With the development of deep convolutional neural networks, medical image segmentation has achieved a series of breakthroughs in recent years. However, the higher-performance convolutional neural networks always mean numerous parameters and high computation costs, which will hinder the applications in clinical scenarios. Meanwhile, the scarceness of large-scale annotated medical image datasets further impedes the application of high-performance networks. To tackle these problems, we propose Graph Flow, a comprehensive knowledge distillation framework, for both network-efficiency and annotation-efficiency medical image segmentation. Specifically, our core Graph Flow Distillation transfer the essence of cross-layer variations from a well-trained cumbersome teacher network to a non-trained compact student network. In addition, an unsupervised Paraphraser Module is designed to purify the knowledge of the teacher network, which is also beneficial for the stabilization of training procedure. Furthermore, we build a unified distillation framework by integrating the adversarial distillation and the vanilla logits distillation, which can further refine the final predictions of the compact network. Extensive experiments conducted on Gastric Cancer Segmentation Dataset and Synapse Multi-organ Segmentation Dataset demonstrate the prominent ability of our method which achieves state-of-the-art performance on these different-modality and multi-category medical image datasets. Moreover, we demonstrate the effectiveness of our Graph Flow through a new semi-supervised paradigm for dual efficient medical image segmentation. Our code will be available at Graph Flow.
A comprehensive benchmark analysis for sand dust image reconstruction
Feb 07, 2022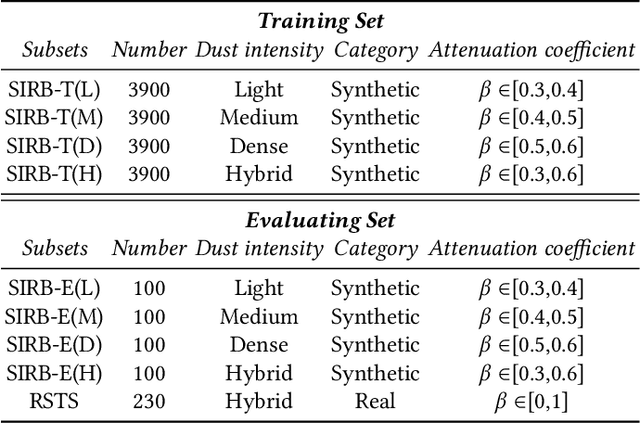
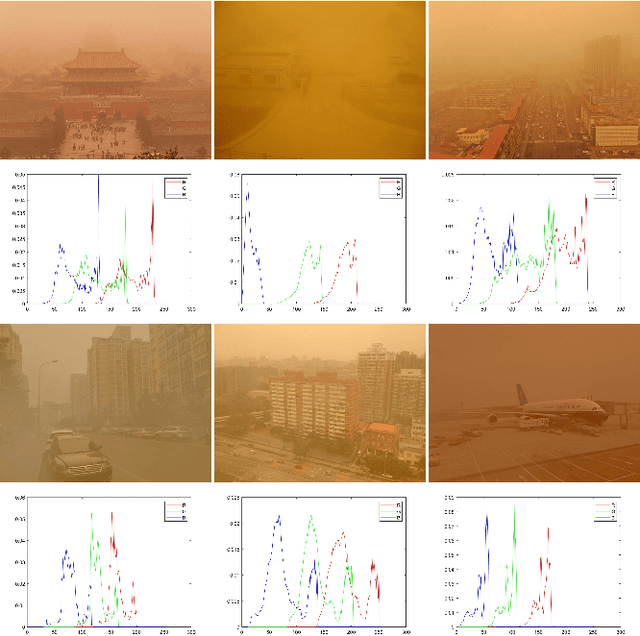
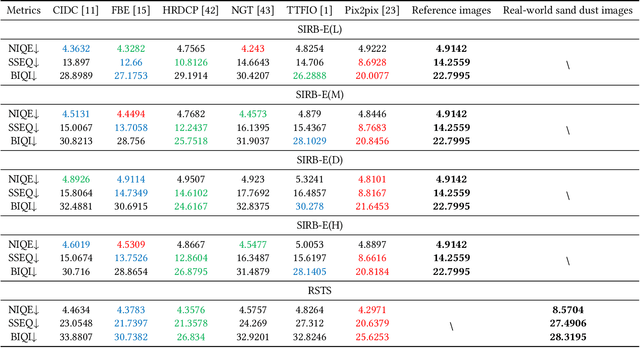
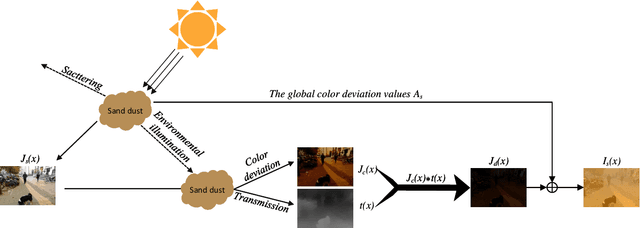
Numerous sand dust image enhancement algorithms have been proposed in recent years. To our best acknowledge, however, most methods evaluated their performance with no-reference way using few selected real-world images from internet. It is unclear how to quantitatively analysis the performance of the algorithms in a supervised way and how we could gauge the progress in the field. Moreover, due to the absence of large-scale benchmark datasets, there are no well-known reports of data-driven based method for sand dust image enhancement up till now. To advance the development of deep learning-based algorithms for sand dust image reconstruction, while enabling supervised objective evaluation of algorithm performance. In this paper, we presented a comprehensive perceptual study and analysis of real-world sand dust images, then constructed a Sand-dust Image Reconstruction Benchmark (SIRB) for training Convolutional Neural Networks (CNNs) and evaluating algorithms performance. In addition, we adopted the existing image transformation neural network trained on SIRB as baseline to illustrate the generalization of SIRB for training CNNs. Finally, we conducted the qualitative and quantitative evaluation to demonstrate the performance and limitations of the state-of-the-arts (SOTA), which shed light on future research in sand dust image reconstruction.
What to Hide from Your Students: Attention-Guided Masked Image Modeling
Mar 23, 2022
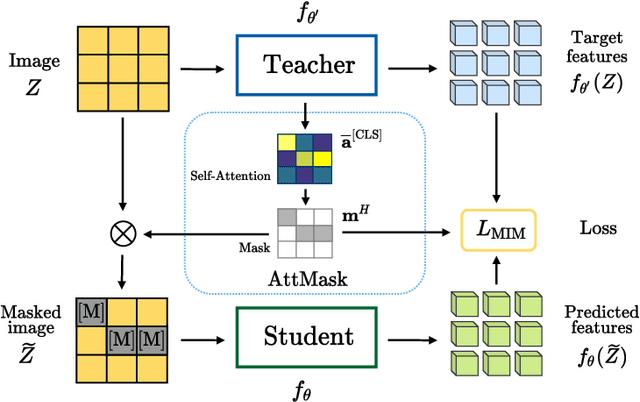
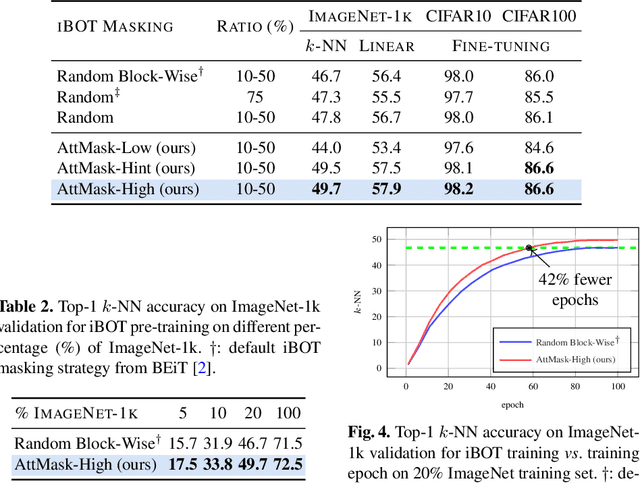
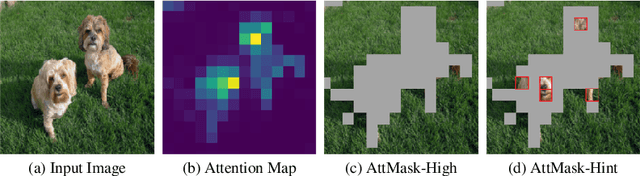
Transformers and masked language modeling are quickly being adopted and explored in computer vision as vision transformers and masked image modeling (MIM). In this work, we argue that image token masking is fundamentally different from token masking in text, due to the amount and correlation of tokens in an image. In particular, to generate a challenging pretext task for MIM, we advocate a shift from random masking to informed masking. We develop and exhibit this idea in the context of distillation-based MIM, where a teacher transformer encoder generates an attention map, which we use to guide masking for the student encoder. We thus introduce a novel masking strategy, called attention-guided masking (AttMask), and we demonstrate its effectiveness over random masking for dense distillation-based MIM as well as plain distillation-based self-supervised learning on classification tokens. We confirm that AttMask accelerates the learning process and improves the performance on a variety of downstream tasks.
Deep Appearance Prefiltering
Nov 08, 2022


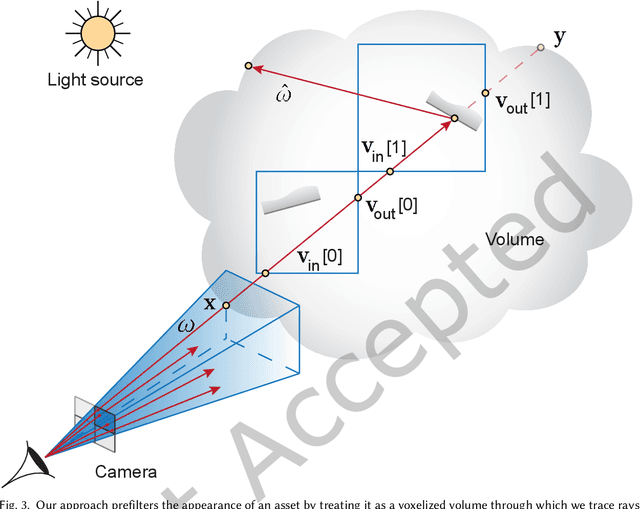
Physically based rendering of complex scenes can be prohibitively costly with a potentially unbounded and uneven distribution of complexity across the rendered image. The goal of an ideal level of detail (LoD) method is to make rendering costs independent of the 3D scene complexity, while preserving the appearance of the scene. However, current prefiltering LoD methods are limited in the appearances they can support due to their reliance of approximate models and other heuristics. We propose the first comprehensive multi-scale LoD framework for prefiltering 3D environments with complex geometry and materials (e.g., the Disney BRDF), while maintaining the appearance with respect to the ray-traced reference. Using a multi-scale hierarchy of the scene, we perform a data-driven prefiltering step to obtain an appearance phase function and directional coverage mask at each scale. At the heart of our approach is a novel neural representation that encodes this information into a compact latent form that is easy to decode inside a physically based renderer. Once a scene is baked out, our method requires no original geometry, materials, or textures at render time. We demonstrate that our approach compares favorably to state-of-the-art prefiltering methods and achieves considerable savings in memory for complex scenes.
RegionCLIP: Region-based Language-Image Pretraining
Dec 16, 2021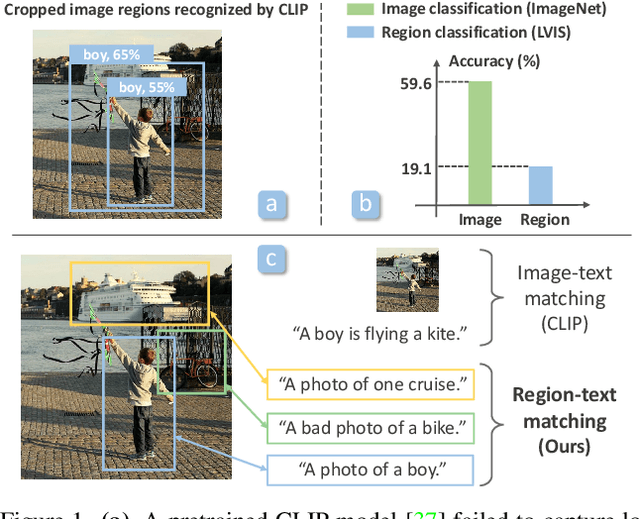
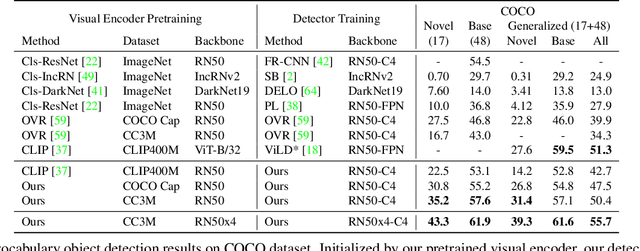
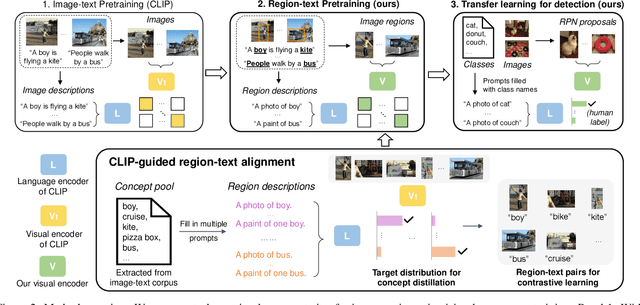
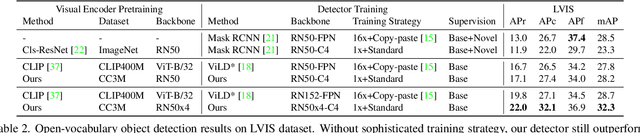
Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, we show that directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, we propose a new method called RegionCLIP that significantly extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. Our method leverages a CLIP model to match image regions with template captions and then pretrains our model to align these region-text pairs in the feature space. When transferring our pretrained model to the open-vocabulary object detection tasks, our method significantly outperforms the state of the art by 3.8 AP50 and 2.2 AP for novel categories on COCO and LVIS datasets, respectively. Moreoever, the learned region representations support zero-shot inference for object detection, showing promising results on both COCO and LVIS datasets. Our code is available at https://github.com/microsoft/RegionCLIP.
Text2Model: Model Induction for Zero-shot Generalization Using Task Descriptions
Oct 27, 2022
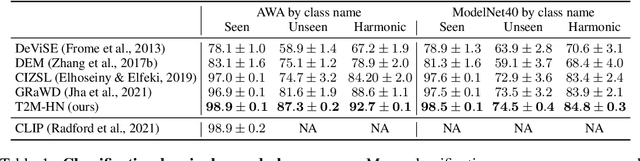
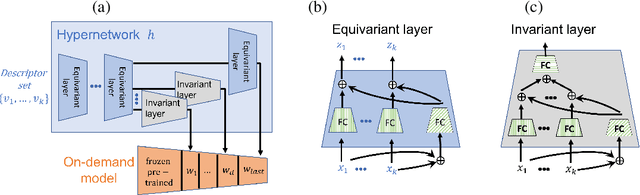
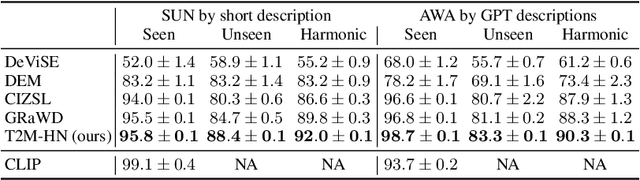
We study the problem of generating a training-free task-dependent visual classifier from text descriptions without visual samples. This \textit{Text-to-Model} (T2M) problem is closely related to zero-shot learning, but unlike previous work, a T2M model infers a model tailored to a task, taking into account all classes in the task. We analyze the symmetries of T2M, and characterize the equivariance and invariance properties of corresponding models. In light of these properties, we design an architecture based on hypernetworks that given a set of new class descriptions predicts the weights for an object recognition model which classifies images from those zero-shot classes. We demonstrate the benefits of our approach compared to zero-shot learning from text descriptions in image and point-cloud classification using various types of text descriptions: From single words to rich text descriptions.
Search for Concepts: Discovering Visual Concepts Using Direct Optimization
Oct 25, 2022

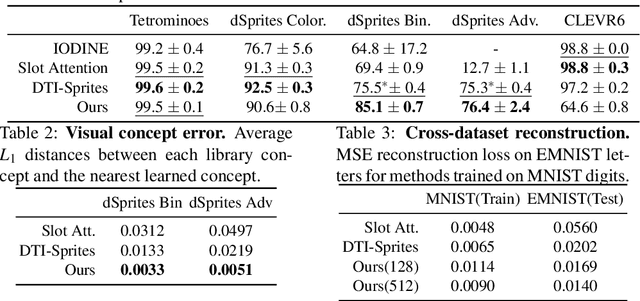
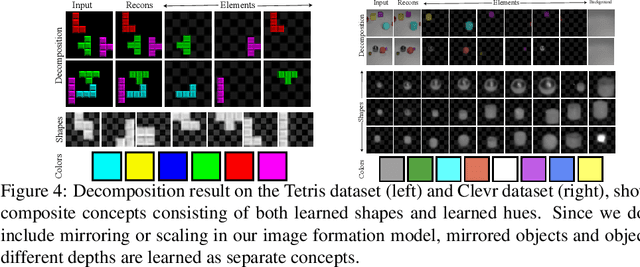
Finding an unsupervised decomposition of an image into individual objects is a key step to leverage compositionality and to perform symbolic reasoning. Traditionally, this problem is solved using amortized inference, which does not generalize beyond the scope of the training data, may sometimes miss correct decompositions, and requires large amounts of training data. We propose finding a decomposition using direct, unamortized optimization, via a combination of a gradient-based optimization for differentiable object properties and global search for non-differentiable properties. We show that using direct optimization is more generalizable, misses fewer correct decompositions, and typically requires less data than methods based on amortized inference. This highlights a weakness of the current prevalent practice of using amortized inference that can potentially be improved by integrating more direct optimization elements.
Object recognition in atmospheric turbulence scenes
Oct 25, 2022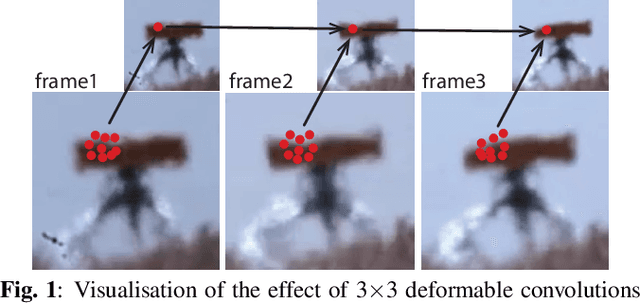
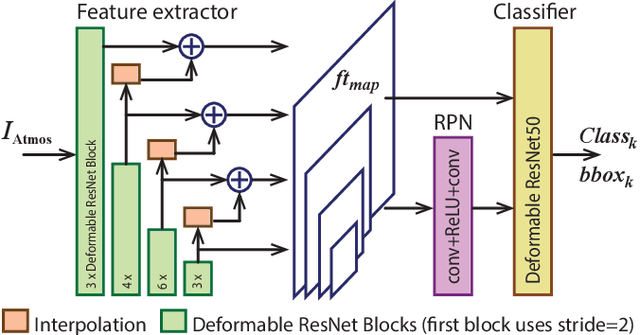
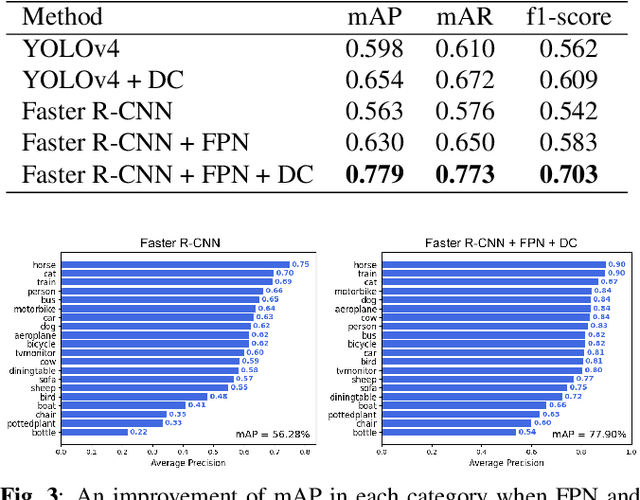

The influence of atmospheric turbulence on acquired surveillance imagery makes image interpretation and scene analysis extremely difficult. It also reduces the effectiveness of conventional approaches for classifying, and tracking targets in the scene. Whilst deep-learning based object detection is highly successful in normal conditions, these methods cannot directly be applied to the atmospheric turbulence sequences. This paper hence proposes a novel framework learning the distorted features to detect and classify object types. Specifically, deformable convolutions are exploited to deal with spatial turbulent displacement. The features are extracted via a feature pyramid network and Faster R-CNN is employed as a detector. Testing with synthetic VOC dataset, the results show that the proposed framework outperforms the benchmark with mean Average Precision (mAP) score of >30%. Subjective results on the real data are also significantly improved.