 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Augmentation for Satellite Images
Jul 29, 2022
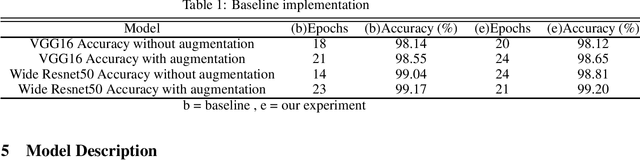
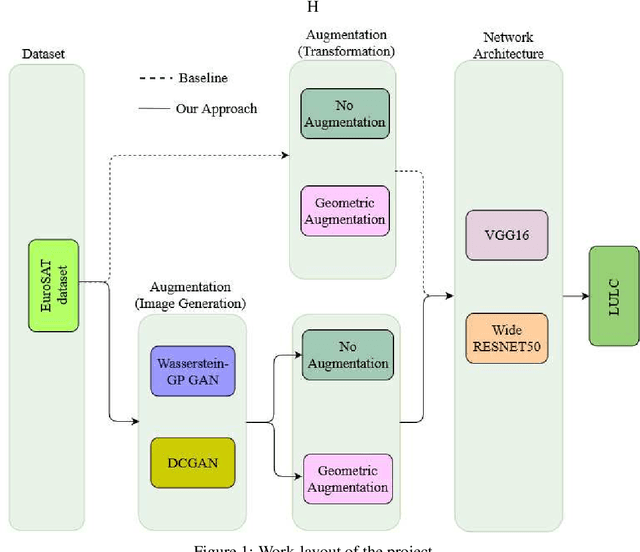
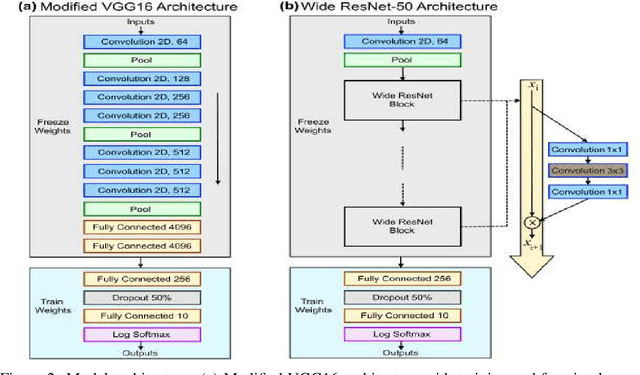
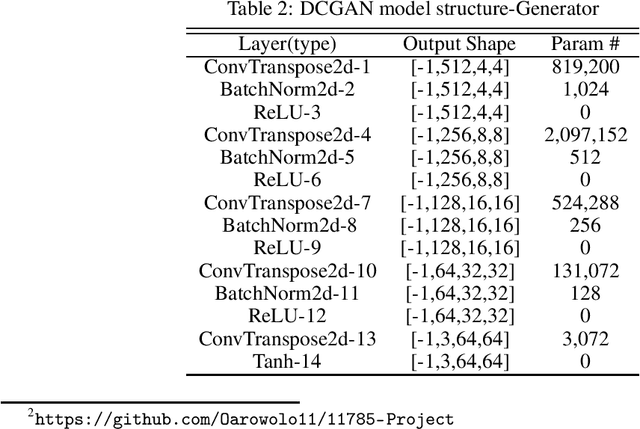
This study proposes the use of generative models (GANs) for augmenting the EuroSAT dataset for the Land Use and Land Cover (LULC) Classification task. We used DCGAN and WGAN-GP to generate images for each class in the dataset. We then explored the effect of augmenting the original dataset by about 10% in each case on model performance. The choice of GAN architecture seems to have no apparent effect on the model performance. However, a combination of geometric augmentation and GAN-generated images improved baseline results. Our study shows that GANs augmentation can improve the generalizability of deep classification models on satellite images.
Single-image Defocus Deblurring by Integration of Defocus Map Prediction Tracing the Inverse Problem Computation
Jul 07, 2022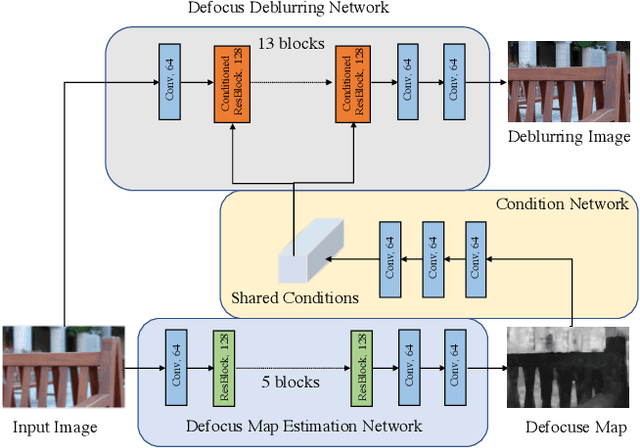
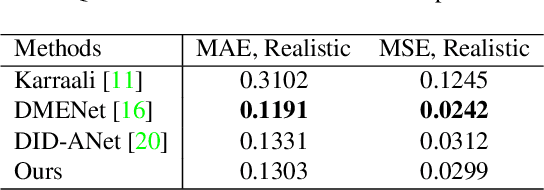
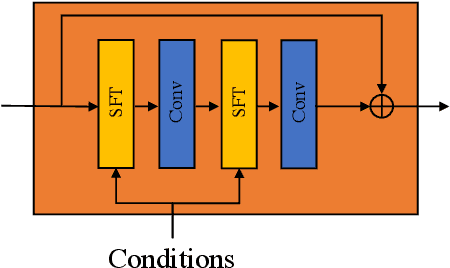
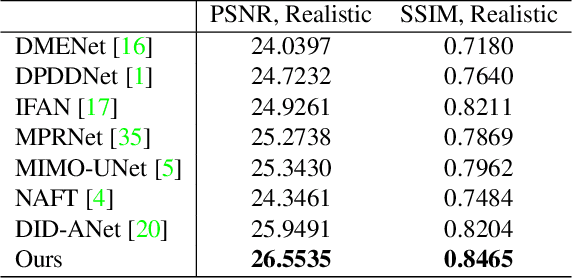
In this paper, we consider the problem in defocus image deblurring. Previous classical methods follow two-steps approaches, i.e., first defocus map estimation and then the non-blind deblurring. In the era of deep learning, some researchers have tried to address these two problems by CNN. However, the simple concatenation of defocus map, which represents the blur level, leads to suboptimal performance. Considering the spatial variant property of the defocus blur and the blur level indicated in the defocus map, we employ the defocus map as conditional guidance to adjust the features from the input blurring images instead of simple concatenation. Then we propose a simple but effective network with spatial modulation based on the defocus map. To achieve this, we design a network consisting of three sub-networks, including the defocus map estimation network, a condition network that encodes the defocus map into condition features, and the defocus deblurring network that performs spatially dynamic modulation based on the condition features. Moreover, the spatially dynamic modulation is based on an affine transform function to adjust the features from the input blurry images. Experimental results show that our method can achieve better quantitative and qualitative evaluation performance than the existing state-of-the-art methods on the commonly used public test datasets.
I see what you hear: a vision-inspired method to localize words
Oct 24, 2022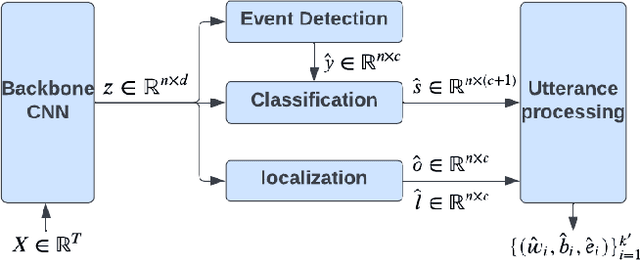
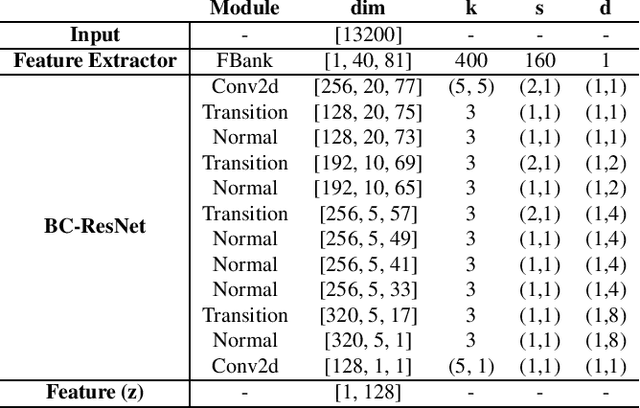
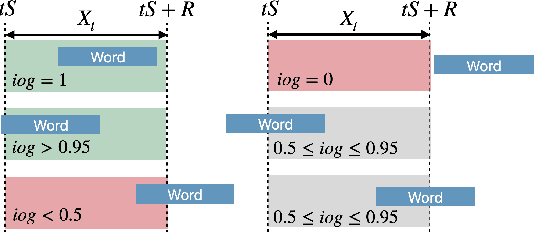

This paper explores the possibility of using visual object detection techniques for word localization in speech data. Object detection has been thoroughly studied in the contemporary literature for visual data. Noting that an audio can be interpreted as a 1-dimensional image, object localization techniques can be fundamentally useful for word localization. Building upon this idea, we propose a lightweight solution for word detection and localization. We use bounding box regression for word localization, which enables our model to detect the occurrence, offset, and duration of keywords in a given audio stream. We experiment with LibriSpeech and train a model to localize 1000 words. Compared to existing work, our method reduces model size by 94%, and improves the F1 score by 6.5\%.
MARSIM: A light-weight point-realistic simulator for LiDAR-based UAVs
Nov 19, 2022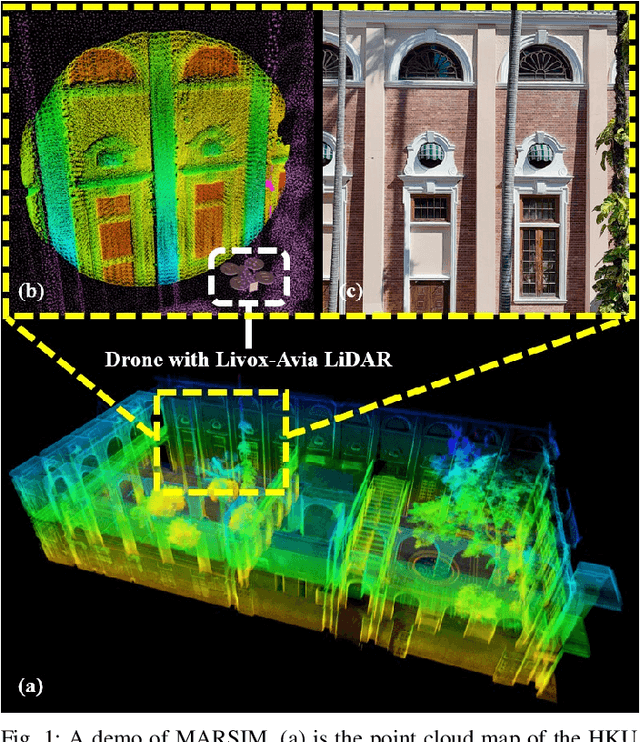
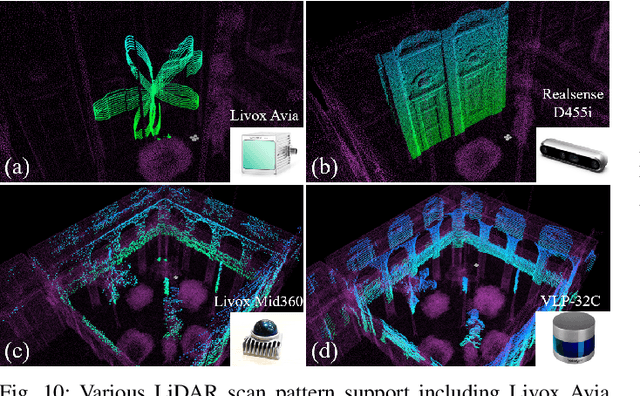
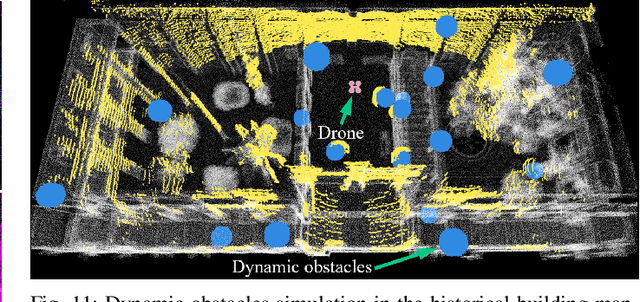
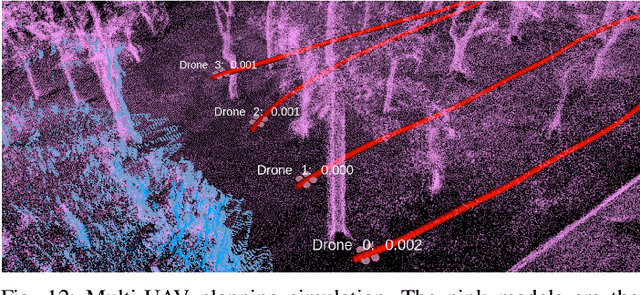
The emergence of low-cost, small form factor and light-weight solid-state LiDAR sensors have brought new opportunities for autonomous unmanned aerial vehicles (UAVs) by advancing navigation safety and computation efficiency. Yet the successful developments of LiDAR-based UAVs must rely on extensive simulations. Existing simulators can hardly perform simulations of real-world environments due to the requirements of dense mesh maps that are difficult to obtain. In this paper, we develop a point-realistic simulator of real-world scenes for LiDAR-based UAVs. The key idea is the underlying point rendering method, where we construct a depth image directly from the point cloud map and interpolate it to obtain realistic LiDAR point measurements. Our developed simulator is able to run on a light-weight computing platform and supports the simulation of LiDARs with different resolution and scanning patterns, dynamic obstacles, and multi-UAV systems. Developed in the ROS framework, the simulator can easily communicate with other key modules of an autonomous robot, such as perception, state estimation, planning, and control. Finally, the simulator provides 10 high-resolution point cloud maps of various real-world environments, including forests of different densities, historic building, office, parking garage, and various complex indoor environments. These realistic maps provide diverse testing scenarios for an autonomous UAV. Evaluation results show that the developed simulator achieves superior performance in terms of time and memory consumption against Gazebo and that the simulated UAV flights highly match the actual one in real-world environments. We believe such a point-realistic and light-weight simulator is crucial to bridge the gap between UAV simulation and experiments and will significantly facilitate the research of LiDAR-based autonomous UAVs in the future.
Audio Time-Scale Modification with Temporal Compressing Networks
Oct 31, 2022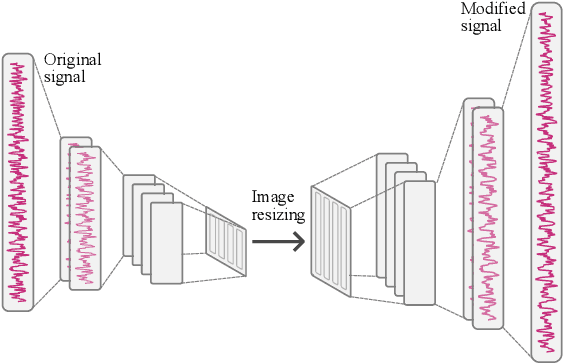
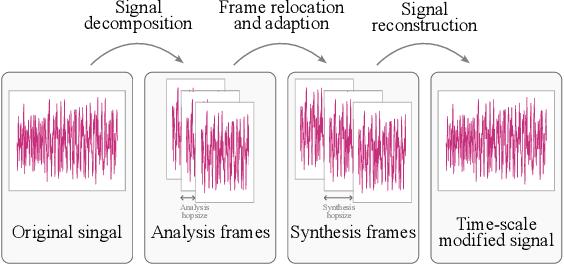
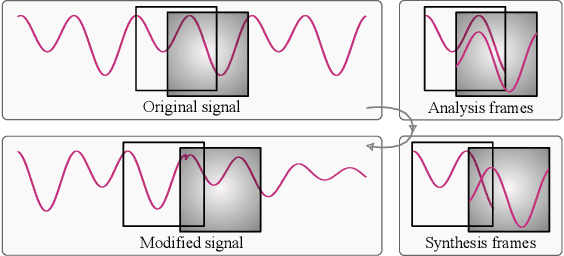
We proposed a novel approach in the field of time-scale modification on audio signals. While traditional methods use the framing technique, spectral approach uses the short-time Fourier transform to preserve the frequency during temporal stretching. TSM-Net, our neural-network model encodes the raw audio into a high-level latent representation. We call it Neuralgram, in which one vector represents 1024 audio samples. It is inspired by the framing technique but addresses the clipping artifacts. The Neuralgram is a two-dimensional matrix with real values, we can apply some existing image resizing techniques on the Neuralgram and decode it using our neural decoder to obtain the time-scaled audio. Both the encoder and decoder are trained with GANs, which shows fair generalization ability on the scaled Neuralgrams. Our method yields little artifacts and opens a new possibility in the research of modern time-scale modification. The audio samples can be found on https://ernestchu.github.io/tsm-net-demo/
ShapeNet: Shape Constraint for Galaxy Image Deconvolution
Mar 14, 2022

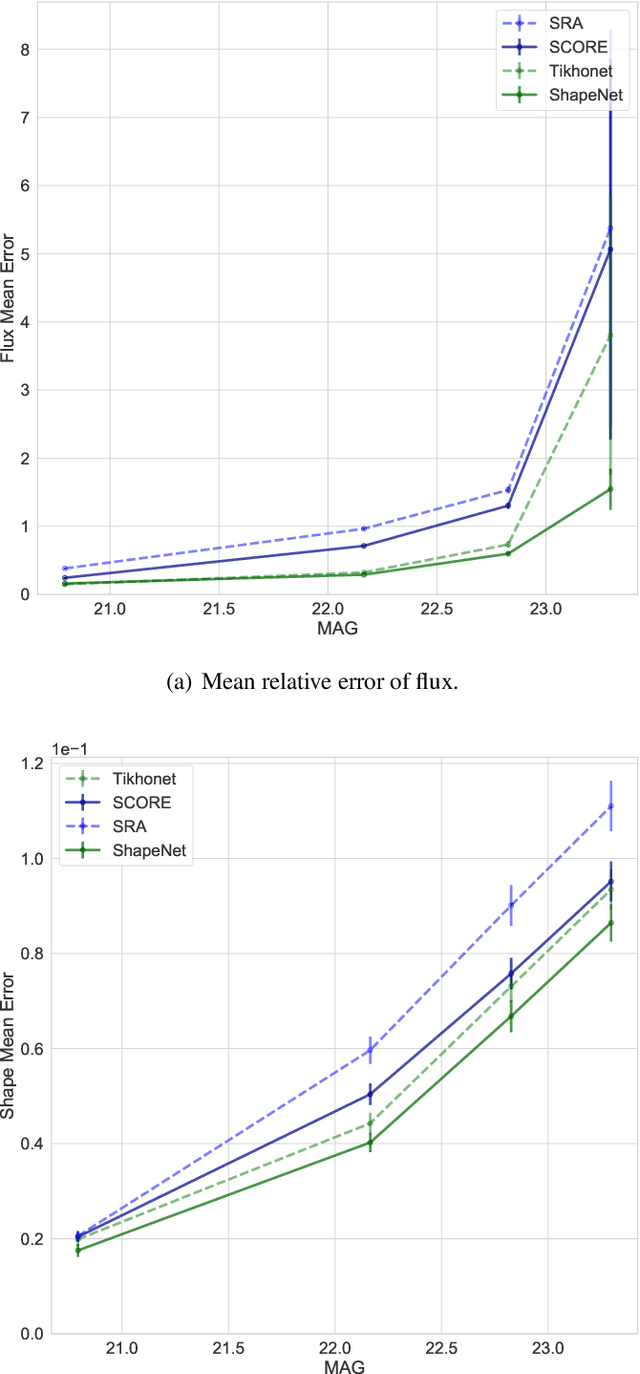
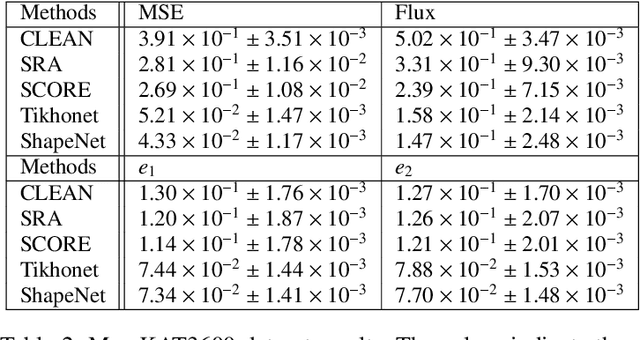
Deep Learning (DL) has shown remarkable results in solving inverse problems in various domains. In particular, the Tikhonet approach is very powerful to deconvolve optical astronomical images (Sureau et al. 2020). Yet, this approach only uses the $\ell_2$ loss, which does not guarantee the preservation of physical information (e.g. flux and shape) of the object reconstructed in the image. In Nammour et al. (2021), a new loss function was proposed in the framework of sparse deconvolution, which better preserves the shape of galaxies and reduces the pixel error. In this paper, we extend Tikhonet to take into account this shape constraint, and apply our new DL method, called ShapeNet, to optical and radio-interferometry simulated data set. The originality of the paper relies on i) the shape constraint we use in the neural network framework, ii) the application of deep learning to radio-interferometry image deconvolution for the first time, and iii) the generation of a simulated radio data set that we make available for the community. A range of examples illustrates the results.
Sparse Semantic Map-Based Monocular Localization in Traffic Scenes Using Learned 2D-3D Point-Line Correspondences
Oct 10, 2022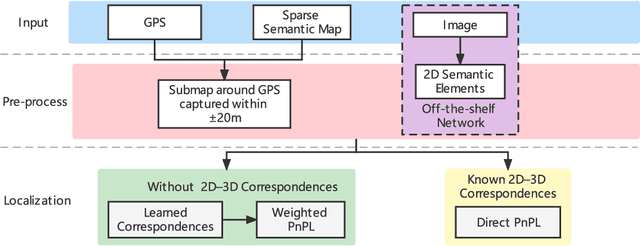
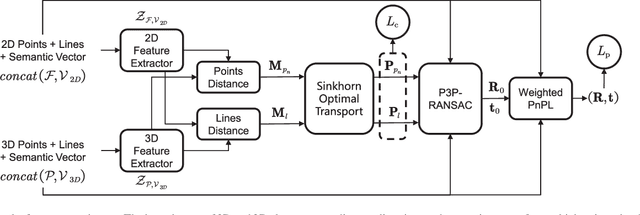
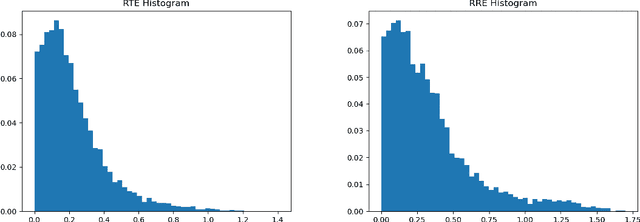
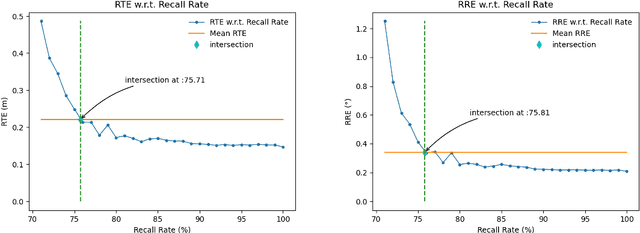
Vision-based localization in a prior map is of crucial importance for autonomous vehicles. Given a query image, the goal is to estimate the camera pose corresponding to the prior map, and the key is the registration problem of camera images within the map. While autonomous vehicles drive on the road under occlusion (e.g., car, bus, truck) and changing environment appearance (e.g., illumination changes, seasonal variation), existing approaches rely heavily on dense point descriptors at the feature level to solve the registration problem, entangling features with appearance and occlusion. As a result, they often fail to estimate the correct poses. To address these issues, we propose a sparse semantic map-based monocular localization method, which solves 2D-3D registration via a well-designed deep neural network. Given a sparse semantic map that consists of simplified elements (e.g., pole lines, traffic sign midpoints) with multiple semantic labels, the camera pose is then estimated by learning the corresponding features between the 2D semantic elements from the image and the 3D elements from the sparse semantic map. The proposed sparse semantic map-based localization approach is robust against occlusion and long-term appearance changes in the environments. Extensive experimental results show that the proposed method outperforms the state-of-the-art approaches.
A Wavelet-based Dual-stream Network for Underwater Image Enhancement
Feb 17, 2022

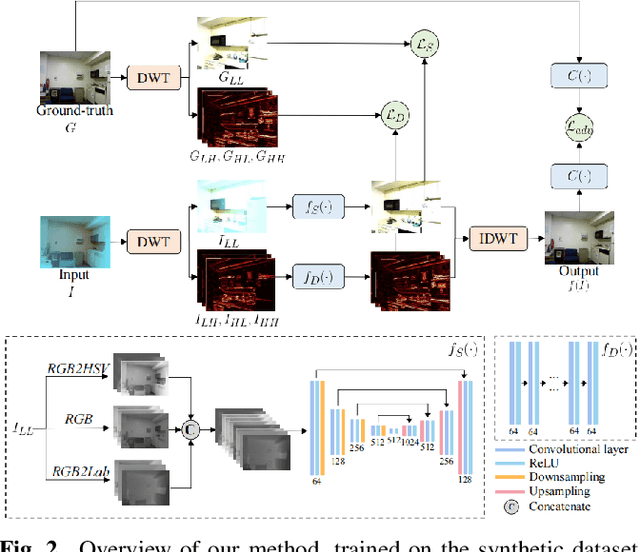
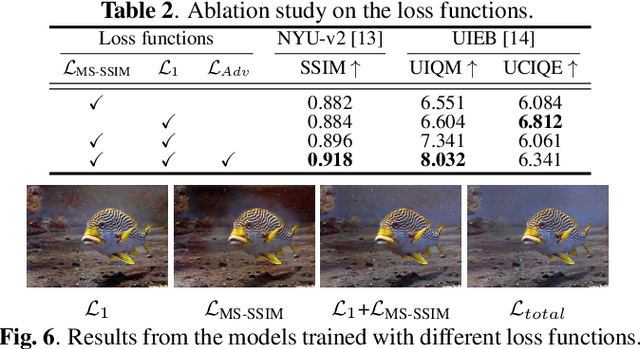
We present a wavelet-based dual-stream network that addresses color cast and blurry details in underwater images. We handle these artifacts separately by decomposing an input image into multiple frequency bands using discrete wavelet transform, which generates the downsampled structure image and detail images. These sub-band images are used as input to our dual-stream network that incorporates two sub-networks: the multi-color space fusion network and the detail enhancement network. The multi-color space fusion network takes the decomposed structure image as input and estimates the color corrected output by employing the feature representations from diverse color spaces of the input. The detail enhancement network addresses the blurriness of the original underwater image by improving the image details from high-frequency sub-bands. We validate the proposed method on both real-world and synthetic underwater datasets and show the effectiveness of our model in color correction and blur removal with low computational complexity.
Large Scale Real-World Multi-Person Tracking
Nov 03, 2022
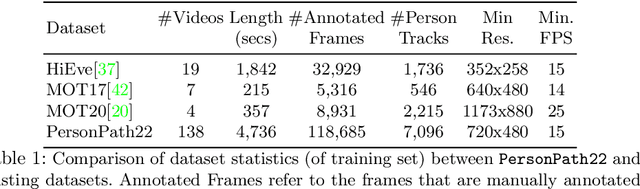
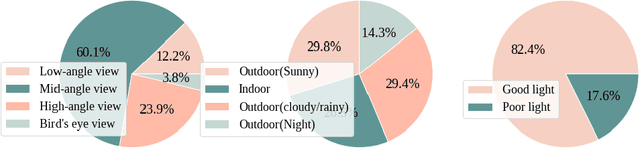
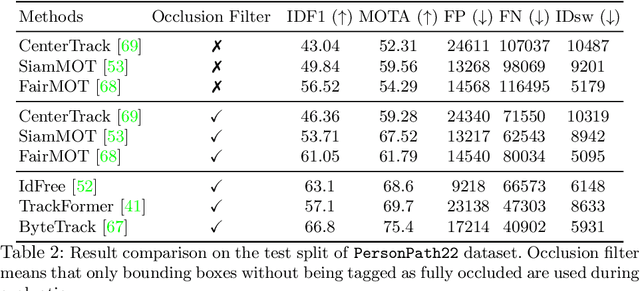
This paper presents a new large scale multi-person tracking dataset -- \texttt{PersonPath22}, which is over an order of magnitude larger than currently available high quality multi-object tracking datasets such as MOT17, HiEve, and MOT20 datasets. The lack of large scale training and test data for this task has limited the community's ability to understand the performance of their tracking systems on a wide range of scenarios and conditions such as variations in person density, actions being performed, weather, and time of day. \texttt{PersonPath22} dataset was specifically sourced to provide a wide variety of these conditions and our annotations include rich meta-data such that the performance of a tracker can be evaluated along these different dimensions. The lack of training data has also limited the ability to perform end-to-end training of tracking systems. As such, the highest performing tracking systems all rely on strong detectors trained on external image datasets. We hope that the release of this dataset will enable new lines of research that take advantage of large scale video based training data.
Q-LIC: Quantizing Learned Image Compression with Channel Splitting
May 28, 2022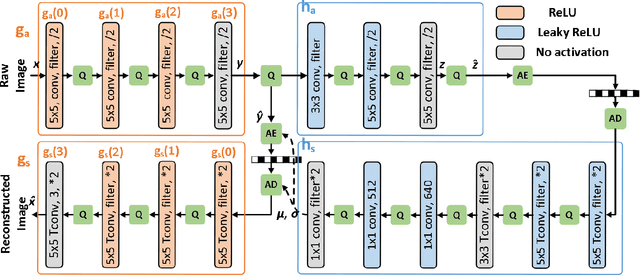

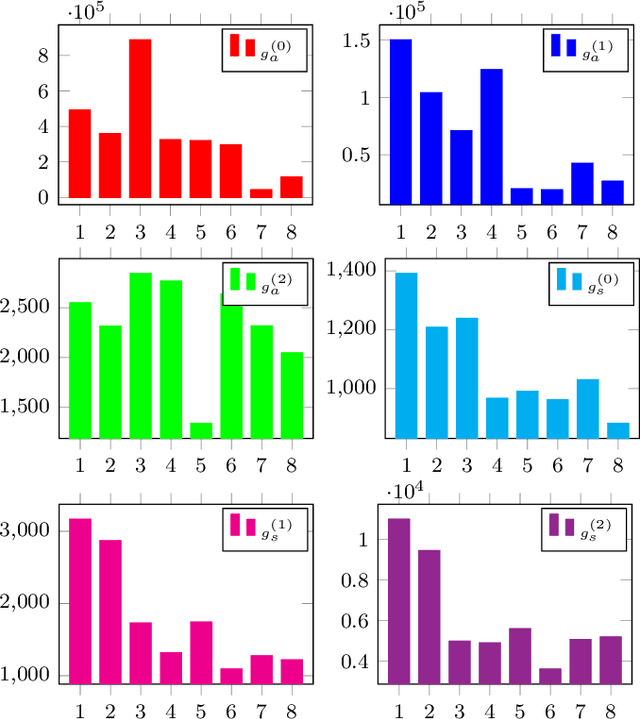
Learned image compression (LIC) has reached a comparable coding gain with traditional hand-crafted methods such as VVC intra. However, the large network complexity prohibits the usage of LIC on resource-limited embedded systems. Network quantization is an efficient way to reduce the network burden. This paper presents a quantized LIC (QLIC) by channel splitting. First, we explore that the influence of quantization error to the reconstruction error is different for various channels. Second, we split the channels whose quantization has larger influence to the reconstruction error. After the splitting, the dynamic range of channels is reduced so that the quantization error can be reduced. Finally, we prune several channels to keep the number of overall channels as origin. By using the proposal, in the case of 8-bit quantization for weight and activation of both main and hyper path, we can reduce the BD-rate by 0.61%-4.74% compared with the previous QLIC. Besides, we can reach better coding gain compared with the state-of-the-art network quantization method when quantizing MS-SSIM models. Moreover, our proposal can be combined with other network quantization methods to further improve the coding gain. The moderate coding loss caused by the quantization validates the feasibility of the hardware implementation for QLIC in the future.